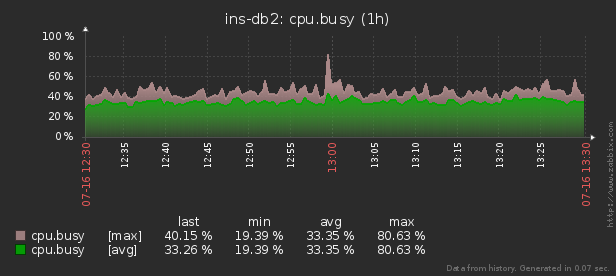
Par conséquent, lorsqu'une consommation anormale de ressources (CPU, mémoire, disque, réseau, ...) se produit sur l'un des milliers de serveurs contrôlés , il est nécessaire de déterminer «qui est à blâmer et quoi faire».
L' utilitaire pidstat est disponible pour la surveillance en temps réel de l'utilisation des ressources du serveur Linux "pour le moment" . Autrement dit, si les pics de charge sont périodiques, ils peuvent être «hachurés» directement dans la console. Mais nous voulons analyser ces données après coup , en essayant de trouver le processus qui a créé la charge maximale sur les ressources.
Autrement dit, j'aimerais pouvoir examiner les données précédemment collectées, divers beaux rapports avec un regroupement et des détails sur un intervalle tel que celui-ci:
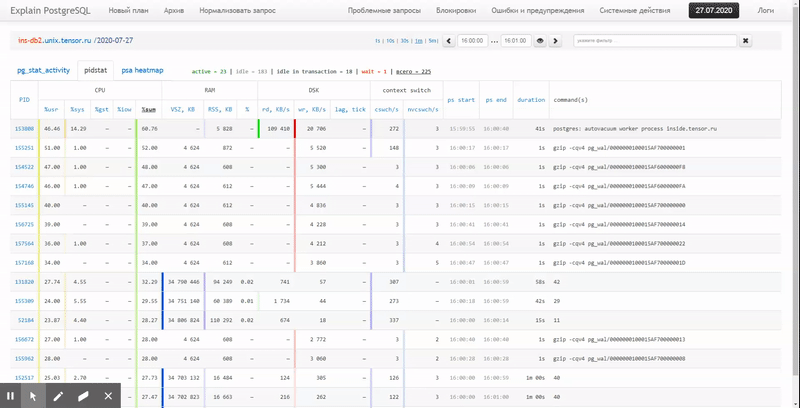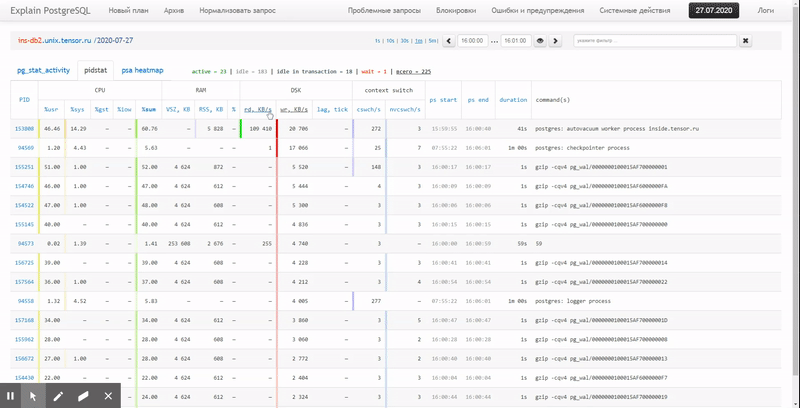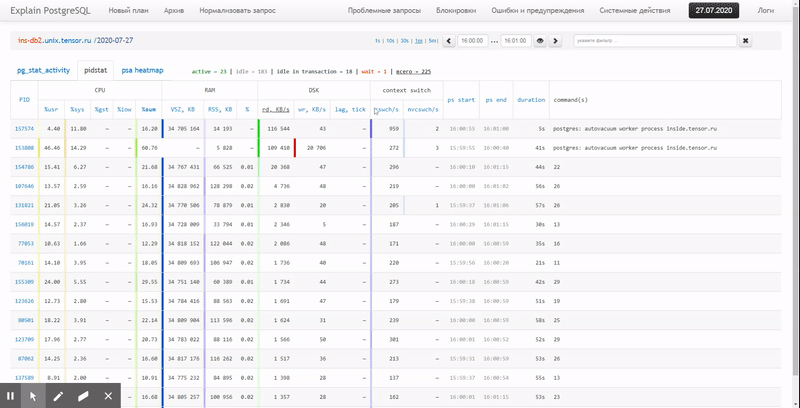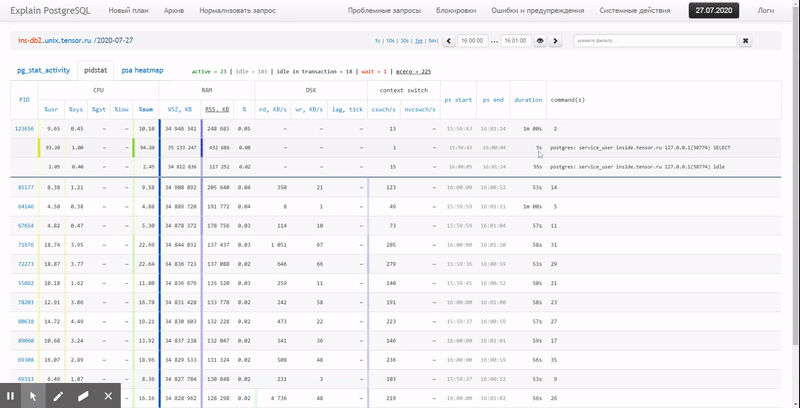
Dans cet article, nous examinerons comment tout cela peut être économiquement localisé dans la base de données et comment collecter le plus efficacement un rapport à partir de ces données à l'aide des fonctions de fenêtre et GROUPEMENT D'ENSEMBLES .
Voyons d'abord quel type de données nous pouvons extraire si nous prenons «tout au maximum»:
pidstat -rudw -lh 1| Temps | UID | PID | % usr | % système | % invité | % CPU | CPU | minflt / s | majflt / s | VSZ | RSS | % MEM | kB_rd / s | kB_wr / s | kB_ccwr / s | cswch / s | nvcswch / s | Commander |
| 1594893415 | 0 | 1 | 0,00 | 13.08 | 0,00 | 13.08 | 52 | 0,00 | 0,00 | 197312 | 8512 | 0,00 | 0,00 | 0,00 | 0,00 | 0,00 | 7,48 | / usr / lib / systemd / systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | neuf | 0,00 | 0,93 | 0,00 | 0,93 | 40 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 350,47 | 0,00 | rcu_sched |
| 1594893415 | 0 | treize | 0,00 | 0,00 | 0,00 | 0,00 | 1 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 1,87 | 0,00 | migration / 11.87 |
Toutes ces valeurs sont divisées en plusieurs classes. Certains d'entre eux changent constamment (activité du processeur et du disque), d'autres rarement (allocation de mémoire), et la commande change non seulement rarement dans le même processus, mais se répète également régulièrement sur différents PID.
Structure de base
Par souci de simplicité, limitons-nous à une métrique pour chaque "classe" que nous allons enregistrer:% CPU, RSS et Command.
Puisque nous savons à l'avance que la commande est répétée régulièrement, nous la déplacerons simplement dans un dictionnaire de table séparé, où le hachage MD5 agira comme la clé UUID:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);Et pour les données elles-mêmes, un tableau du type suivant nous convient:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);Permettez-moi d'attirer votre attention sur le fait que puisque% CPU nous arrive toujours avec une précision de 2 décimales et ne dépasse certainement pas 100,00, nous pouvons facilement le multiplier par 100 et le mettre
smallint. D'une part, cela nous évitera les problèmes de précision comptable lors des opérations, d'autre part, il est toujours préférable de ne stocker que 2 octets contre 4 realou 8 octets double precision.
Vous pouvez en savoir plus sur les moyens de regrouper efficacement les enregistrements dans le stockage PostgreSQL dans l'article «Économisez un joli centime sur de gros volumes» et sur l'augmentation du débit de la base de données pour l'écriture - dans «Écriture sur sous-lumière: 1 hôte, 1 jour, 1 To» .
Stockage "gratuit" de NULL
Pour sauvegarder les performances du sous-système de disque de notre base de données et le volume occupé par la base de données, nous essaierons de représenter autant de données que possible sous la forme de NULL - leur stockage est pratiquement "gratuit", car il ne prend qu'un bit dans l'en-tête d'enregistrement.
Plus d'informations sur la mécanique interne de la représentation des enregistrements dans PostgreSQL peuvent être trouvées dans le discours de Nikolai Shaplov à PGConf.Russia 2016 "Ce qu'il y a dedans: stockage de données à un bas niveau . " La diapositive n ° 16 est consacrée au stockage NULL .Examinons de plus près les types de nos données:
- CPU / DSK
Change constamment, mais tourne très souvent à zéro - il est donc avantageux d'écrire NULL au lieu de 0 dans la base . - RSS / CMD
Modifie assez rarement - nous écrirons donc NULL au lieu de répétitions dans le même PID.
Il en résulte une image comme celle-ci, si vous la regardez dans le contexte d'un PID spécifique:

il est clair que si notre processus commence à exécuter une autre commande, la valeur de la mémoire utilisée sera probablement également différente de celle d'avant - nous conviendrons donc que lors du changement de CMD, la valeur de RSS sera également corriger quelle que soit la valeur précédente.
Autrement dit , une entrée avec une valeur CMD remplie a également une valeur RSS . Souvenons-nous de ce moment, il nous sera encore utile.
Préparer un beau rapport
Créons maintenant une requête qui nous montrera les consommateurs de ressources d'un hôte spécifique à un intervalle de temps spécifique.
Mais faisons-le tout de suite avec une utilisation minimale des ressources - similaire à l'article sur SELF JOIN et les fonctions de fenêtre .
Utilisation des paramètres entrants
Afin de ne pas spécifier les valeurs des paramètres du rapport (ou $ 1 / $ 2) à plusieurs endroits pendant la requête SQL, nous sélectionnons le CTE dans le seul champ json dans lequel ces paramètres sont localisés par des clés:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
Récupération des données brutes
Comme nous n'avons inventé aucun agrégat complexe, la seule façon d'analyser les données est de les lire. Pour cela, nous avons besoin d'un index évident:
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
Regroupement des clés d'analyse
Pour chaque PID trouvé, nous déterminons l'intervalle de son activité et prenons CMD à partir du premier enregistrement de cet intervalle.
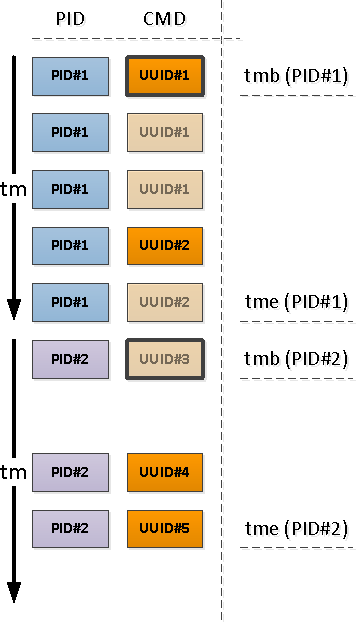
Pour ce faire, nous utiliserons les fonctions uniques de traversée
DISTINCT ONet de fenêtre:
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
Limites d'activité de processus
Notez que par rapport au début de notre intervalle, le premier enregistrement qui apparaît peut être soit celui qui a déjà un champ CMD rempli (PID # 1 dans l'image ci-dessus), soit avec NULL, indiquant la continuation de la valeur «ci-dessus» remplie dans la chronologie (PID # 2 ).
Ceux des PID qui ont été laissés sans CMD à la suite de l'opération précédente ont commencé plus tôt que le début de notre intervalle, ce qui signifie que ces "débuts" doivent être trouvés:

puisque nous savons avec certitude que le segment d'activité suivant commence par une valeur CMD remplie (et il y a un RSS rempli, donc ), l'index conditionnel nous aidera ici:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
Si nous voulons (et nous voulons) connaître l'heure de fin de l'activité du segment, alors pour chaque PID nous devrons utiliser un "bidirectionnel" pour déterminer la limite inférieure.
Nous avons déjà utilisé une technique similaire dans l'article PostgreSQL Antipatterns: Registry Navigation .

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
Conversion JSON des formats de publication
Notez que nous avons sélectionné
precmd/pstcmduniquement les champs qui affectent les lignes suivantes, et tout processeur / DSK qui change constamment - non. Par conséquent, le format des enregistrements dans la table d'origine et ces CTE diffère pour nous. Aucun problème!
- row_to_json - transforme chaque enregistrement avec des champs en un objet json
- array_agg - collecte toutes les entrées dans '{...}' :: json []
- array_to_json - convertit array-from-JSON en JSON-array '[...]' :: json
- json_populate_recordset - génère une sélection d'une structure donnée à partir d'un tableau JSON
Ici, nous utilisons un seul appelNous collons les "débuts" et "fins" trouvés dans un tas commun et ajoutons à l'ensemble original d'enregistrements:json_populate_recordsetau lieu d'un multiplejson_populate_record, car il est parfois plus rapide.
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
Combler les lacunes nulles
Utilisons le modèle présenté dans l'article "SQL HowTo: Build Chains with Window Functions" .Commençons par sélectionner les groupes "répéter":
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
De plus, selon CMD et RSS, les groupes seront indépendants les uns des autres, ils peuvent donc ressembler à ceci:
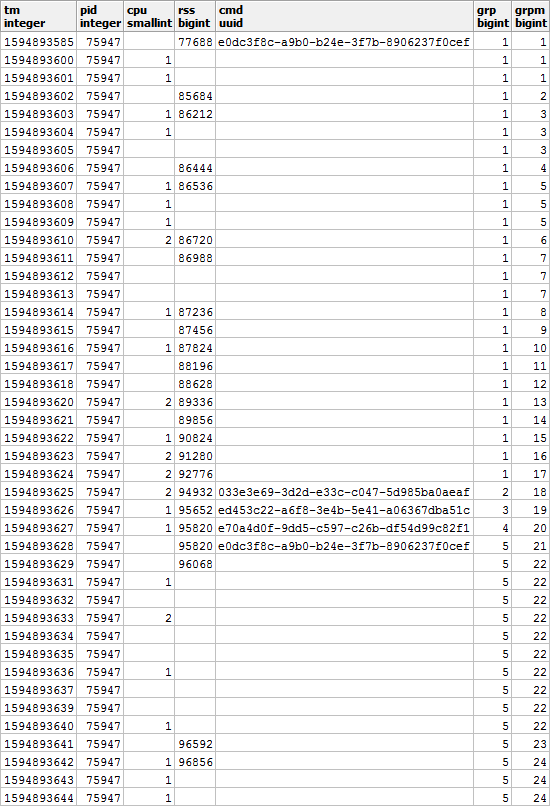
comblez les lacunes en RSS et calculez la durée de chaque segment afin de prendre correctement en compte la répartition de la charge dans le temps:
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
Multi-grouping avec GROUPING SETS
Puisque nous voulons voir en conséquence à la fois un résumé de l'ensemble du processus et ses détails par différents segments d'activité, nous utiliserons le regroupement par plusieurs jeux de clés à la fois en utilisant GROUPING SETS :
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
Le cas d'utilisation (array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]nous permet d'obtenir la première valeur non vide (même si ce n'est pas la toute première) de l'ensemble entier dès le regroupement, sans mouvements corporels supplémentaires .La possibilité d'obtenir plusieurs sections de l'échantillon cible à la fois est très pratique pour générer divers rapports avec des détails, de sorte que toutes les données de détail n'aient pas besoin d'être reconstruites, mais qu'elles apparaissent dans l'interface utilisateur avec l'échantillon principal.
Dictionnaire au lieu de JOIN
Créez un "dictionnaire" CMD pour tous les segments trouvés:
Vous pouvez en savoir plus sur la technique de "mastering" dans l'article "Antipatterns PostgreSQL: Frappons une jointure lourde avec un dictionnaire" .
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
Et maintenant, nous l'utilisons à la place
JOIN, obtenant les "belles" données finales:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;
Enfin, assurons-nous que l'ensemble de notre requête s'est avéré assez léger lors de son exécution:

[regardez explic.tensor.ru]
Seulement 44 ms et 33 Mo de données ont été lus!