
En fait, c'est l'histoire de la recherche d'un défaut dans la mise en page d'un site bancaire, qui a conduit à un affichage inexact de sa page principale sur la recherche. Un problème similaire se rencontre souvent sur un site assemblé, par exemple, dans un constructeur en ligne, ou conçu, par exemple, par un concepteur de mise en page qui ne connaît pas les bases de l'optimisation des moteurs de recherche.
Et cette histoire ne serait restée intéressante que pour un cercle restreint de seoshniks pratiquants, si elle n'avait pas touché à une caractéristique non documentée de l'indexation, que d'autres spécialistes de la maintenance de sites Web auraient probablement voulu connaître. Je les invite au chat.
Brève introduction
Tout SEO-master expérimenté connaît les règles d'analyse sémantique d'une page de site par des robots-indexeurs de recherche. Ces règles sont soumises à certaines dispositions de certaines normes techniques Internet. Par exemple:
- la balise <title> est un nom unique pour tout le document et n'est utilisée que dans sa section d'en-tête, et une seule fois;
- la balise <h1> titre une section spécifique du document et peut être réutilisée, mais seulement dans une autre section et tout en conservant l'unicité parmi toutes les balises <h1> du même document;
- la balise <h2> est un sous-titre de section qui peut être réutilisé même dans la même section, tout en conservant l'unicité parmi les sous-titres homologues de sa section;
- la balise <h3> est le sous-titre du sous-titre parent;
- … etc.
Bien sûr, il existe différentes nuances dans ces règles d'analyse des pages avant de les indexer, qui sont interprétées par chaque serveur de recherche à sa manière:
- , «», — , <p> ;
- (outlines), «» — , <h2> <p> () ;
- … .
Pour l'instant, ces règles d'analyse sémantique et de nuances ne sont pas importantes pour nous. Et si vous êtes tellement intéressé par les dispositions mêmes des normes techniques sur lesquelles repose l'indexation du contenu, l'essentiel de ces dispositions est clairement indiqué dans la publication de synthèse [1] sur l'admissibilité de plusieurs balises <h1> sur une page du site.
Je noterai simplement que les maîtres SEO sont habitués à de telles nuances, ce n'est pas la première fois qu'ils vérifient leur validité sur leur propre expérience, et promeuvent depuis longtemps des sites en recherche en tenant compte de cette vision de la priorité des tags. En effet, la compréhension des principes de l'indexation permet de «gérer» partiellement le texte que l'extrait de recherche d'un site affichera en réponse à une demande d'un utilisateur.
Mais il y a quelques jours, des informations d'initiés sont apparues que dans les résultats de la recherche organique concernant le site officiel de la Monobanque ukrainienne, un comportement d'un extrait incompréhensible a été révélé: le moteur de recherche ne le nomme pas par la balise <title> ou <h1>. Autrement dit, un rédacteur pourrait écrire le titre et le texte les plus uniques, un gestionnaire de contenu pourrait insérer du texte dans le site, mais la recherche serait toujours erronée.
Il était nécessaire de comprendre la raison, dont je parlerai plus loin.
La première étape de la recherche
Donc, pour commencer, j'ai effacé le cache et l'historique du navigateur, l'ai redémarré, ouvert la barre de recherche Google et entré le nom de la banque. Afin que même une personne SEO inexpérimentée puisse comprendre chacune de mes étapes, j'ai pris une photo de la première étape.
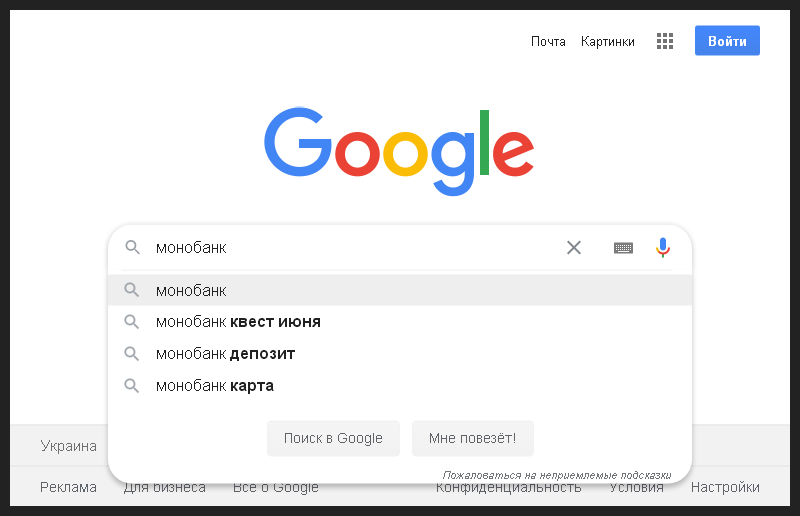
Il s'agit d'une demande d'informations de marque, ce qui signifie qu'en premier lieu des résultats organiques, il est logique de s'attendre à ce qu'un extrait de code apparaisse sur la page d'accueil de la banque.
Tout s'est passé comme prévu, l'extrait était le premier de la recherche et contenait également un bloc de liens rapides vers les principales sections du site. J'ai capturé ce moment sur la photo suivante.
Jusqu'à présent, tout a semblé normal.

Afin de m'assurer qu'une situation obscure ne se produise que dans les résultats de Google, j'ai répété la même requête dans la recherche Yandex et j'ai agréablement noté que ce géant de la recherche adhérait aux règles habituelles: l'extrait était intitulé monobank - une banque mobile - exactement comme écrit dans la balise <title> de la pages.

La réponse dans l'instantané de recherche Google était fondamentalement différente, du moins dans la partie titre. Et en plus, j'étais quelque peu confus par les textes ridicules sous les en-têtes de l'extrait de code Google.
J'ai supposé que cela n'était qu'une conséquence du fait qu'après la promotion par SMM de la marque et de son application mobile, mise en œuvre par Promodo en 2017-2018 [2] pour l'ancien domaine monobank.com.ua , pour embaucher plus de maîtres SEO pour desservir le nouveau domaine monobanque .ua n'avait plus de sens. Après tout, la campagne publicitaire a porté les résultats escomptés. Et la direction de la banque a probablement marqué un objectif dans la promotion des moteurs de recherche du nouveau domaine, ou confié la responsabilité à des informaticiens à temps plein.
Par conséquent, j'ai attribué la maladresse des textes actuels à la réticence compréhensible des membres du personnel à vérifier le résultat de la requête, qu'un utilisateur de banque typique ne tapera jamais.
Après tout, la clientèle de la banque visite le site principalement via une application mobile, ne respectant pratiquement pas l'apparence des pages de la banque dans la recherche. Et la partie des clients qui passent par la recherche Internet utilise principalement des requêtes du formulaire:
- taux du dollar monobanque;
- Taux de change de la monobanque;
- ouvrir un compte monobanque;
- faire une carte monobanque;
- créer une carte monobanque;
- carte de crédit monobanque;
- obtenir un prêt monobanque;
- prendre un prêt monobanque;
- … etc.
Toute banque connaît une liste complète de ces expressions de recherche qui correspondent aux modèles «que trouver + où» ou «où + quoi» et qui génèrent le trafic entrant le plus élevé de la recherche organique.
Vérification des requêtes "savoureuses"
Quelle surprise j'ai été lorsque, pour la plupart de ces requêtes, le même extrait de code est apparu dans les résultats de recherche avec le même titre et souvent un texte stupide qui ne correspondait guère à la requête saisie.
J'ai photographié un exemple d'une telle demande sur la photo suivante et indiqué le problème.

De plus, l'adresse cible (URL) de l'extrait de code pour presque toutes les demandes a conduit au haut de la page principale, sans même ancrer sa section dans l'adresse pertinente à la demande actuelle.
Eh bien, disons, si la demande concernait le taux de change et que la section correspondante serait présente sur la page de destination cible, il serait logique d'ancrer le lien vers la section avec un hachage comme monobank.ua/#kurs-valut avec la canonisation de la même URL ancrée pour que le robot de recherche puisse comprendre que la page de destination a plusieurs points de destination pour les phrases de recherche correspondantes, qui seraient énoncées par le référencement normal dans le texte d'ancrage des liens placés par eux quelque part sur le site ou en dehors du site, par exemple, dans les réseaux sociaux
Sinon, tout semblait que les développeurs du site avaient attribué le rôle d'un atterrissage multi-sections à la page principale, mais ils ne l'ont pas dit aux participants et ils ont mis en place des liens de promotion avec le texte d'ancrage prévu, mais sans ancres de section. En conséquence, tous les liens pour différents types de demandes semblaient tomber dans le point d'entrée initial de la page principale et recevaient inévitablement un seul extrait avec un titre relatif à la section principale de la page principale.
Petite digression
Au cas où, je vais montrer dans l'image suivante un exemple de balisage HTML, comment la disposition sémantique est utilisée pour résoudre les problèmes de plusieurs points de destination sur une seule page de destination du site.

Bien sûr, ce schéma fonctionnera à condition que nous mettions des liens vers la page de destination avec une ancre correspondant au cas d'information. C'est à dire:
- monobank.ua - informations de base;
- monobank.ua/#kurs-valut - sur les taux de change;
- monobank.ua/#otkryt-schet - sur l'ouverture d'un compte;
- monobank.ua/#kreditnaja-karta - sur les cartes de crédit.
Mais revenons au jambage SEO détecté
L'erreur, bien que moins grave, car le flux principal de clients passe toujours par l'application mobile, néanmoins, en raison de cette erreur, la banque perd une partie de son trafic de recherche. Parce que les utilisateurs de la recherche sont divisés en 2 types - une majorité pressée et une minorité tranquille:
- le premier ne lit que les en-têtes des extraits de code et les clique si la signification de l'en-tête et la demande entrée correspondent;
- ces derniers lisent attentivement le titre et le texte en dessous et ne cliquent également que lorsque le sens coïncide.
Il est clair que la signification du message dans l'extrait de recherche ossifié pour la page bancaire ne coïncidait qu'avec un très faible pourcentage de demandes. Il fallait comprendre où l'erreur avait été commise.
Afficher le balisage de la page maître
J'ai ouvert la page principale de la banque en utilisant le lien de l'extrait. Dans le code source de cette page, il y avait une seule balise <h1>, généralement utilisée pour écrire le titre principal de la page, qui finit généralement également dans le titre de l'extrait.
De plus, cette balise d'en-tête principale était utilisée dans le code de la page avant le reste des balises d'en-tête <h>. Donc, à première vue, il semblait qu'il n'y avait aucune erreur de référencement.
J'ai pris une photo de cette page et marqué la position des deux premières balises d'en-tête <h> dessus.
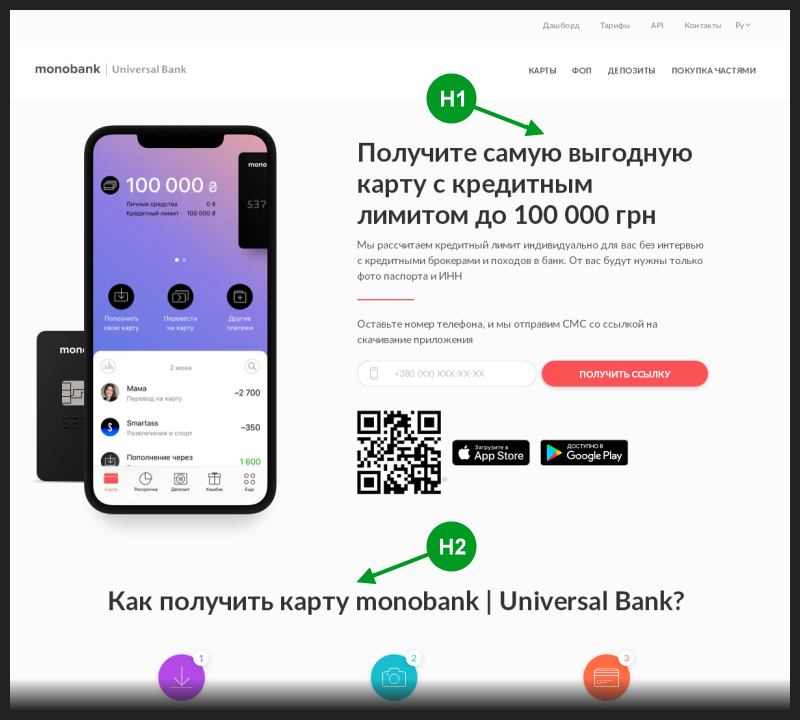
Il était logique de s'attendre à ce que la balise <h1> prenne la place du titre de l'extrait de recherche. Mais pour une raison quelconque, une balise d'un rang inférieur est arrivée à chaque fois.
Au début, j'ai supposé que l'affaire ne concernait que les demandes de renseignements portant sur le nom de la banque. Ce n'est pas dans la balise <h1>, mais c'est dans la balise <h2> - par conséquent, cette balise, malgré son rang inférieur, a toujours l'avantage de prendre le titre de l'extrait de code.
Cependant, cette hypothèse est facile à tester: vous devez écrire une requête exactement égale à la balise <h1>, puis cette balise d'en-tête est garantie d'avoir le droit d'occuper le titre de l'extrait en fonction d'une correspondance absolue avec la requête. Ce que j'ai fait, tout en capturant simultanément le résultat dans l'image suivante.

Il résulte de l'instantané que le serveur de recherche voit et comprend toujours le texte de la balise <h1>, mais pour une raison quelconque, il ne le considère pas comme l'en-tête principal du site Web de cette banque. Ceci est possible dans 2 cas:
- soit le maître SEO a ajouté un micro-balisage sémantique spécifique à la mise en page, qui ordonne à une autre balise de devenir l'en-tête principal;
- ou il y a le soi-disant «problème des concepteurs en ligne» lorsque, en raison de la sous-optimalité de recherche des blocs de construction, leurs balises de texte apparaissent dans différentes sections du document HTML, tandis que la balise de titre principale est omise plus profondément que la balise de titre non principale du contour de sa section.
J'ai décidé de vérifier d'abord le premier cas et j'ai ouvert le site dans l'outil de validation des données structurées. Cependant, seul le micro-balisage Open Graph a été trouvé, aucun indice de réaffectation forcée de la sémantique des balises.
J'ai capturé ce moment dans la photo suivante.

Ensuite, j'ai ouvert le code source de la page de problème, formaté les espaces pour une étude facile, supprimé les attributs de balise dans le même but, puis noté l'essence du problème dans l'image suivante.

En conséquence, nous avons la situation, interprétée ci-dessous, à partir de laquelle je vais écrire une conclusion importante à l'avance : après un mois (c'est à peu près le temps moyen pour les explorations par indexation des robots) à partir du lancement du site, assurez-vous de vérifier quelques questions clés comment le moteur de recherche a pris la mise en page de vos pages, c'est-à-dire quelles parties Il a en fait indexé le contenu.
Interprétation du résultat
Yandex, lors de l'analyse de la page sur le nouveau domaine Monobank, n'a pas trouvé la disposition sémantique (puisque tout est présenté avec des <div> s), et, n'ayant pas d'instructions pour analyser la sémantique implicite, n'a pas commencé à deviner par les classes de balises, et lors de la sélection du titre de l'extrait, il a simplement utilisé la règle de la spécification: balise <title> est le titre principal du document.
Google, lors de l'analyse de la même page, n'a pas non plus trouvé de mise en page sémantique, mais son intelligence artificielle est capable d'analyser les fonctionnalités sémantiques cachées, il a donc remarqué quatre <div> s avec un contenu de classe sémantique implicite ., indiquant le contour de la section dans la situation de marquage actuelle. Par conséquent, la règle concernant la balise <title> a été rejetée et le moteur de recherche a utilisé la règle de la spécification concernant les contours de section, essayant de trouver une section appropriée parmi les quatre déclarées. La première section ne convient pas, car sa balise de titre est plus éloignée du contour que la balise de titre des sections 2, 3 et 4. Parmi ces sections plus appropriées, la deuxième section a été sélectionnée en fonction de sa proximité avec le début du document. C'est ainsi que son titre est entré dans l'extrait.
En fait, la logique de choix d'un titre pour un extrait de code était identique pour les deux moteurs de recherche. C'est juste que Yandex a sélectionné la première balise de titre à partir du premier plan (la balise <head> est implicitement utilisée) dans le document, et Google a choisi la première balise de titre du contour sémantiquement marqué (il s'agissait clairement de la balise <div class = "content">).
C'est cette caractéristique étonnante de la recherche, appelée "non documentée" au début de mon enquête. La balise <h1> n'a pas vraiment d'importance. En fonction de la requête de recherche de l'utilisateur, un plan de section correspondant dans le document et le premier en-tête du plan sont sélectionnés sans tenir compte du niveau d'en-tête numérique utilisé.
Matériaux utilisés
[1] Un H1 ou plusieurs - pourquoi est-ce correct? , Mars 2020. Impera, Documents SEO. Des extraits des spécifications de la norme HTML montrent que l'écriture d'une ou plusieurs balises H1 sur une page est considérée comme correcte dans les deux cas.
[2] Cas de promotion des applications mobiles Monobank , août 2017 - mars 2018. Promodo, cas. Sur l'exemple des événements utilisés par l'agence, il est décrit comment l'application mobile sur iOS et Android a été promue à l'aide d'AdWords, Facebook, Instagram, Twitter, YouTube, et également optimisée dans l'App Store et Google Play.