Alors que des langages tels que Python et R deviennent de plus en plus populaires pour la science des données, C et C ++ peuvent être des choix solides pour résoudre efficacement les problèmes en science des données. Dans cet article, nous utiliserons C99 et C ++ 11 pour écrire un programme qui fonctionne avec le quatuor Anscombe, dont je parlerai ensuite.
J'ai écrit sur ma motivation à apprendre constamment les langues dans un article sur Python et GNU Octave qui vaut la peine d'être lu. Tous les programmes sont destinés à la ligne de commande et non à une interface utilisateur graphique (GUI). Des exemples complets sont disponibles dans le référentiel polyglot_fit.
Défi de programmation
Le programme que vous allez écrire dans cette série:
- Lit les données d'un fichier CSV
- Interpole les données avec une ligne droite (c'est-à-dire f (x) = m ⋅ x + q).
- Écrit le résultat dans un fichier image
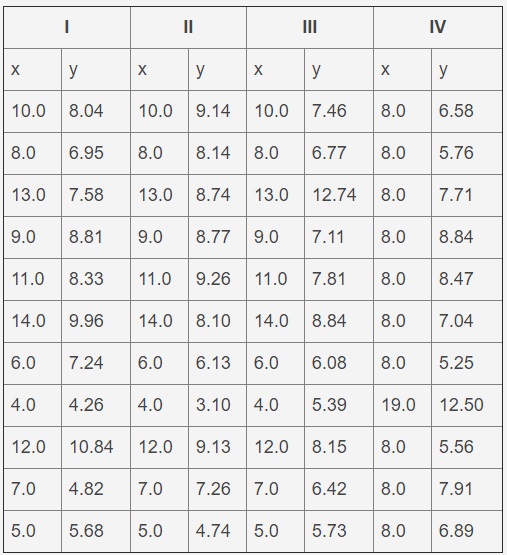
C'est un défi commun auquel sont confrontés de nombreux scientifiques des données. Un exemple de données est le premier ensemble du quatuor Anscombe, présenté dans le tableau ci-dessous. Il s'agit d'un ensemble de données artificiellement construites qui donnent les mêmes résultats lorsqu'elles sont ajustées à une ligne droite, mais leurs graphiques sont très différents. Un fichier de données est un fichier texte avec des onglets pour séparer les colonnes et plusieurs lignes qui forment un en-tête. Ce problème utilisera uniquement le premier ensemble (c'est-à-dire les deux premières colonnes).
Quatuor Anscombe
Solution en C
C est un langage de programmation à usage général et est l'un des langages les plus utilisés aujourd'hui (tel que mesuré par l' indice TIOBE , le classement des langages de programmation RedMonk , l' indice de popularité des langages de programmation et la recherche GitHub ). C'est un vieux langage (il a été créé vers 1973) et de nombreux programmes à succès y ont été écrits (par exemple, le noyau Linux et Git). Ce langage est également aussi proche que possible du fonctionnement interne d'un ordinateur, car il est utilisé pour la gestion directe de la mémoire. C'est un langage compilé , donc le code source doit être traduit en code machine par le compilateur . Le sienla bibliothèque standard est petite et légère, donc d'autres bibliothèques ont été développées pour fournir la fonctionnalité manquante.
C'est le langage que j'utilise le plus pour l' écrasement des nombres , principalement en raison de ses performances. Je trouve cela assez fastidieux à utiliser car il nécessite beaucoup de code standard , mais il est bien pris en charge dans une variété d'environnements. La norme C99 est une révision récente qui ajoute des fonctionnalités intéressantes et est bien prise en charge par les compilateurs.
Je couvrirai les prérequis pour la programmation en C et C ++ afin que les utilisateurs débutants et expérimentés puissent utiliser ces langages.
Installation
Le développement C99 nécessite un compilateur. J'utilise habituellement Clang , mais GCC , un autre compilateur open source à part entière , fera l'affaire . Pour adapter les données, j'ai décidé d'utiliser la bibliothèque scientifique GNU . Pour le traçage, je n'ai trouvé aucune bibliothèque raisonnable et donc ce programme repose sur un programme externe: Gnuplot . L'exemple utilise également une structure de données dynamique pour stocker les données, qui est définie dans la Berkeley Software Distribution (BSD ).
L'installation sur Fedora est très simple:
sudo dnf install clang gnuplot gsl gsl-develCommentaires sur le code
En C99, les commentaires sont formatés en ajoutant // au début de la ligne, et le reste de la ligne sera ignoré par l'interpréteur. Tout ce qui se trouve entre / * et * / est également ignoré.
// .
/* */Bibliothèques requises
Les bibliothèques se composent de deux parties:
- Fichier d'en-tête contenant la description des fonctions
- Fichier source contenant des définitions de fonction
Les fichiers d'en-tête sont inclus dans le code source et le code source des bibliothèques est lié à l'exécutable. Par conséquent, les fichiers d'en-tête sont requis pour cet exemple:
// -
#include <stdio.h>
//
#include <stdlib.h>
//
#include <string.h>
// "" BSD
#include <sys/queue.h>
// GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>Fonction principale
En C, le programme doit être à l'intérieur d'une fonction spéciale appelée main () :
int main(void) {
...
}Ici, vous pouvez remarquer une différence par rapport à Python, qui a été discuté dans le dernier tutoriel, car dans le cas de Python, le code qu'il trouve dans les fichiers source s'exécutera.
Définition des variables
En C, les variables doivent être déclarées avant d'être utilisées et elles doivent être associées à un type. Chaque fois que vous souhaitez utiliser une variable, vous devez décider des données à y stocker. Vous pouvez également indiquer si vous allez utiliser la variable comme valeur constante, ce qui n'est pas obligatoire, mais le compilateur peut bénéficier de ces informations. Exemple du programme fit_C99.c dans le référentiel:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;Les tableaux en C ne sont pas dynamiques dans le sens où leur longueur doit être déterminée à l'avance (c'est-à-dire avant la compilation):
int data_array[1024];Comme vous ne savez généralement pas combien de points de données se trouvent dans le fichier, utilisez une seule liste liée . C'est une structure de données dynamique qui peut croître indéfiniment. Heureusement, BSD fournit des listes chaînées individuelles . Voici un exemple de définition:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);Cet exemple définit une liste data_point , constituée de valeurs structurées contenant à la fois des valeurs x et y . La syntaxe est assez complexe, mais intuitive, et une description détaillée serait trop verbeuse.
Imprimer
Pour imprimer sur le terminal, vous pouvez utiliser la fonction printf () , qui fonctionne comme la fonction printf () d'Octave (décrite dans le premier article):
printf("#### C99 ####\n");La fonction printf () n'ajoute pas automatiquement une nouvelle ligne à la fin de la ligne imprimée, vous devez donc l'ajouter vous-même. Le premier argument est une chaîne, qui peut contenir des informations sur le format d'autres arguments pouvant être passés à la fonction, par exemple:
printf("Slope: %f\n", slope);Lecture des données
Vient maintenant la partie la plus délicate ... Il existe plusieurs bibliothèques pour analyser les fichiers CSV en C, mais aucune n'est suffisamment stable ou populaire pour être dans le référentiel de paquets Fedora. Au lieu d'ajouter une dépendance pour ce tutoriel, j'ai décidé d'écrire cette partie moi-même. Encore une fois, ce serait trop verbeux pour entrer dans les détails, donc je n'expliquerai que l'idée générale. Certaines lignes du code source seront ignorées par souci de concision, mais vous pouvez trouver un exemple complet dans le référentiel.
Ouvrez d'abord le fichier d'entrée:
FILE* input_file = fopen(input_file_name, "r");Ensuite, lisez le fichier ligne par ligne jusqu'à ce qu'une erreur se produise ou jusqu'à la fin du fichier:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}La fonction getline () est un joli ajout récent au standard POSIX.1-2008 . Il peut lire une ligne entière dans un fichier et s'occuper d'allouer la mémoire nécessaire. Chaque ligne est ensuite divisée en jetons à l'aide de la fonction strtok () . En regardant le jeton, sélectionnez les colonnes dont vous avez besoin:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}Enfin, avec les valeurs x et y sélectionnées, ajoutez un nouveau point à la liste:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);La fonction malloc () alloue (réserve) dynamiquement une certaine quantité de mémoire permanente pour un nouveau point.
Données d'ajustement
La fonction d'interpolation linéaire de GSL gsl_fit_linear () accepte des tableaux réguliers en entrée. Par conséquent, comme vous ne pouvez pas connaître à l'avance la taille des tableaux créés, vous devez leur allouer manuellement de la mémoire:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);Parcourez ensuite la liste pour stocker les données pertinentes dans les tableaux:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}Maintenant que vous avez terminé avec la liste, nettoyez la commande. Toujours libérer de la mémoire allouée manuellement pour éviter les fuites de mémoire . Les fuites de mémoire sont mauvaises, mauvaises et encore mauvaises. Chaque fois que la mémoire n'est pas libérée, le nain de jardin perd la tête:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}Enfin, enfin (!), Vous pouvez ajuster vos données:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);Tracer un graphique
Pour créer un graphique, vous devez utiliser un programme externe. Conservez donc la fonction de montage dans un fichier externe:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}La commande de traçage Gnuplot ressemble à ceci:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'résultats
Avant d'exécuter le programme, vous devez le compiler:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99Cette commande indique au compilateur d'utiliser le standard C99, de lire le fichier fit_C99.c, de charger les bibliothèques gsl et gslcblas et d'enregistrer le résultat dans le fichier fit_C99. La sortie résultante sur la ligne de commande:
#### C99 ####
: 0.500091
: 3.000091
: 0.816421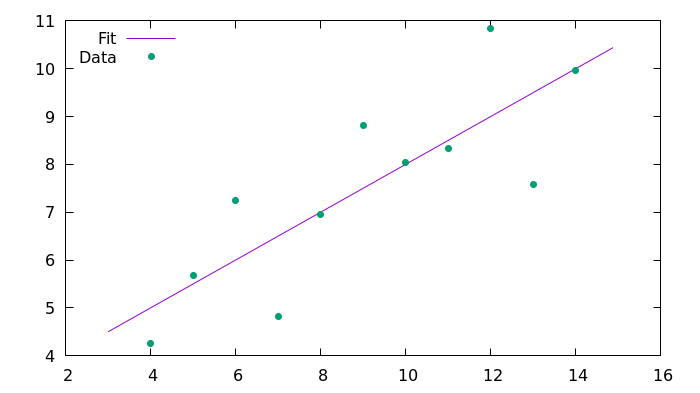
Voici l'image résultante générée à l'aide de Gnuplot.
Solution C ++ 11
C ++ est un langage de programmation à usage général qui est également l'un des langages les plus utilisés aujourd'hui. Il a été créé comme successeur du langage C (en 1983) avec un accent sur la programmation orientée objet (POO). C ++ est généralement considéré comme un sur-ensemble de C, donc un programme C doit être compilé avec un compilateur C ++. Ce n'est pas toujours le cas, car il existe des cas extrêmes où ils se comportent différemment. D'après mon expérience, C ++ nécessite moins de code standard que C, mais sa syntaxe est plus complexe si vous souhaitez concevoir des objets. Le standard C ++ 11 est une révision récente qui ajoute des fonctionnalités intéressantes plus ou moins supportées par les compilateurs.
Puisque C ++ est à peu près compatible C, je me concentrerai simplement sur les différences entre les deux. Si je ne décris pas une section dans cette partie, cela signifie qu'elle est la même que dans C.
Installation
Les dépendances pour C ++ sont les mêmes que pour l'exemple C. Sur Fedora, exécutez la commande suivante:
sudo dnf install clang gnuplot gsl gsl-develBibliothèques requises
Les bibliothèques fonctionnent de la même manière qu'en C, mais les directives d'inclusion sont légèrement différentes:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}Comme les bibliothèques GSL sont écrites en C, le compilateur doit être informé de cette fonctionnalité.
Définition des variables
C ++ prend en charge plus de types de données (classes) que C, par exemple, le type chaîne, qui a beaucoup plus de fonctionnalités que son homologue C. Mettez à jour vos définitions de variables en conséquence:
const std::string input_file_name("anscombe.csv");Pour les objets structurés tels que les chaînes, vous pouvez définir une variable sans utiliser le signe = .
Imprimer
Vous pouvez utiliser la fonction printf () , mais il est plus courant d'utiliser cout . Utilisez l'opérateur << pour spécifier la chaîne (ou les objets) que vous souhaitez imprimer avec cout :
std::cout << "#### C++11 ####" << std::endl;
...
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Lecture des données
Le circuit est le même qu'avant. Le fichier est ouvert et lu ligne par ligne, mais avec une syntaxe différente:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}Les jetons de chaîne sont récupérés par la même fonction que dans l'exemple C99. Utilisez deux vecteurs au lieu des tableaux C standard . Les vecteurs sont une extension des tableaux C dans la bibliothèque standard C ++ pour gérer dynamiquement la mémoire sans appeler malloc () :
std::vector<double> x;
std::vector<double> y;
// x y
x.emplace_back(value);
y.emplace_back(value);Données d'ajustement
Pour ajuster les données en C ++, vous n'avez pas à vous soucier des listes, car les vecteurs sont garantis d'avoir une mémoire séquentielle. Vous pouvez directement transmettre des pointeurs aux tampons vectoriels aux fonctions d'ajustement:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Tracer un graphique
Le tracé se fait de la même manière qu'auparavant. Ecrire dans un fichier:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();Utilisez ensuite Gnuplot pour tracer le graphique.
résultats
Avant d'exécuter le programme, il doit être compilé avec une commande similaire:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11Résultat résultant sur la ligne de commande:
#### C++11 ####
: 0.500091
: 3.00009
: 0.816421Et voici l'image résultante, générée avec Gnuplot.
Conclusion
Cet article fournit des exemples d'ajustement et de traçage de données en C99 et C ++ 11. Étant donné que C ++ est largement compatible avec C, cet article utilise les similitudes pour écrire un deuxième exemple. Dans certains aspects, C ++ est plus facile à utiliser, car il soulage partiellement le fardeau de la gestion explicite de la mémoire, mais sa syntaxe est plus complexe, car il introduit la possibilité d'écrire des classes pour la POO. Cependant, vous pouvez également écrire en C en utilisant les techniques de POO, puisque la POO est un style de programmation, il peut être utilisé dans n'importe quel langage. Il existe d'excellents exemples de POO en C, tels que les bibliothèques GObject et Jansson .
Je préfère utiliser C99 pour travailler avec des nombres en raison de sa syntaxe plus simple et de sa prise en charge plus large. Jusqu'à récemment, C ++ 11 n'était pas largement pris en charge et j'ai essayé d'éviter les aspérités des versions précédentes. Pour les logiciels plus complexes, C ++ peut être un bon choix.
Utilisez-vous C ou C ++ pour la science des données? Partagez votre expérience dans les commentaires.

Apprenez comment obtenir une profession recherchée à partir de zéro ou augmenter vos compétences et votre salaire en suivant des cours en ligne payés par SkillFactory:
- Cours d'apprentissage automatique (12 semaines)
- Apprendre la science des données à partir de zéro (12 mois)
- Profession analytique avec n'importe quel niveau de départ (9 mois)
- Cours Python pour le développement Web (9 mois)