distorsions cognitives sur les coûts irrécupérables (erreur de coût irrécupérable) sont l'un des nombreux biais cognitifs nuisibles dont les gens deviennent victimes. Cela fait référence à notre tendance à continuer à consacrer du tempset des ressources à une cause perdue, parce que nous avons déjà passé - noyé - tellement de temps à la poursuite. L'erreur de sous-coût s'applique au fait de rester dans un mauvais travail plus longtemps que nous le devrions, de travailler servilement sur un projet même s'il est clair que cela ne fonctionnera pas, et oui, de continuer à utiliser la bibliothèque de traçage ennuyeuse et obsolète - matplotlib - quand il y a des alternatives plus efficaces, interactives et plus engageantes.
Au cours des derniers mois, j'ai réalisé que la seule raison pour laquelle j'utilise matplotlib est à cause des centaines d'heures que j'ai passées à apprendre la syntaxe complexe . Ces complexités conduisent à des heures de frustration à comprendre sur StackOverflow comment formater les dates ou ajouter un deuxième axe Y. Heureusement, c'est le moment idéal pour tracer des graphiques en Python, et après avoir exploré les options , le gagnant clair - en termes de facilité d'utilisation, de documentation et de fonctionnalité - est intrigue . Dans cet article, nous allons plonger directement dans l'intrigue, en apprenant à créer de meilleurs graphiques en moins de temps - souvent avec une seule ligne de code.
Tout le code de cet article est disponible sur GitHub . Tous les graphiques sont interactifs et peuvent être consultés sur NBViewer .
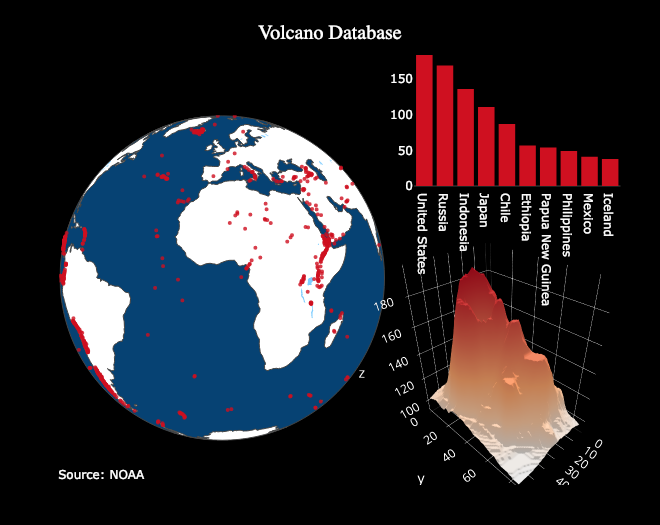
Aperçu de Plotly
Forfait plotly pour Python - une bibliothèque de logiciels open source, construit sur plotly.js , qui, à son tour, est construit sur d3.js . Nous utiliserons un wrapper sur des boutons de manchette appelés complotement conçus pour fonctionner avec le Pandas DataFrame. Ainsi, nos boutons de manchette de pile> plotly> plotly.js> d3.js - cela signifie que nous obtenons de l'efficacité dans la programmation Python avec d'incroyables capacités graphiques interactives de d3 .
( Plotly elle - même est une société graphiqueavec plusieurs produits et outils open source. L'utilisation de la bibliothèque Python est gratuite et nous pouvons créer un nombre illimité de graphiques hors ligne et jusqu'à 25 graphiques en ligne à partager avec le monde .)
Tout le travail de cet article a été effectué dans Jupyter Notebook avec des boutons de manchette et des tracés fonctionnels. hors ligne. Après avoir installé plotly et des boutons de manchette avec,
pip install cufflinks plotly importez les éléments suivants pour les exécuter dans Jupiter:
# Standard plotly imports
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# Using plotly + cufflinks in offline mode
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)Distributions à variable unique: histogrammes et boîtes à moustaches
Tracés à variable unique - un tracé à une dimension est la méthode standard pour démarrer une analyse, et un histogramme est un tracé de transition ( avec quelques problèmes ) pour tracer un diagramme de distribution. Ici, en utilisant mes statistiques d'article moyennes (vous pouvez voir comment obtenir vos propres statistiques ici ou utiliser les miennes ), faisons un histogramme interactif du nombre de claps sur les articles (
dfc'est le dataframe standard de Pandas):
df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')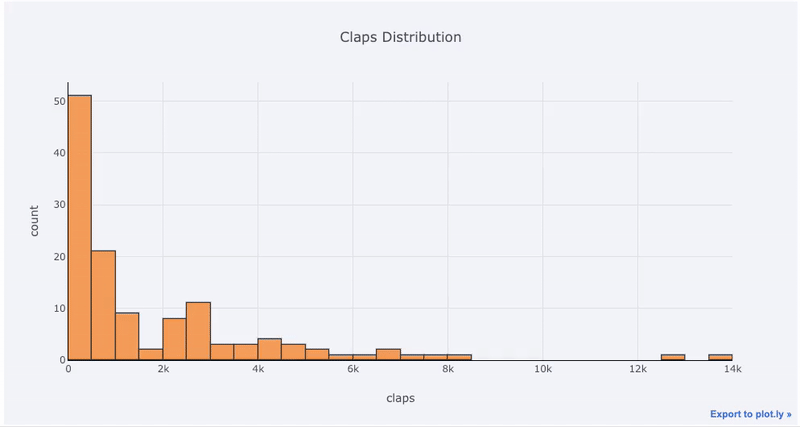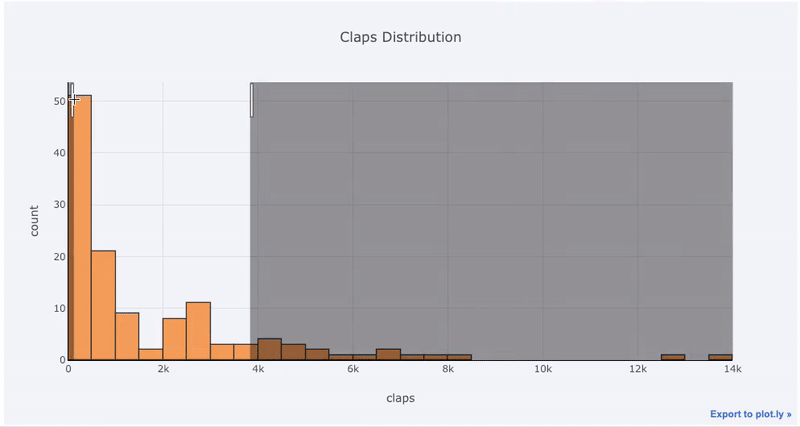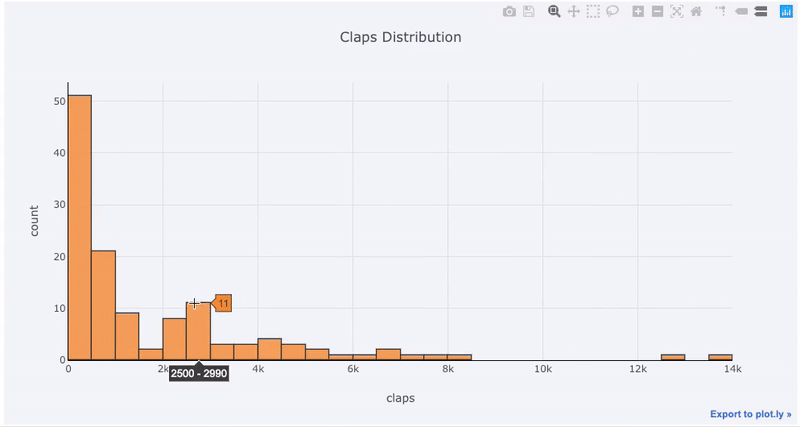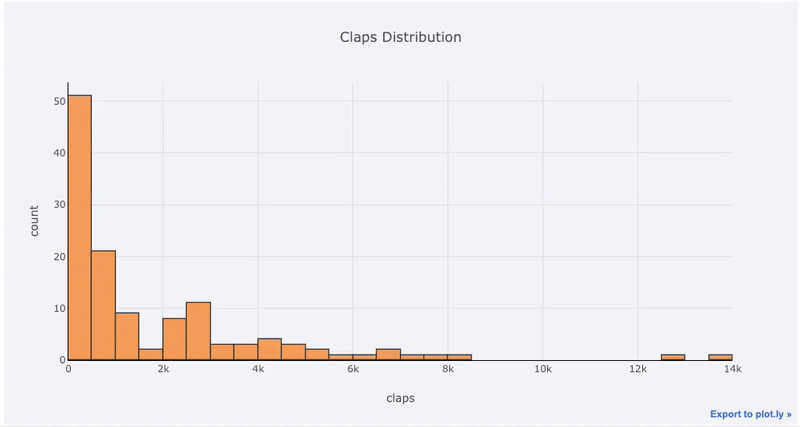
Pour ceux qui en ont l'habitude
matplotlib, tout ce que nous avons à faire est d'ajouter une lettre de plus ( iplotau lieu de plot) et nous obtenons un graphique beaucoup plus beau et interactif! Nous pouvons cliquer sur les données pour obtenir plus d'informations, zoomer sur des parties du graphique et, comme nous le verrons plus tard, sélectionner différentes catégories.
Si nous voulons tracer des histogrammes superposés, c'est tout aussi simple:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')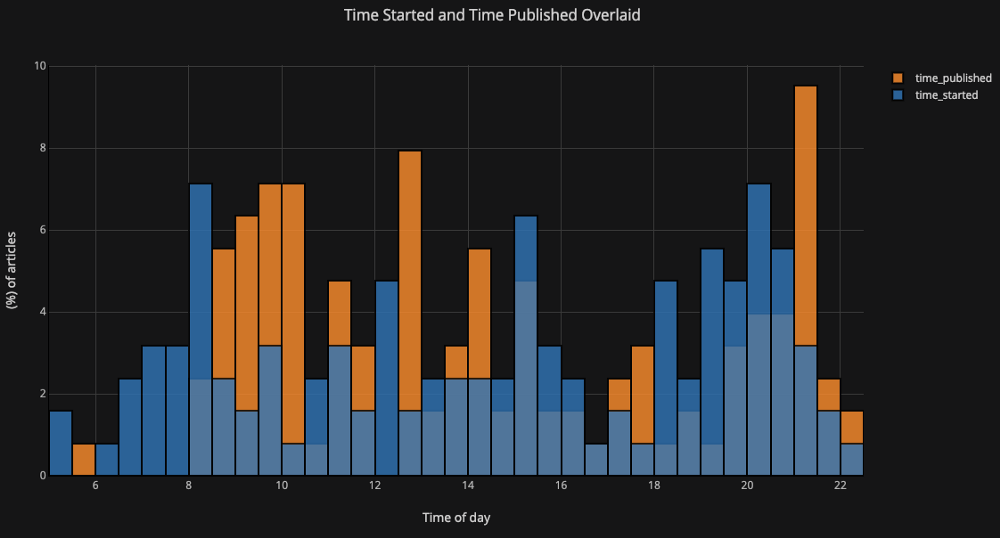
Avec un peu de manipulation
Pandas, nous pouvons faire un barplot:
# Resample to monthly frequency and plot
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')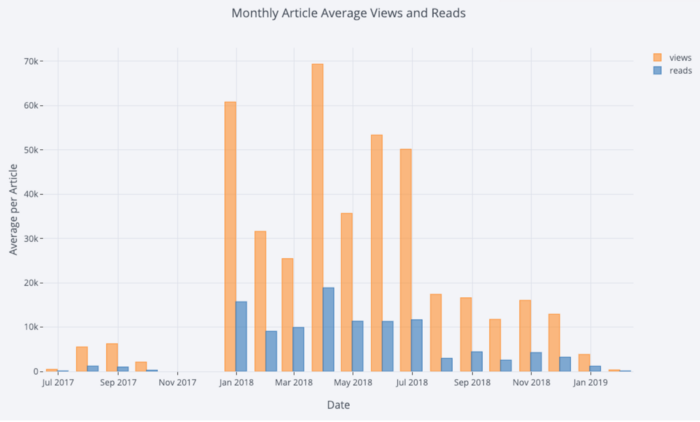
comme nous l'avons vu, nous pouvons combiner la puissance des Pandas avec des boutons de manchette compliqués +. Pour tracer la répartition des fans par publication, nous utilisons
pivot, puis nous traçons:
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')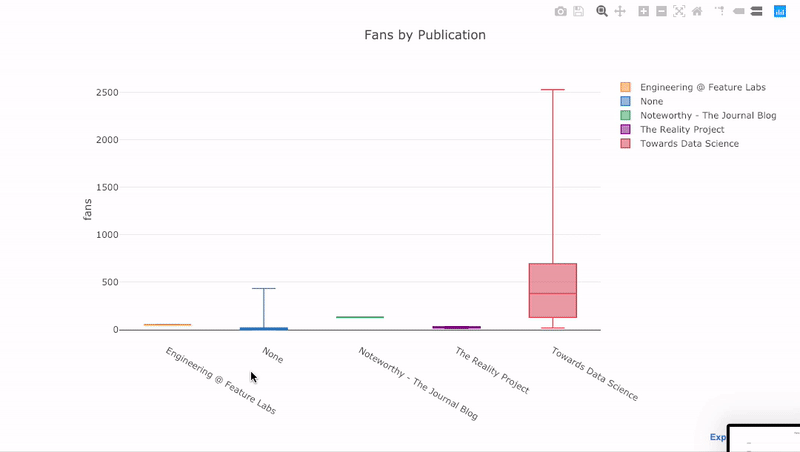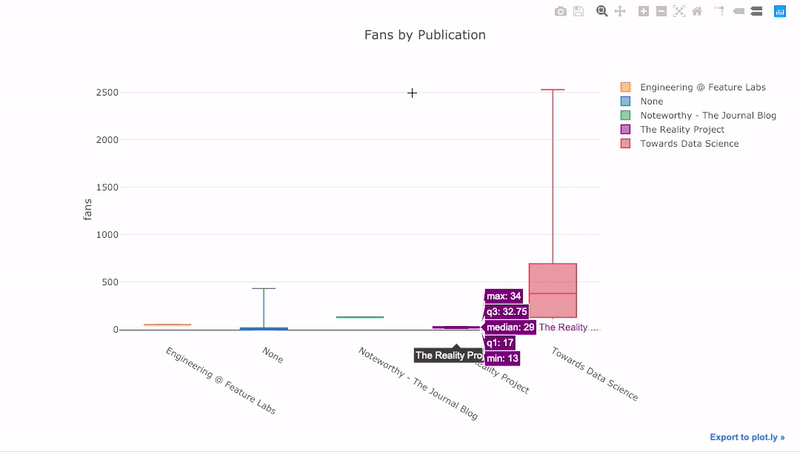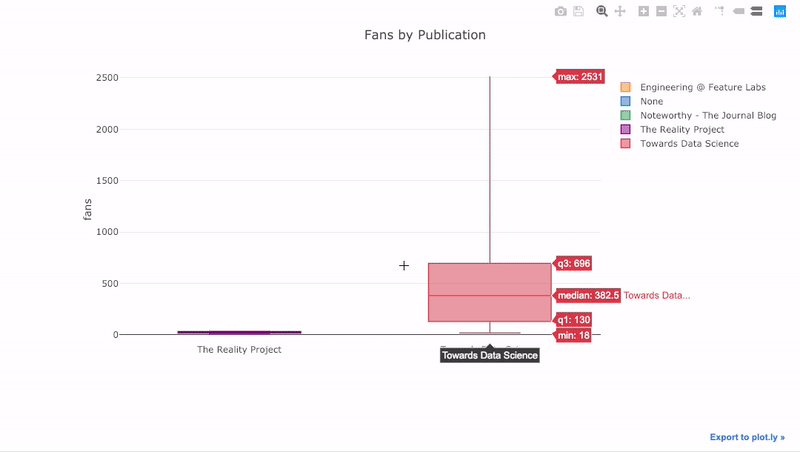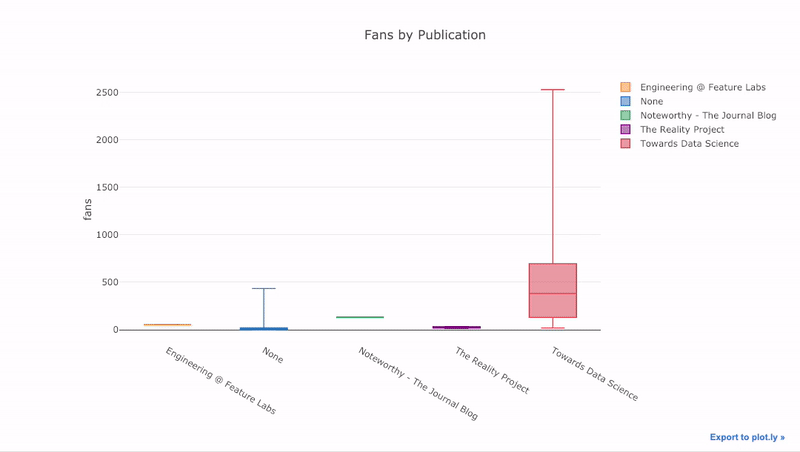
Les avantages de l'interactivité sont que nous pouvons explorer et héberger les données comme bon nous semble. Il y a beaucoup d'informations dans le radeau, et sans la possibilité de voir les chiffres, nous en manquerons la plupart!
Nuage de points
Le nuage de points est au cœur de la plupart des analyses. Cela nous permet de voir l'évolution d'une variable dans le temps, ou la relation entre deux (ou plus) variables.
Des séries chronologiques
La plupart des données réelles ont un élément temporel. Heureusement, les boutons de manchette plotly + ont été conçus pour la visualisation de séries chronologiques. Cadrons les données de mes articles TDS et voyons comment les tendances ont changé.
Create a dataframe of Towards Data Science Articles
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
# Plot read time as a time series
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')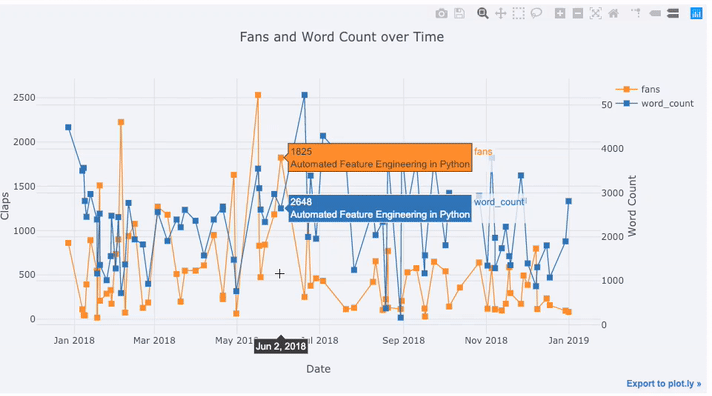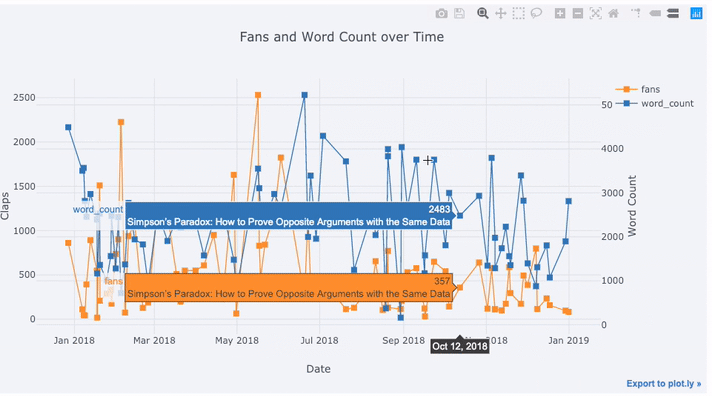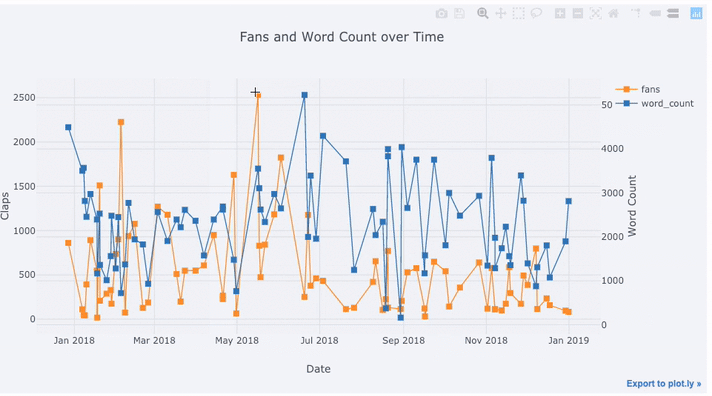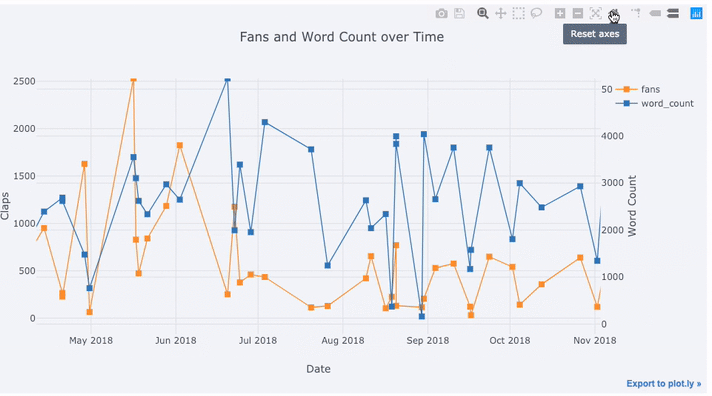
Nous voyons pas mal de choses différentes ici:
- Obtenez automatiquement des séries chronologiques bien formatées sur l'axe des x
- Ajout d'un axe y secondaire car nos variables ont des plages différentes
- Afficher les titres des articles au survol
Pour plus d'informations, nous pouvons également ajouter des annotations textuelles assez facilement:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')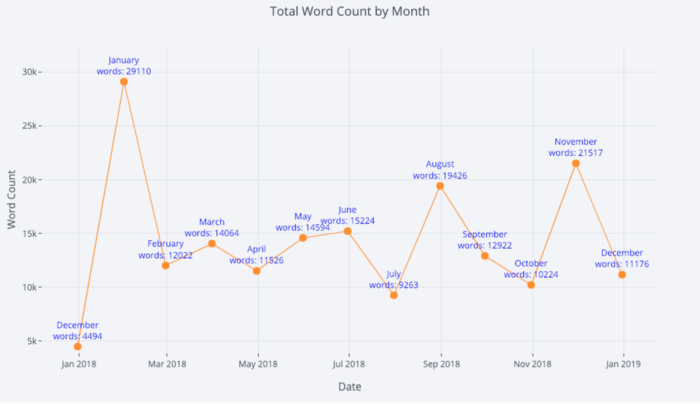
Pour un nuage de points à deux variables coloré avec la troisième variable catégorielle, nous utilisons:
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')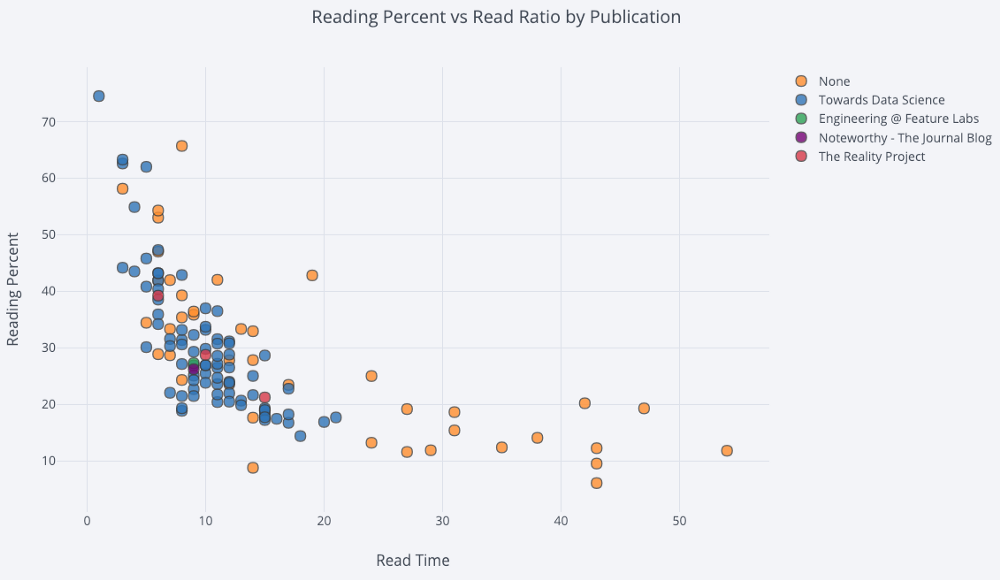
Compliquons un peu les choses en utilisant un axe de journal, spécifié comme une mise en page graphique - (voir la documentation Plotly pour les spécifications de mise en page), et en définissant la taille des bulles d'une variable numérique:
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# Log xaxis
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))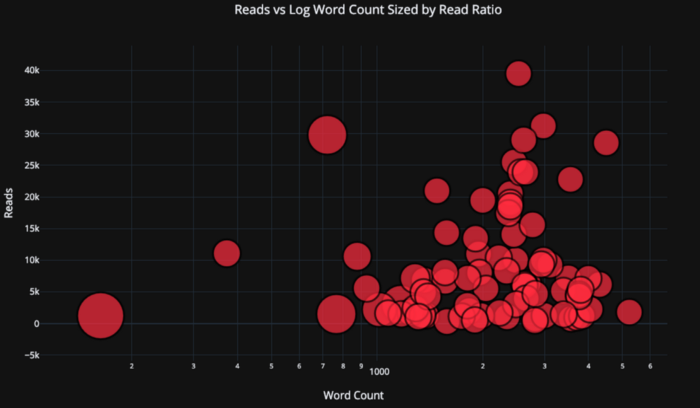
Avec un peu de travail ( voir NoteBook pour plus de détails ), nous pouvons même mettre quatre variables ( non recommandées ) sur un graphique!
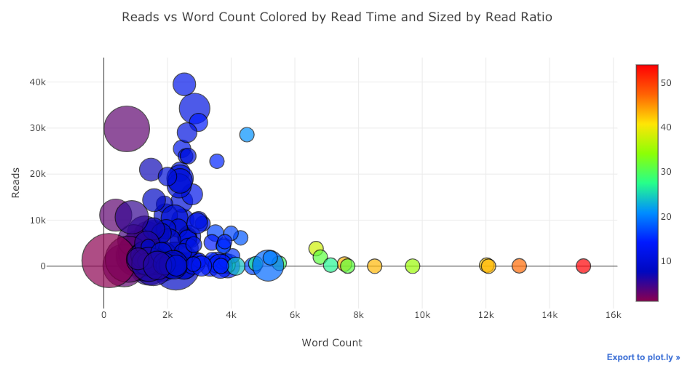
Comme auparavant, nous pouvons combiner des pandas avec des boutons de manchette plotly + pour des graphiques utiles
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))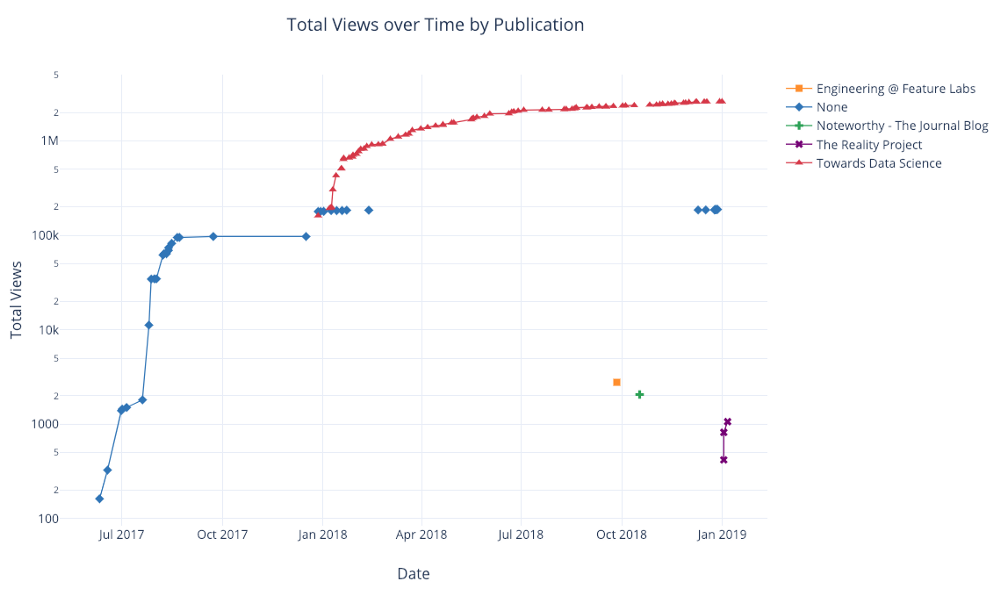
Pour plus d'exemples de fonctionnalités, consultez le bloc-notes ou la documentation . Nous pouvons ajouter des annotations de texte, des lignes de référence et des lignes de meilleur ajustement à nos diagrammes avec une ligne de code et toujours avec toutes les interactions.
Graphiques avancés
Nous passons maintenant à quelques graphiques que vous n'utiliserez probablement pas aussi souvent, mais qui peuvent être assez impressionnants. Nous allons utiliser plotly figure_factory pour faire même ces haffics incroyables en une seule ligne.
Matrice de dispersion
Lorsque nous voulons explorer les relations entre de nombreuses variables, la matrice de dispersion (également appelée splom) est une excellente option:
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')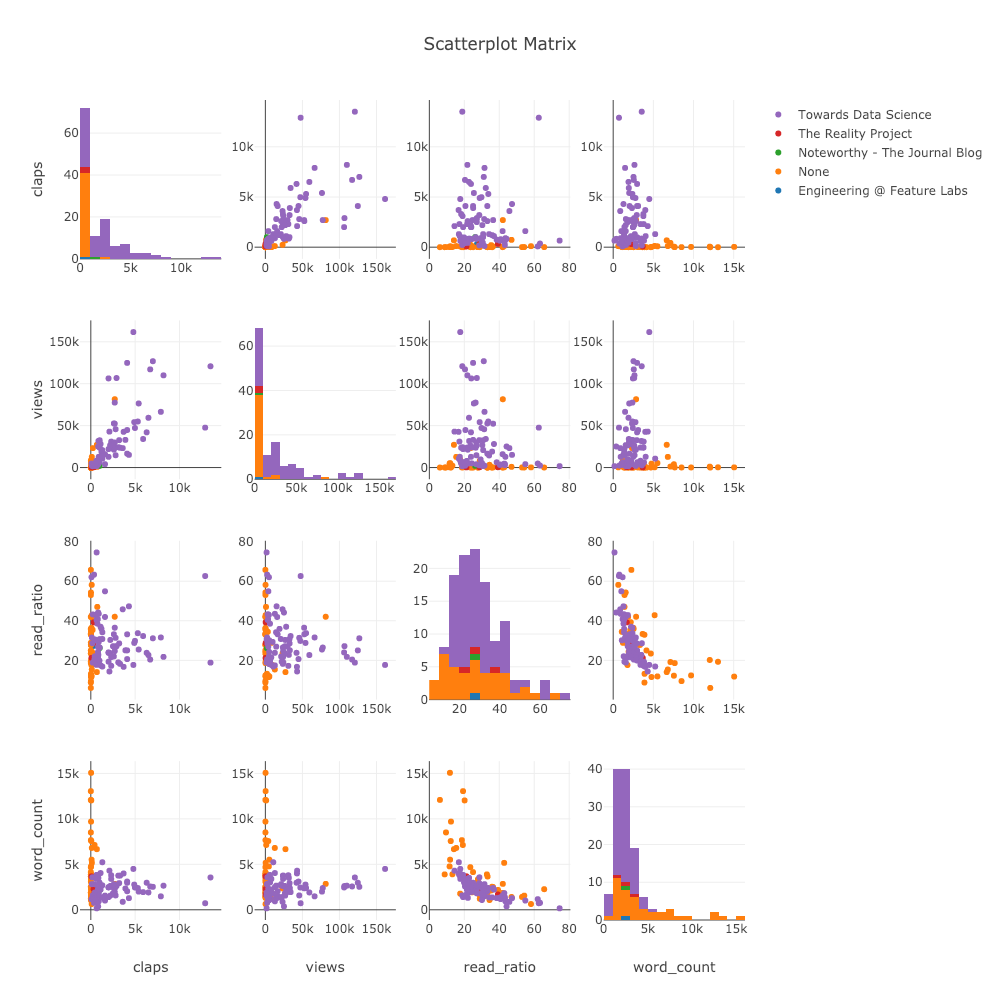
Même ce graphique est entièrement interactif, ce qui nous permet d'explorer les données.
Carte thermique de corrélation
Pour visualiser les corrélations entre les variables numériques, nous calculons les corrélations puis réalisons une heatmap annotée:
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
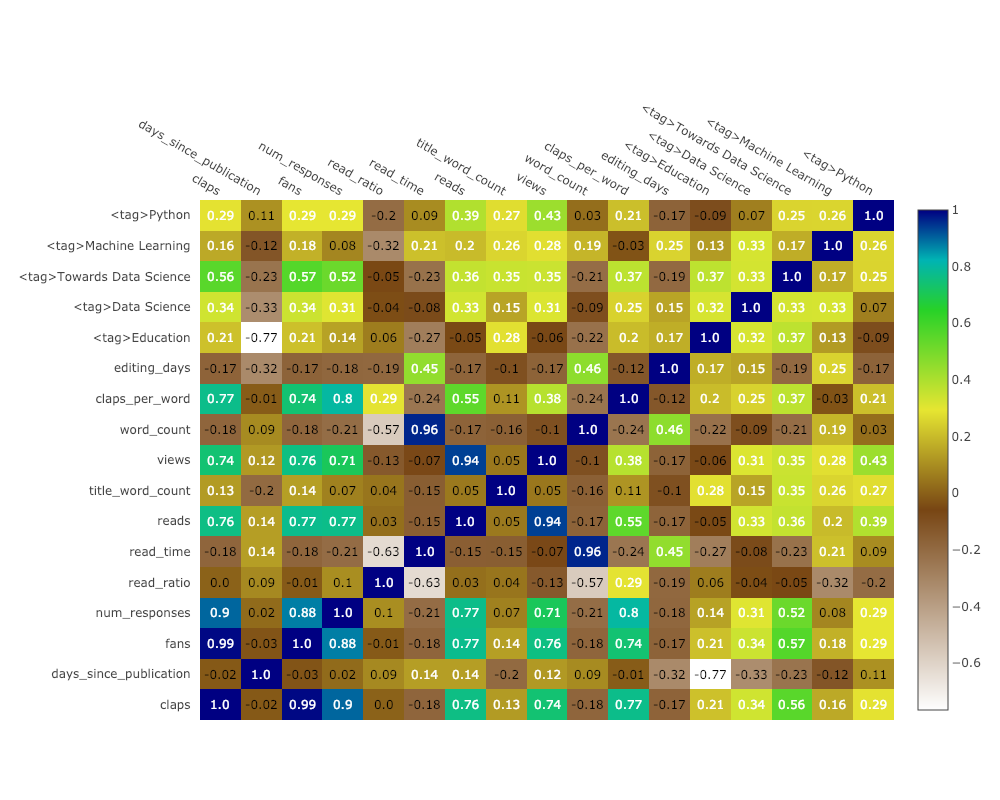
La liste des graphiques s'allonge encore et encore. Les boutons de manchette ont également plusieurs thèmes que nous pouvons utiliser pour obtenir une apparence et une sensation complètement différentes sans aucun effort. Par exemple, ci-dessous, nous avons un diagramme de rapport dans le thème "espace" et un diagramme de propagation dans "ggplot":
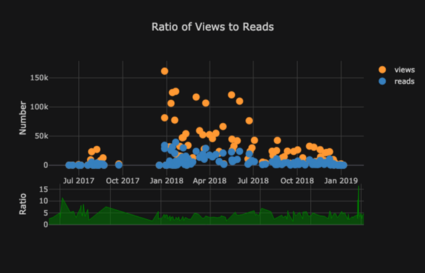
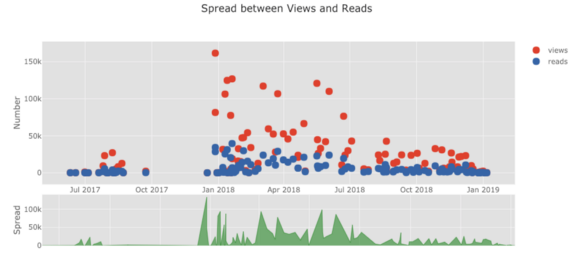
Nous obtenons également des tracés 3D (surfaces et bulles):
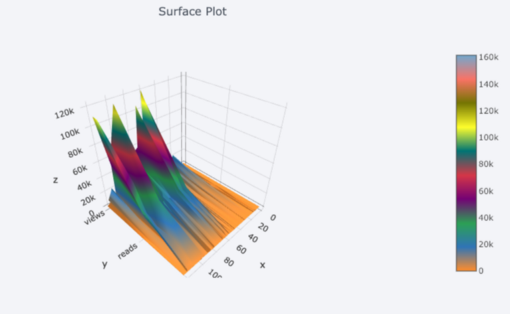
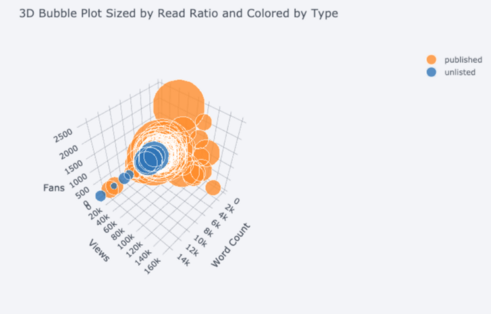
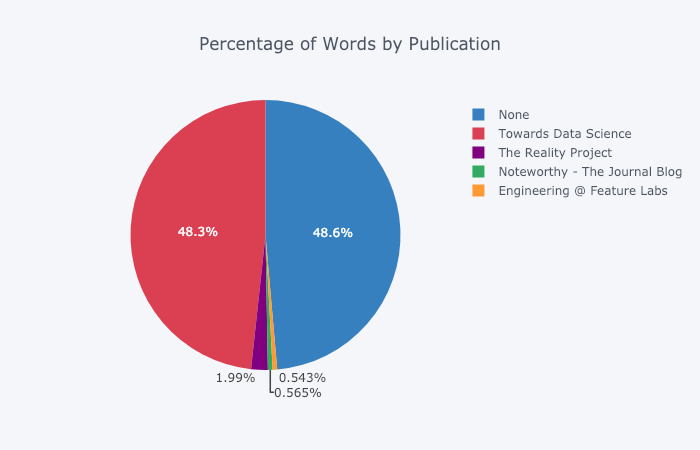
Pour ceux qui l'aiment , vous pouvez même créer un camembert:
Modification dans Plotly Chart Studio
Lorsque vous créez ces graphiques dans NoteBook Jupiter, vous remarquerez un petit lien dans le coin inférieur droit du graphique «Exporter vers plot.ly», si vous cliquez sur ce lien, vous serez redirigé vers Chart Studio où vous pourrez modifier votre graphique pour la présentation finale. Vous pouvez ajouter des annotations, spécifier des couleurs et généralement tout effacer pour obtenir un bon graphique. Ensuite, vous pouvez publier votre planning sur Internet afin que tout le monde puisse le trouver par référence.
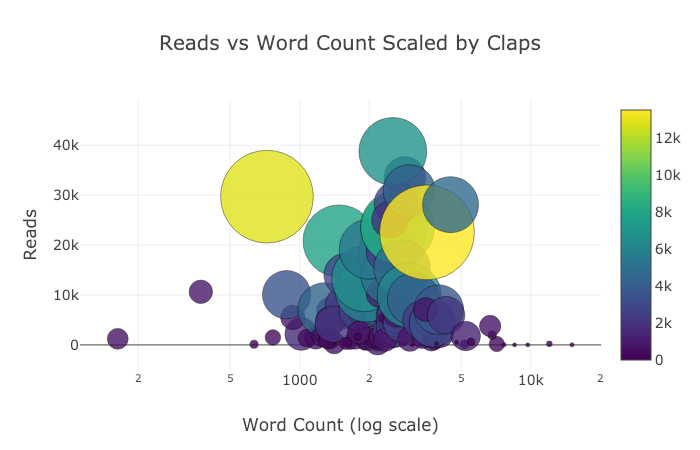
Voici deux graphiques que j'ai modifiés dans Chart Studio:
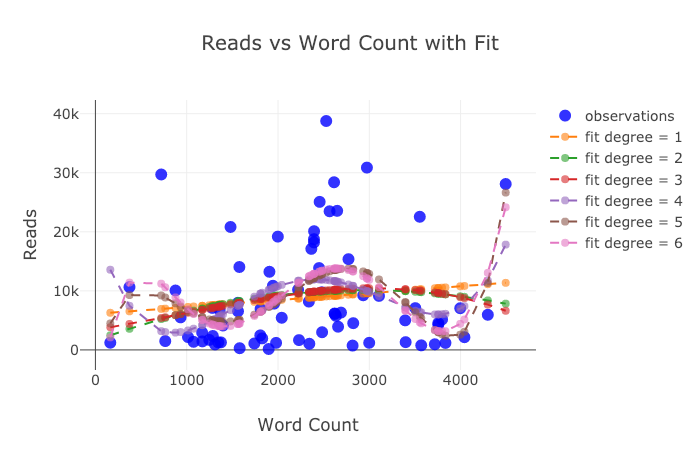
Malgré ce qui a été dit ici, nous n'avons toujours pas exploré toutes les fonctionnalités de la bibliothèque! Je vous conseillerais de regarder à la fois la documentation de l'intrigue et la documentation des boutons de manchette pour des intrigues plus incroyables.
conclusions
Le pire dans cette idée fausse sous-évaluée est que vous ne réalisez que le temps que vous avez perdu après avoir arrêté. Heureusement, maintenant que j'ai commis l'erreur de rester trop longtemps avec matploblib, vous n'êtes pas obligé de le faire!
Lorsque nous pensons aux bibliothèques de tracés, nous voulons plusieurs choses:
- Graphiques en une ligne pour une exploration rapide
- Substitution / exploration de données interactives
- La possibilité de fouiller dans les détails au besoin
- Configuration facile pour la présentation finale
Pour le moment, la meilleure option pour faire tout cela en Python est l'intrigue. Plotly nous permet de faire des visualisations rapidement et nous aide à mieux comprendre nos données grâce à l'interactivité. De plus, avouons-le, la création de graphiques doit être l'une des plus belles parties de la science des données! Avec d'autres bibliothèques, le traçage est devenu une tâche fastidieuse, mais avec l'intrigue, il y a la joie de refaire une belle figure!

Découvrez comment obtenir une profession de haut niveau à partir de zéro ou augmenter vos compétences et votre salaire en suivant les cours en ligne rémunérés de SkillFactory:
- Former le métier de Data Science à partir de zéro (12 mois)
- Profession d'analytique avec n'importe quel niveau de départ (9 mois)
- Cours d'apprentissage automatique (12 semaines)
- «Python -» (9 )
- DevOps (12 )
- - (8 )