J'ai décidé de créer une multisession à partir d'enregistrements audio accumulés en un mois calendaire afin d'éviter un encombrement inutile pour Adobe Audition. Bien sûr, une telle session peut être construite manuellement, mais c'est un travail long et laborieux. L'intérêt principal de cette tâche est d'automatiser la construction d'une multisession par logiciel. Plus précisément, écrivez un programme qui, basé sur une liste de fichiers d'enregistrement audio, générera un fichier SES pour une multisession Adobe Audition. Pour ceux qui ne sont pas au courant: une multisession, en bref, est un projet composé de nombreux enregistrements audio différents répartis dans le temps et sur des pistes (pistes) et conçu pour créer un mix à partir d'eux.
Tout d'abord, il vaut la peine de discuter de la façon dont j'obtiens les enregistrements audio des conversations téléphoniques. Ce n'est un secret pour personne que les smartphones modernes ont la capacité d'enregistrer les appels téléphoniques avec divers outils, à la fois intégrés au système et à des tiers. Personnellement, j'utilise une tablette Lenovo TAB3 (avec processeur MT8735P). L'appareil vous permet de faire des enregistrements audio en mode manuel dans un format compressé, en recevant des fichiers avec l'extension 3gpp. Les enregistrements sont obtenus en stéréo avec des canaux séparés: la voix de l'abonné est enregistrée dans un canal et sa propre voix dans l'autre. Le format compressé des enregistrements audio affecte leur distorsion pendant la lecture. Pour cette raison, j'utilise des applications d'enregistrement audio tierces, dont il existe d'innombrables. L'une des applications que j'ai le plus aimé est «Enregistrer mon appel».Cette application enregistre les appels en mode automatique, dispose de nombreux paramètres liés, notamment, au choix du format et de la qualité de l'enregistrement audio. Et aussi, en prime, l'application dispose d'un joli journal d'appels intégré très pratique, qui est enregistré dans le fichier de base de données db (Fig. 1).
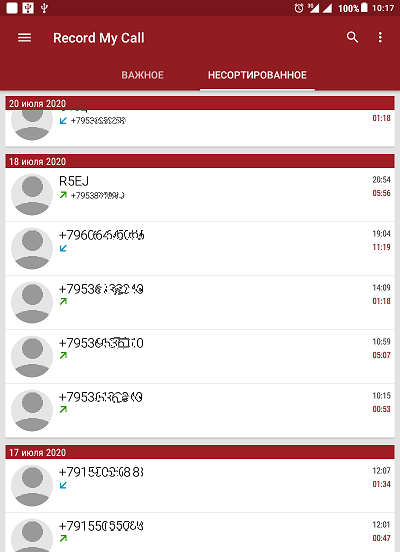
Figure: 1. Journal des appels dans l'application "Enregistrer mon appel".
Les meilleurs paramètres d'enregistrement audio pour la qualité sonore sont WAV 8000Hz 16bit Stereo. Avec de tels réglages, l'enregistrement n'a pas de distorsions, sonne clair, bien qu'il prenne plus d'espace mémoire. L'application est configurée de manière à ce que l'enregistrement audio démarre automatiquement avant même le début d'une conversation téléphonique: lorsqu'un appel entrant arrive avant de «décrocher le combiné» ou lors de la composition d'un numéro pendant les bips. Autrement dit, les appels manqués et sans réponse sont également enregistrés. Peut être configuré pour enregistrer uniquement la conversation. Le format du nom du fichier d'enregistrement audio est également configurable. Dans mon cas, je l'ai configuré comme le montre la figure 2.
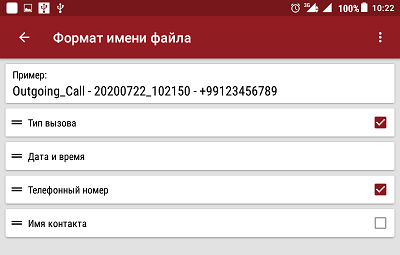
Fig. 2. Définition du format du nom de fichier dans «Enregistrer mon appel».
Lors du développement du programme de génération multisession, il sera nécessaire de prendre des informations sur la date et l'heure de l'enregistrement audio de l'appel téléphonique. Ces informations seront tirées du nom du fichier à des positions fixes.
Avant de commencer à créer un fichier SES multisession, vous devez comprendre comment un tel fichier fonctionne. Bien sûr, il n'y a nulle part de documentation sur ce format, donc j'ai dû le résoudre moi-même, en m'appuyant sur l'expérience et les connaissances personnelles. Ce fichier n'est pas un fichier texte, il est donc inutile de l'ouvrir dans le Bloc-notes. "WinHex" - un éditeur hexadécimal vient à la rescousse. J'ai déjà écrit un certain nombre d'articles sur le travail avec des données binaires et le décryptage d'informations, en particulier, un article sur l'écriture d'un programme de reconditionnement vidéo 264-avi. Là, j'ai écrit plus ou moins en détail sur le périphérique du fichier avi.
Tout d'abord, j'ai créé une simple multisession arbitraire dans Adobe Audition 1.5, composée d'une piste et d'un fichier audio (Fig. 3), en l'enregistrant dans un fichier avec l'extension ses. Le fichier a une taille de 2422 octets. Ensuite, j'ai ouvert ce fichier dans WinHex (Fig. 4).
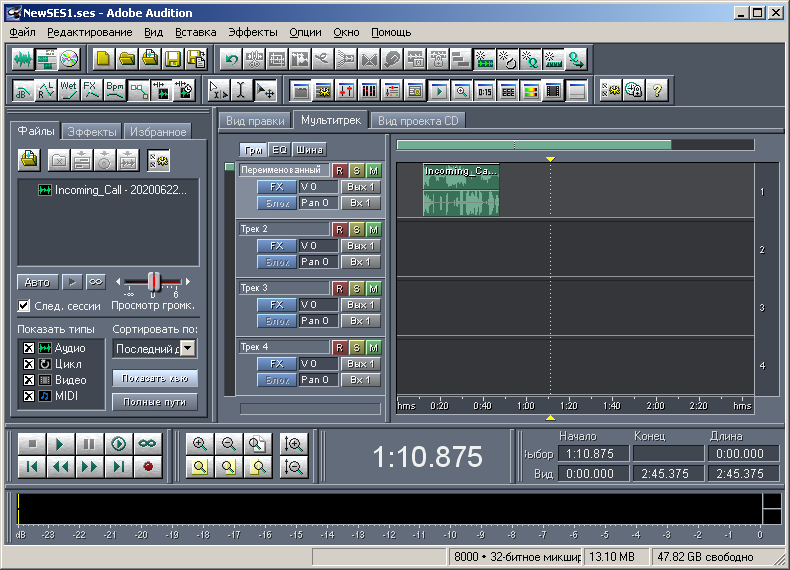
Figure: 3. Vue de la multisession dans Adobe Audition 1.5 - Exemple 1.
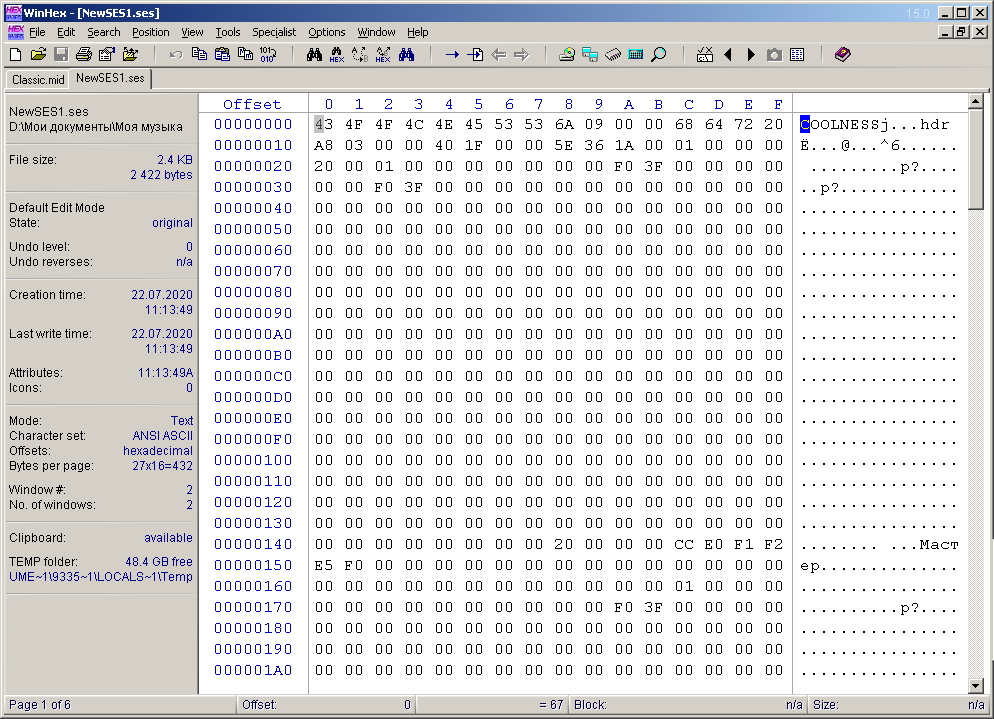
Fig. 4. Fichier multisession ouvert dans WinHex.
À première vue, rien n'est clair du tout. Dans la partie symbolique de la fenêtre, vous pouvez voir les mots sémantiques "COOLNESS", "hdr", "Master". Si vous faites défiler le document ci-dessous, vous pouvez voir le texte contenant le chemin complet du fichier (et, en deux versions), qui est utilisé dans la multisession. Ceci est illustré à la figure 5 et entouré en vert. Les mots sémantiques courts encerclés dans un cadre rouge sur la même figure sont immédiatement frappants.
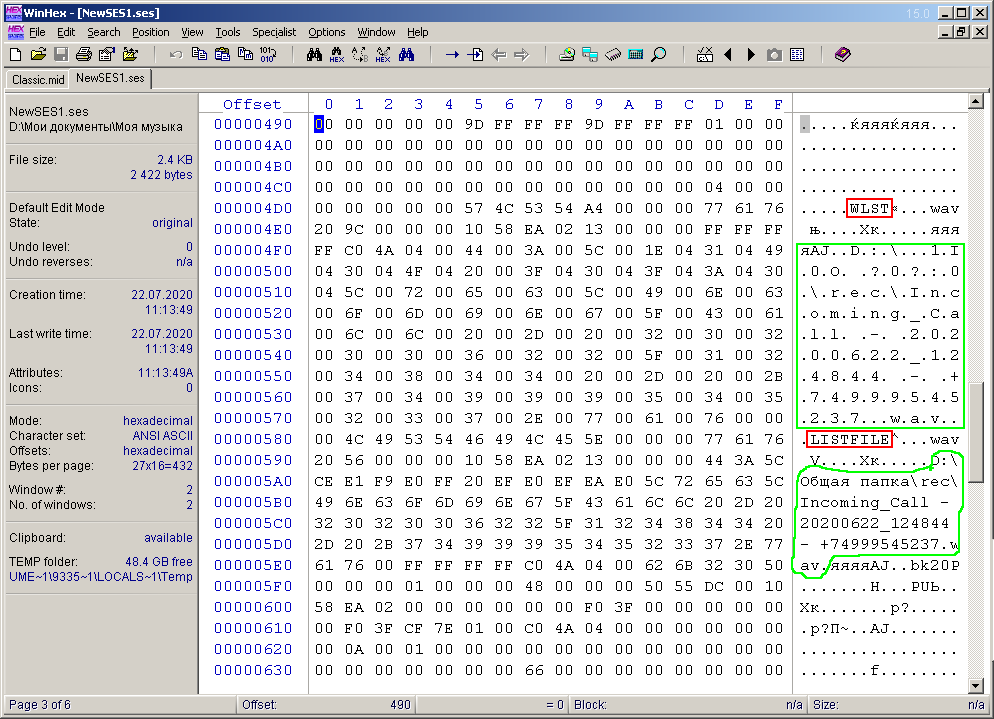
Figure: 5. Octets de chemins vers des fichiers audio multisession.
En regardant de plus près ce document du début à la fin, j'ai remarqué quelques autres mots sémantiques courts. J'ai également remarqué que la longueur de tout mot significatif est un multiple de quatre. Apparemment, ces mots sont les en-têtes des blocs qui composent l'ensemble du fichier multisession. Cela m'a rappelé la structure RIFF d'un fichier avi ou wav, composé de blocs qui ont également des en-têtes de la même taille. Ces en-têtes étaient suivis d'un nombre de 32 bits (4 octets) indiquant la taille du bloc actuel. Avec ce fait à l'esprit, j'ai décidé de vérifier si ce principe fonctionne pour le fichier ses? Il s'est avéré que dans le cas du format ses, cela fonctionne également (Fig. 6).
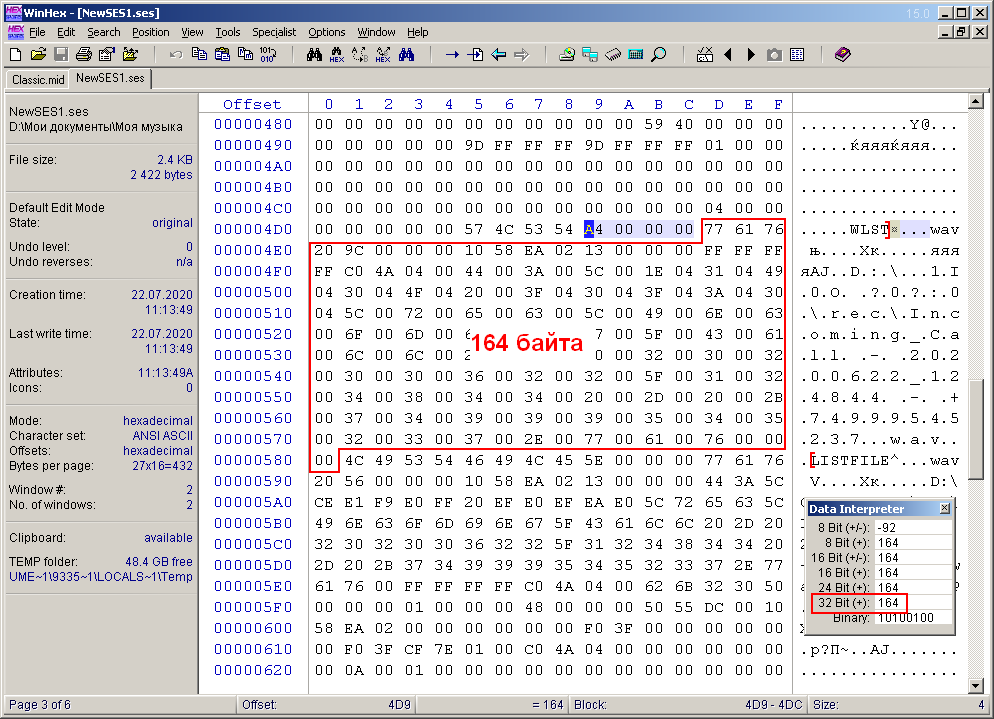
Figure: 6. Similitude avec la structure RIFF (par exemple, le bloc "WLST").
Le premier mot "COOLNESS" dans le fichier ses semble être l'en-tête principal et le type de ce fichier. Les 4 octets suivants correspondent à la taille du contenu placé ensuite, jusqu'à la fin du fichier. Autrement dit, si vous calculez soigneusement, cette valeur est inférieure de 12 octets à la taille du fichier entier. Et le contenu supplémentaire consiste en une collection de différents blocs. Le bloc a un en-tête de quatre ou huit octets, suivis de 4 octets indiquant la taille de ce bloc, et après eux le contenu de ce bloc suit. Dans certains blocs, j'ai identifié la présence de sous-blocs, mais cela sera discuté au cours d'une description plus détaillée de chaque bloc. Dans ce fichier, qui dans l'exemple, j'ai compté 17 blocs, ils sont répertoriés dans le tableau de la figure 7.
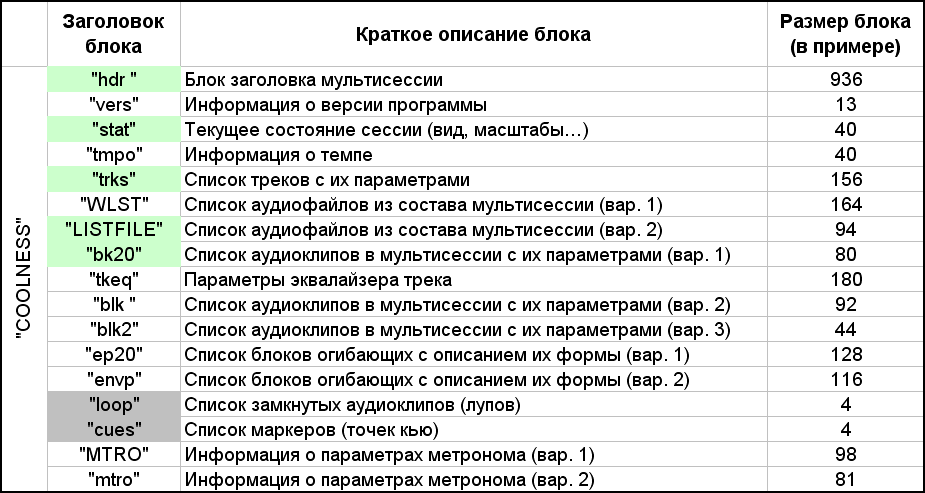
Fig. 7. Liste des blocs qui composent la multisession.
Comme vous pouvez le voir dans le tableau, certaines des mêmes informations sont présentées dans différentes versions par différents blocs. Ceci est probablement fait pour la compatibilité des différentes versions du programme. Pour l'avenir, ces blocs sont surlignés en vert, sans quoi la multisession présentée dans l'exemple ne peut exister. Deux blocs de 4 octets sont surlignés en gris, qui sont fictifs dans cette session. En effet, j'avais une question: que se passera-t-il si vous supprimez certains blocs du fichier? Après tout, par exemple, je n'ai pas besoin d'informations sur le métronome et le tempo, et les enveloppes sur les clips (plus précisément, sur un clip) manquent dans mon exemple simple. Les enveloppes sont des courbes au-dessus d'un clip audio qui définissent la dynamique des paramètres sonores (volume, balance) dans le temps. J'ai commencé séquentiellement à couper des blocs à partir du fichier donné,sans oublier de recalculer et de corriger la valeur après le mot "COOLNESS". En conséquence, la multisession a été ouverte avec succès avec au moins cinq blocs surlignés en vert. La session contient deux blocs de la liste des fichiers audio. N'importe lequel d'entre eux pourrait être laissé. Je préfère la deuxième option (le bloc "LISTFILE"), car dans la première option (le bloc "WLST") il y a deux octets par caractère dans la description du chemin du fichier. Cela peut avoir été fait pour l'alphabet de caractères étendus, mais l'alphabet ASCII standard me suffit. De plus, comme vous pouvez le voir, les caractères russes sont bien pris en charge. La description des clips audio est présentée en trois versions. J'ai choisi la première option (bloc "bk20"), car j'ai compris sa description le plus rapidement.La session contient deux blocs de la liste des fichiers audio. N'importe lequel d'entre eux pourrait être laissé. Je préfère la deuxième option (le bloc "LISTFILE"), car dans la première option (le bloc "WLST") il y a deux octets par caractère dans la description du chemin du fichier. Cela peut avoir été fait pour l'alphabet de caractères étendus, mais l'alphabet ASCII standard me suffit. De plus, les caractères russes, comme vous pouvez le voir, sont bien supportés. La description des clips audio est présentée en trois versions. J'ai choisi la première option (bloc "bk20"), car j'ai compris sa description le plus rapidement.La session contient deux blocs de la liste des fichiers audio. N'importe lequel d'entre eux pourrait être laissé. Je préfère la deuxième option (le bloc "LISTFILE"), car dans la première option (le bloc "WLST"), il y a deux octets par caractère dans la description du chemin du fichier. Cela peut avoir été fait pour l'alphabet de caractères étendus, mais l'alphabet ASCII standard me suffit. De plus, comme vous pouvez le voir, les caractères russes sont bien pris en charge. La description des clips audio est présentée en trois versions. J'ai choisi la première option (bloc "bk20"), car j'ai compris sa description le plus rapidement.mais l'alphabet ASCII standard me suffit. De plus, comme vous pouvez le voir, les caractères russes sont bien pris en charge. La description des clips audio est présentée en trois versions. J'ai choisi la première option (bloc "bk20"), car j'ai compris sa description le plus rapidement.mais l'alphabet ASCII standard me suffit. De plus, comme vous pouvez le voir, les caractères russes sont bien pris en charge. La description des clips audio est présentée en trois versions. J'ai choisi la première option (bloc "bk20"), car j'ai compris sa description le plus rapidement.
Une multisession à partir d'enregistrements audio de conversations téléphoniques aura une complexité similaire à la multisession présentée dans cet exemple. La seule différence est qu'il sera plus volumineux: le nombre de fichiers audio sera assez important, et le nombre de pistes sera égal au nombre de jours dans un mois. Pour une telle multisession, aucun autre "cloches et sifflets" n'est nécessaire. Les tailles de bloc "hdr" et "stat" sont statiques et sont toujours de 936 et 40 octets, respectivement, quelle que soit la taille de la multisession. Les tailles des blocs «trks» et «bk20» dépendent du nombre de pistes et de clips audio dans la multisession, respectivement. Mais la taille du bloc "LISTFILE" est la plus imprévisible: elle dépend non seulement du nombre de fichiers audio dans une multisession, mais aussi de la longueur de leurs noms et de leurs chemins de localisation.
Décrypter et composer une description complète des blocs d'un fichier multisession est une tâche assez longue. Par conséquent, j'ai partiellement décodé les informations, en ne prêtant attention qu'aux sections d'octets qui doivent être prises en compte lors de la formation d'une multisession de contenu simplifié. Dans cet article, je vais fournir une description du contenu de chaque bloc que j'ai pu déchiffrer.
Dans le contenu du bloc d'en-tête multisession "hdr" (il n'y a qu'un espace à la fin), les octets clés sont les 12 premiers octets, c'est-à-dire 3 mots de 4 octets chacun (Fig. 8). Le premier mot est le taux d'échantillonnage des échantillons dans la multisession. Pour ma multisession, cette valeur est de 8000 Hz (0x1F40). Dans la figure 8, il est mis en évidence avec un remplissage vert. Laissez-moi vous rappeler que les octets des mots pour les valeurs numériques sont lus à l'envers. Le deuxième mot est la durée (longueur) de la multisession, exprimée en nombre d'échantillons (remplissage orange sur la figure). Dans cet exemple, cette valeur est 0x1A365E (1717854). Si traduit en minutes, vous obtenez 1717854/8000/60, soit environ trois minutes et demie. Et il en est ainsi: à une échelle minimale, une multisession a exactement cette durée.Et pour une multisession à partir des enregistrements d'appels téléphoniques, la durée doit être d'un jour ou de 24 * 3600 * 8000 = 691200000 = 0x2932E000 échantillons. Dans cette situation, en passant, l'heure de lecture actuelle de la multisession sur le panneau ci-dessous, qui est une heure relative, coïncidera exactement avec la valeur de l'heure absolue de l'appel téléphonique en cours (ou d'un groupe d'appels par jour). Le mot suivant surligné en jaune indique le nombre de clips audio dans la multisession. Dans l'exemple, cette valeur est égale à un, mais dans le cas d'appels téléphoniques, le nombre de ces clips sera égal au nombre de fichiers audio. Pour l'avenir, la dernière affirmation n'est pas tout à fait correcte. En fait, le nombre de clips audio peut être légèrement supérieur au nombre de fichiers audio. Un fichier peut contenir deux clips dans le cas oùsi un nouveau jour est arrivé pendant une conversation téléphonique. Dans ce cas, vous devrez "transférer" l'enregistrement sur une nouvelle piste, et un clip ne fonctionnera pas. Mais de tels cas sont rares dans la pratique, car le passage à un nouveau jour se produit la nuit, lorsque l'activité des appels téléphoniques est minime. D'ailleurs, je n'ai pas pris ce point en compte lors de la formation du diagramme SVG dans l'article précédent. Après le mot de la valeur du nombre de blocs suit, très probablement, un "demi-mot" de deux octets 0x0020, ou 32 sous forme décimale. Il pourrait également être mis en évidence avec un remplissage de couleur, car cela signifie probablement la profondeur de bits du mélange. Dans Adobe Audition, la barre d'état en bas indique: 8000 Hz, mixage 32 bits. En plus des trois mots les plus essentiels du contenu "hdr", il existe d'autres octets obscurs. Par exemple, je ne connais même pas le mot «maître»à quoi il fait référence. Apparemment, c'est le nom du bus de mixage principal. Mais les groupes d'octets les plus intéressants que j'ai encerclés dans un cadre gris. Le fait est que cette séquence se trouve souvent dans d'autres blocs du fichier multisession. Ce n'est pas par hasard que j'ai combiné exactement 8 octets dans un groupe, car il s'agit probablement d'un type de données réel. En particulier, cette constante "00 00 00 00 00 00 F0 3F" HEX par l'éditeur en type Double est interprétée comme 1.0e + 0, c'est-à-dire comme une unité. Il s'agit très probablement des valeurs des niveaux de sonie et d'autres «torsions», mais spécifiées non pas en décibels, mais sous la forme d'un coefficient. Je dois dire tout de suite que tous les octets de tout bloc que je ne pourrais pas reconnaître (ou qui n'était pas nécessaire) seront écrits dans le fichier multisession généré sans changement, comme dans l'exemple.Mais les groupes d'octets les plus intéressants que j'ai encerclés dans un cadre gris. Le fait est que cette séquence se trouve souvent dans d'autres blocs du fichier multisession. Ce n'est pas par hasard que j'ai combiné exactement 8 octets dans un groupe, car il s'agit probablement d'un type de données réel. En particulier, cette constante "00 00 00 00 00 00 F0 3F" HEX par l'éditeur en type Double est interprétée comme 1.0e + 0, c'est-à-dire comme une unité. Il s'agit très probablement des valeurs des niveaux de sonie et d'autres «torsions», mais spécifiées non pas en décibels, mais sous la forme d'un coefficient. Je dois dire tout de suite que tous les octets de tout bloc que je ne pourrais pas reconnaître (ou qui n'était pas nécessaire) seront écrits dans le fichier multisession généré sans changement, comme dans l'exemple.Mais les groupes d'octets les plus intéressants que j'ai encerclés dans un cadre gris. Le fait est que cette séquence se trouve souvent dans d'autres blocs du fichier multisession. Ce n'est pas par hasard que j'ai combiné exactement 8 octets dans un groupe, car il s'agit probablement d'un type de données réel. En particulier, cette constante "00 00 00 00 00 00 F0 3F" HEX par l'éditeur en type Double est interprétée comme 1.0e + 0, c'est-à-dire comme une unité. Il s'agit très probablement des valeurs des niveaux de sonie et d'autres «torsions», mais spécifiées non pas en décibels, mais sous la forme d'un coefficient. Je dois dire tout de suite que tous les octets de tout bloc que je n'ai pas pu reconnaître (ou n'était pas nécessaire) seront écrits dans le fichier multisession généré sans changement, comme dans l'exemple.Ce n'est pas par hasard que j'ai combiné exactement 8 octets dans un groupe, car il s'agit probablement d'un type de données réel. En particulier, cette constante "00 00 00 00 00 00 F0 3F" HEX par l'éditeur en type Double est interprétée comme 1.0e + 0, c'est-à-dire comme une unité. Il s'agit très probablement des valeurs des niveaux de sonie et d'autres «torsions», mais spécifiées non pas en décibels, mais sous la forme d'un coefficient. Je dois dire tout de suite que tous les octets de tout bloc que je n'ai pas pu reconnaître (ou n'était pas nécessaire) seront écrits dans le fichier multisession généré sans changement, comme dans l'exemple.Ce n'est pas par hasard que j'ai combiné exactement 8 octets dans un groupe, car il s'agit probablement d'un type de données réel. En particulier, cette constante "00 00 00 00 00 00 F0 3F" HEX par l'éditeur en type Double est interprétée comme 1.0e + 0, c'est-à-dire comme une unité. Il s'agit très probablement des valeurs des niveaux de sonie et d'autres «torsions», mais spécifiées non pas en décibels, mais sous la forme d'un coefficient. Je dois dire tout de suite que tous les octets de tout bloc que je ne pourrais pas reconnaître (ou qui n'était pas nécessaire) seront écrits dans le fichier multisession généré sans changement, comme dans l'exemple.et comme coefficient. Je dois dire tout de suite que tous les octets de tout bloc que je n'ai pas pu reconnaître (ou n'était pas nécessaire) seront écrits dans le fichier multisession généré sans changement, comme dans l'exemple.et comme coefficient. Je dois dire tout de suite que tous les octets de tout bloc que je ne pourrais pas reconnaître (ou qui n'était pas nécessaire) seront écrits dans le fichier multisession généré sans changement, comme dans l'exemple.
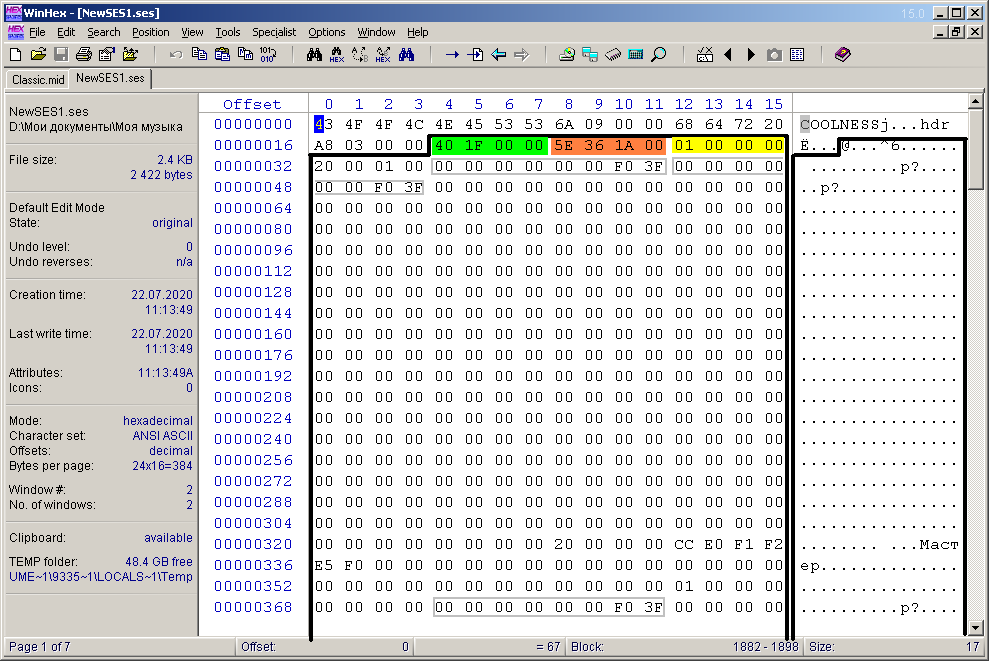
. 8. «hdr ».
J'ai décidé de ne pas étudier le bloc "stat" de l'état multisession actuel (le plus court). J'ai créé un autre exemple de multisession à partir d'un fichier audio, je l'ai étiré pendant 24 heures et j'ai fait sa vue complète (échelle) horizontalement. Et verticalement, la vue des pistes a été mise à l'échelle de sorte que lorsque la fenêtre Adobe Audition a été agrandie, 31 pistes puissent tenir sur l'écran FullHD. Il s'agit du nombre maximum de jours dans un mois. Le curseur multisession a été positionné au tout début. Ensuite, j'ai enregistré cette multisession dans un autre fichier, puis j'ai sorti le bloc "stat" avec tous ses en-têtes. J'ai enregistré ces octets dans le fichier "stat_31_full.BLK" pour une utilisation ultérieure dans le développement du programme. La vue du contenu d'un tel fichier est représentée sur la figure 9. La taille de ce fichier était de 48 octets (40 octets du contenu du bloc + 4 octets de l'en-tête + 4 octets de la description de la taille du contenu).
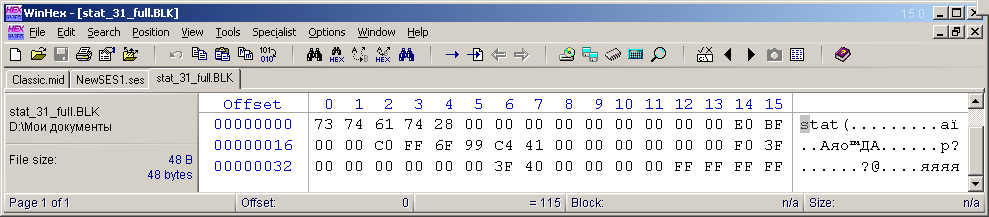
. 9. «stat» .
Pour une description plus visuelle des trois blocs suivants au cours de la rédaction de cet article, j'ai décidé de créer une multisession plus complexe, composée de deux pistes, deux fichiers et trois clips (Fig. 10). Le premier fichier "Incoming_Call - 20200622_124844 - + 74999545237.wav" a une durée de 281280 échantillons. Le deuxième fichier "Outgoing_Call - 20200621_231753 - + 79536170218.wav" a une durée de 63360 échantillons. La première piste nommée "First" (renommée) contient deux clips. Le premier clip est décalé du début de la session de 10 secondes (de 80 000 échantillons). Le clip est représenté par le contenu complet du premier fichier audio, c'est-à-dire que la durée du clip est la même que la durée du fichier. Le deuxième clip est décalé de 50 secondes à partir du début de la session (de 50 * 8000 = 400000 échantillons). Le clip est représenté par le contenu incomplet du deuxième fichier audio. Dans un clip donné, l'audio commence au début du fichier,mais ne dure que 5 secondes (40 000 échantillons). Autrement dit, la durée du clip est de 5 secondes. La deuxième piste nommée «Second» contient un clip. Il est décalé du début de la session d'une seconde (de 8 000 échantillons). Ce clip est représenté par le contenu incomplet du premier fichier audio. Dans ce clip, l'audio ne démarre pas depuis le début, mais après 3 secondes, mais le contient jusqu'à la toute fin. Ainsi, le décalage des données audio dans ce clip est de 3 secondes (24 000 échantillons). Et la longueur d'un clip donné est calculée comme la différence entre la durée de l'audio correspondant et le décalage des données audio dans le clip. Dans ce cas, la longueur du clip est de 281280-24000 = 257280 échantillons.Ce clip est représenté par le contenu incomplet du premier fichier audio. Dans ce clip, l'audio ne démarre pas depuis le début, mais après 3 secondes, mais le contient jusqu'à la toute fin. Ainsi, le décalage des données audio dans ce clip est de 3 secondes (24 000 échantillons). Et la longueur d'un clip donné est calculée comme la différence entre la durée de l'audio correspondant et le décalage des données audio dans le clip. Dans ce cas, la longueur du clip est de 281280-24000 = 257280 échantillons.Ce clip est représenté par le contenu incomplet du premier fichier audio. Dans ce clip, l'audio ne démarre pas depuis le début, mais après 3 secondes, mais le contient jusqu'à la toute fin. Ainsi, le décalage des données audio dans ce clip est de 3 secondes (24 000 échantillons). Et la longueur d'un clip donné est calculée comme la différence entre la durée de l'audio correspondant et le décalage des données audio dans le clip. Dans ce cas, la longueur du clip est de 281280-24000 = 257280 échantillons.Dans ce cas, la longueur du clip est de 281280-24000 = 257280 échantillons.Dans ce cas, la longueur du clip est de 281280-24000 = 257280 échantillons.
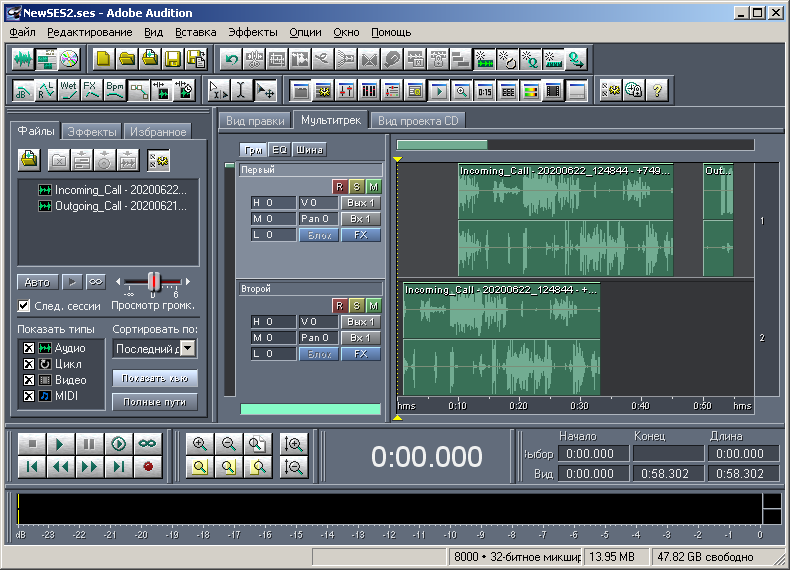
. 10. Adobe Audition 1.5 — 2.
La figure 11 montre la vue du contenu du bloc de description de piste "trks". Les 4 octets de l'en-tête du bloc sont mis en évidence dans le cadre rouge et la taille du contenu du bloc est dans le vert. Cela a déjà été discuté ci-dessus. Vient ensuite le contenu du bloc, dont les octets sont mis en évidence dans l'éditeur WinHex avec un remplissage bleuâtre caractéristique. La taille de la sélection, dont la valeur est affichée dans le coin inférieur droit de l'éditeur (également entouré en vert), coïncide avec la valeur des octets après l'en-tête, et déjà dans cet exemple, elle est de 308 octets. Si dans le premier exemple (précédent) d'une piste, la taille de bloc était de 156 octets et dans le premier exemple de 308 octets, alors la conclusion suivante peut être tirée. En raison de l'hypothèse d'homogénéité et d'équivalence des pistes, les zones de description de chaque piste doivent avoir la même taille. Ces zones, pour ainsi dire, sont des sous-blocs du bloc "trks".Ils sont encadrés en bleu sur la figure. Il s'est avéré que la taille d'un tel sous-bloc est de 152 octets. Et au tout début des sous-blocs consécutifs, il y a un sous-titre de quatre octets, marqué sur la figure avec un remplissage jaune. Ces quatre octets ne sont rien de plus que la valeur du nombre de pistes dans une multisession, ou le nombre de sous-blocs. Ainsi, la taille S du contenu du bloc "trks" peut être calculée par la formule S = 4 + 152 * n, où n est le nombre de pistes dans la session. Donc c'est: 4 + 152 * 1 = 156 et 4 + 152 * 2 = 308.la taille S du contenu du bloc "trks" peut être calculée par la formule S = 4 + 152 * n, où n est le nombre de pistes dans la session. C'est donc: 4 + 152 * 1 = 156 et 4 + 152 * 2 = 308.la taille S du contenu du bloc "trks" peut être calculée par la formule S = 4 + 152 * n, où n est le nombre de pistes dans la session. Donc c'est: 4 + 152 * 1 = 156 et 4 + 152 * 2 = 308.
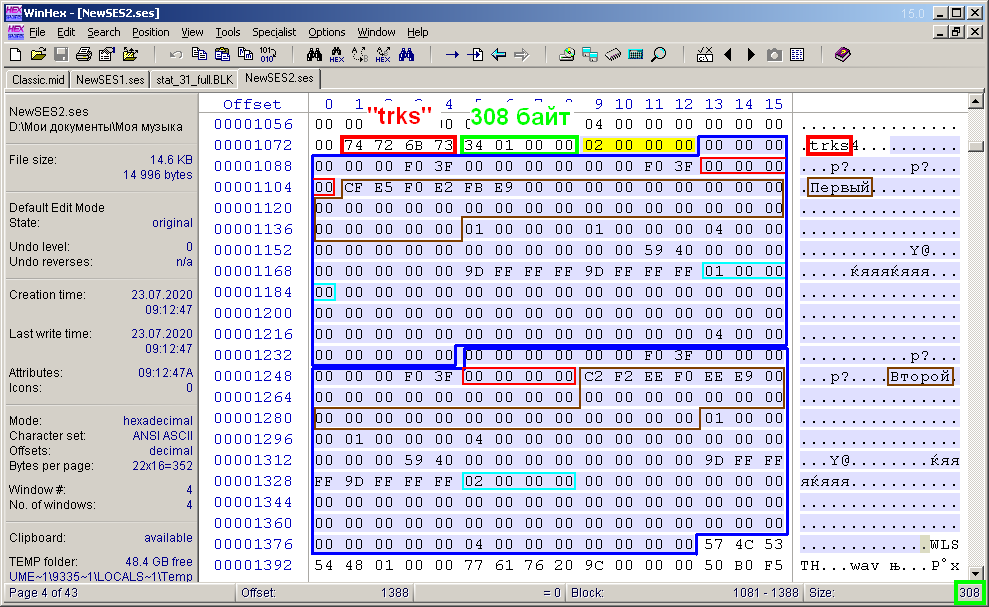
. 11. «trks».
Passons maintenant à la description du contenu du sous-bloc. Il y en a beaucoup, mais je n'ai déchiffré que l'essentiel. Il n'y a que trois paramètres: 4 octets d'indicateurs binaires (entourés en rouge), le nom de la piste (entouré en marron) et l'ID de la piste (entouré en bleu). L'identifiant de la piste est son numéro de séquence. Il est nécessaire d'indiquer un lien vers une piste dans la description des clips audio (plus à ce sujet plus tard). Le nom de la piste occupe une zone de 36 octets. Il s'agit du nombre maximum de caractères dans le nom de la piste, mais il peut être inférieur, comme dans l'exemple actuel. Les octets inutilisés sont zéro. Dans une multisession avec des enregistrements audio d'appels téléphoniques, les noms des pistes correspondront à l'enregistrement des dates correspondantes. Vous pouvez ajouter le jour de la semaine correspondant à côté de la date en deux lettres majuscules sous forme abrégée.Quatre octets de drapeaux binaires (32 drapeaux au total) sont destinés à décrire les paramètres binaires inhérents à la piste. En fait, il peut y en avoir moins de 32. Je n'ai décodé qu'une partie des drapeaux. Parmi ceux-ci, au moins trois indicateurs indiquent si la piste est «R» (Record), «S» (Solo) ou «M» (Mute). Dans l'exemple donné, aucun de ces trois boutons sur les pistes n'est enfoncé et la valeur des indicateurs binaires est zéro (0x00000000). Mais si vous appuyez sur le bouton "R" sur la piste (c'est-à-dire, mettez la piste en enregistrement) et enregistrez à nouveau la session, alors la valeur des drapeaux binaires sera égale à 0x00000004, en d'autres termes, le troisième bit à partir de la droite (bit2) deviendra un. C'est ce bit qui est responsable de la propriété "record" de la piste. Cette propriété n'a aucune signification dans mon projet, car ma multisession est conçue pour la visualisation et la lecture visuelles.Cependant, j'ai eu l'idée que le bouton "R" était enfoncé sur les pistes qui correspondent au week-end. Cette technique facilitera la visualisation de la multisession.
Le bloc de la liste des fichiers audio de la multisession "LISTFILE" (Fig. 12) se compose des parties suivantes. Comme dans le cas du bloc de description de piste, il peut également être divisé en sous-blocs en fonction du nombre de fichiers dans la session. Semblable à la figure 11, j'ai également mis en évidence l'en-tête de bloc de 8 octets dans une case rouge et la taille de son contenu dans une case verte. Dans cet exemple particulier, cette valeur est de 188 octets. Le contenu est mis en évidence par analogie avec la Fig. 11. Il est divisé en deux zones mises en évidence par une ligne bleue. Ce sont les sous-blocs du bloc de liste de fichiers.
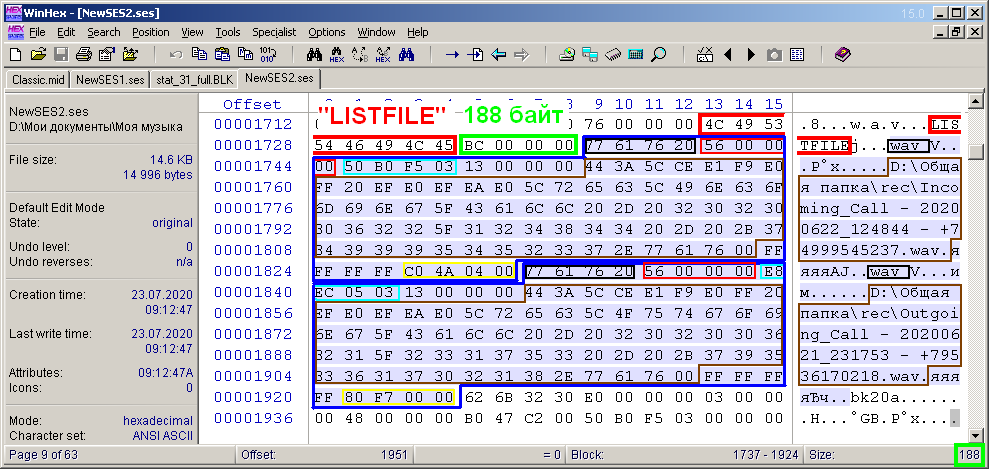
Figure: 12. Octets du bloc de description des fichiers audio "LISTFILE".
Chaque sous-bloc correspond à un fichier audio. L'exemple utilise deux fichiers audio, le nombre de sous-blocs est donc approprié. Contrairement au cas précédent avec des descriptions de pistes, il n'y a pas de sous-titre concernant le nombre de sous-blocs. Le sous-bloc contient 4 octets de son en-tête «wav» (surligné en noir) et 4 octets indiquant la taille du contenu supplémentaire (surligné en magenta). Pour les deux sous-blocs, cette valeur est la même dans cet exemple et correspond à 0x56 (86) octets. Cela est dû au fait que les fichiers se trouvent dans le même chemin et portent le même nom. Plus précisément, les noms de fichiers complets ont le même nombre de caractères. Sinon, les sous-unités auraient des tailles différentes. La zone de contenu du sous-bloc (octets supplémentaires) contient les informations suivantes. Un numéro identifiant le fichier audio est mis en surbrillance dans un cadre bleu.Contrairement à l'ID de piste, ce numéro n'est pas un numéro de séquence de fichier. Si je comprends bien, lors de l'enregistrement d'une multisession, elle est attribuée de manière aléatoire ou pseudo-aléatoire pour chaque fichier. L'essentiel est qu'il n'y ait pas de coïncidence entre ces valeurs. J'en étais convaincu lorsque j'ai enregistré deux fois la multisession et comparé les fichiers ses par contenu. En conséquence, il s'est avéré que les fichiers diffèrent uniquement par ces mêmes octets. Et pas seulement ceux-ci. Un nombre aléatoire est également attribué à l'ID des couches d'enveloppe dans le bloc «ep20». Mais dans ce bloc, comme mentionné ci-dessus, il n'y en a aucun besoin, et sa description ne sera pas prise en compte dans cet article. Des identifiants audio sont nécessaires pour les lier aux clips. Ce lien prend place dans le bloc avec la description des clips.Dans mon cas, pour une multisession avec des enregistrements téléphoniques, les identifiants des fichiers audio seront une séquence de nombres naturels, mais ne commençant pas à zéro, mais par exemple à 1000. Les 4 octets suivants, que je n'ai pas mis en évidence, dans les deux sous-blocs ont la valeur 0x13. Très probablement, cette valeur indique le type de format de fichier audio. Vous pouvez conditionnellement considérer cette valeur comme une constante, car tous les fichiers audio sont du même type. La chaîne d'octets suivante décrit le nom complet du fichier audio, avec un terminateur nul (tel qu'un terminateur de ligne). La taille de cette chaîne est un de plus que le nombre de caractères du nom complet du fichier audio. Vient ensuite la constante 0xFFFFFFFF. Il est suivi d'une valeur indiquant le nombre d'échantillons dans ce fichier audio (sur la figure 12 surligné dans un cadre jaune). Pour le premier fichier, cette valeur est 0x44AC0 et pour le second, c'est 0xF780.Ils correspondent juste aux valeurs décimales 281280 et 63360, respectivement, qui sont déjà apparues ci-dessus dans la description du deuxième exemple multisession.
Enfin, il reste à considérer la description du bloc le plus difficile - le bloc de description des clips audio "bk20" (Fig. 13). Par analogie avec les deux chiffres précédents, le titre et la taille du contenu du bloc sont mis en évidence.
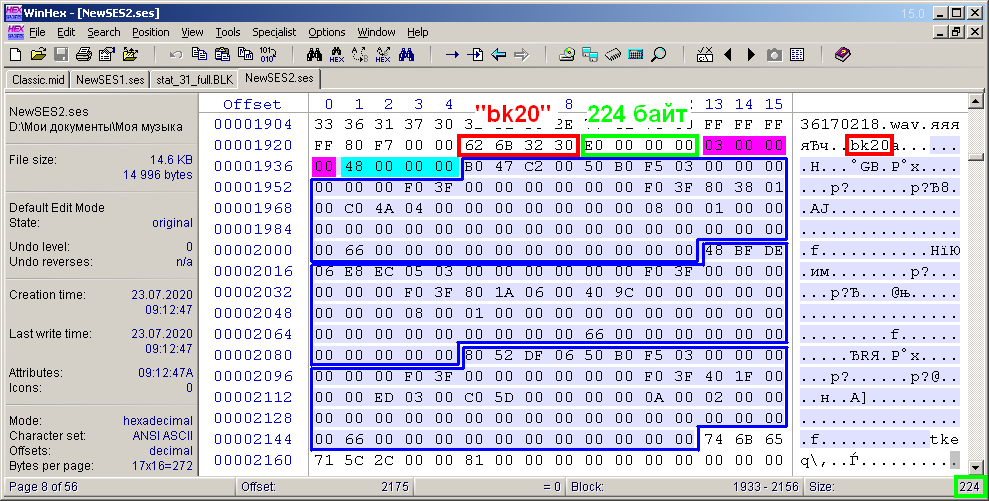
Figure: 13. Octets du bloc de description des clips audio "bk20".
Dans le contenu du bloc, tout d'abord, il y a deux sous-titres de 4 octets chacun. Ils sont mis en évidence avec des remplissages magenta et cyan. Le premier sous-titre correspond au nombre de clips dans la session. Il y en a trois dans l'exemple. Le deuxième sous-titre est la constante 0x48 (72). Apparemment, cela indique la taille de chaque sous-bloc, et ils vont juste plus loin. Leur nombre coïncide avec le nombre de clips de la session. Chacun de ces sous-blocs décrit les paramètres d'un clip. À propos, la taille D du contenu du bloc «bk20», il s'avère, peut être calculée par la formule D = 8 + 72 * b, où b est le nombre de clips audio dans une multisession. Dans la figure, il n'y a pas d'allocation d'octets explicative dans les sous-blocs, car il y a beaucoup de paramètres nécessaires. Ils sont répertoriés dans un tableau séparé (Fig. 14). Le remplissage bleu marque les paramètres nécessaires dans mon projet et le remplissage gris - constantes non reconnues.Ce tableau montre également les valeurs des paramètres pour chacun des trois clips multisession du dernier exemple.
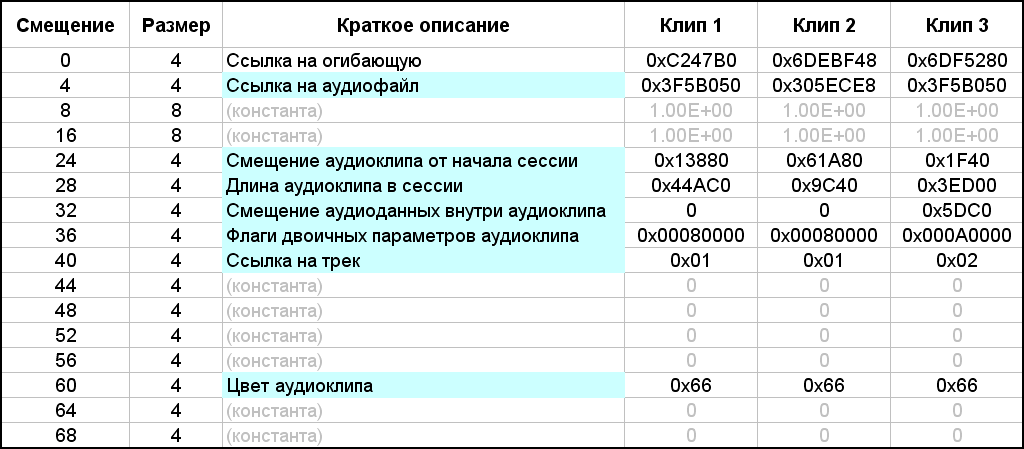
. 14. .
Le premier mot (groupe de 4 octets) est une référence à l'enveloppe, dont nous n'avons pas besoin. Le deuxième paramètre est un lien vers le fichier audio. La valeur de ce paramètre est égale à la valeur de l'identifiant du fichier audio auquel correspond ce clip audio. Ensuite, il y a deux constantes réelles, qui sont déjà apparues plus tôt. Ils sont suivis de trois paramètres de coordination exprimés en nombre d'échantillons: le décalage du clip depuis le début de la session, la longueur (durée) du clip dans la session et le décalage de l'audio dans le clip. Tout devrait être clair d'après les noms de ces paramètres. Auparavant, en décrivant en détail le deuxième exemple d'une multisession, j'ai indiqué les valeurs numériques de tous les décalages et durées. Dans la figure 14, le tableau répertorie les paramètres de chaque clip sous forme hexadécimale. J'ai entré ces valeurs dans le tableau en les réécrivant directement à partir de la figure 13.Mais si vous les convertissez en forme décimale, ils coïncideront avec les valeurs correspondantes de la description du deuxième exemple (vérifiées séparément). Il est à noter que les liens vers le fichier audio pour les premier et troisième clips ont la même valeur 0x3F5B050, puisque les deux clips font référence au même fichier audio avec l'identifiant correspondant. Ceci est suivi d'un bloc d'octets de paramètres binaires (4 octets). Comme dans le cas de la description des pistes, je n'ai décodé qu'une partie des bits. La valeur par défaut est 0x00080000, c'est-à-dire que si elle est traduite en binaire, un seul bit19 est "élevé" à un et les 31 bits restants sont égaux à zéro. Sans ce seul bit, comme la pratique l'a montré, la multisession refuse de se charger. Dans l'exemple actuel, une telle valeur est caractéristique des premier et deuxième clips, mais pour le troisième, pour une raison quelconque, la valeur des indicateurs est égale à 0x000A0000.Si vous comptez, alors dans cette valeur deux bits sont "soulevés": toujours le bit19 et un autre bit17. Je ne sais pas pourquoi c'est arrivé. J'ai essayé de réinitialiser bit17 à zéro, en changeant la valeur de tout le paramètre en 0x00080000, comme dans les clips voisins. En conséquence, la session dans Adobe Audition s'est ouverte sans aucune modification visible. En travaillant dans Adobe Audition, j'ai remarqué des propriétés de clip telles que "Fix in Time" et "Fix for Playback Only". Il est logique de supposer que certains bits du bloc de paramètres binaires sont responsables du stockage de ces propriétés. Il existe également d'autres propriétés binaires pour les clips, mais nous n'en avons pas besoin. Et les deux propriétés énumérées seront très utiles. La propriété "Fix in time" est utile car le clip sera protégé contre la possibilité d'un mouvement accidentel du pointeur de la souris dans le sens horizontal.Mais sur un tel clip, un symbole sous la forme d'un verrou dans un cercle sera visuellement dessiné dans le coin inférieur gauche, et ce sont des informations graphiques inutiles pour la visualisation. La deuxième propriété du clip «Fix for playback only» est utile en ce que lorsque le paramètre «R» (Record) est activé sur la piste correspondante, le clip n'acquiert pas une couleur rouge forcée. Pour ce que j'ai décidé d'utiliser le paramètre "R" sur certaines pistes - il est écrit ci-dessus. Empiriquement, j'ai compris que bit1 est responsable de la première propriété du clip et bit3 de la seconde. De tout ce qui a été dit, voici ce qui suit. Pour définir la propriété Clip in Time, vous devez écrire la valeur 0x00080002 dans les paramètres binaires. La propriété Valider pour la lecture uniquement est 0x00080008. Pour les deux propriétés, leur somme logique est 0x0008000A. Traite les paramètres binaires.Après ces octets, il y a un lien vers la piste sur laquelle se trouve le clip. En fait, l'identifiant de piste est enregistré, ce qui coïncide avec son numéro de série. Adobe Audition 1.5, en passant, ne prend pas en charge plus de 128 pistes, donc cet identifiant tient dans un octet, bien qu'il soit répertorié comme une valeur 32 bits. Ensuite, il y a des constantes nulles non déchiffrées (4 constantes, 4 octets chacune). Enfin, le dernier paramètre significatif est la couleur du clip. L'éditeur Adobe Audition 1.5 vous permet de définir une valeur de couleur de 0 à 239 pour un élément dans la boîte de dialogue correspondante ou de le sélectionner dans une palette (Fig. 15). La palette de couleurs n'est pas particulièrement agréable, mais d'autres options ne sont pas données. La couleur de clip par défaut est 102 (0x66) (vert).en passant, il ne prend pas en charge plus de 128 pistes, donc un tel identifiant tient dans un octet, bien qu'il soit répertorié comme une valeur de 32 bits. Ensuite, il y a des constantes nulles non déchiffrées (4 constantes, 4 octets chacune). Enfin, le dernier paramètre significatif est la couleur du clip. L'éditeur Adobe Audition 1.5 vous permet de définir une valeur de couleur de 0 à 239 pour un élément dans la boîte de dialogue correspondante ou de le sélectionner dans une palette (Fig. 15). La palette de couleurs n'est pas particulièrement agréable, mais d'autres options ne sont pas données. La couleur de clip par défaut est 102 (0x66) (vert).en passant, il ne prend pas en charge plus de 128 pistes, donc un tel identifiant tient dans un octet, bien qu'il soit répertorié comme une valeur de 32 bits. Ensuite, il y a des constantes nulles non déchiffrées (4 constantes, 4 octets chacune). Enfin, le dernier paramètre significatif est la couleur du clip. L'éditeur Adobe Audition 1.5 vous permet de définir une valeur de couleur de 0 à 239 pour un élément dans la boîte de dialogue correspondante ou de la sélectionner dans une palette (Fig. 15). La palette de couleurs n'est pas particulièrement agréable, mais d'autres options ne sont pas données. La couleur de clip par défaut est 102 (0x66) (vert).5 vous permet de définir une valeur de couleur de 0 à 239 pour le clip dans la boîte de dialogue correspondante ou de la sélectionner dans la palette (Fig. 15). La palette de couleurs n'est pas particulièrement agréable, mais d'autres options ne sont pas données. La couleur de clip par défaut est 102 (0x66) (vert).5 permet de définir une valeur de couleur de 0 à 239 pour le clip dans la boîte de dialogue correspondante ou de la sélectionner dans la palette (Fig. 15). La palette de couleurs n'est pas particulièrement agréable, mais d'autres options ne sont pas données. La couleur de clip par défaut est 102 (0x66) (vert).
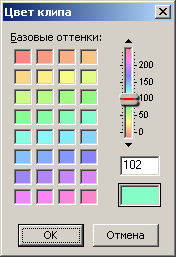
. 15. Adobe Audition 1.5.
Le paramètre de couleur dans le fichier ses est de 32 bits, et en fait il n'y a que 240 couleurs, ce qui tient dans un octet. Les trois autres octets les plus significatifs sont zéro. J'ai eu l'idée que si j'essayais d'éditer ces octets pour des valeurs différentes, lors de l'ouverture d'une multisession, de nouvelles couleurs apparaîtront sur le clip. Mais cette astuce n'a pas fonctionné. Comme indiqué dans l'article précédent, les couleurs d'un graphique sont utiles pour mettre en évidence visuellement une caractéristique particulière d'un appel téléphonique. Une multisession d'enregistrements audio d'appels téléphoniques ressemblera à un diagramme similaire, de sorte que la couleur des clips sera très utile. Le paramètre de couleur du clip est suivi de deux mots de zéros. Ceci termine la description de la sous-unité. Ces huit octets de zéros sont les derniers du sous-bloc du dernier bloc. Par conséquent, ils seront également les derniers de tout le fichier ses.
En réfléchissant au projet, j'ai eu une autre idée: ajouter des marqueurs (points de repère) à la multisession, les placer toutes les heures et leur signer les marques appropriées. Si nous comparons cette idée avec l'article précédent, il s'agit d'une analogie complète des lignes verticales du diagramme, dessinées toutes les heures. Pour que les points de repère soient présents dans la multisession, il est nécessaire de prendre en compte le sixième bloc appelé "cues". Je n'ai pas commencé à comprendre les octets de ce bloc. Par analogie avec le bloc "stat", dans la multisession créée pendant 24 heures, j'ai placé 23 points de repère manuellement toutes les heures et leur ai donné les noms appropriés. Ensuite, j'ai enregistré la multisession dans un fichier ses séparé, découpé le contenu du bloc "cues" et l'ai sauvegardé dans le fichier "cues_24h.BLK". Ce fichier sera pris en compte lors du développement du programme. Les octets de ce fichier sont indiqués dans la figure 16. Je ne sais pas pourquoi,mais j'ai enregistré exactement le contenu, sans le titre et le champ de taille du contenu (par opposition à "stat_31_full.BLK"). Ces deux mots seront ajoutés dans le code du programme. Et la taille du contenu est de 556 octets. Parmi ceux-ci, 4 octets sont occupés par un sous-titre (le nombre de points de repère) et 23 sous-blocs de 24 octets chacun. Sur la figure 16, les octets de contenu du premier sous-bloc sont remplis. J'ai décidé de faire les noms des points de repère (étiquettes) comme suit: 01h, 02h,…, 23h.
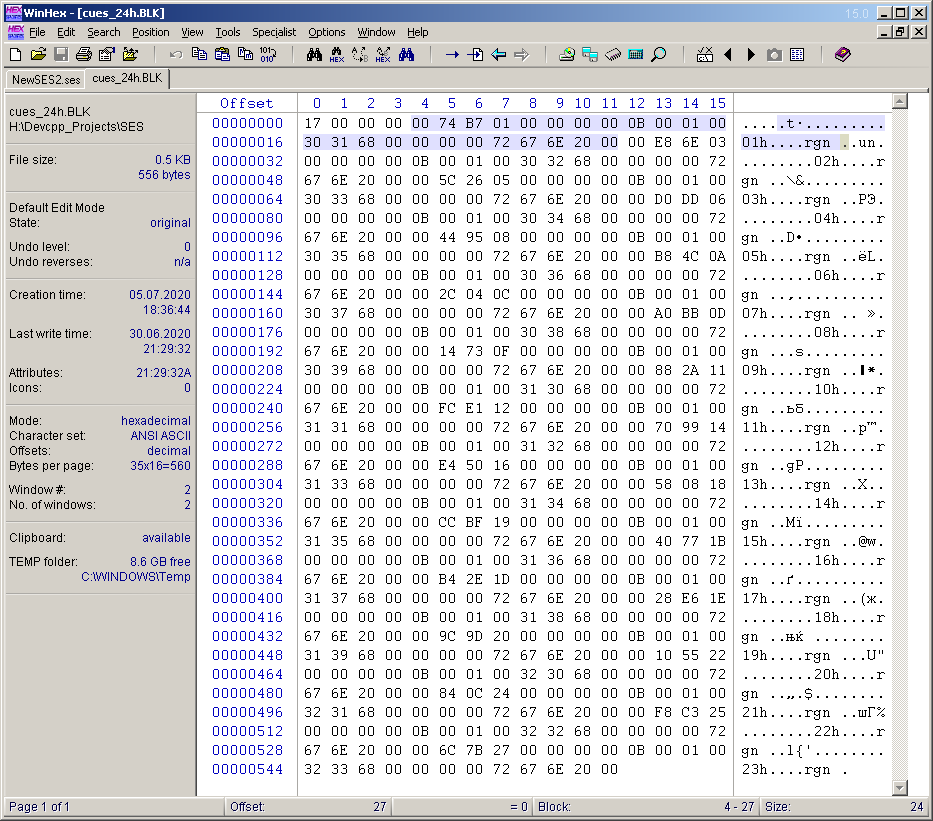
. 16. «cues» .
Ceci conclut la description du format multisession. Nous avons maintenant la base de connaissances nécessaire pour commencer à écrire un programme de création d'une multisession. Ecrire un programme est une tâche plus facile que d'apprendre et de décrypter le format ses. J'ai terminé le programme en deux soirs et j'ai passé au moins une semaine à étudier le format. De plus, j'ai écrit le programme en utilisant des fonctions précédemment utilisées, en particulier en travaillant avec des fichiers et des répertoires. Par conséquent, le principal support pour la rédaction du programme n'était pas des livres de référence ou Internet, mais mes projets antérieurs, dont j'ai également écrit sur Habré. Depuis Internet, je n'ai pris qu'une seule fonction qui renvoie le jour de la semaine par date. Mais avant de citer le texte du programme, j'ai décidé de partager quelques informations supplémentaires, sur lesquelles je ne voulais initialement pas écrire dans cet article.
L'idée de former une multisession à partir d'enregistrements téléphoniques m'est venue lorsque je travaillais sur une version plus récente d'Adobe Audition 3.0, qui prend en charge l'entrée / sortie audio via ASIO. Lors de l'enregistrement de la multisession, j'ai constaté qu'elle pouvait être enregistrée dans deux formats au choix: le SES classique habituel et le nouveau format XML, qui n'était pas dans les versions précédentes du programme. Après avoir sauvegardé la session au format XML, j'ai immédiatement ouvert ce fichier dans "notepad", où j'ai trouvé une description d'un tas de paramètres liés entre eux dans une structure hiérarchique complexe. Pour faciliter la visualisation de cette hiérarchie, j'ai utilisé le programme WMHelp XmlPad. La figure 17 montre une capture d'écran de ce programme avec un fichier multisession simple d'essai ouvert. Sur la gauche se trouve la hiérarchie des documents. L'élément actif (sélectionné) de la hiérarchie est le paramètre de longueur du premier fichier audio,debout dans la première sous-unité du bloc de description de fichier audio.
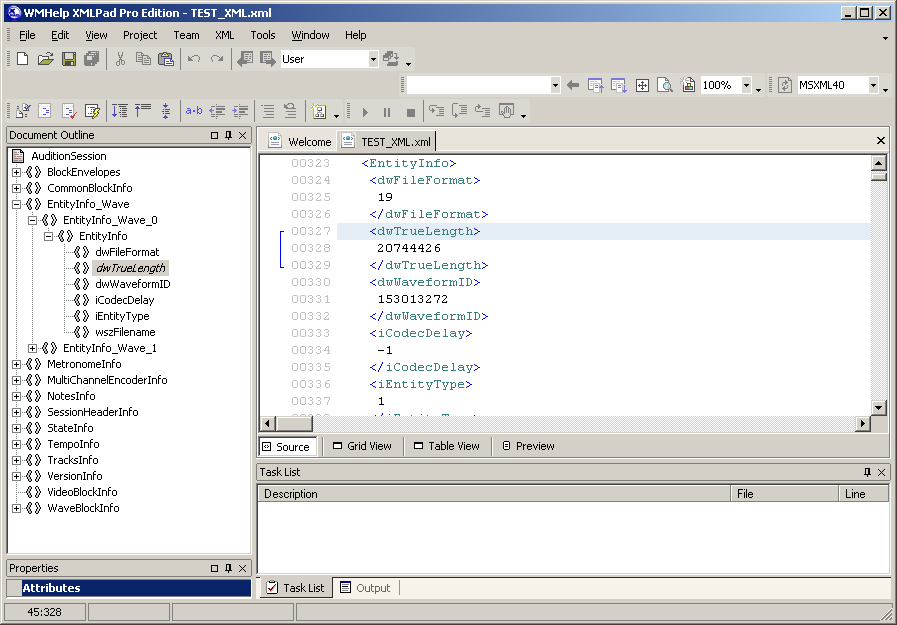
. 17. XML Adobe Audition 3.0.
J'ai décidé d'étudier ce format particulier et, à l'avenir, de générer par programme le texte XML requis, en obtenant la multisession souhaitée en sortie. Il y avait même une idée d'utiliser Excel à cette fin. La difficulté était qu'environ 95% de l'ensemble du fichier XML est occupé par le bloc de description de piste. Il y a un nombre colossal de paramètres, que je ne pourrais pas exclure sans nuire à la multisession. Le fait est que dans cette version d'Adobe Audition, il existe de nombreuses autres fonctions liées aux pistes. Logiquement, ces fonctions ne sont pas nécessaires pour ma simple multisession. Cependant, en excluant les champs correspondants du document XML, la session cesse de vivre. Et je devrais "tirer" cet énorme morceau de texte dans la description de chaque piste pour la session la plus simple. C'est le seul inconvénient lors de la génération d'un fichier XML multisession. Connaissance,les variantes multisession obtenues lors de l'étude du XML textuel ont bien sûr été utiles lors de l'étude des ses binaires. Et même en XML, je n'ai pas pu décrypter certains paramètres. Les champs de chaque paramètre ont un nom abrégé en anglais, mais même ainsi, je n'ai pas toujours compris ce qu'était ce paramètre. L'essentiel est que j'ai pu étudier et déchiffrer les paramètres de base nécessaires, leurs blocs hiérarchiques et leurs champs. Puis j'ai été longtemps tourmenté par la question: comment ouvrir une telle session dans une ancienne version d'Adobe Audition? Les nouvelles versions des programmes ont une interface très sophistiquée (presque 3D), ce qui est très peu pratique pour visualiser une multisession comme des diagrammes. Et à cause de ce "trois-te" dans Adobe Audition 3.0 avec une fenêtre entièrement agrandie sur l'écran FullHD, un maximum (à l'échelle minimale) de 28 pistes convient. Et dans Adobe Audition 1.5, 37 conviendraient (Fig.18, échelle 1: 2). Au total, 31 pistes doivent être affichées à l'écran.
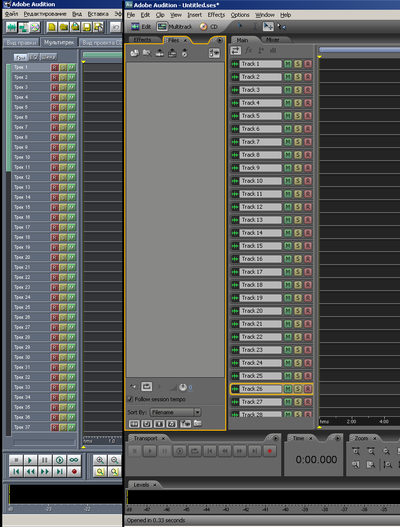
. 18. Adobe Audition .
Mais surtout, j'ai terminé la qualité sonore lors de la lecture d'une multisession avec une fréquence de 8000 Hz dans la nouvelle version du programme. Le son n'est pas très bon, la distorsion harmonique est présente. Cela est dû au fait que le son est émis à une fréquence d'échantillonnage différente (48 kHz), et ASIO ne peut pas faire autrement. La situation ne change pas lorsque vous sélectionnez un autre périphérique de sortie «Audition 3.0 Windows Sound» dans les paramètres. La nouvelle version du programme ne prend pas en charge les périphériques de sortie classiques "DirectSound" (j'appelle la version 3.0 nouvelle). La figure 19 montre le spectre audio lors de la lecture audio (ou session) 8 kHz dans Adobe Audition 3.0 avec une distorsion harmonique à spectre inversé. Ces fréquences sont entourées de vert, ce qui devrait sonner idéalement (et rien d'autre). Et les fréquences sont entourées de rouge,qui sont une distorsion supplémentaire. Cet effet est probablement dû à l'absence de filtrage après la procédure de suréchantillonnage. C'est après cela que j'ai décidé de me lancer dans l'étude du format binaire SES du programme Adobe Audition 1.5 plus simple et plus agréable. J'espérais qu'après avoir appris le format XML "humain" à partir d'une version plus récente du programme, il ne me serait pas difficile de le comprendre, compte tenu de mon expérience avec les fichiers binaires. Et c'est arrivé: j'ai assez rapidement "promu" le format SES. Et l'essentiel est que la rétrocompatibilité, pour l'avenir, fonctionne bien: une session formée pour la version 1.5 est ouverte avec succès dans la version 3.0. Ci-dessus, j'ai souligné les inconvénients d'Adobe Audition 3.0 liés à la qualité sonore et à l'interface graphique. Mais cette version du programme présente des avantages dans la navigation multisession. Par exemple,il est possible d'écouter de manière opérationnelle un clip audio dans une multisession en cliquant dessus avec une souris puis en le déplaçant vers la droite.
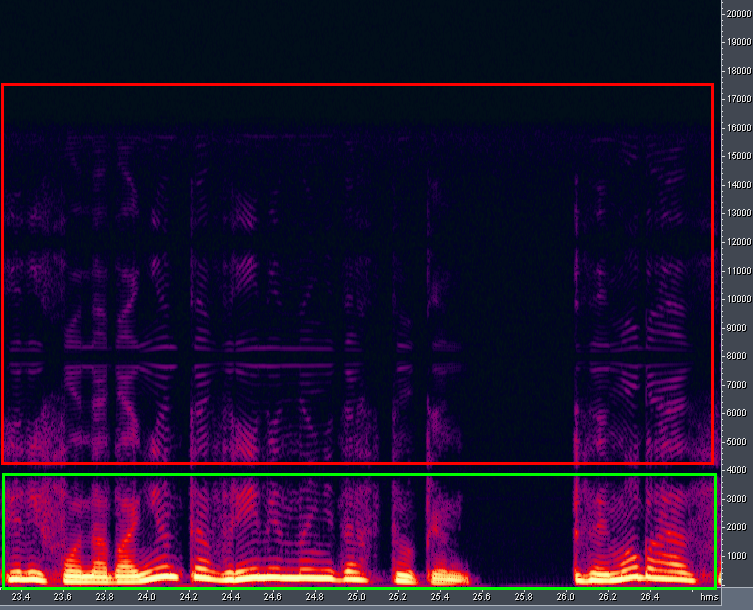
Figure: 19. Distorsion harmonique pendant la lecture.
Maintenant, je vais donner le texte du programme sous le spoiler. Le programme, bien sûr, n'a pas d'interface graphique, car il n'est pas nécessaire pour cette tâche. Le texte du programme est fourni avec des commentaires détaillés, aucune explication supplémentaire n'est donc nécessaire. Le programme est lancé sur la ligne de commande et en une seconde traite une liste de quatre cents fichiers, formant un fichier multisession. Dans le programme, il y a quatre variables paramétriques qui, si vous le souhaitez, vous permettent de ne pas générer de marqueurs de repère, de ne pas mettre un "R" sur les pistes le week-end, de ne pas définir la propriété "Fix in time" sur les clips, et de sélectionner le critère de coloration des clips (par type d'appel ou par numéro de téléphone) ... Ces trois variables devraient être exclues du texte du programme et "ressorties", c'est-à-dire dans un fichier séparé contenant les paramètres du programme.
Code source du programme C
/********************************************************************
"RMC" ,
wav .
, .
yyyy-mn,
. .
(.. -),
.
, ,
"RMC" "I:".
*********************************************************************/
#include <windows.h>
#include <stdio.h>
#include <string.h>
DWORD wr; // , ;
DWORD ww; // , ;
DWORD wi; // , ;
// ( );
int Date( int D, int M, int Y ){
int a, y, m, R;
a = ( 14 - M ) / 12;
y = Y - a;
m = M + 12 * a - 2;
R = 6999 + ( D + y + y / 4 - y / 100 + y / 400 + (31 * m) / 12 );
return R % 7;
}
// ;
HANDLE openInputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_READ, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
HANDLE openOutputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_WRITE, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
void filepos(HANDLE f, __int64 p){
LONG HPos;
LONG LPos;
HPos = p>>32;
LPos = p;
SetFilePointer (f, LPos, &HPos, FILE_BEGIN);
}
// 32- ;
void write32(HANDLE f, signed long int a){
WriteFile(f, &a, 4, &ww, NULL);
}
// ;
void fill(HANDLE f, signed long int a, unsigned char c){
unsigned char i;
for(i=0;i<c;i++){
write32(f,a);
}
}
int main(){
HANDLE out; // Adobe Audition;
HANDLE stat; // "stat" (+ );
HANDLE cues; // "cues";
HANDLE lf; // "LISTFILE";
HANDLE blk; // "bk20";
char* week[7]={"", "", "", "", "", "", ""}; // -;
unsigned char dm[]={31,29,31,30,31,30,31,31,30,31,30,31}; // ;
unsigned char p_cues=1; //: (cues);
unsigned char p_R=1; //: "R" ( ) ;
unsigned char p_lock=1; //: ;
unsigned char p_color=2; // ;
unsigned char flg; // , . ;
unsigned long int lfsize=0; // "LISTFILE";
unsigned long int blksize=0; // "bk20";
unsigned long int smp; // ;
unsigned long int offset; // ;
unsigned int cfile=0; // ;
unsigned int cblk=0; // ;
char name[100]; // ( ...);
char fullname[100]; // ;
char infld[8]; // ;
char number[11]; // . ;
unsigned char len; // ;
printf("Input yyyy-dd name of folder:\n"); // ;
scanf("%s",infld); // ;
WIN32_FIND_DATA fld; // ;
HANDLE hf; // ( , );
char buf1[48],buf2[556]; // "stat" "cues";
char str[16]; // ;
unsigned long int outpos=0; // ;
unsigned char byte; // "LISTFILE" "bk20";
unsigned char i; // ;
unsigned char mn,d,dw,h,m,s; // -;
unsigned char cdm; // ;
int yy; // ;
yy=2000+(infld[2]-48)*10+(infld[3]-48); // ;
mn=(infld[5]-48)*10+(infld[6]-48); // ;
sprintf(name,"I:\\RMC\\%s.ses",infld); // ( );
out=openOutputFile(name); // ;
WriteFile(out, "COOLNESS", 8, &wi, NULL); // : ;
write32(out,0); // ( , );
WriteFile(out, "hdr ", 4, &wi, NULL); //, : ;
write32(out,936); // , 936;
write32(out,8000); // ;
write32(out,24*3600*8000); // (. 24 );
write32(out,0); // ( );
write32(out,0x00010020);
write32(out,0);
write32(out,0x3ff00000);
write32(out,0);
write32(out,0x3ff00000);
filepos(out,328); // ;
write32(out,0x20);
WriteFile(out, "", 6, &wi, NULL); // ;
filepos(out,376); // ;
write32(out,0x3ff00000);
filepos(out,892); // ;
write32(out,0x0430041c);
write32(out,0x04420441);
write32(out,0x04400435);
filepos(out,956); // ;
stat=openInputFile("stat_31_full.BLK"); // ,
ReadFile(stat, &buf1, 48, &wr, NULL); // ;
WriteFile(out, buf1, 48, &wi, NULL);
CloseHandle(stat);
if(mn==2){ // ,
if(!(yy%4)){ // ,
cdm=29; // 29 ,
}else{
cdm=28; // - 28;
}
}else{ // ,
cdm=dm[mn-1]; // ;
}
WriteFile(out, "trks", 4, &wi, NULL); // ;
write32(out,4+cdm*152); // ;
write32(out,cdm); // ;
outpos=1016; // ;
for(i=0;i<cdm;i++){ //
dw=Date(i+1,mn,yy); // ;
write32(out,0); // ses, ;
write32(out,0x3ff00000);
write32(out,0); // 8- double;
write32(out,0x3ff00000);
if((dw%7==5||dw%7==6)&&p_R){ // - , "R",
write32(out,4); // "R",
}else{
write32(out,0); // - ;
}
sprintf(str,"%02d.%02d.%i %s",i+1,mn,yy,week[dw]); // , ;
WriteFile(out, str, strlen(str), &wi, NULL);
filepos(out,1072+152*i); // (i+1)- ;
write32(out,1); // , ;
write32(out,1);
write32(out,4);
write32(out,0);
write32(out,0);
write32(out,0x40590000);
write32(out,0);
write32(out,0);
write32(out,0xffffff9d);
write32(out,0xffffff9d);
write32(out,i+1); // , ;
fill(out,0,11);
write32(out,4);
write32(out,0);
outpos+=152; // ;
}
if(p_cues){ // , "cues";
WriteFile(out, "cues", 4, &wi, NULL); // ,
write32(out,556); // - ;
cues=openInputFile("cues_24h.BLK"); // , ;
ReadFile(cues, &buf2, 556, &wr, NULL); //( , "stat");
WriteFile(out, buf2, 556, &wi, NULL);
CloseHandle(cues);
outpos+=564;
}
DeleteFile("LISTFILE"); // ( )
DeleteFile("bk20"); // "LISTFILE" "bk20",
lf=openOutputFile("LISTFILE"); // ()
blk=openOutputFile("bk20"); // ;
WriteFile(lf, "LISTFILE", 8, &wi, NULL); // ;
WriteFile(blk, "bk20", 4, &wi, NULL);
write32(lf,0);
write32(blk,0);
write32(blk,0);
write32(blk,0x48); // , ;
sprintf(name,"I:\\RMC\\%s\\*.wav",infld); // wav ;
hf=FindFirstFile(name,&fld); // ;
do{ // ;
len=strlen(fld.cFileName); // ;
for(i=10;i>=1;i--){ // 10 ;
number[10-i]=fld.cFileName[len-i-4]; // ;
}
number[10]=0; // , ;
cfile+=1; // ;
sprintf(fullname,"I:\\RMC\\%s\\%s",infld,fld.cFileName); // ;
d=(fld.cFileName[22]-48)*10+(fld.cFileName[23]-48); // () ;
h=(fld.cFileName[25]-48)*10+(fld.cFileName[26]-48); // ;
m=(fld.cFileName[27]-48)*10+(fld.cFileName[28]-48); // ;
s=(fld.cFileName[29]-48)*10+(fld.cFileName[30]-48); // ;
offset=(h*3600+m*60+s)*8000; // ;
smp=(fld.nFileSizeLow-44)/4; // ( );
WriteFile(lf, "wav ", 4, &wi, NULL); // ;
write32(lf,17+strlen(fullname)); // ( );
write32(lf,1000+cfile); // ( , 1000 );
write32(lf,0x14); // ( );
WriteFile(lf, fullname, strlen(fullname), &wi, NULL); // ( );
WriteFile(lf, "\0", 1, &wi, NULL); // ;
write32(lf,0xffffffff); //;
write32(lf,smp); // ;
lfsize+=(25+strlen(fullname)); // "LISTFILE";
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile); // ();
write32(blk,0); // ;
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,offset); // ;
if(((24*3600*8000)-offset)>smp){ // ( ) ,
write32(blk,smp); // ,
}else{
write32(blk,(24*3600*8000)-offset); // ;
}
write32(blk,0); // ;
if(p_lock){ // ,
write32(blk,0x0008000a); // (3 32 ),
}else{
write32(blk,0x00080008); // (2 32 );
} // - " ";
write32(blk,d); // ( );
fill(blk,0,4); // ;
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ;
case 'I': // "I" ( ),
write32(blk,0); // ;
break;
case 'O': // "O" ( ),
write32(blk,102); // ( );
break;
default: // - ,
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0; // ;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // - ();
if(!flg){ // ( ),
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
if(((24*3600*8000)-offset)<=smp){ // ( ) ( ),
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0); // ,
write32(blk,smp-((24*3600*8000)-offset)); // ,
write32(blk,(24*3600*8000)-offset); // , ;
if(p_lock){
write32(blk,0x0008000a);
}else{
write32(blk,0x00080008);
}
write32(blk,d+1); // () ();
fill(blk,0,4);
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ( );
case 'I': // ,
write32(blk,0); // ;
break;
case 'O': // ,
write32(blk,102); // , ;
break;
default: // - ( ),
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // ( );
if(!flg){ // ,
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
}
}while(FindNextFile(hf,&fld)); // wav ;
filepos(lf,8);
write32(lf,lfsize); // "LISTFILE", ;
filepos(blk,4);
blksize=8+72*cblk; // "bk20", ;
write32(blk,blksize); // "bk20";
write32(blk,cblk); // ;
blksize+=8; // "bk20", . ;
lfsize+=12; // "LISTFILE", . ;
CloseHandle(lf); // . ;
CloseHandle(blk); // . ;
lf=openInputFile("LISTFILE"); // . ;
do{ // , ( );
ReadFile(lf, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(lf); // . ;
blk=openInputFile("bk20"); // . ;
do{ // , ( );
ReadFile(blk, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(blk); // . ;
outpos=outpos+blksize+lfsize; // ;
filepos(out,8);
write32(out,outpos-12); // ;
filepos(out,28);
write32(out,cblk); // ;
CloseHandle(out); // ! ;
printf("c_files: %i\nc_block: %i\n",cfile,cblk); // ( );
system("PAUSE");
return 0;
}
Vous pouvez maintenant afficher des captures d'écran des résultats. Il y en aura plusieurs: à différentes échelles de visualisation, dans différentes versions du programme et avec des critères de coloration différents. Le catalogue "2020-05" a été traité, c'est-à-dire les enregistrements du mois de mai de l'année en cours. Au total, 446 enregistrements ont été traités. Le nombre de blocs est le même, car il n'y a pas d'enregistrements avec la transition vers un nouveau jour.
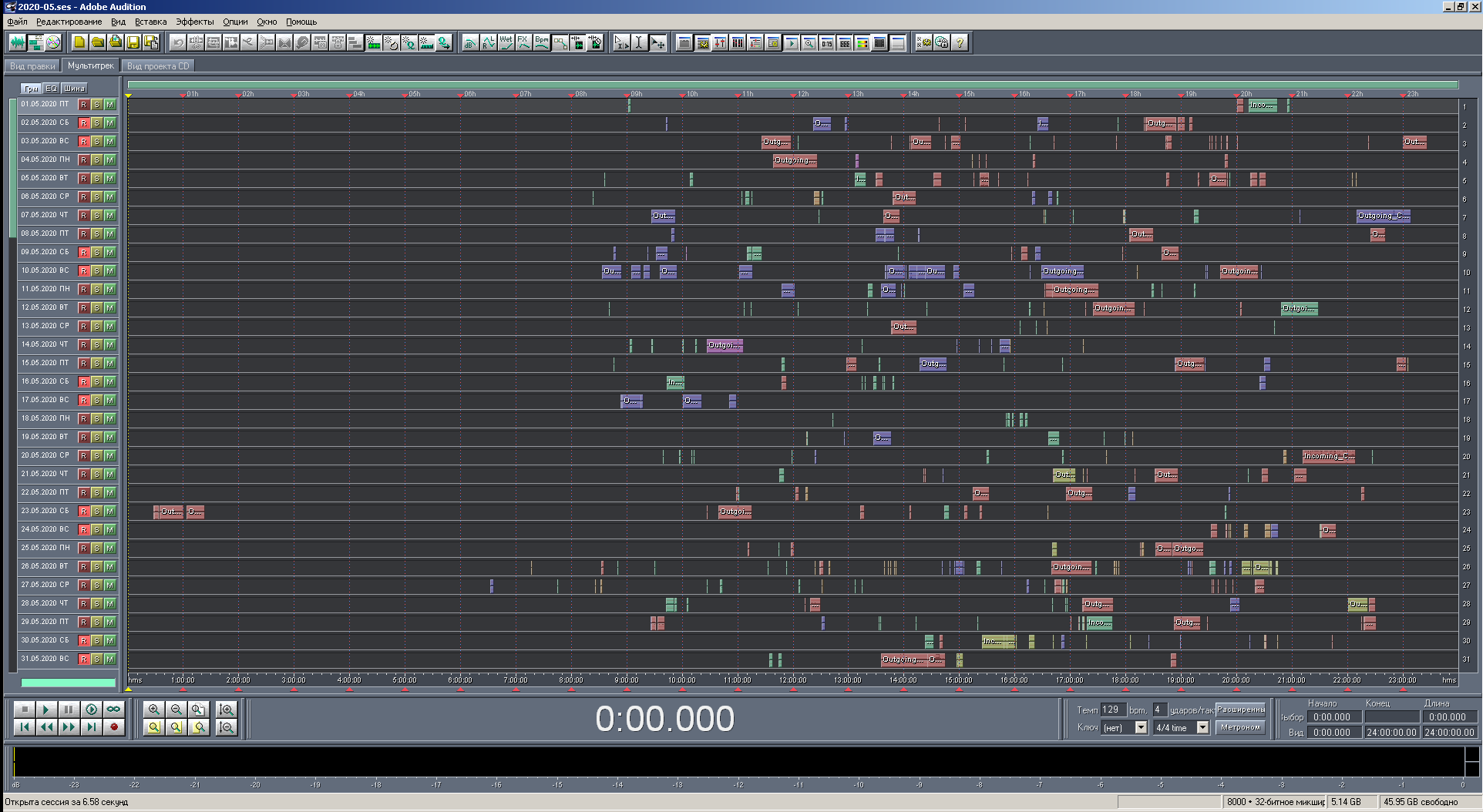
Figure: 20. Vue de la multisession à grande échelle avec coloration par téléphone. Nombres.
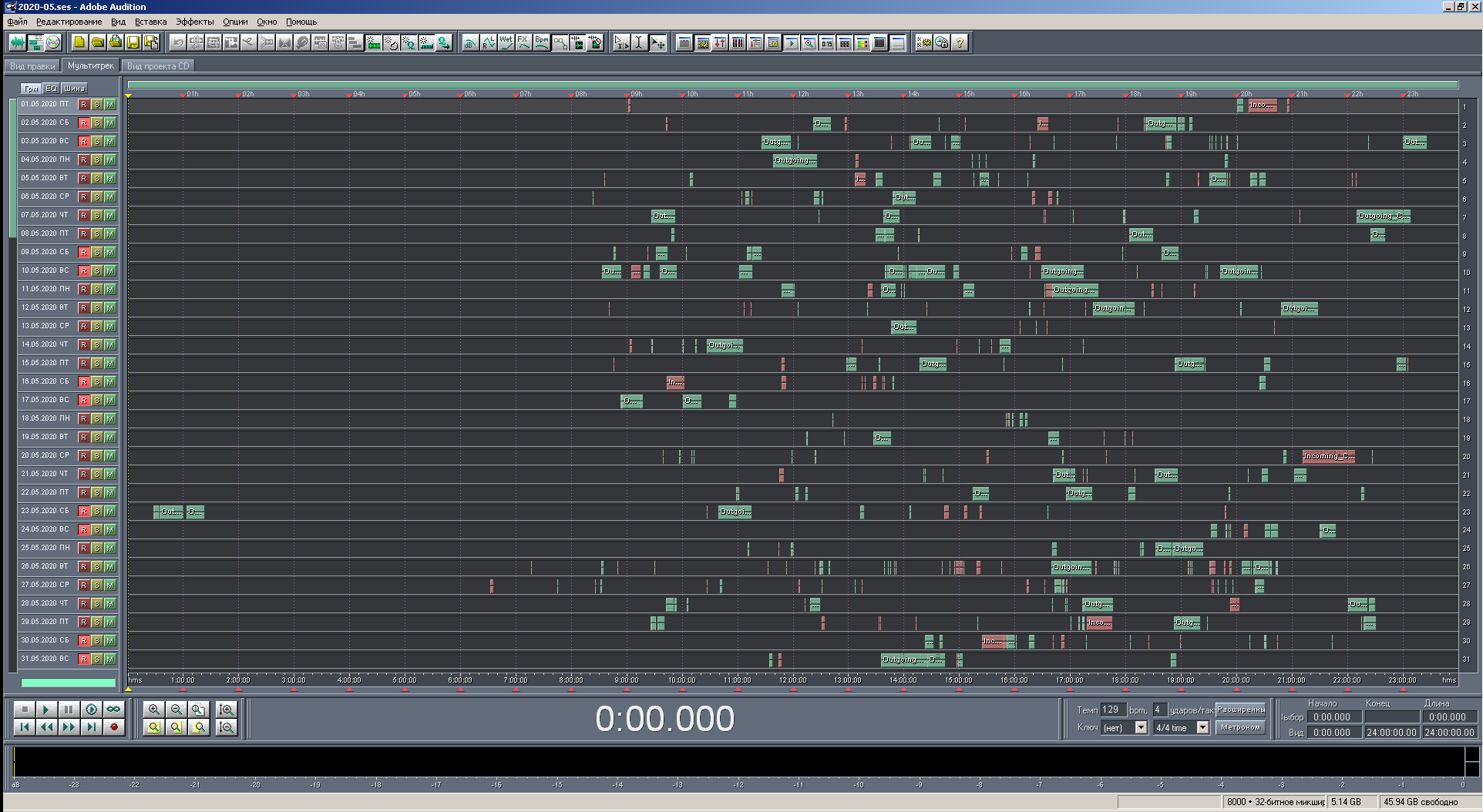
Figure: 21. Vue de la multisession en pleine échelle avec coloration par type d'appel.
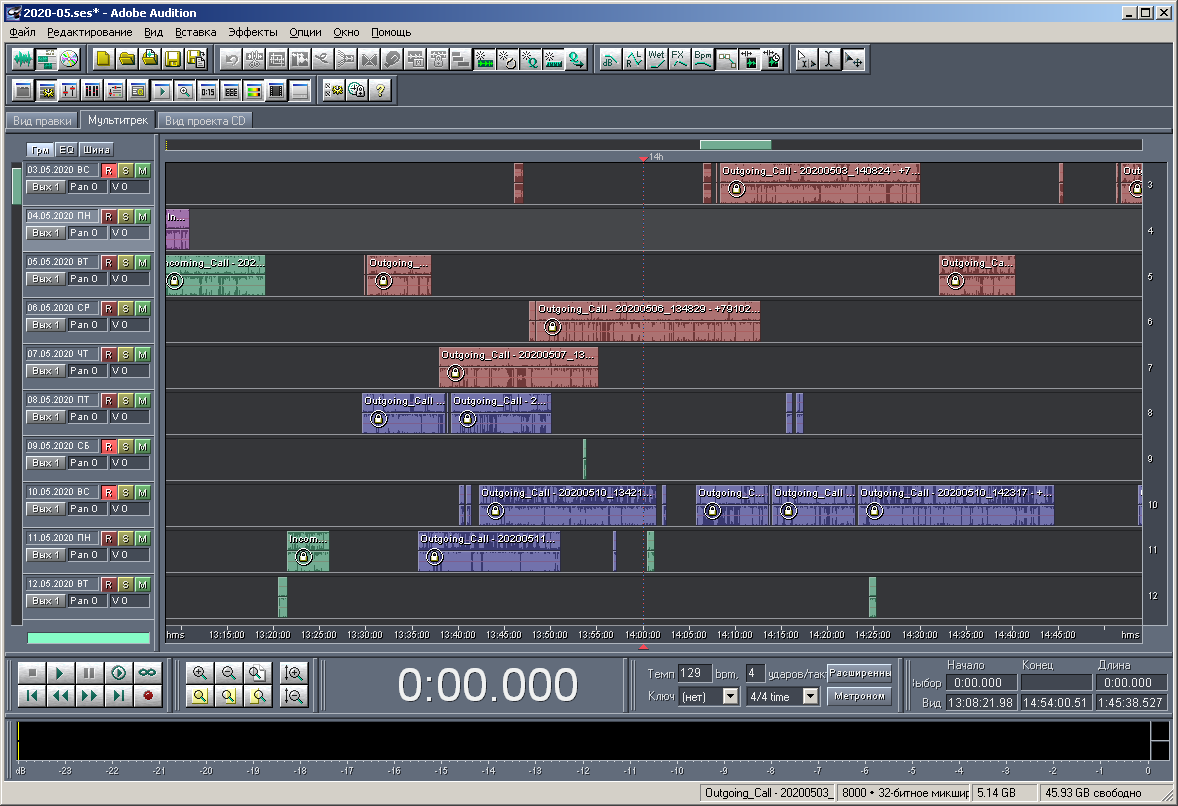
Figure: 22. Type de multisession à moyenne échelle.
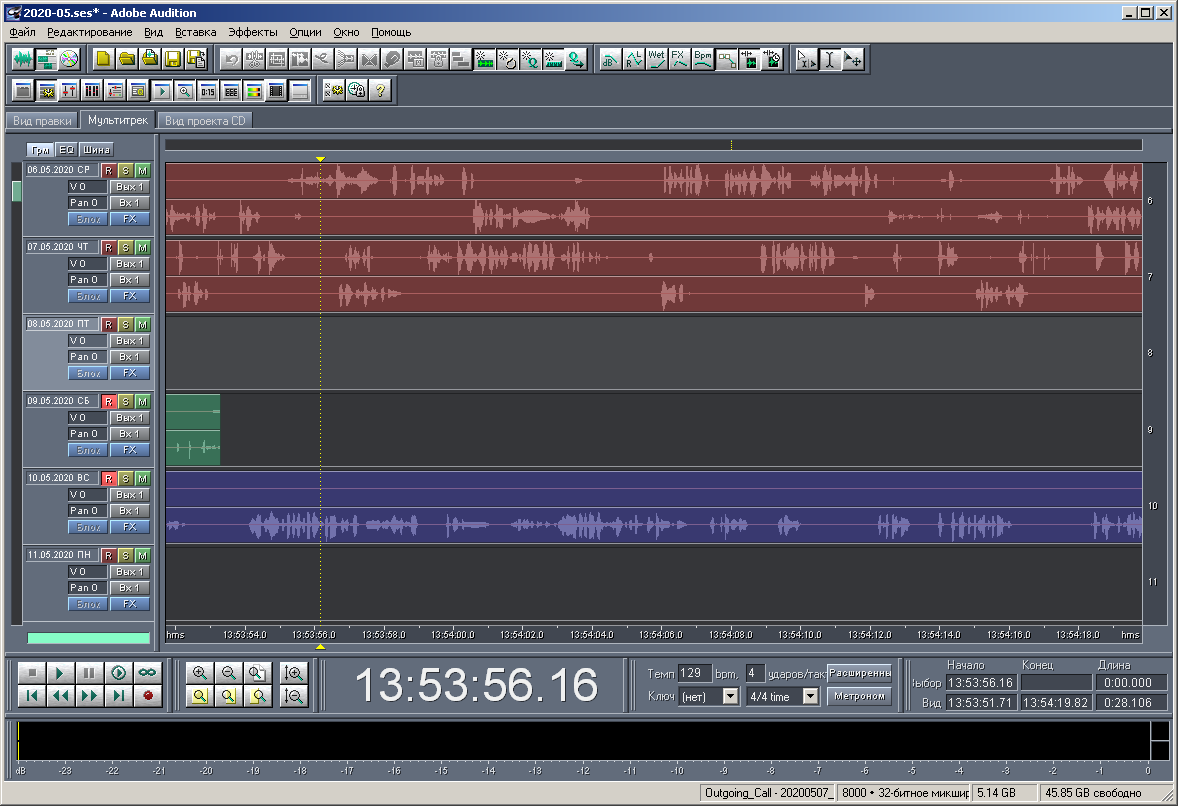
Figure: 23. Vue d'une multisession à grande échelle.
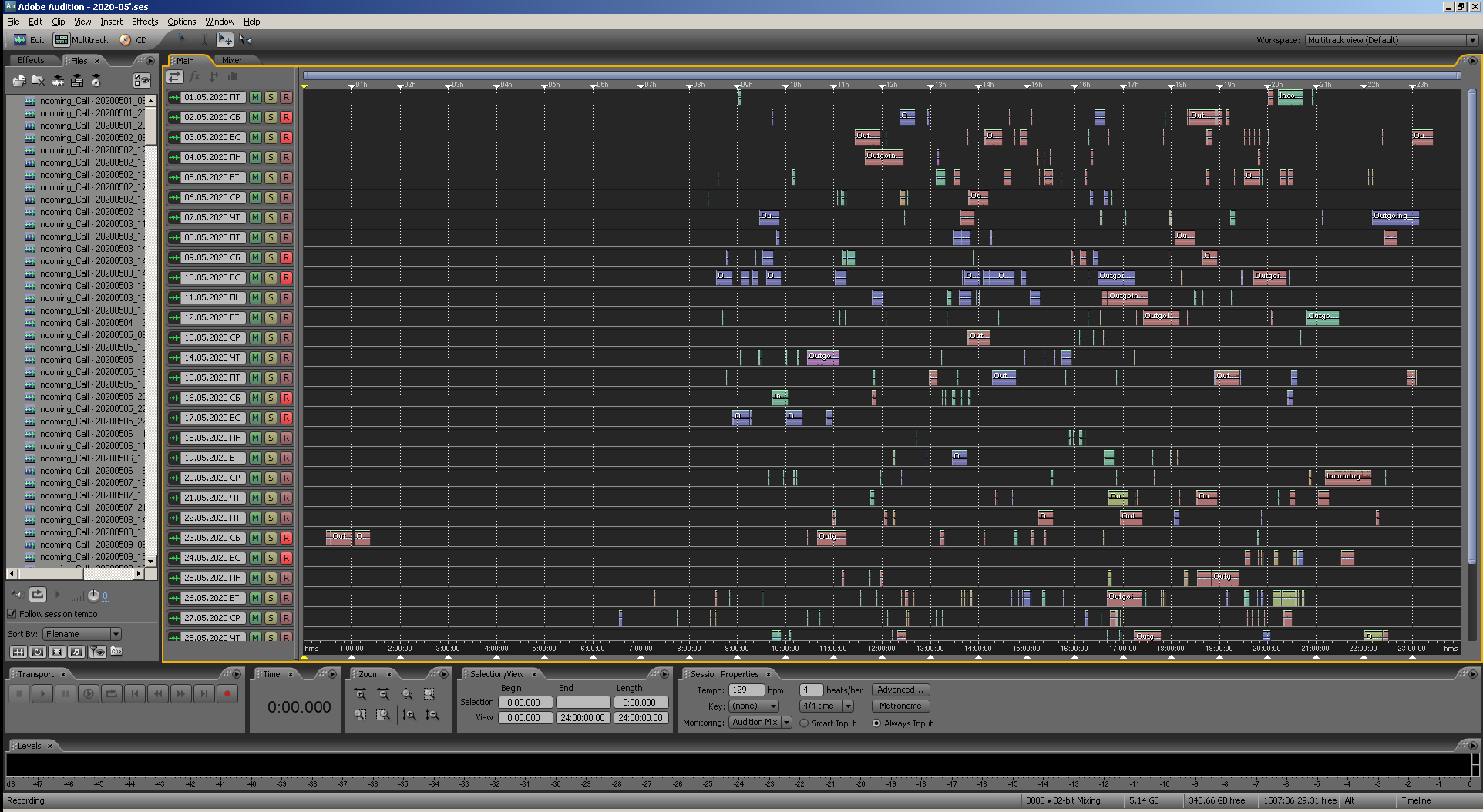
Figure: 24. Vue de la même multisession dans Adobe Audition 3.0.