
Pourquoi les pétroliers ont-ils besoin de la PNL? Comment obtenir un ordinateur pour comprendre le jargon professionnel? Est-il possible d'expliquer à la machine ce que sont «pression», «réponse du papillon», «annulaire»? Comment les nouvelles recrues et l'assistant vocal sont-ils connectés? Nous tenterons de répondre à ces questions dans l'article sur l'introduction d'un assistant numérique dans le logiciel d'aide à la production pétrolière, ce qui facilite le travail de routine d'un géologue-développeur.
À l'institut, nous développons notre propre logiciel ( https://rn.digital/ ) pour l'industrie pétrolière, et pour que les utilisateurs en tombent amoureux, vous devez non seulement y mettre en œuvre des fonctions utiles, mais aussi penser à la commodité de l'interface tout le temps. L'une des tendances actuelles de l'UI / UX est la transition vers les interfaces vocales. Après tout, quoi qu'on en dise, la forme d'interaction la plus naturelle et la plus pratique pour une personne est la parole. La décision a donc été prise de développer et d'implémenter un assistant vocal dans nos produits logiciels.
En plus d'améliorer le composant UI / UX, l'introduction de l'assistant vous permet également de réduire le «seuil» pour que les nouveaux employés travaillent avec des logiciels. La fonctionnalité de nos programmes est étendue, et cela peut prendre plus d'un jour pour le comprendre. La possibilité de «demander» à l'assistant d'exécuter la commande souhaitée réduira le temps consacré à la résolution de la tâche, ainsi que le stress d'un nouveau travail.
Le service de sécurité de l'entreprise étant très sensible au transfert de données vers des services externes, nous avons pensé développer un assistant basé sur des solutions open source permettant de traiter les informations localement.
Structurellement, notre assistant se compose des modules suivants:
- Reconnaissance vocale (ASR)
- Attribution d'objets sémantiques (Natural Language Understanding, NLU)
- Exécution de la commande
- Synthèse de la parole (Text-to-Speech, TTS)
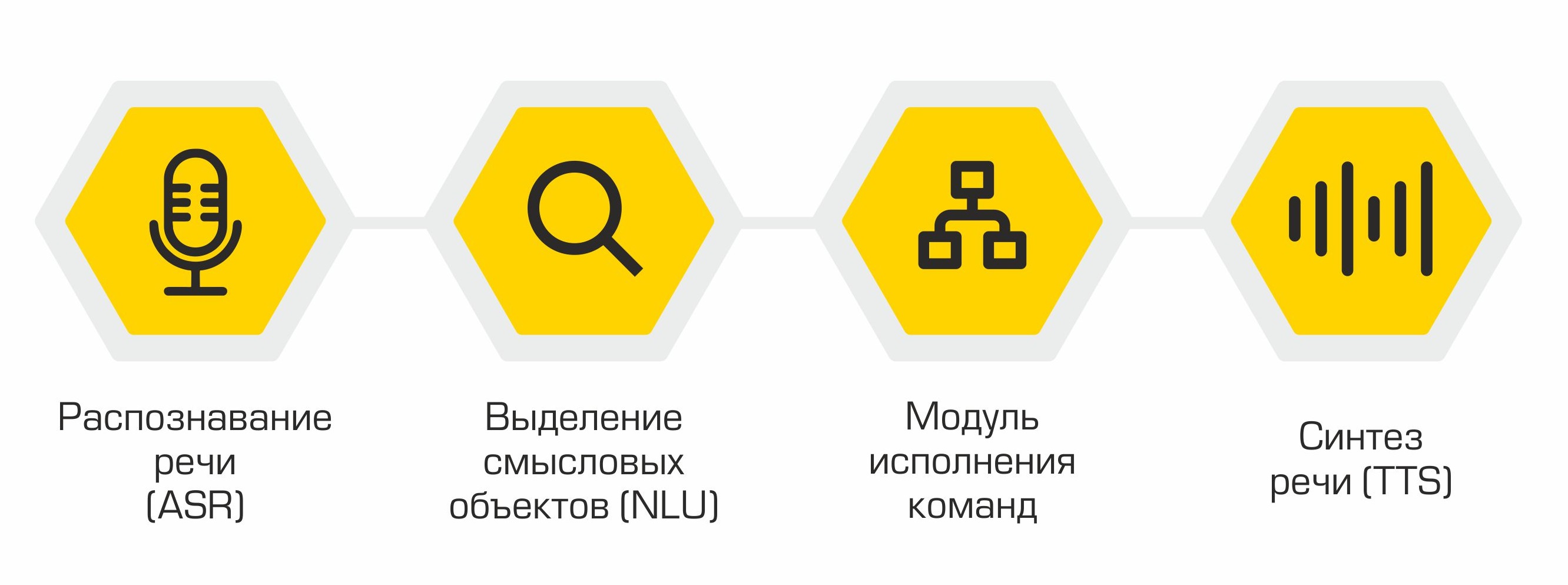
Le principe de l'assistant: des mots (utilisateur) aux actions (en logiciel)!
La sortie de chaque module sert de point d'entrée pour le composant suivant du système. Ainsi, la parole de l'utilisateur est convertie en texte et envoyée pour traitement aux algorithmes d'apprentissage automatique afin de déterminer l'intention de l'utilisateur. En fonction de cette intention, la classe requise est activée dans le module d'exécution de commande, qui répond à la demande de l'utilisateur. A la fin de l'opération, le module d'exécution de commande transmet des informations sur l'état d'exécution de commande au module de synthèse vocale, qui, à son tour, en informe l'utilisateur.
Chaque module d'assistance est un microservice. Ainsi, s'il le souhaite, l'utilisateur peut se passer des technologies vocales et se tourner directement vers le «cerveau» de l'assistant - vers le module de mise en évidence des objets sémantiques - sous la forme d'un chat bot.
Reconnaissance de la parole
La première étape de la reconnaissance vocale est le traitement du signal vocal et l'extraction de caractéristiques. La représentation la plus simple d'un signal audio est un oscillogramme. Il reflète la quantité d'énergie à un moment donné. Cependant, ces informations ne sont pas suffisantes pour déterminer le son prononcé. Il est important pour nous de savoir combien d'énergie est contenue dans différentes gammes de fréquences. Pour ce faire, à l'aide de la transformée de Fourier, une transition est effectuée de l'oscillogramme vers le spectre.
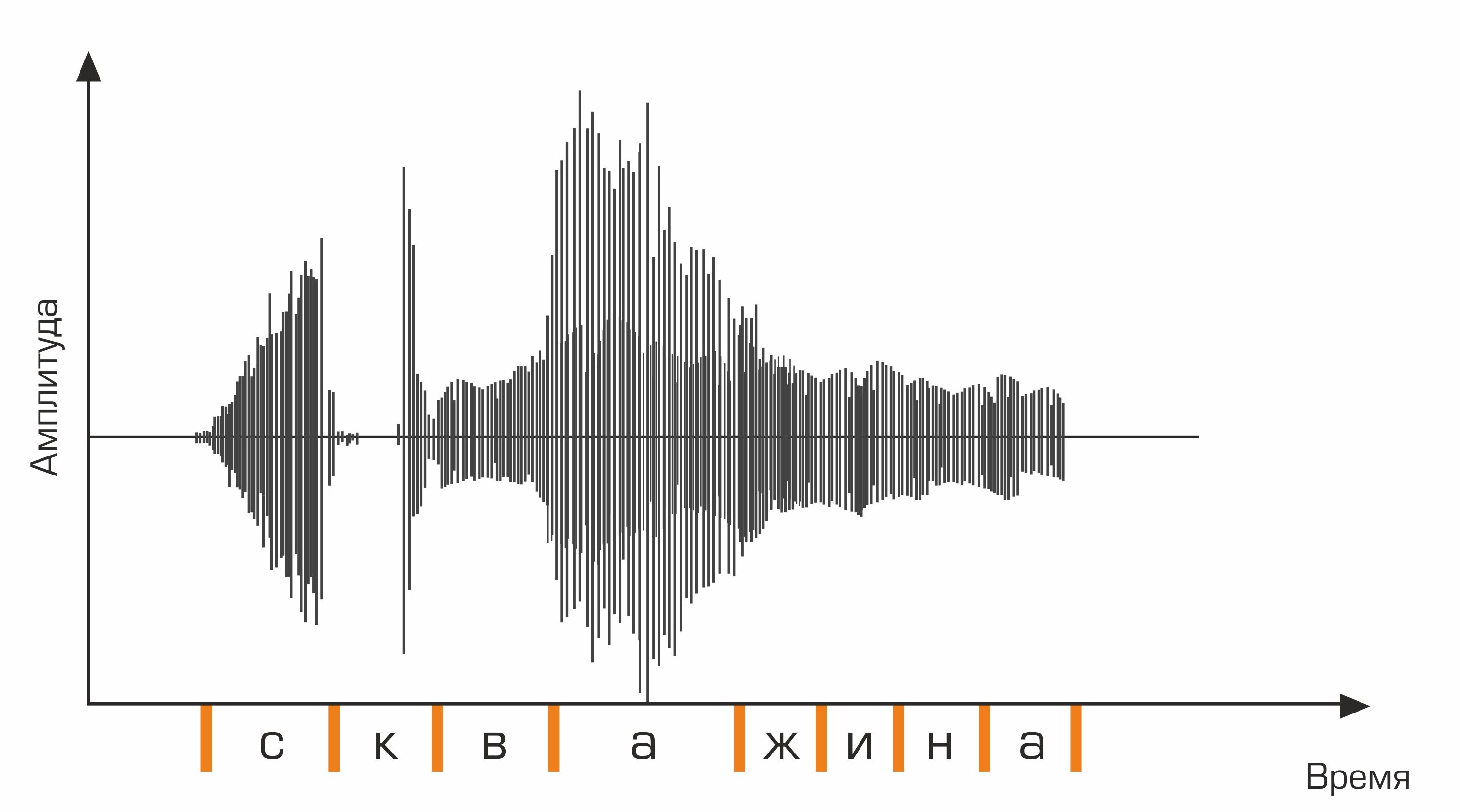
Ceci est un oscillogramme.
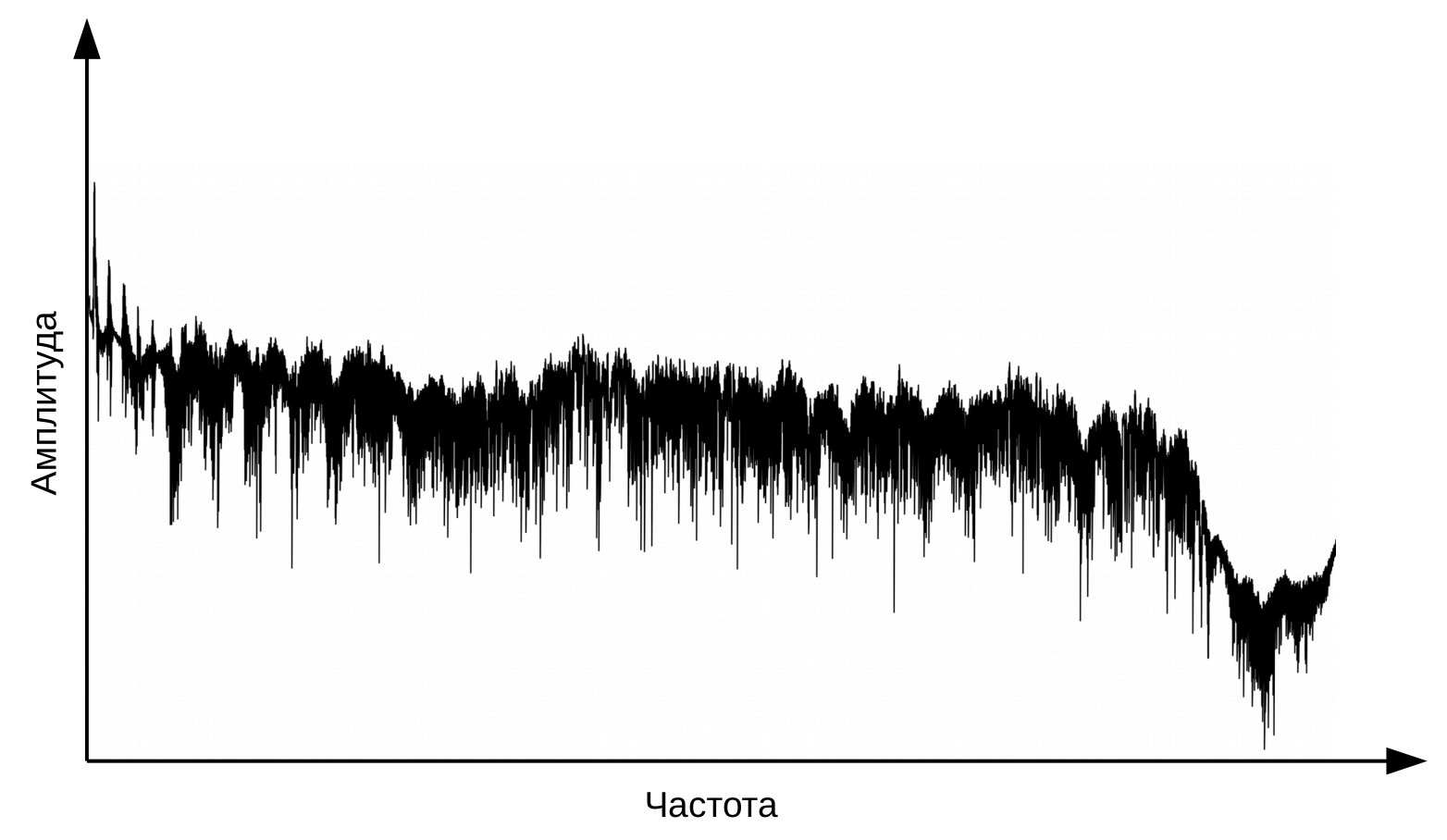
Et c'est le spectre pour chaque instant dans le temps.
Ici, il est nécessaire de préciser que la parole se forme lorsqu'un flux d'air vibrant traverse le larynx (source) et le tractus vocal (filtre). Pour classer les phonèmes, nous n'avons besoin que d'informations sur la configuration du filtre, c'est-à-dire sur la position des lèvres et de la langue. Cette information peut être distinguée par le passage du spectre au cepstre (cepstre - un anagramme du mot spectre), réalisé en utilisant la transformée de Fourier inverse du logarithme du spectre. Encore une fois, l'axe des x n'est pas la fréquence, mais le temps. Le terme «fréquence» est utilisé pour faire la distinction entre les domaines temporels du cepstre et le signal audio original (Oppenheim, Schafer. Digital Signal Processing, 2018).
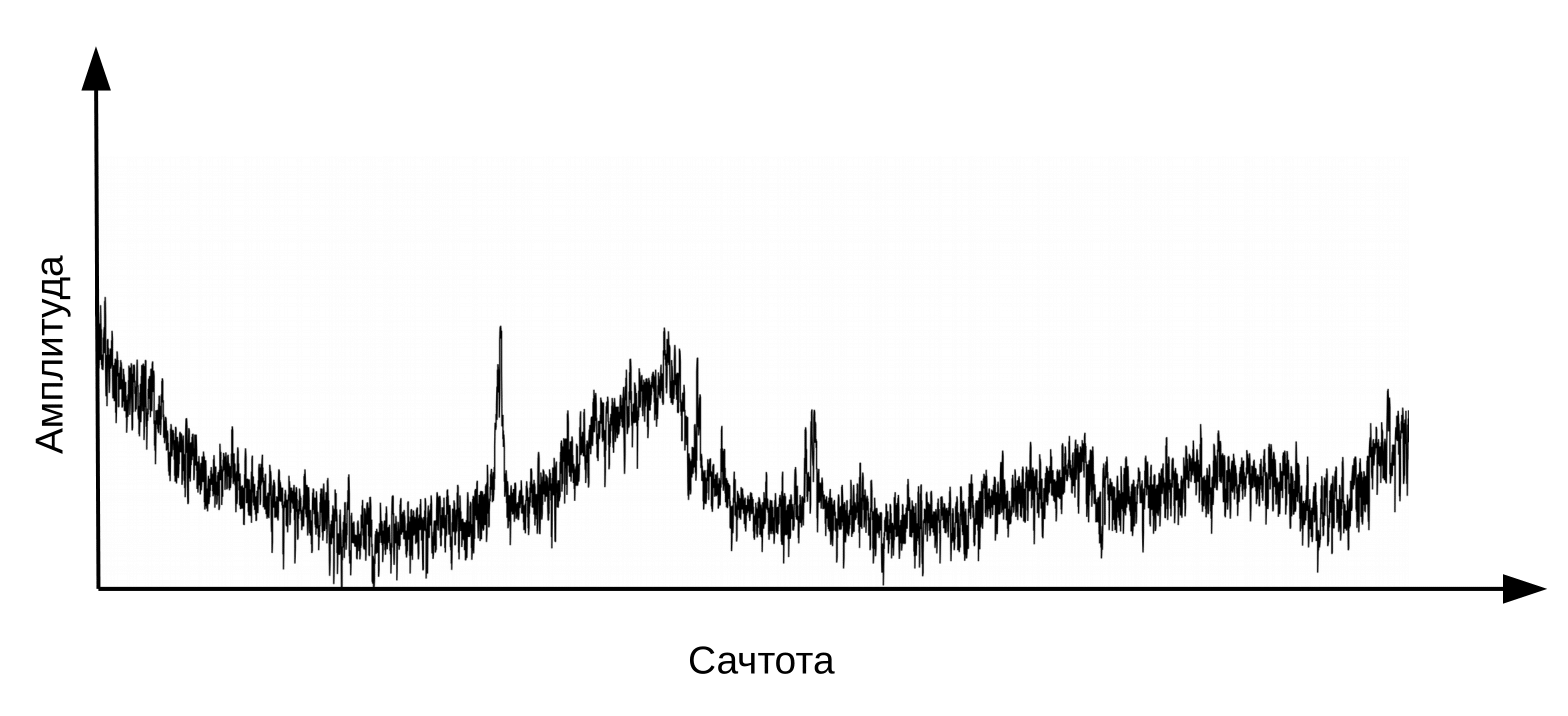
Cepstrum, ou simplement «spectre du logarithme du spectre». Oui, oui, commun est un terme , pas une faute de frappe
Les informations sur la position du tractus vocal se trouvent dans les 12 premiers coefficients cepstre. Ces 12 coefficients cepstraux sont complétés par des caractéristiques dynamiques (delta et delta-delta) décrivant les changements dans le signal audio. (Jurafsky, Martin. Traitement de la parole et du langage, 2008). Le vecteur de valeurs résultant est appelé le vecteur MFCC (Mel-frequency cepstral coefficients) et est la caractéristique acoustique la plus couramment utilisée dans la reconnaissance vocale.
Que se passe-t-il ensuite avec les signes? Ils sont utilisés comme entrée du modèle acoustique. Il montre quelle unité linguistique est la plus susceptible de "générer" un tel vecteur MFCC. Dans différents systèmes, ces unités linguistiques peuvent être des parties de phonèmes, de phonèmes ou même de mots. Ainsi, le modèle acoustique transforme une séquence de vecteurs MFCC en une séquence de phonèmes les plus probables.
En outre, pour la séquence de phonèmes, il est nécessaire de sélectionner la séquence de mots appropriée. C'est là qu'intervient le dictionnaire de langues, contenant la transcription de tous les mots reconnus par le système. La compilation de tels dictionnaires est un processus laborieux qui nécessite une connaissance approfondie de la phonétique et de la phonologie d'une langue particulière. Un exemple de ligne d'un dictionnaire de transcriptions:
bien skv aa zh yn ay
Dans l'étape suivante, le modèle de langage détermine la probabilité antérieure de la phrase dans la langue. En d'autres termes, le modèle donne une estimation de la probabilité qu'une telle phrase apparaisse dans une langue. Un bon modèle de langage déterminera que la phrase «Chart the oil rate» est plus probable que la phrase «Chart the nine oil».
La combinaison d'un modèle acoustique, d'un modèle de langage et d'un dictionnaire de prononciation crée une «grille» d'hypothèses - toutes les séquences de mots possibles à partir desquelles la plus probable peut être trouvée en utilisant l'algorithme de programmation dynamique. Son système le proposera comme texte reconnu.
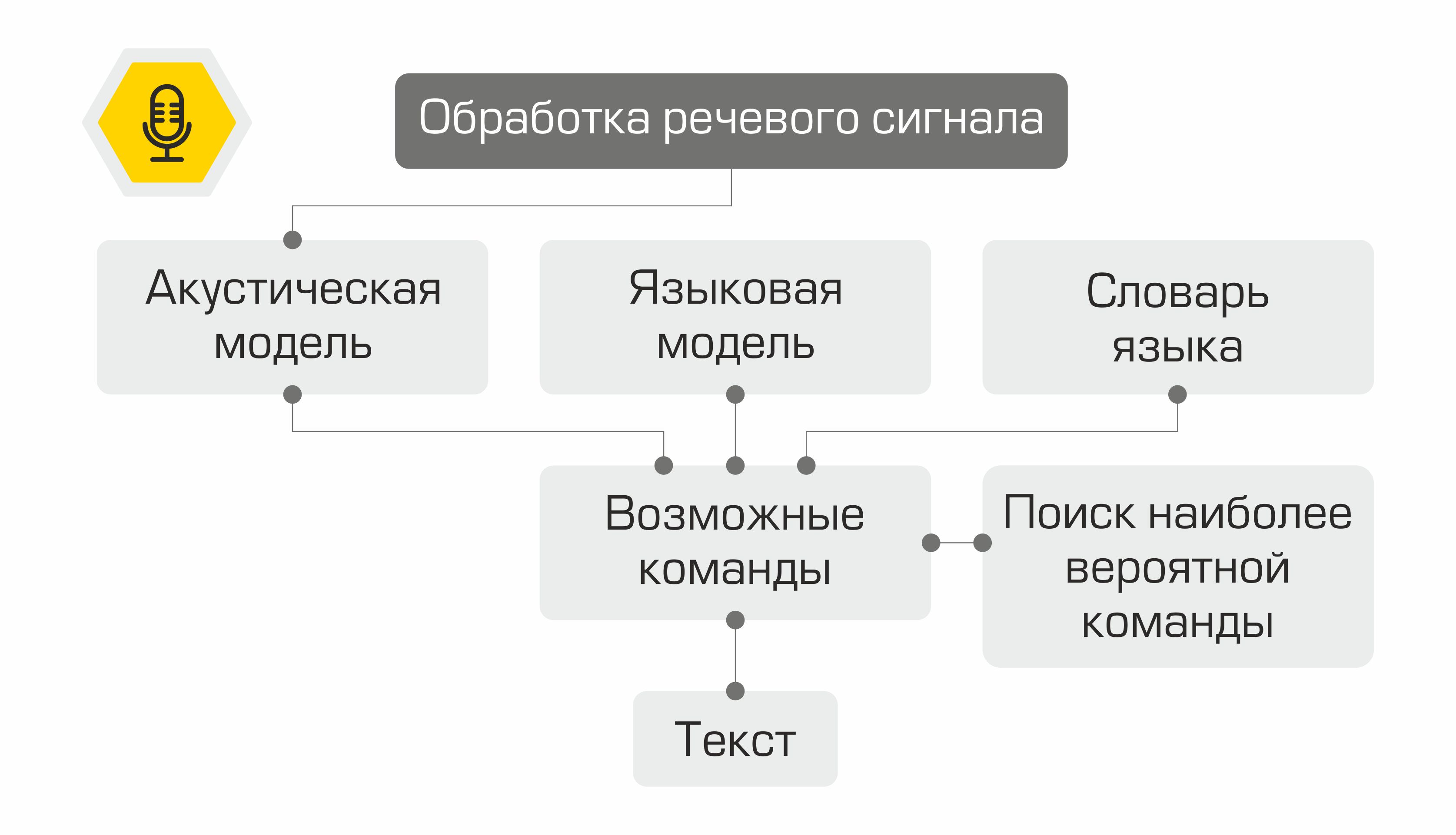
Représentation schématique du fonctionnement du système de reconnaissance vocale
Il ne serait pas pratique de réinventer la roue et d'écrire une bibliothèque de reconnaissance vocale à partir de zéro, notre choix s'est donc porté sur le framework kaldi . L'avantage incontestable de la bibliothèque est sa flexibilité, permettant, si nécessaire, de créer et de modifier tous les composants du système. De plus, la licence Apache 2.0 vous permet d'utiliser librement la bibliothèque dans le développement commercial.
Comme données pour la formation, un modèle acoustique a utilisé le jeu de données audio gratuit VoxForge . Pour convertir une séquence de phonèmes en mots, nous avons utilisé un dictionnaire russe fourni par la bibliothèque CMU Sphinx . Étant donné que le dictionnaire ne contenait pas la prononciation des termes spécifiques à l'industrie pétrolière, basée sur celui-ci, en utilisant l'utilitaireg2p-seq2seq a entraîné un modèle de graphème en phonème pour créer rapidement des transcriptions pour de nouveaux mots. Le modèle de langage a été formé à la fois sur des transcriptions audio de VoxForge et sur un ensemble de données que nous avons créé, contenant des termes de l'industrie pétrolière et gazière, des noms de champs et des sociétés productrices.
Sélection d'objets sémantiques
Nous avons donc reconnu le discours de l'utilisateur, mais ce n'est qu'une ligne de texte. Comment dites-vous à l'ordinateur quoi faire? Les premiers systèmes de commande vocale utilisaient un ensemble de commandes très limité. Ayant reconnu l'une de ces phrases, il était possible d'invoquer l'opération correspondante. Depuis lors, les technologies dans le domaine du traitement et de la compréhension du langage naturel (NLP et NLU, respectivement) ont fait un bond en avant. Déjà aujourd'hui, les modèles formés sur de grandes quantités de données sont capables de bien comprendre le sens d'une déclaration.
Pour extraire du sens du texte d'une phrase reconnue, il est nécessaire de résoudre deux problèmes d'apprentissage automatique:
- Classification des équipes d'utilisateurs (classification des intentions).
- Attribution d'entités nommées (reconnaissance d'entités nommées).
Lors du développement des modèles, nous avons utilisé la bibliothèque open source Rasa , distribuée sous la licence Apache 2.0.
Pour résoudre le premier problème, il est nécessaire de présenter le texte comme un vecteur numérique pouvant être traité par une machine. Pour une telle transformation, le modèle neuronal StarSpace est utilisé , ce qui permet d '« imbriquer » le texte de la requête et la classe de la requête dans un espace commun.

Modèle neuronal StarSpace
Au cours de la formation, le réseau neuronal apprend à comparer des entités, afin de minimiser la distance entre le vecteur de requête et le vecteur de la classe correcte et maximiser la distance aux vecteurs de différentes classes. Pendant le test, la classe y est sélectionnée pour la requête x de sorte que:
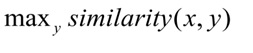
La distance cosinus est utilisée comme mesure de la similitude des vecteurs:,
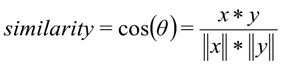
où
x est la demande de l'utilisateur, y est la catégorie de la demande.
3000 requêtes ont été balisées pour former le classificateur d'intentions de l'utilisateur. Au total, nous avons eu 8 cours. Nous avons divisé l'échantillon en échantillons d'apprentissage et de test dans un rapport 70/30 en utilisant la méthode de stratification des variables cibles. La stratification nous a permis de conserver la distribution originale des classes dans le train et le test. La qualité du modèle formé a été évaluée par plusieurs critères à la fois:
- Rappel - la proportion de demandes correctement classées pour toutes les demandes de cette classe.
- La part des demandes correctement classées (Précision).
- Précision - la proportion de demandes correctement classées par rapport à toutes les demandes attribuées par le système à cette classe.
- F1 – .
De plus, la matrice d'erreur système est utilisée pour évaluer la qualité du modèle de classification. L'axe des y est la vraie classe de l'instruction, l'axe des x est la classe prédite par l'algorithme.
Sur l'échantillon de contrôle, le modèle a montré les résultats suivants:
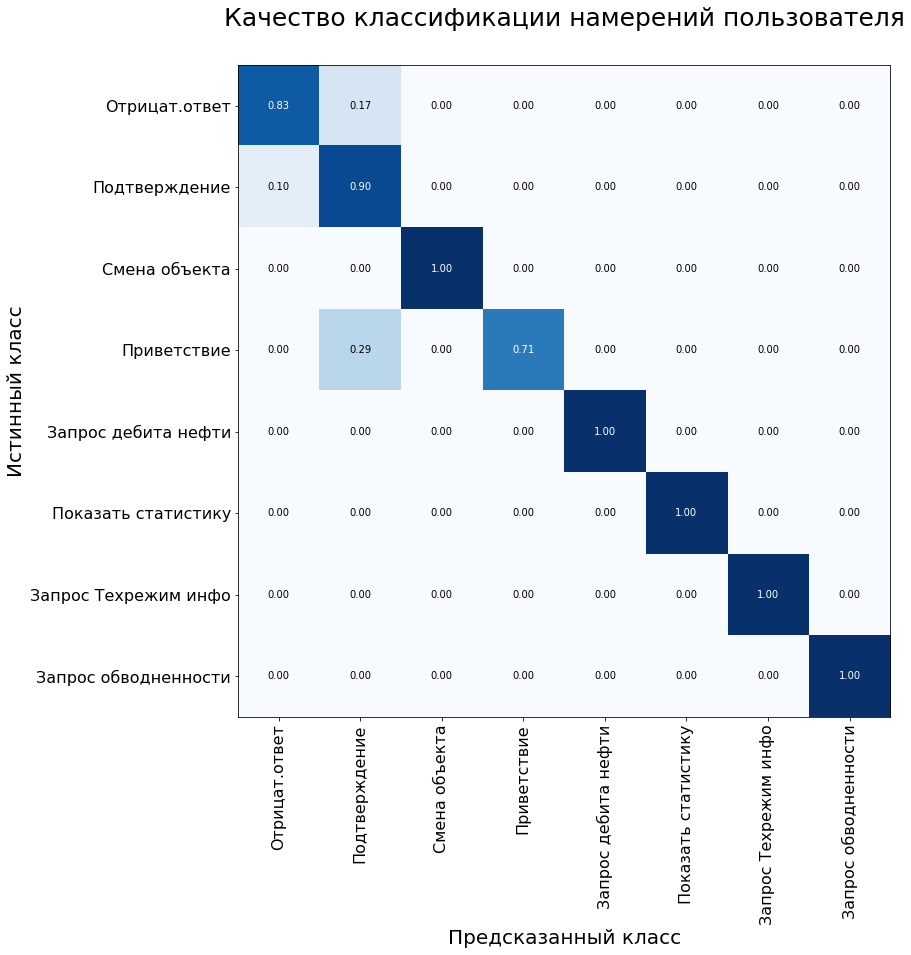
Métriques du modèle sur l'ensemble de données de test: Précision - 92%, F1 - 90%.
La deuxième tâche - la sélection des entités nommées - est d'identifier les mots et les phrases qui désignent un objet ou un phénomène spécifique. Ces entités peuvent être, par exemple, le nom d'un gisement ou d'une société minière.
Pour résoudre le problème, on a utilisé l'algorithme des champs aléatoires conditionnels, qui sont une sorte de champs de Markov. CRF est un modèle discriminant, c'est-à-dire qu'il modélise la probabilité conditionnelle P(Y | X) état latent Y (classe de mot) à partir de l'observation X (mot).
Pour répondre aux demandes des utilisateurs, notre assistant doit mettre en évidence trois types d'entités nommées: le nom du champ, le nom du puits et le nom de l'objet de développement. Pour entraîner le modèle, nous avons préparé un ensemble de données et fait une annotation: chaque mot de l'échantillon s'est vu attribuer une classe correspondante.

Un exemple de l'ensemble de formation pour le problème de reconnaissance d'entités nommées.
Cependant, tout s'est avéré pas si simple. Le jargon professionnel est assez courant chez les développeurs de terrain et les géologues. Il n'est pas difficile pour les gens de comprendre que «l'injecteur» est un puits d'injection, et «Samotlor», très probablement, signifie le champ Samotlor. Pour un modèle formé sur une quantité limitée de données, il est encore difficile de faire un tel parallèle. Pour faire face à cette limitation, une fonctionnalité aussi merveilleuse de la bibliothèque Rasa aide à créer un dictionnaire de synonymes.
## synonyme: Samotlor
- Samotlor
- Samotlor
- le plus grand champ pétrolifère de Russie
L'ajout de synonymes nous a également permis d'élargir légèrement l'échantillon. Le volume de l'ensemble de données était de 2000 demandes, que nous avons divisées en train et test dans un rapport 70/30. La qualité du modèle a été évaluée à l'aide de la métrique F1 et était de 98% lorsqu'elle était testée sur un échantillon témoin.
Exécution de la commande
En fonction de la classe de demande utilisateur définie à l'étape précédente, le système active la classe correspondante dans le noyau logiciel. Chaque classe a au moins deux méthodes: une méthode qui exécute directement la requête et une méthode pour générer une réponse pour l'utilisateur.
Par exemple, lorsqu'une commande est affectée à la classe "request_production_schedule", un objet de la classe RequestOilChart est créé, qui décharge les informations sur la production de pétrole de la base de données. Des entités nommées dédiées (par exemple, les noms de puits et de champs) sont utilisées pour remplir les emplacements dans les requêtes pour accéder à la base de données ou au noyau du logiciel. L'assistant répond à l'aide de modèles préparés, les espaces dans lesquels sont remplis les valeurs des données téléchargées.

Un exemple de prototype d'assistant fonctionnant.
Synthèse de discours

Fonctionnement de la synthèse vocale concaténative
Le texte de notification utilisateur généré à l'étape précédente est affiché à l'écran et est également utilisé comme entrée pour le module de synthèse vocale orale. La génération de la parole est effectuée à l'aide de la bibliothèque RHVoice... La licence GNU LGPL v2.1 permet d'utiliser le framework en tant que composant d'un logiciel commercial. Les principaux composants du système de synthèse vocale sont le processeur linguistique, qui traite le texte d'entrée. Le texte est normalisé: les nombres sont réduits à une représentation écrite, les abréviations sont déchiffrées, etc. Ensuite, à l'aide du dictionnaire de prononciation, une transcription du texte est créée, qui est ensuite transmise à l'entrée du processeur acoustique. Ce composant est responsable de la sélection des éléments sonores dans la base de données vocales, de la concaténation des éléments sélectionnés et du traitement du signal sonore.
Mettre tous ensemble
Ainsi, tous les composants de l'assistant vocal sont prêts. Il ne reste plus qu'à les «collecter» dans le bon ordre et à les tester. Comme nous l'avons mentionné précédemment, chaque module est un microservice. Le framework RabbitMQ est utilisé comme bus pour connecter tous les modules. L'illustration montre clairement le travail interne de l'assistant à l'aide de l'exemple d'une demande utilisateur type:
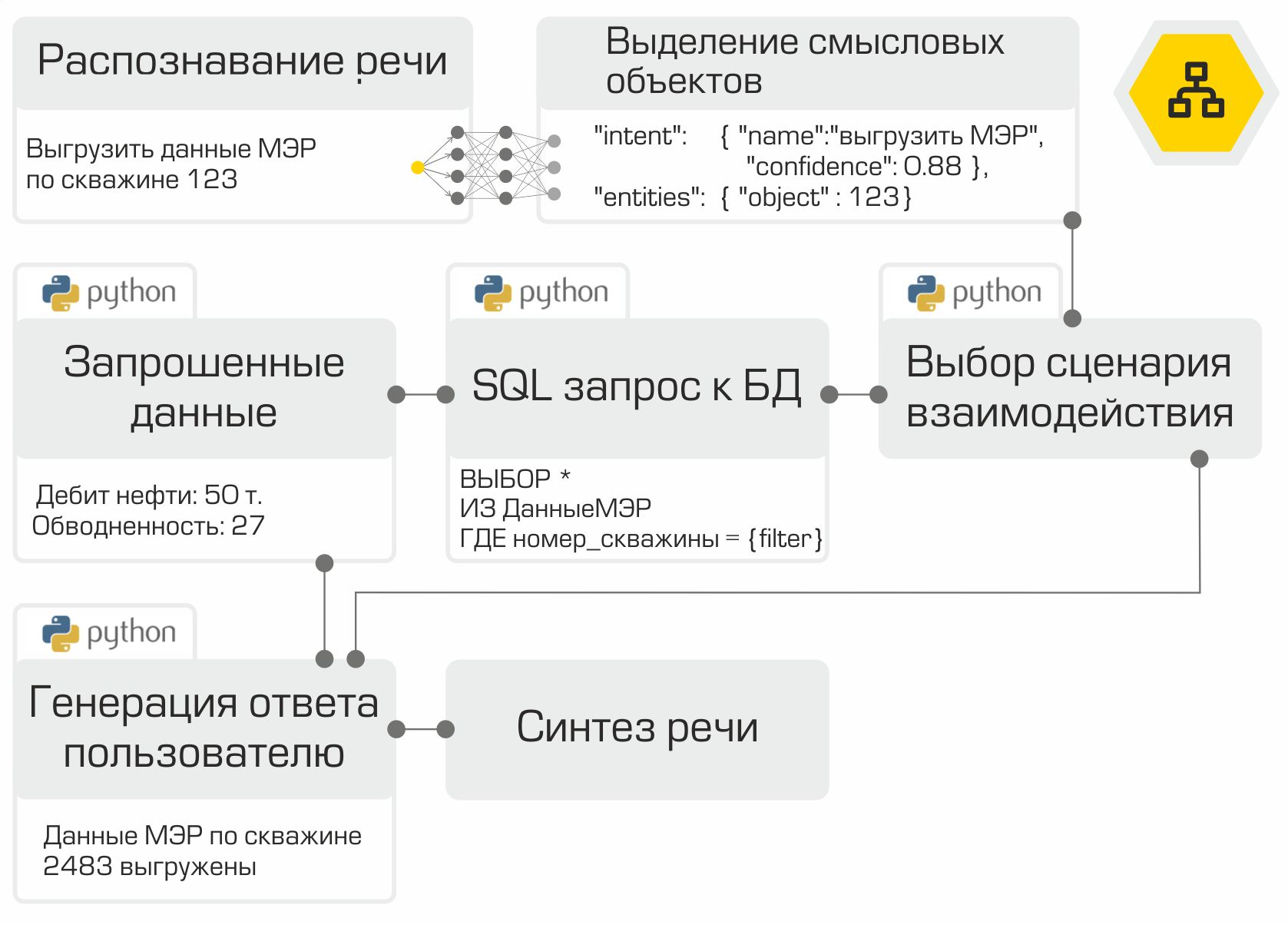
La solution créée permet de placer l'ensemble de l'infrastructure dans le réseau de l'entreprise. Le traitement local de l'information est le principal avantage du système. Cependant, vous devez payer pour l'autonomie car vous devez collecter des données, former et tester des modèles vous-même, et ne pas utiliser la puissance des meilleurs fournisseurs sur le marché des assistants numériques.
Pour le moment, nous intégrons l'assistant dans l'un des produits en cours de développement.
Comme il sera pratique de rechercher votre puits ou votre buisson préféré avec une seule phrase!
À l'étape suivante, il est prévu de collecter et d'analyser les commentaires des utilisateurs. Il est également prévu d'étendre les commandes reconnues et exécutées par l'assistant.
Le projet décrit dans l'article est loin d'être le seul exemple d'utilisation de méthodes d'apprentissage automatique dans notre entreprise. Ainsi, par exemple, l'analyse des données est utilisée pour sélectionner automatiquement des puits candidats pour des mesures géologiques et techniques, dont le but est de stimuler la production de pétrole. Dans l'un des articles à venir, nous vous expliquerons comment nous avons résolu ce problème sympa. Abonnez-vous à notre blog pour ne pas le rater!