 Dialogue 2020 , une conférence scientifique internationale sur la linguistique computationnelle et les technologies intelligentes, a récemment pris fin . Pour la première fois, la Phystech School of Applied Mathematics and Informatics (FPMI) du MIPT est devenue partenaire de la conférence . Traditionnellement, l'un des événements clés du Dialogue est l' évaluation du dialogue , une compétition entre les développeurs de systèmes automatiques d'analyse de textes linguistiques. Nous avons déjà parlé sur Habré des tâches que les participants au concours ont résolues l'année dernière, par exemple, générer des titres et trouver les mots manquants dans le texte. Aujourd'hui, nous avons discuté avec les lauréats de deux pistes de l'évaluation du dialogue de cette année - Vladislav Korzun et Daniil Anastasyev - pour expliquer pourquoi ils ont décidé de participer à des concours technologiques, quels problèmes et de quelle manière ils ont résolu, ce qui intéresse les gars, où ils ont étudié et ce qu'ils prévoient de faire à l'avenir. Bienvenue au chat!
Dialogue 2020 , une conférence scientifique internationale sur la linguistique computationnelle et les technologies intelligentes, a récemment pris fin . Pour la première fois, la Phystech School of Applied Mathematics and Informatics (FPMI) du MIPT est devenue partenaire de la conférence . Traditionnellement, l'un des événements clés du Dialogue est l' évaluation du dialogue , une compétition entre les développeurs de systèmes automatiques d'analyse de textes linguistiques. Nous avons déjà parlé sur Habré des tâches que les participants au concours ont résolues l'année dernière, par exemple, générer des titres et trouver les mots manquants dans le texte. Aujourd'hui, nous avons discuté avec les lauréats de deux pistes de l'évaluation du dialogue de cette année - Vladislav Korzun et Daniil Anastasyev - pour expliquer pourquoi ils ont décidé de participer à des concours technologiques, quels problèmes et de quelle manière ils ont résolu, ce qui intéresse les gars, où ils ont étudié et ce qu'ils prévoient de faire à l'avenir. Bienvenue au chat!
Vladislav Korzun, vainqueur de la piste Dialogue Evaluation RuREBus-2020

Que faire?
Je suis développeur chez NLP Advanced Research Group chez ABBYY. Nous résolvons actuellement une tâche d'apprentissage unique pour l'extraction d'entités. Autrement dit, avec un petit échantillon de formation (5 à 10 documents), vous devez apprendre à extraire des entités spécifiques de documents similaires. Pour cela, nous allons utiliser les sorties du modèle NER entraîné sur les types d'entités standards (Personne, Lieu, Organisation) comme fonctionnalités pour résoudre ce problème. Nous prévoyons également d'utiliser un modèle de langage spécial, qui a été formé sur des documents similaires dans le domaine de notre tâche.
Quelles tâches avez-vous résolues chez Dialogue Evaluation?
Lors du Dialogue, j'ai participé au concours RuREBus dédié à l'extraction d'entités et de relations à partir de documents spécifiques du corpus du ministère du Développement économique. Ce cas était très différent des cas utilisés, par exemple, dans le concours Conll . Premièrement, les types d'entités eux-mêmes n'étaient pas standard (personnes, lieux, organisations), parmi lesquels il y avait même des actions de fond et sans nom. Deuxièmement, les textes eux-mêmes n'étaient pas des ensembles de phrases vérifiées, mais de vrais documents, qui conduisaient à diverses listes, en-têtes et même tableaux. En conséquence, les principales difficultés sont apparues précisément avec le traitement des données et non avec la résolution du problème. en fait, il s'agit de tâches classiques de reconnaissance d'entités nommées et d'extraction de relations.
Dans le concours lui-même, il y avait 3 pistes: NER, RE avec des entités données et RE de bout en bout. J'ai essayé de résoudre les deux premiers. Dans la première tâche, j'ai utilisé des approches classiques. Tout d'abord, j'ai essayé d'utiliser un réseau récurrent comme modèle, et des embeddings de mots en texte rapide, des modèles de capitalisation, des embeddings symboliques et des balises POS comme fonctionnalités [1]. Ensuite, j'ai déjà utilisé divers BERT pré-entraînés [2], qui sont bien supérieurs à mon approche précédente. Cependant, cela ne suffisait pas pour prendre la première place de cette piste.
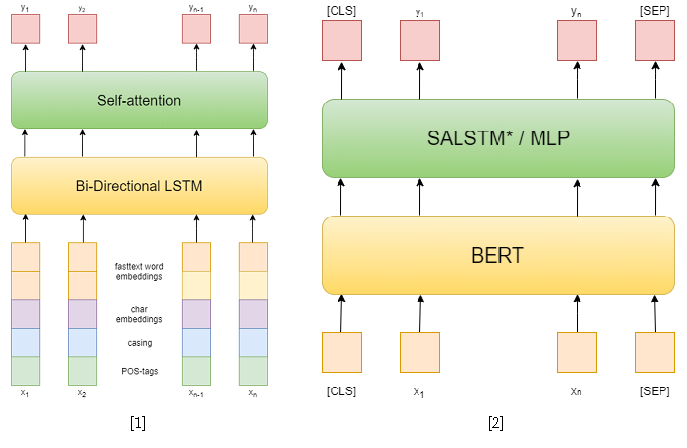
Mais dans la deuxième piste, j'ai réussi. Pour résoudre le problème de l'extraction des relations, je l'ai réduit au problème de la classification des relations, similaire à SemEval 2010 Tâche 8 . Dans ce problème, pour chaque phrase, une paire d'entités est donnée, pour laquelle la relation doit être classée. Et dans une piste, chaque phrase peut contenir autant d'entités que vous le souhaitez, cependant, elle se réduit simplement à la précédente en échantillonnant la phrase pour chaque paire d'entités. Aussi, pendant la formation, j'ai pris des exemples négatifs au hasard pour chaque phrase d'une taille ne dépassant pas le double du nombre de phrases positives afin de réduire l'échantillon d'apprentissage.
Pour résoudre le problème de la classification des relations, j'ai utilisé deux modèles basés sur BERT-e. Dans le premier, j'ai simplement concaténé les sorties BERT avec des embeddings NER, puis j'ai fait la moyenne des caractéristiques de chaque jeton en utilisant Self-attention [3]. L'une des meilleures solutions pour SemEval 2010 Task 8 - R-BERT [4] a été prise comme deuxième modèle. L'essence de cette approche est la suivante: insérer des jetons spéciaux avant et après chaque entité, faire la moyenne des sorties BERT pour les jetons de chaque entité, combiner les vecteurs résultants avec la sortie correspondant au jeton CLS et classer le vecteur d'entités résultant. En conséquence, ce modèle a pris la première place dans la piste. Les résultats du concours sont disponibles ici .
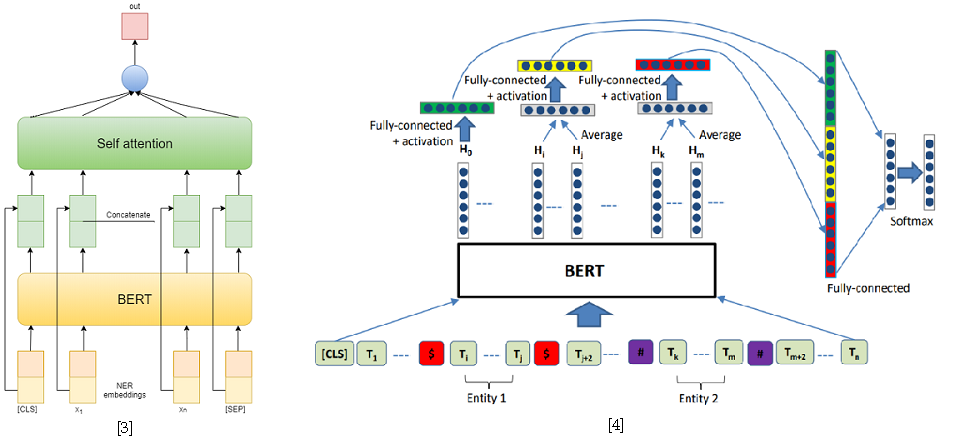
[4] Wu, S., He, Y. (2019, novembre). Enrichissement du modèle de langage pré-entraîné avec des informations d'entité pour la classification des relations. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management ( pp. 2361-2364 ).
Qu'est-ce qui vous a semblé le plus difficile dans ces tâches?
Le plus problématique était le traitement de l'affaire. Les tâches elles-mêmes sont aussi classiques que possible, pour leur solution, il existe déjà des frameworks prêts à l'emploi, par exemple AllenNLP. Mais la réponse doit être donnée en économisant les portées de jetons, donc je ne pouvais pas simplement utiliser le pipeline prêt à l'emploi sans écrire beaucoup de code supplémentaire. J'ai donc décidé d'écrire l'intégralité du pipeline en pure PyTorch pour ne rien rater. Bien que j'aie encore utilisé certains modules d'AllenNLP.
Il y avait aussi de nombreuses phrases assez longues dans le corpus, ce qui causait des inconvénients lors de l'enseignement de gros transformateurs, par exemple, BERT, car ils deviennent exigeants en mémoire vidéo avec une longueur de phrase croissante. Cependant, la plupart de ces phrases sont des énumérations délimitées par des points-virgules et peuvent être séparées par ce caractère. J'ai simplement divisé les offres restantes par le nombre maximum de jetons.
Avez-vous déjà participé à Dialogue et aux pistes?
L'année dernière, j'ai parlé avec ma maîtrise lors de la session étudiante.
Pourquoi avez-vous décidé de participer au concours cette année?
A cette époque, je résolvais simplement le problème de l'extraction des relations, mais pour un corps différent. J'ai essayé d'utiliser une approche différente basée sur l'analyse des arbres. Le chemin dans l'arborescence d'une entité à une autre a été utilisé comme entrée. Mais cette approche n'a malheureusement pas donné de bons résultats, même si elle était au niveau de l'approche basée sur des réseaux récurrents, utilisant des plongements de jetons et d'autres caractéristiques comme signes, comme la longueur du chemin d'un jeton à une racine ou l'une des entités de l'arbre syntaxique. l'analyse, ainsi que la position relative des entités.
Dans ce concours, j'ai décidé de participer, car j'avais déjà quelques bases pour résoudre des problèmes similaires. Et pourquoi ne pas les appliquer dans un concours et se faire publier? Cela n'a pas été aussi simple que je le pensais, mais c'est plutôt dû à des problèmes d'interaction avec les coques. En conséquence, pour moi, c'était plus une tâche d'ingénierie qu'une tâche de recherche.
Avez-vous participé à d'autres compétitions?
Dans le même temps, notre équipe a participé à SemEval . Ilya Dimov était principalement impliqué dans la tâche, je viens de suggérer quelques idées. Il y avait la tâche de classer la propagande: la portée du texte était choisie et il fallait le classer. J'ai suggéré d'utiliser l'approche R-BERT, c'est-à-dire de sélectionner cette entité en jetons, d'insérer un jeton spécial devant et après elle, et de faire la moyenne des sorties. En conséquence, cela a donné une petite augmentation. Telle est la valeur scientifique: pour résoudre le problème, nous avons utilisé un modèle conçu pour quelque chose de complètement différent.
J'ai également participé au hackathon ABBYY, à ACM icpc - compétition de programmation sportive dans les premières années. Nous ne sommes pas allés très loin à l'époque, mais c'était amusant. Ces concours sont très différents de ceux présentés au Dialogue, où il y a suffisamment de temps pour mettre en œuvre et tester calmement plusieurs approches. Dans les hackathons, il faut tout faire rapidement, il n'y a pas de temps pour se détendre, il n'y a pas de thé. Mais c'est la beauté de ces événements - ils ont une atmosphère spécifique.
Quels sont les problèmes les plus intéressants que vous avez résolus lors de compétitions ou au travail?
Il y a bientôt un concours de génération de gestes GENEA et je vais y aller. Je pense que ce sera intéressant. Il s'agit d'un atelier à ACM - Conférence internationale sur les agents virtuels intelligents . Dans ce concours, il est proposé de générer des gestes pour un modèle humain 3D basé sur la voix. J'ai parlé cette année au Dialogue avec un sujet similaire, fait un petit tour d'horizon des approches du problème de la génération automatique d'expressions faciales et de gestes à partir de la voix. J'ai besoin d'acquérir de l'expérience, car je dois encore défendre ma thèse sur un sujet similaire. Je veux essayer de créer un agent virtuel de lecture, avec des expressions faciales, des gestes et bien sûr, de la voix. Les approches actuelles de la synthèse vocale permettent de générer une parole assez réaliste à partir d'un texte, tandis que les approches de génération de gestes permettent de générer des gestes à partir de la voix. Alors pourquoi ne pas combiner ces approches.
Au fait, où étudiez-vous maintenant?
Je suis étudiant de troisième cycle au Département de linguistique informatique d'ABBYY à la Phystech School of Applied Mathematics and Informatics du MIPT . Je soutiendrai ma thèse dans deux ans.
Quelles connaissances et compétences acquises à l'université vous aident maintenant?
Curieusement, les mathématiques. Même si je n'intègre pas tous les jours et que je ne multiplie pas les matrices dans ma tête, les mathématiques enseignent la pensée analytique et la capacité de tout comprendre. Après tout, tout examen comprend la preuve de théorèmes, et essayer de les apprendre est inutile, mais se comprendre et se prouver, ne se souvenir que d'une idée, est possible. Nous avons également eu de bons cours de programmation, où nous avons appris à un bas niveau pour comprendre comment tout fonctionne, analysé divers algorithmes et structures de données. Et maintenant, ce ne sera plus un problème de gérer un nouveau framework ou même un langage de programmation. Oui, bien sûr, nous avons eu des cours en machine learning, et en PNL en particulier, mais quand même, il me semble que les compétences de base sont plus importantes.
Daniil Anastasyev, lauréat de la piste Dialogue Evaluation GramEval-2020

Que faire?
Je développe l'assistant vocal "Alice", je travaille dans la recherche de groupe de sens. Nous analysons les demandes qui arrivent à Alice. Un exemple standard de requête est "Quel temps fera-t-il demain à Moscou?" Vous devez comprendre qu'il s'agit d'une demande sur la météo, que la demande concerne l'emplacement (Moscou) et qu'il y a une indication de l'heure (demain).
Parlez-nous du problème que vous avez résolu cette année sur l'une des pistes d'évaluation du dialogue.
Je faisais une tâche très proche de ce que fait ABBYY. Il était nécessaire de construire un modèle qui analyserait la phrase, ferait une analyse morphologique et syntaxique et définirait les lemmes. C'est très similaire à ce qu'ils font à l'école. Il m'a fallu environ 5 jours pour construire le modèle.

Le modèle étudié en russe normal, mais, comme vous pouvez le voir, il fonctionne également dans la langue qui était dans le problème.
Cela ressemble-t-il à ce que vous faites au travail?
Probablement pas. Ici, vous devez comprendre que cette tâche en elle-même n'a pas beaucoup de sens - elle est résolue comme une sous-tâche dans le cadre de la résolution d'un problème commercial important. Ainsi, par exemple, chez ABBYY, où j'ai déjà travaillé, l'analyse morpho-syntaxique est la première étape de la résolution du problème de l'extraction d'informations. Dans le cadre de mes tâches actuelles, je n'ai pas besoin de telles analyses. Cependant, l'expérience supplémentaire de travailler avec des modèles de langage pré-formés tels que BERT me semble certainement utile pour mon travail. En général, c'était la principale motivation de la participation - je ne voulais pas gagner, mais pratiquer et acquérir des compétences utiles. De plus, mon diplôme était en partie lié au sujet du problème.
Avez-vous déjà participé à l'évaluation du dialogue?
Participé à la piste MorphoRuEval-2017 la 5ème année et a également pris la 1ère place. Ensuite, il a fallu définir uniquement la morphologie et les lemmes, sans relations syntaxiques.
Est-il réaliste d'appliquer votre modèle à d'autres tâches dès maintenant?
Oui, mon modèle peut être utilisé pour d'autres tâches - j'ai publié tout le code source. Je prévois de publier le code en utilisant un modèle plus léger et plus rapide mais moins précis. En théorie, si quelqu'un le souhaite, le modèle actuel peut être utilisé. Le problème est que ce sera trop gros et trop lent pour la plupart. En compétition, personne ne se soucie de la vitesse, il est intéressant d'obtenir la meilleure qualité possible, mais en pratique, tout est généralement l'inverse. Par conséquent, le principal avantage de ces grands modèles est de savoir quelle qualité est la plus réalisable afin de comprendre ce que vous sacrifiez.
Pourquoi participez-vous à l'évaluation du dialogue et à d'autres concours similaires?
Les hackathons et ces compétitions ne sont pas directement liés à mon travail, mais c'est quand même une expérience enrichissante. Par exemple, lorsque j'ai participé au hackathon AI Journey l'année dernière, j'ai appris certaines choses que j'ai ensuite utilisées dans mon travail. La tâche consistait à apprendre à réussir l'examen en langue russe, c'est-à-dire à résoudre des tests et à rédiger un essai. Il est clair que tout cela n'a pas grand-chose à voir avec le travail. Mais la possibilité de créer et de former rapidement un modèle qui résout certains problèmes est très utile. Au fait, mon équipe et moi avons remporté la première place.
Quelle éducation avez-vous reçue et qu'avez-vous fait après l'université?
Il est diplômé de la licence et du master du département de linguistique informatique ABBYY de l'Institut de physique et de technologie de Moscou, diplômé en 2018. Il a également étudié à la School of Data Analysis (SHAD). Quand est venu le temps de choisir un département de base en 2ème année, l'essentiel du groupe s'est tourné vers les départements d'ABBYY - linguistique computationnelle ou reconnaissance d'images et traitement de texte. Dans le programme de premier cycle, on nous a appris à bien programmer - il y avait des cours très utiles. Dès la 4e année, j'ai travaillé chez ABBYY pendant 2,5 ans. D'abord, dans le groupe de morphologie, j'ai ensuite été engagé dans des tâches liées aux modèles de langage pour améliorer la reconnaissance de texte dans ABBYY FineReader. J'ai écrit du code, formé des modèles, maintenant je fais la même chose, mais pour un produit complètement différent.
Que faites-vous de votre temps libre?
J'aime lire des livres. Selon la saison, j'essaye de courir ou de skier. J'adore la photographie en voyage.
Avez-vous des plans ou des objectifs pour les cinq prochaines années, disons?
5 ans est un horizon de planification trop éloigné. Je n'ai même pas 5 ans d'expérience professionnelle. Au cours des 5 dernières années, beaucoup de choses ont changé, maintenant il y a clairement un sentiment différent de la vie. J'ai du mal à imaginer ce qui peut changer d'autre, mais il y a des idées pour obtenir un doctorat à l'étranger.
Quels conseils pouvez-vous donner aux jeunes développeurs engagés dans la linguistique computationnelle et au début de leur parcours?
Il est préférable de s'entraîner, d'essayer et de concourir. Les débutants complets peuvent suivre l'un des nombreux cours: par exemple, de SHAD , DeepPavlov, ou même le mien , que j'ai déjà enseigné à ABBYY.
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .