salut! Il est difficile de trouver un programmeur de microcontrôleur qui n'ait jamais rencontré de panne grave. Très souvent, il n'est en aucun cas traité, mais reste simplement suspendu dans une boucle sans fin du gestionnaire fourni dans le fichier de démarrage du fabricant. Dans le même temps, le programmeur essaie de trouver intuitivement la raison de l'échec. À mon avis, ce n'est pas la meilleure façon de résoudre le problème.
Dans cet article, je souhaite décrire une technique pour analyser les défaillances graves des microcontrôleurs populaires avec un noyau Cortex M3 / M4. Bien que, peut-être, «technique» soit un mot trop fort. Je vais plutôt prendre un exemple de la façon dont j'analyse l'occurrence de pannes graves et montre ce qui peut être fait dans une situation similaire. J'utiliserai le logiciel IAR et la carte de débogage STM32F4DISCOVERY, car de nombreux programmeurs en herbe ont ces outils. Cependant, ceci est totalement hors de propos, cet exemple peut être adapté à tout processeur de la famille et à tout environnement de développement.

Tomber dans HardFault
Avant d'essayer d'analyser HatdFault, vous devez y entrer. Il existe de nombreuses façons de procéder. Il m'est immédiatement venu à l'esprit d'essayer de faire passer le processeur de l'état Thumb à l'état ARM en définissant l'adresse de l'instruction de saut inconditionnel sur un nombre pair.
Une petite digression. Comme vous le savez, les microcontrôleurs de la famille Cortex M3 / M4 utilisent le jeu d'instructions d'assemblage Thumb-2 et fonctionnent toujours en mode Thumb. Le mode ARM n'est pas pris en charge. Si vous essayez de définir la valeur de l'adresse de saut inconditionnel (reg BX) avec le bit le moins significatif effacé, l'exception UsageFault se produira, car le processeur tentera de basculer son état sur ARM. Vous pouvez en savoir plus à ce sujet dans [1] (clauses 2.8 THE INSTRUCTION SET; 4.3.4 Assembler Language: Call and Unconditional Branch).
Pour commencer, je propose de simuler un saut inconditionnel vers une adresse paire en C / C ++. Pour ce faire, je vais créer la fonction func_hard_fault, puis je vais essayer de l'appeler par pointeur, après avoir diminué l'adresse du pointeur de un. Cela peut être fait comme suit:
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //
ptr_hard_fault_func = reinterpret_cast<void(*)()>(reinterpret_cast<uint8_t *>(func_hard_fault) - 1); //
ptr_hard_fault_func(); //
while(1) continue;
}
void func_hard_fault(void) //,
{
while(1) continue;
}
Voyons avec le débogueur ce que j'ai fait.

En rouge, j'ai mis en évidence l'instruction de saut actuelle à l'adresse dans RON R1, qui contient une adresse de saut pair. En conséquence:

Cette opération peut être effectuée encore plus simplement à l'aide d'inserts assembleur:
void main(void)
{
//
asm("LDR R1, =0x0800029A"); //- f
asm("BX r1"); // R1
while(1) continue;
}
Hourra, nous sommes entrés dans HardFault, mission terminée!
Analyse HardFault
Où en sommes-nous arrivés à HardFault?
À mon avis, le plus important est de savoir d'où nous sommes arrivés à HardFault. Ce n'est pas difficile à faire. Tout d'abord, écrivons notre propre gestionnaire pour la situation HardFault.
extern "C"
{
void HardFault_Handler(void)
{
}
}Voyons maintenant comment comprendre comment nous sommes arrivés ici. Le cœur du processeur Cortex M3 / M4 a une chose aussi merveilleuse que la préservation du contexte [1] (clause 9.1.1 Empilement). En termes simples, lorsqu'une exception se produit, le contenu des registres R0-R3, R12, LR, PC, PSR est stocké sur la pile.

Ici, le registre le plus important pour nous sera le registre PC, qui contient des informations sur l'instruction en cours d'exécution. Puisque la valeur du registre a été poussée sur la pile au moment de l'exception, elle contiendra l'adresse de la dernière instruction exécutée. Le reste des registres est moins important pour l'analyse, mais quelque chose d'utile peut leur être arraché. LR est l'adresse de retour de la dernière transition, R0-R3, R12 sont des valeurs qui peuvent dire dans quelle direction se déplacer, PSR n'est qu'un registre général de l'état du programme.
Je propose de connaître les valeurs des registres dans le gestionnaire. Pour ce faire, j'ai écrit le code suivant (j'ai vu un code similaire dans l'un des fichiers du fabricant):
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; // (SP)
asm(
"TST lr, #4 \n" // 3 ( )
"ITE EQ \n" // 3?
"MRSEQ %[ptr], MSP \n" //,
"MRSNE %[ptr], PSP \n" //,
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
En conséquence, nous avons les valeurs de tous les registres enregistrés:
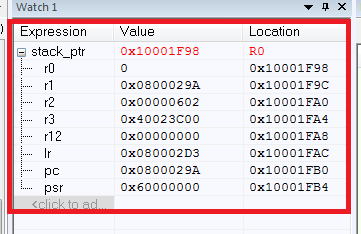
que s'est-il passé ici? Tout d'abord, nous avons le pointeur de pile stack_ptr, tout est clair ici. Des difficultés surviennent avec l'insertion de l'assembleur (s'il est nécessaire de comprendre les instructions de l'assembleur pour Cortex, je recommande [2]).
Pourquoi n'avons-nous pas simplement sauvegardé la pile via MRS stack_ptr, MSP? Le fait est que les cœurs Cortex M3 / M4 ont deux pointeurs de pile [1] (point 3.1.3 Pointeur de pile R13) - le pointeur de pile principal MSP et le pointeur de pile de processus PSP. Ils sont utilisés pour différents modes de processeur. Je ne vais pas approfondir ce pour quoi cela est fait et comment cela fonctionne, mais je vais donner une petite explication.
Pour connaître le mode de fonctionnement du processeur (utilisé dans ce MSP ou PSP), vous devez vérifier le troisième bit du registre de communication. Ce bit détermine quel pointeur de pile est utilisé pour renvoyer à partir d'une exception. Si ce bit est mis à 1, alors c'est MSP, sinon, alors PSP. En général, la plupart des applications écrites en C / C ++ utilisent uniquement des MSP, et cette vérification peut être omise.
Alors, quelle est la ligne du bas? Ayant une liste de registres enregistrés, nous pouvons facilement déterminer d'où provient le programme dans HardFault à partir du registre PC. Le PC pointe vers l'adresse 0x0800029A, qui est l'adresse de notre instruction "breaker". N'oubliez pas l'importance des valeurs des autres registres.
Cause de HardFault
En fait, nous pouvons également déterminer la cause du HardFault. Deux registres nous y aideront. Registre d'état de défaut dur (HFSR) et registre d'état de défaut configurable (CFSR; UFSR + BFSR + MMFSR). Le registre CFSR se compose de trois registres: registre d'état de défaut d'utilisation (UFSR), registre d'état de défaut de bus (BFSR), registre d'adresse de défaut de gestion de la mémoire (MMFSR). Vous pouvez lire à leur sujet, par exemple, dans [1] et [3].
Je propose de voir ce que ces registres produisent dans mon cas:

Premièrement, le bit HFSR FORCED est défini. Cela signifie qu'une défaillance s'est produite qui ne peut pas être traitée. Pour des diagnostics supplémentaires, les registres d'état de défaut restants doivent être examinés.
Deuxièmement, le bit CFSR INVSTATE est mis à 1. Cela signifie qu'un UsageFault s'est produit parce que le processeur a essayé d'exécuter une instruction qui utilise illégalement EPSR.
Qu'est-ce que l'EPSR? EPSR - Registre d'état du programme d'exécution. Il s'agit d'un registre PSR interne - un registre spécial d'état du programme (qui, comme nous le rappelons, est stocké sur la pile). Le vingt-quatrième bit de ce registre indique l'état actuel du processeur (Thumb ou ARM). Cela peut déterminer notre raison de l'échec. Essayons de le compter:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
À la suite de l'exécution, nous obtenons la valeur EPSR = 0.

Il s'avère que le registre montre l'état d'ARM et nous avons trouvé la cause de l'échec? Pas vraiment. En effet, d'après [3] (p. 23), la lecture de ce registre à l'aide d'une commande MSR spéciale renvoie toujours zéro. Je ne comprends pas très bien pourquoi cela fonctionne de cette façon, car ce registre est déjà en lecture seule, mais ici il ne peut pas être lu complètement (seuls quelques bits peuvent être utilisés via xPSR). Ce sont peut-être des limitations architecturales.
En conséquence, malheureusement, toutes ces informations ne donnent pratiquement rien à un programmeur MK ordinaire. C'est pourquoi je considère tous ces registres uniquement comme un complément à l'analyse du contexte stocké.
Cependant, par exemple, si l'échec a été causé par une division par zéro (cet échec est autorisé en positionnant le bit DIV_0_TRP du registre CCR), alors le bit DIVBYZERO sera positionné dans le registre CFSR, ce qui nous indiquera la raison de cet échec même.
Et après?
Que peut-on faire après avoir analysé la cause de l'échec? La procédure suivante semble être une bonne option:
- Imprimez les valeurs de tous les registres analysés sur la console de débogage (printf). Cela ne peut être fait que si vous disposez d'un débogueur JTAG.
- Enregistrez les informations de panne sur un flash interne ou externe (si disponible). Il est également possible d'afficher la valeur du registre PC sur l'écran de l'appareil (si disponible).
- Recharger le processeur NVIC_SystemReset ().

Sources
- Joseph Yiu. Le guide définitif de l'ARM Cortex-M3.
- Guide de l'utilisateur générique des appareils Cortex-M3.
- Manuel de programmation des MCU et MPU STM32 Cortex-M4.