
introduction
La programmation asynchrone est un type de programmation parallèle dans laquelle une unité de travail peut être effectuée séparément du thread d' exécution principal de l' application. Une fois le travail terminé, le thread principal est informé que le flux de travail est terminé ou qu'une erreur s'est produite. Cette approche présente de nombreux avantages, tels que l'amélioration des performances des applications et une vitesse de réponse accrue.
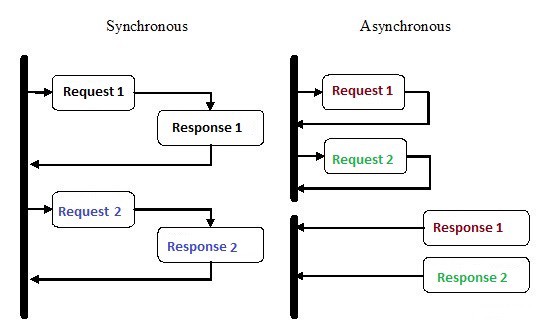
La programmation asynchrone a reçu beaucoup d'attention ces dernières années, et pour une bonne raison. Bien que ce type de programmation puisse être plus complexe que l'exécution séquentielle traditionnelle, il est beaucoup plus efficace.
Par exemple, au lieu d'attendre la fin de la demande HTTP avant de poursuivre l'exécution, vous pouvez envoyer la demande et effectuer d'autres travaux en attente en utilisant des coroutines asynchrones en Python.
L'asynchronie est l'une des principales raisons de la popularité de Node.js pour l'implémentation backend. Une grande partie du code que nous écrivons, en particulier dans les applications lourdes d'E / S telles que les sites Web, dépend de ressources externes. Il peut contenir n'importe quoi, d'un appel de base de données distant à des requêtes POST vers un service REST. Une fois que vous avez soumis une demande à l'une de ces ressources, votre code attend simplement une réponse. Avec la programmation asynchrone, vous laissez votre code gérer d'autres tâches pendant que vous attendez une réponse des ressources.
Comment Python parvient-il à faire plusieurs choses en même temps?

1. Processus multiples
Le moyen le plus évident est d'utiliser plusieurs processus. Depuis le terminal, vous pouvez exécuter votre script deux, trois, quatre, dix fois, et tous les scripts s'exécuteront indépendamment et simultanément. Le système d'exploitation se chargera de la répartition des ressources du processeur entre toutes les instances. Vous pouvez également utiliser la bibliothèque multitraitement , qui peut générer plusieurs processus, comme illustré dans l'exemple ci-dessous.
from multiprocessing import Process
def print_func(continent='Asia'):
print('The name of continent is : ', continent)
if __name__ == "__main__": # confirms that the code is under main function
names = ['America', 'Europe', 'Africa']
procs = []
proc = Process(target=print_func) # instantiating without any argument
procs.append(proc)
proc.start()
# instantiating process with arguments
for name in names:
# print(name)
proc = Process(target=print_func, args=(name,))
procs.append(proc)
proc.start()
# complete the processes
for proc in procs:
proc.join()Production:
The name of continent is : Asia
The name of continent is : America
The name of continent is : Europe
The name of continent is : Africa2. Plusieurs threads
Une autre façon d'exécuter plusieurs jobs en parallèle est d'utiliser des threads. Un thread est une file d'attente d'exécution, qui est très similaire à un processus, cependant, vous pouvez avoir plusieurs threads dans un seul processus, et tous partageront des ressources. Cependant, il sera difficile d'écrire du code de flux à cause de cela. De même, le système d'exploitation fera tout le travail difficile d'allocation de la mémoire du processeur, mais le verrou d'interpréteur global (GIL) ne permettra à un thread Python de s'exécuter qu'en une seule unité de temps, même si vous avez du code multi-thread. C'est ainsi que le GIL sur CPython empêche la concurrence multicœur. Autrement dit, vous ne pouvez exécuter de force que sur un seul cœur, même si vous en avez deux, quatre ou plus.
import threading
def print_cube(num):
"""
function to print cube of given num
"""
print("Cube: {}".format(num * num * num))
def print_square(num):
"""
function to print square of given num
"""
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating thread
t1 = threading.Thread(target=print_square, args=(10,))
t2 = threading.Thread(target=print_cube, args=(10,))
# starting thread 1
t1.start()
# starting thread 2
t2.start()
# wait until thread 1 is completely executed
t1.join()
# wait until thread 2 is completely executed
t2.join()
# both threads completely executed
print("Done!")Production:
Square: 100
Cube: 1000
Done!3. Coroutines et
yield: Les
coroutines sont une généralisation des sous-programmes. Ils sont utilisés pour le multitâche coopératif, où un processus abandonne volontairement le contrôle (
yield) à une certaine fréquence ou pendant des périodes d'attente pour permettre à plusieurs applications de s'exécuter en même temps. Les coroutines sont similaires aux générateurs , mais avec des méthodes supplémentaires et des changements mineurs dans la façon dont nous utilisons l' instruction yield . Les générateurs produisent des données pour l'itération, tandis que les coroutines peuvent également consommer des données.
def print_name(prefix):
print("Searching prefix:{}".format(prefix))
try :
while True:
# yeild used to create coroutine
name = (yield)
if prefix in name:
print(name)
except GeneratorExit:
print("Closing coroutine!!")
corou = print_name("Dear")
corou.__next__()
corou.send("James")
corou.send("Dear James")
corou.close()Production:
Searching prefix:Dear
Dear James
Closing coroutine!!4. Programmation asynchrone
La quatrième voie est la programmation asynchrone, dans laquelle le système d'exploitation n'est pas impliqué. Du côté du système d'exploitation, il ne vous reste qu'un seul processus avec un seul thread, mais vous pouvez toujours effectuer plusieurs tâches en même temps. Alors, quel est le truc?
Réponse:
asyncio
Asyncio- Le module de programmation asynchrone qui a été introduit dans Python 3.4. Il est conçu pour utiliser des coroutines et des futurs pour faciliter l'écriture de code asynchrone et le rend presque aussi lisible que le code synchrone en raison du manque de rappels.
Asyncioutilise différentes constructions:, event loopcoroutines et future.
- event loop . .
- ( ) – , Python, await event loop. event loop. Tasks, Future.
- Future , . exception.
Avec l'aide de
asynciovous, vous pouvez structurer votre code de sorte que les sous-tâches soient définies comme des coroutines et vous permettent de planifier leur lancement comme vous le souhaitez, y compris en même temps. Les coroutines contiennent des points yieldauxquels nous identifions les points de changement de contexte possibles. S'il y a des tâches dans la file d'attente, le contexte sera changé, sinon, non.
Un changement de contexte
asyncioest event loopcelui qui transfère le flux de contrôle d'une coroutine à une autre.
Dans l'exemple suivant, nous exécutons 3 tâches asynchrones qui effectuent individuellement des demandes à Reddit, récupèrent et produisent du contenu JSON. Nous utilisons aiohttp - une bibliothèque cliente http qui garantit que même une requête HTTP est effectuée de manière asynchrone.
import signal
import sys
import asyncio
import aiohttp
import json
loop = asyncio.get_event_loop()
client = aiohttp.ClientSession(loop=loop)
async def get_json(client, url):
async with client.get(url) as response:
assert response.status == 200
return await response.read()
async def get_reddit_top(subreddit, client):
data1 = await get_json(client, 'https://www.reddit.com/r/' + subreddit + '/top.json?sort=top&t=day&limit=5')
j = json.loads(data1.decode('utf-8'))
for i in j['data']['children']:
score = i['data']['score']
title = i['data']['title']
link = i['data']['url']
print(str(score) + ': ' + title + ' (' + link + ')')
print('DONE:', subreddit + '\n')
def signal_handler(signal, frame):
loop.stop()
client.close()
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
asyncio.ensure_future(get_reddit_top('python', client))
asyncio.ensure_future(get_reddit_top('programming', client))
asyncio.ensure_future(get_reddit_top('compsci', client))
loop.run_forever()Production:
50: Undershoot: Parsing theory in 1965 (http://jeffreykegler.github.io/Ocean-of-Awareness-blog/individual/2018/07/knuth_1965_2.html)
12: Question about best-prefix/failure function/primal match table in kmp algorithm (https://www.reddit.com/r/compsci/comments/8xd3m2/question_about_bestprefixfailure_functionprimal/)
1: Question regarding calculating the probability of failure of a RAID system (https://www.reddit.com/r/compsci/comments/8xbkk2/question_regarding_calculating_the_probability_of/)
DONE: compsci
336: /r/thanosdidnothingwrong -- banning people with python (https://clips.twitch.tv/AstutePluckyCocoaLitty)
175: PythonRobotics: Python sample codes for robotics algorithms (https://atsushisakai.github.io/PythonRobotics/)
23: Python and Flask Tutorial in VS Code (https://code.visualstudio.com/docs/python/tutorial-flask)
17: Started a new blog on Celery - what would you like to read about? (https://www.python-celery.com)
14: A Simple Anomaly Detection Algorithm in Python (https://medium.com/@mathmare_/pyng-a-simple-anomaly-detection-algorithm-2f355d7dc054)
DONE: python
1360: git bundle (https://dev.to/gabeguz/git-bundle-2l5o)
1191: Which hashing algorithm is best for uniqueness and speed? Ian Boyd's answer (top voted) is one of the best comments I've seen on Stackexchange. (https://softwareengineering.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed)
430: ARM launches “Facts” campaign against RISC-V (https://riscv-basics.com/)
244: Choice of search engine on Android nuked by “Anonymous Coward” (2009) (https://android.googlesource.com/platform/packages/apps/GlobalSearch/+/592150ac00086400415afe936d96f04d3be3ba0c)
209: Exploiting freely accessible WhatsApp data or “Why does WhatsApp web know my phone’s battery level?” (https://medium.com/@juan_cortes/exploiting-freely-accessible-whatsapp-data-or-why-does-whatsapp-know-my-battery-level-ddac224041b4)
DONE: programmingUtilisation de Redis et Redis Queue RQ
L'utilisation
asyncioet aiohttpn'est pas toujours une bonne idée, surtout si vous utilisez des versions plus anciennes de Python. De plus, il y a des moments où vous devez répartir des tâches sur différents serveurs. Dans ce cas, vous pouvez utiliser RQ (Redis Queue). Il s'agit de la bibliothèque Python habituelle pour ajouter des travaux à la file d'attente et les traiter par des travailleurs en arrière-plan. Pour organiser la file d'attente, Redis est utilisé - une base de données de clés / valeurs.
Dans l'exemple ci-dessous, nous avons ajouté une fonction simple à la file d'attente à l'
count_words_at_urlaide de Redis.
from mymodule import count_words_at_url
from redis import Redis
from rq import Queue
q = Queue(connection=Redis())
job = q.enqueue(count_words_at_url, 'http://nvie.com')
******mymodule.py******
import requests
def count_words_at_url(url):
"""Just an example function that's called async."""
resp = requests.get(url)
print( len(resp.text.split()))
return( len(resp.text.split()))Production:
15:10:45 RQ worker 'rq:worker:EMPID18030.9865' started, version 0.11.0
15:10:45 *** Listening on default...
15:10:45 Cleaning registries for queue: default
15:10:50 default: mymodule.count_words_at_url('http://nvie.com') (a2b7451e-731f-4f31-9232-2b7e3549051f)
322
15:10:51 default: Job OK (a2b7451e-731f-4f31-9232-2b7e3549051f)
15:10:51 Result is kept for 500 secondsConclusion
À titre d'exemple, prenons une exposition d'échecs où l'un des meilleurs joueurs d'échecs est en compétition contre un grand nombre de personnes. Nous avons 24 parties et 24 personnes avec lesquelles vous pouvez jouer, et si le joueur d'échecs joue avec eux de manière synchrone, cela prendra au moins 12 heures (en supposant que le jeu moyen dure 30 coups, le joueur d'échecs réfléchit au mouvement pendant 5 secondes, et l'adversaire prend environ 55 secondes.) Cependant, en mode asynchrone, le joueur d'échecs pourra faire un mouvement et laisser le temps à l'adversaire de réfléchir, tout en passant à l'adversaire suivant et en divisant le coup. Ainsi, il est possible de faire un mouvement dans les 24 matchs en 2 minutes, et ils peuvent tous être gagnés en une heure seulement.
C'est ce que l'on entend quand on dit que l'asynchronisme accélère le travail. Nous parlons d'une telle vitesse. Un bon joueur d'échecs ne commence pas à jouer aux échecs plus rapidement, c'est juste que le temps est plus optimisé et qu'il n'est pas perdu d'attendre. Voilà comment cela fonctionne.
Par cette analogie, un joueur d'échecs sera un processeur, et l'idée principale sera de garder le processeur inactif le moins de temps possible. Il s'agit d'avoir toujours quelque chose à faire.
En pratique, l'asynchronie est définie comme un style de programmation parallèle dans lequel certaines tâches libèrent le processeur pendant les périodes d'attente pour que d'autres tâches puissent l'utiliser. Il existe plusieurs façons d'obtenir une concurrence simultanée en Python qui répond à vos exigences, à votre flux de code, à votre traitement de données, à votre architecture et à vos cas d'utilisation, et vous pouvez choisir n'importe lequel d'entre eux.
.