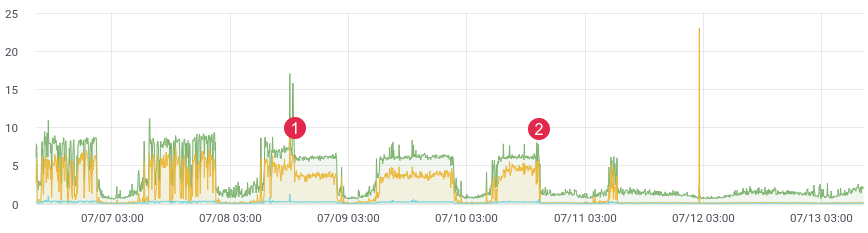
environ. latence / temps.
Tout le monde est probablement confronté à la tâche de profiler le code en production. Le xhprof de Facebook fait bien ce travail. Vous profilez, par exemple, 1/1000 demandes et voyez l'image pour le moment. Après chaque version, le produit est lancé et dit «c'était mieux et plus rapide avant la sortie». Vous n'avez aucune donnée historique et vous ne pouvez rien prouver. Et si tu pouvais?
Il n'y a pas si longtemps, nous avons réécrit une partie problématique du code et nous attendions un fort gain de performances. Nous avons écrit des tests unitaires, fait des tests de charge, mais comment le code se comportera-t-il sous une charge dynamique? Après tout, nous savons que les tests de charge n'affiche pas toujours des données réelles, et après le déploiement, vous devez rapidement obtenir des commentaires de votre code. Si vous collectez des données, après la publication, vous n'avez besoin que de 10 à 15 minutes pour comprendre la situation dans l'environnement de combat.
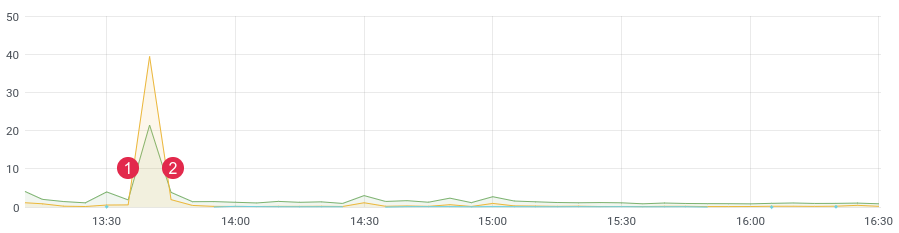
environ. latence / temps. (1) déployer, (2) revenir en arrière
Empiler
Pour notre tâche, nous avons pris une base de données ClickHouse en colonnes (abrégé kx). La vitesse, l'évolutivité linéaire, la compression des données et l'absence de blocage ont été les principales raisons de ce choix. C'est maintenant l'une des principales bases du projet.
Dans la première version, nous écrivions des messages dans la file d'attente et, en tant que consommateurs, nous les écrivions sur ClickHouse. Le délai atteint 3-4 heures (oui, ClickHouse est lent à insérer un par unrecords). Le temps passait et il fallait changer quelque chose. Il ne servait à rien de répondre aux notifications avec un tel retard. Ensuite, nous avons écrit une commande couronne qui a sélectionné le nombre requis de messages dans la file d'attente et envoyé un lot à la base de données, puis les avons marqués comme traités dans la file d'attente. Les premiers mois, tout allait bien, jusqu'à ce que les problèmes commencent ici aussi. Il y a eu trop d'événements, des données en double ont commencé à apparaître dans la base de données, les files d'attente n'ont pas été utilisées aux fins prévues (elles sont devenues une base de données) et la commande crown n'a plus géré l'écriture dans ClickHouse. Pendant ce temps, quelques dizaines de tables ont été ajoutées au projet, qui ont dû être écrites par lots en kx. La vitesse de traitement a chuté. La solution était aussi simple et rapide que possible. Cela nous a incité à écrire du code avec des listes en redis. L'idée est la suivante: nous écrivons des messages à la fin de la liste,Avec la commande crown, nous formons un pack et l'envoyons dans la file d'attente. Ensuite, les consommateurs analysent la file d'attente et écrivent un tas de messages dans le kx.
Nous avons : ClickHouse, Redis et une file d'attente (any - rabbitmq, kafka, beanstalkd ...)
Redis et listes
Jusqu'à un certain temps, Redis était utilisé comme cache, mais cela est en train de changer. La base a d'énormes fonctionnalités, et pour notre tâche, seules 3 commandes sont nécessaires : rpush , lrange et ltrim .
Nous écrirons les données à la fin de la liste en utilisant la commande rpush. Dans la commande crown, lisez les données à l'aide de lrange et envoyez-les à la file d'attente, si nous avons réussi à envoyer dans la file d'attente, nous devons supprimer les données sélectionnées à l'aide de ltrim.
De la théorie à la pratique. Créons une liste simple.

Nous avons une liste de trois messages, ajoutons un peu plus ... De
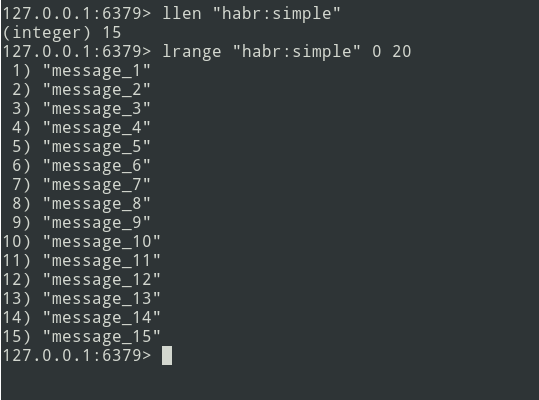
nouveaux messages sont ajoutés à la fin de la liste. À l'aide de la commande lrange, sélectionnez le lot (soit = 5 messages).
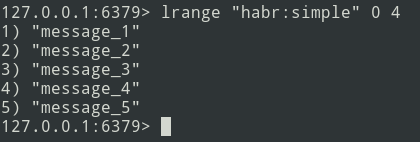
Ensuite, nous envoyons le pack dans la file d'attente. Vous devez maintenant supprimer ce bundle de Redis afin de ne plus le renvoyer.
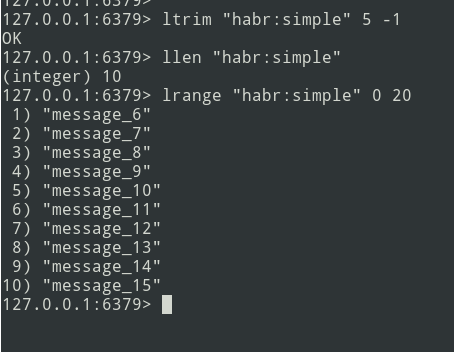
Il existe un algorithme, passons à l'implémentation.
la mise en oeuvre
Commençons par la table ClickHouse. Je ne me suis pas trop demandé et j'ai tout défini dans le type String .
create table profile_logs
(
hostname String, // ,
project String, //
version String, //
userId Nullable(String),
sessionId Nullable(String),
requestId String, //
requestIp String, // ip
eventName String, //
target String, // URL
latency Float32, // (latency=endTime - beginTime)
memoryPeak Int32,
date Date,
created DateTime
)
engine = MergeTree(date, (date, project, eventName), 8192);L'événement sera comme ceci:
{
"hostname": "debian-fsn1-2",
"project": "habr",
"version": "7.19.1",
"userId": null,
"sessionId": "Vv6ahLm0ZMrpOIMCZeJKEU0CTukTGM3bz0XVrM70",
"requestId": "9c73b19b973ca460",
"requestIp": "46.229.168.146",
"eventName": "app:init",
"target": "/",
"latency": 0.01384348869323730,
"memoryPeak": 2097152,
"date": "2020-07-13",
"created": "2020-07-13 13:59:02"
}La structure est définie. Pour calculer la latence, nous avons besoin d'une période. Nous identifions à l'aide de la fonction microtime :
$beginTime = microtime(true);
//
$latency = microtime(true) - $beginTime;Pour simplifier l'implémentation, nous utiliserons le framework laravel et la bibliothèque laravel-entry . Ajoutez un modèle (table profile_logs):
class ProfileLog extends \Bavix\Entry\Models\Entry
{
protected $fillable = [
'hostname',
'project',
'version',
'userId',
'sessionId',
'requestId',
'requestIp',
'eventName',
'target',
'latency',
'memoryPeak',
'date',
'created',
];
protected $casts = [
'date' => 'date:Y-m-d',
'created' => 'datetime:Y-m-d H:i:s',
];
}Écrivons une méthode tick (j'ai créé un service ProfileLogService ) qui écrira des messages dans Redis. Nous obtenons l'heure actuelle (notre beginTime) et l'écrivons dans la variable $ currentTime:
$currentTime = \microtime(true);Si le tick d'un événement est appelé pour la première fois, écrivez-le dans le tableau de ticks et terminez la méthode:
if (empty($this->ticks[$eventName])) {
$this->ticks[$eventName] = $currentTime;
return;
}Si le tick est appelé à nouveau, nous écrivons le message à Redis en utilisant la méthode rpush:
$tickTime = $this->ticks[$eventName];
unset($this->ticks[$eventName]);
Redis::rpush('events:profile_logs', \json_encode([
'hostname' => \gethostname(),
'project' => 'habr',
'version' => \app()->version(),
'userId' => Auth::id(),
'sessionId' => \session()->getId(),
'requestId' => \bin2hex(\random_bytes(8)),
'requestIp' => \request()->getClientIp(),
'eventName' => $eventName,
'target' => \request()->getRequestUri(),
'latency' => $currentTime - $tickTime,
'memoryPeak' => \memory_get_usage(true),
'date' => $tickTime,
'created' => $tickTime,
]));La variable $ this-> ticks n'est pas statique. Vous devez enregistrer le service en tant que singleton.
$this->app->singleton(ProfileLogService::class);La taille du lot ( $ batchSize ) est configurable, il est recommandé de spécifier une petite valeur (par exemple, 10 000 éléments). Si des problèmes surviennent (par exemple, ClickHouse n'est pas disponible), la file d'attente commencera à échouer et vous devrez déboguer les données.
Écrivons une commande couronne:
$batchSize = 10000;
$key = 'events:profile_logs'
do {
$bulkData = Redis::lrange($key, 0, \max($batchSize - 1, 0));
$count = \count($bulkData);
if ($count) {
// json, decode
foreach ($bulkData as $itemKey => $itemValue) {
$bulkData[$itemKey] = \json_decode($itemValue, true);
}
// ch
\dispatch(new BulkWriter($bulkData));
// redis
Redis::ltrim($key, $count, -1);
}
} while ($count >= $batchSize);Vous pouvez immédiatement écrire des données dans ClickHouse, mais le problème réside dans le fait que kronor fonctionne en mode monothread. Par conséquent, nous irons dans l'autre sens - avec la commande, nous formerons des packs et les enverrons dans la file d'attente pour un enregistrement multithread ultérieur dans ClickHouse. Le nombre de consommateurs peut être régulé - cela accélérera l'envoi des messages.
Passons à l'écriture d'un consommateur:
class BulkWriter implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
protected $bulkData;
public function __construct(array $bulkData)
{
$this->bulkData = $bulkData;
}
public function handle(): void
{
ProfileLog::insert($this->bulkData);
}
}
}Ainsi, la formation des packs, l'envoi à la file d'attente et le consommateur sont développés - vous pouvez commencer le profilage:
app(ProfileLogService::class)->tick('post::paginate');
$posts = Post::query()->paginate();
$response = view('posts', \compact('posts'));
app(ProfileLogService::class)->tick('post::paginate');
return $response;Si tout est fait correctement, les données doivent être dans Redis. Nous allons confondre la commande crown et envoyer les packs dans la file d'attente, et le consommateur les insérera dans la base de données.
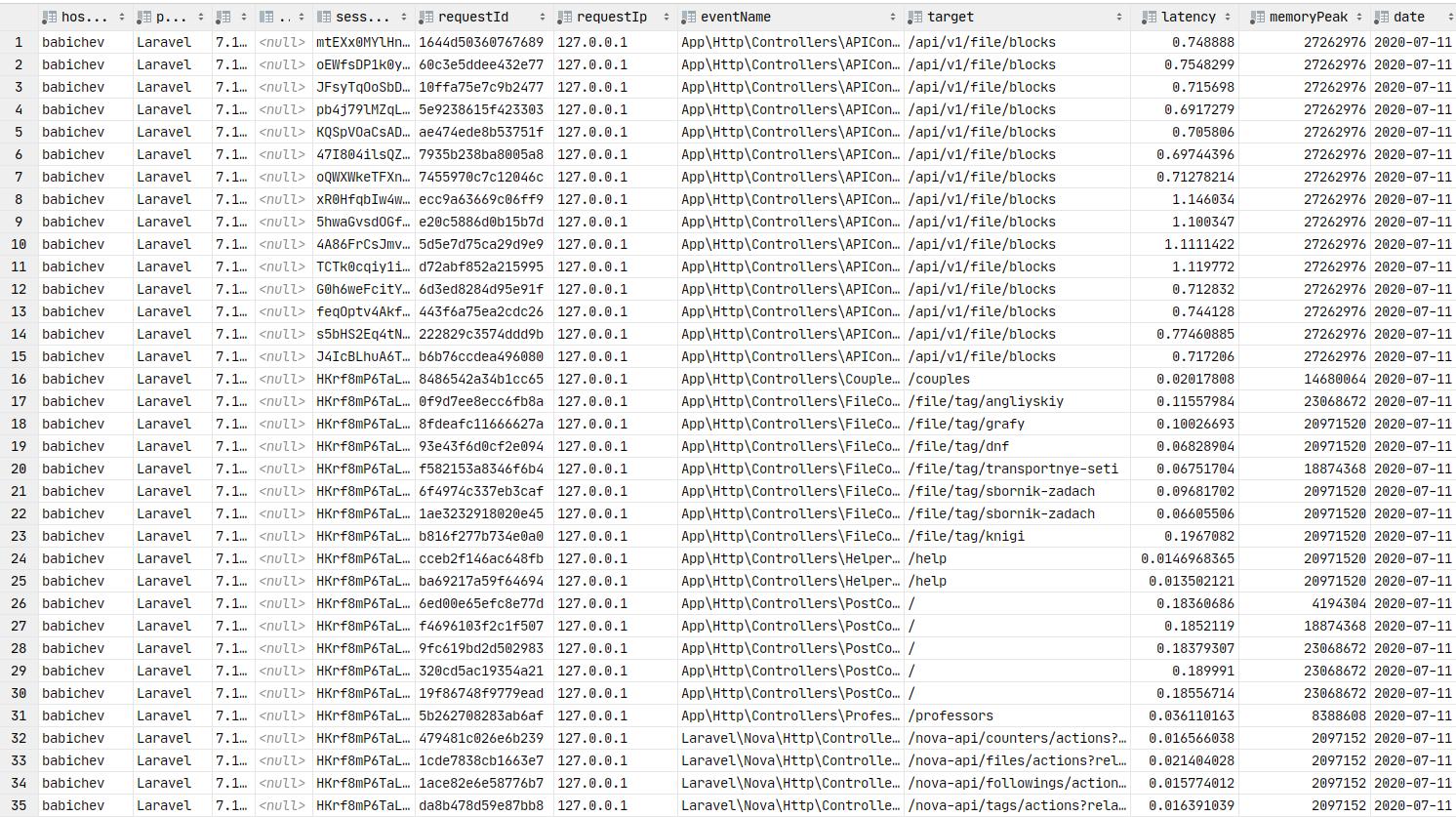
Données dans la base de données. Vous pouvez créer des graphiques.
Grafana
Passons maintenant à la présentation graphique des données, qui est un élément clé de cet article. Vous devez installer grafana . Ignorons le processus d'installation des assemblys de type debain, vous pouvez utiliser le lien vers la documentation . Habituellement, l'étape d'installation se résume à apt installer grafana .
Sur ArchLinux, l'installation ressemble à ceci:
yaourt -S grafana
sudo systemctl start grafanaLe service a démarré. URL: http: // localhost: 3000
Vous devez maintenant installer le plugin de source de données ClickHouse :
sudo grafana-cli plugins install vertamedia-clickhouse-datasourceSi vous avez installé grafana 7+, ClickHouse ne fonctionnera pas. Vous devez apporter des modifications à la configuration:
sudo vi /etc/grafana.iniTrouvons la ligne:
;allow_loading_unsigned_plugins =Remplaçons-le par celui-ci:
allow_loading_unsigned_plugins=vertamedia-clickhouse-datasourceSauvegardons et redémarrons le service:
sudo systemctl restart grafanaTerminé. Nous pouvons maintenant passer à la grafana .
Login: admin / mot de passe: admin par défaut.

Après une autorisation réussie, cliquez sur l'engrenage. Dans la fenêtre contextuelle qui s'ouvre, sélectionnez Sources de données, ajoutez une connexion à ClickHouse.
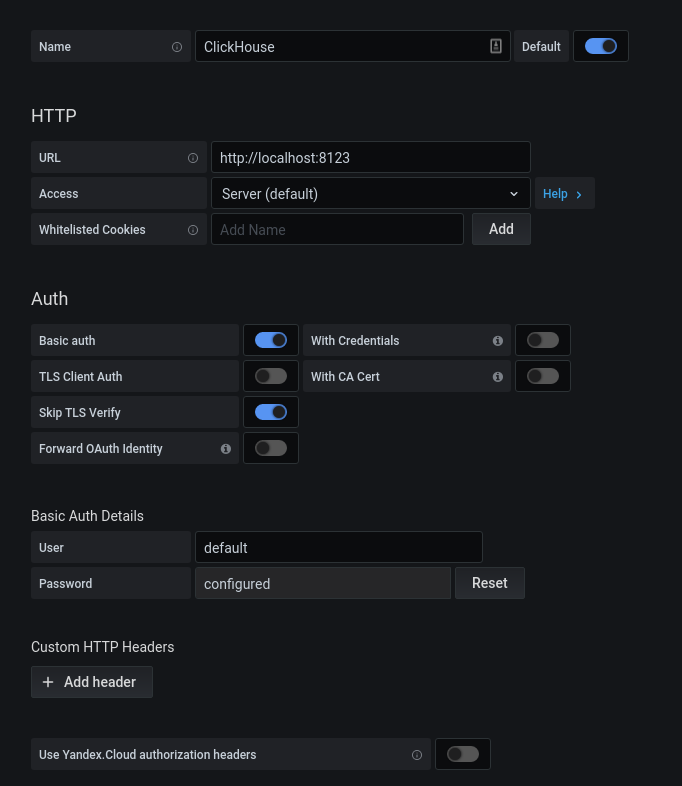
Nous remplissons la configuration kx. Cliquez sur le bouton "Enregistrer et tester", nous recevons un message indiquant une connexion réussie.
Maintenant, ajoutons un nouveau tableau de bord:
Ajouter un panneau:

Sélectionnez la base et les colonnes correspondantes pour travailler avec les dates:
Passons à la requête:
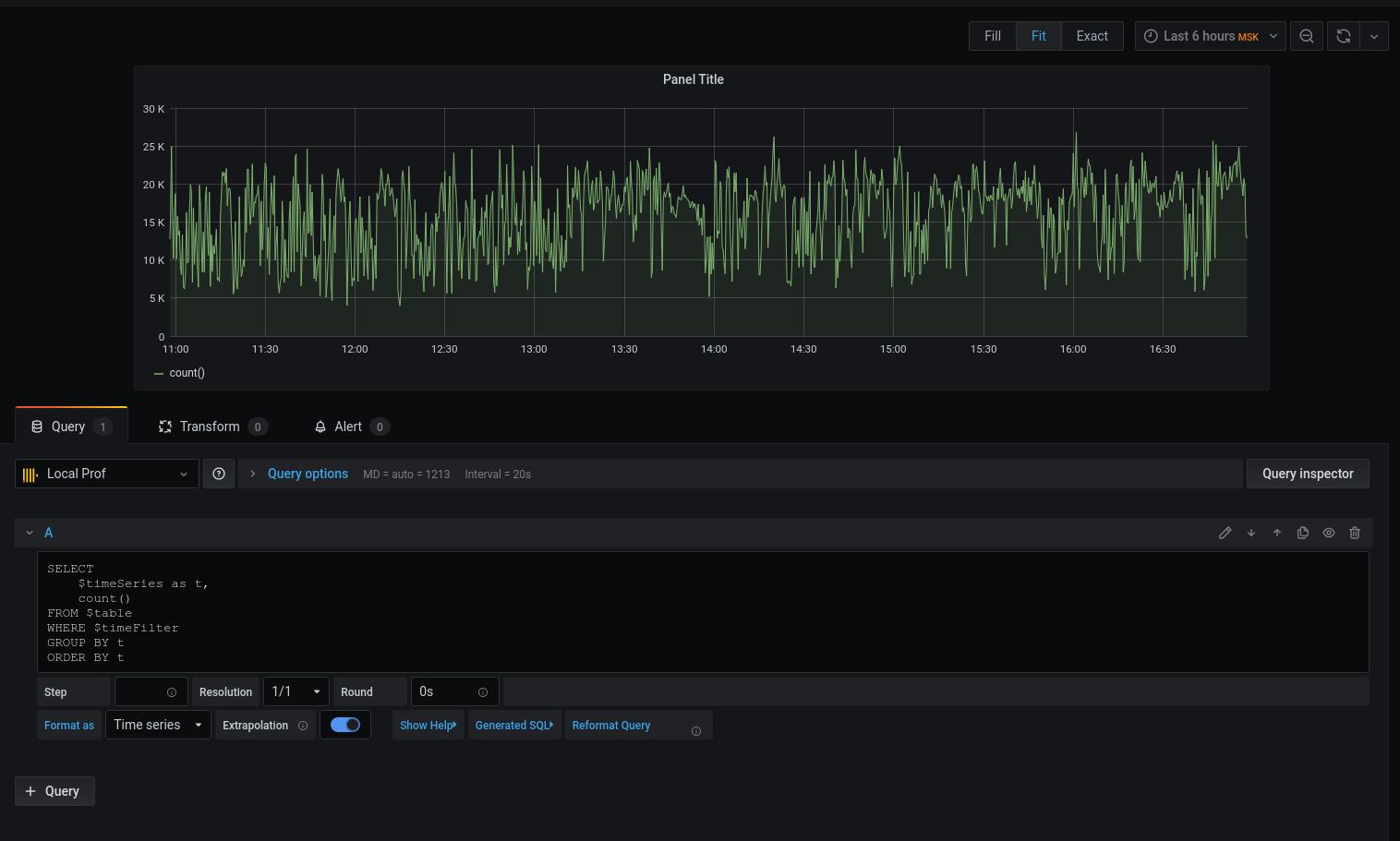
Nous avons un graphique, mais je veux des détails. Imprimons la latence moyenne arrondissant la date avec l'heure au début de l'intervalle de cinq minutes :
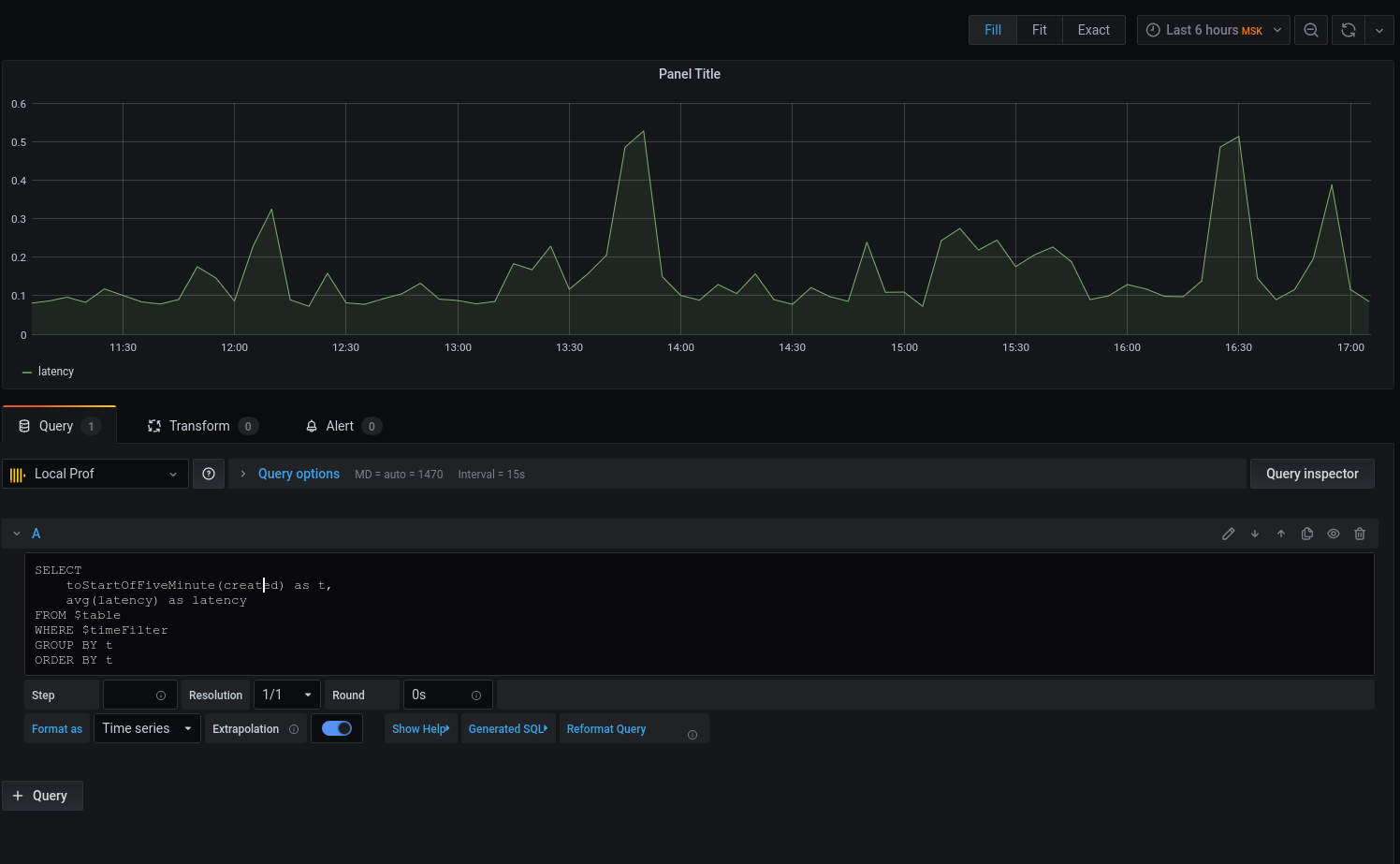
Maintenant que les données sélectionnées sont affichées sur le graphique, nous pouvons nous concentrer sur elles. Pour les alertes, configurez les déclencheurs, regroupez par événements, etc.
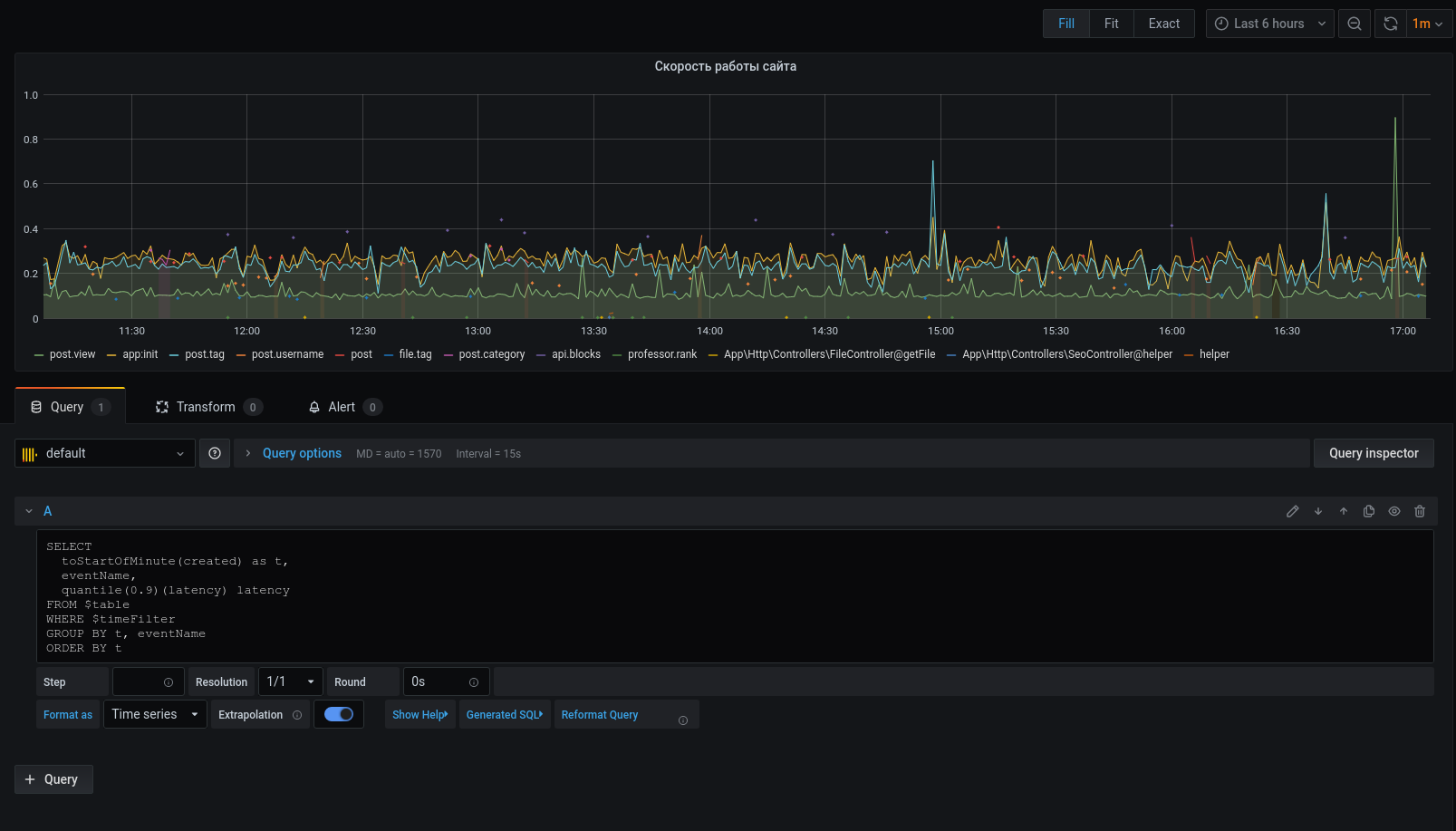
Le profileur ne remplace en aucun cas les outils: xhprof (facebook) , xhprof (tideways) , liveprof de (Badoo) . Et ne fait que les compléter.
Tout le code source est sur github - modèle de profileur , service , BulkWriteCommand , BulkWriterJob et middleware ( 1 , 2 ).
Installation du package:
composer req bavix/laravel-profConfiguration des connexions (config / database.php), ajoutez clickhouse:
'bavix::clickhouse' => [
'driver' => 'bavix::clickhouse',
'host' => env('CH_HOST'),
'port' => env('CH_PORT'),
'database' => env('CH_DATABASE'),
'username' => env('CH_USERNAME'),
'password' => env('CH_PASSWORD'),
],
Début des travaux:
use Bavix\Prof\Services\ProfileLogService;
// ...
app(ProfileLogService::class)->tick('event-name');
//
app(ProfileLogService::class)->tick('event-name');Pour envoyer un lot à la file d'attente, vous devez ajouter une commande à cron:
* * * * * php /var/www/site.com/artisan entry:bulkVous devez également exécuter un consommateur:
php artisan queue:work --sleep=3 --tries=3Il est recommandé de configurer le superviseur . Config (5 consommateurs):
[program:bulk_write]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/site.com/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
user=www-data
numprocs=5
redirect_stderr=true
stopwaitsecs=3600
UPD:
1. ClickHouse peut extraire nativement des données de la file d'attente kafka . Merci,sdm