
Bonjour, Khabrovites. Aujourd'hui, nous allons parler de RxJava. Je sais qu'un wagon et un petit chariot ont été écrits à son sujet, mais il me semble que j'ai quelques points intéressants à partager. Tout d'abord, je vais vous dire comment nous utilisons RxJava avec l'architecture VIPER pour les applications Android, et en même temps regarder la manière «classique» de l'utiliser. Après cela, passons en revue les principales fonctionnalités de RxJava et revenons plus en détail sur la manière dont les planificateurs sont organisés. Si vous avez déjà fait le plein de collations, alors bienvenue sous chat.
Une architecture qui convient à tous
RxJava est une implémentation du concept ReactiveX et a été créé par Netflix. Leur blog contient une série d'articles expliquant pourquoi ils l'ont fait et quels problèmes ils ont résolus. Les liens (1, 2) se trouvent à la fin de l'article. Netflix a utilisé RxJava côté serveur (backend) pour paralléliser le traitement d'une grande requête. Bien qu'ils aient suggéré un moyen d'utiliser RxJava sur le backend, cette architecture convient à l'écriture de différents types d'applications (mobile, desktop, backend et bien d'autres). Les développeurs Netflix ont utilisé RxJava dans la couche de service de telle sorte que chaque méthode de la couche de service renvoie un observable. Le fait est que les éléments d'un Observable peuvent être livrés de manière synchrone et asynchrone. Cela permet à la méthode de décider d'elle-même si elle doit renvoyer la valeur immédiatement de manière synchrone (par exemple,si disponible dans le cache) ou obtenez d'abord ces valeurs (par exemple, à partir d'une base de données ou d'un service distant) et retournez-les de manière asynchrone. Dans tous les cas, le contrôle retournera immédiatement après l'appel de la méthode (avec ou sans données).
/**
* , ,
* , ,
* callback `onNext()`
*/
public Observable<T> getProduct(String name) {
if (productInCache(name)) {
// ,
return Observable.create(observer -> {
observer.onNext(getProductFromCache(name));
observer.onComplete();
});
} else {
//
return Observable.<T>create(observer -> {
try {
//
T product = getProductFromRemoteService(name);
//
observer.onNext(product);
observer.onComplete();
} catch (Exception e) {
observer.onError(e);
}
})
// Observable IO
// /
.subscribeOn(Schedulers.io());
}
}
Avec cette approche, nous obtenons une API immuable pour le client (dans notre cas, le contrôleur) et différentes implémentations. Le client interagit toujours avec l'Observable de la même manière. Peu importe que les valeurs soient reçues de manière synchrone ou non. Dans le même temps, les implémentations d'API peuvent passer de synchrone à asynchrone, sans affecter en aucune façon l'interaction avec le client. Avec cette approche, vous ne pouvez absolument pas penser à la façon d'organiser le multithreading et vous concentrer sur la mise en œuvre des tâches métier.
L'approche est applicable non seulement dans la couche service sur le backend, mais aussi dans les architectures MVC, MVP, MVVM, etc. Par exemple, pour MVP, nous pouvons créer une classe Interactor qui sera responsable de la réception et de la sauvegarde des données vers diverses sources, et tout faire ses méthodes ont renvoyé Observable. Il s'agira d'un contrat d'interaction avec Model. Cela permettra également à Presenter d'exploiter toute la puissance des opérateurs disponibles dans RxJava.
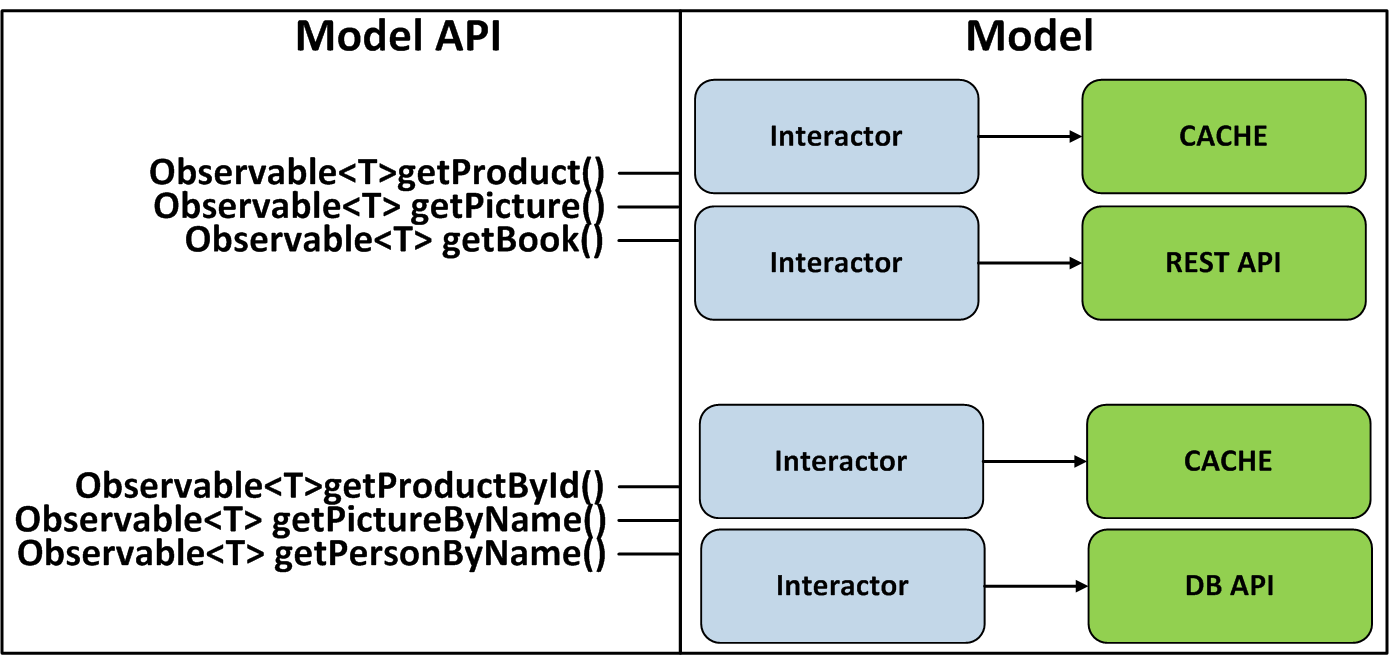
Nous pouvons aller plus loin et faire du Presenter une API réactive, mais pour cela, nous devons implémenter correctement le mécanisme de désabonnement qui permet à toutes les vues de se désinscrire simultanément du Presenter.
Ensuite, regardons un exemple de la façon dont cette approche est appliquée à l'architecture VIPER, qui est un MVP amélioré. Il convient également de se rappeler que vous ne pouvez pas créer d'objets singleton Observable, car les abonnements à un tel Observable généreront des fuites de mémoire.
Expérience dans Android et VIPER
Dans la plupart des projets Android actuels et nouveaux, nous utilisons l'architecture VIPER. Je l'ai rencontrée lorsque j'ai rejoint l'un des projets dans lesquels elle était déjà utilisée. Je me souviens avoir été surpris quand on m'a demandé si je regardais vers iOS. «IOS dans un projet Android?» Ai-je pensé. Pendant ce temps, VIPER nous est venu du monde iOS et est en fait une version plus structurée et modulaire de MVP. VIPER est très bien écrit dans cet article (3).
Au début, tout semblait aller bien: couches correctement divisées, pas surchargées, chaque couche a sa propre zone de responsabilité, logique claire. Mais après un certain temps, un inconvénient a commencé à apparaître et, à mesure que le projet grandissait et changeait, il a même commencé à interférer.
Le fait est que nous avons utilisé Interactor de la même manière que nos collègues dans notre article. Interactor implémente un petit cas d'utilisation, par exemple «télécharger des produits à partir du réseau» ou «prendre un produit de la base de données par identifiant», et effectue des actions dans le flux de travail. En interne, l'Interactor effectue des opérations à l'aide d'un Observable. Pour "exécuter" l'Interactor et obtenir le résultat, l'utilisateur implémente l'interface ObserverEntity avec ses méthodes onNext, onError et onComplete et la transmet avec les paramètres à la méthode execute (params, ObserverEntity).
Vous avez probablement déjà remarqué le problème - la structure de l'interface. En pratique, nous avons rarement besoin des trois méthodes, souvent en utilisant une ou deux d'entre elles. Pour cette raison, des méthodes vides peuvent apparaître dans votre code. Bien sûr, nous pouvons marquer toutes les méthodes de l'interface par défaut, mais de telles méthodes sont plutôt nécessaires pour ajouter de nouvelles fonctionnalités aux interfaces. De plus, c'est bizarre d'avoir une interface où toutes ses méthodes sont facultatives. Nous pouvons également, par exemple, créer une classe abstraite qui hérite d'une interface et remplacer les méthodes dont nous avons besoin. Ou, enfin, créez des versions surchargées de la méthode execute (params, ObserverEntity) qui acceptent une à trois interfaces fonctionnelles. Ce problème est mauvais pour la lisibilité du code, mais heureusement, il est assez facile à résoudre. Cependant, elle n'est pas la seule.
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
// ,
//
}
@Override
public void onError(Throwable throwable) {
//
// -
}
@Override
public void onComplete() {
//
// -
}
});
Outre les méthodes vides, il y a un problème plus ennuyeux. Nous utilisons Interactor pour effectuer une action, mais cette action n'est presque toujours pas la seule. Par exemple, nous pouvons prendre un produit dans une base de données, puis obtenir des critiques et une photo à son sujet, puis l'enregistrer dans un autre endroit et enfin aller sur un autre écran. Ici, chaque action dépend de la précédente, et lors de l'utilisation d'Interactors, nous obtenons une énorme chaîne de rappels, qui peut être très fastidieux à tracer.
private void checkProduct(int id, Locale locale) {
getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale), new ObserverEntity<Product>() {
@Override
public void onNext(Product product) {
getProductInfo(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void getProductInfo(Product product) {
getReviewsByProductIdInteractor.execute(product.getId(), new ObserverEntity<List<Review>>() {
@Override
public void onNext(List<Review> reviews) {
product.setReviews(reviews);
saveProduct(productInfo);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
// -
}
});
getImageForProductInteractor.execute(product.getId(), new ObserverEntity<Image>() {
@Override
public void onNext(Image image) {
product.setImage(image);
saveProduct(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void saveProduct(Product product) {
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
goToSomeScreen();
}
});
}
Eh bien, comment aimez-vous ce macaroni? En même temps, nous avons une logique métier simple et une imbrication unique, mais imaginez ce qui se passerait avec un code plus complexe. Cela rend également difficile la réutilisation de la méthode et l'application de différents planificateurs pour l'Interactor.
La solution est étonnamment simple. Avez-vous l'impression que cette approche essaie d'imiter le comportement d'un observable, mais elle le fait mal et crée elle-même des contraintes étranges? Comme je l'ai déjà dit, nous avons obtenu ce code à partir d'un projet existant. Lors de la correction de ce code hérité, nous utiliserons l'approche que les gars de Netflix nous ont léguée. Au lieu d'avoir à implémenter un ObserverEntity à chaque fois, faisons en sorte que l'Interactor renvoie simplement un Observable.
private Observable<Product> getProductById(int id, Locale locale) {
return getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale));
}
private Observable<Product> getProductInfo(Product product) {
return getReviewsByProductIdInteractor.execute(product.getId())
.map(reviews -> {
product.set(reviews);
return product;
})
.flatMap(product -> {
getImageForProductInteractor.execute(product.getId())
.map(image -> {
product.set(image);
return product;
})
});
}
private Observable<Product> saveProduct(Product product) {
return saveProductInteractor.execute(product);
}
private doAll(int id, Locale locale) {
//
getProductById (id, locale)
//
.flatMap(product -> getProductInfo(product))
//
.flatMap(product -> saveProduct(product))
//
.ignoreElements()
//
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
//
.subscribe(() -> goToSomeScreen(), throwable -> handleError());
}
Voila! Nous avons donc non seulement éliminé cette horreur encombrante et lourde, mais également apporté la puissance de RxJava à Presenter.
Les concepts au cœur
J'ai assez souvent vu comment ils essayaient d'expliquer le concept de RxJava en utilisant la programmation réactive fonctionnelle (ci-après FRP). En fait, cela n'a rien à voir avec cette bibliothèque. Le FRP concerne davantage les significations (comportements) à changement dynamique continu, le temps continu et la sémantique dénotationnelle. À la fin de l'article, vous pouvez trouver quelques liens intéressants (4, 5, 6, 7).
RxJava utilise la programmation réactive et la programmation fonctionnelle comme concepts de base. La programmation réactive peut être décrite comme un transfert séquentiel d'informations de l'objet observé à l'objet observateur de telle sorte que l'objet observateur la reçoive automatiquement (de manière asynchrone) lorsque ces informations surviennent.
La programmation fonctionnelle utilise le concept de fonctions pures, c'est-à-dire celles qui n'utilisent pas ou ne changent pas d'état externe; ils dépendent complètement de leurs intrants pour obtenir leurs extrants. L'absence d'effets secondaires pour les fonctions pures permet d'utiliser les résultats d'une fonction comme paramètres d'entrée dans une autre. Cela permet de composer une chaîne illimitée de fonctions.
L'association de ces deux concepts, ainsi que des modèles GoF Observer et Iterator, vous permet de créer des flux de données asynchrones et de les traiter avec un énorme arsenal de fonctions très pratiques. Il permet également d'utiliser le multithreading très simplement, et surtout en toute sécurité, sans penser à ses problèmes tels que la synchronisation, l'incohérence de la mémoire, le chevauchement des threads, etc.
Trois baleines de RxJava
Les trois principaux composants sur lesquels RxJava est construit sont Observable, les opérateurs et les planificateurs.
Observable dans RxJava est responsable de la mise en œuvre du paradigme réactif. Les observables sont souvent appelés flux car ils implémentent à la fois le concept de flux de données et la propagation des changements. Observable est un type qui réalise un paradigme réactif en combinant deux modèles du Gang of Four: Observer et Iterator. Observable ajoute deux sémantiques manquantes à Observer, qui sont dans Iterable:
- La possibilité pour le producteur de signaler au consommateur qu'il n'y a plus de données disponibles (la boucle foreach sur Iterable se termine et retourne simplement; l'Observable dans ce cas appelle la méthode onCompleate).
- La possibilité pour le producteur d'informer le consommateur qu'une erreur s'est produite et que l'Observable ne peut plus émettre d'éléments (Iterable lève une exception si une erreur se produit pendant l'itération; Observable appelle onError sur son observateur et quitte).
Si Iterable utilise l'approche «pull», c'est-à-dire que le consommateur demande une valeur au producteur et que le thread se bloque jusqu'à ce que cette valeur arrive, alors l'Observable est son équivalent «push». Cela signifie que le producteur n'envoie des valeurs au consommateur que lorsqu'elles sont disponibles.
Observable n'est que le début de RxJava. Il vous permet de récupérer des valeurs de manière asynchrone, mais la puissance réelle vient avec des "extensions réactives" (d'où ReactiveX) - opérateursqui vous permettent de transformer, combiner et créer des séquences d'éléments émis par un observable. C'est là que le paradigme fonctionnel prend le dessus avec ses fonctions pures. Les opérateurs utilisent pleinement ce concept. Ils vous permettent de travailler en toute sécurité avec les séquences d'éléments qu'un Observable émet, sans crainte d'effets secondaires, à moins, bien sûr, que vous les créez vous-même. Les opérateurs permettent le multithreading sans se soucier des problèmes tels que la sécurité des threads, le contrôle des threads de bas niveau, la synchronisation, les erreurs d'incohérence de la mémoire, les superpositions de threads, etc. Disposant d'un large arsenal de fonctions, vous pouvez facilement utiliser diverses données. Cela nous donne un outil très puissant. La chose principale à retenir est que les opérateurs modifient les éléments émis par l'Observable, pas l'Observable lui-même.Les observables ne changent jamais depuis leur création. Lorsque vous pensez aux threads et aux opérateurs, il est préférable de penser aux graphiques. Si vous ne savez pas comment résoudre le problème, réfléchissez, regardez la liste complète des opérateurs disponibles et réfléchissez à nouveau.
Alors que le concept de programmation réactive lui-même est asynchrone (à ne pas confondre avec le multithreading), par défaut, tous les éléments d'un Observable sont livrés à l'abonné de manière synchrone, sur le même thread sur lequel la méthode subscribe () a été appelée. Pour introduire la même asynchronie, vous devez soit appeler les méthodes onNext (T), onError (Throwable), onComplete () vous-même dans un autre thread d'exécution, soit utiliser des planificateurs. Habituellement, tout le monde analyse son comportement, alors jetons un coup d'œil à leur structure.
Planificateursabstraire l'utilisateur de la source du parallélisme derrière sa propre API. Ils garantissent qu'ils fourniront certaines propriétés quel que soit le mécanisme de concurrence sous-jacent (implémentation), tels que Threads, boucle d'événements ou Executor. Les planificateurs utilisent des threads de démon. Cela signifie que le programme se terminera avec la fin du thread principal d'exécution, même si un certain calcul se produit à l'intérieur de l'opérateur Observable.
RxJava a plusieurs programmateurs standard qui conviennent à des fins spécifiques. Ils étendent tous la classe abstraite Scheduler et implémentent leur propre logique de gestion des travailleurs. Par exemple, le ComputationScheduler, au moment de sa création, forme un pool de workers dont le nombre est égal au nombre de threads du processeur. Le ComputationScheduler utilise ensuite des nœuds de calcul pour effectuer des tâches exécutables. Vous pouvez transmettre le Runnable au planificateur à l'aide des méthodes scheduleDirect () et schedulePeriodicallyDirect (). Pour les deux méthodes, le planificateur prend le prochain worker du pool et lui transmet le Runnable.
Le worker se trouve à l'intérieur du planificateur et est une entité qui exécute des objets exécutables (tâches) à l'aide de l'un des nombreux schémas de concurrence. En d'autres termes, le planificateur reçoit le Runnable et le transmet au worker pour exécution. Vous pouvez également obtenir indépendamment un travailleur du planificateur et lui transférer un ou plusieurs exécutables, indépendamment des autres travailleurs et du planificateur lui-même. Lorsqu'un travailleur reçoit une tâche, il la met dans la file d'attente. Le travailleur garantit que les tâches sont exécutées séquentiellement dans l'ordre dans lequel elles ont été soumises, mais l'ordre peut être perturbé par les tâches en attente. Par exemple, dans ComputationScheduler, le worker est implémenté à l'aide d'un ScheduledExecutorService à un seul thread.
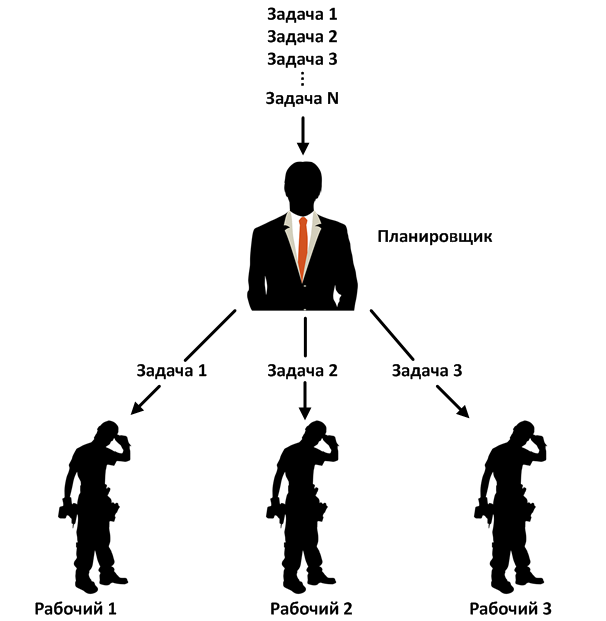
Ainsi, nous avons des travailleurs abstraits qui peuvent implémenter n'importe quel schéma de parallélisme. Cette approche présente de nombreux avantages: modularité, flexibilité, une API, différentes implémentations. Nous avons vu une approche similaire dans ExecutorService. De plus, nous pouvons utiliser des planificateurs distincts de Observable.
Conclusion
RxJava est une bibliothèque très puissante qui peut être utilisée de différentes manières dans de nombreuses architectures. Les façons de l'utiliser ne se limitent pas à celles existantes, essayez donc toujours de l'adapter pour vous-même. Cependant, rappelez-vous des principes de conception SOLID, DRY et autres, et n'oubliez pas de partager votre expérience avec vos collègues. J'espère que vous avez pu apprendre quelque chose de nouveau et d'intéressant de l'article, à bientôt!