Dans mon discours, j'ai rappelé l'évolution de Python dans l'entreprise: des premiers services emballés dans des packages deb et déployés sur du bare metal, à un mono-référentiel complexe avec son propre système de construction et cloud. Plus dans l'histoire sera Django, Flask, Tornado, Docker, PyCharm, IPv6 et d'autres choses que nous avons rencontrées au fil des ans.
- Je vais vous parler de moi. Je suis arrivé à Yandex en 2008. Au début, j'ai fait des services de contenu, en particulier Yandex.Afishu. J'y ai écrit en Python, nous avons réécrit le service à partir de Perl et d'autres technologies amusantes.
Puis je suis passé aux services internes. Le département des services internes s'est progressivement transformé en gestion des interfaces de recherche et des services pour les organisations. Beaucoup de temps s'est écoulé, d'un simple développeur que j'ai grandi à la tête du développement python de notre division, environ 30 personnes.
Un point important: la société est très grande, et je ne peux pas parler pour tout Yandex. Je communique, bien sûr, avec des collègues d'autres départements, je sais comment ils vivent. Mais au fond, je ne peux parler que de notre département, de nos produits. Mon exposé portera sur ce point. Parfois, je vous dirai qu'ailleurs à Yandex, ils font ceci et cela. Mais cela n'arrivera pas souvent.
Python est utilisé dans de nombreux endroits de l'entreprise: toute technologie, toute pile technologique, tout langage. Tout ce qui vient à l'esprit quelque part dans l'entreprise est soit sous la forme d'une expérience, soit autre chose. Et dans n'importe quel service Yandex, il y aura certainement Python dans un composant ou un autre.
Tout ce que je vais vous dire est mon interprétation des événements. Je ne prétends pas être à cent pour cent d'objectivité. Tout cela, y compris à travers mes mains, était émotionnellement coloré. Toute mon expérience est si personnelle.

Comment le rapport sera-t-il structuré? Pour vous faciliter la perception de l'information, et pour moi de le dire, j'ai décidé de briser toute l'évolution de 2007 à environ le moment actuel en plusieurs époques. Le rapport sera strictement structuré par ces époques. L'époque signifie une sorte de changement radical des infrastructures ou de l'approche du développement. Si notre infrastructure sidérurgique est en train de changer et en même temps nous changeons la façon dont nous développons les services, les outils que nous utilisons, c'est une époque. Il est clair que j'ai dû m'ajuster un peu. Il est clair que tout ne s'est pas produit de manière synchrone et qu'il y avait des écarts entre ces changements, mais j'ai essayé de tout ranger sous une seule chronologie, juste pour le rendre plus compact.
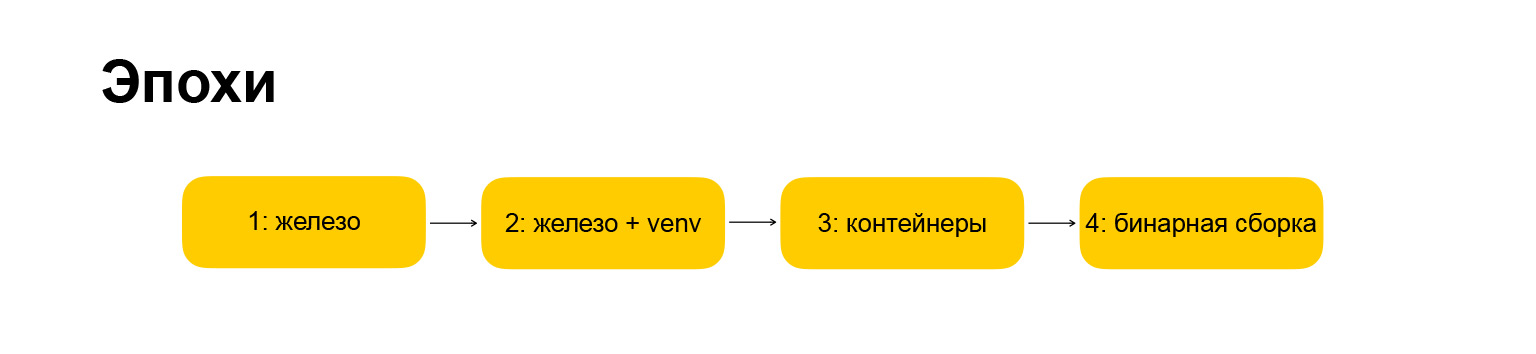
Quelles époques avons-nous? Ici aussi, tout est copyright, tous les noms sont à moi. La première ère s'appelle le «fer», c'est là que nous avons commencé lorsque je suis arrivé dans l'entreprise. Par conséquent, tout a un peu changé. L'ère est devenue "fer + venv". De plus, je vais révéler ce qui se cache derrière ces noms. Tout d'abord, je veux vous donner un guide sur ce que je vais vous dire.
La prochaine ère est celle des "conteneurs", tout est plus ou moins clair ici. L'ère dans laquelle nous évoluons en ce moment est "l'assemblage binaire", je vous en parlerai aussi.

Comment sera structurée chaque époque? C'est aussi important, car je voulais faire une narration rythmée, pour que chaque section soit strictement structurée et plus facile à comprendre. L'époque est décrite par l'infrastructure, les cadres que nous utilisons, la façon dont nous travaillons avec les dépendances, le type d'environnement de développement dont nous disposons et les avantages et les inconvénients de telle ou telle approche.
(Pause technique.) Je vous ai dit l'introduction, expliqué comment le rapport sera structuré, passons à l'histoire elle-même.
Âge 1: fer
Le premier service que j'ai commencé à faire lorsque j'ai rejoint l'entreprise s'appelait "Where Everybody Goes". C'était le satellite Afisha, le premier grand service sur Django.
Grisha Bakunovbobukpeut dire pourquoi il a une fois décidé de transférer Django à Yandex - en général, c'est arrivé. Nous avons commencé à créer des services à Django.
Je suis venu et ils m'ont dit: faisons "Où tout le monde va". Ensuite, il y avait déjà une sorte de base. Je me suis connecté et nous l'avons considéré comme une sorte d'expérience - cela fonctionnera-t-il ou non. L'expérience s'est avérée un succès. Tout le monde a convenu qu'il était possible de créer des services Web dans Yandex en Python et Django. Bien! Notre infrastructure est prête pour cela, les gens sont prêts, le monde est également prêt. Allons-y, distribuons Python et Django plus loin dans toute l'entreprise. Nous avons commencé à le faire. Réécrit Yandex.Afisha, Météo. Puis - le programme télévisé. Puis tout s'est passé comme un brouillard, ils ont commencé à tout réécrire.
À ce moment-là, l'infrastructure Yandex semblait que tout le backend était principalement écrit sur les pros. De toute évidence, le passage à Python a beaucoup accéléré le développement dans de nombreux endroits, et cela a été bien accueilli par l'entreprise et la direction. Parlons maintenant de l'infrastructure - où ces services fonctionnaient-ils, sur quoi se sont-ils développés et tout cela.

C'étaient des machines à fer, d'où le nom de cette époque. Que sont les machines à repasser? Ce ne sont que des serveurs dans le centre de données. Il existe de nombreux serveurs, ils sont tous combinés en un cluster de, disons, 15 machines. Ensuite, il y en avait 30, puis 50, 100. Et tout cela sur Debian ou Ubuntu. À ce moment-là, nous avions migré de Debian vers Ubuntu. Nous avons lancé toutes les applications via un processus d'initialisation standard. Tout était standard, comme cela se faisait à l'époque. Pour que nos applications communiquent sur le serveur Web, nous avons utilisé le protocole FastCGI et la bibliothèque flup. Si vous utilisez Python depuis longtemps, vous en avez probablement entendu parler. Mais maintenant, je suis sûr que vous ne l’utilisez pas, car il est obsolète et était une chose très étrange, cela a fonctionné très lentement.
A ce moment, évidemment, il n'y avait pas de troisième Python, nous avons écrit en Python 2.3. Ensuite, ils ont migré vers la version 2.4. Des temps sauvages. Je ne veux même pas y penser, parce que la langue, les communautés et l'écosystème étaient complètement différents, même si c'était aussi cool, et beaucoup étaient attirés par cela à l'époque. Personnellement, cela m'a plongé dans le monde de Python - que même malgré les particularités et les bizarreries, il était déjà clair à l'époque que Python est une technologie prometteuse, vous pouvez y investir votre temps.
Un point important: alors nous n'avons pas encore utilisé nginx, n'avons plus utilisé Apache, mais avons utilisé un serveur web appelé Lighttpd. Si vous créez des services Web depuis longtemps, vous en avez probablement entendu parler aussi. À un moment donné, il était très populaire.

Parmi les frameworks, nous avons en fait utilisé Django. Nous avons commencé à créer de gros services à Django. Quelque part dans l'entreprise, il y avait CherryPy, quelque part - Web.py. Vous avez peut-être également entendu parler de ces cadres. Maintenant, ils ne sont pas dans les premiers rôles, ils ont longtemps été mis de côté par des cadres plus jeunes et audacieux. Ensuite, ils avaient leur propre créneau, mais finalement ils se sont éteints tôt ou tard, nous avons arrêté de faire quoi que ce soit sur eux. Ils ont commencé à tout faire à Django.
À ce stade, Python s'est tellement répandu dans l'entreprise qu'il a fait irruption dans notre département: les services Web en Python et Django ont commencé à se faire partout dans l'entreprise.

Passons au travail avec les dépendances. Et puis, il y a une telle chose que vous avez probablement également rencontrée si vous êtes venu travailler dans une grande entreprise: la société dispose déjà d'une infrastructure établie, vous devez vous y adapter. Yandex avait une infrastructure deb, des référentiels internes de paquets deb. On pensait que le développeur Yandex était capable d'assembler ce package deb. Nous avons été obligés de nous intégrer dans ce flux, d'assembler nos projets sous la forme de packages deb complets, puis, en tant que package deb, nous avons mis tout cela sur les serveurs dont je parlais, puis nous les avons également placés sur des clusters en tant que packages deb.
En conséquence, toutes les dépendances et bibliothèques, le même Django, nous avons également dû emballer dans des packages deb. Pour cela, nous avons créé notre propre infrastructure, créé un référentiel interne, appris à le faire. Ce n'est pas une activité très originale: si vous avez essayé de construire un RPM ou un package deb, alors vous le savez. RPM est légèrement plus simple, deb est plus complexe. Mais tout de même - cela ne fonctionnera pas juste pour venir de la rue et cliquer dessus pour commencer à le faire. Vous devez creuser un peu.
Nous construisons des paquets deb depuis de nombreuses années après cela. Et il me semble que tous ceux qui ont fait cela pour des besoins professionnels ne comprenaient pas ce qui se passait sous le capot. Ils se sont simplement pris les uns les autres, copié des blancs, des modèles, mais n'ont pas creusé profondément. Mais ceux qui déterraient ce qui se passait à l'intérieur devenaient des collègues très utiles et très demandés: si soudain quelque chose n'allait pas, tout le monde leur demandait des conseils et leur demandait des nuances et de l'aide pour le débogage. C'était une période amusante, car j'étais intéressé à découvrir ce qu'il y avait à l'intérieur. Ainsi gagné une popularité bon marché auprès de ses collègues.

Outre l'écosystème de dépendances, il existe également un travail avec du code partagé. Déjà au début, il y avait une croissance explosive du nombre de projets, et il était nécessaire de travailler avec du code commun, de créer des bibliothèques partagées, etc. Nous avons commencé à faire ce genre d'open source interne. Ils ont fait les fonctions générales d'autorisation, travailler avec des logs, avec d'autres choses communes, des API internes, des référentiels internes. Nous avons fait tout cela sous forme de bibliothèques, mis dans le référentiel interne. Au départ, il s'agissait de référentiels SVN, puis du GitHub interne.
Et à la fin, toutes ces dépendances ont été empaquetées, toutes ces bibliothèques étaient également dans deb, chargées dans un seul référentiel. À partir de là, un tel environnement de package a été formé. Si vous démarrez un nouveau projet, vous pouvez y placer plusieurs bibliothèques, obtenir une base de fonctionnalités et lancer immédiatement le projet dans l'infrastructure Yandex. C'était très confortable.

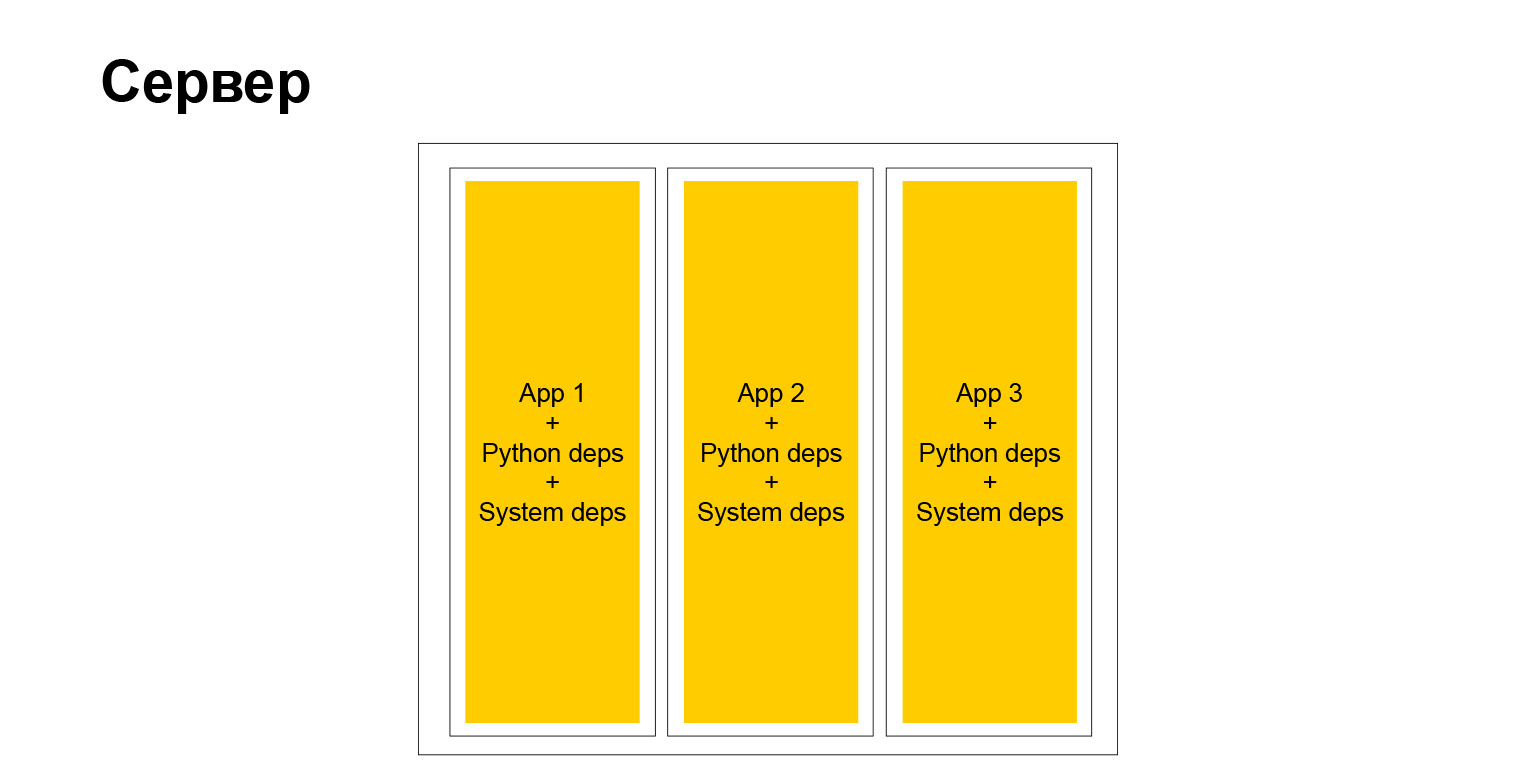
À quoi ressemblait notre serveur typique? Classiquement. Il y a des dépendances système, il y a des dépendances et des applications python. Plusieurs choses en découlent. Tout d'abord, toutes les applications qui s'exécutent sur le même serveur et donc sur le même cluster doivent avoir les mêmes dépendances. Parce que si vous installez un système de packages, c'est toujours une version, il ne peut pas y en avoir plusieurs, vous devez synchroniser.
Quand il y a peu de projets, cela peut encore être fait d'une manière ou d'une autre. Quand il y en a beaucoup, tout devient très compliqué. Ils sont réalisés par des équipes différentes, il leur est difficile de s'entendre. Chaque équipe souhaite effectuer une mise à niveau précoce vers une bibliothèque ou souhaite mettre à niveau le framework. Et tout le monde devrait suivre cela. Au fil du temps, cela crée beaucoup de problèmes. Cela nous a incités à abandonner un tel schéma, à passer à l'ère suivante. Mais j'en parlerai un peu plus tard.
Parlons de l'environnement de développement. Mais il existe une telle compréhension élargie de l'environnement de développement. C'est ainsi que vous arrivez au travail, comment vous écrivez du code, comment vous le déboguez, comment vous travaillez avec, où vous le vérifiez, comment vous l'exécutez, où vous exécutez des tests et tout ça.

Lorsque j'ai rejoint l'entreprise, nous travaillions tous sur des serveurs de développement distants. Autrement dit, vous avez une sorte de bureau, sous Windows ou Linux, ce n’est pas grave. Vous allez sur un serveur distant avec la bonne Debian et le bon référentiel de paquets. Et vous exécutez, exécutez vim, Emacs, écrivez du code, déboguez.
Ce n’est pas très pratique, mais nous ne connaissions pas vraiment une autre vie. Ceux qui avaient de la chance, qui avaient un ordinateur de bureau ou un ordinateur portable avec Linux, pouvaient essayer de le faire localement. Mais il n'y avait pas non plus d'instructions spéciales, rien. Un peu de temps sauvage. Des personnes spéciales qui à cette époque vivaient sous Windows et sur Mac et voulaient être développées localement ont élevé une machine virtuelle à l'intérieur de laquelle Linux. Ils ont écrit du code à l'intérieur de cette machine virtuelle et l'ont lancée. Plus précisément, ils ont écrit le code sur le système hôte, lancé le code à l'intérieur de la machine virtuelle et y ont en quelque sorte jeté le système de fichiers pour que tout se synchronise. Tout a très mal fonctionné, mais d'une manière ou d'une autre, il a survécu.
Quels sont les avantages et les inconvénients de cette époque, de cette approche du développement? En fait, il y a de solides inconvénients:
- Comme je l'ai dit, les groupes généraux étaient à l'étroit.
- Tous les projets du cluster doivent avoir les mêmes dépendances.
- . , , Django . , . 15-20 . . , , — . X, . , . - , - , . . , , . .
- Yandex dépendait de l'infrastructure Debian. Nous l'avons supporté, construit des packages, maintenu un référentiel interne. Et cela, bien sûr, n'est pas non plus très bon, pas très pratique, pas très flexible. Vous dépendez de choses étranges qui n'ont pas été faites pour l'entreprise. Debian en tant que solution open source, en tant que distribution Linux, a néanmoins été conçue pour d'autres tâches.
Parlons un peu plus de Django. Pourquoi avons-nous commencé à l'utiliser? Je pensais juste avant le rapport, assis sur une chaise, qu'il s'avère qu'il y a 11 ans, j'ai pris la parole lors d'une conférence à Kiev sur le même sujet "Pourquoi devrais-je utiliser Django?" Ensuite, je l'ai aimé moi-même. J'étais un développeur admiré qui a lu la documentation, fait mon premier projet, et il lui semble que tout, maintenant cet outil est universel pour tout et vous pouvez, je ne sais pas, même clouer des clous dessus.
Mais cela a pris du temps. J'adore toujours Django, il est encore assez utilisé dans notre département et en général dans l'entreprise. Par exemple, même avant l'automne 2018, Alice avait Django dans son backend. Désormais, elle n'est plus là, mais pour démarrer rapidement, ses collègues l'ont choisie. Parce que certains des avantages sont toujours valables - un vaste écosystème, il existe encore de nombreux spécialistes. Il y a toutes les piles dont vous avez besoin.
Et il y a une grande flexibilité. Quand vous commencez tout juste à travailler avec Django, il vous semble que cela vous restreint très, vous lie en main, nécessite un certain flux de travail avec lui. Mais si vous creusez un peu plus profondément, beaucoup de choses peuvent être désactivées, modifiées, configurées. Et si vous pouvez l'utiliser habilement, vous pouvez obtenir tous les petits pains associés au framework Python le plus probablement le plus populaire. Vous pouvez contourner tous les inconvénients. Il y en a aussi beaucoup, mais ils peuvent être stoppés d'une manière ou d'une autre.
Âge 2: fer + venv
Nous avons fini de discuter de cette époque. L'année 2011 est terminée, nous sommes passés à l'ère suivante, «Iron + venv». Vous connaissez déjà le fer, maintenant vous devez dire ce qui s'est passé, d'où vient le nom venv. Digression lyrique: venv n'est pas apparu parce que des machines virtuelles sont apparues. Pourquoi entre guillemets? Parce que nous avons commencé à essayer toutes sortes de choses comme des conteneurs comme OpenVZ ou LXC. Ensuite, ils étaient très peu développés, pas comme maintenant. Ils n'ont pas vraiment volé avec nous. Nous vivions toujours sur des clusters communs, nous devions encore coexister avec d'autres projets côte à côte sur les mêmes machines. Nous recherchions une solution.

Par exemple, nous sommes passés de init à upstart systemd, et un peu plus tard, nous avons eu la flexibilité de lancer nos applications. Nous avons abandonné FastCGI et avons commencé à utiliser soit l'interface WSGI pour communiquer avec le serveur Web, soit HTTP. À ce stade, nous utilisions déjà du Python plus ou moins moderne, l'écosystème était déjà très bien développé. Nous sommes passés à nginx en tant que serveur Web, en général tout allait bien.

Nous avons également commencé à nous adapter de nouveaux cadres. Par exemple, ils ont commencé à utiliser Tornado. Bien sûr, à ce moment-là, Flask était déjà apparu, après 2012, Flask était déjà très à la mode, populaire et Django menaçait de se débarrasser du piédestal des frameworks populaires en Python. Et, bien sûr, ils ont commencé à utiliser du céleri. Parce que lorsque les projets se développent, leur nombre augmente, ils deviennent plus chargés, résolvent plus de tâches, traitent plus de données, alors vous avez besoin d'un cadre pour l'exécution hors ligne des tâches sur un grand cluster informatique. Bien sûr, nous avons commencé à utiliser le céleri pour cela. Mais plus là-dessus plus tard.

Ce qui a radicalement changé, c'est comment cela fonctionne avec les dépendances. Nous avons commencé à collecter un environnement virtuel. À cette époque, la communauté python est arrivée au point qu'il est possible de ne pas mettre de bibliothèques python dans le système, mais de créer un environnement virtuel, d'y placer toutes les dépendances python dont vous avez besoin, et cet environnement sera complètement indépendant. Il peut y avoir autant d'environnements virtuels sur une machine. C'est l'isolement, une addiction très pratique. Vous l'utilisez toujours. Et nous avons également tout adapté. En conséquence, qu'avons-nous fait? Nous avons créé un environnement virtuel et y avons placé toutes les dépendances python, l'avons emballé dans un package deb et l'avons déjà roulé sur le serveur.
En conséquence, tous les projets ont cessé d'interférer les uns avec les autres, dépendent de la dépendance python commune dans le système, ils pouvaient facilement choisir la version du framework ou de la bibliothèque à utiliser. C'est très pratique. Des modifications ont également été apportées au code partagé. Puisque nous avons partiellement abandonné l'infrastructure Debian et, en particulier, arrêté d'installer les dépendances python avec les paquets deb, nous avions besoin de quelque chose où nous pourrions décharger tout notre code commun et nos bibliothèques communes et d'où nous pourrions les mettre.

Lien de la diapositive
À ce moment-là, il existait déjà plusieurs implémentations de PyPI, c'est-à-dire un référentiel de packages python, implémentations écrites notamment en Django. Et nous en avons choisi un. Ça s'appelle Localshop, voici un lien... Ce référentiel est toujours vivant, il contient déjà un millier de packages internes. Autrement dit, entre 2011 et 2012 environ, une entreprise de la taille de Yandex a généré environ mille bibliothèques différentes, des utilitaires écrits en Python, qui sont censés être réutilisés dans d'autres projets. Vous pouvez estimer l'échelle.
Toutes les bibliothèques sont publiées sur ce référentiel interne. Et puis à partir de là, ils sont soit installés en Python, soit il existe une infrastructure automatique spéciale qui les transforme en Debian. Tout cela est plus ou moins automatisé, pratique. Nous avons cessé de gaspiller autant de ressources pour maintenir l'infrastructure Debian. Tout cela fonctionnait plus ou moins tout seul.
Et c'est une étape qualitative. Voici un diagramme avec ce dont je parlais.
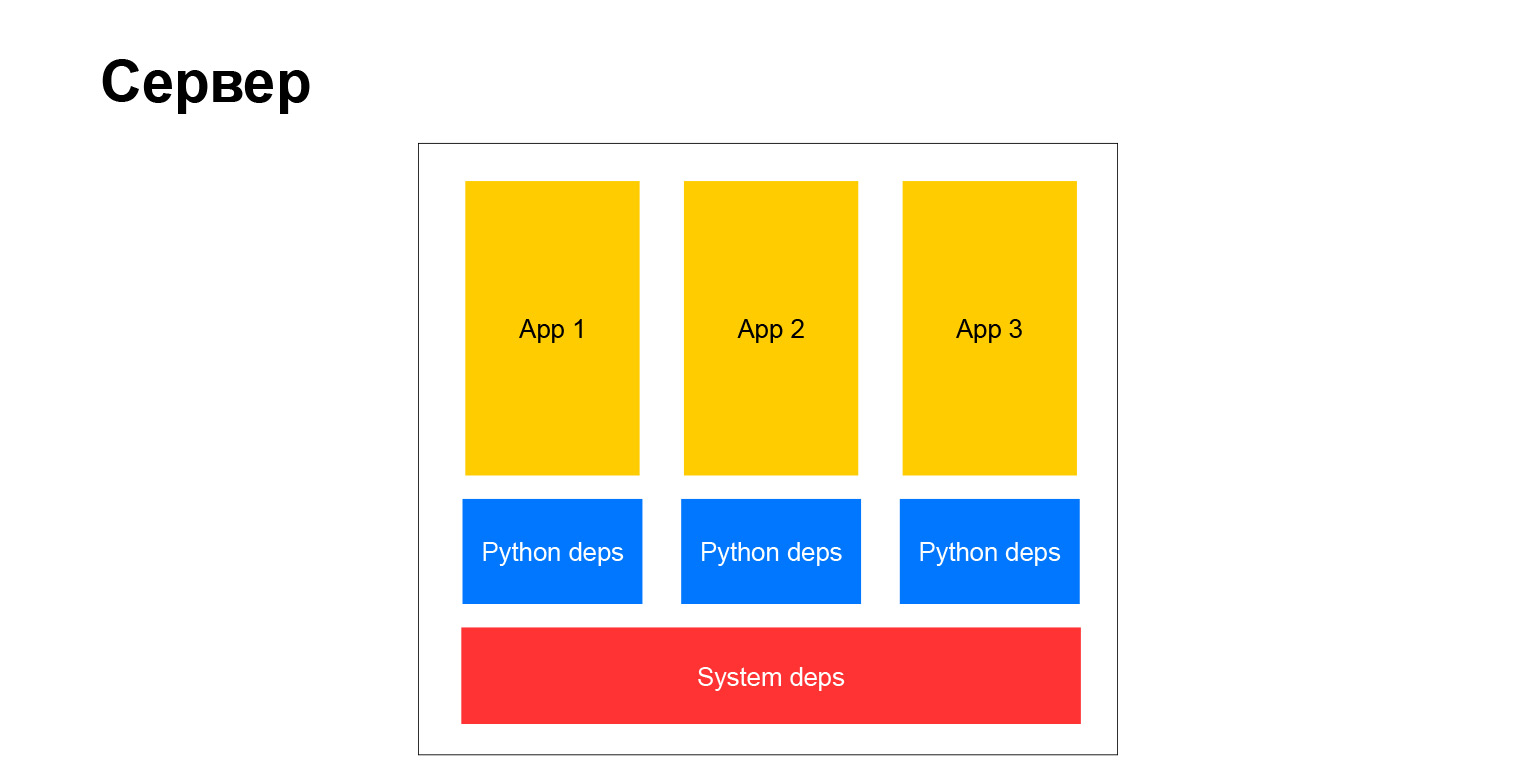
Autrement dit, les addictions au python ont finalement cessé d'être les mêmes pour tout le monde. Ceux du système existent toujours, mais ils sont peu nombreux. Par exemple, un pilote pour une base de données, un analyseur XML requis des binaires système. En général, à ce moment-là, nous ne pouvions pas nous débarrasser de ces dépendances.

L'environnement de développement a également changé. Depuis venv, l'environnement virtuel est devenu disponible et a fonctionné partout à ce moment-là, nous avons pu construire notre projet en général sur n'importe quelle plateforme locale. Cela a rendu la vie beaucoup plus facile. Il n'y avait plus besoin de se soucier de Debian, aucune machine virtuelle n'était nécessaire. Vous pouvez simplement prendre n'importe quel système d'exploitation, disons virtual venv, puis pip installer quelque chose. Et ça a marché.
Quels sont les avantages de ce schéma? Depuis que nous avons vécu assez longtemps - peut-être un peu plus de trois ans - avec cette configuration de paramètres, il est devenu plus facile de vivre sur des clusters d'auberges. C'est vraiment pratique. Autrement dit, nous nous sommes arrêtés en fonction de ces mises à jour globales de certains Django dans toute l'entreprise. Nous pourrions sélectionner plus précisément les versions qui nous conviennent, mettre à jour les dépendances critiques plus souvent si elles corrigent des vulnérabilités ou autre chose. Et il y avait une très bonne manière, nous l'avons aimé et nous a sauvé beaucoup de tout.
Mais il y avait aussi des inconvénients. Les dépendances du système restaient courantes. Parfois ça tirait, parfois ça gênait. Encore une fois, je vais aller un peu au-delà de la portée de notre département et vous parler de l'entreprise. Puisque l'entreprise est grande, tout le monde n'a pas suivi ces époques avec nous. À cette époque, la société continuait à utiliser les packages deb pour travailler avec les dépendances python. Permettez-moi de vous expliquer plus en détail pourquoi nous avons commencé à utiliser ces ou ces cadres. En particulier, Tornado.

Nous avions besoin d'un framework asynchrone, nous avons maintenant des tâches pour lui. Le troisième Python et son asyncio n'existaient pas encore, ou ils étaient dans un état initial, il n'était pas encore très fiable de les utiliser. Par conséquent, nous avons essayé de choisir le framework asynchrone à utiliser. Il y avait plusieurs options: Gevent et Twisted. Très probablement, il y en avait plus, mais nous avons choisi parmi eux. Twisted a déjà été utilisé par l'entreprise - par exemple, le backend Yandex.Taxi a été écrit en Twisted. Mais nous les avons regardés et avons décidé que Twisted ne ressemble pas à un python, même PEP-8 ne correspond pas. Et Gevent - il y a une sorte de hack avec une pile de python à l'intérieur. Utilisons Tornado.
Nous ne l'avons pas regretté. Nous utilisons toujours Tornado dans certains services - dans ceux que nous n'avons pas encore réécrit en troisième Python. Le cadre a prouvé au fil des ans qu'il est compact, fiable et fiable.
Et bien sûr le céleri. J'en ai déjà partiellement parlé. Nous avions besoin d'un cadre pour l'exécution distribuée des tâches différées. Nous avons compris.

C'était très pratique que Celery prenne en charge différents courtiers. Nous avons activement utilisé ce b pour diverses tâches en essayant de trouver l'un ou l'autre bon courtier. Quelque part c'était Mongo, quelque part SQS, quelque part Redis. Mais nous avons essayé de choisir en fonction des besoins et nous avons réussi.
Malgré le fait qu'il y ait beaucoup de plaintes concernant Celery, comment il est écrit à l'intérieur, comment le déboguer, quel type de journalisation existe, cela fonctionne plutôt. Le céleri est toujours activement utilisé dans presque tous les projets de notre département et, pour autant que je sache, en dehors de notre projet. Le céleri est un incontournable. Si vous avez besoin d'une exécution différée des tâches, tout le monde prend du céleri. Ou au début, ils ne le prennent pas, ils essaient de prendre autre chose, mais ensuite ils viennent toujours à Celery.
Nous passons à l'ère suivante. Nous approchons déjà du temps présent, plus moderne. Ici, le nom de l'époque parle de lui-même.
Âge 3: conteneurs

Au sein de l'entreprise, nous avons un cloud compatible docker. À l'intérieur, pas le runtime docker, mais le développement interne. Mais en même temps, vous pouvez y déployer des images de docker. Cela nous a beaucoup aidés, car nous avons pu utiliser l'ensemble de l'écosystème docker pour le développement et les tests. Nous pourrions utiliser toutes sortes de goodies, puis, simplement après avoir reçu l'image testée, la télécharger sur ce cloud. Cela a commencé là-bas et a fonctionné comme il se doit.
À ce moment-là, nous étions déjà indépendants de quel système d'exploitation se trouvait à l'intérieur du conteneur. Vous pouvez en choisir un. Bien sûr, nous n'avons pas utilisé de démons ordinaires, mais, par exemple, un superviseur. Par la suite, tout le monde est passé à uWSGI - il s'est avéré que uWSGI ne sait pas seulement comment exécuter vos applications Web et fournir une interface pour le serveur Web. C'est aussi juste une bonne chose générique pour démarrer des processus.
Il y a cependant une configuration un peu étrange, mais, en général, c'est pratique. Nous nous sommes débarrassés de l'essence inutile et avons commencé à tout faire via uWSGI. Nous l'utilisons pour communiquer avec le serveur Web. Les particularités de notre cloud sont telles que nous ne pouvons pas utiliser le protocole uWSGI pour communiquer avec l'équilibreur, qui est globalement représenté dans le cloud, en tant que composant. Mais ça va. À l'intérieur de l'uWSGI, le serveur HTTP est assez bien implémenté, il fonctionne rapidement et de manière fiable.

Qu'en est-il des cadres? Le framework Falcon est apparu, et nous avons réécrit la même Alice avec Django sur Falcon, car il y avait un certain nombre d'apis - il fallait qu'ils fonctionnent rapidement, mais en même temps ils n'étaient pas très compliqués.
Django à un moment donné est devenu un peu redondant, et afin d'augmenter la vitesse et de se débarrasser d'une si grande dépendance, une grande bibliothèque, nous avons décidé de la réécrire dans Falcon.
Et bien sûr asyncio. Nous avons commencé à écrire de nouveaux services dans le troisième Python, et d'anciens - à réécrire dans le troisième Python. Seulement dans notre département, il y a maintenant une trentaine de services qui sont écrits en Python. Ce sont 30 produits à part entière, avec un backend, un frontend et leur propre infrastructure. Ce qui traite les données fournit des services aux consommateurs internes et externes.
Mais la société, comme vous le savez, possède des milliers de services Python, et ils sont différents. Ils sont sur différents frameworks, différents Python, plus anciens et plus récents. Maintenant, l'entreprise utilise presque tous les cadres modernes que vous connaissez. Django, Flask, Falcon, autre chose, asynchrone - Tornado, Twisted, asyncio. Tout est utilisé et bénéfique.
Revenons à la structure de l'époque - comment nous avons commencé à travailler avec les dépendances.

Tout est simple ici. Désormais, nous ne pouvons plus utiliser l'environnement virtuel. Nous n'avons pas besoin de paquets deb. Nous juste au moment de la construction de l'image mis avec pip tout ce dont nous avons besoin. Il est complètement isolé. On ne dérange personne. Et très confortable. Toutes les dépendances du système, vous pouvez choisir n'importe quelle image de base de Debian, Ubuntu, peu importe. Nous aimons. Pleine liberté.
Mais en fait, la liberté totale, comme vous le savez, a un second côté. Lorsque vous avez une grande entreprise, et encore plus lorsque vous souhaitez promouvoir des méthodes et des méthodes de développement uniformes, des méthodes de test, des approches de la documentation - en ce moment, vous êtes confronté au fait que ce zoo, d'une part, aide quelque part. En revanche, au contraire, cela complique. Il ne peut pas facilement, par exemple, implémenter une sorte de bibliothèque dans tous les services, car les services sont différents. Ils ont différentes versions de Python, Django ou d'un autre framework. Cela complique les choses. Mais à la fin, un serveur typique a commencé à ressembler à ceci.
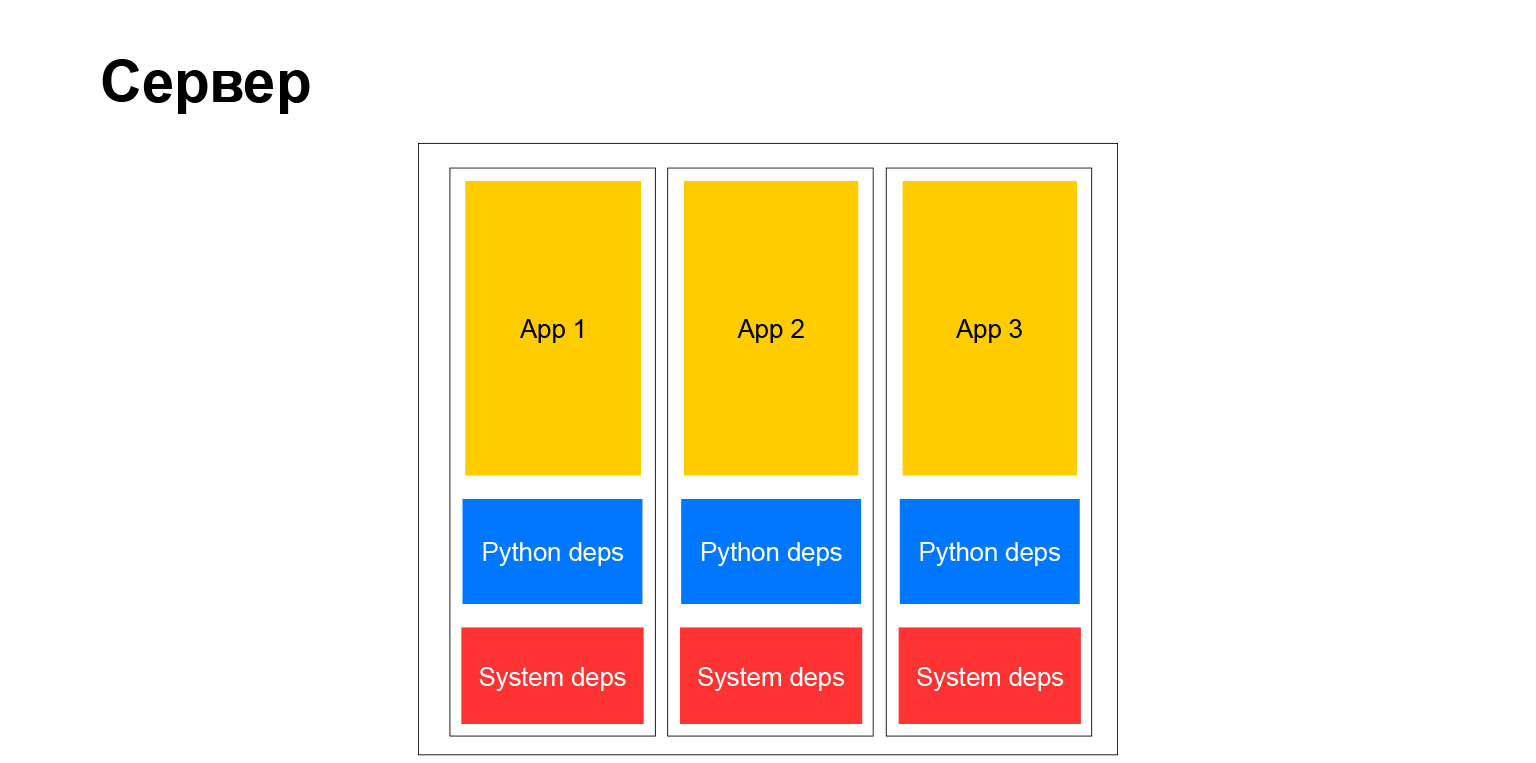
Oui, c'est un serveur. Nous avons des conteneurs totalement indépendants. Chacun d'eux a son propre environnement système et nos applications tournent. Très confortablement. Mais comme je l'ai dit, il y a des inconvénients.
Revenons à docker pendant un moment. Nous avons commencé à utiliser Docker pour le développement, cela nous a beaucoup aidés.

Docker est disponible pour toutes les plateformes. Vous pouvez tester, utiliser docker-compose, faire un essaim de dockers et essayer d'émuler votre environnement de production sur de petits clusters pour tester quelque chose. Peut-être des tests de charge. Nous avons commencé à l'utiliser activement.
Docker est également très bien intégré à toutes sortes d'environnements de développement. Par exemple, je développe chez PyCharm, et la plupart de mes collègues aussi. Il existe un support de docker intégré, avec ses avantages et ses inconvénients, mais en général, tout fonctionne.
C'est devenu très pratique, nous avons fait un pas qualitatif, et c'est à ce stade que nous en sommes maintenant. Il est pratique de développer à l'aide de docker, même si notre cloud cible, où nous déploierons nos applications, n'est pas un Docker Runtime à part entière, présente certaines limites. Mais cela ne nous empêche toujours pas d'utiliser le moteur Docker en local et dans les tâches associées.
Faisons le point sur cette époque. Avantages - isolation complète, chaîne d'outils pratique pour le développement et, comme je l'ai dit, support IDE.
Il y a aussi des inconvénients. Docker est partout, mais si ce n'est pas Linux, cela fonctionne un peu étrange. Les développeurs Yandex qui ont un docker d'installation MacBook pour Mac. Et il y a des fonctionnalités, par exemple, IPv6 fonctionne étrangement, ou vous devez le modifier d'une manière ou d'une autre. Et dans notre entreprise, IPv6 est très répandu. Nous avons longtemps manqué d'adresses IPv4, de sorte que toute l'infrastructure interne est largement liée à IPv6. Et quand IPv6 ne fonctionne pas sur votre ordinateur portable ou dans le docker, qui se trouve sur l'ordinateur portable, vous souffrez et ne pouvez vraiment rien faire, alors nous devons le contourner.

Malgré cela, nous aimons beaucoup docker. Il est efficace et possède un bon écosystème. On dit que les gens viennent de la rue - pouvez-vous docker? Ils - oui, je peux. Tout parfaitement. Une personne arrive et commence littéralement immédiatement à être utile, car elle n'a pas besoin de se plonger dans la façon de démarrer et de construire un projet, comment exécuter des tests, comment regarder la composition ou une sortie de débogage. L'homme sait déjà tout. C'est une norme de facto dans le monde extérieur, cela augmente notre efficacité, nous pouvons rapidement fournir des fonctionnalités aux utilisateurs et ne pas dépenser d'argent en infrastructure.
Âge 4: construction binaire
Mais nous approchons déjà de la dernière ère dans laquelle nous venons d'entrer. Et ici, je reviendrai au début de mon rapport, quand je dis: vous arrivez dans une grande entreprise avec vos propres approches d'infrastructure. C'est la même chose avec Yandex. Si auparavant c'était une infrastructure Debian, maintenant c'est différent. La société dispose d'un référentiel monolithique unique depuis un certain temps, où tout le code est progressivement collecté. Un mécanisme de construction, un mécanisme de test distribué, un tas d'outils et tout ce que nous n'utilisons pas encore, mais que nous commençons à utiliser, a été créé autour de lui. Autrement dit, nos projets python tombent également dans ce référentiel. Nous essayons de collecter avec les mêmes outils. Mais comme ces outils d'un référentiel unique, affûtés principalement en C ++, Java et Go, il y a là une particularité.
La particularité est la suivante. Si maintenant le résultat de la construction de notre projet est le moteur Docker, où se trouve simplement notre code source avec toutes les dépendances, alors nous arrivons à la conclusion que le résultat de la construction de notre projet ne sera qu'un binaire. Juste un binar, dans lequel il y a un interpréteur python, un code et nos lapins python et toutes les autres dépendances nécessaires, ils sont liés statiquement.
On pense que vous pouvez venir, lancer ce binaire sur n'importe quel service Linux avec une architecture compatible et cela fonctionnera. Et c'est vrai.
Cela semble un peu non natif. La plupart des gens de la communauté python ne le font pas, et je suis sûr que vous ne le faites pas. Cela a ses avantages et ses inconvénients. Avantages:
- . , , , , , . , . , , . .
- , , , . , , . , . , checkout , , . .
- , .
Et, bien sûr, il y a un inconvénient: un écosystème fermé. Un étranger doit être plongé dans la façon dont tout cela fonctionne, pour dire comment cela fonctionne. Il doit essayer et alors seulement devient efficace. Nous ne sommes qu'au début de ce chemin. Peut-être que si je viens à cette conférence dans un an ou deux, je pourrais vous dire comment nous sommes passés par cette transformation. Mais maintenant, nous sommes optimistes quant à l'avenir et sommes soumis à certaines règles internes de l'entreprise, et nous l'aimons plutôt que non, car nous obtenons beaucoup de petits pains internes.
conclusions
Ils sont plus philosophiques. Le rapport lui-même n’est pas tant technique que philosophique.
- L'évolution est inévitable. Si vous créez un service et qu'il dure longtemps, alors vous le ferez évoluer, faire évoluer son infrastructure, la façon dont vous le développez.
- . , , , .
- . , Django, . , . , , , Django - , . , .
- Python-. , , -. , , . , , , , , : , . , .
Le sujet est très vaste. Je vous ai très brièvement expliqué comment et ce que nous faisons, comment Python a évolué dans notre pays. Vous pouvez prendre chaque époque, prendre chaque élément sur la diapositive et le démonter plus profondément. Et cela suffit également pour 40 minutes - vous pouvez parler très longtemps des dépendances, de l'open source interne et de l'infrastructure. J'ai donné une vue d'ensemble. Si un sujet est très populaire, je peux le couvrir lors des prochaines rencontres ou conférences. Remercier.