
Il existe déjà pas mal de publications sur le coprocesseur Apple Matrix (AMX). Mais la plupart ne sont pas très clairs pour tout le monde. Je vais essayer d'expliquer les nuances du coprocesseur dans un langage compréhensible.
Pourquoi Apple ne parle-t-il pas trop de ce coprocesseur? Qu'y a-t-il de si secret? Et si vous avez lu sur le Neural Engine dans SoC M1, vous aurez peut-être du mal à comprendre ce qui est si inhabituel à propos d'AMX.
Mais d'abord, rappelons-nous les choses de base ( si vous savez bien ce que sont les matrices, et je suis sûr qu'il y a la plupart de ces lecteurs sur Habré, alors vous pouvez sauter la première section, - environ Transl. ).
Qu'est-ce qu'une matrice?
Pour faire simple, c'est un tableau avec des nombres. Si vous avez travaillé dans Microsoft Excel, cela signifie que vous avez traité de la similitude des matrices. La principale différence entre les matrices et les tables ordinaires avec des nombres réside dans les opérations qui peuvent être effectuées avec elles, ainsi que dans leur essence spécifique. La matrice peut être considérée sous de nombreuses formes différentes. Par exemple, sous forme de chaînes, il s'agit d'un vecteur de ligne. Ou comme colonne, alors c'est, tout à fait logiquement, un vecteur colonne.

Nous pouvons ajouter, soustraire, mettre à l'échelle et multiplier des matrices. L'addition est l'opération la plus simple. Vous ajoutez simplement chaque élément séparément. La multiplication est un peu plus délicate. Voici un exemple simple.
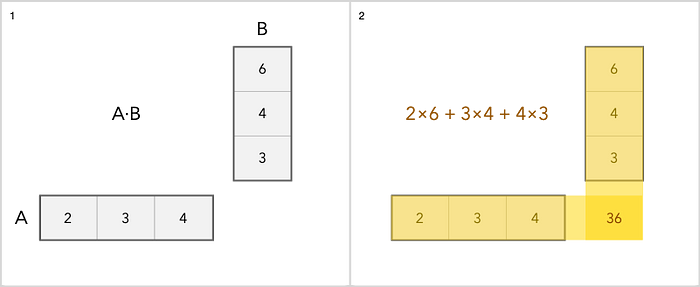
Comme pour les autres opérations avec des matrices, vous pouvez en savoir plus ici .
Pourquoi parle-t-on même de matrices?
Le fait est qu'ils sont largement utilisés dans:
• Le traitement d'images.
• Apprentissage automatique.
• Écriture manuscrite et reconnaissance vocale.
• Compression.
• Travaillez avec l'audio et la vidéo.
En matière d'apprentissage automatique, cette technologie nécessite des processeurs puissants. Et simplement ajouter quelques cœurs à la puce n'est pas une option. Désormais, les noyaux sont "affinés" pour certaines tâches.

Le nombre de transistors dans le processeur est limité, de sorte que le nombre de tâches / modules qui peuvent être ajoutés à la puce est également limité. En général, vous pouvez simplement ajouter plus de cœurs au processeur, mais cela ne fera qu'accélérer les calculs standard qui sont déjà rapides. Apple a donc décidé d'emprunter une voie différente et de mettre en évidence les modules pour le traitement d'image, le décodage vidéo et les tâches d'apprentissage automatique. Ces modules sont des coprocesseurs et des accélérateurs.
Quelle est la différence entre le coprocesseur Apple Matrix et le Neural Engine?
Si vous étiez intéressé par le Neural Engine, vous savez probablement qu'il effectue également des opérations matricielles pour travailler avec des problèmes d'apprentissage automatique. Mais si oui, pourquoi avez-vous également besoin du coprocesseur Matrix? C'est peut-être la même chose? Suis-je déroutant quelque chose? Permettez-moi de clarifier la situation et de vous dire quelle est la différence, en expliquant pourquoi les deux technologies sont nécessaires.
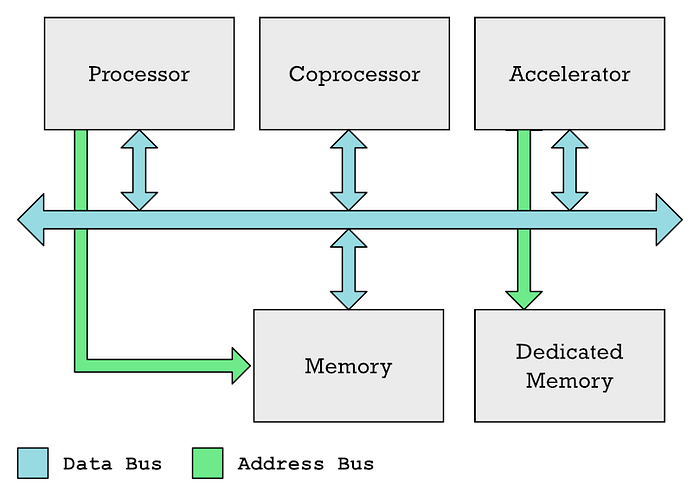
L'unité de traitement principale (CPU), les coprocesseurs et les accélérateurs peuvent généralement communiquer sur un bus de données commun. Le processeur contrôle généralement l'accès à la mémoire, tandis qu'un accélérateur tel qu'un GPU a souvent sa propre mémoire dédiée.
J'avoue que dans mes articles précédents, j'ai utilisé les termes «coprocesseur» et «accélérateurs» de manière interchangeable, bien qu'ils ne soient pas la même chose. Ainsi, GPU et Neural Engine sont différents types d'accélérateurs.
Dans les deux cas, vous disposez de zones spéciales de mémoire que la CPU doit remplir avec les données qu'elle souhaite traiter, plus une autre zone de mémoire que la CPU remplit avec une liste d'instructions que l'accélérateur doit exécuter. Le processeur prend du temps pour effectuer ces tâches. Vous devez coordonner tout cela, remplir les données, puis attendre que les résultats soient reçus.
Et un tel mécanisme convient aux tâches à grande échelle, mais pour les petites tâches, c'est exagéré.

C'est l'avantage des coprocesseurs par rapport aux accélérateurs. Les coprocesseurs s'assoient et surveillent le flux des instructions de code machine qui viennent de la mémoire (ou en particulier du cache) vers le processeur. Le coprocesseur est obligé de répondre aux instructions spécifiques qu'il a été forcé de traiter. Pendant ce temps, le CPU ignore généralement ces instructions ou aide à les rendre plus faciles à gérer par le coprocesseur.
L'avantage est que les instructions exécutées par le coprocesseur peuvent être incluses dans du code normal. Dans le cas du GPU, tout est différent - les programmes de shader sont placés dans des tampons de mémoire séparés, qui doivent ensuite être transférés explicitement vers le GPU. Vous ne pourrez pas utiliser le code normal pour cela. Et c'est pourquoi AMX est idéal pour les tâches simples de traitement matriciel.
L'astuce ici est que vous devez définir des instructions dans l'architecture du jeu d'instructions (ISA) de votre microprocesseur. Ainsi, lors de l'utilisation d'un coprocesseur, l'intégration avec le processeur est plus étroite que lors de l'utilisation d'un accélérateur.
Soit dit en passant, les créateurs d'ARM ont longtemps résisté à l'ajout d'instructions personnalisées à ISA. Et c'est l'un des avantages du RISC-V. Mais en 2019, les développeurs ont abandonné, cependant, déclarant ce qui suit: «Les nouvelles instructions sont combinées avec les instructions ARM standard. Pour éviter la fragmentation des logiciels et maintenir un environnement de développement logiciel cohérent, ARM s'attend à ce que les clients utilisent des instructions personnalisées principalement dans les appels de bibliothèque. "
Cela pourrait être une bonne explication du manque de description des instructions AMX dans la documentation officielle. ARM s'attend simplement à ce qu'Apple inclue des instructions dans les bibliothèques fournies par le client (dans ce cas, Apple).
Quelle est la différence entre un coprocesseur matriciel et un SIMD vectoriel?
En général, il n'est pas si difficile de confondre un coprocesseur matriciel avec la technologie vectorielle SIMD, que l'on trouve dans la plupart des processeurs modernes, y compris ARM. SIMD signifie Single Instruction Multiple Data.

SIMD vous permet d'augmenter les performances du système lorsque vous devez effectuer la même opération sur plusieurs éléments, ce qui est étroitement lié aux matrices. En général, les instructions SIMD, y compris les instructions ARM Neon ou Intel x86 SSE ou AVX, sont souvent utilisées pour accélérer la multiplication de la matrice.
Mais le moteur vectoriel SIMD fait partie du cœur du microprocesseur, tout comme ALU (Arithmetic Logic Unit) et FPU (Floating Point Unit) font partie du CPU. Eh bien, déjà le décodeur d'instructions dans le microprocesseur "décide" quel bloc fonctionnel activer.

Mais le coprocesseur est un module physique distinct et ne fait pas partie du cœur du microprocesseur. Auparavant, par exemple, le 8087 d'Intel était une puce distincte destinée à accélérer les opérations en virgule flottante.

Vous pourriez trouver étrange que quelqu'un développe un système aussi complexe, avec une puce distincte qui traite les données allant de la mémoire au processeur afin de détecter une instruction en virgule flottante.
Mais le coffre s'ouvre simplement. Le fait est que le processeur 8086 d'origine ne comptait que 29 000 transistors. Les 8087 en comptaient déjà 45 000. Au final, les technologies ont permis d'intégrer des FPU dans la puce principale, de se débarrasser des coprocesseurs.
Mais pourquoi AMX ne fait pas partie du noyau M1 Firestorm n'est pas tout à fait clair. Peut-être qu'Apple a simplement décidé de déplacer des éléments ARM non standard en dehors du processeur principal.
Mais pourquoi on ne parle pas beaucoup d'AMX?
Si AMX n'est pas décrit dans la documentation officielle, comment pourrions-nous même le savoir? Merci au développeur Dougall Johnson, qui a fait une merveilleuse rétro-ingénierie du M1 et découvert le coprocesseur. Son travail est décrit ici . En fait, Apple a créé des bibliothèques et / ou des frameworks spécialisés comme Accelerate pour les opérations mathématiques liées aux matrices . Tout cela comprend les éléments suivants:
• vImage - traitement d'image de niveau supérieur, tel que la conversion entre les formats, la manipulation d'images.
• BLASEst une sorte de standard de l'industrie pour l'algèbre linéaire (ce que nous appelons les mathématiques traitant des matrices et des vecteurs).
• BNNS - utilisé pour faire fonctionner des réseaux neuronaux et s'entraîner.
• vDSP - traitement numérique du signal. Transformée de Fourier, convolution. Ce sont des opérations mathématiques effectuées lors du traitement d'une image ou de tout signal contenant du son.
• LAPACK - Fonctions d'algèbre linéaire de niveau supérieur , telles que la résolution d'équations linéaires.
Johnson a compris que ces bibliothèques utiliseraient le coprocesseur AMX pour accélérer les calculs. Par conséquent, il a développé un logiciel spécialisé pour l'analyse et le suivi des actions de la bibliothèque. En fin de compte, il a pu localiser des instructions de code machine AMX non documentées.
Et Apple ne documente pas tout cela car ARM LTD. essaie de ne pas publier trop d'informations. Le fait est que si les fonctions personnalisées sont vraiment largement utilisées, cela peut conduire à la fragmentation de l'écosystème ARM, comme indiqué ci-dessus.
Apple a la possibilité, sans vraiment annoncer tout cela, de modifier ultérieurement le fonctionnement des systèmes si nécessaire - par exemple, supprimer ou ajouter des instructions AMX. Pour les développeurs, la plateforme Accelerate suffit, le système fera le reste lui-même. En conséquence, Apple peut contrôler à la fois le matériel et les logiciels.
Avantages du coprocesseur Apple Matrix
Il y a beaucoup de choses ici, un excellent aperçu des capacités de l'élément a été fait par Nod Labs, spécialisé dans l'apprentissage automatique, l'intelligence et la perception. En particulier, ils ont réalisé des tests de performances comparatifs entre AMX2 et NEON.
En fait, AMX effectue les opérations nécessaires pour effectuer des opérations avec des matrices deux fois plus rapidement. Cela ne signifie pas, bien sûr, que AMX est le meilleur, mais pour l'apprentissage automatique et le calcul haute performance - oui.
L'essentiel est que le coprocesseur d'Apple est une technologie impressionnante qui donne à Apple ARM un avantage en matière d'apprentissage automatique et de calcul haute performance.
