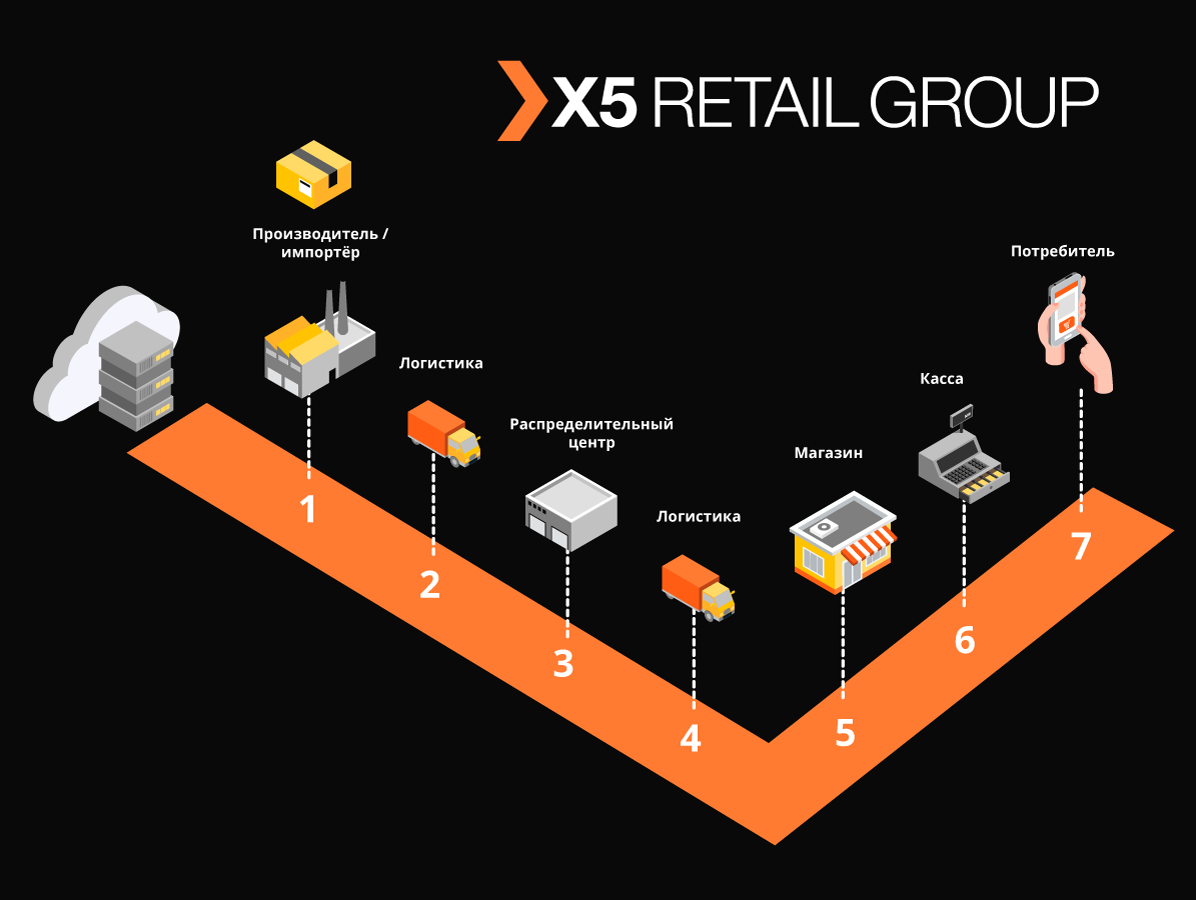
Dans X5, le système qui suivra les marchandises étiquetées et échangera des données avec le gouvernement et les fournisseurs s'appelle «Markus». Disons dans l'ordre comment et qui l'a développé, quel type de pile technologique il possède et pourquoi nous avons quelque chose dont nous pouvons être fiers.
Real HighLoad
«Markus» résout de nombreux problèmes, dont le principal est l'interaction d'intégration entre les systèmes d'information X5 et le système d'information d'état des produits labellisés (SIG MP) pour suivre le mouvement des produits labellisés. La plate-forme stocke également tous les codes de marquage que nous avons reçus et l'historique complet du mouvement de ces codes à travers les objets, aide à éliminer le re-tri des produits marqués. Dans l'exemple des produits du tabac, qui ont été inclus dans les premiers groupes de produits étiquetés, un seul camion de cigarettes contient environ 600 000 paquets, chacun ayant son propre code unique. Et la tâche de notre système est de suivre et de vérifier la légalité des mouvements de chacun de ces emballages entre les entrepôts et les magasins, et in fine de vérifier la recevabilité de leur mise en œuvre auprès du client final. Et nous enregistrons les transactions en espèces environ 125 000 par heure,et il est également nécessaire d'enregistrer comment chacun de ces paquets est entré dans le magasin. Ainsi, compte tenu de tous les mouvements entre objets, on attend des dizaines de milliards d'enregistrements par an.
Équipe M
Bien que "Markus" soit considéré comme un projet au sein du X5, il est mis en œuvre selon l'approche produit. L'équipe travaille sur Scrum. Le projet a débuté l'été dernier, mais les premiers résultats ne sont arrivés qu'en octobre - leur propre équipe a été entièrement assemblée, l'architecture du système a été développée et l'équipement a été acheté. Aujourd'hui, l'équipe compte 16 personnes, dont six sont engagées dans le développement du backend et du frontend, trois dans l'analyse du système. Six autres personnes sont impliquées dans les tests manuels, de charge, automatisés et de support produit. De plus, nous avons un spécialiste SRE.
Le code de notre équipe n'est pas seulement écrit par les développeurs, presque tous les gars savent programmer et écrire des autotests, charger des scripts et des scripts d'automatisation. Nous y accordons une attention particulière, car même le support produit nécessite un haut niveau d'automatisation. Nous essayons toujours de conseiller et d'aider nos collègues qui n'ont pas programmé auparavant, à donner quelques petites tâches au travail.
Dans le cadre de la pandémie de coronavirus, nous avons transféré toute l'équipe vers le travail à distance, la disponibilité de tous les outils de gestion du développement, le workflow intégré dans Jira et GitLab nous ont permis de franchir facilement cette étape. Les mois passés dans un endroit éloigné ont montré que la productivité de l'équipe n'en souffrait pas, pour beaucoup le confort de travail a augmenté, le seul problème est qu'il n'y a pas assez de communication en direct.
Réunion d'équipe avant la distance

Réunions à distance
Pile technologique de solution
Le référentiel standard et l'outil CI / CD pour X5 est GitLab. Nous l'utilisons pour le stockage de code, les tests continus, le déploiement sur des serveurs de test et de production. Nous utilisons également la pratique de la révision du code, quand au moins 2 collègues doivent approuver les modifications apportées par le développeur au code. Les analyseurs de code statique SonarQube et JaCoCo nous aident à garder le code propre et à fournir le niveau requis de couverture de test unitaire. Toutes les modifications du code doivent passer par ces vérifications. Tous les scripts de test exécutés manuellement sont ensuite automatisés.
Pour une exécution réussie des processus commerciaux par «Markus», nous avons dû résoudre un certain nombre de problèmes technologiques, chacun dans l'ordre.
Tâche 1. Nécessité d'une évolutivité horizontale du système
Pour résoudre ce problème, nous avons choisi une approche microservice de l'architecture. Dans le même temps, il était très important de comprendre les domaines de responsabilité des services. Nous avons essayé de les diviser en opérations commerciales, en tenant compte des spécificités des processus. Par exemple, la réception dans un entrepôt n'est pas une opération très fréquente, mais très volumineuse, au cours de laquelle il est nécessaire d'obtenir le plus rapidement possible du régulateur de l'État des informations sur les unités de marchandises reçues, dont le nombre en une livraison atteint 600000, vérifier l'admissibilité de l'acceptation de ce produit à l'entrepôt et donner tout informations nécessaires pour le système d'automatisation de l'entrepôt. Mais les expéditions depuis les entrepôts ont une intensité beaucoup plus élevée, mais fonctionnent en même temps avec de petites quantités de données.
Nous implémentons tous les services sur le principe sans état et essayons même de diviser les opérations internes en étapes, en utilisant ce que nous appelons les self-topics Kafka. C'est à ce moment qu'un microservice s'envoie un message à lui-même, ce qui permet d'équilibrer la charge pour des opérations plus gourmandes en ressources et simplifie la maintenance du produit, mais plus à ce sujet plus tard.
Nous avons décidé de séparer les modules d'interaction avec les systèmes externes en services séparés. Cela a permis de résoudre le problème des API fréquemment changeantes des systèmes externes, sans pratiquement aucun impact sur les services dotés de fonctionnalités métier.
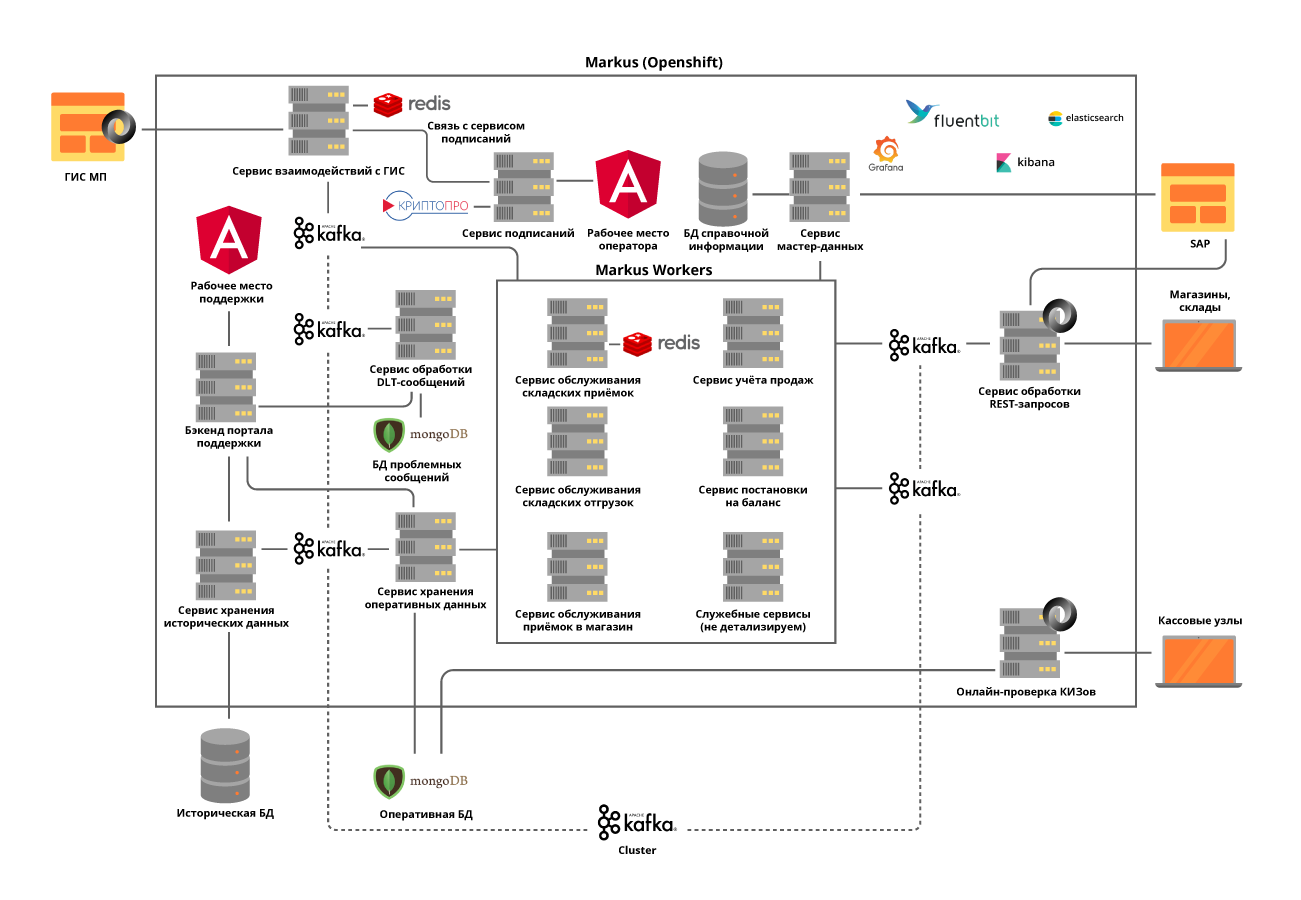
Tous les microservices sont déployés dans le cluster OpenShift, ce qui résout à la fois le problème de la mise à l'échelle de chaque microservice et nous permet de ne pas utiliser d'outils tiers de découverte de services.
Tâche 2. La nécessité de maintenir une charge élevée et un échange de données très intensif entre les services de la plateforme: seulement lors de la phase de lancement du projet, environ 600 opérations par seconde sont effectuées. Nous nous attendons à ce que cette valeur augmente jusqu'à 5000 op / s à mesure que les objets de trading se connectent à notre plateforme.
Cette tâche a été résolue en déployant un cluster Kafka et en abandonnant presque complètement la communication synchrone entre les microservices de la plateforme. Cela nécessite une analyse très minutieuse de la configuration système requise, car toutes les opérations ne peuvent pas être asynchrones. Dans le même temps, nous transmettons non seulement les événements via le courtier, mais également toutes les informations commerciales requises dans le message. Ainsi, la taille du message peut aller jusqu'à plusieurs centaines de kilo-octets. La limitation du volume de messages dans Kafka nous oblige à prédire avec précision la taille des messages, et, si nécessaire, nous les divisons, mais la division est logique, associée aux opérations commerciales.
Par exemple, les marchandises arrivées dans la voiture, nous les divisons en boîtes. Pour les opérations synchrones, des microservices séparés sont alloués et des tests de charge rigoureux sont effectués. L'utilisation de Kafka a posé un autre défi pour nous: tester notre service avec l'intégration de Kafka rend tous nos tests unitaires asynchrones. Nous avons résolu ce problème en écrivant nos propres méthodes utilitaires à l'aide de Embedded Kafka Broker. Cela n'élimine pas la nécessité d'écrire des tests unitaires pour des méthodes individuelles, mais nous préférons tester des cas complexes en utilisant Kafka.
Nous avons accordé beaucoup d'attention au traçage des journaux afin que leur TraceId ne soit pas perdu lorsque des exceptions sont levées pendant le fonctionnement des services ou lorsque vous travaillez avec Kafka batch. Et s'il n'y avait pas de questions spéciales avec le premier, alors dans le second cas, nous sommes obligés d'écrire dans le journal tous les TraceId avec lesquels le lot est venu et d'en sélectionner un pour continuer le traçage. Ensuite, lors de la recherche du TraceId initial, l'utilisateur trouvera facilement avec quelle trace la trace a continué.
Objectif 3. La nécessité de stocker une grande quantité de données: plus d'un milliard d'étiquettes par an pour le seul tabac sont envoyées à X5. Ils nécessitent un accès constant et rapide. Au total, le système doit traiter environ 10 milliards d'enregistrements sur l'historique du mouvement de ces marchandises marquées.
Pour résoudre le troisième problème, la base de données MongoDB NoSQL a été choisie. Nous avons construit un fragment de 5 nœuds et dans chaque nœud un jeu de répliques de 3 serveurs. Cela vous permet de mettre à l'échelle le système horizontalement, d'ajouter de nouveaux serveurs au cluster et de garantir sa tolérance aux pannes. Ici, nous avons été confrontés à un autre problème: garantir la transactionnalité dans le cluster mongo, en tenant compte de l'utilisation de microservices évolutifs horizontalement. Par exemple, l'une des tâches de notre système est de détecter les tentatives de revente de marchandises avec les mêmes codes de marquage. Ici, les superpositions apparaissent avec des scans erronés ou avec des opérations de caisse erronées. Nous avons constaté que de tels doublons peuvent se produire à la fois dans un lot traité dans Kafka et dans deux lots traités en parallèle. Ainsi, la vérification des doublons en interrogeant la base de données n'a rien donné.Pour chacun des microservices, nous avons résolu le problème séparément en fonction de la logique métier de ce service. Par exemple, pour les reçus, nous avons ajouté un chèque à l'intérieur du lot et un traitement séparé pour l'apparition des doublons lors de l'insertion.
Pour que le travail des utilisateurs avec l'historique des opérations n'affecte pas la chose la plus importante - le fonctionnement de nos processus commerciaux, nous avons séparé toutes les données historiques dans un service séparé avec une base de données séparée, qui reçoit également des informations via Kafka. Ainsi, les utilisateurs travaillent avec un service isolé sans affecter les services qui traitent les données sur les opérations en cours.
Tâche 4. Retraitement des files d'attente et surveillance:
Dans les systèmes distribués, des problèmes et des erreurs de disponibilité des bases de données, des files d'attente et des sources de données externes surviennent inévitablement. Dans le cas de Markus, la source de telles erreurs est l'intégration avec des systèmes externes. Il était nécessaire de trouver une solution qui autoriserait des demandes répétées de réponses erronées avec un délai spécifié, mais en même temps ne pas arrêter le traitement des demandes réussies dans la file d'attente principale. Pour cela, le concept dit de «relance par thème» a été choisi. Pour chaque sujet principal, un ou plusieurs sujets de nouvelle tentative sont créés, auxquels des messages erronés sont envoyés, et en même temps, le retard dans le traitement des messages du sujet principal est éliminé. Schéma d'interaction -
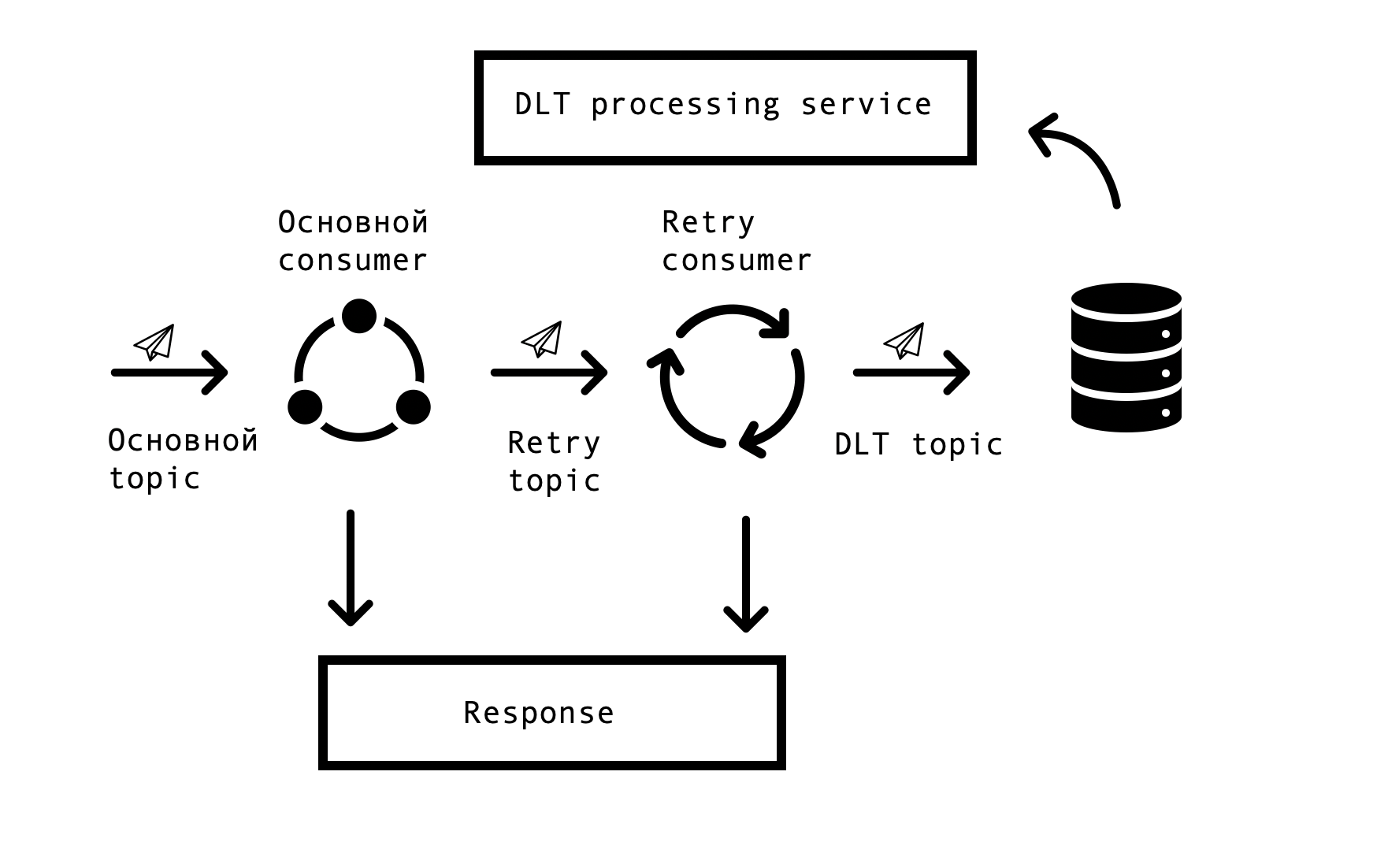
Pour implémenter un tel schéma, nous avions besoin des éléments suivants: intégrer cette solution à Spring et éviter la duplication de code. Dans l'immensité du réseau, nous sommes tombés sur une solution similaire basée sur Spring BeanPostProccessor, mais elle nous a semblé inutilement lourde. Notre équipe a conçu une solution plus simple qui nous permet de nous intégrer dans le cycle de création des consommateurs de Spring et d'ajouter en outre des nouveaux utilisateurs. Nous avons proposé un prototype de notre solution à l'équipe Spring, vous pouvez le voir ici . Le nombre de Retry Consumers et le nombre de tentatives de chaque consommateur sont configurés via les paramètres, en fonction des besoins du processus métier, et pour que tout fonctionne, il ne reste plus qu'à mettre l'annotation org.springframework.kafka.annotation.KafkaListener, qui est familière à tous les développeurs Spring.
Si le message n'a pas pu être traité après toutes les tentatives, il entre dans le DLT (sujet de lettre morte) à l'aide de Spring DeadLetterPublishingRecoverer. À la demande du support, nous avons étendu cette fonctionnalité et créé un service séparé qui vous permet d'afficher les messages, stackTrace, traceId et d'autres informations utiles à leur sujet qui sont entrés dans DLT. De plus, une surveillance et des alertes ont été ajoutées à tous les sujets DLT, et maintenant, en fait, l'apparition d'un message dans un sujet DLT est une raison pour analyser et créer un défaut. C'est très pratique - par le nom du sujet, nous comprenons immédiatement à quelle étape du processus le problème est survenu, ce qui accélère considérablement la recherche de sa cause première.

Plus récemment, nous avons mis en place une interface qui nous permet de renvoyer les messages par notre support, après avoir éliminé leurs causes (par exemple, restaurer l'opérabilité du système externe) et, bien sûr, établir le défaut correspondant pour analyse. C'est là que nos self-topics ont été utiles, afin de ne pas redémarrer une longue chaîne de traitement, vous pouvez la redémarrer à partir de l'étape souhaitée.
Fonctionnement de la plate-forme
La plateforme est déjà en opération productive, chaque jour nous effectuons des livraisons et expéditions, connectons de nouveaux centres de distribution et magasins. Dans le cadre du pilote, le système fonctionne avec les groupes de produits «Tabac» et «Chaussures».
Toute notre équipe est impliquée dans la conduite de projets pilotes, l'analyse des problèmes émergents et la formulation de propositions pour améliorer notre produit, de l'amélioration des logs à l'évolution des processus.
Afin de ne pas répéter nos erreurs, tous les cas trouvés lors du pilote sont reflétés dans des tests automatisés. La présence d'un grand nombre d'autotests et de tests unitaires permet de réaliser des tests de régression et de mettre un hotfix en quelques heures seulement.
Maintenant, nous continuons à développer et à améliorer notre plateforme, et sommes constamment confrontés à de nouveaux défis. Si vous êtes intéressé, nous vous présenterons nos solutions dans les articles suivants.