Les cascades sont magnifiques par leur nature même, il n'est donc pas surprenant que les ingénieurs soient un peu obsédés par elles. L'ancienne norme DOD-STD-2167A recommandait d'utiliser le modèle en cascade, et mes connaissances en ingénierie héritées étaient basées sur le modèle Phase-Gate , qui, à mon avis, est assez similaire au modèle de cascade. D'un autre côté, ceux d'entre nous qui ont étudié l'informatique à l'université savent probablement que le modèle de la cascade est en quelque sorte un anti-pattern . Nos amis de la tour d'ivoire académique nous disent non, non, AgileC'est la voie du succès et il semble que l'industrie ait prouvé que cette affirmation était vraie.
Alors, que devrait choisir un développeur entre le modèle de cascade vieillissant et le nouveau modèle Agile? L'équation change-t-elle lorsqu'il s'agit de développer des algorithmes? Ou un logiciel critique de sécurité?
Comme d'habitude dans la vie, la réponse se situe quelque part entre les deux.
Hybride, en spirale et en V
Le développement hybride est la réponse qui se situe au milieu. Là où le modèle en cascade ne permet pas de revenir en arrière et de modifier les exigences, le modèle hybride le permet. Et là où Agile a des problèmes avec la conception initiale, le développement hybride lui laisse de la place. De plus, le développement hybride vise à réduire le nombre de défauts dans le produit final, ce que nous souhaitons probablement lors de la conception d'algorithmes pour des applications critiques pour la sécurité.
Ça sonne bien, mais quelle est son efficacité?
Pour répondre à cette question, nous misons sur le développement hybride tout en travaillant sur l'algorithme de localisation NDT.. La localisation est un élément essentiel de toute pile autonome qui dépasse le simple contrôle réactif. Si vous ne me croyez pas ou si vous n'êtes pas familier avec la localisation, je vous recommande vivement de jeter un œil à certains des documents de conception qui ont été développés au cours de ce processus.
Alors, qu'est-ce que le développement hybride en un mot? De mon point de vue amateur, je dirais qu'il s'agit d'un modèle idéalisé en forme de V ou en spirale . Vous planifiez, concevez, mettez en œuvre et testez, puis parcourez tout le processus en fonction des leçons apprises et des nouvelles connaissances que vous avez acquises pendant cette période.
Utilisation pratique
Plus précisément, nous, avec le groupe de travail NDT d'Autoware.Auto, avons terminé notre première descente dans la cascade gauche du modèle en V (c'est-à-dire effectué la première itération de la phase de conception) en préparation de l' Autoware Hackathon à Londres (organisé par Parkopedia !). Notre premier passage dans la phase de conception comprenait les étapes suivantes:
- Revue de littérature
- Vue d'ensemble des implémentations existantes
- Conception de composants, cas d'utilisation et exigences de haut niveau
- Analyse des défauts
- Définition des métriques
- Architecture et conception d'API
Vous pouvez jeter un œil à chacun des documents résultants si vous êtes intéressé par quelque chose de similaire, mais pour le reste de cet article, je vais essayer de décomposer certains d'entre eux, et également d'expliquer ce qui et pourquoi il en est résulté à chacune de ces étapes.
Revue de la littérature et des implémentations existantes
La première étape de tout effort décent (c'est ainsi que je classerais une implémentation NDT) est de voir ce que d'autres personnes ont fait. Les humains sont, après tout, des êtres sociaux, et toutes nos réalisations reposent sur les épaules de géants.
Allusions mises à part, il y a deux domaines importants à considérer lorsque l'on considère «l'art du passé»: la littérature académique et les réalisations fonctionnelles.
Il est toujours utile de regarder sur quoi travaillaient les étudiants diplômés pauvres au milieu de la famine. Au mieux, vous constaterez qu'il existe un algorithme parfaitement excellent que vous pouvez implémenter au lieu du vôtre. Dans le pire des cas, vous comprendrez l'espace et la variation des solutions (ce qui peut aider l'architecture de l'information), et vous pourrez également en apprendre davantage sur certains des fondements théoriques de l'algorithme (et donc sur les invariants à surveiller ).
D'un autre côté, il est tout aussi utile de regarder ce que font les autres - après tout, il est toujours plus facile de commencer à faire quelque chose avec une invite de démarrage. Non seulement vous pouvez emprunter gratuitement de bonnes idées architecturales, mais vous pouvez également découvrir certaines des suppositions et astuces dont vous pourriez avoir besoin pour que l'algorithme fonctionne dans la pratique (et vous pourriez même être en mesure de les intégrer pleinement dans votre architecture).
À partir de notre revue de la littérature CND , nous avons rassemblé les informations utiles suivantes:
- La famille d'algorithmes NDT a plusieurs variantes:
- P2D
- D2D
- Limité
- Sémantique - Il existe des tonnes de trucs sales qui peuvent être utilisés pour améliorer les performances de l'algorithme.
- NDT est généralement comparé à ICP
- NDT est légèrement plus rapide et légèrement plus fiable.
- NDT fonctionne de manière fiable (a un taux de réussite élevé) dans une zone définie
Rien d'incroyable, mais ces informations peuvent être enregistrées pour une utilisation ultérieure, à la fois dans la conception et la mise en œuvre.
De même, de notre aperçu des implémentations existantes, nous avons vu non seulement des étapes concrètes, mais aussi quelques stratégies d'initialisation intéressantes.
Cas d'utilisation, exigences et mécanismes
Une partie intégrante de tout processus de développement de conception ou de planification d'abord consiste à résoudre le problème que vous essayez de résoudre à un niveau élevé. Au sens large, du point de vue de la sécurité fonctionnelle (qui, je l'avoue, je suis loin d'être un expert), la «vision de haut niveau du problème» s'organise approximativement comme suit:
- Quels cas d' utilisation essayez-vous de résoudre?
- Quelles sont les exigences (ou limitations) pour qu'une solution réponde aux cas d'utilisation ci-dessus?
- Quels mécanismes répondent aux exigences ci-dessus?
Le processus décrit ci-dessus fournit une vue disciplinée de haut niveau du problème et devient progressivement plus détaillé.
Pour avoir une idée de ce à quoi cela pourrait ressembler, vous pouvez jeter un œil au document de projet de localisation de haut niveau que nous avons préparé en vue du développement du NDT. Si vous n'êtes pas d'humeur à lire avant de vous coucher, poursuivez votre lecture.
Cas d'utilisation
J'aime trois approches réfléchies des cas d'utilisation (attention, je ne suis pas un expert en sécurité fonctionnelle):
- Quel est le rôle du composant? (rappelez-vous SOTIF !)
- De quelles manières puis-je saisir une entrée dans un composant? (cas d'utilisation d'entrée, j'aime les appeler en amont)
- Comment puis-je obtenir la sortie? (cas d'utilisation week-end ou top-down)
- Question bonus: Dans quelles architectures système entières ce composant peut-il résider?
En mettant tout cela ensemble, nous avons trouvé ce qui suit:
- La plupart des algorithmes peuvent utiliser la localisation, mais ils peuvent finalement être divisés en saveurs qui fonctionnent à la fois localement et globalement.
- Les algorithmes locaux ont besoin de continuité dans leur histoire de transformation.
- Presque tous les capteurs peuvent être utilisés comme source de données de localisation.
- Nous avons besoin d'un moyen d'initialiser et de dépanner nos méthodes de localisation.
Outre les différents cas d'utilisation auxquels vous pouvez penser, j'aime aussi penser à certains cas d'utilisation courants qui sont très stricts. Pour ce faire, j'ai la possibilité (ou la tâche) d'un voyage hors route complètement sans pilote, en passant par plusieurs tunnels avec du trafic en caravane. Ce cas d'utilisation présente quelques inconvénients, tels que l'accumulation d'erreurs d'odométrie, les erreurs en virgule flottante, les corrections de localisation et les pannes.
Exigences
Le but du développement de cas d'utilisation, en plus de généraliser tout problème que vous essayez de résoudre, est de définir les exigences. Pour qu'un cas d'utilisation ait lieu (ou soit satisfait), il y a probablement des facteurs qui doivent être réalisés ou possibles. En d'autres termes, chaque cas d'utilisation a un ensemble d'exigences spécifiques.
En fin de compte, les exigences générales d'un système de localisation ne sont pas si effrayantes:
- Fournir des transformations pour les algorithmes locaux
- Fournir des transformations pour les algorithmes globaux
- Fournir le mécanisme d'initialisation des algorithmes de localisation relative
- Assurez-vous que les conversions ne débordent pas
- Assurer la conformité REP105
Les spécialistes de la sécurité fonctionnelle qualifiés sont susceptibles de formuler de nombreuses autres exigences. La valeur de ce travail réside dans le fait que nous formulons clairement certaines exigences (ou restrictions) pour notre conception, qui, comme les mécanismes, satisferont nos exigences pour le fonctionnement de l'algorithme.
Mécanismes
Le résultat final de tout type d'analyse devrait être un ensemble pratique de leçons ou de matériel. Si à la suite de l'analyse nous ne pouvons pas utiliser le résultat (même négatif!), Alors l'analyse a été gaspillée.
Dans le cas d'un document d'ingénierie de haut niveau, nous parlons d'un ensemble de mécanismes ou d'une construction qui encapsule ces mécanismes, qui peut convenablement convenir à nos cas d'utilisation.
Cette conception de localisation de haut niveau spécifique a permis l'ensemble des composants logiciels, des interfaces et des comportements qui composent l'architecture du système de localisation. Un schéma de principe simple de l'architecture proposée est présenté ci-dessous.
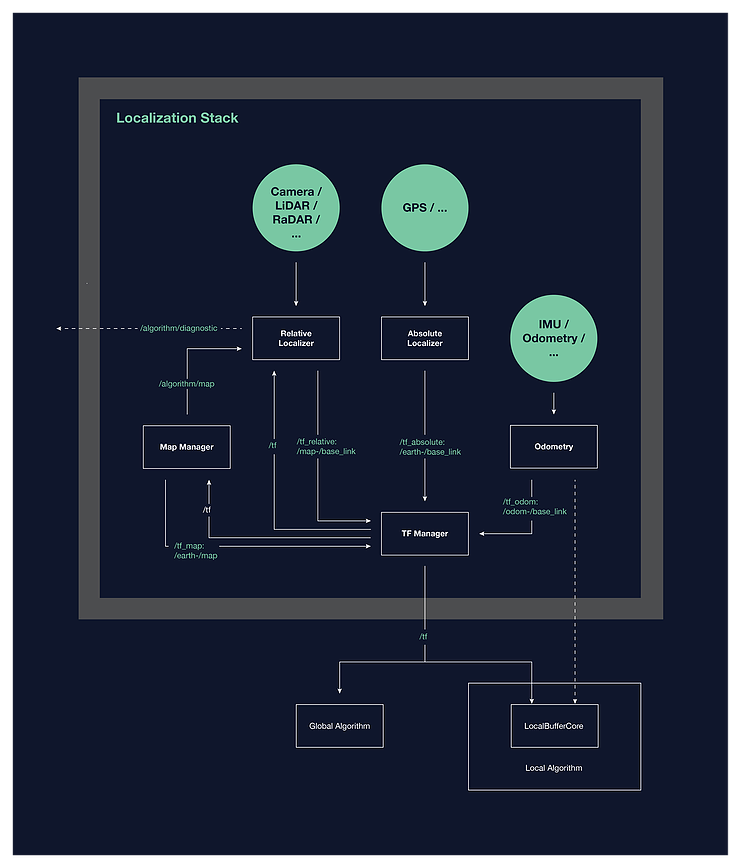
Si vous êtes intéressé par plus d'informations sur l'architecture ou le design, je vous recommande vivement de lirele texte intégral du document .
Analyse des défauts
Puisque nous construisons des composants sur des systèmes critiques pour la sécurité, les pannes sont quelque chose que nous devrions essayer d'éviter, ou du moins atténuer. Par conséquent, avant d'essayer de concevoir ou de construire quoi que ce soit, nous devons au moins savoir comment les choses peuvent se briser.
Lors de l'analyse des défauts, comme dans la plupart des cas, il est utile de regarder un composant sous plusieurs angles. Pour analyser les échecs de l'algorithme NDT, nous l'avons considéré de deux manières différentes: comme un mécanisme de localisation général (relatif), et spécifiquement comme une instance de l'algorithme NDT.
Vu du point de vue du mécanisme de localisation, le mode de défaillance principal est formulé comme suit - "que faire si l'entrée est des données incorrectes?" En effet, du point de vue d'un composant individuel, on ne peut rien faire d'autre que de procéder à une vérification de base de l'adéquation du système. Au niveau du système, vous disposez d'options supplémentaires (par exemple, l'activation des fonctions de sécurité).
En considérant le NDT comme un algorithme isolé, il est utile de faire abstraction de l'algorithme en mettant en évidence le nombre approprié d'aspects. Il sera utile de prêter attention à la version pseudocode de l'algorithme (cela vous aidera, le développeur, à mieux comprendre l'algorithme). Dans ce cas, nous avons analysé l'algorithme en détail et étudié toutes les situations dans lesquelles il peut casser.
Une erreur d'implémentation est un échec parfaitement raisonnable, bien qu'elle puisse être corrigée avec des tests appropriés. Certaines nuances concernant les algorithmes numériques ont commencé à apparaître un peu plus souvent et plus insidieusement. En particulier, il s'agit de trouver des matrices inverses ou, plus généralement, de résoudre des systèmes d'équations linéaires, ce qui peut conduire à des erreurs numériques. Il s'agit d'un scénario de défaillance très sensible et doit être résolu.
Deux autres échecs importants que nous avons également identifiés sont la vérification que certaines expressions ne sont pas illimitées en grandeur (contrôle de précision en virgule flottante) et la vérification que la grandeur ou la taille des entrées est constamment surveillée.
Au total, nous avons élaboré 15 recommandations. Je vous recommande de vous familiariser avec eux.
J'ajouterai également que bien que nous n'ayons pas utilisé cette méthode, l' analyse par arbre de défaillances est un excellent outil pour structurer et quantifier le problème de l'analyse des défaillances.
Définition des métriques
"Ce qui est mesuré est gérable"Malheureusement, en développement professionnel, il ne suffit pas de hausser les épaules et de dire «terminé» lorsque vous êtes fatigué de travailler sur quelque chose. Fondamentalement, tout lot de travaux (qui est encore un développement CND) nécessite des critères d'acceptation, qui doivent être convenus à la fois par le client et le fournisseur (si vous êtes à la fois le client et le vendeur, ignorez cette étape). Toute la jurisprudence existe pour soutenir ces aspects, mais en tant qu'ingénieurs, nous pouvons simplement éliminer les intermédiaires en créant des métriques pour déterminer la disponibilité de nos composants. Après tout, les chiffres sont (pour la plupart) sans ambiguïté et irréfutables.
- Expression populaire des gestionnaires
Même si les critères d'acceptation sont inutiles ou non pertinents, il est toujours agréable d'avoir un ensemble bien défini de mesures qui caractérisent et améliorent la qualité et les performances d'un projet. En fin de compte, ce qui est mesuré est contrôlable.
Pour notre implémentation NDT, nous avons divisé les métriques en quatre grands groupes:
- Mesures générales de la qualité des logiciels
- Mesures communes de qualité du micrologiciel
- Métriques générales de l'algorithme
- Métriques spécifiques à la localisation
Je n'entrerai pas dans les détails car ces métriques sont toutes relativement standard. L'important est que les métriques aient été définies et identifiées pour notre problème spécifique, ce qui est à peu près ce que nous pouvons réaliser en tant que développeurs d'un projet open source. En fin de compte, la barre d'acceptation doit être déterminée en fonction des spécificités du projet par ceux qui déploient le système.
La dernière chose que je vais répéter ici est que si les métriques sont fantastiques à tester, elles ne remplacent pas la vérification de la compréhension de l'implémentation et des exigences d'utilisation.
Architecture et API
Après avoir minutieusement défini le problème que nous essayons de résoudre et acquis une compréhension de l'espace des solutions, nous pouvons enfin nous plonger dans le domaine qui confine à la mise en œuvre. Ces
derniers temps, je suis fan du développement axé sur les tests . Comme la plupart des ingénieurs, j'adore le processus de développement, et l'idée d'écrire des tests me paraissait lourde en premier lieu. Quand j'ai commencé à programmer professionnellement, je suis allé de l'avant et j'ai fait des tests après le développement (même si mes professeurs d'université m'ont dit de faire le contraire). Recherchemontrent que l'écriture de tests avant la mise en œuvre a tendance à entraîner moins de bogues, une couverture de test plus élevée et généralement un meilleur code. Peut-être plus important encore, je pense que le développement piloté par les tests aide à résoudre le gros problème de la mise en œuvre d'algorithmes.
À quoi cela ressemble-t-il?
Au lieu d'introduire un ticket monolithique appelé «Implémenter NDT» (y compris les tests), qui se traduira par plusieurs milliers de lignes de code (qui ne peuvent pas être visualisées et étudiées efficacement), vous pouvez diviser le problème en fragments plus significatifs:
- Ecrire des classes et des méthodes publiques pour un algorithme (créer une architecture)
- Écrivez des tests pour l'algorithme en utilisant l'API publique (ils devraient échouer!).
- Mettre en œuvre la logique de l'algorithme
La première étape consiste donc à écrire l'architecture et l'API de l'algorithme. Je couvrirai les autres étapes dans un autre article.
Bien qu'il existe de nombreux ouvrages sur la façon de «créer une architecture», il me semble que la conception d'une architecture logicielle a quelque chose à voir avec la magie noire. Personnellement, j'aime penser à l'architecture logicielle comme tracer des frontières entre les concepts et essayer de caractériser les degrés de liberté en posant un problème et comment le résoudre en termes de concepts.
Quels sont alors les degrés de liberté en CND?
Une revue de la littérature nous apprend qu'il existe différentes manières de présenter des scans et des observations (par exemple P2D-NDT et D2D-NDT). De même, notre article d'ingénierie de haut niveau indique que nous avons plusieurs façons de représenter la carte (statique et dynamique), c'est donc aussi un degré de liberté. Une littérature plus récente suggère également que le problème d'optimisation peut être revisité. Cependant, en comparant la mise en œuvre pratique et la littérature, nous voyons que même les détails de la solution d'optimisation peuvent différer.
Et la liste continue encore et encore.
Sur la base des résultats de la conception initiale, nous avons retenu les concepts suivants:
- Problèmes d'optimisation
- Solutions d'optimisation
- Vue de numérisation
- Vue de la carte
- Systèmes de génération d'hypothèses initiales
- Algorithme et interfaces de nœud
Avec une certaine subdivision à l'intérieur de ces éléments.
L'attente ultime d'une architecture est qu'elle doit être extensible et maintenable. Si l'architecture que nous proposons est à la hauteur de cet espoir, seul le temps le dira.
Plus loin
Après la conception, bien sûr, il est temps de mettre en œuvre. Travail officiel sur l'implémentation de NDT dans Autoware.Auto a été réalisé lors du hackathon Autoware organisé par Parkopedia .
Il convient de rappeler que ce qui a été présenté dans ce texte n'est que la première étape de la phase de conception. Connuqu'aucun plan de bataille ne résiste à affronter l'ennemi, et il en va de même pour la conception de logiciels. L'échec final du modèle de cascade a été réalisé en supposant que la spécification et la conception étaient parfaites. Il va sans dire que ni la spécification ni la conception ne sont parfaites, et à mesure que la mise en œuvre et les tests progressent, des failles seront découvertes et des modifications devront être apportées aux conceptions et aux documents décrits ici.
Et ça va. En tant qu'ingénieurs, nous ne sommes pas notre travail ou ne nous y identifions pas, et tout ce que nous pouvons essayer de faire est d'itérer et de rechercher des systèmes parfaits. Après tout ce qui a été dit sur le développement du CND, je pense que nous avons fait un bon premier pas.
Abonnez-vous aux chaînes:
@TeslaHackers — Tesla-, Tesla
@AutomotiveRu — ,

: