Quel était le but de cette étude? Je voulais savoir:
- Dans quelles applications Python est-il utilisé
- Quelles connaissances sont nécessaires: bases de données, bibliothèques, frameworks
- Combien de spécialistes dans chaque direction sont demandés
- Quels salaires sont offerts

Chargement des données
Emploi téléchargé à partir du site hh.ru , en utilisant l'API: dev.hh.ru . À la demande de "Python", les postes vacants de 1994 ont été téléchargés (région de Moscou), qui ont été divisés en suites de formation et de test, dans une proportion de 80% et 20% . La taille de l'ensemble d'apprentissage est de 1595 , la taille de l'ensemble de test est de 399 . L'ensemble de test ne sera utilisé que dans les sections Compétences Top / Antitop et Classification des emplois.
Panneaux
Sur la base du texte des offres d'emploi téléchargées, deux groupes de n-grammes de mots les plus courants ont été formés :
- 2 grammes en cyrillique et en latin
- 1 grammes en latin
Dans les postes vacants en TI, les compétences et technologies clés sont généralement rédigées en anglais, de sorte que le deuxième groupe comprenait des mots uniquement en latin.
Après la sélection de n-grammes, le premier groupe contenait 81 2 grammes et le second 98 1 grammes:
| Non. | n | n-gramme | Poids | Postes vacants |
| 1 | 2 | en python | huit | 258 |
| 2 | 2 | ci cd | huit | 230 |
| 3 | 2 | compréhension des principes | huit | 221 |
| 4 | 2 | connaissance de SQL | huit | 178 |
| cinq | 2 | développement et | neuf | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1 | sql | cinq | 490 |
| 83 | 1 | Linux | 6 | 462 |
| 84 | 1 | postgresql | cinq | 362 |
| 85 | 1 | docker | sept | 358 |
| 86 | 1 | Java | neuf | 297 |
| ... | ... | ... | ... | ... |
Il a été décidé de diviser les postes vacants en groupes selon les critères suivants par ordre de priorité:
| Une priorité | Critère | Poids |
| 1 | Domaine (direction appliquée), poste, expérience
n-gram: "apprentissage automatique", "administration linux", "excellente connaissance" |
7-9 |
| 2 | Outils, technologies, logiciels.
n-grammes: "sql", "linux os", "pytest" |
4-6 |
| 3 | Autres compétences
n-gram: "enseignement technique", "anglais", "tâches intéressantes" |
1-3 |
La détermination du groupe de critères auquel appartient le n-gramme et du poids à lui attribuer s'est déroulée de manière intuitive. Voici quelques exemples:
- À première vue, "Docker" peut être attribué au deuxième groupe de critères avec un poids de 4 à 6. Mais la mention de "Docker" dans le poste vacant signifie très probablement que le poste vacant concernera le poste "ingénieur DevOps". Par conséquent, "Docker" est tombé dans le premier groupe et a reçu un poids de 7.
- «Java» , .. «Java» Java- « Python». «-». , , , «Java» 9.
n- — .
Pour les calculs, chaque vacance a été transformée en un vecteur avec une dimension de 179 (le nombre de caractéristiques sélectionnées) d'entiers de 0 à 9, où 0 signifie que le i-ème n-gramme est absent de la vacance, et les nombres de 1 à 9 signifient la présence du i-ème n - grammes et son poids. Plus loin dans le texte, un point signifie une vacance représentée par un tel vecteur.
Exemple:
disons qu'une liste de n-grammes ne contient que trois valeurs:
Non. n n-gramme Poids Postes vacants 1 2 en python huit 258 2 2 compréhension des principes huit 221 3 1 sql cinq 490
Puis pour un poste vacant avec texte.
Exigences:
- 3+ années d' expérience dans le développement de python .
- Bonne connaissance de SQL
le vecteur est égal à [8, 0, 5].
Métrique
Pour travailler avec des données, vous devez les comprendre. Dans notre cas, je voudrais voir s'il existe des groupes de points, que nous considérerons comme des groupes. Pour ce faire, j'ai utilisé l'algorithme t-SNE pour traduire tous les vecteurs dans l'espace 2D.
L'essence de la méthode est de réduire la dimension des données, tout en préservant au maximum les proportions des distances entre les points de l'ensemble. Il est assez difficile de comprendre comment fonctionne t-SNE à partir des formules. Mais j'ai aimé un exemple trouvé quelque part sur Internet: disons que nous avons des balles dans un espace tridimensionnel. Nous connectons chaque balle avec toutes les autres balles par des ressorts invisibles, qui ne se croisent en aucune façon et n'interfèrent pas entre eux lors du croisement. Les ressorts agissent dans deux directions, c'est-à-dire ils résistent à la fois à la distance et à l'approche des balles les unes par rapport aux autres. Le système est dans un état stable, les balles sont stationnaires. Si nous prenons l'une des billes et la retirons, puis la relâchons, elle reviendra à son état d'origine en raison de la force des ressorts. Ensuite, nous prenons deux grandes assiettes et pressons les boules en une fine couche,tout en n'interférant pas avec les billes pour se déplacer dans le plan entre les deux plaques. Les forces des ressorts commencent à agir, les billes bougent et finissent par s'arrêter lorsque les forces de tous les ressorts s'équilibrent. Les ressorts agiront de sorte que les billes qui étaient proches les unes des autres restent relativement proches et plates. Aussi avec les balles retirées - elles seront retirées les unes des autres. À l'aide de ressorts et de plaques, nous avons converti l'espace tridimensionnel en deux dimensions, en préservant la distance entre les points sous une forme ou une autre!Aussi avec les balles retirées - elles seront retirées les unes des autres. À l'aide de ressorts et de plaques, nous avons converti l'espace tridimensionnel en deux dimensions, en préservant la distance entre les points sous une forme ou une autre!Aussi avec les balles retirées - elles seront retirées les unes des autres. À l'aide de ressorts et de plaques, nous avons converti l'espace tridimensionnel en deux dimensions, en préservant la distance entre les points sous une forme ou une autre!
L'algorithme t-SNE a été utilisé par moi uniquement pour visualiser un ensemble de points. Il a aidé à choisir une métrique et à sélectionner les pondérations des entités.
Si nous utilisons la métrique euclidienne que nous utilisons dans notre vie quotidienne, l'emplacement des postes vacants ressemblera à ceci:

La figure montre que la plupart des points sont concentrés au centre et qu'il y a de petites branches sur les côtés. Avec cette approche, les algorithmes de clustering qui utilisent la distance entre les points ne produiront rien de bon.
Il existe de nombreuses mesures (façons de déterminer la distance entre deux points) qui fonctionneront bien sur les données que vous explorez. J'ai choisi la distance de Jaccard comme mesure , en tenant compte des poids de n-grammes. La mesure de Jaccard est facile à comprendre, mais elle fonctionne bien pour résoudre le problème considéré.
:
1 n-: « python», «sql», «docker»
2 n-: « python», «sql», «php»
:
« python» — 8
«sql» — 5
«docker» — 7
«php» — 9
(n- 1- 2- ): « python», «sql» = 8 + 5 = 13
( n- 1- 2- ): « python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
=1 — ( / ) = 1 — (13 / 29) = 0.55
La matrice des distances entre toutes les paires de points a été calculée, la taille de la matrice est de 1595 x 1595. Au total, 1 271 215 distances entre des paires uniques. La distance moyenne s'est avérée être de 0,96, entre 619 659 la distance est de 1 (c'est-à-dire qu'il n'y a aucune similitude). Le graphique suivant montre que dans l'ensemble, il y a peu de similitude entre les emplois:
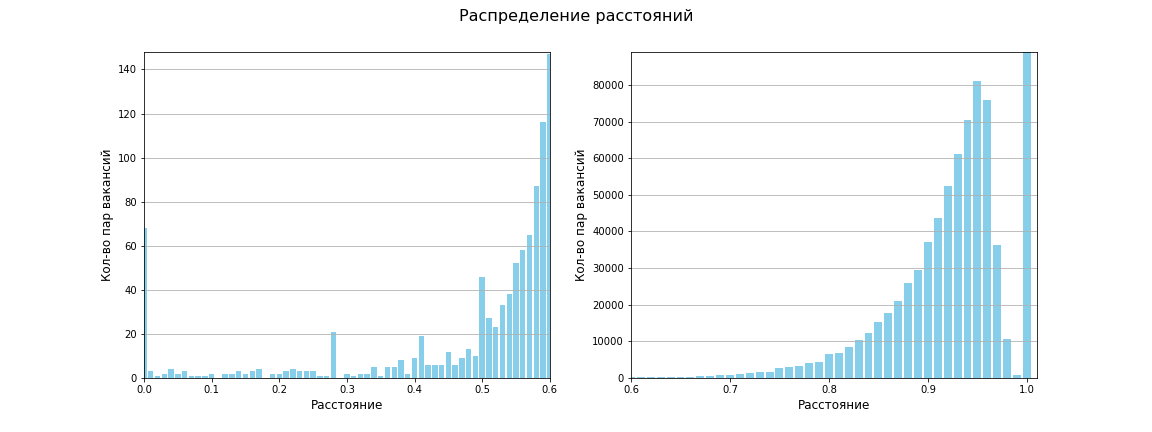
En utilisant la métrique Jaccard, notre espace ressemble maintenant à ceci:

Quatre zones de densité distinctes sont apparues et deux petits groupes de faible densité. Du moins, c'est ainsi que mes yeux voient!
Clustering
Le modèle de mélange gaussien (GMM) a été choisi comme algorithme de clustering . L'algorithme reçoit des données sous forme de vecteurs en entrée, et le paramètre n_components est le nombre de clusters dans lesquels l'ensemble doit être divisé. Vous pouvez voir comment fonctionne l'algorithme ici (en anglais). J'ai utilisé une implémentation GMM prête à l'emploi de la bibliothèque scikit-learn: sklearn.mixture.GaussianMixture .
Notez que GMM n'utilise pas de métrique, mais sépare les données uniquement par un ensemble d'entités et leurs pondérations. Dans l'article, la distance Jaccard est utilisée pour visualiser les données, calculer la compacité des clusters (j'ai pris la distance moyenne entre les points des clusters pour la compacité) et déterminerle point central du cluster (vacance typique) - le point avec la plus petite distance moyenne par rapport aux autres points du cluster. De nombreux algorithmes de clustering utilisent exactement la distance entre les points. La section Autres méthodes abordera d'autres types de clustering qui sont basés sur des métriques et donnent également de bons résultats.
Dans la section précédente, il a été déterminé à l'œil nu qu'il y aura probablement six grappes. Voici à quoi ressemblent les résultats du clustering avec n_components = 6:

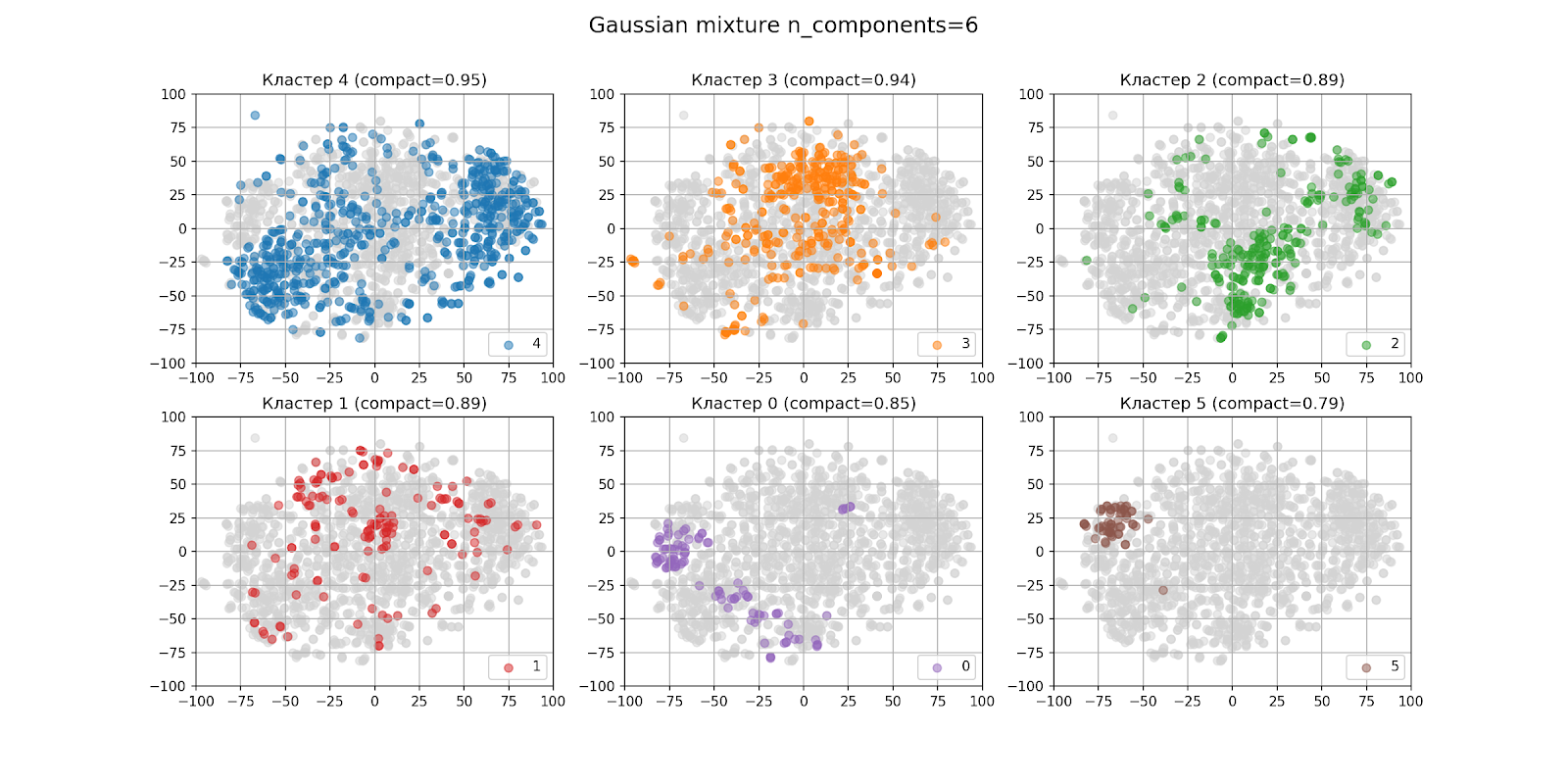
Dans la figure avec la sortie des clusters séparément, les clusters sont classés par ordre décroissant du nombre de points de gauche à droite, de haut en bas: le cluster 4 est le plus grand, le cluster 5 est le plus petit. La compacité de chaque cluster est indiquée entre parenthèses.
Le clustering ne semble pas très bon, même si vous considérez que l'algorithme t-SNE n'est pas parfait. Lors de l'analyse des clusters, le résultat n'était pas non plus encourageant.
Pour trouver le nombre optimal de clusters n_components, nous utiliserons les critères AIC et BIC, que vous pouvez lire ici . Le calcul de ces critères est intégré à la méthode sklearn.mixture.GaussianMixture . Voici à quoi ressemble le graphique des critères:

Lorsque n_composants = 12, le critère BIC a la valeur la plus basse (meilleure), le critère AIC a également une valeur proche du minimum (minimum lorsque n_composants = 23). Divisons les postes vacants en 12 groupes:


Les clusters sont désormais plus compacts, tant en apparence qu'en termes numériques. Au cours de l'analyse manuelle, les postes vacants ont été divisés en groupes caractéristiques pour comprendre une personne. La figure montre les noms des clusters. Les clusters numérotés 11 et 4 sont marqués comme <Corbeille 2>:
- Dans le cluster 11, toutes les entités ont approximativement les mêmes poids totaux.
- Le cluster 4 est dédié à Java. Néanmoins, il y a peu de postes vacants pour le poste de Développeur Java dans le cluster, la connaissance de Java est souvent requise car «sera un plus».
Clusters
Après avoir supprimé deux clusters non informatifs numérotés 11 et 4, le résultat est 10 clusters:
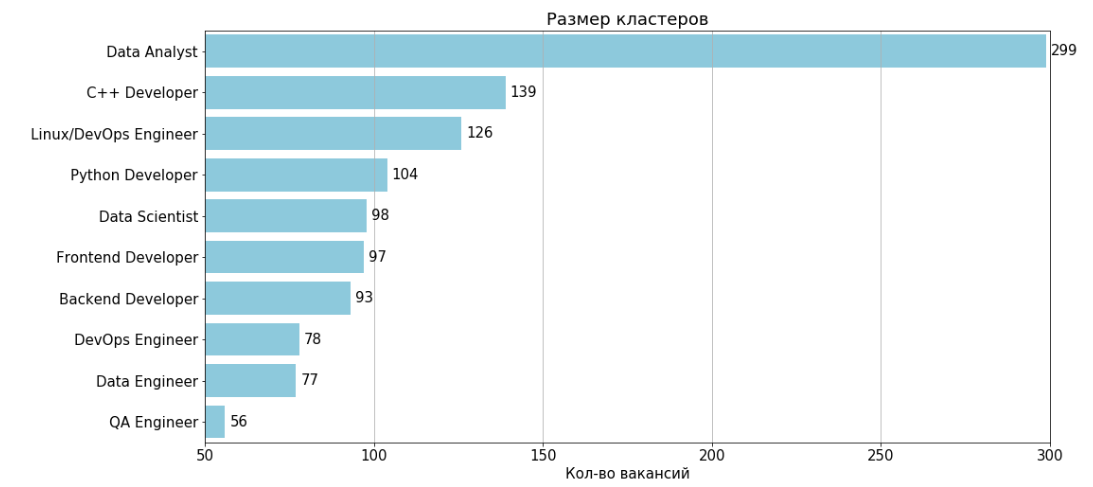
Pour chaque cluster, il existe un tableau des caractéristiques et 2 grammes que l'on retrouve le plus souvent dans les postes vacants du cluster.
Légende:
S - la proportion de postes vacants dans laquelle le trait est trouvé, multipliée par le poids du trait
% - le pourcentage de postes vacants dans lesquels le trait / 2 grammes se trouve
Poste vacant typique de la grappe - vacance, avec la plus petite distance moyenne par rapport aux autres points de la grappe
Analyste de données
Nombre d'emplois: 299 Emploi
typique: 35805914
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | exceller | 3.13 | sql | 64,55 | connaissance de SQL | 18,39 |
| 2 | r | 2,59 | exceller | 34,78 | en développement | 14.05 |
| 3 | sql | 2,44 | r | 28,76 | python r | 14.05 |
| 4 | connaissance de SQL | 1,47 | bi | 19,40 | avec grand | 13,38 |
| cinq | l'analyse des données | 1,17 | tableau | 15,38 | développement et | 13,38 |
| 6 | tableau | 1,08 | 14,38 | l'analyse des données | 13.04 | |
| sept | avec grand | 1,07 | vba | 13.04 | connaissance de python | 12,71 |
| huit | développement et | 1,07 | science | 9,70 | entrepôt analytique | 11,71 |
| neuf | vba | 1,04 | dwh | 6,35 | expérience de développement | 11,71 |
| Dix | connaissance de python | 1,02 | oracle | 6,35 | bases de données | 11,37 |
Développeur C ++
Nombre d'emplois: 139 Emploi
typique: 39955360
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | c ++ | 9h00 | c ++ | 100,00 | expérience de développement | 44,60 |
| 2 | Java | 3.30 | Linux | 44,60 | c c ++ | 27,34 |
| 3 | Linux | 2,55 | Java | 36,69 | c ++ python | 17,99 |
| 4 | c # | 1,88 | sql | 23.02 | en c ++ | 16,55 |
| cinq | aller | 1,75 | c # | 20,86 | développement sur | 15,83 |
| 6 | développement sur | 1,27 | aller | 19,42 | structures de données | 15.11 |
| sept | bonne connaissance | 1,15 | unix | 12,23 | expérience d'écriture | 14,39 |
| huit | structures de données | 1,06 | tensorflow | 11,51 | programmation sur | 13,67 |
| neuf | tensorflow | 1,04 | frapper | 10.07 | en développement | 13,67 |
| Dix | expérience de programmation | 0,98 | postgresql | 9,35 | langages de programmation | 12,95 |
Ingénieur Linux / DevOps
Nombre d'emplois: 126 Emploi type
: 39533926
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | ansible | 5,33 | Linux | 84,92 | ci cd | 58,73 |
| 2 | docker | 4,78 | ansible | 76,19 | expérience en administration | 42,06 |
| 3 | frapper | 4,78 | docker | 74,60 | bash python | 33,33 |
| 4 | ci cd | 4.70 | frapper | 68,25 | ip tcp | 39,37 |
| cinq | Linux | 4,43 | Prométhée | 58,73 | expérience de personnalisation | 28,57 |
| 6 | Prométhée | 4.11 | zabbix | 54,76 | surveillance et | 26,98 |
| sept | nginx | 3,67 | nginx | 52,38 | prométhée grafana | 23,81 |
| huit | expérience en administration | 3,37 | Grafana | 52,38 | systèmes de surveillance | 22,22 |
| neuf | zabbix | 3,29 | postgresql | 51,59 | avec docker | 16,67 |
| Dix | wapiti | 3,22 | kubernetes | 51,59 | gestion de la configuration | 16,67 |
Développeur Python
Nombre d'offres d'emploi: 104 Emploi type
: 39705484
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | en python | 6,00 | docker | 65,38 | en python | 75,00 |
| 2 | Django | 5,62 | Django | 62,50 | développement sur | 51,92 |
| 3 | ballon | 4,59 | postgresql | 58,65 | expérience de développement | 43,27 |
| 4 | docker | 4,24 | ballon | 50,96 | flacon de Django | 04.24 |
| cinq | développement sur | 4.15 | redis | 38,46 | reste api | 23.08 |
| 6 | postgresql | 2,93 | Linux | 35,58 | python de | 21,15 |
| sept | aiohttp | 1,99 | lapinmq | 33,65 | bases de données | 18,27 |
| huit | redis | 1,92 | sql | 30,77 | expérience d'écriture | 18,27 |
| neuf | Linux | 1,73 | mongodb | 25,00 | avec docker | 17,31 |
| Dix | lapinmq | 1,68 | aiohttp | 22.12 | avec postgresql | 16,35 |
Data scientist
Nombre de postes vacants: 98 Poste
vacant type: 38071218
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | pandas | 7,35 | pandas | 81,63 | apprentissage automatique | 63,27 |
| 2 | engourdi | 6,04 | engourdi | 75,51 | pandas numpy | 43,88 |
| 3 | apprentissage automatique | 5,69 | sql | 62,24 | l'analyse des données | 29,59 |
| 4 | pytorche | 3,77 | pytorche | 41,84 | science des données | 26,53 |
| cinq | ml | 3,49 | ml | 38,78 | connaissance de python | 25,51 |
| 6 | tensorflow | 3,31 | tensorflow | 36,73 | scipy engourdi | 24,49 |
| sept | l'analyse des données | 2,66 | étincelle | 32,65 | pandas python | 23,47 |
| huit | scikitlearn | 2,57 | scikitlearn | 28,57 | en python | 21,43 |
| neuf | science des données | 2,39 | docker | 27,55 | statistiques mathématiques | 20,41 |
| Dix | étincelle | 2,29 | hadoop | 27,55 | algorithmes de machine | 20,41 |
Développeur frontal
Nombre d'emplois: 97 Emploi
typique: 39681044
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | javascript | 9h00 | javascript | 100 | html css | 27,84 |
| 2 | Django | 2,60 | html | 42,27 | expérience de développement | 25,77 |
| 3 | réagir | 2,32 | postgresql | 38,14 | en développement | 17,53 |
| 4 | nodejs | 2.13 | docker | 37,11 | connaissance de javascript | 15,46 |
| cinq | l'extrémité avant | 2.13 | css | 37,11 | et support | 15,46 |
| 6 | docker | 2,09 | Linux | 32,99 | python et | 14,43 |
| sept | postgresql | 1,91 | sql | 31,96 | css javascript | 13,40 |
| huit | Linux | 1,79 | Django | 28,87 | bases de données | 12,37 |
| neuf | html css | 1,67 | réagir | 25,77 | en python | 12,37 |
| Dix | php | 1,58 | nodejs | 23,71 | conception et | 11,34 |
Développeur backend
Nombre d'emplois: 93 Emploi type
: 40226808
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | Django | 5,90 | Django | 65,59 | python django | 26,88 |
| 2 | js | 4,74 | js | 52,69 | expérience de développement | 25,81 |
| 3 | réagir | 2,52 | postgresql | 40,86 | connaissance de python | 20,43 |
| 4 | docker | 2,26 | docker | 35,48 | en développement | 18,28 |
| cinq | postgresql | 2,04 | réagir | 27,96 | ci cd | 17,20 |
| 6 | compréhension des principes | 1,89 | Linux | 27,96 | connaissance confiante | 16,13 |
| sept | connaissance de python | 1,63 | backend | 22,58 | reste api | 15.05 |
| huit | backend | 1,58 | redis | 22,58 | html css | 13,98 |
| neuf | ci cd | 1,38 | sql | 20,43 | capacité à comprendre | 10,75 |
| Dix | l'extrémité avant | 1,35 | mysql | 19,35 | chez un inconnu | 10,75 |
Ingénieur DevOps
Nombre d'emplois: 78 Emploi type
: 39634258
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | devops | 8,54 | devops | 94,87 | ci cd | 51,28 |
| 2 | ansible | 5,38 | ansible | 76,92 | bash python | 30,77 |
| 3 | frapper | 4,76 | Linux | 74,36 | expérience en administration | 24,36 |
| 4 | Jenkins | 4,49 | frapper | 67,95 | et support | 23.08 |
| cinq | ci cd | 4.10 | Jenkins | 64,10 | docker kubernetes | 20,51 |
| 6 | Linux | 3,54 | docker | 50,00 | développement et | 17,95 |
| sept | docker | 2,60 | kubernetes | 41.03 | expérience d'écriture | 17,95 |
| huit | Java | 2,08 | sql | 29,49 | et personnalisation | 17,95 |
| neuf | expérience en administration | 1,95 | oracle | 25,64 | développement et | 16,67 |
| Dix | et support | 1,85 | OpenShift | 24,36 | script | 14.10 |
Ingénieur de données
Nombre d'emplois: 77 Emploi
typique: 40 008 757
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | étincelle | 6,00 | hadoop | 89,61 | traitement de l'information | 38,96 |
| 2 | hadoop | 5,38 | étincelle | 85,71 | Big Data | 37,66 |
| 3 | Java | 4,68 | sql | 68,83 | expérience de développement | 23,38 |
| 4 | ruche | 4,27 | ruche | 61,04 | connaissance de SQL | 22.08 |
| cinq | scala | 3,64 | Java | 51,95 | développement et | 19,48 |
| 6 | Big Data | 3,39 | scala | 51,95 | étincelle hadoop | 19,48 |
| sept | etl | 3,36 | etl | 48,05 | java scala | 19,48 |
| huit | sql | 2,79 | flux d'air | 44,16 | qualité des données | 18,18 |
| neuf | traitement de l'information | 2,73 | kafka | 42,86 | et traitement | 18,18 |
| Dix | kafka | 2,57 | oracle | 35,06 | ruche hadoop | 18,18 |
Ingénieur QA
Nombre d'emplois: 56 Emploi
typique: 39630489
| Non. | Signer avec poids | S | Signe | % | 2 grammes | % |
| 1 | automatisation des tests | 5,46 | sql | 46,43 | automatisation des tests | 60,71 |
| 2 | expérience de test | 4,29 | qa | 42,86 | expérience de test | 53,57 |
| 3 | qa | 3,86 | Linux | 35,71 | en python | 41,07 |
| 4 | en python | 3,29 | sélénium | 32,14 | expérience d'automatisation | 35,71 |
| cinq | développement et | 2,57 | la toile | 32,14 | développement et | 32,14 |
| 6 | sql | 2,05 | docker | 30,36 | expérience de test | 30,36 |
| sept | Linux | 2,04 | Jenkins | 26,79 | expérience d'écriture | 28,57 |
| huit | sélénium | 1,93 | backend | 26,79 | test sur | 23,21 |
| neuf | la toile | 1,93 | frapper | 21,43 | tests automatisés | 21,43 |
| Dix | backend | 1,88 | ui | 19,64 | ci cd | 21,43 |
Les salaires
Les salaires ne sont indiqués que dans 261 (22%) postes vacants sur 1 167 dans les grappes.
Lors du calcul des salaires:
- Si la plage "de ... à ..." a été spécifiée, la valeur moyenne a été utilisée
- Si seulement "de ..." ou seulement "à ..." était indiqué, alors cette valeur était prise
- Les calculs ont utilisé (ou ont été donnés) le salaire après impôts (NET)
Sur le graphique:
- Les grappes sont classées par ordre décroissant du salaire médian
- Barre verticale dans la boîte - médiane
- Boîte - plage [Q1, Q3], où Q1 (25%) et Q3 (75%) sont des centiles. Ceux. 50% des salaires tombent dans la boîte
- La «moustache» comprend les salaires de la fourchette [Q1 - 1,5 * IQR, Q3 + 1,5 * IQR], où IQR = Q3 - Q1 - intervalle interquartile
- Les points individuels sont des anomalies qui ne sont pas tombées dans la moustache. (Il y a des anomalies non incluses dans le diagramme)

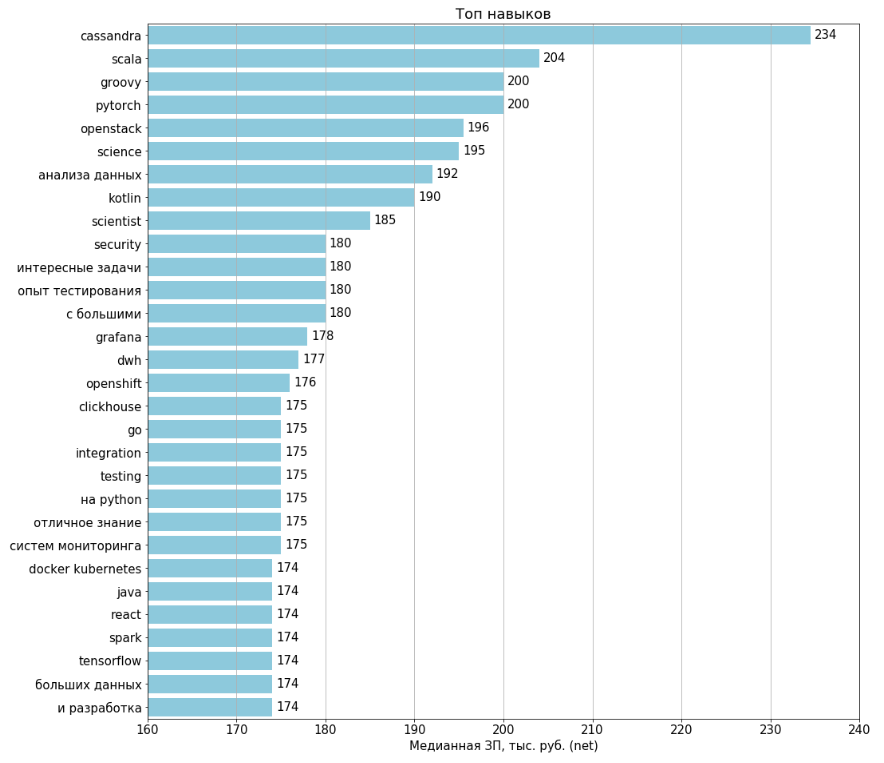
Compétences Top / Antitop
Les graphiques ont été créés pour tous les postes vacants téléchargés en 1994. Les salaires sont indiqués dans 443 (22%) postes vacants. Pour le calcul de chaque fonctionnalité, les postes vacants ont été sélectionnés lorsque cette fonctionnalité est présente, et sur leur base, le salaire médian a été calculé.

Classification des emplois
Le regroupement pourrait être beaucoup plus facile sans recourir à des modèles mathématiques complexes: pour compiler les principaux noms des postes vacants et les diviser en groupes. Ensuite, analysez chaque groupe pour les n-grammes les plus élevés et les salaires moyens. Il n'est pas nécessaire de mettre en évidence les caractéristiques et de leur attribuer des pondérations.
Cette approche fonctionnerait bien (dans une certaine mesure) pour une requête "Python". Mais pour la demande "1C Programmer" cette approche ne fonctionnera pas, car pour les programmeurs 1C dans les noms des postes vacants, les configurations 1C ou les domaines d'application sont rarement indiqués. Et il existe de nombreux domaines où 1C est utilisé: comptabilité, calcul des salaires, calcul des taxes, calcul des coûts dans les entreprises industrielles, comptabilité d'entrepôt, budgétisation, systèmes ERP, commerce de détail, comptabilité de gestion, etc.
Pour moi, je vois deux tâches pour analyser les postes vacants:
- Comprenez où un langage de programmation que je connais peu est utilisé (comme dans cet article).
- Filtrer les nouvelles offres d'emploi publiées.
Le clustering convient pour résoudre le premier problème, pour résoudre le second - divers classificateurs, forêts aléatoires, arbres de décision, réseaux de neurones. Néanmoins, je voulais évaluer la pertinence du modèle choisi pour le problème de classification des emplois.
Si vous utilisez la méthode prédire () intégrée à sklearn.mixture.GaussianMixture , rien de bon ne se passe. Il attribue la plupart des postes vacants à de grandes grappes, et deux des trois premières grappes ne sont pas informatives. J'ai utilisé une approche différente:
- Nous prenons le poste vacant que nous voulons classer. Nous le vectorisons et obtenons un point dans notre espace.
- Nous calculons la distance entre ce point et tous les clusters. Sous la distance entre un point et un cluster, j'ai pris la distance moyenne entre ce point et tous les points du cluster.
- La grappe avec la plus petite distance est la classe prévue pour le poste vacant sélectionné. La distance au cluster indique la fiabilité d'une telle prédiction.
- Pour augmenter la précision du modèle, j'ai choisi 0,87 comme distance seuil, c'est-à-dire si la distance à la grappe la plus proche est supérieure à 0,87, le modèle ne classe pas le poste vacant.
Pour évaluer le modèle, 30 postes vacants ont été sélectionnés au hasard dans l'ensemble de test. Dans la colonne verdict:
N / a: le modèle n'a pas classé le poste (distance> 0,87)
+: classification correcte
-: classification incorrecte
| Poste vacant | Cluster le plus proche | Distance | Verdict |
| 37637989 | Ingénieur Linux / DevOps | 0,9464 | N / a |
| 37833719 | Développeur C ++ | 0,8772 | N / a |
| 38324558 | Ingénieur de données | 0.8056 | + |
| 38517047 | Développeur C ++ | 0,8652 | + |
| 39053305 | Poubelle | 0,9914 | N / a |
| 39210270 | Ingénieur de données | 0,8530 | + |
| 39349530 | Développeur frontal | 0,8593 | + |
| 39402677 | Ingénieur de données | 0,8396 | + |
| 39415267 | Développeur C ++ | 0,8701 | N / a |
| 39734664 | Ingénieur de données | 0,8492 | + |
| 39770444 | Développeur backend | 0,8960 | N / a |
| 39770752 | Data scientist | 0,7826 | + |
| 39795880 | Analyste de données | 0,9202 | N / a |
| 39947735 | Développeur Python | 0,8657 | + |
| 39954279 | Ingénieur Linux / DevOps | 0,8398 | - |
| 40008770 | Ingénieur DevOps | 0,8634 | - |
| 40015219 | Développeur C ++ | 0,8405 | + |
| 40031023 | Développeur Python | 0,7794 | + |
| 40072052 | Analyste de données | 0,9302 | N / a |
| 40112637 | Ingénieur Linux / DevOps | 0,8285 | + |
| 40164815 | Ingénieur de données | 0.8019 | + |
| 40186145 | Développeur Python | 0,7865 | + |
| 40201231 | Data scientist | 0,7589 | + |
| 40211477 | Ingénieur DevOps | 0,8680 | + |
| 40224552 | Data scientist | 0,9473 | N / a |
| 40230011 | Ingénieur Linux / DevOps | 0,9298 | N / a |
| 40241704 | Corbeille 2 | 0,9093 | N / a |
| 40245997 | Analyste de données | 0,9800 | N / a |
| 40246898 | Data scientist | 0,9584 | N / a |
| 40267920 | Développeur frontal | 0,8664 | + |
Total: 12 postes vacants sont sans résultat, 2 postes vacants - classement erroné, 16 postes vacants - classement correct. Exhaustivité du modèle - 60%, précision du modèle - 89%.
Côtés faibles
Le premier problème - prenons deux postes vacants:
Poste vacant 1 - "Lead C ++ Programmer"
"Conditions requises:
- Plus de 5 ans d'expérience en développement C ++.
- La connaissance de Python sera un atout supplémentaire. "
Poste vacant 2 - "Lead Python Programmer"Du point de vue du modèle, ces vacances sont identiques. J'ai essayé d'ajuster les poids des entités selon leur ordre d'apparition dans le texte. Cela n'a abouti à rien de bon.
"Conditions requises:
- Plus de 5 ans d'expérience en développement Python.
- La connaissance de C ++ sera un atout supplémentaire "
Le deuxième problème est que GMM regroupe tous les points dans un ensemble, comme de nombreux algorithmes de clustering. Les clusters non informatifs ne sont pas un problème en eux-mêmes. Mais les clusters informatifs contiennent également des valeurs aberrantes. Cependant, cela peut être facilement résolu en effaçant les clusters, par exemple en supprimant les points les plus atypiques qui ont la plus grande distance moyenne au reste des points de cluster.
Autres méthodes
La page de comparaison de cluster illustre bien les divers algorithmes de clustering. GMM est le seul à avoir donné de bons résultats.
Le reste des algorithmes n'a pas fonctionné ou a donné des résultats très modestes.
Parmi ceux que j'ai mis en œuvre, de bons résultats étaient dans deux cas:
- Des points à forte densité ont été sélectionnés dans un certain voisinage, situés à une distance éloignée les uns des autres. Les points sont devenus les centres des grappes. Puis, sur la base des centres, le processus de formation de grappes a commencé - la jonction des points voisins.
- Le clustering agglomératif est une fusion itérative de points et de clusters. La bibliothèque scikit-learn présente ce type de clustering, mais cela ne fonctionne pas bien. Dans mon implémentation, j'ai changé la matrice de jointure après chaque itération de la fusion. Le processus s'est arrêté lorsque certains paramètres limites ont été atteints - en fait, les dendrogrammes n'aident pas à comprendre le processus de fusion si 1500 éléments sont regroupés.
Conclusion
La recherche que j'ai faite m'a donné les réponses à toutes les questions au début de l'article. J'ai acquis une expérience pratique du clustering tout en implémentant des variantes d'algorithmes connus. J'espère vraiment que l'article motivera le lecteur à mener ses recherches analytiques et aidera d'une certaine manière dans cette leçon passionnante.