
D'un point de vue architectural, la plateforme IoT nécessite la résolution des tâches suivantes:
- La quantité de données reçues, reçues et traitées nécessite une bande passante, un stockage et une puissance de calcul élevés.
- Les appareils peuvent être répartis sur une vaste zone géographique
- Les entreprises exigent que leur architecture évolue constamment pour que de nouveaux services puissent être proposés aux clients.
L'une des fonctionnalités de la plateforme IoT est l'indépendance entre les objets et les signaux, qui permet des calculs parallèles, augmentant ainsi la productivité.
Les données des capteurs sont collectées à partir de sources: PLC, DCS, microcontrôleurs, etc. et peuvent être stockées dans le domaine temporel pour éviter la perte de données due à des problèmes de connexion. Les données peuvent être des séries chronologiques (événements), des données semi-structurées (journaux et binaires) ou des données non structurées (images). Les données et événements de séries chronologiques sont collectés fréquemment (de chaque seconde à plusieurs minutes). Ils sont ensuite envoyés sur le réseau et stockés dans un lac de données centralisé et une base de données chronologique TSDB. Le lac de données peut être basé sur le cloud, un centre de données local ou un stockage tiers.
Les données peuvent être traitées immédiatement à l'aide d'une analyse de flux de données appelée "hot path" avec un mécanisme de vérification des règles basé sur un point de consigne simple ou intelligent. L'analyse avancée peut inclure des jumeaux numériques, l'apprentissage automatique, l'apprentissage en profondeur ou l'analyse basée sur la physique. Un tel système peut traiter une grande quantité de données (de dix minutes à un mois) provenant de différents capteurs. Ces données sont stockées dans un stockage intermédiaire. Cette analyse est appelée «chemin froid» et est généralement lancée par le planificateur ou lorsque des données sont disponibles et nécessitent beaucoup de ressources informatiques. Les analyses avancées ont souvent besoin d'informations supplémentaires telles que le modèle de véhicule surveillé et les attributs opérationnels, qui se trouvent dans le registre des actifs.Le registre des actifs contient des informations sur le type d'actif, notamment son nom, son numéro de série, son nom symbolique, son emplacement, ses capacités opérationnelles, l'historique des pièces qui le composent et le rôle qu'il joue dans le processus de fabrication. Dans le registre des actifs, nous pouvons stocker une liste des dimensions de chaque actif, nom logique, unité de mesure et plage de limites. Dans le secteur industriel, ces informations statiques sont essentielles pour un modèle analytique correct.Dans le secteur industriel, ces informations statiques sont essentielles pour un modèle analytique correct.Dans le secteur industriel, ces informations statiques sont essentielles pour un modèle analytique correct.
Raisons de développer une plateforme personnalisée:
- Retour sur investissement: petit budget;
- Technologie: utilisation de la technologie quel que soit le fournisseur;
- Confidentialité des données;
- Intégration: la nécessité de développer un niveau d'intégration avec une plateforme nouvelle ou obsolète;
- Autres restrictions.
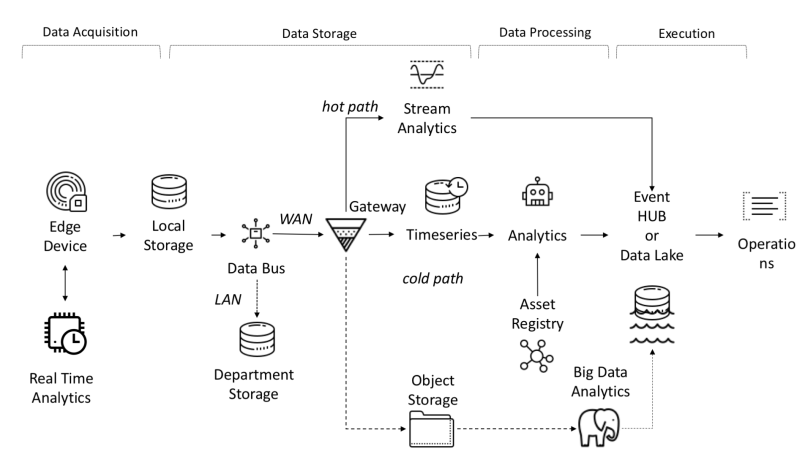
Flux de données de bout en bout dans I-IoT
Exemple d'implémentation personnalisée de la plateforme Edge
Cette figure montre l'implémentation des liens de plateforme suivants:
- Source de données: à titre d'exemple, un simulateur de contrôleur Simatic PLCSIM Advanced avec un serveur OPC activé est sélectionné, comme décrit dans l'article précédent;
- La plate-forme populaire Node-Red avec le plugin node-red-contrib-opcua installé a été choisie comme passerelle frontalière ;
- Le courtier MQTT Mosquitto est utilisé comme répartiteur pour le transfert de données entre d'autres liens dans le flux;
- Apache Kafka est utilisé comme plate-forme de diffusion en continu distribuée qui sert d'analyse de chemin d'accès à chaud à l'aide de flux kafka.
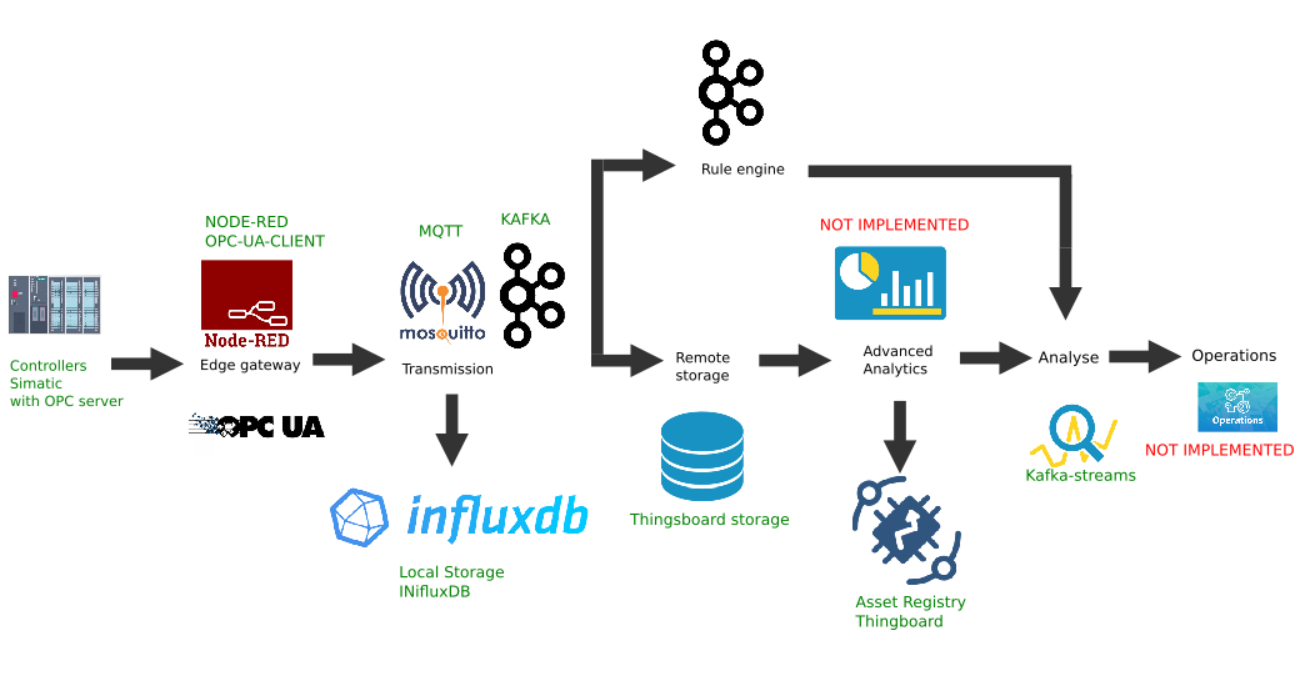
Passerelle Node-Red Edge
En tant que passerelle de calcul de périphérie, nous utiliserons Node-red, une plate-forme personnalisée simple qui a de nombreux plugins différents. Le rôle de l'adaptateur industriel est joué par le plugin node-red-contrib-opcua. Pour la collecte multiple de données du contrôleur par la méthode d'abonnement, les nœuds sont utilisés: OpcUa-Browser et OpcUa-client. Dans le nœud du navigateur OPC, l'url du serveur OPC (endpoint) et la rubrique sont configurées, ce qui spécifie l'espace de nom et le nom du bloc de données lisible, par exemple: ns = 3; s = "HMI_Alarms_Area". Dans le poste client OPC, l'url du serveur OPC est également spécifiée, l'ABONNE et l'intervalle de mise à jour des données sont définis comme Action.
Flux principal rouge nœud
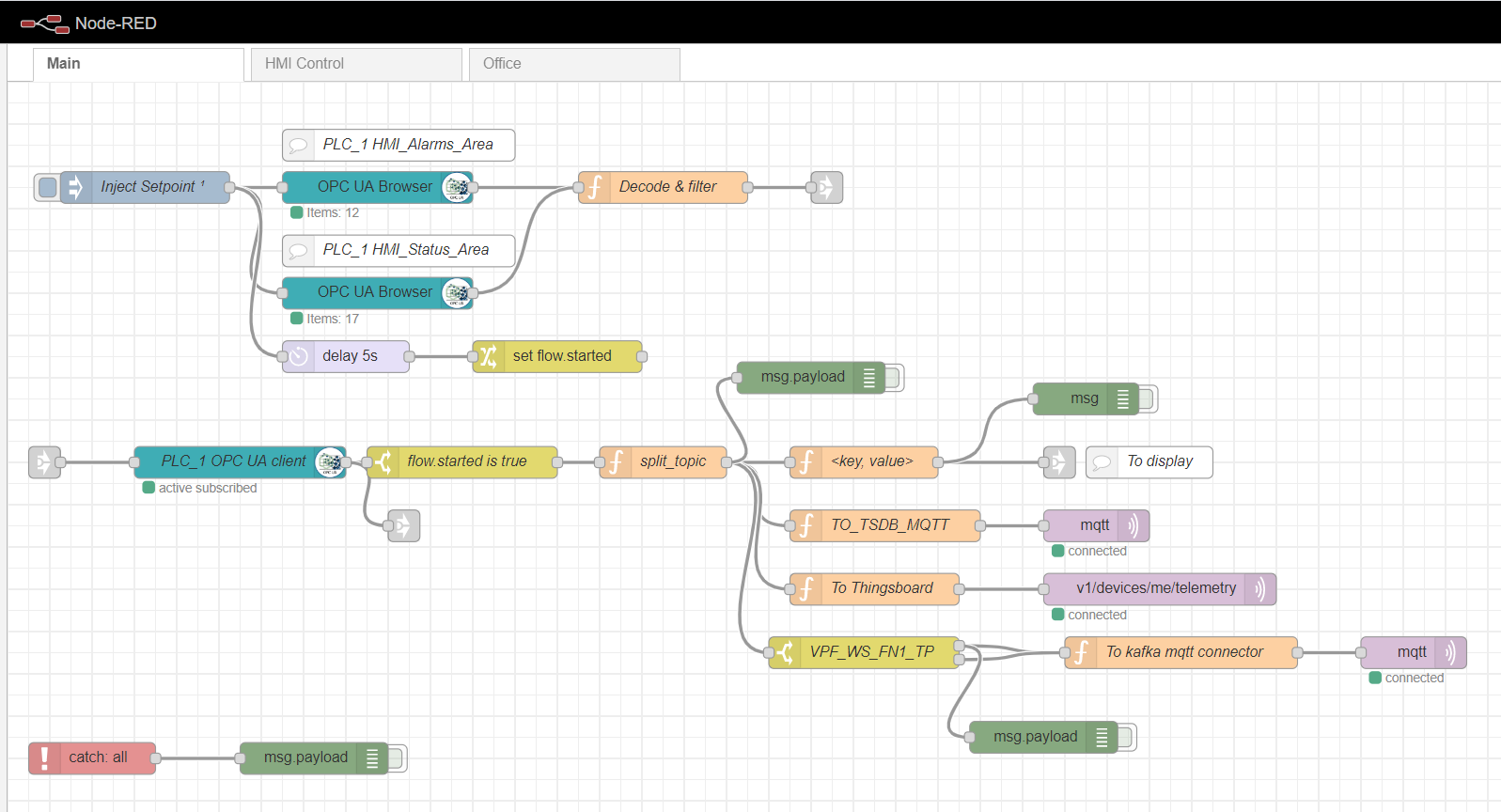
Configuration du nœud du navigateur OPC

OPC-client

Afin de s'abonner pour lire plusieurs données, il est nécessaire de préparer et de télécharger des variables depuis le contrôleur, conformément au protocole OPC. Pour ce faire, tout d'abord, un nœud d'injection est utilisé avec la case à cocher une seule fois, qui déclenche une lecture unique des blocs de données spécifiés dans les nœuds du navigateur OPC. Les données sont ensuite traitées par la fonction Décoder et filtrer. Ensuite, le poste client OPC s'abonne et lit les données modifiées à partir du contrôleur. Le traitement ultérieur du flux dépend de l'implémentation et des exigences spécifiques. Dans mon exemple, je traite les données pour les envoyer ultérieurement au courtier MQTT sur différents sujets.
Les onglets Contrôle IHM et Office sont une implémentation IHM simple basée sur Scadavis.io et un tableau de bord rouge comme décrit plus haut dans l'article .
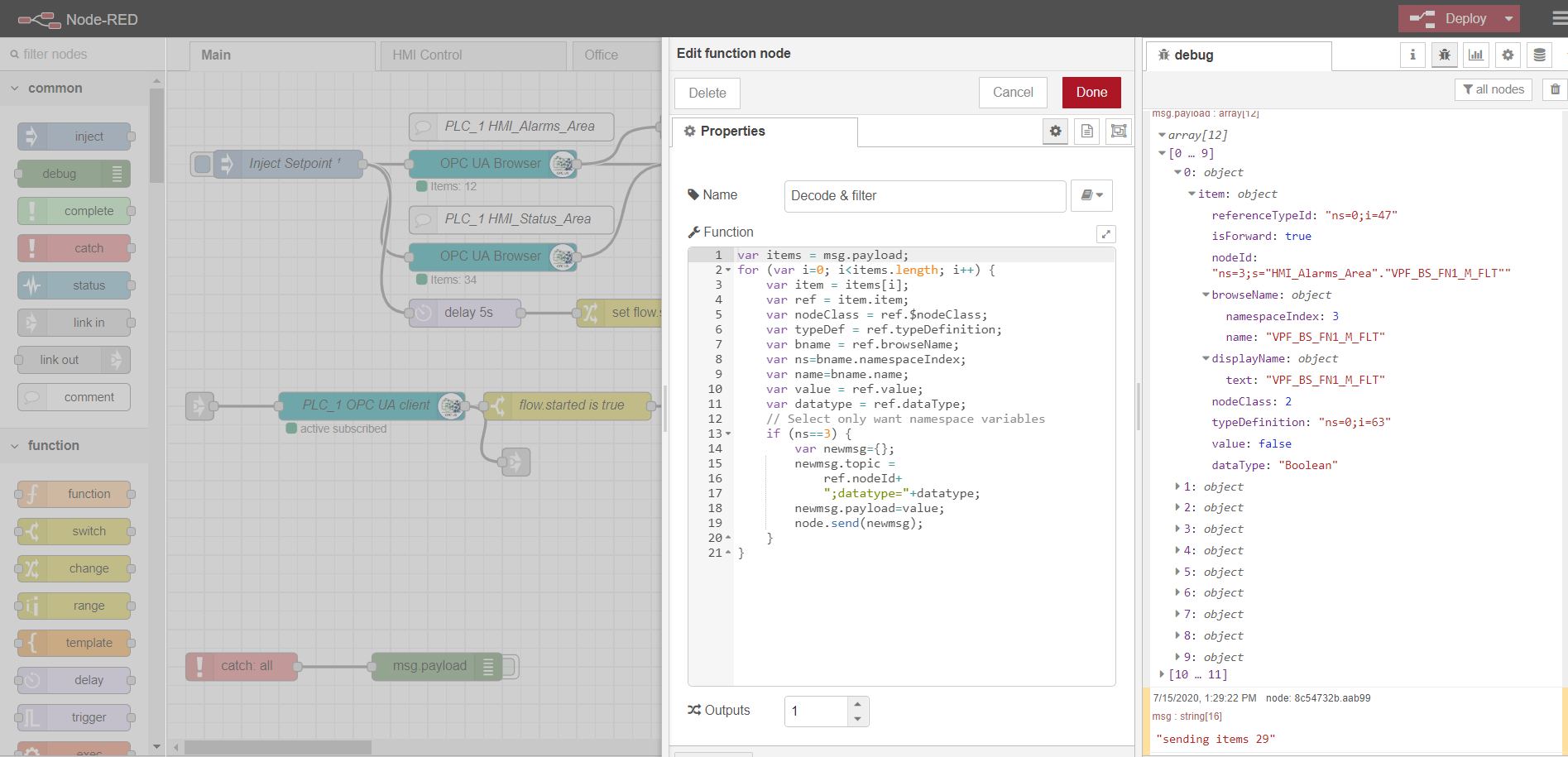
Un exemple d'analyse de données à partir d'un nœud de navigateur OPC:
var items = msg.payload;
for (var i=0; i<items.length; i++) {
var item = items[i];
var ref = item.item;
var nodeClass = ref.$nodeClass;
var typeDef = ref.typeDefinition;
var bname = ref.browseName;
var ns=bname.namespaceIndex;
var name=bname.name;
var value = ref.value;
var datatype = ref.dataType;
// Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
Courtier MQTT
Toute implémentation peut être utilisée comme courtier. Dans mon cas, le courtier Mosquitto est déjà installé et configuré . Le courtier remplit la fonction de transport des données entre la passerelle Edge et les autres participants de la plateforme. Il existe des exemples avec l'équilibrage de charge et l'architecture distribuée ( comme ici ). Dans ce cas, nous nous limiterons à un courtier mqtt avec transfert de données sans cryptage.
Stockage local des données de séries chronologiques
Il est pratique d'enregistrer et de stocker des données de séries chronologiques dans la base de données de séries chronologiques NoSql. La pile InfluxData fonctionne bien pour nos besoins . Nous avons besoin de quatre services de cette pile:
InfluxDB est une base de données de séries chronologiques open source qui fait partie de la pile TICK (Telegraf, InfluxDB, Chronograf, Kapacitor). Conçu pour le traitement de données à forte charge et fournit un langage de requête de type SQL InfluxQL pour interagir avec les données.
Telegraf est un agent de collecte et d'envoi de métriques et d'événements à InfluxDB à partir de systèmes IoT externes, de capteurs, etc. Il est configuré pour collecter des données à partir de rubriques mqtt.
Kapacitor est un moteur de données intégré pour InfluxDB 1.x et un composant intégré à la plate-forme InfluxDB. Ce service peut être configuré pour surveiller divers paramètres et alarmes, ainsi que pour installer un gestionnaire pour l'envoi d'événements à des systèmes externes tels que Kafka, e-mail, etc.
Chronograf est l'interface utilisateur et le composant administratif de la plateforme InfluxDB. Utilisé pour créer rapidement des tableaux de bord avec une visualisation en temps réel.
Tous les composants de la pile peuvent être exécutés localement ou configurer un conteneur Docker.
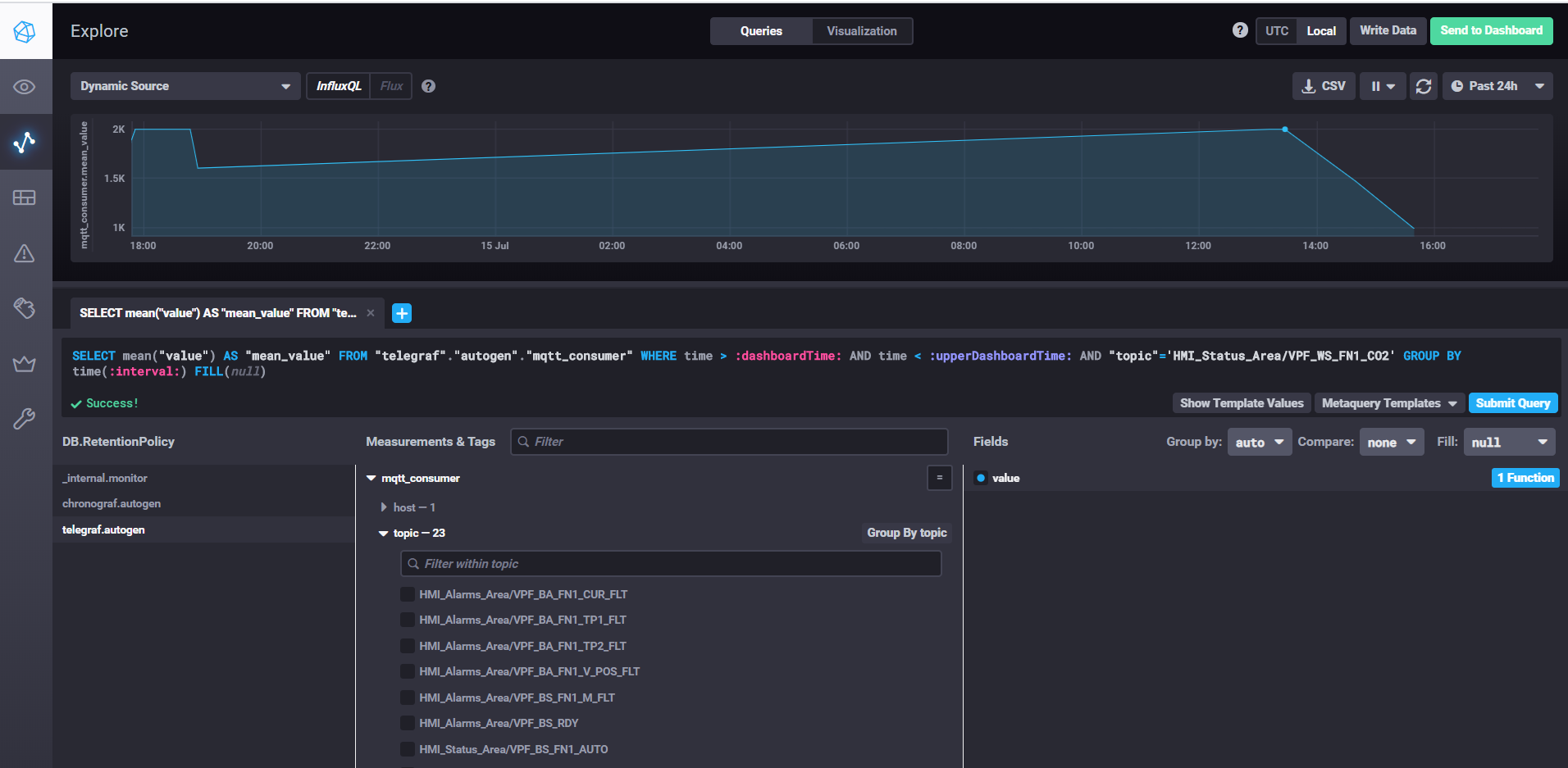
Récupération des données et personnalisation des tableaux de bord avec Chronograf
Pour démarrer InfluxDB, exécutez simplement la commande influxd, dans les paramètres influxdb.conf, vous pouvez spécifier l'emplacement de stockage et d'autres propriétés, par défaut les données sont stockées dans le répertoire utilisateur dans le répertoire .influxdb.
Pour démarrer telegraf, vous devez exécuter la commande telegraf -config telegraf.conf, où vous pouvez spécifier les sources des métriques et des événements dans les paramètres, dans notre exemple pour mqtt cela ressemble à ceci:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
Dans la propriété servers, nous spécifions l'url du courtier mqtt, qos peut laisser 0 s'il suffit d'écrire des données sans confirmation. Dans la propriété topics, spécifiez les masques mqtt des sujets à partir desquels nous lirons les données. Par exemple, HMI_Status_Area / # signifie que nous lisons toutes les rubriques qui ont le préfixe HMI_Status_Area. Ainsi, telegraf pour chaque sujet créera sa propre métrique dans la base de données, où il écrira des données.
Pour démarrer kapacitor, vous devez exécuter la commande kapacitord -config kapacitor.conf. Les propriétés peuvent être laissées par défaut et d'autres réglages peuvent être effectués avec chronograf.
Pour démarrer chronograf, exécutez simplement la commande chronograf du même nom. L'interface Web sera disponible localhost : 8888 /
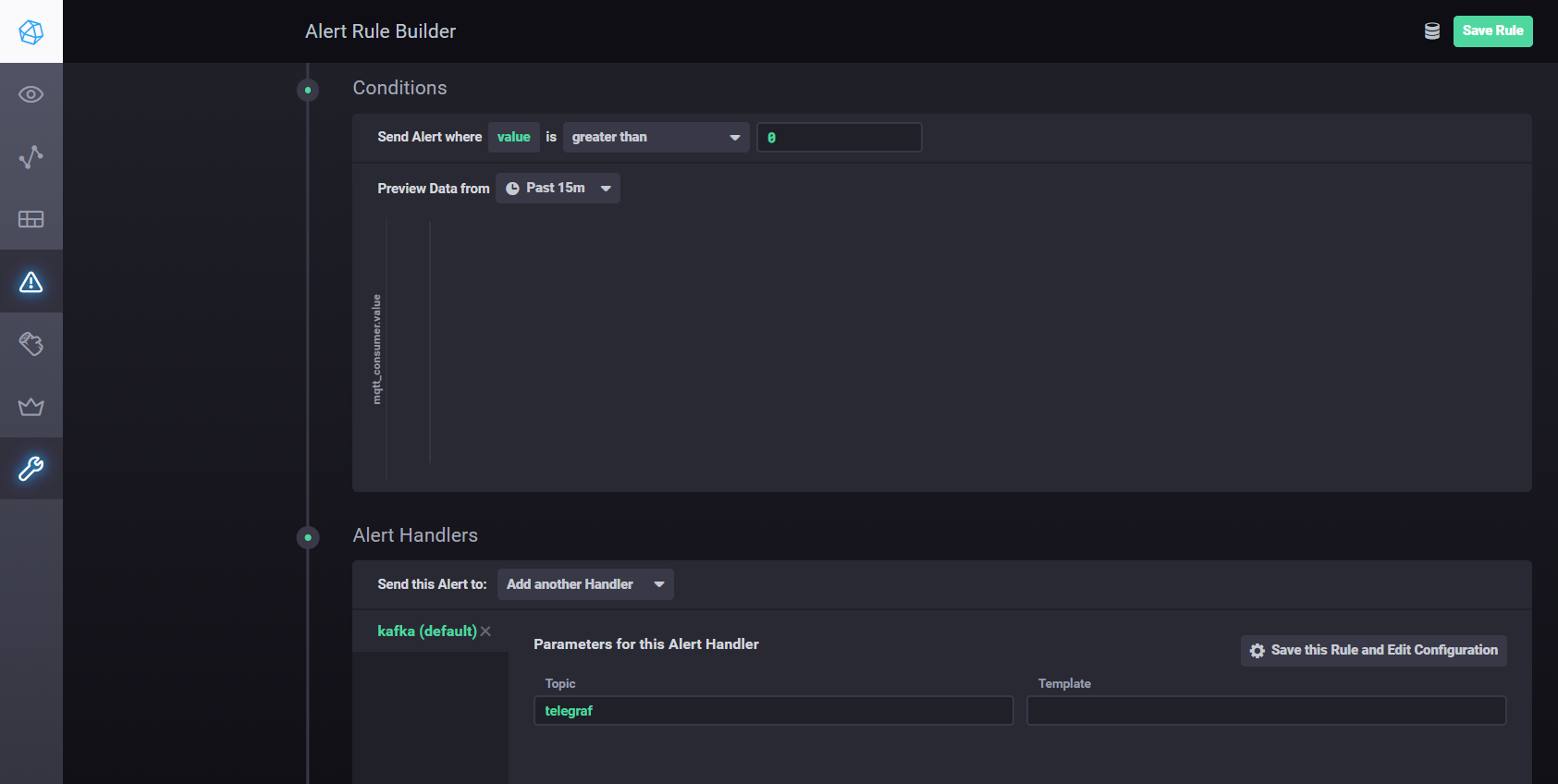
Pour configurer les paramètres et les alarmes à l'aide de Kapacitor, vous pouvez utilisermanuel . En bref - vous devez aller dans l'onglet Alerte dans Chronograf et créer une nouvelle règle à l'aide du bouton Créer une règle d'alerte, l'interface est intuitive, tout se fait visuellement. Pour configurer l'envoi des résultats du traitement à kafka, etc. vous devez ajouter un gestionnaire dans la section Conditions
Paramètres du gestionnaire Kapacitor
Diffusion distribuée avec Apache Kafka
Pour l'architecture proposée, il est nécessaire de séparer la collecte des données du traitement, ce qui améliore l'évolutivité et l'indépendance des couches. Nous pouvons utiliser une file d'attente pour atteindre cet objectif. L'implémentation peut être Java Message Service (JMS) ou Advanced Message Queuing Protocol (AMQP), mais dans ce cas, nous utiliserons Apache Kafka. Kafka est pris en charge par la plupart des plates-formes d'analyse, offre des performances et une évolutivité très élevées et dispose d'une bonne bibliothèque de flux Kafka.
Vous pouvez utiliser le plugin Node-red node-red-contrib-kafka-manager pour interagir avec Kafka . Mais, en tenant compte de la séparation de la collecte du traitement des données, nous installerons le plugin MQTT, qui s'abonne aux sujets Mosquitto. Le plugin MQTT est disponible ici .
Pour configurer le connecteur, copiez les bibliothèques kafka-connect-mqtt-1.1-SNAPSHOT.jar et org.eclipse.paho.client.mqttv3-1.0.2.jar (ou une autre version) dans le répertoire kafka / libs /. Ensuite, dans le répertoire / config, vous devez créer un fichier de propriétés mqtt.properties avec le contenu suivant:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
Après avoir précédemment lancé zookeeper-server et kafka-server, nous pouvons démarrer le connecteur en utilisant la commande:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
À partir de la rubrique mqtt (mqtt.topic = mqtt), les données seront écrites dans la rubrique streams-measures Kafka (kafka.topic = streams-measures).
À titre d'exemple simple, vous pouvez créer un projet maven à l'aide de la bibliothèque kafka-streams.
À l'aide de kafka-streams, vous pouvez implémenter divers services et scénarios pour l'analyse à chaud et le traitement des données en continu.
Un exemple de comparaison de la température actuelle avec le point de consigne pour la période.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-measures");
KStream<Windowed<String>, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed<String> key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde<String> STRING_SERDE = Serdes.String();
final Serde<Windowed<String>> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
Registre des actifs
Le registre d'actifs, en fait, n'est pas un composant structurel de la plate-forme Edge et fait partie de l'environnement IoT cloud. Mais cet exemple montre comment Edge et Cloud interagissent.
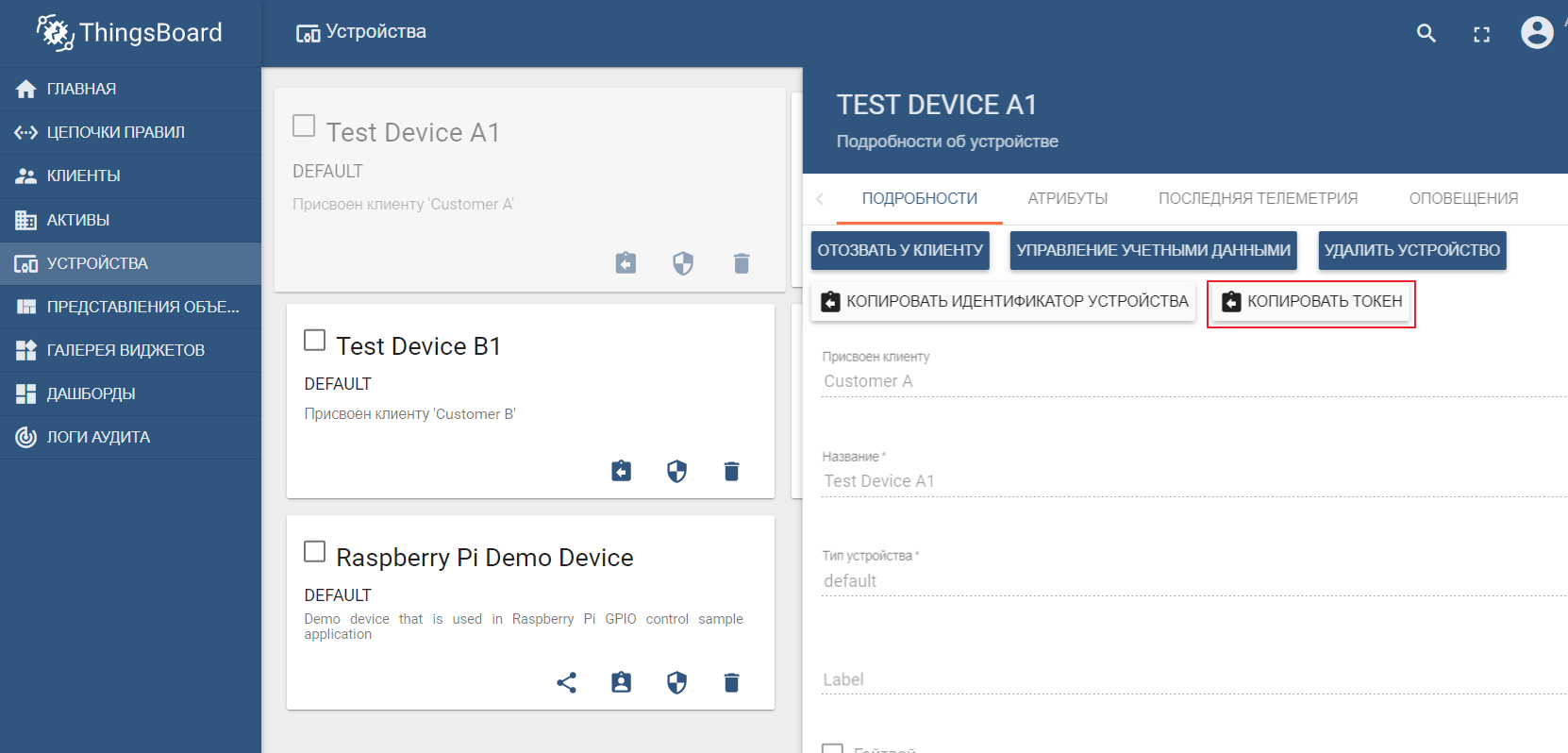
En tant que registre d'actifs, nous utiliserons la populaire plate-forme ThingsBoard IoT, dont l'interface est également assez intuitive. L'installation est possible avec des données de démonstration. La plate-forme peut être installée localement, dans docker ou à l'aide d'un environnement cloud prêt à l'emploi .
L'ensemble de données de démonstration comprend des appareils de test (vous pouvez facilement en créer un nouveau) auxquels vous pouvez envoyer des valeurs. Par défaut ThingsBoard commence avec son propre courtier mqtt, auquel vous devez vous connecter et envoyer des donnéesau format json. Disons que nous voulons envoyer des données à ThingsBoard à partir de TEST DEVICE A1. Pour ce faire, nous devons nous connecter au courtier ThingBoard sur localhost: 1883 en utilisant A1_TEST_TOKEN comme connexion, qui peut être copiée à partir des paramètres de l'appareil. Ensuite, nous pouvons publier les données dans la rubrique v1 / devices / me / telemetry: {"temperature": 26}
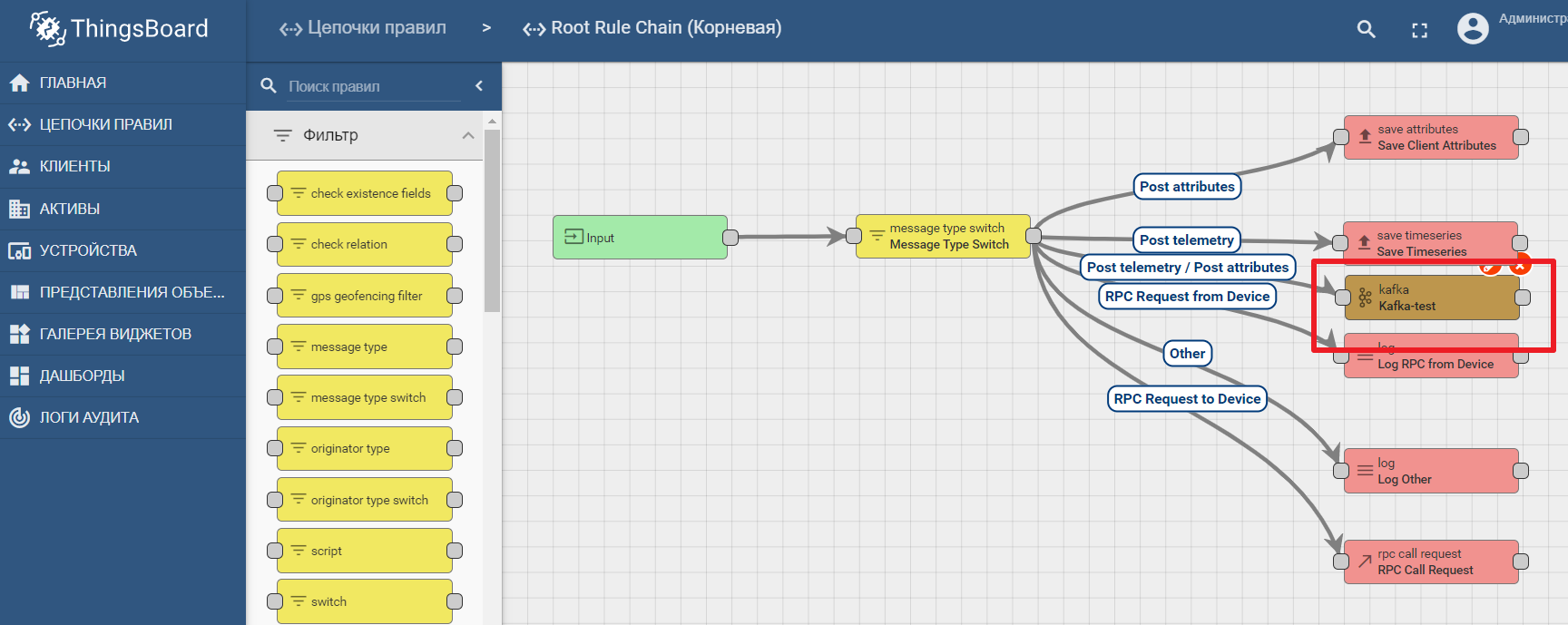
La documentation de la plate-forme contient un manuel pour configurer le transfert de données et traiter les analyses dans Kafka - Analyse des données IoT à l'aide de Kafka, Kafka Streams et ThingsBoard
Un exemple d'utilisation d'un nœud kafka dans Thingsboard
Conclusion
Les technologies informatiques modernes et les protocoles ouverts permettent de concevoir des systèmes de toute complexité. La plate-forme de périphérie est le point de connexion entre l'environnement industriel et la plate-forme IoT basée sur le cloud. Il peut être décomposé en macrocomposants, parmi lesquels la passerelle de périphérie joue un rôle clé, responsable du transfert des données des appareils vers le hub de données IoT. Les outils de streaming de données ouvertes permettent des analyses et un calcul de périphérie efficaces.