- Bref, quel plan aurons-nous? Tout d'abord, nous expliquerons pourquoi nous allons apprendre Python. Voyons ensuite comment l'interpréteur CPython fonctionne plus en profondeur, comment il gère la mémoire, comment fonctionne le système de types en Python, les dictionnaires, les générateurs et les exceptions. Je pense que cela prendra environ une heure.
- Pourquoi Python?
- Dispositif d'interprétation
- Dactylographie
- Dictionnaires
- Gestion de la mémoire
- Générateurs
- Des exceptions
Pourquoi Python?
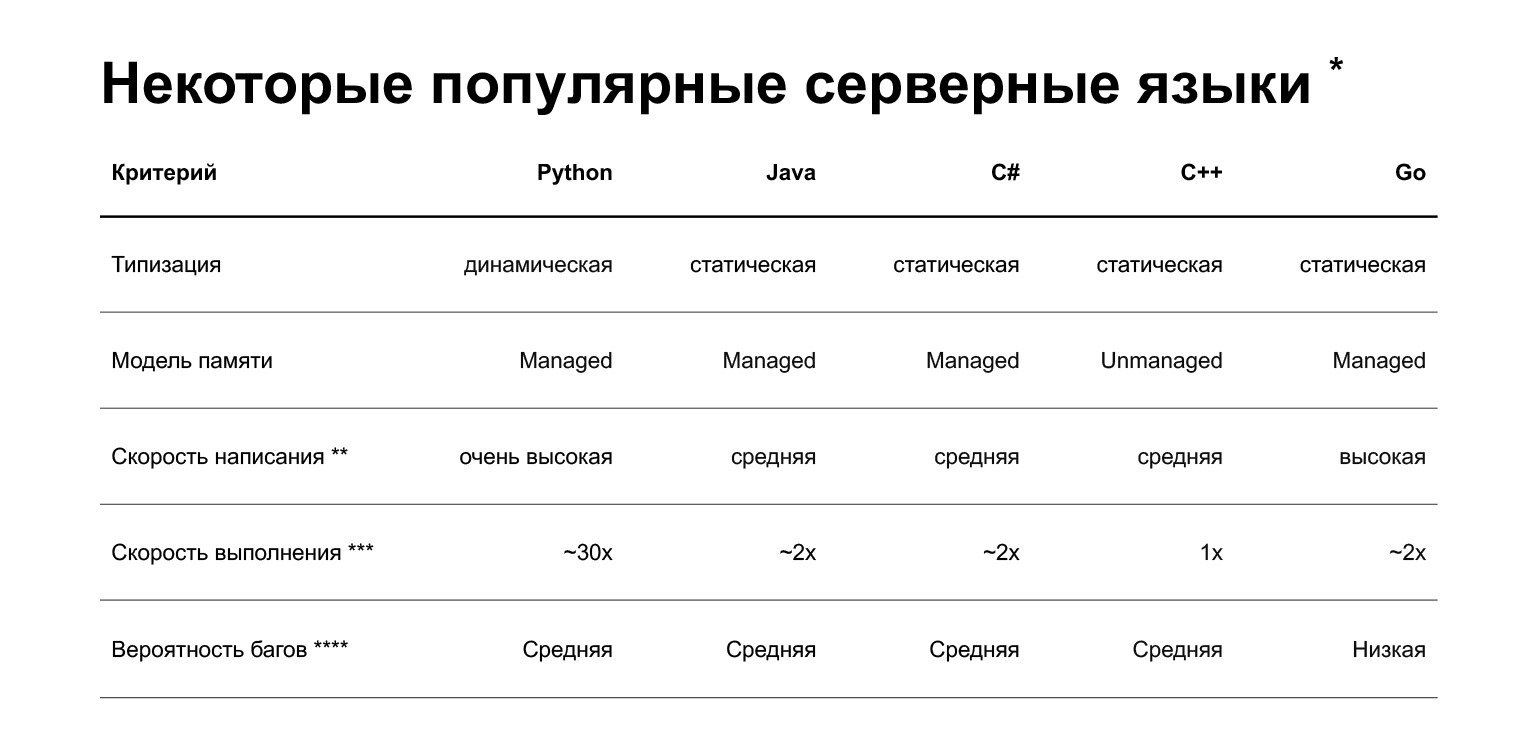
* insights.stackoverflow.com/survey/2019
** interprétation très subjective
*** de l' étude
**** interprétation de l' étude
Commençons. Pourquoi Python? La diapositive présente une comparaison de plusieurs langages actuellement utilisés dans le développement backend. Mais en bref, quel est l'avantage de Python? Vous pouvez rapidement écrire du code dessus. Ceci, bien sûr, est très subjectif - les personnes qui écrivent du C ++ ou Go cool peuvent discuter avec cela. Mais en moyenne, écrire en Python est plus rapide.
Quels sont les inconvénients? Le premier et probablement le principal inconvénient est que Python est plus lent. Il peut être 30 fois plus lent que les autres langues, voici uneétudesur ce sujet. Mais sa vitesse dépend de la tâche. Il existe deux classes de tâches:
- Tâches liées au processeur, liées au processeur, liées au processeur.
- I / O bound, tâches limitées par les entrées-sorties: soit sur le réseau, soit dans les bases de données.
Si vous résolvez le problème lié au processeur, alors oui, Python sera plus lent. Si les E / S sont liées et qu'il s'agit d'une grande classe de tâches, alors pour comprendre la vitesse d'exécution, vous devez exécuter des tests de performances. Et peut-être qu'en comparant Python à d'autres langages, vous ne remarquerez même pas la différence de performances.
De plus, Python est typé dynamiquement: l'interpréteur ne vérifie pas les types au moment de la compilation. Dans la version 3.5, des indices de type sont apparus, vous permettant de spécifier des types de manière statique, mais ils ne sont pas très stricts. Autrement dit, vous détecterez des erreurs déjà en production, et non au stade de la compilation. D'autres langages populaires pour le backend - Java, C #, C ++, Go - ont un typage statique: si vous passez le mauvais objet dans le code, le compilateur vous en informera.
Plus terre à terre, comment Python est-il utilisé dans le développement de produits Taxi? Nous évoluons vers une architecture de microservices. Nous avons déjà 160 microservices, à savoir l'épicerie - 35, 15 d'entre eux en Python, 20 en plus. Autrement dit, nous écrivons maintenant soit uniquement en Python, soit sur des avantages.
Comment choisissons-nous la langue? Le premier concerne les exigences de charge, c'est-à-dire que nous voyons si Python peut le gérer ou non. S'il tire, alors nous regardons la compétence des développeurs d'équipe.
Maintenant, je veux parler de l'interprète. Comment fonctionne CPython?
Dispositif d'interprétation
La question peut se poser: pourquoi avons-nous besoin de savoir comment fonctionne l'interprète. La question est valable. Vous pouvez facilement rédiger des services sans savoir ce qu'il y a sous le capot. Les réponses peuvent être les suivantes:
1. Optimisation pour une charge élevée. Imaginez que vous ayez un service Python. Cela fonctionne, la charge est faible. Mais un jour, la tâche vous revient: écrire un stylo, prêt pour une lourde charge. Vous ne pouvez pas vous en sortir, vous ne pouvez pas réécrire l'ensemble du service en C ++. Vous devez donc optimiser le service pour une charge élevée. Comprendre le fonctionnement de l'interprète peut y contribuer.
2. Débogage de cas complexes. Disons que le service est en cours d'exécution, mais que la mémoire commence à "fuir" dedans. Chez Yandex.Taxi, nous avons eu un tel cas récemment. Le service consommait 8 Go de mémoire toutes les heures et tombait en panne. Nous devons le comprendre. Il s'agit du langage, Python. Une connaissance du fonctionnement de la gestion de la mémoire en Python est requise.
3. Ceci est utile si vous allez écrire des bibliothèques complexes ou du code complexe.
4. Et en général, il est considéré comme une bonne forme de connaître l'outil avec lequel vous travaillez à un niveau plus profond, et pas seulement en tant qu'utilisateur. Ceci est apprécié dans Yandex.
5. Ils posent des questions à ce sujet lors des entretiens, mais ce n'est même pas le but, mais vos perspectives informatiques générales.

Rappelons brièvement quels sont les types de traducteurs. Nous avons des compilateurs et des interprètes. Le compilateur, comme vous le savez probablement, est la chose qui traduit votre code source directement en code machine. Au contraire, l'interpréteur traduit d'abord en bytecode, puis l'exécute. Python est un langage interprété.
Le bytecode est une sorte de code intermédiaire obtenu à partir de l'original. Il n'est pas lié à la plate-forme et s'exécute sur une machine virtuelle. Pourquoi virtuel? Ce n'est pas une vraie voiture, mais une sorte d'abstraction.

Quels types de machines virtuelles existe-t-il? Inscrivez-vous et empilez. Mais ici, nous devons nous souvenir non pas de cela, mais du fait que Python est une machine à pile. Ensuite, nous verrons comment fonctionne la pile.
Et une dernière mise en garde: ici, nous ne parlerons que de CPython. CPython est une implémentation Python de référence, écrite, comme vous pouvez le deviner, en C. Utilisé comme synonyme: quand on parle de Python, on parle généralement de CPython.
Mais il y a aussi d'autres interprètes. Il y a PyPy, qui utilise la compilation JIT et accélère environ cinq fois. Il est rarement utilisé. Je n'ai honnêtement pas rencontré. Il y a JPython, il y a IronPython, qui traduit le bytecode pour la machine virtuelle Java et pour la machine Dotnet. C'est hors de portée de la conférence d'aujourd'hui - pour être honnête, je ne l'ai pas rencontré. Jetons donc un coup d'œil à CPython.

Voyons ce qui se passe. Vous avez une source, une ligne, vous voulez l'exécuter. Que fait l'interprète? Une chaîne n'est qu'une collection de caractères. Pour en faire quelque chose de significatif, vous devez d'abord traduire le code en jetons. Un jeton est un ensemble groupé de caractères, un identifiant, un nombre ou une sorte d'itération. En fait, l'interpréteur traduit le code en jetons.

De plus, l'arbre de syntaxe abstraite AST est construit à partir de ces jetons. Aussi, ne vous inquiétez pas encore, ce ne sont que quelques arbres, dans les nœuds desquels vous avez des opérations. Disons que dans notre cas, il y a BinOp, une opération binaire. Opération - exponentiation, opérandes: le nombre à élever et la puissance à élever.
De plus, vous pouvez déjà créer du code en utilisant ces arborescences. Je rate beaucoup d'étapes, il y a une étape d'optimisation, d'autres étapes. Ensuite, ces arbres de syntaxe sont traduits en bytecode.
Voyons plus en détail ici. Bytecode est, comme son nom l'indique, un code composé d'octets. Et en Python, à partir de 3.6, le bytecode est de deux octets.

Le premier octet est l'opérateur lui-même, appelé opcode. Le deuxième octet est l'argument oparg. On dirait que nous avons d'en haut. Autrement dit, une séquence d'octets. Mais Python a un module appelé dis, de Disassembler, avec lequel nous pouvons voir une représentation plus lisible par l'homme.
À quoi cela ressemble-t-il? Il y a un numéro de ligne de la source - le plus à gauche. La deuxième colonne est l'adresse. Comme je l'ai dit, le bytecode dans Python 3.6 prend deux octets, donc toutes les adresses sont paires et nous voyons 0, 2, 4 ...
Load.name, Load.const sont déjà les options de code elles-mêmes, c'est-à-dire les codes de ces opérations qui Python devrait s'exécuter. 0, 0, 1, 1 sont des oparg, c'est-à-dire les arguments de ces opérations. Voyons comment ils sont faits ensuite.
(...) Voyons comment le bytecode est exécuté en Python, quelles structures sont là pour cela.

Si vous ne connaissez pas C, ça va. Les notes de bas de page sont destinées à une compréhension générale.
Python a deux structures qui nous aident à exécuter le bytecode. Le premier est CodeObject, vous pouvez voir son résumé. En fait, la structure est plus grande. C'est du code sans contexte. Cela signifie que cette structure contient, en fait, le bytecode que nous venons de voir. Il contient les noms des variables utilisées dans cette fonction, si la fonction contient des références à des constantes, des noms de constantes, autre chose.

La structure suivante est FrameObject. C'est déjà le contexte d'exécution, la structure qui contient déjà la valeur des variables; références à des variables globales; la pile d'exécution, dont nous parlerons un peu plus tard, et beaucoup d'autres informations. Disons le numéro de l'exécution de l'instruction.
A titre d'exemple: si vous souhaitez appeler une fonction plusieurs fois, alors vous aurez le même CodeObject, et un nouveau FrameObject sera créé pour chaque appel. Il aura ses propres arguments, sa propre pile. Ils sont donc interconnectés.

Quelle est la boucle d'interprétation principale, comment le bytecode est-il exécuté? Vous avez vu que nous avions une liste de ces opcode avec oparg. Comment tout cela est-il fait? Python, comme tout interpréteur, a une boucle qui exécute ce bytecode. Autrement dit, une trame y entre et Python passe simplement par le bytecode dans l'ordre, regarde de quel type d'oparg il s'agit et se dirige vers son gestionnaire en utilisant un énorme commutateur. Un seul opcode est affiché ici par exemple. Par exemple, nous avons ici une soustraction binaire, une soustraction binaire, disons «AB», sera effectuée à cet endroit.
Expliquons comment fonctionne la soustraction binaire. Très simple, c'est l'un des codes les plus simples. La fonction TOP prend la valeur la plus élevée de la pile, la prend de la plus haute, ne la fait pas simplement sortir de la pile, puis la fonction PyNumber_Subtract est appelée. Résultat: la fonction slash SET_TOP est repoussée sur la pile. Si la pile n'est pas claire, un exemple suivra.

Très brièvement sur le GIL. Le GIL est un mutex au niveau du processus en Python qui prend ce mutex dans la boucle d'interprétation principale. Et ce n'est qu'après cela que le bytecode commence à s'exécuter. Ceci est fait pour qu'un seul thread exécute le bytecode à la fois afin de protéger la structure interne de l'interpréteur.
Disons, pour aller un peu plus loin, que tous les objets en Python ont un certain nombre de références à eux. Et si deux threads modifient ce nombre de liens, l'interpréteur se cassera. Il existe donc un GIL.
Vous en serez informé dans la conférence sur la programmation asynchrone. Comment cela peut-il être important pour vous? Le multithreading n'est pas utilisé, car même si vous créez plusieurs threads, alors en général vous n'en aurez qu'un seul en cours d'exécution, le bytecode sera exécuté dans l'un des threads. Par conséquent, utilisez le multitraitement, l'extension sish ou autre chose.

Un exemple rapide. Vous pouvez explorer ce cadre en toute sécurité depuis Python. Il existe un module sys qui a une fonction de soulignement get_frame. Vous pouvez obtenir un cadre et voir quelles variables sont là. Il y a une instruction. C'est plus pour enseigner, dans la vraie vie je ne l'ai pas utilisé.
Essayons de voir comment la pile de machines virtuelles Python fonctionne pour comprendre. Nous avons un code, assez simple, qui ne comprend pas ce qu'il fait.
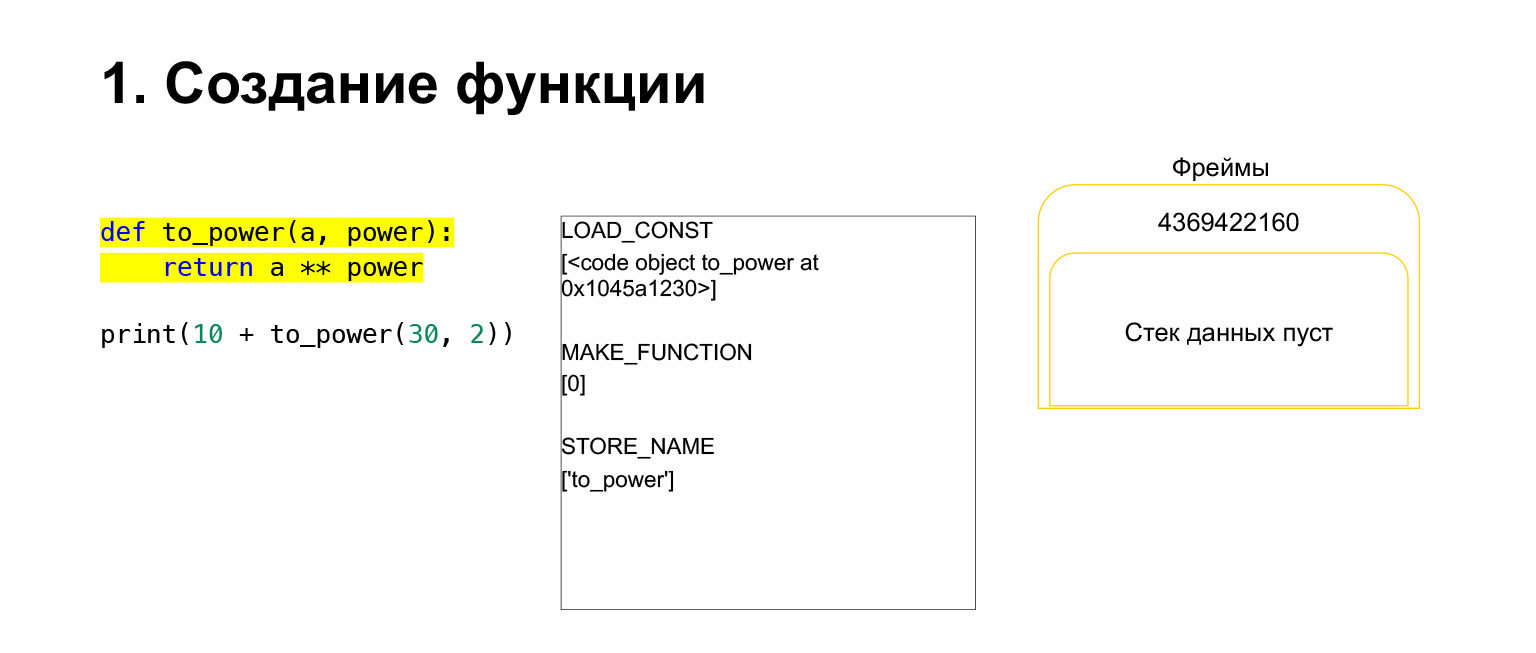
Sur la gauche se trouve le code. La partie que nous examinons actuellement est surlignée en jaune. Dans la deuxième colonne, nous avons le bytecode de cette pièce. La troisième colonne contient des cadres avec des piles. Autrement dit, chaque FrameObject a sa propre pile d'exécution.
Que fait Python? Il va simplement dans l'ordre, bytecode, dans la colonne du milieu, s'exécute et fonctionne avec la pile.
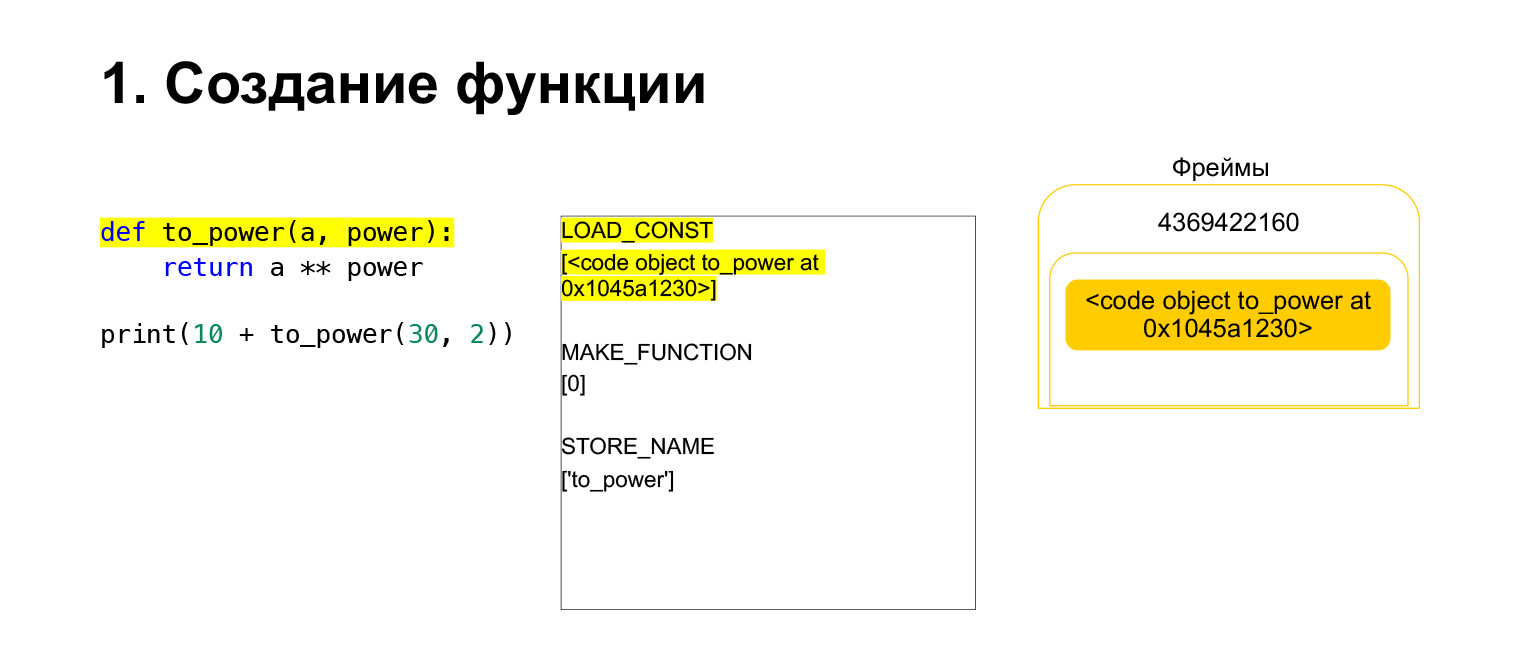
Nous avons exécuté le premier opcode appelé LOAD_CONST. Il charge une constante. Nous avons sauté la partie, un CodeObject y est créé et nous avons eu un CodeObject quelque part dans les constantes. Python l'a chargé sur la pile en utilisant LOAD_CONST. Nous avons maintenant un CodeObject sur la pile dans ce cadre. Nous pouvons avancer.
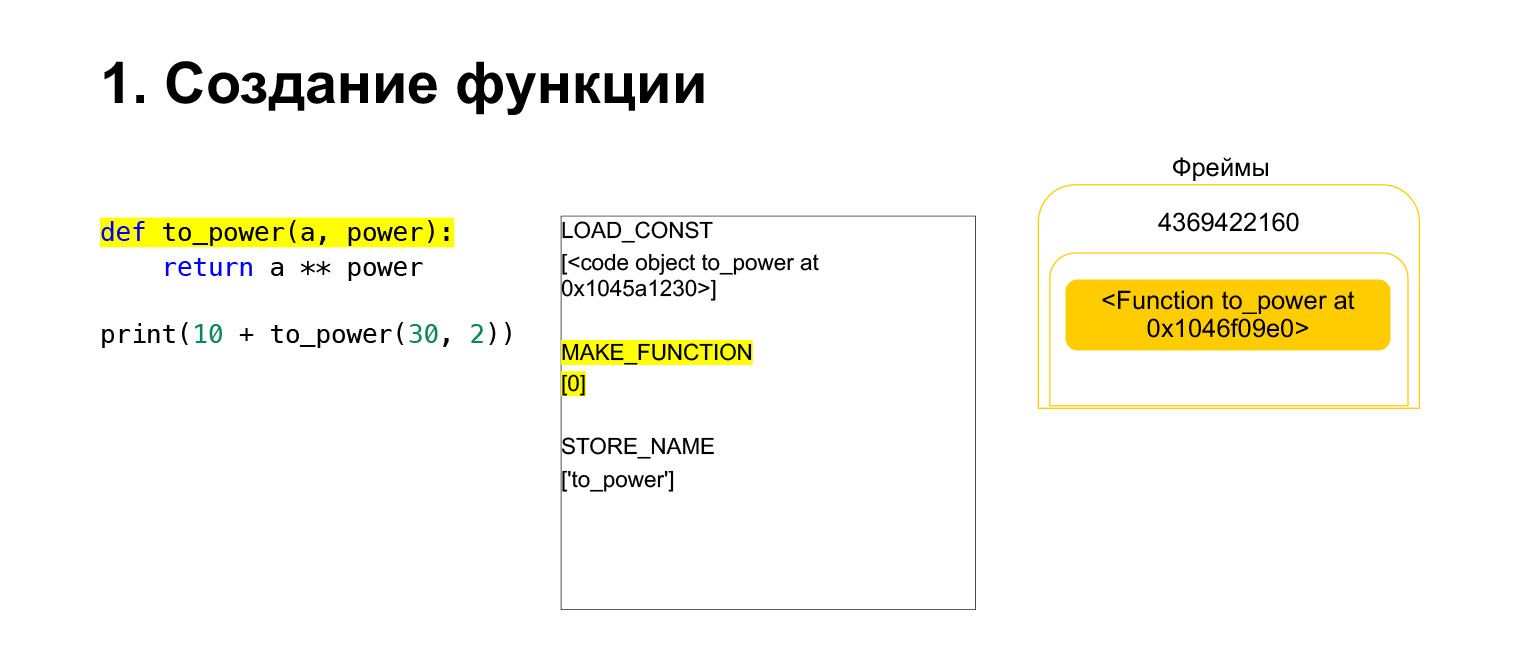
Puis Python exécute l'opcode MAKE_FUNCTION. MAKE_FUNCTION fait évidemment une fonction. Il s'attend à ce que vous ayez un CodeObject sur la pile. Il effectue une action, crée une fonction et repousse la fonction sur la pile. Vous avez maintenant FUNCTION au lieu de CodeObject qui se trouvait sur la pile de cadres. Et maintenant, cette fonction doit être placée dans la variable to_power afin que vous puissiez vous y référer.
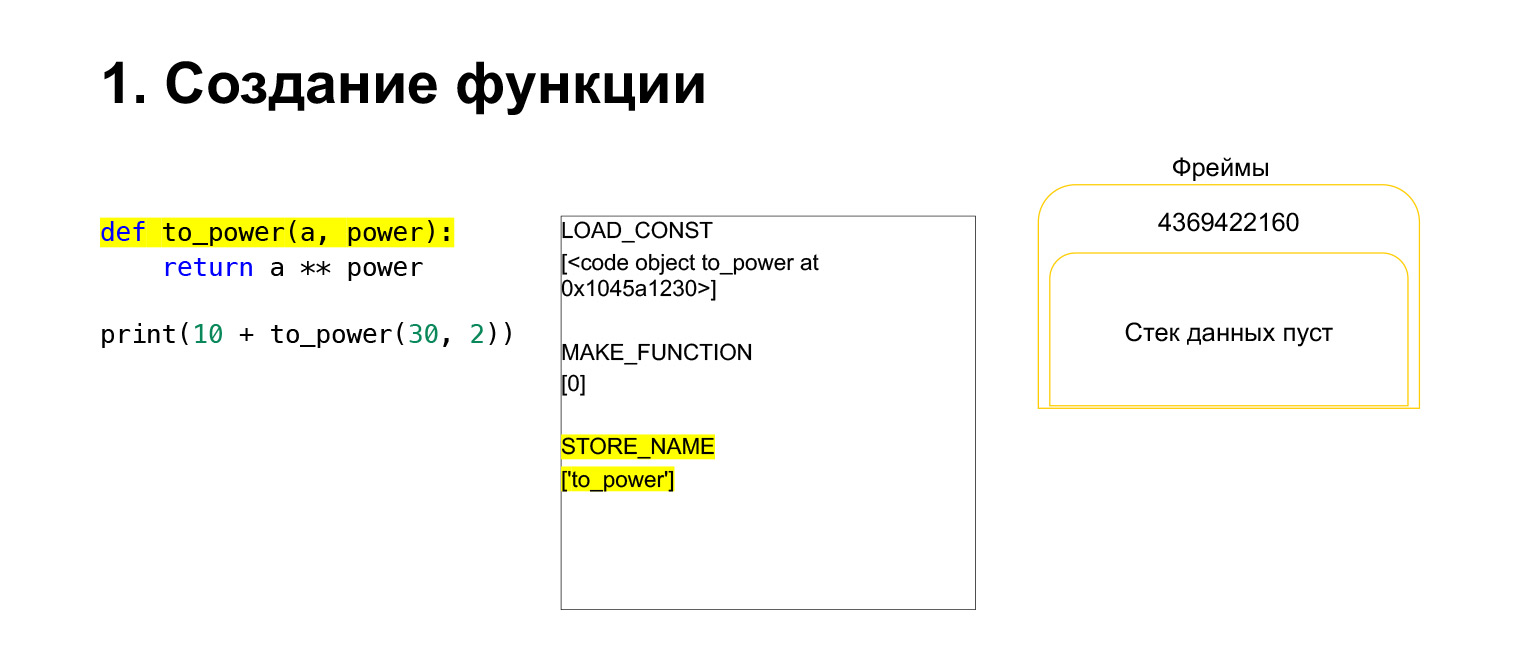
L'opcode STORE_NAME est exécuté, il est placé dans la variable to_power. Nous avions une fonction sur la pile, maintenant c'est la variable to_power, vous pouvez vous y référer.
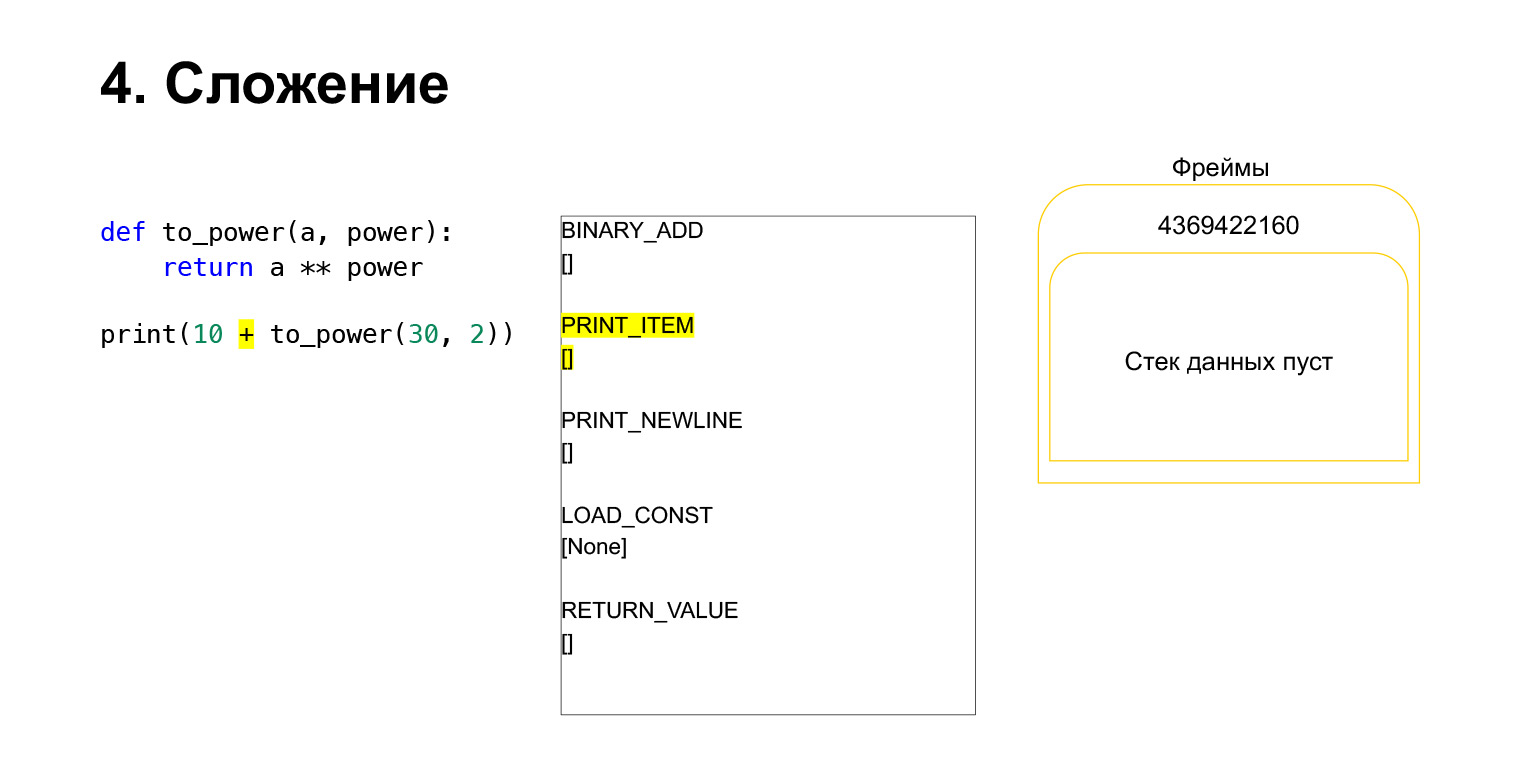
Ensuite, nous voulons imprimer 10 + la valeur de cette fonction.
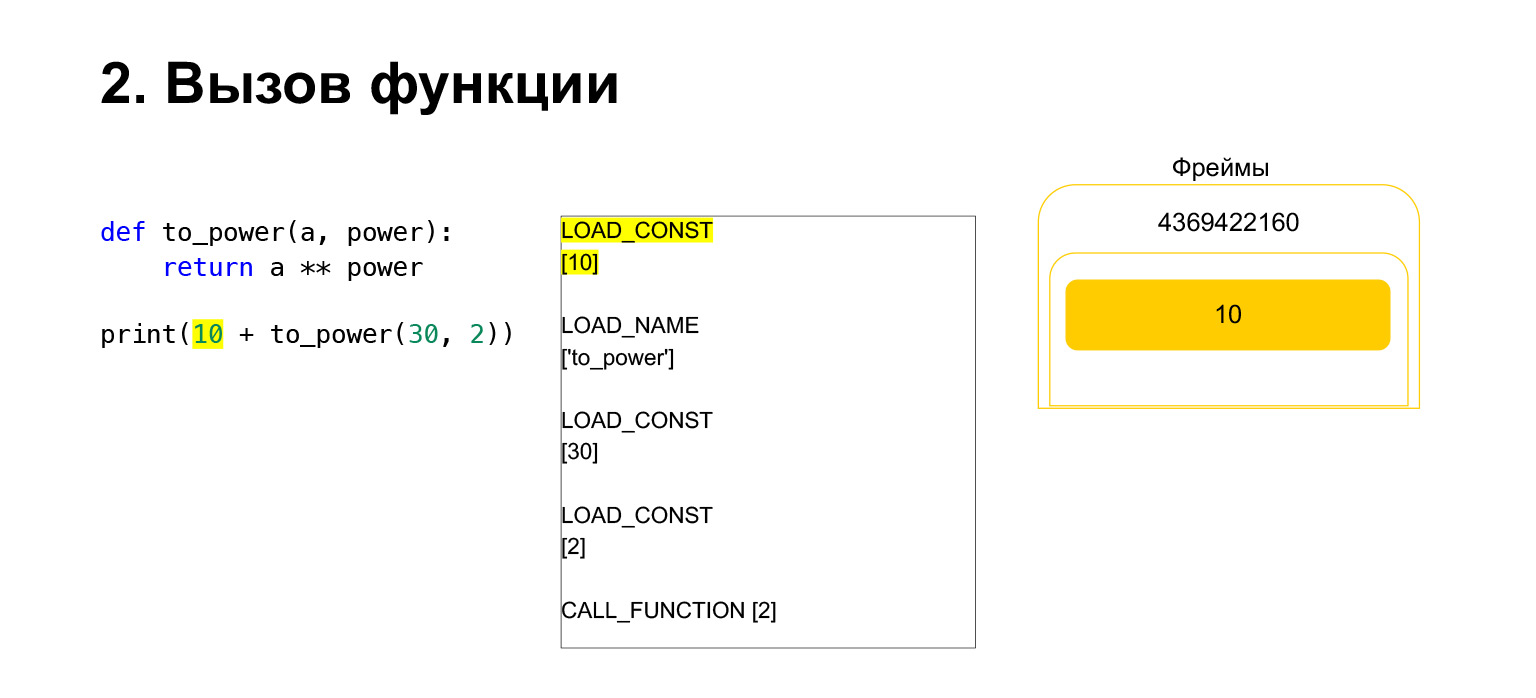
Que fait Python? Cela a été converti en bytecode. Le premier opcode que nous avons est LOAD_CONST. Nous chargeons les dix premiers sur la pile. Une douzaine est apparue sur la pile. Nous devons maintenant exécuter to_power.

La fonction est exécutée comme suit. S'il a des arguments de position - nous ne regarderons pas le reste pour l'instant - alors Python place d'abord la fonction elle-même sur la pile. Ensuite, il met tous les arguments et appelle CALL_FUNCTION avec l'argument nombre d'arguments de fonction.
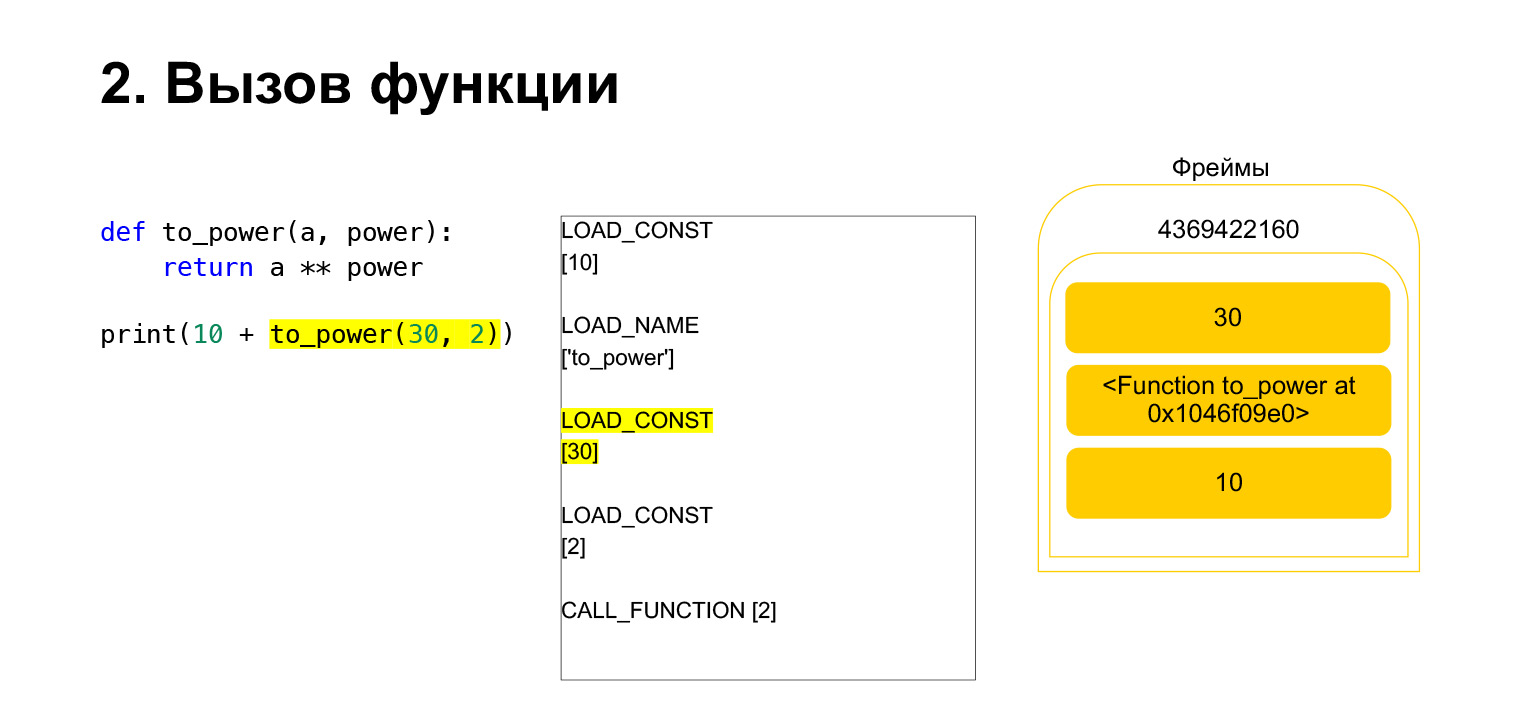
Nous avons chargé le premier argument sur la pile, c'est une fonction.
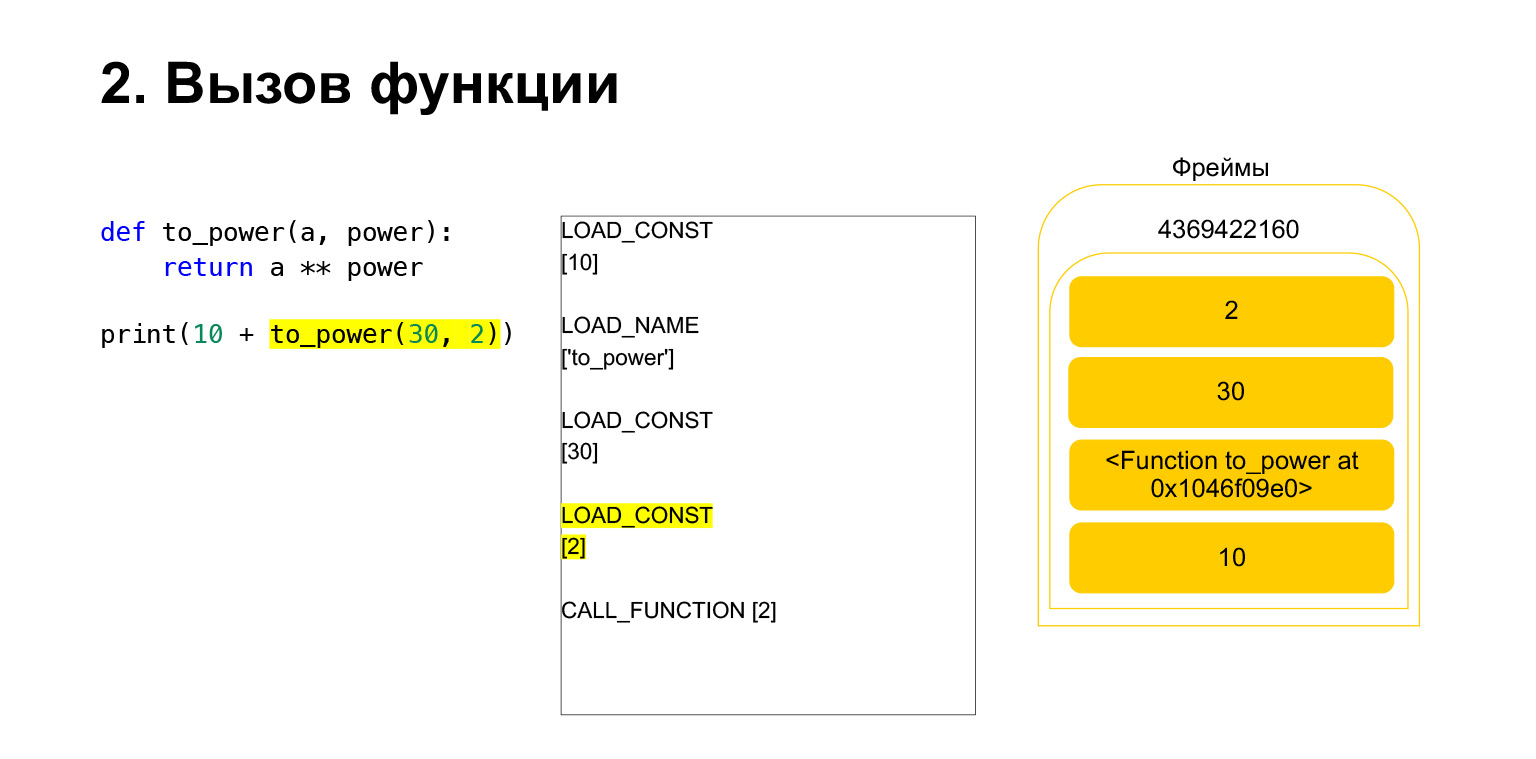
Nous avons chargé deux autres arguments sur la pile - 30 et 2. Nous avons maintenant une fonction et deux arguments sur la pile. Le haut de la pile est en haut. CALL_FUNCTION nous attend. Nous disons: CALL_FUNCTION (2), c'est-à-dire que nous avons une fonction avec deux arguments. CALL_FUNCTION s'attend à avoir deux arguments sur la pile, suivis d'une fonction. Nous l'avons: 2, 30 et FUNCTION.
Opcode en cours.
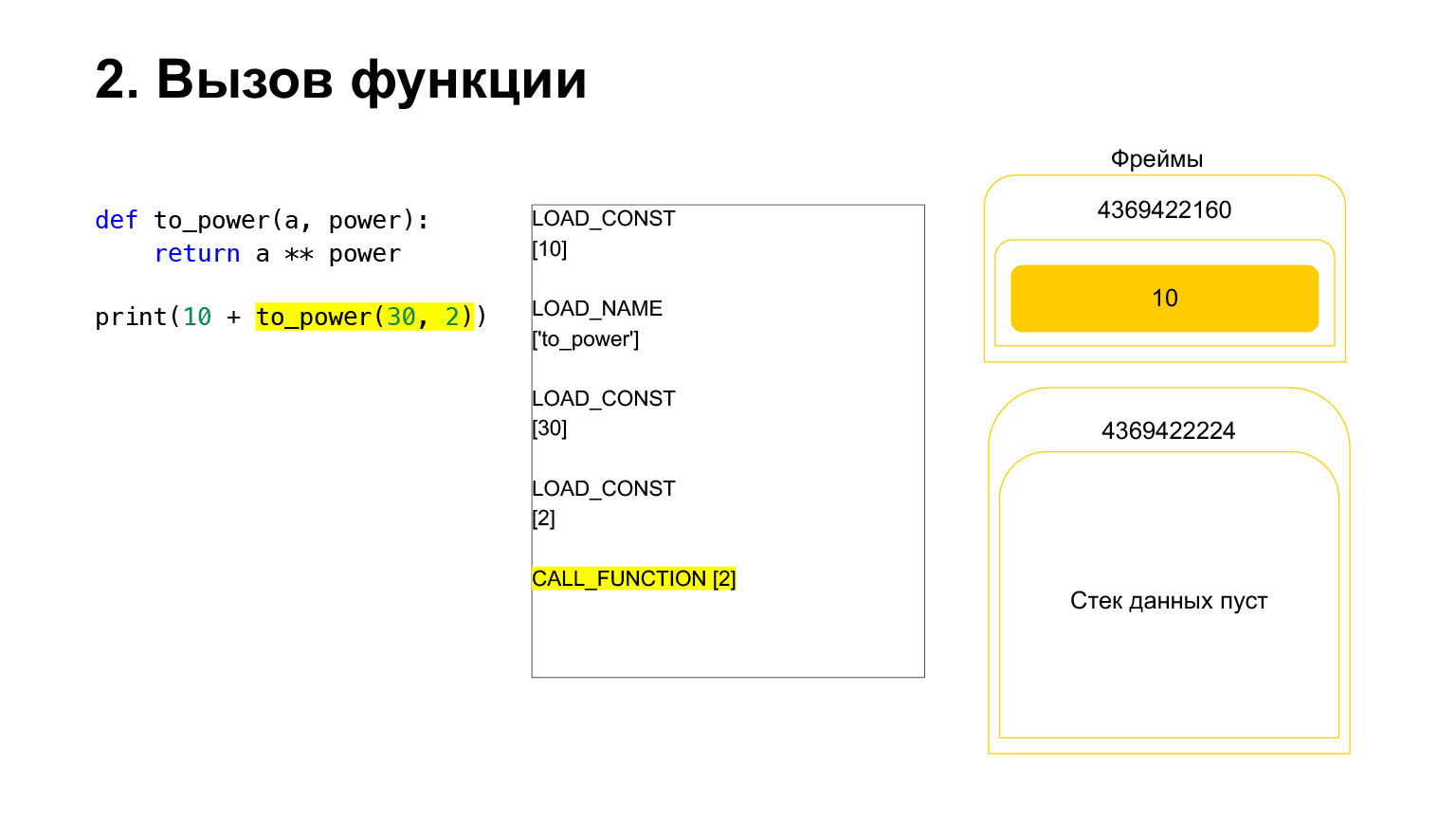
Pour nous, en conséquence, cette pile part, une nouvelle fonction est créée, dans laquelle l'exécution va maintenant avoir lieu.
Le cadre a sa propre pile. Un nouveau cadre a été créé pour sa fonction. Il est encore vide.
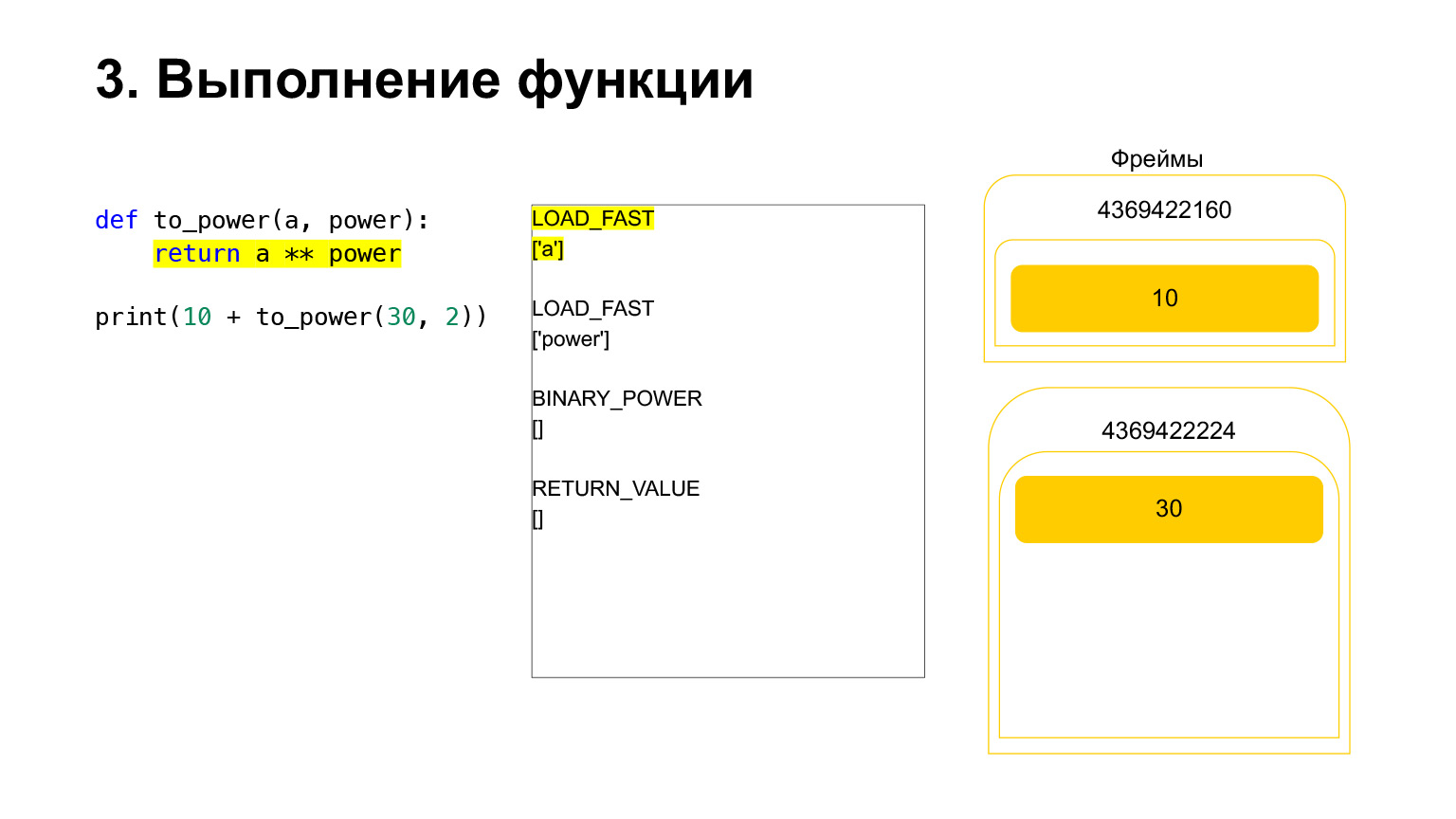
Une autre exécution a lieu. C'est déjà plus facile ici. Nous devons élever A au pouvoir. On charge sur la pile la valeur de la variable A - 30 La valeur de la variable power - 2.
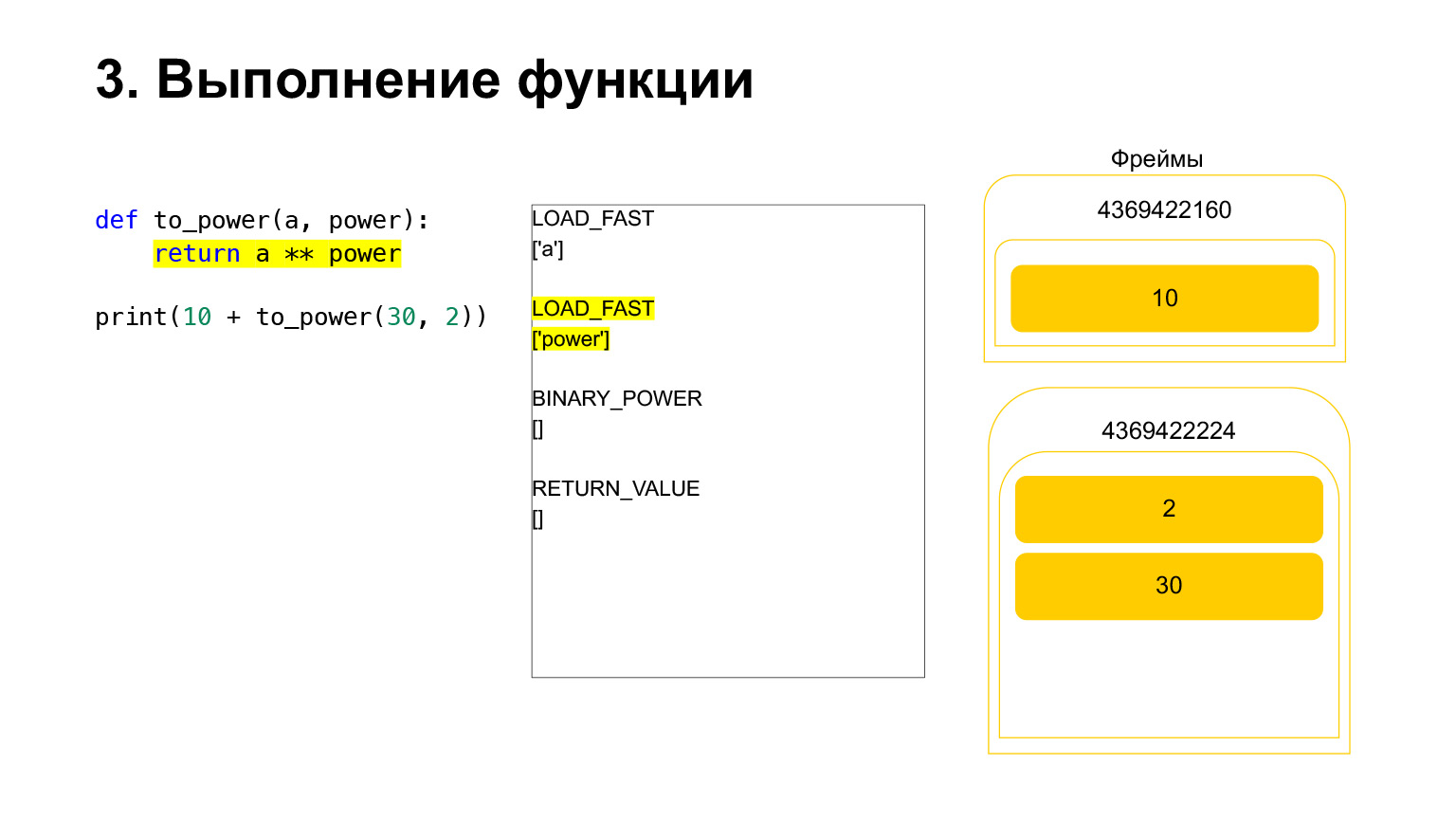
Et l'opcode BINARY_POWER est exécuté.
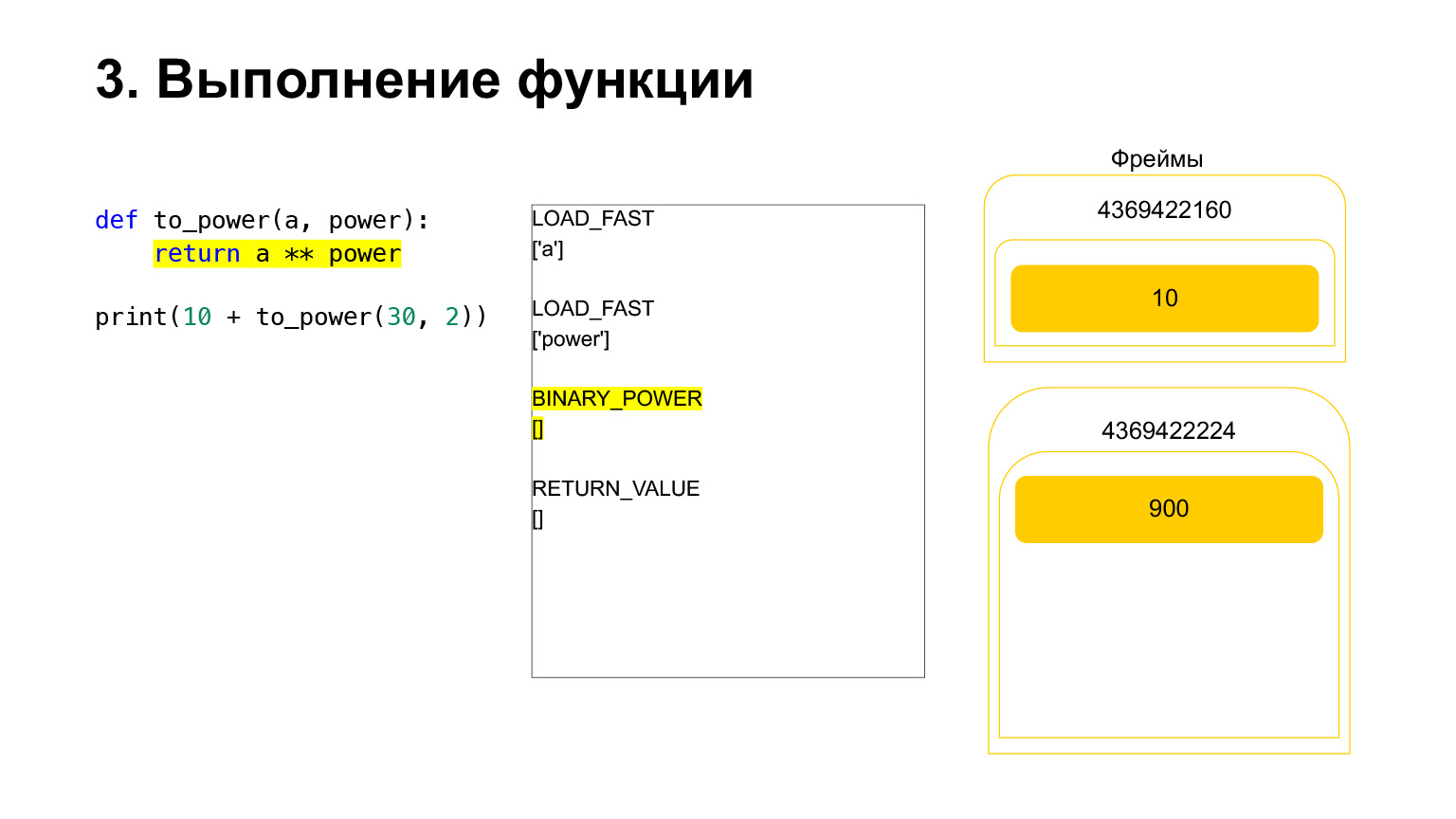
Nous élevons un nombre à la puissance d'un autre et le remettons sur la pile. Il s'est avéré 900 sur la pile de fonctions.
Le prochain opcode RETURN_VALUE renverra la valeur de la pile à l'image précédente.

C'est ainsi que se déroule l'exécution. La fonction est terminée, le cadre sera très probablement effacé s'il n'a pas de références et il y aura deux nombres sur le cadre de la fonction précédente.

Ensuite, tout est à peu près pareil. L'ajout se produit.
(...) Parlons des types et de PyObject.
Dactylographie

Un objet est une structure sish dans laquelle il y a deux champs principaux: le premier est le nombre de références à cet objet, le second est le type de l'objet, bien sûr, une référence au type de l'objet.
D'autres objets héritent de PyObject en l'enfermant. Autrement dit, si nous regardons un flottant, un nombre à virgule flottante, la structure là-bas est PyFloatObject, alors il a un HEAD, qui est une structure PyObject, et, en plus, des données, c'est-à-dire double ob_fval, où la valeur de ce flotteur lui-même est stockée.

Et c'est le type d'objet. Nous venons de regarder le type dans PyObject, c'est une structure qui désigne un type. En fait, il s'agit également d'une structure C qui contient des pointeurs vers des fonctions qui implémentent le comportement de cet objet. Autrement dit, il y a une très grande structure là-bas. Il a des fonctions spécifiées qui sont appelées si, par exemple, vous souhaitez ajouter deux objets de ce type. Ou vous voulez soustraire, appeler cet objet ou le créer. Tout ce que vous pouvez faire avec les types doit être spécifié dans cette structure.

Par exemple, regardons int, entiers en Python. Aussi une version très abrégée. Qu'est-ce qui pourrait nous intéresser? Int a tp_name. Vous pouvez voir qu'il y a tp_hash, nous pouvons obtenir hash int. Si nous appelons hash sur int, cette fonction sera appelée. tp_call nous avons zéro, non défini, cela signifie que nous ne pouvons pas appeler int. tp_str - chaîne de caractères non définie. Python a une fonction str qui peut convertir en une chaîne.
Il n'est pas apparu sur la diapositive, mais vous savez tous déjà que int peut toujours être imprimé. Pourquoi zéro ici? Comme il y a aussi tp_repr, Python a deux fonctions de passage de chaîne: str et repr. Coulée plus détaillée à la corde. Il est en fait défini, il n'est tout simplement pas apparu sur la diapositive, et il sera appelé si vous conduisez réellement à une chaîne.
À la toute fin, nous voyons tp_new - une fonction qui est appelée lorsque cet objet est créé. tp_init nous avons zéro. Nous savons tous que int n'est pas un type mutable, immuable. Après l'avoir créé, il ne sert à rien de le changer, de l'initialiser, il y a donc un zéro.

Regardons également Bool par exemple. Comme certains d'entre vous le savent peut-être, Bool en Python hérite en fait de int. Autrement dit, vous pouvez ajouter Bool, partager les uns avec les autres. Ceci, bien sûr, ne peut pas être fait, mais c'est possible.
Nous voyons qu'il y a un tp_base - un pointeur vers l'objet de base. Tout à part tp_base sont les seules choses qui ont été écrasées. Autrement dit, il a son propre nom, sa propre fonction de présentation, où ce n'est pas un nombre écrit, mais vrai ou faux. Représentation sous forme de nombre, certaines fonctions logiques y sont remplacées. Docstring est le sien et sa création. Tout le reste vient de int.

Je vais vous parler très brièvement des listes. En Python, une liste est un tableau dynamique. Un tableau dynamique est un tableau qui fonctionne comme ceci: vous initialisez une zone mémoire à l'avance avec une certaine dimension. Ajoutez-y des éléments. Dès que le nombre d'éléments dépasse cette taille, vous le développez avec une certaine marge, c'est-à-dire non pas d'un, mais d'une valeur de plus d'un, de sorte qu'il y ait un bon point d'asin.
En Python, la taille augmente comme 0, 4, 8, 16, 25, c'est-à-dire selon une sorte de formule qui nous permet de faire l'insertion asymptotiquement pour une constante. Et vous pouvez voir qu'il y a un extrait de la fonction d'insertion dans la liste. Autrement dit, nous effectuons un redimensionnement. Si nous n'avons pas de redimensionnement, nous lançons une erreur et affectons l'élément. En Python, il s'agit d'un tableau dynamique normal implémenté en C.
(...) Parlons brièvement des dictionnaires. Ils sont partout en Python.
Dictionnaires
Nous savons tous que dans les objets, toute la composition des classes est contenue dans des dictionnaires. Beaucoup de choses sont basées sur eux. Dictionnaires en Python dans une table de hachage.
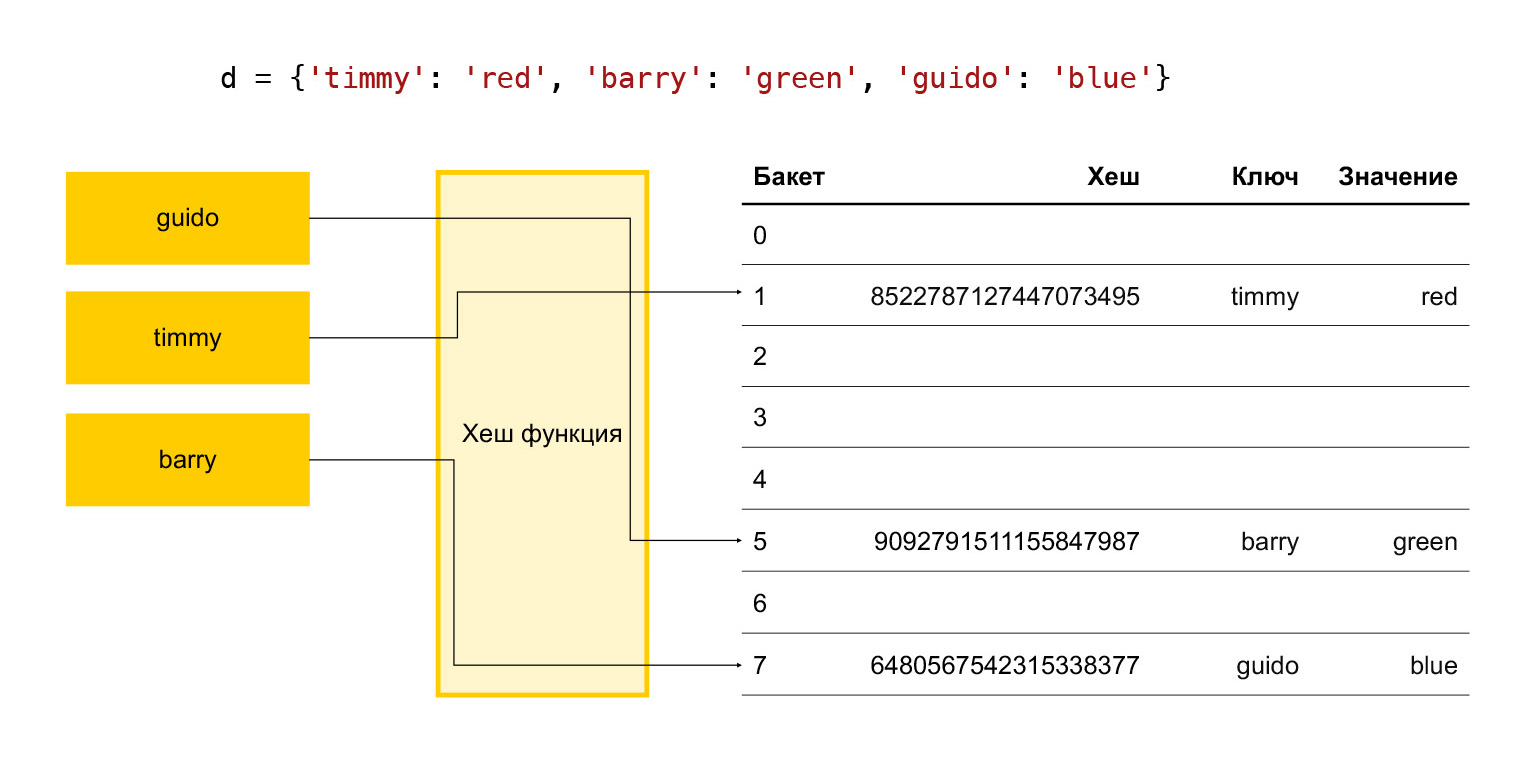
En bref, comment fonctionne une table de hachage? Il y a quelques clés: timmy, barry, guido. Nous voulons les mettre dans un dictionnaire, nous exécutons chaque clé via une fonction de hachage. Il s'avère un hachage. Nous utilisons ce hachage pour trouver le seau. Un bucket est simplement un nombre dans un tableau d'éléments. La division modulo finale se produit. Si le seau est vide, nous y mettons simplement l'élément souhaité. S'il n'est pas vide et qu'il y a déjà un élément là-bas, alors c'est une collision et nous choisissons le prochain bucket, voyons s'il est libre ou non. Et ainsi de suite jusqu'à ce que nous trouvions un seau gratuit.
Par conséquent, pour que l'opération d'ajout ait lieu dans un délai adéquat, nous devons constamment garder un certain nombre de seaux libres. Sinon, à l'approche de la taille de ce tableau, nous chercherons un bucket gratuit pendant très longtemps, et tout ralentira.
Par conséquent, il est empiriquement accepté en Python qu'un tiers des éléments du tableau sont toujours libres. Si leur nombre est supérieur aux deux tiers, le tableau se développe. Ce n'est pas bon, car un tiers des éléments est gaspillé, rien d'utile n'est stocké.

Lien de la diapositive
Par conséquent, depuis la version 3.6, Python a fait une telle chose. Sur la gauche, vous pouvez voir comment c'était avant. Nous avons un tableau clairsemé où ces trois éléments sont stockés. Depuis la version 3.6, ils ont décidé de faire d'un tableau aussi fragmenté un tableau régulier, mais en même temps de stocker les indices des éléments du bucket dans un tableau d'indices séparé.
Si nous regardons le tableau d'indices, alors dans le premier bucket nous avons None, dans le second il y a un élément avec l'index 1 de ce tableau, etc.
Cela a permis, d'une part, de réduire l'utilisation de la mémoire, et d'autre part, nous l'avons également sorti de la boîte gratuitement tableau ordonné. Autrement dit, nous ajoutons des éléments à ce tableau, conditionnellement, avec l'ajout de sish habituel, et le tableau est automatiquement ordonné.
Il y a quelques optimisations intéressantes que Python utilise. Pour que ces tables de hachage fonctionnent, nous avons besoin d'une opération de comparaison d'éléments. Imaginons que nous mettions un élément dans une table de hachage, puis que nous voulions prendre un élément. Nous prenons le hasch, allons dans le seau. On voit: le seau est plein, il y a quelque chose là-bas. Mais est-ce l'élément dont nous avons besoin? Peut-être qu'il y a eu une collision lorsqu'il a été placé et que l'objet est en fait ramené dans un autre seau. Par conséquent, nous devons comparer les clés. Si la clé est fausse, nous utilisons le même mécanisme de recherche de compartiment suivant que celui utilisé pour la résolution des collisions. Et passons à autre chose.

Lien de la diapositive
Par conséquent, nous devons avoir une fonction de comparaison clé. En général, la fonction de comparaison d'objets peut être très coûteuse. Par conséquent, une telle optimisation est utilisée. Tout d'abord, nous comparons les identifiants des articles. L'ID dans CPython est, comme vous le savez, une position en mémoire.
Si les identifiants sont les mêmes, alors ce sont les mêmes objets et, bien sûr, ils sont égaux. Ensuite, nous retournons True. Sinon, regardez les hachages. Le hachage devrait être une opération assez rapide si nous n'avons pas remplacé d'une manière ou d'une autre. Nous prenons des hachages de ces deux objets et comparons. Si leurs hachages ne sont pas égaux, alors les objets ne sont certainement pas égaux, nous retournons donc False.
Et seulement dans un cas très improbable - si nos hachages sont égaux, mais nous ne savons pas s'il s'agit du même objet - alors seulement nous comparons les objets eux-mêmes.
Une petite chose intéressante: vous ne pouvez rien insérer dans les clés pendant l'itération. C'est une erreur.

Sous le capot, le dictionnaire a une variable appelée version, qui stocke la version du dictionnaire. Lorsque vous modifiez le dictionnaire, la version change, Python comprend cela et vous renvoie une erreur.

À quoi peuvent servir les dictionnaires dans un exemple plus pratique? Chez Taxi, nous avons des commandes et les commandes ont des statuts qui peuvent changer. Lorsque vous modifiez le statut, vous devez effectuer certaines actions: envoyer des SMS, enregistrer des commandes.
Cette logique est écrite en Python. Afin de ne pas écrire un énorme si comme «si l'état de la commande est tel ou tel, faites ceci», il y a un certain dict dans lequel la clé est l'état de la commande. Et pour VALUE, il y a un tuple, qui contient tous les gestionnaires qui doivent être exécutés lors de la transition vers cet état. C'est une pratique courante, en fait, c'est un remplacement pour le commutateur.

Quelques autres choses par type. Je vais vous parler d'immuable. Ce sont des types de données immuables, et mutables sont, respectivement, des types mutables: dictats, classes, instances de classe, feuilles, et peut-être autre chose. Presque tout le reste est composé de chaînes, de nombres ordinaires - ils sont immuables. À quoi servent les types mutables? Premièrement, ils facilitent la compréhension du code. Autrement dit, si vous voyez dans le code que quelque chose est un tuple, comprenez-vous qu'il ne change pas davantage, et que cela vous facilite la lecture du code? comprendre ce qui va se passer ensuite. Dans tuple ds, vous ne pouvez pas saisir d'éléments. Vous comprendrez cela et cela vous aidera à vous lire, vous et toutes les personnes qui liront le code pour vous.
Par conséquent, il existe une règle: si vous ne modifiez pas quelque chose, il est préférable d'utiliser des types immuables. Cela conduit également à un travail plus rapide. Il existe deux constantes utilisées par tuple: pit_tuple, tap_tuple, max et CC. À quoi ça sert? Pour tous les tuples de taille jusqu'à 20, une méthode d'allocation spécifique est utilisée, ce qui accélère cette allocation. Et il peut y avoir jusqu'à deux mille objets de chaque type, beaucoup. C'est beaucoup plus rapide que les feuilles, donc si vous utilisez tuple, vous serez plus rapide.
Il existe également des contrôles d'exécution. De toute évidence, si vous essayez de brancher quelque chose dans un objet, et qu'il ne prend pas en charge cette fonction, alors il y aura une erreur, une sorte de compréhension que vous avez fait quelque chose de mal. Les clés d'un dict ne peuvent être que des objets qui ont un hachage qui ne change pas au cours de leur vie. Seuls les objets immuables satisfont à cette définition. Seulement ils peuvent être des clés dict.

À quoi cela ressemble-t-il en C? Exemple. À gauche, un tuple, à droite une liste régulière. Ici, bien sûr, toutes les différences ne sont pas visibles, mais seulement celles que je voulais montrer. Dans la liste du champ tp_hash, nous avons NotImplemented, c'est-à-dire que la liste n'a pas de hachage. Dans tuple, il y a une fonction qui vous renverra un hachage. C'est exactement pourquoi tuple, entre autres, peut être une clé de dict, et non list.
La prochaine chose mise en évidence est la fonction d'affectation d'élément, sq_ass_item. Dans la liste c'est, dans tuple c'est zéro, c'est-à-dire que vous ne pouvez naturellement rien assigner à tuple.

Encore une chose. Python ne copie rien tant que nous ne le lui demandons pas. Cela doit également être rappelé. Si vous voulez copier quelque chose, utilisez, par exemple, le module de copie, qui a une fonction copy.deepcopy. Quelle est la différence? copy copie l'objet, s'il s'agit d'un objet conteneur, tel qu'une liste de frères. Toutes les références qui étaient dans cet objet sont insérées dans le nouvel objet. Et deepcopy copie de manière récursive tous les objets dans ce conteneur et au-delà.
Ou, si vous souhaitez copier rapidement une liste, vous pouvez utiliser une seule tranche de deux points. Vous en obtiendrez une copie, un tel raccourci est simple.
(...) Parlons ensuite de la gestion de la mémoire.
Gestion de la mémoire

Prenons notre module sys. Il a une fonction qui vous permet de voir s'il utilise une mémoire. Si vous démarrez l'interpréteur et regardez les statistiques des changements de mémoire, vous verrez que vous avez créé beaucoup d'objets, y compris des petits. Et ce ne sont que les objets actuellement créés.
En fait, Python crée beaucoup de petits objets à l'exécution. Et si nous utilisions la fonction standard C malloc pour les allouer, nous nous retrouverions très vite dans le fait que notre mémoire est fragmentée et, par conséquent, l'allocation mémoire est lente.

Cela implique la nécessité d'utiliser votre propre gestionnaire de mémoire. Bref, comment ça marche? Python s'attribue des blocs de mémoire, appelés arena, de 256 kilo-octets chacun. À l'intérieur, il se découpe en pools de quatre kilo-octets, c'est la taille d'une page mémoire. À l'intérieur des pools, nous avons des blocs de différentes tailles, de 16 à 512 octets.
Lorsque nous essayons d'allouer moins de 512 octets à un objet, Python sélectionne à sa manière un bloc qui convient à cet objet et place l'objet dans ce bloc.
Si l'objet est désalloué, supprimé, ce bloc est marqué comme libre. Mais il n'est pas donné au système d'exploitation, et à l'emplacement suivant, nous pouvons écrire cet objet dans le même bloc. Cela accélère beaucoup l'allocation de mémoire.

Libérer de la mémoire. Plus tôt, nous avons vu la structure PyObject. Elle a ce refcnt - nombre de références. Cela fonctionne très simplement. Lorsque vous référencez cet objet, Python incrémente le nombre de références. Dès que vous avez un objet, la référence y disparaît, vous désallouez le nombre de références.
Ce qui est surligné en jaune. Si refcnt n'est pas nul, alors nous faisons quelque chose là-bas. Si refcnt vaut zéro, alors nous désallouons immédiatement l'objet. Nous n'attendons aucun ramasse-miettes, rien, mais en ce moment nous effaçons la mémoire.
Si vous rencontrez la méthode del, elle supprime simplement la liaison de la variable à l'objet. Et la méthode __del__, que vous pouvez définir dans la classe, est appelée lorsque l'objet est effectivement supprimé de la mémoire. Vous appellerez del sur l'objet, mais s'il a encore des références, l'objet ne sera supprimé nulle part. Et son Finalizer, __del__, ne sera pas appelé. Bien qu'ils soient appelés très similaires.
Une courte démonstration sur la façon dont vous pouvez voir le nombre de liens. Il y a notre module sys préféré, qui a une fonction getrefcount. Vous pouvez voir le nombre de liens vers un objet.

Je vais vous en dire plus. Un objet est fait. Le nombre de liens en est tiré. Détail intéressant: la variable A pointe vers TaxiOrder. Vous prenez le nombre de liens, vous obtiendrez "2" imprimé. Il semblerait pourquoi? Nous avons une référence d'objet. Mais lorsque vous appelez getrefcount, cet objet est enveloppé autour de l'argument à l'intérieur de la fonction. Par conséquent, vous avez déjà deux références à cet objet: la première est la variable, la seconde est l'argument de la fonction. Par conséquent, "2" est imprimé.
Le reste est trivial. Nous affectons une autre variable à l'objet, nous obtenons 3. Ensuite, nous supprimons cette liaison, nous obtenons 2. Ensuite, nous supprimons toutes les références à cet objet, et en même temps le finaliseur est appelé, ce qui affichera notre ligne.

(...) Il existe une autre fonctionnalité intéressante de CPython, sur laquelle on ne peut pas construire, et il semble que cela ne soit dit nulle part dans la documentation. Les nombres entiers sont souvent utilisés. Il serait inutile de les recréer à chaque fois. Par conséquent, les nombres les plus couramment utilisés, les développeurs Python ont choisi la plage de –5 à 255, ils sont Singleton. Autrement dit, ils sont créés une fois, se trouvent quelque part dans l'interpréteur, et lorsque vous essayez de les obtenir, vous obtenez une référence au même objet. Nous avons pris A et B, les uns, les avons imprimés, comparé leurs adresses. C'est vrai. Et nous avons, par exemple, 105 références à cet objet, simplement parce que maintenant il y en a tellement.
Si nous prenons un certain nombre plus grand - par exemple, 1408 - ces objets ne sont pas égaux pour nous et il y a, respectivement, deux références à eux. En fait, un.
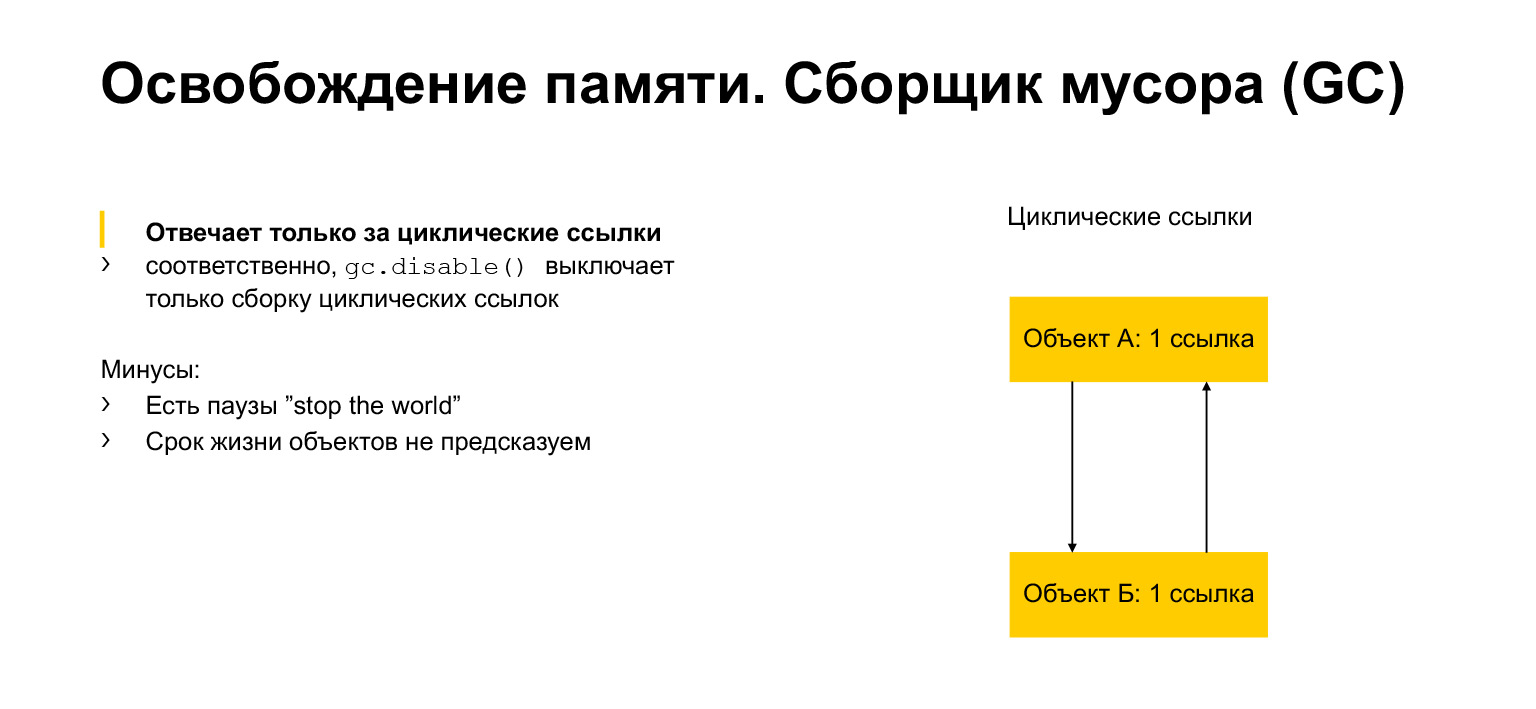
Nous avons un peu parlé d'allocation et de libération de mémoire. Parlons maintenant du ramasse-miettes. Pourquoi est-ce? Il semblerait que nous ayons un certain nombre de liens. Une fois que personne n'a référencé l'objet, nous pouvons le supprimer. Mais nous pouvons avoir des liens circulaires. Un objet peut par exemple se référer à lui-même. Ou, comme dans l'exemple, il peut y avoir deux objets, chacun faisant référence à un voisin. C'est ce qu'on appelle un cycle. Et puis ces objets ne peuvent jamais donner une référence à un autre objet. Mais en même temps, par exemple, ils ne sont pas accessibles depuis une autre partie du programme. Nous devons les supprimer car ils sont inaccessibles, inutiles, mais ils ont des liens. C'est exactement à quoi sert le module de ramasse-miettes. Il détecte les cycles et supprime ces objets.
Comment ça marche? Je vais d'abord parler brièvement des générations, puis de l'algorithme.
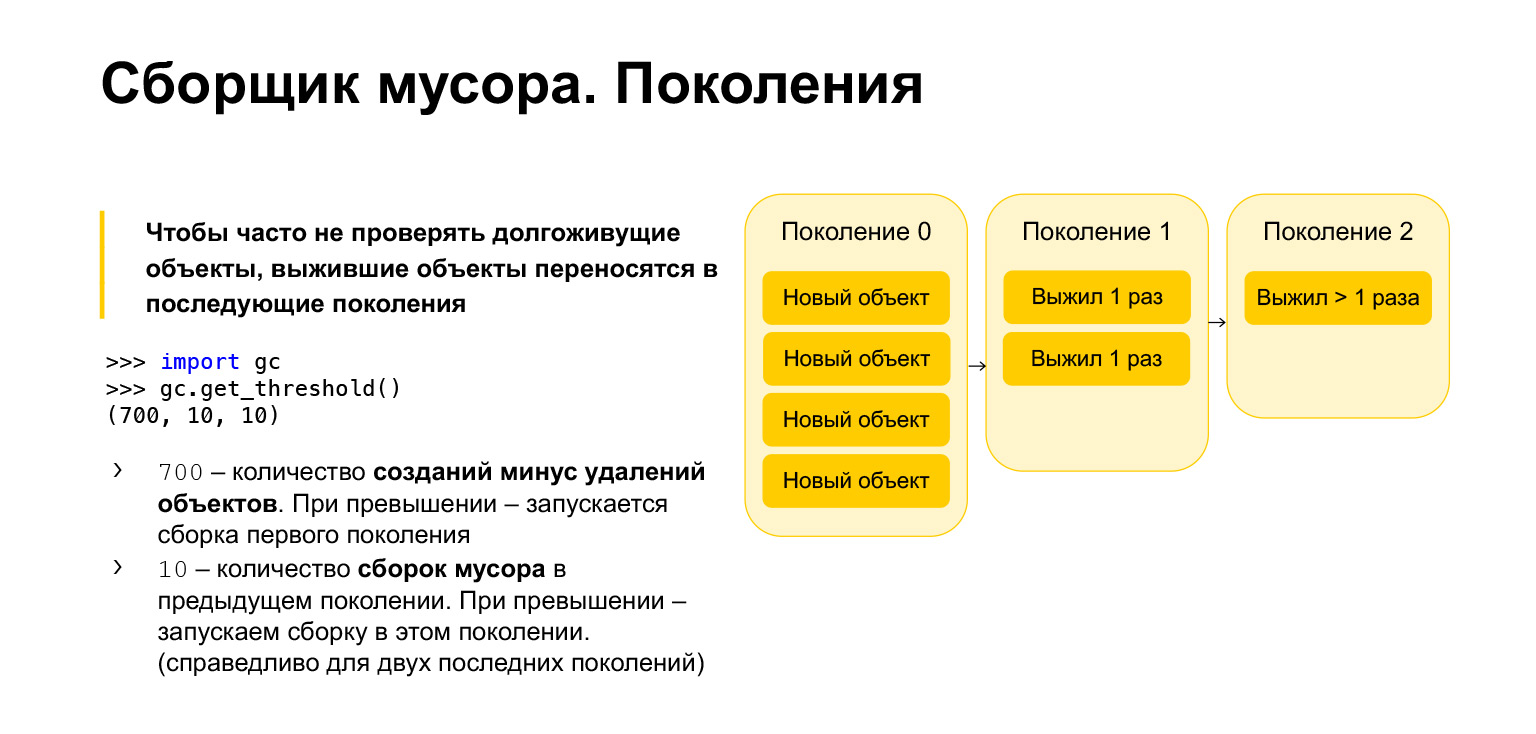
Pour optimiser la vitesse du ramasse-miettes en Python, il est générationnel, c'est-à-dire qu'il fonctionne en utilisant des générations. Il y a trois générations. À quoi servent-ils? Il est clair que les objets qui ont été créés assez récemment sont plus susceptibles d'être inutiles que les objets de longue durée. Disons que vous créez quelque chose au cours des fonctions. Très probablement, il ne sera pas nécessaire lors de la sortie de la fonction. C'est la même chose avec les boucles, avec des variables temporaires. Tous ces objets doivent être nettoyés plus souvent que ceux qui existent depuis longtemps.
Par conséquent, tous les nouveaux objets sont placés dans la génération zéro. Cette génération est nettoyée périodiquement. Python a trois paramètres. Chaque génération a son propre paramètre. Vous pouvez les obtenir, importer le garbage collector, appeler la fonction get_threshold et obtenir ces seuils.
Par défaut, il y en a 700, 10, 10. Qu'est-ce que 700? Il s'agit du nombre de créations d'objets moins le nombre de suppressions. Dès qu'il dépasse 700, un garbage collection de nouvelle génération est lancé. Et 10, 10 est le nombre de garbage collection dans la génération précédente, après quoi nous devons démarrer le garbage collection dans la génération actuelle.
Autrement dit, lorsque nous effacerons la génération zéro 10 fois, nous commencerons la construction dans la première génération. Après avoir nettoyé la première génération 10 fois, nous commencerons la construction dans la deuxième génération. En conséquence, les objets se déplacent de génération en génération. S'ils survivent, ils passent à la première génération. S'ils ont survécu à un garbage collection dans la première génération, ils sont déplacés vers la seconde. A partir de la deuxième génération, ils ne se déplacent plus nulle part, ils y restent pour toujours.
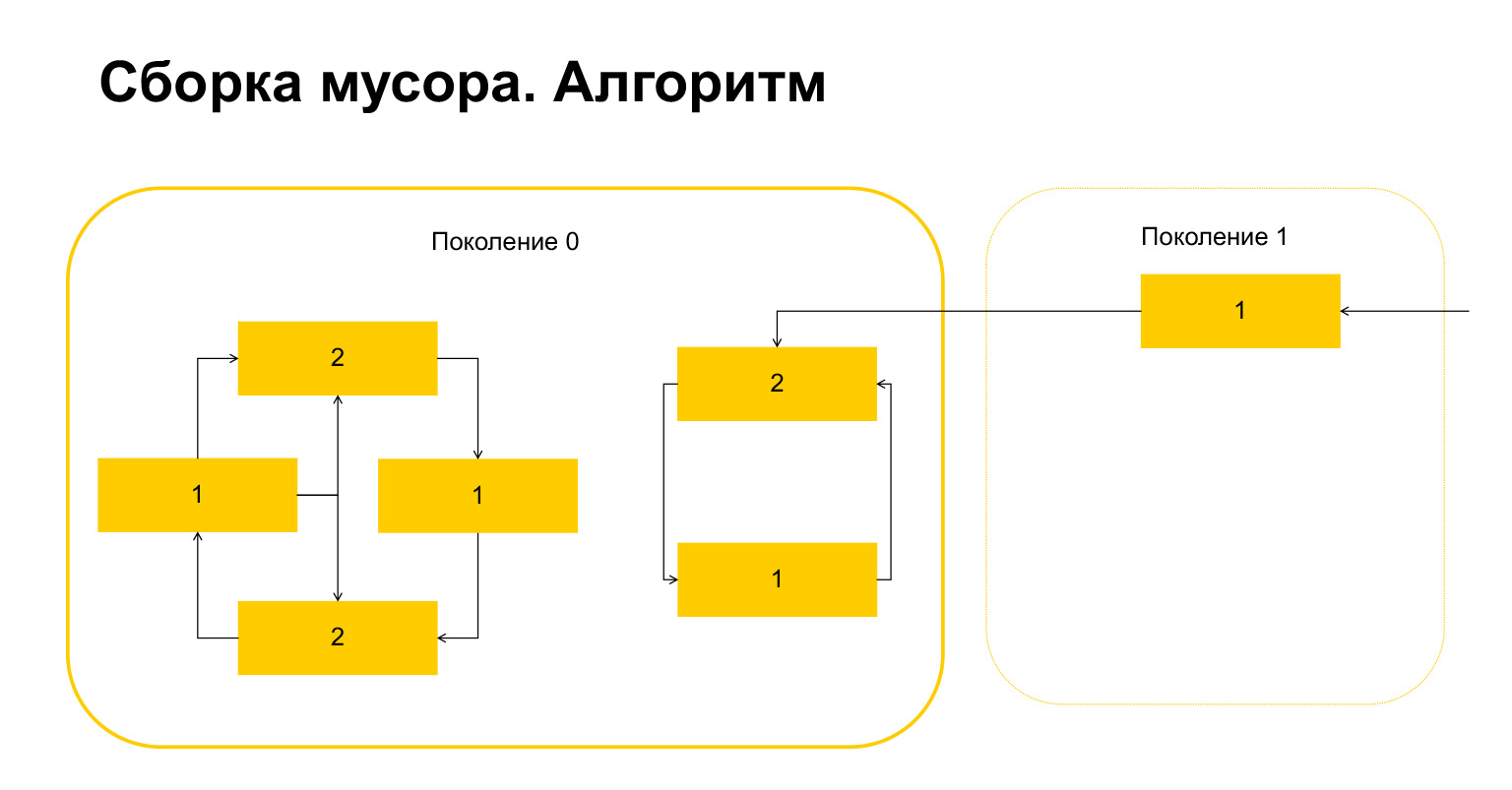
Comment fonctionne le garbage collection en Python? Disons que nous démarrons le garbage collection à la génération 0. Nous avons des objets, ils ont des cycles. Il y a un groupe d'objets sur la gauche qui se réfèrent les uns aux autres, et le groupe sur la droite se réfère également les uns aux autres. Un détail important - ils sont également référencés à partir de la génération 1. Comment Python détecte-t-il les boucles? Tout d'abord, une variable temporaire est créée pour chaque objet et le nombre de références à cet objet y est écrit. Cela se reflète sur la diapositive. Nous avons deux liens vers l'objet en haut. Cependant, un objet de la génération 1 est référencé de l'extérieur. Python s'en souvient. Ensuite (important!) Il parcourt chaque objet de la génération et supprime, décrémente le compteur du nombre de références au sein de cette génération.
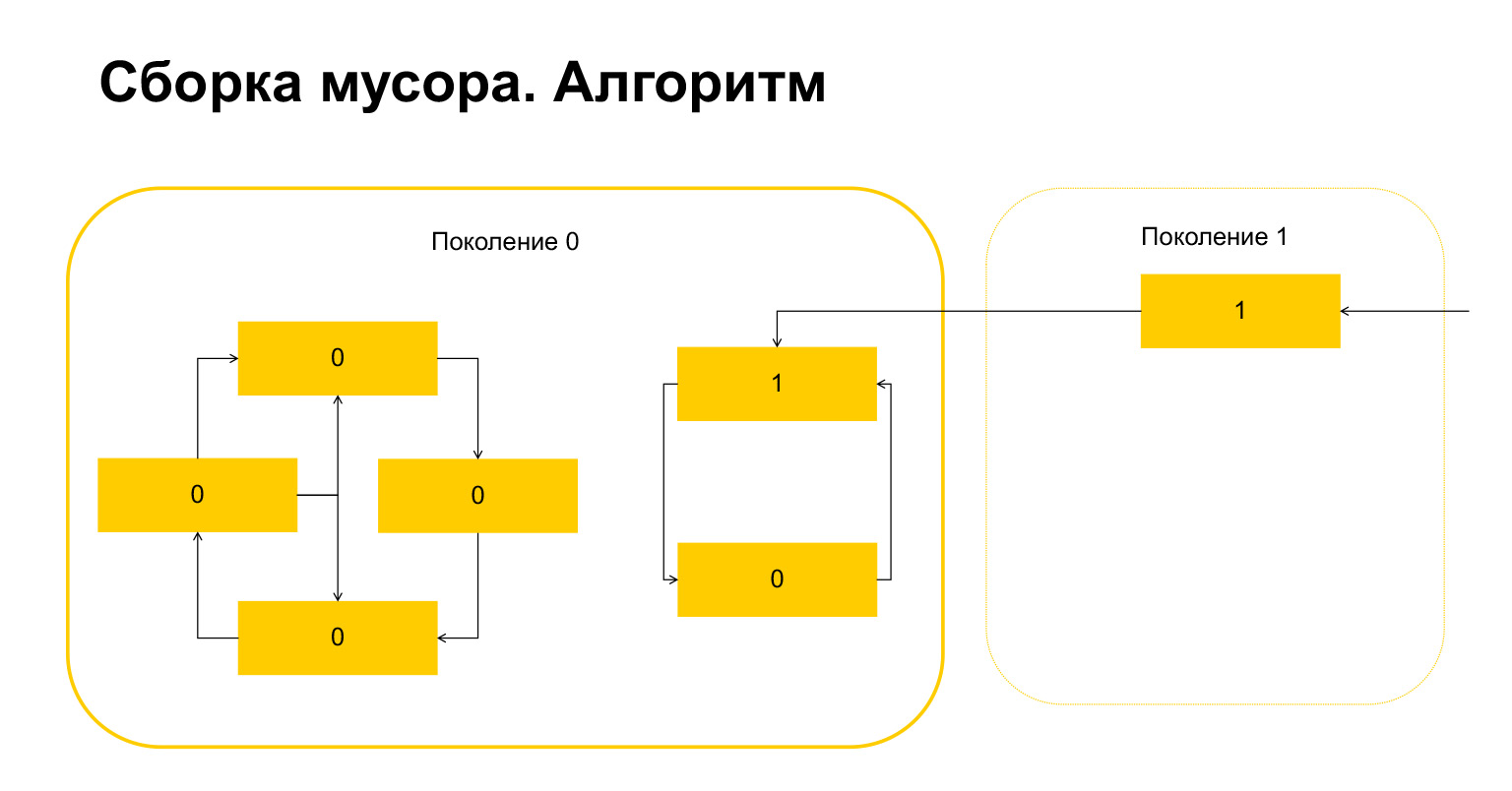
Voici ce qui s'est passé. Pour les objets qui se réfèrent uniquement entre eux au cours d'une génération, cette variable est automatiquement devenue nulle par construction. Seuls les objets référencés de l'extérieur ont une unité.
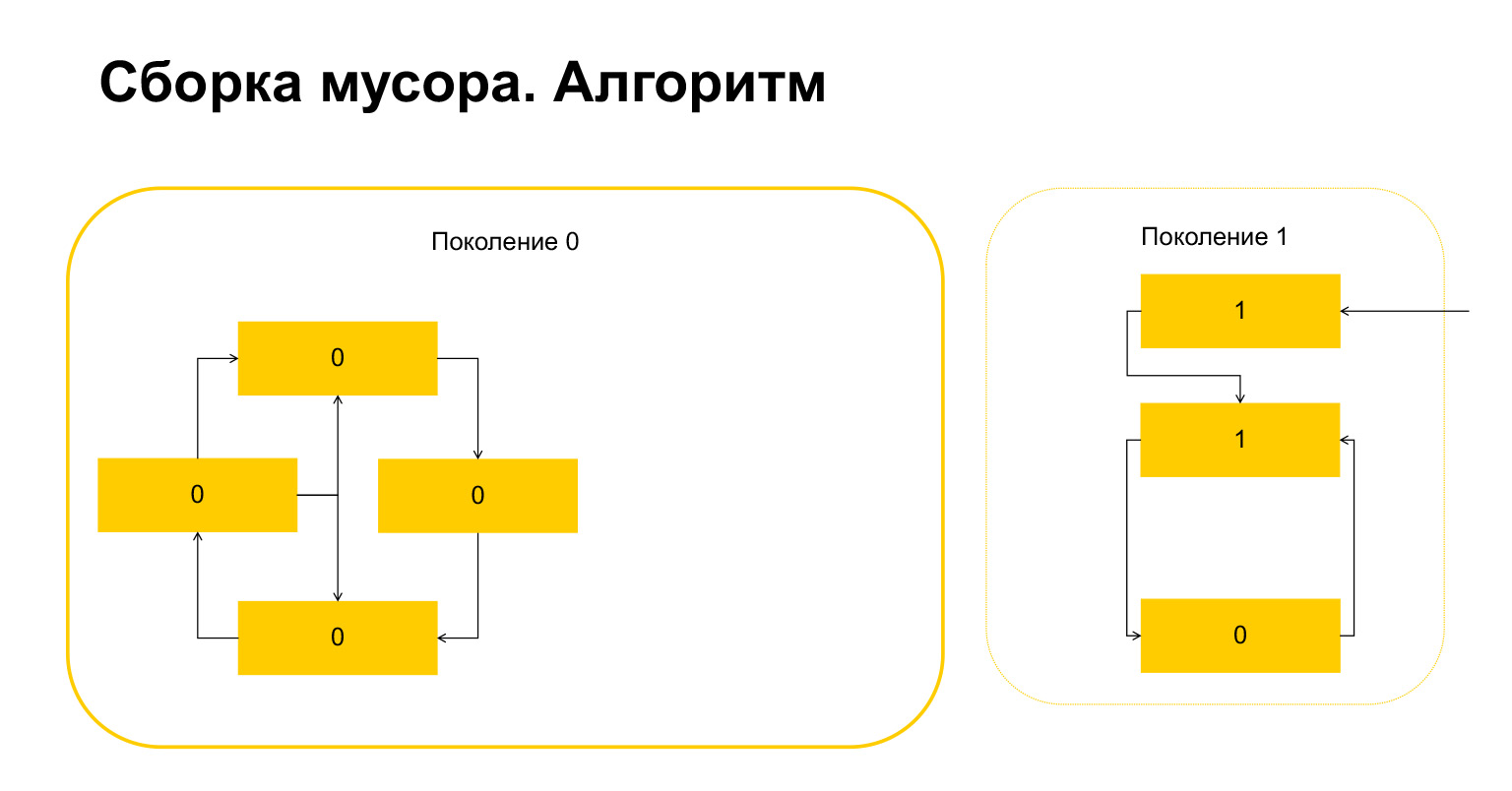
Que fait Python ensuite? Lui, puisqu'il y en a un ici, comprend que ces objets sont référencés de l'extérieur. Et nous ne pouvons supprimer ni cet objet ni celui-ci, sinon nous aurons une situation invalide. Par conséquent, Python transfère ces objets à la génération 1, et tout ce qui reste dans la génération 0, il supprime, nettoie. Tout sur le ramasse-miettes.
(...) Passez. Je vais vous parler très brièvement des générateurs.
Générateurs

Malheureusement, il n'y aura pas d'introduction aux générateurs ici, mais essayons de vous dire ce qu'est un générateur. C'est une sorte de fonction, relativement parlant, qui se souvient du contexte de son exécution en utilisant le mot yield. À ce stade, il renvoie une valeur et se souvient du contexte. Vous pouvez alors vous y référer à nouveau et obtenir la valeur qu'il donne.
Que pouvez-vous faire avec les générateurs? Vous pouvez donner un générateur, cela vous renverra des valeurs, souvenez-vous du contexte. Vous pouvez retourner le générateur. Dans ce cas, l'exécution StopIteration sera lancée, la valeur à l'intérieur de laquelle contiendra la valeur, dans ce cas Y.
Fait moins connu: vous pouvez envoyer des valeurs au générateur. Autrement dit, vous appelez la méthode send sur le générateur, et Z - voir l'exemple - sera la valeur de l'expression yield que le générateur appellera. Si vous souhaitez contrôler le générateur, vous pouvez y passer des valeurs.
Vous pouvez également y lancer des exceptions. La même chose: prenez un objet générateur, lancez-le. Vous y jetez une erreur. Vous aurez une erreur à la place du dernier rendement. Et fermez - vous pouvez fermer le générateur. Ensuite, l'exécution GeneratorExit est déclenchée et le générateur ne devrait rien donner d'autre.

Ici, je voulais juste parler de son fonctionnement en CPython. Vous avez en fait une trame d'exécution dans votre générateur. Et comme nous nous en souvenons, FrameObject contient tout le contexte. De là, il semble clair comment le contexte est préservé. Autrement dit, vous avez juste un cadre dans le générateur.

Lorsque vous exécutez une fonction de générateur, comment Python sait-il que vous n'avez pas besoin de l'exécuter, mais créez un générateur? Le CodeObject que nous avons examiné a des indicateurs. Et lorsque vous appelez une fonction, Python vérifie ses indicateurs. Si l'indicateur CO_GENERATOR est présent, il comprend que la fonction n'a pas besoin d'être exécutée, mais seulement de créer un générateur. Et il le crée. Fonction PyGen_NewWithQualName.

Comment se déroule l'exécution? Depuis GENERATOR_FUNCTION, le générateur appelle d'abord GENERATOR_Object. Ensuite, vous pouvez appeler GENERATOR_Object en utilisant next pour obtenir la valeur suivante. Comment se passe le prochain appel? Sa trame est extraite du générateur, elle est stockée dans la variable F. Et envoyée à la boucle principale de l'interpréteur EvalFrameEx. Vous êtes exécuté comme dans le cas d'une fonction normale. Le mapcode YIELD_VALUE est utilisé pour retourner, mettre en pause l'exécution du générateur. Il se souvient de tout le contexte dans le cadre et cesse de s'exécuter. C'était l'avant-dernier sujet.
(...) Un bref récapitulatif de ce que sont les exceptions et comment elles sont utilisées en Python.
Des exceptions

Les exceptions sont un moyen de gérer les situations d'erreur. Nous avons un bloc d'essai. Nous pouvons écrire dans try ces choses qui peuvent lever des exceptions. Disons que nous pouvons générer une erreur en utilisant le mot augmenter. Avec l'aide de except, nous pouvons intercepter certains types d'exceptions, dans ce cas SomeError. Avec sauf nous attrapons toutes les exceptions sans expression. Le bloc else est moins utilisé, mais il existe et ne sera exécuté que si aucune exception n'a été levée. Le bloc finally s'exécutera de toute façon.
Comment fonctionnent les exceptions dans CPython? En plus de la pile d'exécution, chaque trame a également une pile de blocs. Il vaut mieux utiliser un exemple.


Une pile de blocs est une pile sur laquelle sont écrits des blocs. Chaque bloc a un type, Handler, un handler. Handler est l'adresse de bytecode à laquelle sauter pour traiter ce bloc. Comment ça marche? Disons que nous avons du code. Nous avons fait un bloc try, nous avons un bloc except dans lequel nous interceptons les exceptions RuntimeError, et un bloc finally, qui devrait être dans tous les cas.
Tout cela dégénère en ce bytecode. Au tout début du bytecode sur le bloc try, nous voyons deux deux opcode SETUP_FINALLY avec des arguments à 40 et à 12. Ce sont les adresses des gestionnaires. Lorsque SETUP_FINALLY est exécuté, un bloc est placé sur la pile de blocs, qui dit: pour me traiter, allez dans un cas à la 40e adresse, dans l'autre - à la 12e.
12 en bas de la pile est sauf, la ligne contenant le else RuntimeError. Cela signifie que lorsque nous avons une exception, nous allons regarder la pile de blocs à la recherche d'un bloc avec le type SETUP_FINALLY. Trouvez le bloc dans lequel il y a une transition vers l'adresse 12, allez-y. Et là, nous avons une comparaison de l'exception avec le type: nous vérifions si le type de l'exception est RuntimeError ou non. S'il est égal, nous l'exécutons, sinon, nous sautons ailleurs.
ENFIN est le bloc suivant dans la pile de blocs. Il sera exécuté pour nous si nous avons une autre exception. Ensuite, la recherche se poursuivra sur cette pile de blocs, et nous arriverons au bloc SETUP_FINALLY suivant. Il y aura un gestionnaire qui nous indique, par exemple, l'adresse 40. Nous sautons à l'adresse 40 - vous pouvez voir à partir du code qu'il s'agit d'un bloc finally.

Cela fonctionne très simplement en CPython. Nous avons toutes les fonctions qui peuvent déclencher des exceptions renvoyant un code de valeur. Si tout va bien, 0 est renvoyé. S'il s'agit d'une erreur, -1 ou NULL est renvoyé, selon le type de fonction.
Prenez une telle barre latérale à C. Nous voyons comment la division se produit. Et il y a une vérification que si B est égal à zéro et que nous ne voulons pas diviser par zéro, alors nous nous souvenons de l'exception et retournons NULL. Une erreur s'est donc produite. Par conséquent, toutes les autres fonctions qui sont plus élevées sur la pile d'appels doivent également jeter NULL. Nous allons voir cela dans la boucle principale de l'interpréteur et sauter ici.

C'est le déroulement de la pile. Tout est comme je l'ai dit: nous parcourons toute la pile de blocs et vérifions que son type est SETUP_FINALLY. Si c'est le cas, sautez par-dessus Handler, très simple. C'est en fait tout.
Liens
Interpréteur général:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
Gestion de la mémoire:
arctrix.com/nas/python/gc
rushter.com/blog/python -memory-managment
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
Exceptions:
bugs.python.org/issue17611