salut! Je m'appelle Igor Narazin, je suis le chef d'équipe de l'équipe logistique du Delivery Club. Je veux vous dire comment nous construisons et transformons notre architecture et comment cela affecte nos processus de développement.
Maintenant Delivery Club (ainsi que l'ensemble du marché de la foodtech) se développe très rapidement, ce qui crée un grand nombre de défis pour l'équipe technique, qui peuvent être résumés par deux des critères les plus importants:
- Vous devez garantir une stabilité et une disponibilité élevées de toutes les parties de la plate-forme
- Dans le même temps, gardez un rythme élevé de développement de nouvelles fonctionnalités.
Il semble que ces deux problèmes s'excluent mutuellement: soit nous transformons la plate-forme, en essayant de faire de nouvelles modifications le moins possible jusqu'à ce que nous ayons terminé, soit nous développons rapidement de nouvelles fonctionnalités sans changements drastiques dans le système.
Mais nous réussissons (jusqu'à présent) les deux. La manière dont nous procédons sera discutée plus en détail.
Tout d'abord, je vais vous parler de notre plateforme : comment nous la transformons en tenant compte des volumes de données en constante augmentation, quels critères nous appliquons à nos services et quels problèmes nous rencontrons en cours de route.
Deuxièmement, je partagerai comment nous résolvons le problème de la fourniture de fonctionnalités sans entrer en conflit avec les changements de la plate-forme et sans dégradation inutile du système.
Commençons par la plateforme.
Au début, il y avait un monolithe
Les premières lignes de code Delivery Club ont été écrites il y a 11 ans, et dans les meilleures traditions du genre, l'architecture était un monolithe en PHP. Pendant 7 ans, il a été rempli de fonctionnalités de plus en plus jusqu'à ce qu'il soit confronté aux problèmes classiques de l'architecture monolithique.
Au début, nous en étions entièrement satisfaits: il était facile à maintenir, à tester et à déployer. Et il a fait face aux charges initiales sans problème. Mais, comme c'est généralement le cas, à un moment donné, nous avons atteint des taux de croissance tels que notre monolithe est devenu un goulot d'étranglement très dangereux:
- tout échec ou problème dans le monolithe affectera absolument tous nos processus;
- le monolithe est lié de manière rigide à une pile spécifique qui ne peut pas être modifiée;
- compte tenu de la croissance de l'équipe de développement, il devient difficile de faire des changements: la connectivité élevée des composants ne permet pas une livraison rapide des fonctionnalités;
- le monolithe ne peut pas être mis à l'échelle de manière flexible.
Cela nous a conduit à l'architecture (surprise) des microservices - beaucoup de choses ont été dites et écrites sur ses avantages et ses inconvénients. L'essentiel est qu'il résout l'un de nos principaux problèmes et nous permet d'atteindre une disponibilité et une tolérance aux pannes maximales de l'ensemble du système. Je ne m'attarderai pas là-dessus dans cet article, je vais plutôt vous dire avec des exemples comment nous l'avons fait et pourquoi.
Notre principal problème était la taille de la base de code monolithique et la faible expertise de l'équipe qui la composait (la plate-forme est ce que nous appelons ancienne). Bien sûr, au début, nous voulions simplement prendre et couper le monolithe afin de résoudre complètement le problème. Mais nous nous sommes rendu compte très vite que cela prendra plus d'un an, et le nombre de changements qui y sont apportés ne permettra jamais que cela s'arrête.
Par conséquent, nous sommes allés dans l'autre sens: nous l'avons laissé tel quel et avons décidé de construire le reste des services autour du monolithe. Il continue d'être le principal point de logique de traitement de la commande et de maître de données, mais commence à diffuser des données pour d'autres services.
Écosystème
Comme l'a dit Andrey Evsyukov dans un article sur nos équipes, nous avons mis en évidence les principaux domaines dans les domaines du domaine: R&D, Logistique, Consommateur, Fournisseur, Interne, Plateforme. Dans ces domaines, les principaux domaines avec lesquels les services travaillent sont déjà concentrés: par exemple, pour la logistique, ce sont les courriers et les commandes, et pour les fournisseurs - les restaurants et les postes.
Ensuite, nous devons passer à un niveau supérieur et construire un écosystème de nos services autour de la plateforme: le traitement des commandes est au centre et est le maître des données, le reste des services est construit autour de lui. Dans le même temps, il est important pour nous de rendre nos directions autonomes: si une partie échoue, le reste continue à fonctionner.
À faible charge, la création de l'écosystème nécessaire est assez simple: nos processus de traitement et stocke les données, et les services de référence en font la demande selon les besoins.
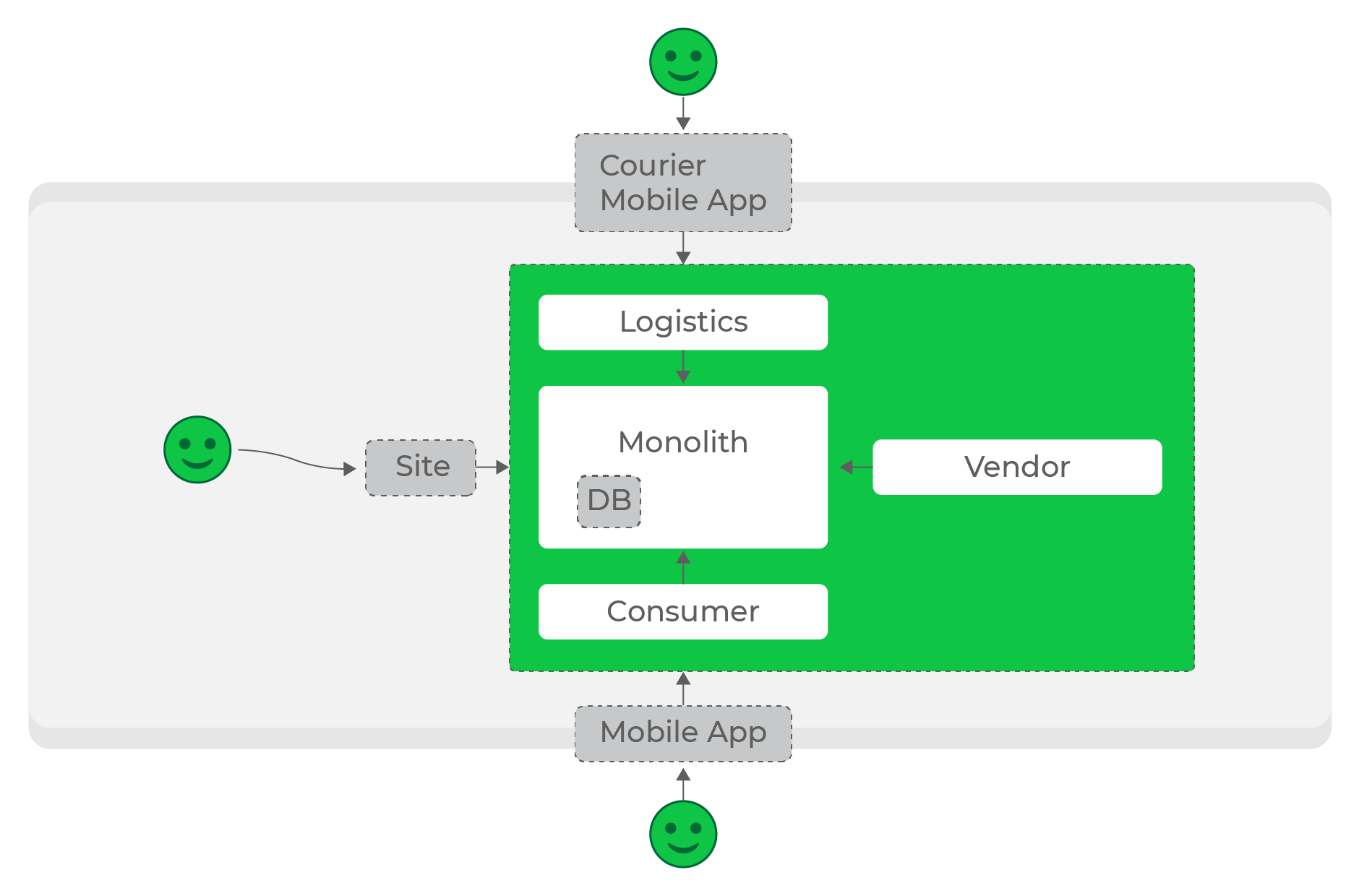 Faibles charges, requêtes synchrones, tout fonctionne très bien.
Faibles charges, requêtes synchrones, tout fonctionne très bien.
Au début, c'est exactement ce que nous avons fait: la plupart des services communiquaient entre eux avec des requêtes HTTP synchrones. Sous une certaine charge, cela était permis, mais plus le projet et le nombre de services augmentaient, plus cela devenait problématique.
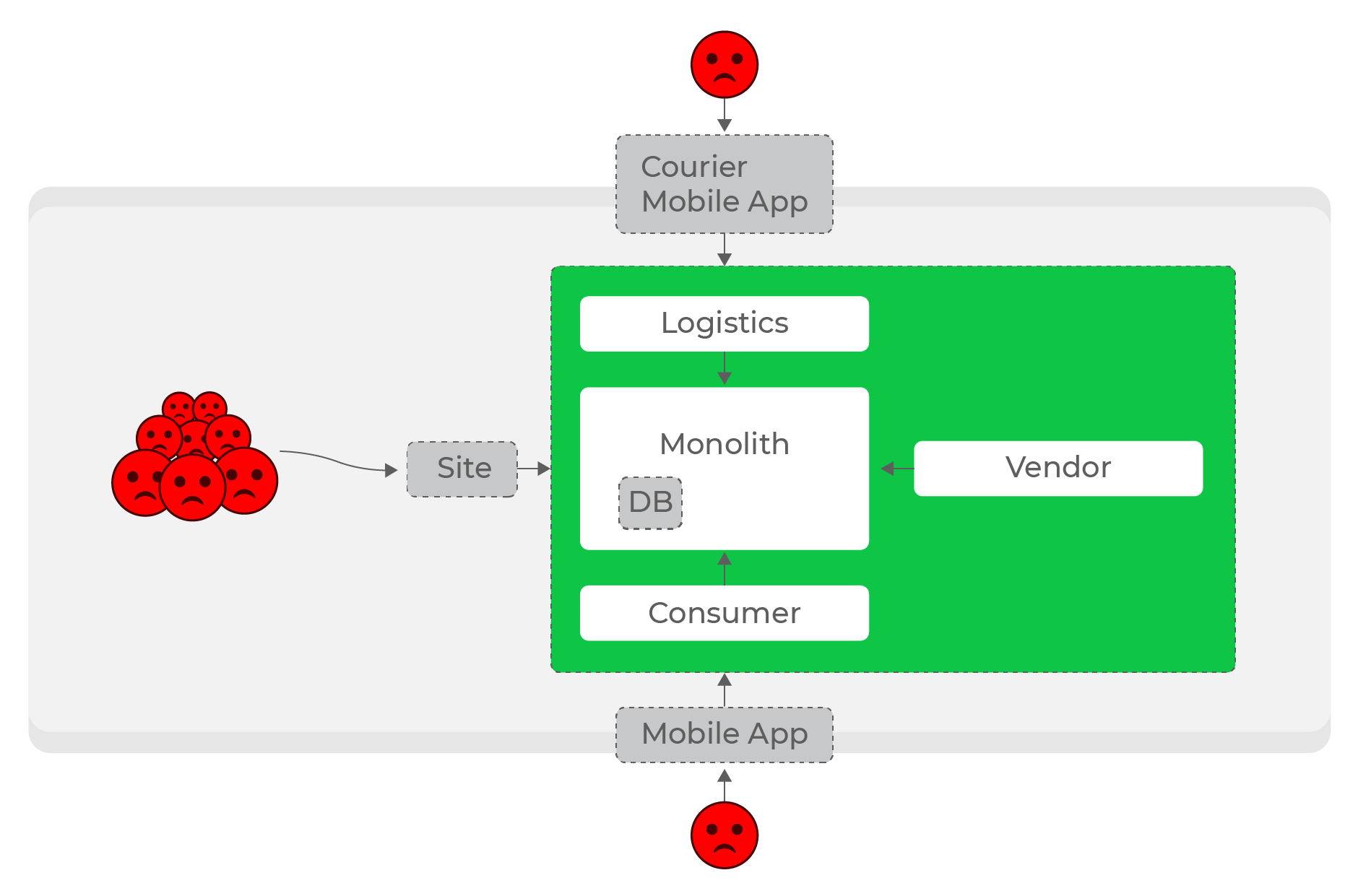
Charges élevées, demandes synchrones: tout le monde souffre, même les utilisateurs de domaines complètement différents - les courriers.
Il est encore plus difficile de rendre les services autonomes dans les directions: par exemple, une augmentation de la charge logistique ne devrait pas affecter le reste du système. Avec n'importe quel nombre de requêtes synchrones, il s'agit d'un problème insoluble. De toute évidence, il fallait abandonner les requêtes synchrones et passer à la communication asynchrone.
Bus de données
Ainsi, nous avons eu beaucoup de goulots d'étranglement, où nous avons accédé aux données en mode synchrone. Ces endroits étaient très dangereux en termes de charge accrue.
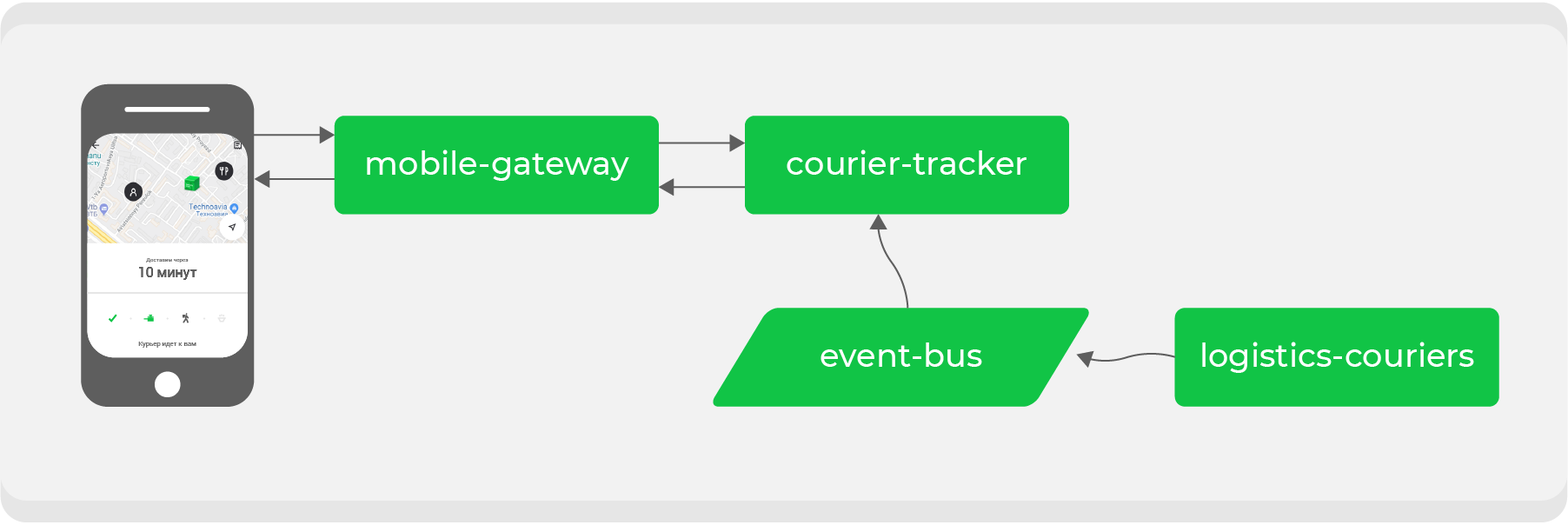
Voici un exemple. Quiconque a passé une commande via Delivery Club au moins une fois sait qu'une fois que le transporteur a récupéré la commande, la carte devient visible. Sur celui-ci, vous pouvez suivre le mouvement du courrier en temps réel. Plusieurs microservices sont impliqués pour cette fonctionnalité, les principaux sont:
mobile-gatewayqui est un backend pour frontend pour une application mobile;courier-tracker, qui stocke la logique de réception et d'envoi des coordonnées;logistics-couriersqui stocke ces coordonnées. Ils sont envoyés à partir d'applications mobiles de messagerie.
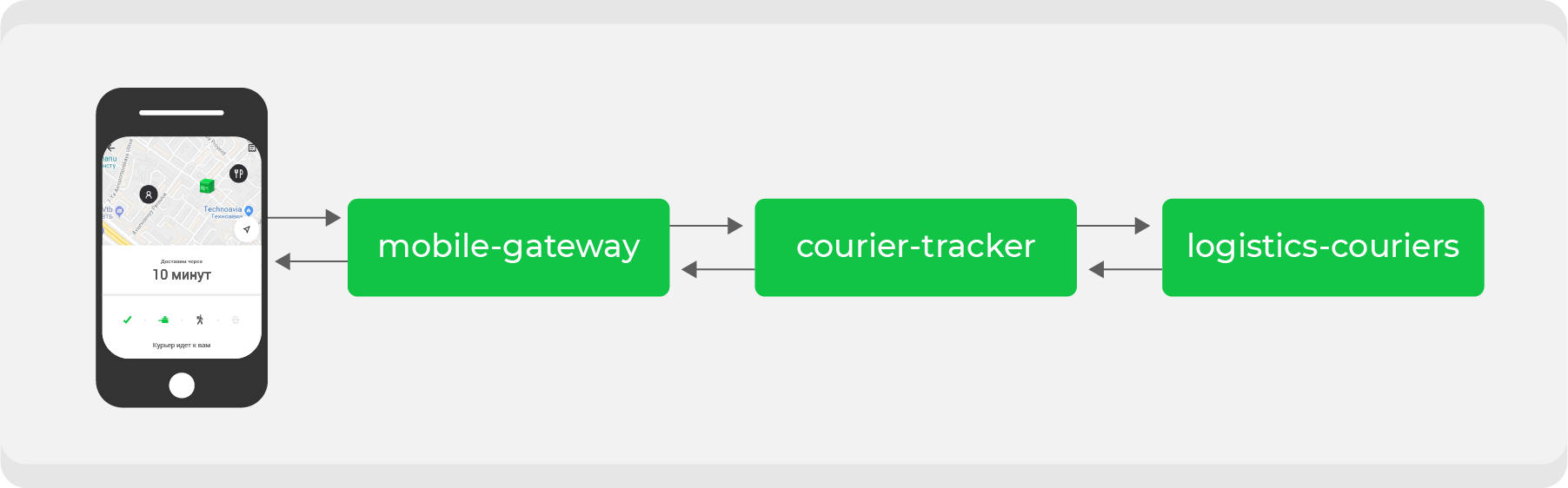
Dans le schéma d'origine, tout fonctionnait de manière synchrone: les demandes de l'application mobile une fois par minute étaient transmises
mobile-gatewayau service courier-trackerqui accédait logistics-courierset recevait les coordonnées. Bien sûr, dans ce schéma, ce n'était pas si simple, mais à la fin tout se résumait à une simple conclusion: plus nous avons d'ordres actifs, plus il y a de demandes de coordonnées reçues logistics-couriers.
Notre croissance est parfois imprévisible et, surtout, rapide - une question de temps avant qu'un tel système échoue. Cela signifie que nous devons refaire le processus d'interaction asynchrone: rendre la demande de coordonnées aussi bon marché que possible. Pour ce faire, nous devons transformer nos flux de données.
Transport
Nous avons déjà utilisé RabbitMQ, y compris pour la communication entre les services. Mais en tant que principal mode de transport, nous avons opté pour l'outil déjà éprouvé - Apache Kafka. Nous allons écrire un article détaillé à ce sujet, mais maintenant je voudrais parler brièvement de la façon dont nous l'utilisons.
Lorsque nous avons commencé à implémenter Kafka en tant que transport, nous l'avons utilisé sous sa forme brute, en nous connectant directement aux courtiers et en leur envoyant des messages. Cette approche nous a permis de tester rapidement Kafka au combat et de décider de continuer à l'utiliser comme mode de transport principal.
Mais cette approche présente un inconvénient majeur: les messages n'ont pas de saisie et de validation - nous ne savons pas avec certitude quel format de message nous lisons dans le sujet.
Cela augmente le risque d'erreurs et d'incohérences entre les services qui fournissent les données et ceux qui les consomment.
Pour résoudre ce problème, nous avons écrit un wrapper - un microservice dans Go, qui cache Kafka derrière son API. Cela a ajouté deux avantages:
- validation des données au moment de l'envoi et de la réception. En fait, ce sont les mêmes DTO, nous sommes donc toujours confiants dans le format des données attendues.
- intégration rapide de nos services avec ce transport.
Ainsi, travailler avec Kafka est devenu le plus abstrait possible pour nos services: ils ne fonctionnent qu'avec l'API de premier niveau de ce wrapper.
Revenons à l'exemple
En transférant la communication synchrone vers le bus d'événements, nous devons inverser le flux de données: ce que nous avons demandé devrait maintenant nous parvenir via Kafka lui-même. Dans l'exemple, nous parlons des coordonnées du courrier, pour lequel nous allons maintenant créer un sujet spécial et les produire au fur et à mesure que nous les recevrons des courriers par le service
logistics-couriers.
Le service
courier-trackern'a qu'à accumuler les coordonnées dans le montant requis et pour la période requise. En conséquence, notre point de terminaison devient aussi simple que possible: prenez les données de la base de données de service et donnez-les à une application mobile. L'augmentation de la charge est désormais sans danger pour nous.
En plus de résoudre un problème spécifique, nous obtenons par conséquent un sujet de données avec les coordonnées réelles des courriers, que n'importe lequel de nos services peut utiliser à ses propres fins.
Finalement, cohérence
Dans cet exemple, tout fonctionne bien, sauf que les coordonnées des courriers ne seront pas toujours à jour par rapport à l'option synchrone: dans une architecture construite sur l'interaction asynchrone, la question se pose de la pertinence des données à un instant donné. Mais nous n'avons pas beaucoup de données critiques que nous devons garder toujours à jour, donc ce schéma est idéal pour nous: nous sacrifions la pertinence de certaines informations afin d'augmenter le niveau de disponibilité du système. Mais nous garantissons qu'en fin de compte, dans toutes les parties du système, toutes les données seront pertinentes et cohérentes (éventuellement cohérence).
Cette dénormalisation des données est nécessaire lorsqu'il s'agit d'un système à forte charge et d'une architecture de microservices: chaque service lui-même assure le stockage des données dont il a besoin pour fonctionner. Par exemple, l'une des principales entités de notre domaine est le courrier. De nombreux services fonctionnent avec, mais ils ont tous besoin d'un ensemble de données différent: quelqu'un a besoin de données personnelles et quelqu'un n'a besoin que d'informations sur le type de mouvement. Le maître de données de ce domaine produira l'entité entière dans le flux, et les services accumulent les parties nécessaires:
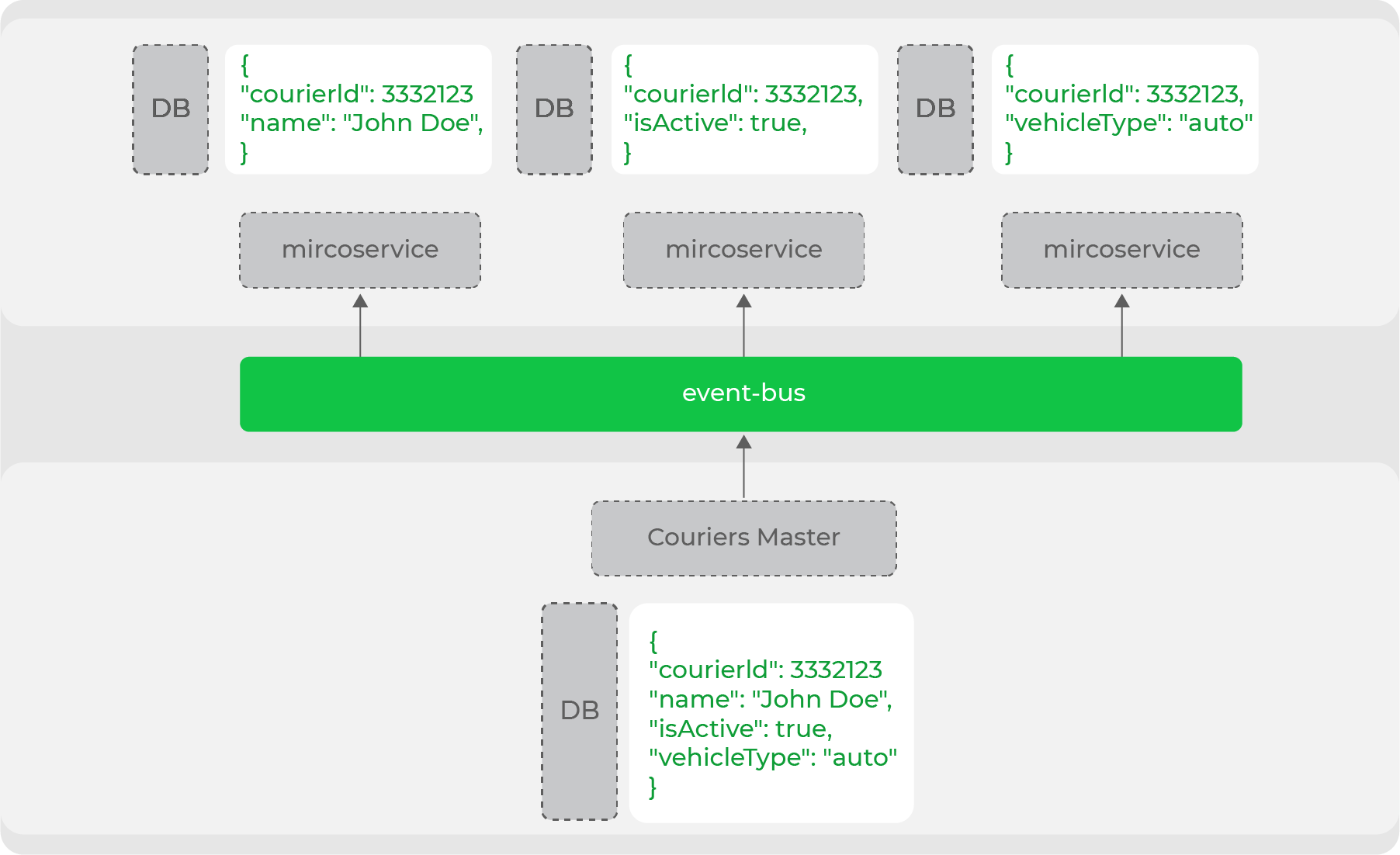
Ainsi, nous divisons clairement nos services entre ceux qui sont des maîtres de données et ceux qui utilisent ces données. En fait, il s'agit d'un commerce sans tête de l'image évolutive - nous avons clairement séparé toutes les «vitrines» (site Web, applications mobiles) des producteurs de ces données.
Dénormalisation
Autre exemple: nous avons un mécanisme de notifications ciblées aux courriers - ce sont des messages qui leur parviendront dans l'application. Du côté backend, il existe une API puissante pour envoyer de telles notifications. Dans celui-ci, vous pouvez configurer des filtres de mailing: d'un courrier spécifique à des groupes de courriers selon certains critères.
Le service est responsable de ces notifications
logistics-courier-notifications. Après avoir reçu une demande d'envoi, sa tâche est de générer des messages pour les courriers qui ont été ciblés. Pour ce faire, il doit connaître les informations nécessaires sur tous les coursiers du Delivery Club. Et nous avons deux options pour résoudre ce problème:
- créer un point de terminaison côté service - l'assistant de données de messagerie (
logistics-couriers), qui sera capable de filtrer et de renvoyer les courriers nécessaires par les champs transmis; - stocker toutes les informations nécessaires directement dans le service, en les consommant à partir de la rubrique correspondante et en enregistrant les données par lesquelles nous devrons filtrer à l'avenir.
Une partie de la logique de génération des messages et de filtrage des courriers n'est pas chargée, elle est exécutée en arrière-plan, il n'y a donc pas de question sur la charge sur le service
logistics-couriers. Mais si nous choisissons la première option, nous sommes confrontés à un ensemble de problèmes:
- vous devrez prendre en charge un point de terminaison hautement spécialisé dans un service tiers, dont nous aurons très probablement besoin;
- si vous sélectionnez un filtre trop large, tous les courriers qui ne rentrent tout simplement pas dans la réponse HTTP seront inclus dans l'exemple et vous devrez implémenter la pagination (et l'itérer lors de l'interrogation du service).
Évidemment, nous nous sommes arrêtés au stockage des données dans le service lui-même. Il effectue tout le travail de manière autonome et isolée, n'accédant nulle part, mais accumulant uniquement toutes les données nécessaires de son sujet Kafka. Il y a un risque que nous recevions un message concernant la création d'un nouveau coursier plus tard, et il ne sera pas inclus dans une sélection. Mais cet inconvénient d'une architecture asynchrone est inévitable.
En conséquence, nous avons formulé plusieurs principes importants pour la conception de services:
- Le service doit avoir une responsabilité spécifique. Si un service est encore nécessaire pour son fonctionnement à part entière, il s'agit d'une erreur de conception, ils doivent soit être combinés, soit l'architecture doit être révisée.
- Nous examinons d'un œil critique tous les appels synchrones. Pour les services dans un sens, cela est acceptable, mais pour la communication entre les services dans des directions différentes, ce n'est pas
- Ne partagez rien. Nous n'allons pas à la base de données des services en les contournant. Toutes les demandes uniquement via l'API.
- Spécification d'abord. Tout d'abord, nous décrivons et approuvons les protocoles.
Ainsi, en transformant de manière itérative notre système selon les principes et approches acceptés, nous sommes arrivés à l'architecture suivante:
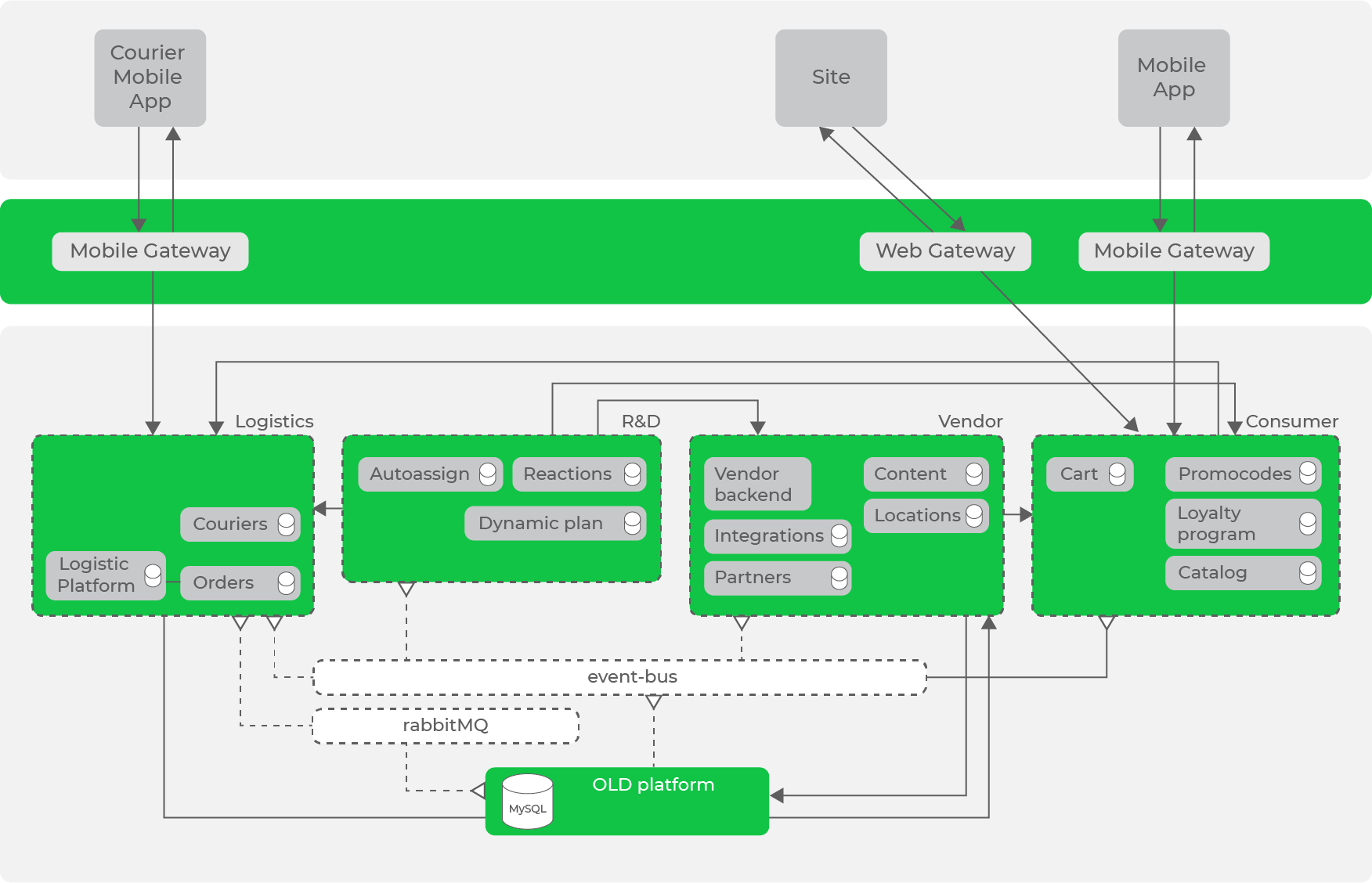
Nous avons déjà un bus de données sous la forme de Kafka, qui a déjà un nombre important de flux de données, mais il y a encore des requêtes synchrones entre les directions.
Comment nous prévoyons de développer notre architecture
Le club de livraison, comme je l'ai dit au début, se développe rapidement, nous sortons un grand nombre de nouvelles fonctionnalités en production. Et nous expérimentons encore plus ( Nikolay Arkhipov en a parlé en détail ) et testons des hypothèses. Tout cela donne lieu à un grand nombre de sources de données et encore plus d'options pour leur utilisation. Et la bonne gestion des flux de données, qu'il est très important de construire correctement - c'est notre tâche.
Désormais, nous continuerons à mettre en œuvre les approches développées à l'ensemble des services Delivery Club: construire des écosystèmes de services autour d'une plateforme avec transport sous forme de bus de données.
La tâche principale est de s'assurer que les informations sur tous les domaines du système sont fournies au bus de données. Pour les nouveaux services avec de nouvelles données, ce n'est pas un problème: au stade de la préparation du service, il sera obligé de streamer ses données de domaine vers Kafka.
Mais en plus des nouveaux, nous avons de grands services hérités avec des données sur nos principaux domaines: les commandes et les courriers. Il est problématique de diffuser ces données «telles quelles», car elles sont stockées réparties sur des dizaines de tables, et il sera très coûteux de construire l'entité finale pour produire tous les changements à chaque fois.
Par conséquent, nous avons décidé d'utiliser Debezium pour les anciens services ., qui vous permet de diffuser des informations directement à partir de tables basées sur bin-log: vous obtenez ainsi une rubrique prête à l'emploi avec les données brutes de la table. Mais ils ne sont pas adaptés à une utilisation dans leur forme d'origine, donc grâce aux transformateurs au niveau Kafka, ils seront convertis dans un format compréhensible pour les consommateurs et poussés dans un nouveau sujet. Ainsi, nous aurons un ensemble de sujets privés avec des données brutes provenant de tableaux, qui seront transformés en un format pratique et diffusés sur un sujet public à l'usage des consommateurs.
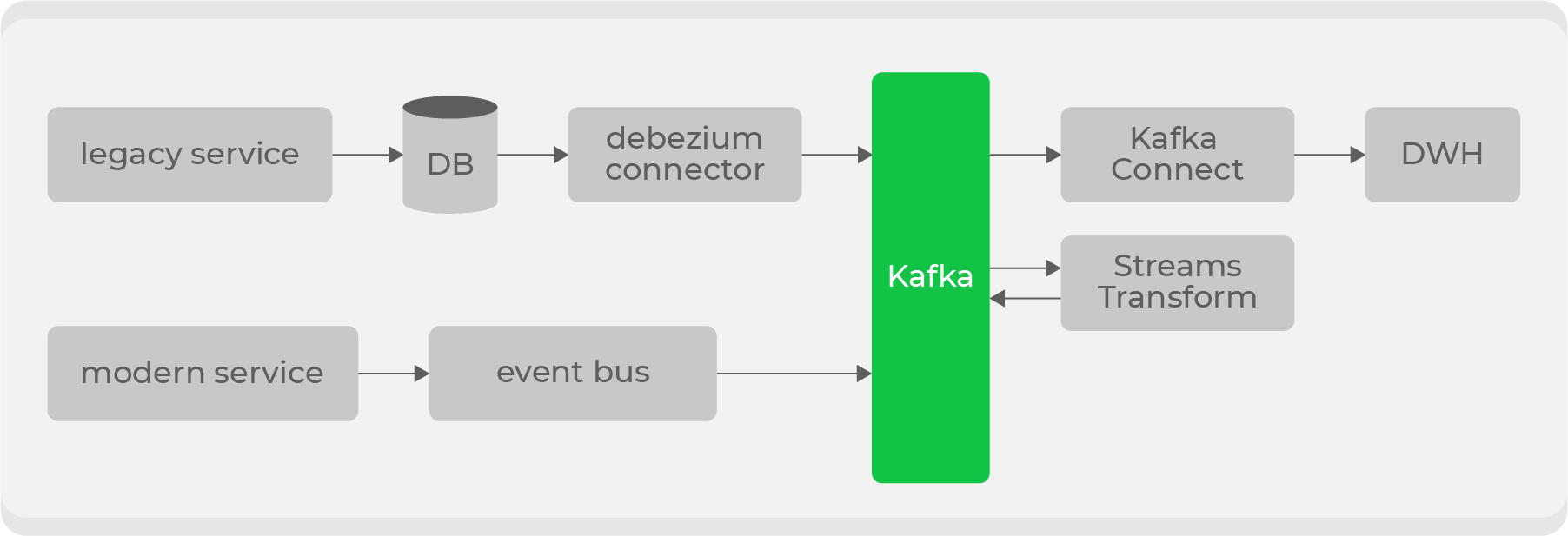
Il y aura plusieurs points d'entrée pour écrire dans Kafka et différents types de sujets, nous allons donc implémenter les droits d'accès par rôle du côté stockage et ajouter la validation de schéma côté bus de données via Confluent .
Plus loin du bus de données, les services consommeront les données des thèmes nécessaires. Et nous utiliserons nous-mêmes ces données pour nos systèmes: par exemple, diffusez via Kafka Connect vers ElasticSearch ou DWH. Avec ce dernier, le processus sera plus compliqué: pour que les informations qu'il contient soient accessibles à tous, il doit être effacé de toute donnée personnelle.
Nous devons également résoudre enfin le problème du monolithe: il y a encore des processus critiques que nous allons endurer dans un proche avenir. Plus récemment, nous avons déjà déployé un service distinct qui traite de la première étape de création d'une commande: formation d'un panier, réception et paiement. Ensuite, il envoie ces données au monolithe pour un traitement ultérieur. Eh bien, toutes les autres opérations ne nécessitent plus de synchronisation.
Comment faire ce refactoring de manière transparente pour les clients
Je vais vous parler d'un autre exemple: un catalogue de restaurants. Évidemment, c'est un endroit très fréquenté, et nous avons décidé de le déplacer vers un service séparé sur Go. Pour accélérer le développement, nous avons divisé les plats à emporter en deux étapes:
- Tout d'abord, à l'intérieur du service, nous allons directement à une réplique de la base de notre monolithe et en récupérons les données.
- Ensuite, nous commençons à diffuser les données dont nous avons besoin via Debezium et à les accumuler dans la base de données du service lui-même.
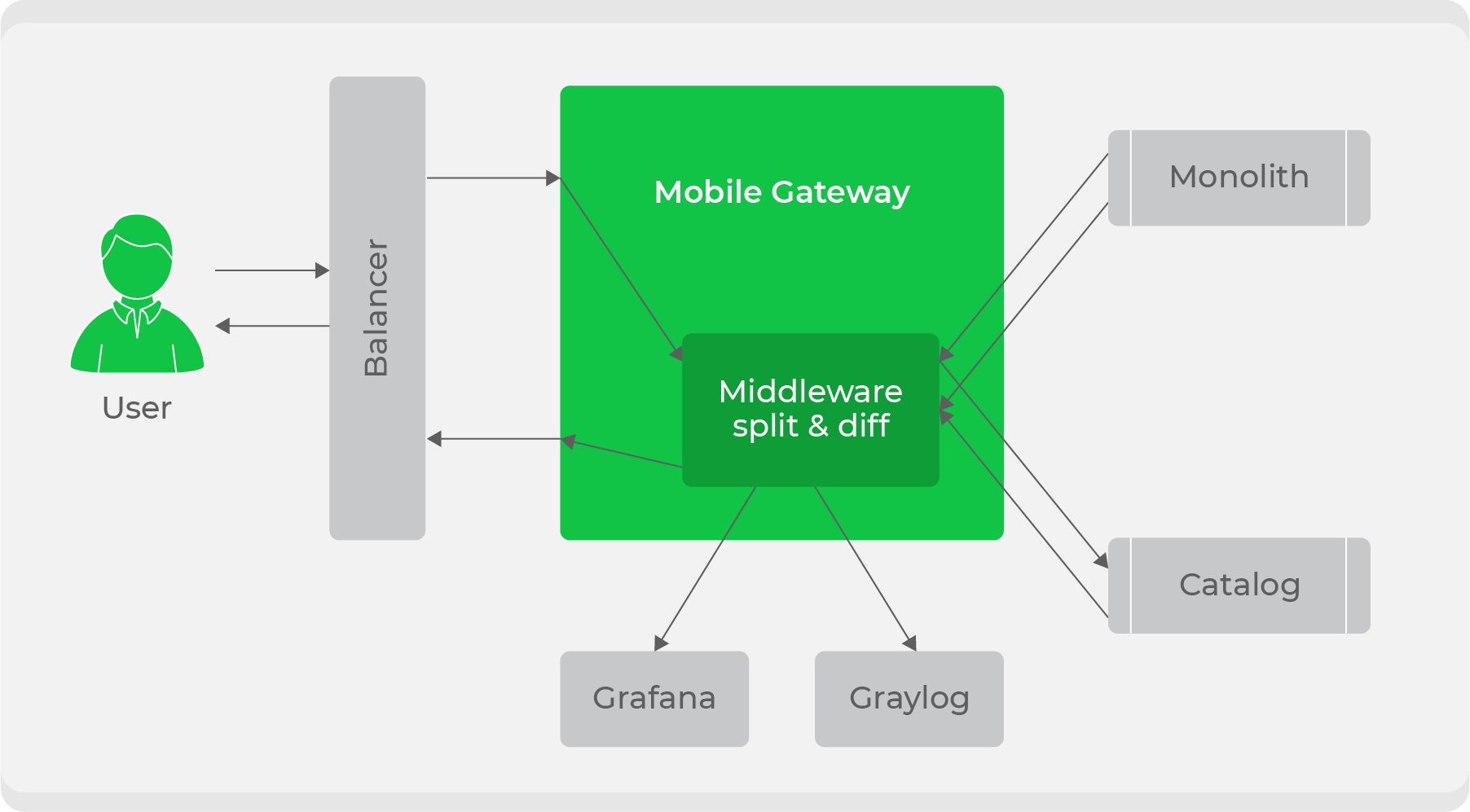
Lorsque le service est prêt, la question se pose de savoir comment l'intégrer de manière transparente dans le flux de travail actuel. Nous avons utilisé un schéma de répartition du trafic: tout le trafic des clients est allé au service
mobile-gateway, puis il a été divisé entre le monolithe et le nouveau service. Au départ, nous avons continué à traiter tout le trafic à travers le monolithe, mais nous avons dupliqué certains d'entre eux dans un nouveau service, comparé leurs réponses et noté les écarts dans nos métriques. Avec cela, nous avons assuré la transparence des tests du service en conditions de combat. Après cela, il ne restait plus qu'à basculer et à augmenter progressivement le trafic jusqu'à ce que le nouveau service remplace complètement le monolithe.
En général, nous avons beaucoup de plans et d'idées ambitieux. Nous n'en sommes qu'au début de l'élaboration de notre nouvelle stratégie, alors que sa forme finale n'est pas claire et que l'on ne sait pas si tout fonctionnera comme prévu. Dès que nous mettrons en œuvre et tirerons des conclusions, nous partagerons certainement les résultats.
Parallèlement à tous ces changements conceptuels, nous continuons à développer activement et à fournir des fonctionnalités au produit, ce qui prend la plupart du temps. Nous arrivons ici au deuxième problème, dont j'ai parlé au début: compte tenu du nombre de développeurs (180 personnes), se pose la question de la validation de l'architecture et de la qualité des nouveaux services. Le nouveau ne doit pas dégrader le système, il doit être correctement intégré dès le début. Mais comment contrôler cela à l'échelle industrielle?
Comité d'architecture
Le besoin ne s'est pas fait sentir immédiatement. Lorsque l'équipe de développement était petite, toutes les modifications apportées au système étaient faciles à contrôler. Mais plus il y a de monde, plus il est difficile de le faire.
Cela pose à la fois des problèmes réels (le service n'a pas pu supporter la charge en raison d'une mauvaise conception) et des problèmes conceptuels («marchons de manière synchrone ici, la charge est faible»).
Il est clair que la plupart des problèmes sont résolus au niveau de l'équipe. Mais si nous parlons d'une sorte d'intégration complexe dans le système actuel, alors l'équipe peut simplement ne pas avoir suffisamment d'expertise. Par conséquent, j'ai voulu créer une sorte d'association de personnes de toutes les directions, à laquelle on pourrait venir avec n'importe quelle question sur l'architecture et obtenir une réponse exhaustive.
Nous sommes donc arrivés à la création d'un comité d'architecture, qui comprend des chefs d'équipe, des chefs de direction et des CTO. Nous nous réunissons toutes les deux semaines et discutons des changements majeurs prévus dans le système ou résolvons simplement des problèmes spécifiques.
En conséquence, nous avons résolu le problème de la maîtrise des grands changements, la question de l'approche générale de la qualité du code dans Delivery Club demeure: les problèmes spécifiques du code ou du framework dans différentes équipes peuvent être résolus de différentes manières. Nous sommes venus à des guildes sur le modèle Spotify: ce sont des syndicats de personnes qui ne sont pas indifférentes à certaines technologies. Par exemple, il existe des guildes Go, PHP et Frontend.
Ils développent des styles de programmation uniformes, des approches de conception et d'architecture, aident à former et à maintenir une culture d'ingénierieau plus haut niveau. Ils ont également leur propre backlog, dans lequel ils améliorent les outils internes, par exemple, notre modèle Go pour les microservices.
Code produit
Outre le fait que les changements majeurs passent par le comité d'architecture, et que les guildes surveillent la culture du code dans son ensemble, nous avons encore une étape importante dans la préparation du service à la production: l'élaboration d'une check-list dans Confluence. Tout d'abord, lors de l'élaboration d'une check-list, le développeur évalue à nouveau sa décision; deuxièmement, il s'agit d'une exigence opérationnelle, car ils doivent comprendre quel type de nouveau service apparaît en production.
La liste de contrôle indique généralement:
- responsable du service (il s'agit généralement du responsable technique du service);
- des liens vers le tableau de bord avec des alertes personnalisées;
- description du service et lien vers Swagger;
- une description des services avec lesquels il interagira;
- charge estimée sur le service;
- health-check. URL, . Health-check - : 200, , - . , health check URL’ , , , PostgreSQL Redis.
Les alertes de service sont conçues au stade de l'approbation architecturale. Il est important que le développeur comprenne que le service est vivant et prend en compte non seulement les métriques techniques, mais également celles du produit. Cela ne signifie pas de conversions commerciales, mais des mesures qui montrent que le service fonctionne comme il se doit.
Par exemple, vous pouvez utiliser le service déjà décrit ci-dessus
courier-tracker, qui suit les courriers sur la carte. L'un des principaux paramètres est le nombre de courriers dont les coordonnées sont mises à jour. Si soudainement certains itinéraires ne sont pas mis à jour pendant une longue période, une alerte "quelque chose s'est mal passé" apparaît. Peut-être que quelque part, ils ne sont pas allés chercher les données, ou ils sont entrés incorrectement dans la base de données, ou un autre service est tombé en panne. Ce n'est pas une métrique technique ou une métrique de produit, mais cela montre la viabilité du service.
Pour les métriques, nous utilisons Graylog et Prometheus, créons des tableaux de bord et configurons des alertes dans Grafana.
Malgré le volume de préparation, la livraison des services à la production est assez rapide: tous les services sont initialement emballés dans Docker, sont déployés automatiquement sur scène après la formation du graphique tapé pour Kubernetes, puis tout est décidé par un bouton dans Jenkins.
Le déploiement d'un nouveau service à prod consiste à attribuer une tâche aux administrateurs dans Jira, qui fournit toutes les informations que nous avons préparées précédemment.
Sous la capuche
Nous avons maintenant 162 microservices écrits en PHP et Go. Ils ont été répartis entre les services d'environ 50% à 50%. Au départ, nous avons réécrit certains services à forte charge dans Go. Ensuite, il est devenu clair que Go est plus facile à entretenir et à surveiller en production, son seuil d'entrée est bas, donc récemment, nous avons écrit des services uniquement à l'intérieur. Il n'y a aucun but de réécrire les services PHP restants dans Go: il gère ses fonctions avec succès.
Dans les services PHP, nous avons Symfony, sur lequel nous utilisons notre propre petit framework. Il impose une architecture commune aux services, grâce à laquelle nous abaissons le seuil de saisie du code source des services: quel que soit le service que vous ouvrez, il sera toujours clair ce qu'il contient et où. Et le framework encapsule également la couche de transport de communication entre les services, pour le développeur, une requête à un service tiers regarde un haut niveau d'abstraction:
Ici, nous formons le DTO de la requête ($courierResponse = $this->courierProtocol->get($courierRequest);
$courierRequest), appelons la méthode de l'objet protocole d'un service spécifique, qui est un wrapper sur un point de terminaison spécifique. Sous le capot, notre objet est $courierRequestconverti en un objet de requête, qui est rempli de champs du DTO. Tout cela est flexible: les champs peuvent être insérés à la fois dans les en-têtes et dans l'URL de la requête elle-même. Ensuite, la requête est envoyée via cURL, nous récupérons l'objet Response et le transformons à nouveau en l'objet attendu $courierResponse.
Cela permet aux développeurs de se concentrer sur la logique métier, sans détails d'interaction à un bas niveau. Les objets des protocoles, les demandes et les réponses des services sont dans un référentiel séparé - le SDK de ce service. Grâce à cela, tout service souhaitant utiliser ses protocoles recevra l'intégralité du package de protocole typé après l'importation du SDK.
Mais ce processus a un gros inconvénient: les référentiels avec le SDK sont difficiles à maintenir, car tous les DTO sont écrits manuellement, et la génération de code pratique n'est pas facile: il y a eu des tentatives, mais au final, étant donné la transition vers Go, ils n'y ont pas investi de temps.
En conséquence, les modifications du protocole de service peuvent se transformer en plusieurs pull requests: dans le service lui-même, dans son SDK et dans un service qui a besoin de ce protocole. Dans ce dernier, nous devons augmenter la version du SDK importé afin que les modifications y parviennent. Cela soulève souvent des questions de la part des nouveaux développeurs: "Je viens de changer le paramètre, pourquoi dois-je faire trois requêtes à trois référentiels différents?!"
En Go, tout est beaucoup plus simple: nous avons un excellent générateur de code (Sergey Popov a écrit un article détaillé à ce sujet), grâce auquel le protocole entier est typé, et maintenant même l'option de stocker toutes les spécifications dans un référentiel séparé est en cours de discussion. Ainsi, si quelqu'un change la spécification, tous les services qui en dépendent commenceront immédiatement à utiliser la version mise à jour.
Radar technique
En plus des Go et PHP déjà mentionnés, nous utilisons un grand nombre d'autres technologies. Ils varient d'une direction à l'autre et dépendent de tâches spécifiques. Fondamentalement, sur le backend, nous utilisons:
Python, sur lequel écrit l'équipe Data Science.KotlinetSwift- pour le développement d'applications mobiles.PostgreSQLen tant que base de données, mais certains services plus anciens exécutent toujours MySQL. Dans les microservices, nous utilisons plusieurs approches: chaque service a sa propre base de données et ne partage rien - nous n'allons pas aux bases de données contournant les services, uniquement via leur API.ClickHouse- pour les services hautement spécialisés liés à l'analyse.RedisetMemcachedcomme stockage en mémoire.
Lors du choix d'une technologie, nous sommes guidés par des principes particuliers . L'une des principales exigences est la facilité d'utilisation: nous utilisons la technologie la plus simple et la plus compréhensible pour le développeur, en adhérant autant que possible à la pile acceptée. Pour ceux qui veulent connaître l'ensemble des technologies spécifiques, nous avons compilé un radar technique très détaillé .
Longue histoire courte
En conséquence, nous sommes passés d'une architecture monolithique à une architecture de microservices, et maintenant nous avons déjà des groupes de services unis par des directions (domaines de domaine) autour de la plate-forme, qui est le cœur et le maître des données.
Nous avons une vision de la façon de réorganiser nos flux de données et comment le faire sans affecter la vitesse de développement de nouvelles fonctionnalités. À l'avenir, nous vous dirons certainement où cela nous a menés.
Et grâce au transfert actif des connaissances et à un processus formalisé de modifications, nous sommes en mesure de fournir un grand nombre de fonctionnalités qui ne ralentissent pas le processus de transformation de notre architecture.
C'est tout pour moi, merci d'avoir lu!