Lors de mon discours à Ya. Subbotnik Pro, je me suis souvenu de ce que nous avions terminé et de la manière dont nous avions terminé l'assemblage et l'architecture du "projet moderne standard" et des résultats obtenus.
- Depuis un an et demi, je travaille dans l'équipe d'architecture de Serp. Nous y développons le runtime et l'assemblage du nouveau code dans React et TypeScript.
Parlons de notre douleur commune que ce discours abordera. Lorsque vous souhaitez créer un petit projet dans React, il vous suffit d'utiliser un ensemble d'outils standard appelé trois lettres - CRA. Cela inclut des scripts de construction, des scripts pour exécuter des tests, la configuration d'un environnement de développement, et tout a déjà été fait pour la production. Tout se fait très simplement via des scripts NPM, et tout le monde le sait probablement qui a de l'expérience avec React.
Mais supposons que le projet devienne volumineux, qu'il ait beaucoup de code, beaucoup de développeurs, des fonctionnalités de production apparaissent, telles que des traductions, dont Create React App ne sait rien. Ou vous avez une sorte de pipeline CI / CD complexe. Ensuite, les pensées commencent à faire un éjection pour utiliser Create React App comme base et la personnaliser pour votre propre projet. Mais ce qui attend là-bas, derrière cet éjection, n'est absolument pas clair. Parce que lorsque vous faites une éjection, cela dit que c'est une opération très dangereuse, il ne sera pas possible de la renvoyer et ainsi de suite, très effrayant. Ceux qui ont appuyé sur eject savent que de nombreuses configurations sont lancées, ce que vous devez comprendre. En général, il y a beaucoup de risques, et on ne sait pas quoi faire.
Je vais vous dire comment c'était avec nous. Tout d'abord, à propos de notre projet. Notre projet frontal est le Serp, les pages de résultats des moteurs de recherche, les pages de résultats de recherche Yandex que tout le monde a vues. Depuis 2018, nous ne déplaçons pas React et TypeScript. Sur Serpa, environ 12 mégaoctets de code ont déjà été écrits l'année dernière. Il existe quelques styles et beaucoup de code TS et SCSS. Combien au début, en 2018, il y en avait, je n'ai pas écrit, il y en a très peu, il y a eu un saut très net.
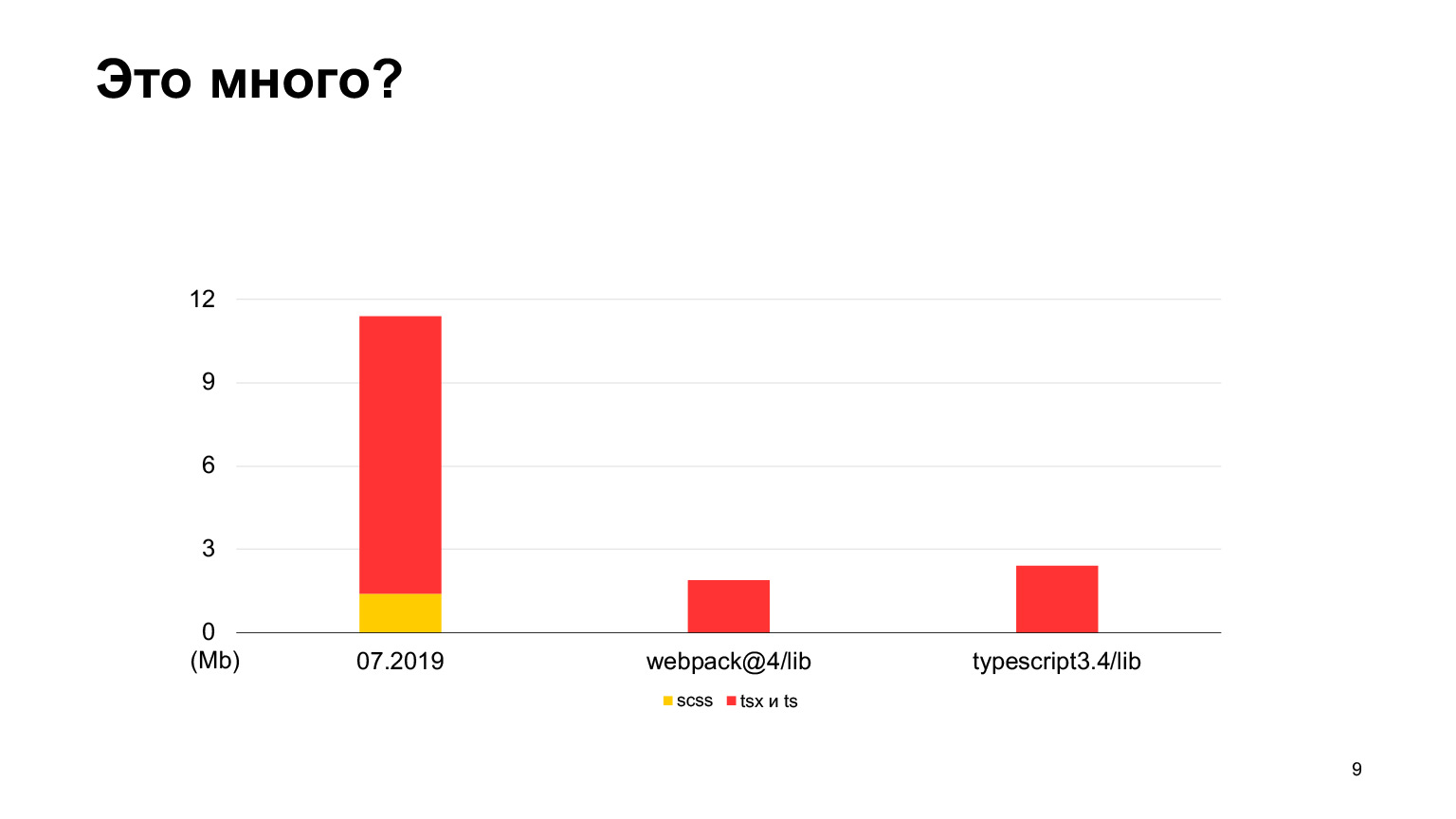
Voyons si c'est beaucoup de code ou non. Par rapport au code source de webpack-4, il y a beaucoup moins de code dans webpack-4. Même le référentiel TypeScript a moins de code.
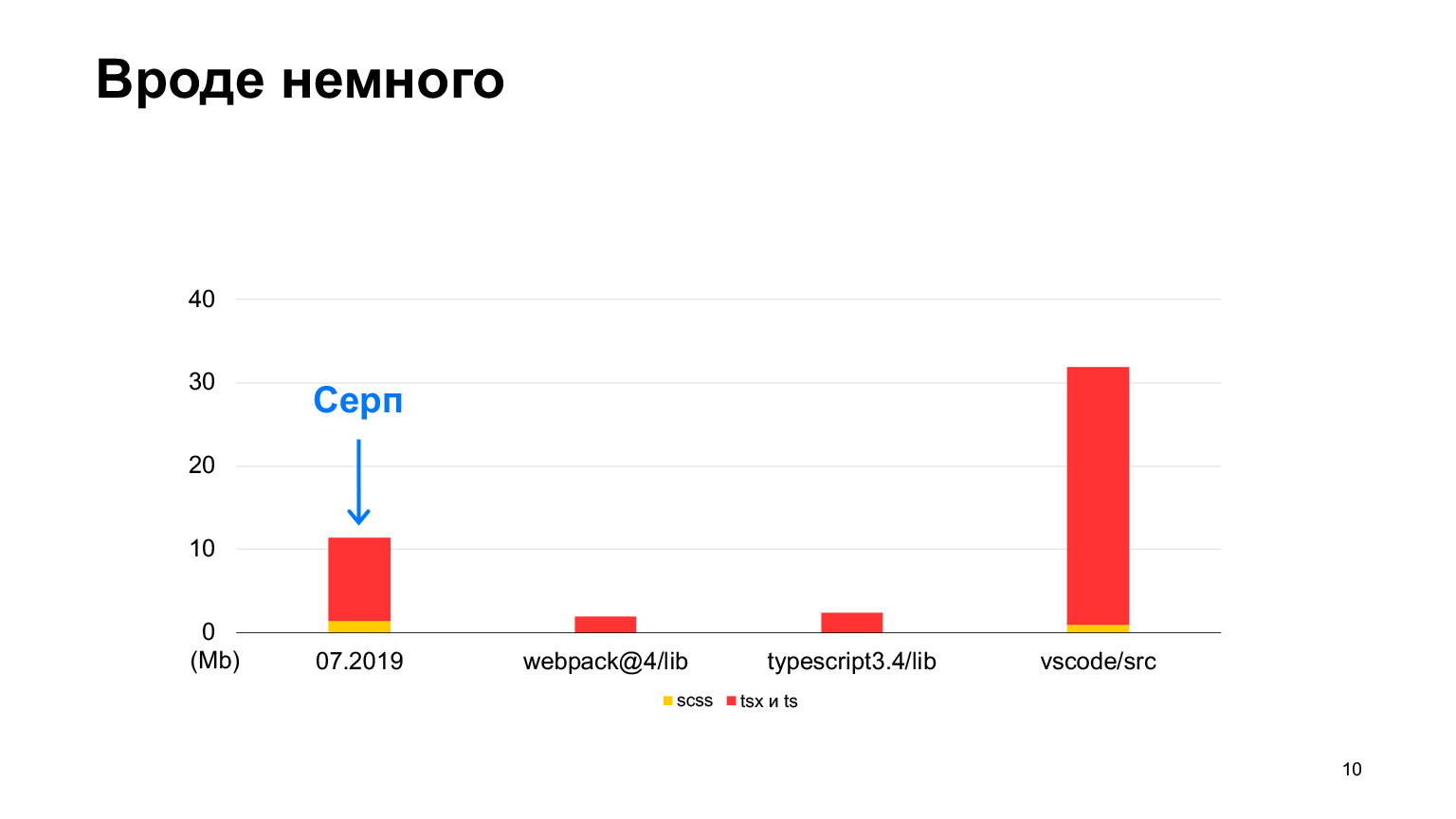
Mais vs-code contient plus de code, un bon projet avec jusqu'à 30 mégaoctets de code TypeScript. Oui, il est également écrit en TypeScript, et la faucille semble être plus petite. En 2018, nous avons commencé, en 2019, il y avait 12 mégaoctets, et 70 de nos développeurs ont travaillé, faisant 100 pull requests par semaine. En un an, ils ont triplé cette taille et ont reçu exactement 30 mégaoctets. J'ai pris des mesures ce mois-ci, au total nous avons 30 mégaoctets de code maintenant, et c'est déjà plus que dans vs-code.
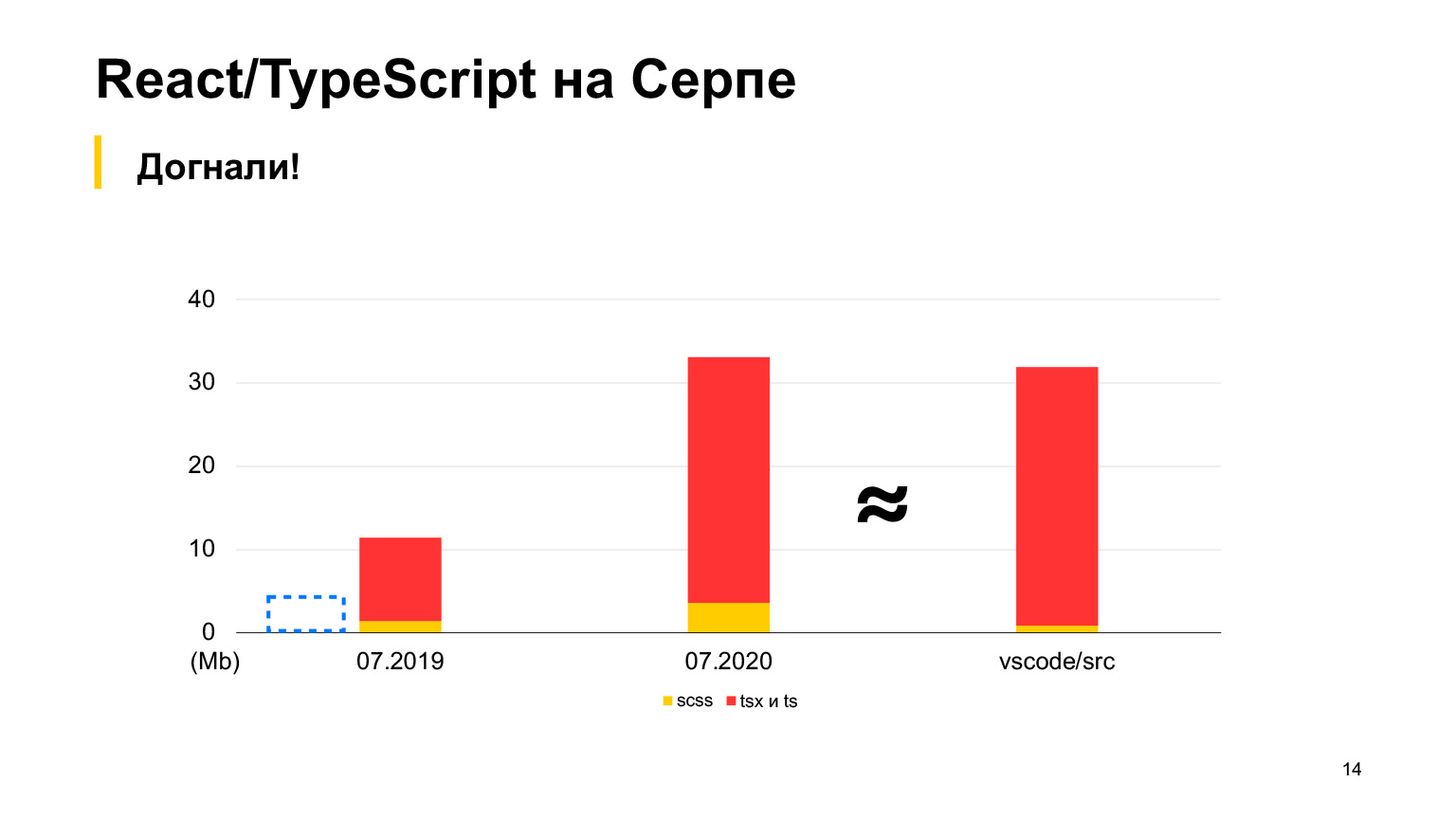
À peu près égal, mais légèrement plus. C'est l'ordre de notre projet.
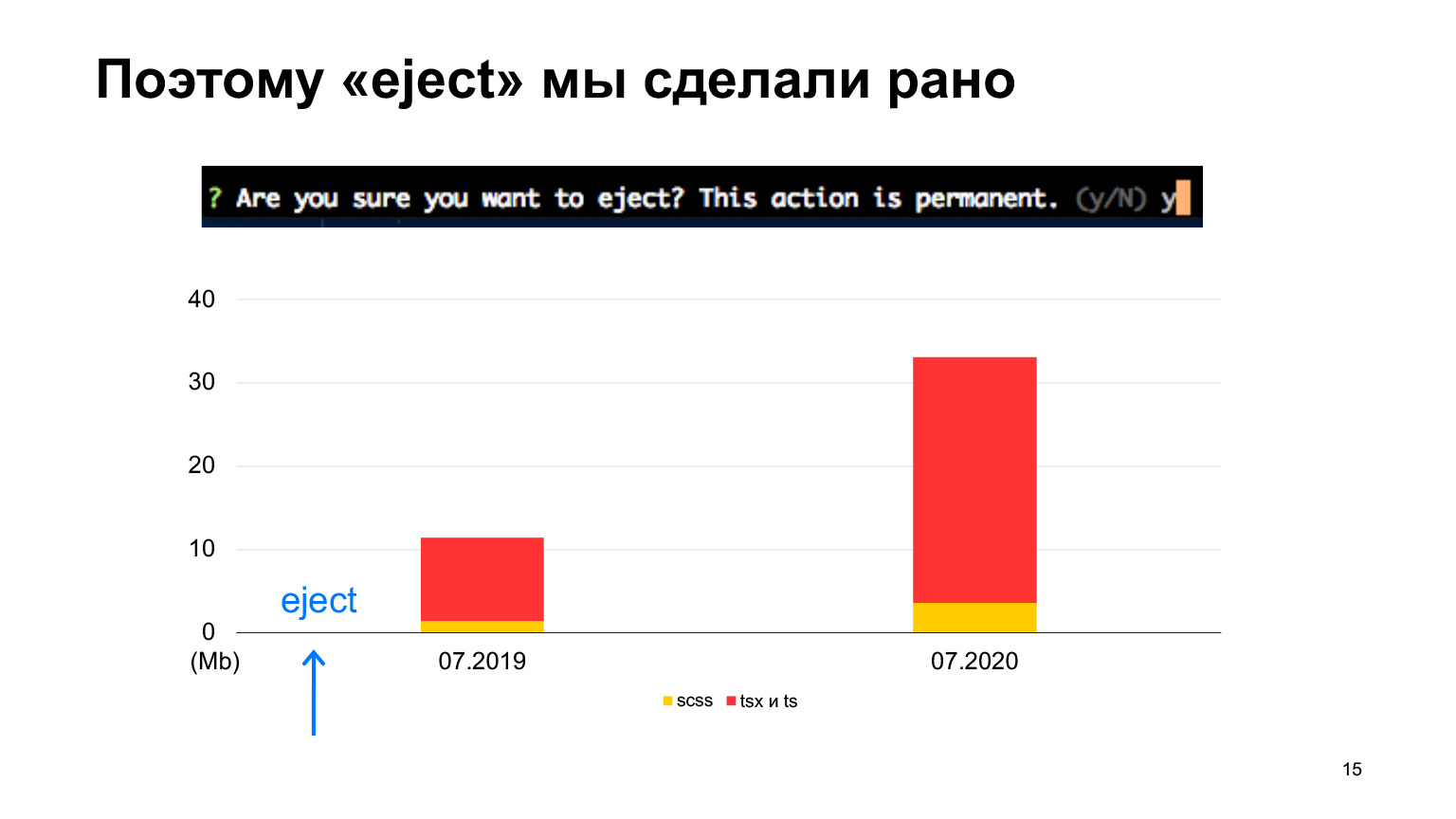
Et nous l'avons éjecté au tout début, car nous savions immédiatement que nous aurions beaucoup de code et, très probablement, les configurations initiales de Create React App ne fonctionneraient pas pour nous. Mais nous avons commencé de la même manière, avec Create React App.
Voilà donc de quoi parlera l'histoire. Nous voulons partager notre expérience, vous dire ce que nous avons dû faire avec l'application Create React pour que Yandex Serp fonctionne correctement dessus. Autrement dit, comment nous avons obtenu un chargement et une initialisation rapides dans le navigateur, et comment nous avons essayé de ne pas ralentir la construction, quels paramètres, plugins et autres éléments nous avons utilisés pour cela. Et naturellement, les résultats que nous avons obtenus viendront à la fin.

Comment avons-nous raisonné? L'idée originale était que notre Sickle est une page qui doit être rendue très rapidement, car, fondamentalement, il existe des résultats de texte très simples, nous avons donc besoin de modèles côté serveur, car c'est le seul moyen d'obtenir un rendu rapide. Autrement dit, avant même que quelque chose ne commence à être initialisé sur le client, nous devons dessiner quelque chose.
Dans le même temps, je voulais faire la taille minimale de la statique, afin de ne rien charger de superflu et l'initialisation était également rapide. Autrement dit, nous voulons que le premier rendu soit rapide et l'initialisation rapide.

Que nous offre l'application Create React? Malheureusement, il ne nous offre rien sur le rendu du serveur.
Il indique directement que le rendu du serveur n'est pas pris en charge dans Create React App. De plus, Create React App n'a qu'une seule entrée pour l'ensemble de l'application. Autrement dit, par défaut, un grand ensemble est collecté pour toute votre grande variété de pages. C’est beaucoup. Il est clair que sur 30 mégaoctets, environ la moitié sont des types TS, mais encore beaucoup de code ira directement au navigateur.
Dans le même temps, Create React App a de bons paramètres, par exemple, le runtime webpack y va dans un morceau séparé. Il est chargé séparément, peut être mis en cache car il ne change pas normalement.
De plus, les modules de node_modules sont également collectés dans des blocs séparés. Ils changent également rarement et sont donc également mis en cache par le navigateur, ce qui est génial, il doit être enregistré. Mais en même temps, il n'y a rien sur les traductions dans Create React App.
Préparons notre liste de ce à quoi devrait ressembler dans notre cas la liste des capacités de notre plate-forme. Tout d'abord, nous voulons que le rendu nord, comme je l'ai dit, fasse un rendu rapide. De plus, nous aimerions avoir un fichier d'entrée distinct pour chaque résultat de recherche.

Si, par exemple, Serpa a une calculatrice, alors nous aimerions que le bundle avec la calculatrice soit livré, et le bundle avec le traducteur n'a pas besoin d'être livré rapidement. Si tout cela est rassemblé dans un gros paquet, tout ira toujours, même si la moitié de ces choses ne concernent pas un problème spécifique.
De plus, je voudrais fournir des modules communs en morceaux séparés afin de ne pas charger ce qui a déjà été chargé.
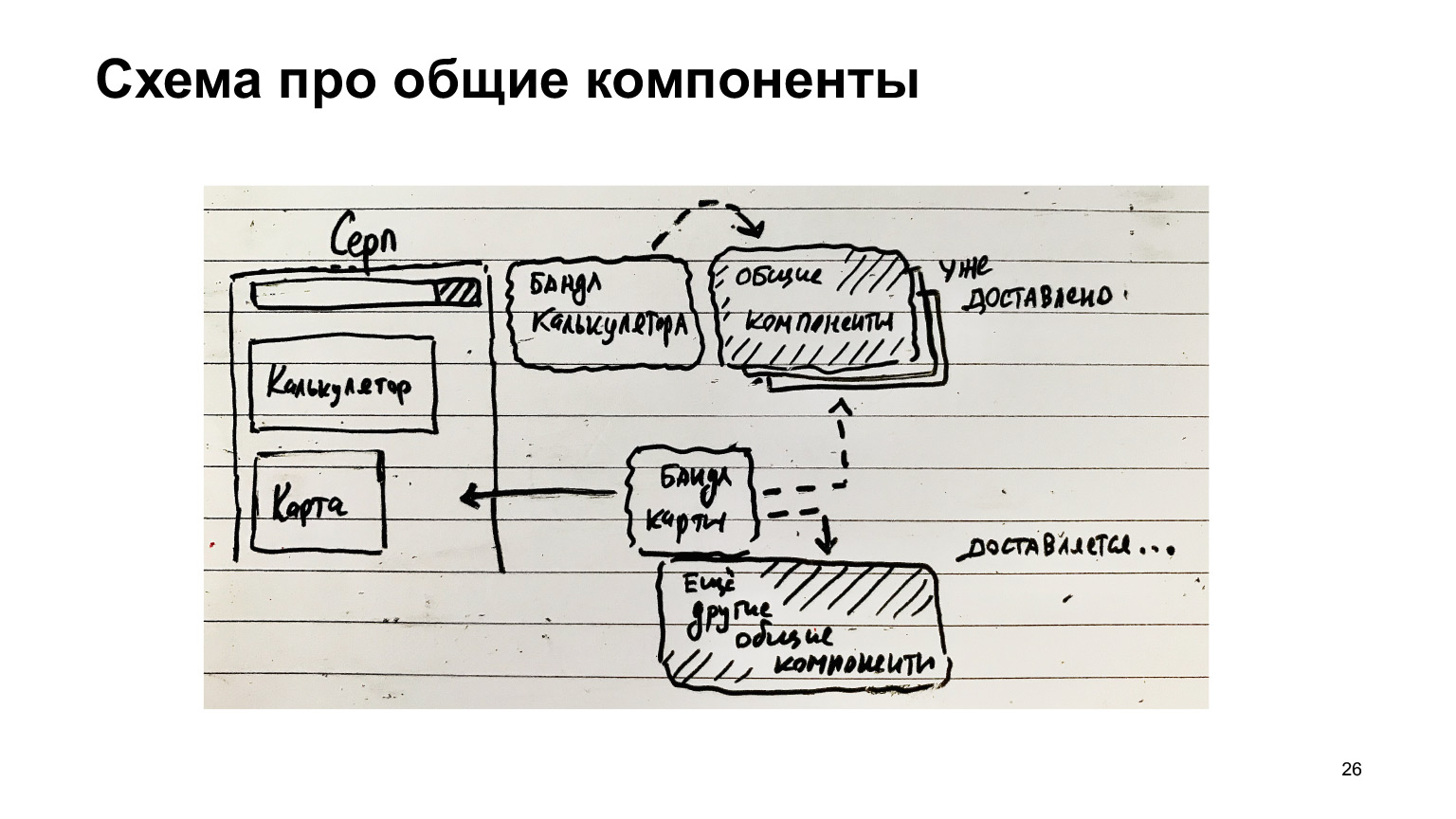
Voici un autre exemple avec la faucille. Il a une calculatrice, il y a un ensemble de calculatrices. Il existe des composants communs. Ils ont été livrés au client. Puis une autre caractéristique est apparue - une carte. J'ai piloté un ensemble de cartes et piloté d'autres composants communs, moins ceux qui ont déjà été livrés.
Si les composants communs sont collectés séparément, alors il y a une excellente opportunité d'optimisation et seul ce qui est nécessaire est livré, seulement diff. Et les modules les plus populaires qui sont toujours sur la page, par exemple, le runtime webpack, qui est toujours nécessaire à toute cette infrastructure, il doit toujours être chargé.
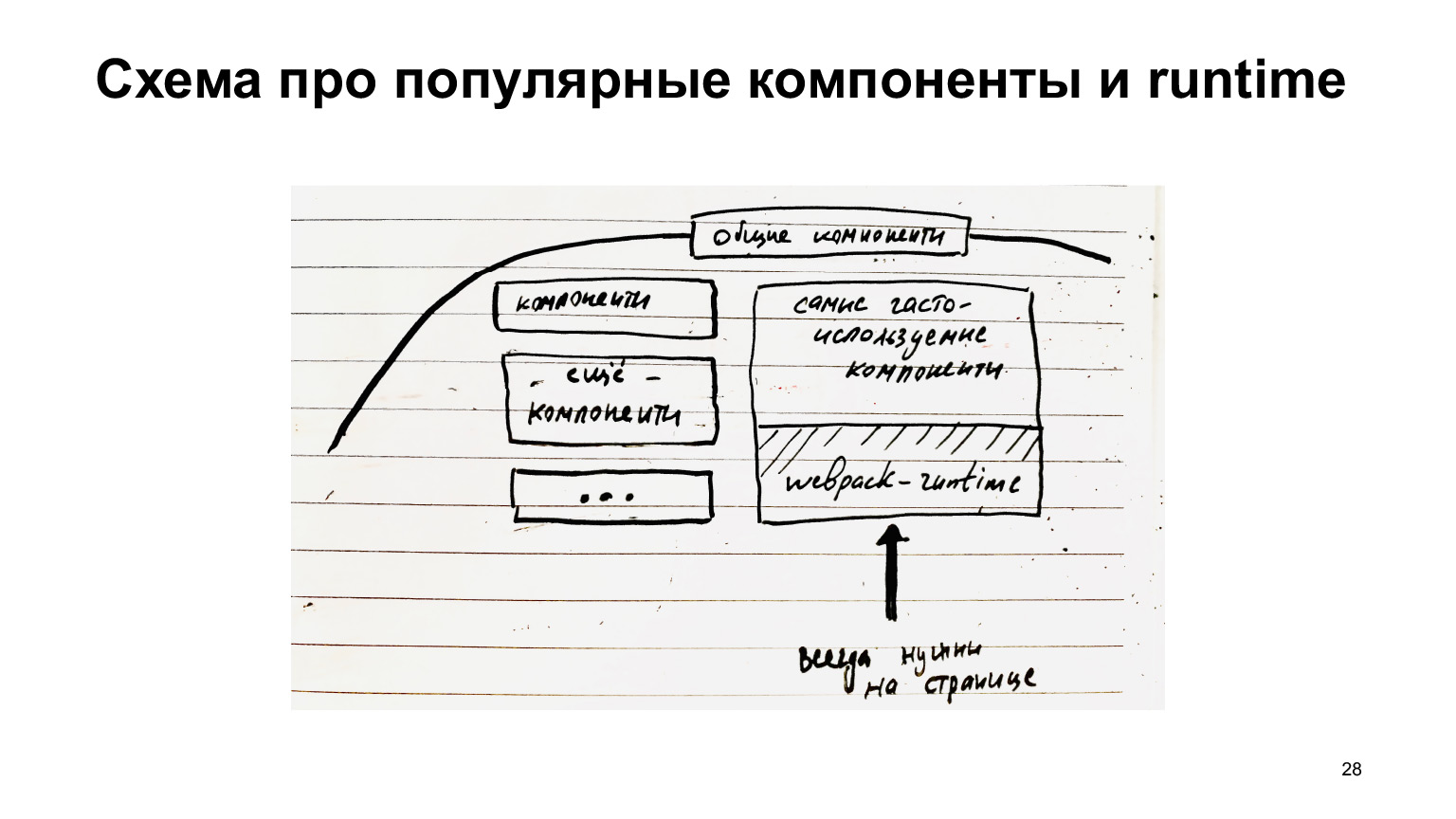
Par conséquent, il est logique de collecter dans un morceau séparé. Autrement dit, ces composants communs peuvent également être décomposés en composants qui ne sont pas toujours nécessaires et en composants qui sont toujours nécessaires. Ils peuvent être collectés dans un fichier séparé et toujours chargés, et également mis en cache, car ces composants communs, tels que les boutons / liens, ne changent pas très souvent, en général, tirent profit de la mise en cache.

Et en même temps, vous devez prendre une décision concernant l'assemblage des traductions.

Tout est assez clair ici. Si nous allons à Turkish Serp, nous aimerions télécharger uniquement les traductions turques et ne pas télécharger toutes les autres traductions, car il s'agit d'un code supplémentaire.
Qu'avons-nous fait? Tout d'abord, à propos du code serveur. À ce sujet, nous aurons deux directions: la construction pour la production et le lancement pour le développement.
En général, vous devez d'abord faire une telle déclaration distincte sur TypeScript. Comme je l'ai entendu, les projets utilisent généralement babel. Mais nous avons immédiatement décidé d'utiliser le compilateur TypeScript standard, car nous pensions que les nouvelles fonctionnalités de TypeScript l'atteindraient plus rapidement. Par conséquent, nous avons immédiatement abandonné babel et utilisé tsc.
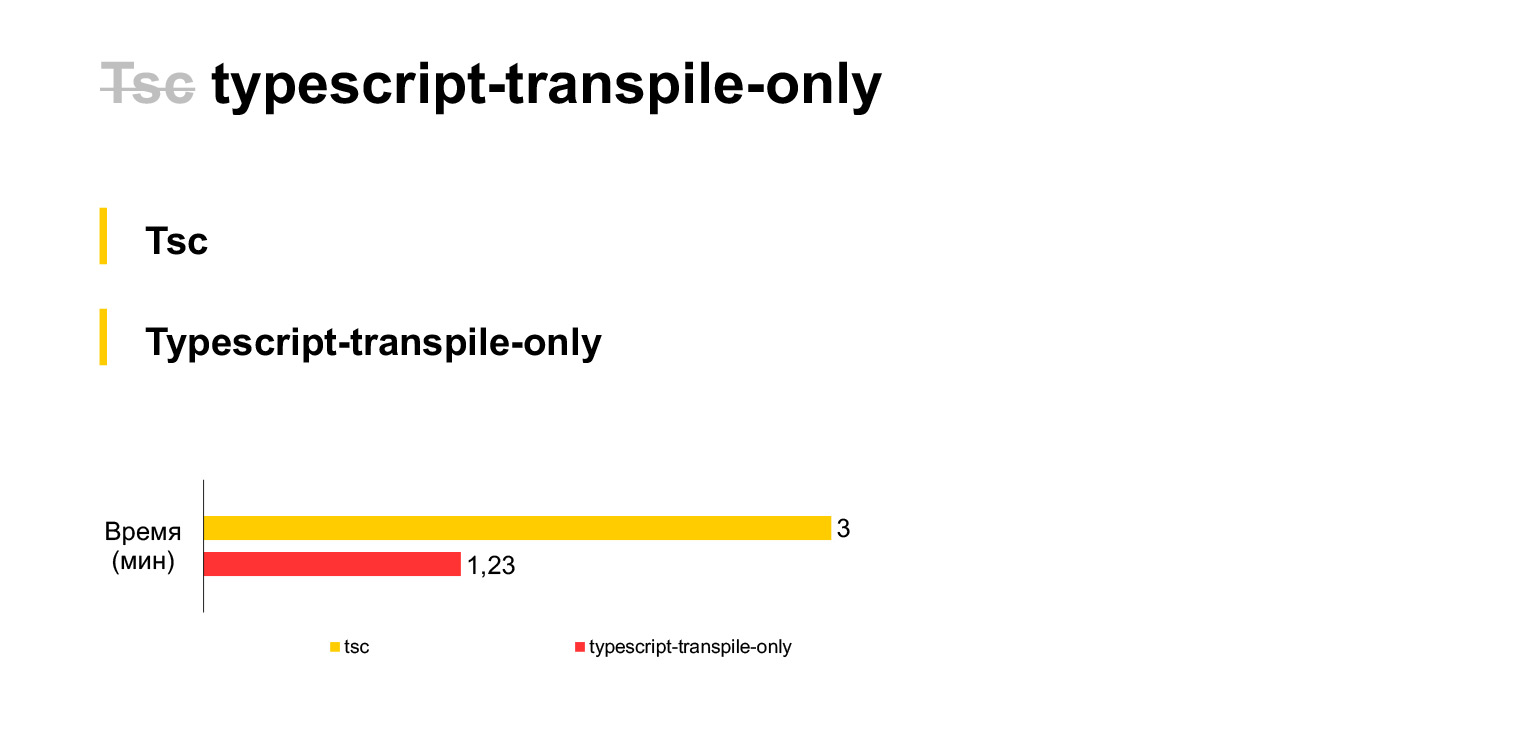
Donc, c'est notre taille de code actuelle, ces 30 mégaoctets sont compilés sur un ordinateur portable en trois minutes. Un peu de. Si vous refusez la vérification de type et utilisez un fork tsc lors de chaque compilation (malheureusement, TSC n'a pas de paramètre qui désactiverait la vérification de type, vous deviez fork), alors vous pouvez gagner deux fois le temps. La compilation de notre code ne prendra qu'une minute et demie.
Pourquoi ne pouvons-nous pas vérifier le type au moment de la compilation? Parce que nous pouvons, par exemple, les vérifier dans les hooks de pré-validation. Créez un linter qui n'exécutera que la vérification de type, et l'assemblage lui-même peut être fait sans vérification de type. Nous avons pris cette décision.
Comment fonctionnons-nous en dev? Dev utilise généralement aussi un bundle de babel avec webpack, mais nous utilisons un outil comme ts-node.

C'est un outil très simple. Pour l'exécuter, il suffit d'écrire ce require (ts-node) dans le fichier JavaScript d'entrée, et il remplacera les require-s de l'ensemble du code TS plus tard dans ce processus. Et si un code TS est chargé dans ce processus en cours de route, il sera compilé à la volée. Une chose très simple.
Naturellement, il y a une petite surcharge associée au fait que si le fichier n'a pas encore été chargé dans ce processus, il doit être recompilé. Mais en réalité, cette surcharge est minime et généralement acceptable.
De plus, il y a des lignes plus intéressantes dans cette liste. La première consiste à ignorer les styles, car nous n'avons pas besoin de styles pour la création de modèles côté serveur. Nous n'avons besoin que de HTML. Par conséquent, nous utilisons également un tel module - ignore-styles. Et en plus, nous désactivons la même vérification de type (transpile uniquement), comme nous l'avons fait dans TSC, afin d'accélérer le travail de ts-node.
Passons au code client. Comment collectons-nous le code TS dans Webpack? Nous utilisons ts-loader et l'option transpileOnly, c'est-à-dire à peu près le même bundle. Au lieu de babel-loader, des outils plus ou moins standard ts-loader et transpileOnly.
Malheureusement, la construction incrémentielle ne fonctionne pas dans ts-loader. Autrement dit, après tout, ts-loader n'est pas tout à fait un outil standard, et il n'est pas fait par les mêmes personnes qui font TypeScript. Par conséquent, toutes les options du compilateur n'y sont pas prises en charge. Par exemple, la génération incrémentielle n'est pas prise en charge.
Une construction incrémentielle est une chose qui peut être très utile en développement. De la même manière, vous pouvez ajouter ces caches au pipeline. En général, lorsque vos modifications sont minimes, vous ne pouvez pas recompiler complètement tout, tout TypeScript, mais seulement ce qui a changé. Cela fonctionne assez efficacement.
En général, pour se passer d'une construction incrémentielle, nous utilisons le chargeur de cache. C'est la solution standard de webpack. Tout est clair. Lorsque le code TypeScript essaie de se connecter pendant une compilation Webpack, il est traité par le compilateur, ajouté au cache, et la prochaine fois, s'il n'y a pas eu de changements dans les fichiers source, le chargeur de cache n'exécutera pas ts-loader et le prendra du cache. Autrement dit, tout est assez simple ici.
Il peut être utilisé pour n'importe quoi, mais spécifiquement pour TypeScript, c'est une chose pratique, car ts-loader est un chargeur assez lourd, donc le chargeur de cache est très approprié ici.

Mais le chargeur de cache a un inconvénient: il fonctionne avec l'heure de modification des fichiers. Voici un extrait du code source. Et cela n'a pas fonctionné pour nous.

Nous avons dû bifurquer et refaire l'algorithme de mise en cache basé sur le hachage du contenu du fichier, car cela ne nous convenait pas pour l'utilisation du chargeur de cache dans le pipeline.
Le fait est que lorsque vous souhaitez réutiliser les résultats de compilation entre plusieurs pull requests, ce mécanisme ne fonctionnera pas. Parce que si l'assemblage était, par exemple, il y a longtemps. Ensuite, vous essayez de faire une nouvelle demande d'extraction qui ne modifie pas les fichiers qui ont été collectés la fois précédente.
Mais leur mtime est plus récent. En conséquence, le chargeur de cache pensera que les fichiers ont été mis à jour, mais en fait non, car ce n'est pas une heure de modification, mais une heure d'extraction. Et si vous le faites comme ça, les hachages du contenu seront comparés. Le contenu n'a pas changé, l'ancien résultat sera utilisé.
Il convient de noter ici que si nous utilisions babel, babel-loader a un mécanisme de mise en cache à l'intérieur par défaut, et il est déjà fait sur les hachages du contenu, pas sur mtime. Par conséquent, nous allons peut-être réfléchir un peu plus et regarder vers Babel.
Maintenant, à propos de l'assemblage des morceaux.

Parlons un peu de ce que fait Webpack par défaut. Si nous avons un fichier d'index d'entrée, les composants y sont connectés. Ils ont aussi des composants, etc. De plus, des modules communs sont connectés: React, React-dom et lodash, par exemple.
Donc, par défaut, webpack, comme tout le monde le sait probablement, mais juste au cas où, je le répète, rassemble toutes les dépendances dans un gros paquet.
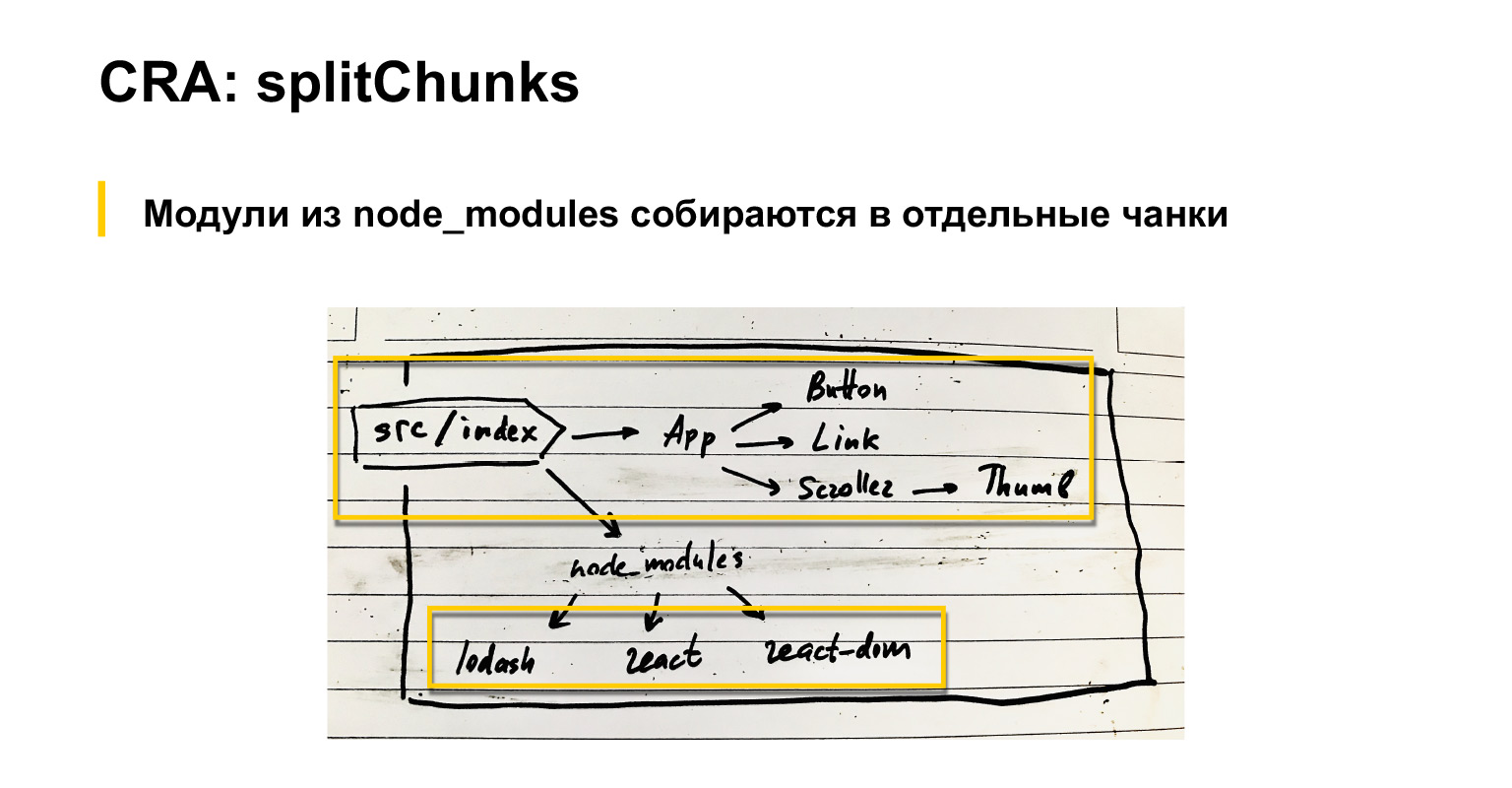
Dans le même temps, tout ce qui est connecté via node_modules peut être assemblé soit en tant qu'externe, chargé avec des scripts séparés, ou dans un bloc séparé en configurant un paramètre optimisation.splitChunks spécial dans webpack. À mon avis, même par défaut, ces modules fournisseurs sont rassemblés dans un bloc séparé. L'ARC a une version légèrement modifiée de ce splitChunks.

Rappelons-nous ce que sont les runtimeChunks. Je l'ai mentionné. C'est le genre de code qui contient un tel "en-tête" de scripts de chargement et de fonctions qui assurent le fonctionnement du système modulaire sur le client. Et puis un tableau (ou cache), qui, en fait, contient les modules.

Pourquoi ai-je parlé de ça? Parce que Create React App utilise toujours un paramètre qui collecte ces runtimeChunks dans un fichier séparé. Ce fichier ne sera pas bloqué dans le bundle sain d'origine, mais dans un fichier séparé. Il peut être mis en cache dans le navigateur et tout ça.
Alors, qu'est-ce qui ne fonctionne pas pour nous dans Create React App?

Ce splitChunks, qui y est utilisé par défaut, collecte uniquement node_modules en blocs séparés. Mais, en fait, il existe des composants communs, des bibliothèques communes, qui sont au niveau du projet. Je voudrais également les rassembler en morceaux séparés, car ils changent peut-être aussi rarement. Pourquoi nous limitons-nous uniquement à ce qui est dans node_modules?
De plus, à propos de runtimeChunks, nous pouvons également dire qu'il serait formidable, comme nous l'avons initialement discuté, en plus du runtime lui-même, de collecter également les modules, dans le même morceau, qui sont toujours nécessaires. Mêmes boutons / liens. Il y a toujours des liens sur Serp. J'aimerais toujours collecter des liens. C'est-à-dire non seulement le runtime webpack, mais aussi certains composants très populaires.
Ce n'est pas présent dans Create React App. Comment l'avons-nous fait avec nous?

Nous avons modifié splitChunks de telle manière que nous avons désactivé tous les comportements standard et demandé de collecter dans un code commun non seulement ce qui se trouve dans node_modules, mais aussi quels sont les composants communs de notre projet et le code de bibliothèque de notre projet, ce qui est dans src / lib , src / components contient.
De plus, nous collectons en blocs séparés ce qui est connecté via des importations dynamiques, et ce que l'on appelle généralement des blocs asynchrones.
Ici, vous devez faire attention à deux options. L'un est en vigueur et l'autre est initial. En général, enforce est un paramètre suffisamment pratique pour désactiver toute heuristique complexe dans splitChunks.
Par défaut, splitChunks essaie de comprendre combien de modules sont demandés et de prendre ces statistiques en compte dans le fractionnement. Mais il est difficile de suivre cela, et la demande d'un module peut changer de temps en temps, et le module «sautera» entre les morceaux. Du bloc général au groupe de fonctionnalités et vice-versa. Autrement dit, il s'agit d'un comportement très imprévisible, nous le désactivons donc.
Autrement dit, nous disons toujours tout ce qui satisfait les conditions dans le champ de test, nous entrons dans les morceaux communs. Nous ne voulons aucune heuristique.
Mais chunks: initial c'est aussi une bonne chose, il s'agit du fait que ces modules synchrones, modules qui sont connectés via des importations dynamiques, peuvent être connectés à différents endroits de différentes manières. Autrement dit, vous pouvez connecter le même module soit par importation dynamique, soit par importation régulière.
Et la valeur initiale permet de construire le même module de deux manières. Autrement dit, il est assemblé, à la fois asynchrone et synchrone, lui permettant ainsi d'être utilisé dans les deux sens. Assez pratique. Cela gonfle légèrement la taille des statiques collectées, mais vous permet d'utiliser toutes les importations.
D'après la documentation, en passant, c'est assez difficile à comprendre. J'ai récemment relu la documentation du webpack et rien de normal n'est écrit sur initial.

C'est ce que nous avons fait avec splitChunks. Maintenant, qu'avons-nous fait avec runtimeChunks. Au lieu de collecter uniquement le runtime dans runtimeChunks, nous souhaitons y ajouter d'autres composants très populaires.
Nous avons écrit notre propre plugin appelé MainChunkPlugin. Et il a une configuration très simple. Il y a juste une liste de modules qui doivent être rassemblés là-bas, ce que nous avons considéré comme populaire.
En utilisant simplement nos outils de test A / B, divers outils hors ligne, nous avons réalisé quels composants sont le plus souvent dans les résultats de recherche. C'est là qu'ils ont été écrits dans une liste aussi plate. Et à la fin, notre plugin collecte ces composants de la liste, ainsi que les bibliothèques, ainsi que le runtime webpack qui recueille cette optimisation standard.splitChunks.

Voici, au fait, un morceau de code qui colle le runtime. Pas si simple non plus de montrer que les plugins ne sont pas si faciles à écrire, mais voyons ensuite ce que cela a donné.

Il convient également de noter que de manière générale, webpack dispose d'un mécanisme standard pour ce faire, appelé DLLPlugin. Il vous permet également de collecter un morceau séparé selon la liste des dépendances. Mais cela présente un certain nombre d'inconvénients. Par exemple, il n'inclut pas les runtimeChunks. Autrement dit, runtimeChunks vous aurez toujours un morceau séparé, et il y aura un morceau assemblé par DLLPlugin. Ce n'est pas très pratique.
DLLPlugin nécessite également un assembly séparé. Autrement dit, si nous voulions construire ce bloc séparé avec les composants les plus percutants à l'aide de DLLPlugin, nous devrons exécuter deux assemblys.
Autrement dit, on a assemblé ce morceau séparé avec le fichier manifeste, et le reste de l'assemblage rassemblerait tout le reste, simplement en soustrayant le fichier manifeste, il ne collecterait pas ce qui est déjà entré dans le morceau avec les composants populaires. Et cela ralentit la construction, car l'implémentation DLLPlugin nous a pris sept secondes localement. C'est beaucoup. Et il ne peut pas être optimisé car il a une exécution séquentielle stricte.
De plus, à un certain moment, nous devions construire cette partie principale de la nôtre avec des composants populaires sans CSS, uniquement JS. DLLPlugin ne fait pas cela. Il collecte toujours tout ce qui est disponible via les importations. Autrement dit, si vous incluez du CSS, il frappe toujours aussi. C'était inconfortable pour nous. Mais si ce n'est pas un problème pour vous et que vous ne voulez pas écrire un code aussi délicat, alors DLLPlugin est une solution tout à fait normale. Il résout le problème principal. Autrement dit, il fournit les composants les plus populaires dans un fichier séparé. Ça peut être utilisé.
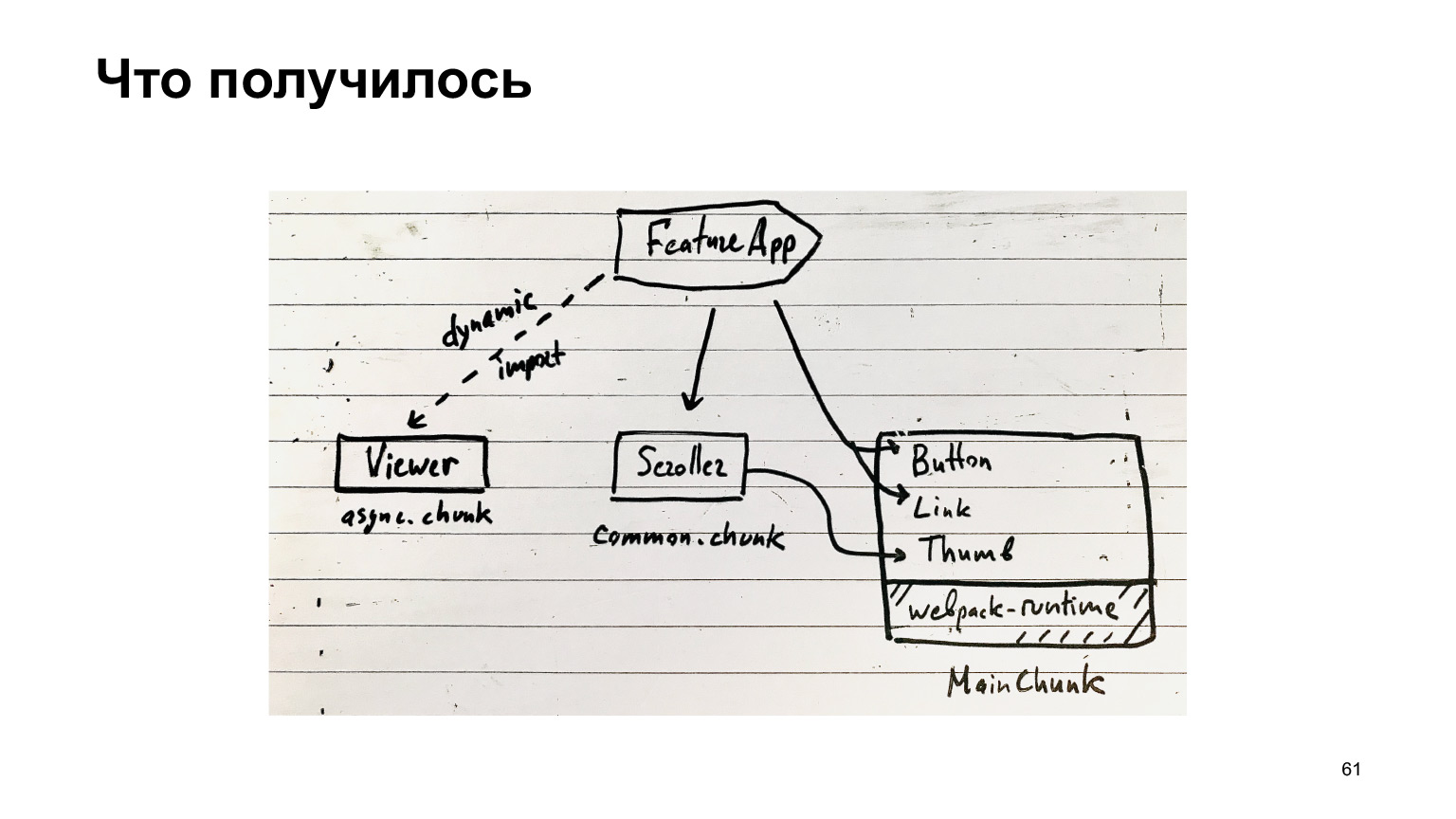
Alors qu'avons-nous obtenu? Notre fonctionnalité peut utiliser des composants très populaires de notre MainChunk, qui sont assemblés par un plugin spécial du même nom. En outre, il existe des blocs communs, qui incluent toutes sortes de composants communs, et il existe des blocs asynchrones, qui sont chargés via des importations dynamiques.
Le reste du code se trouve dans les ensembles de fonctionnalités. En principe, il s'agit de votre structure de bloc.
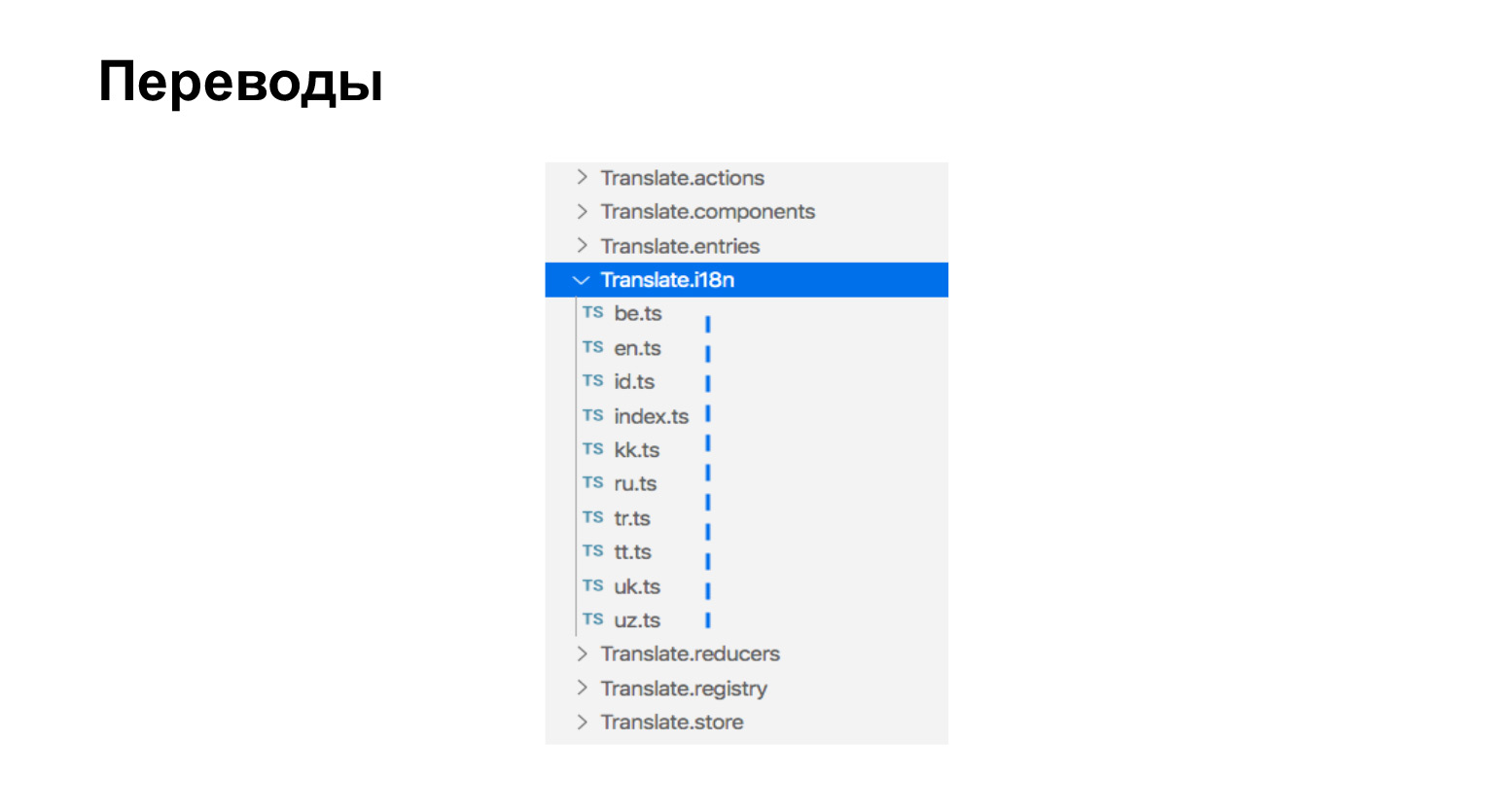
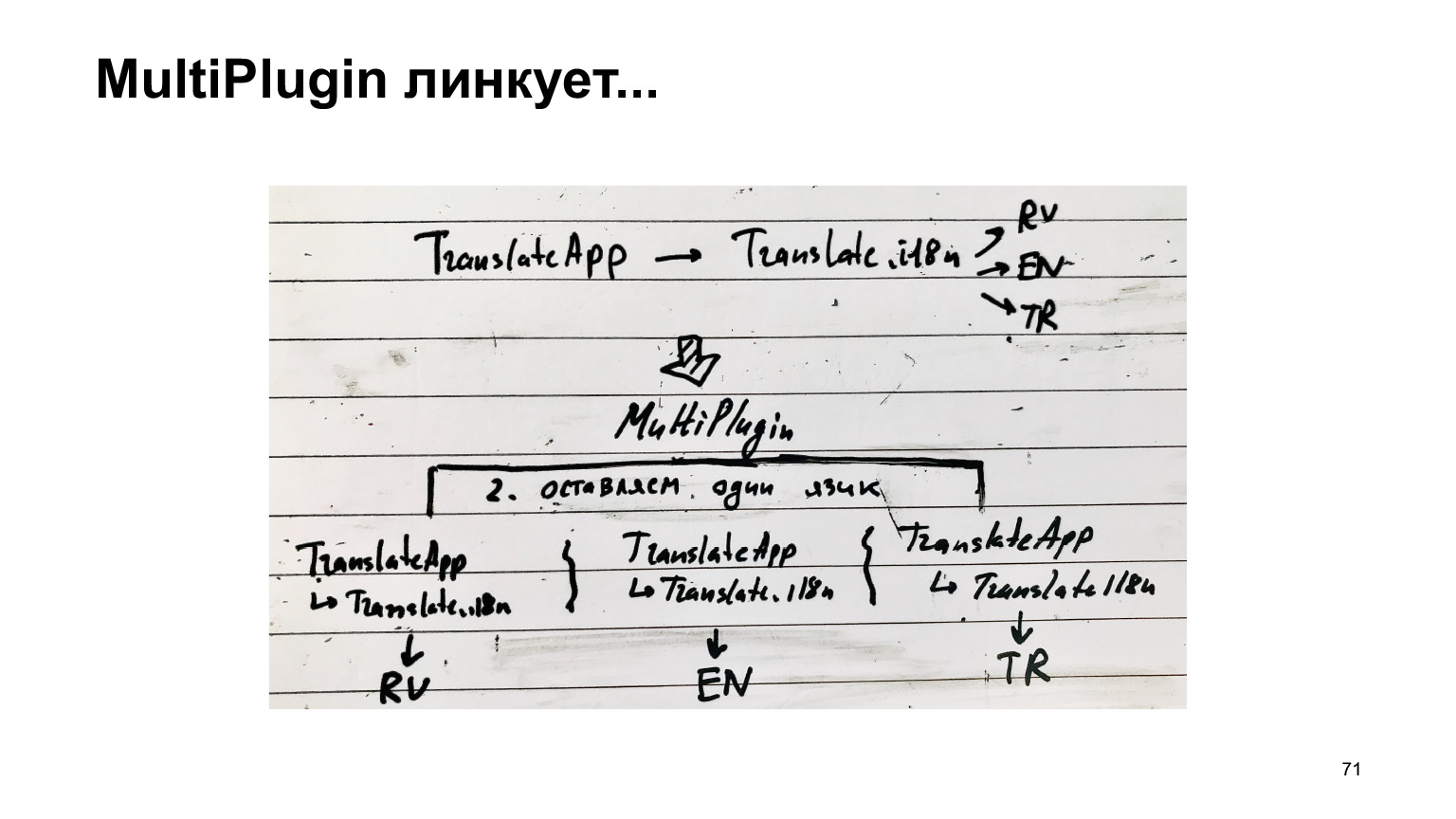
À propos de l'assemblage des traductions. Nos traductions ne sont que des fichiers ts qui se trouvent à côté des composants qui ont besoin de traductions. Ici, nous avons neuf langues, voici neuf fichiers.

Les traductions ressemblent à ceci. Il s'agit simplement d'un objet contenant une phrase clé et la signification de la phrase traduite.

C'est ainsi que les traductions sont connectées au composant, puis un assistant spécial est utilisé.

Comment ces traductions pourraient-elles être collectées? Nous pensons: nous devons collecter les traductions, regarder sur Internet, ce qu'ils écrivent, comment le faire.
Ils disent sur Internet: utilisez la multicompilation. Autrement dit, au lieu d'exécuter une version Webpack, exécutez simplement la version Webpack pour chaque langue. Mais, disent-ils, tout ira bien, car il y a un chargeur de cache, c'est tout ce travail général avec TypeScript, ou tout ce que vous avez, sera mis en cache, et donc ce ne sera pas long.
Ne vous découragez pas, ne pensez pas que ce sera neuf véritables exécutions de webpack. Ce ne sera pas le cas, ce sera bien.
La seule chose à corriger est d'ajouter le module ReplacementPlugin, qui, au lieu d'un fichier d'index qui connecte toutes les langues, le remplacera par une langue spécifique. Tout est assez trivial, et oui, la sortie doit être corrigée. Il s'avère maintenant que nous devons collecter un ensemble distinct pour chaque langue.

Le diagramme de cette recette est le suivant. Il y avait un traducteur. Il a connecté les traductions du traducteur. Il a connecté des langues, et nous, au lieu de collecter cette structure unique, nous l'avons répliquée pour chaque langue, en avons obtenu une distincte et collectons chacune dans une compilation séparée.
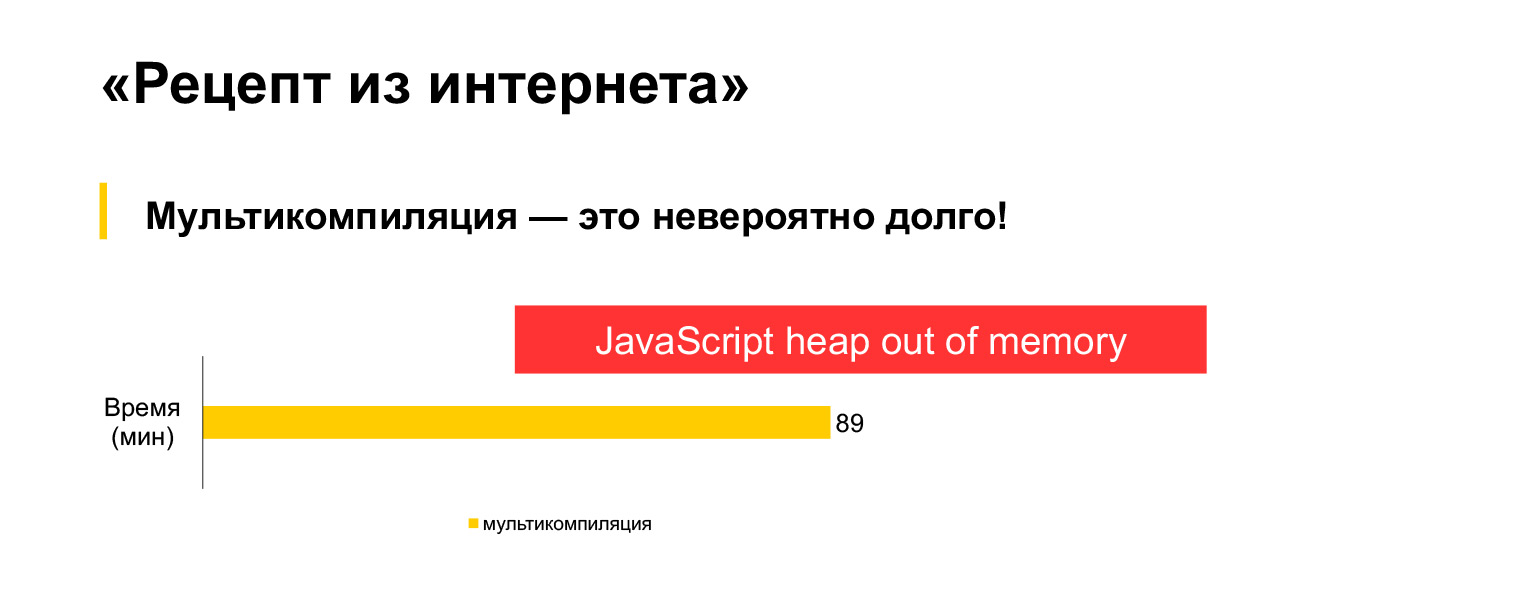
Malheureusement, cela ne fonctionne pas. J'ai essayé d'exécuter cette option de multicompilation pour notre code actuel de 30 Mo, et j'ai attendu une heure et demie et j'ai obtenu cette erreur.

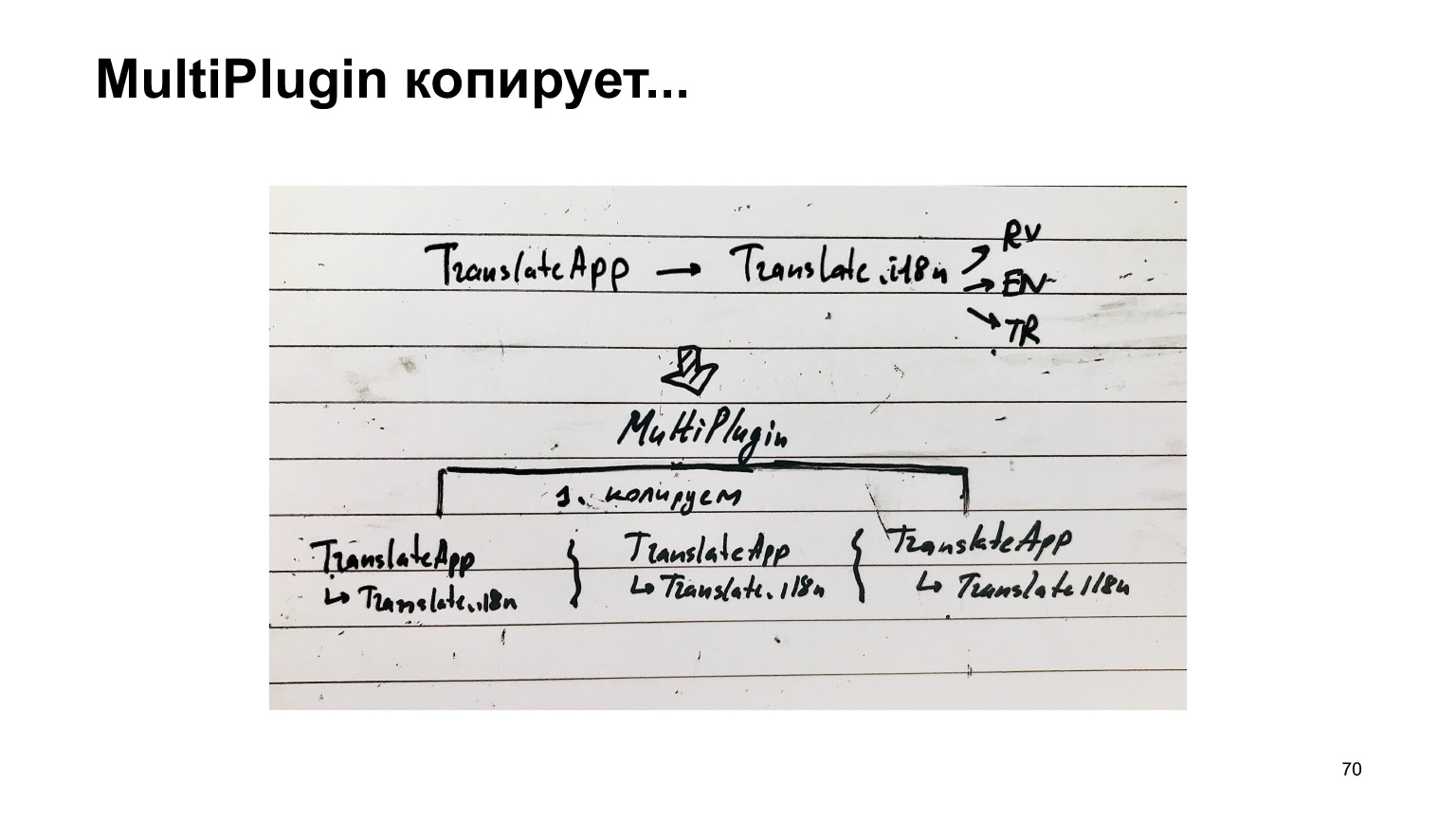
C'est très long et impossible. Qu'avons-nous fait avec cela? Nous avons créé un autre plugin. Nous prenons la même structure et nous nous enfonçons dans le travail de webpack lorsqu'il est sur le point de sauvegarder les fichiers de sortie sur le disque. Nous copions cette structure autant de fois que nous avons de langues, et collons une langue à chacune. Et alors seulement, nous créons les fichiers.

Dans le même temps, le travail principal effectué par Webpack pour contourner les dépendances de compilation n'est pas répété. Autrement dit, nous nous arrêtons à la toute dernière étape, et nous pouvons donc espérer que ce sera rapide.

Mais le code du plugin s'est avéré compliqué. C'est littéralement un huitième de notre plugin. Je montre juste à quel point c'est difficile. Et là, on y trouve régulièrement de petits insectes désagréables. Mais ce n'était pas plus facile de le mettre en œuvre. Mais ça marche très bien.
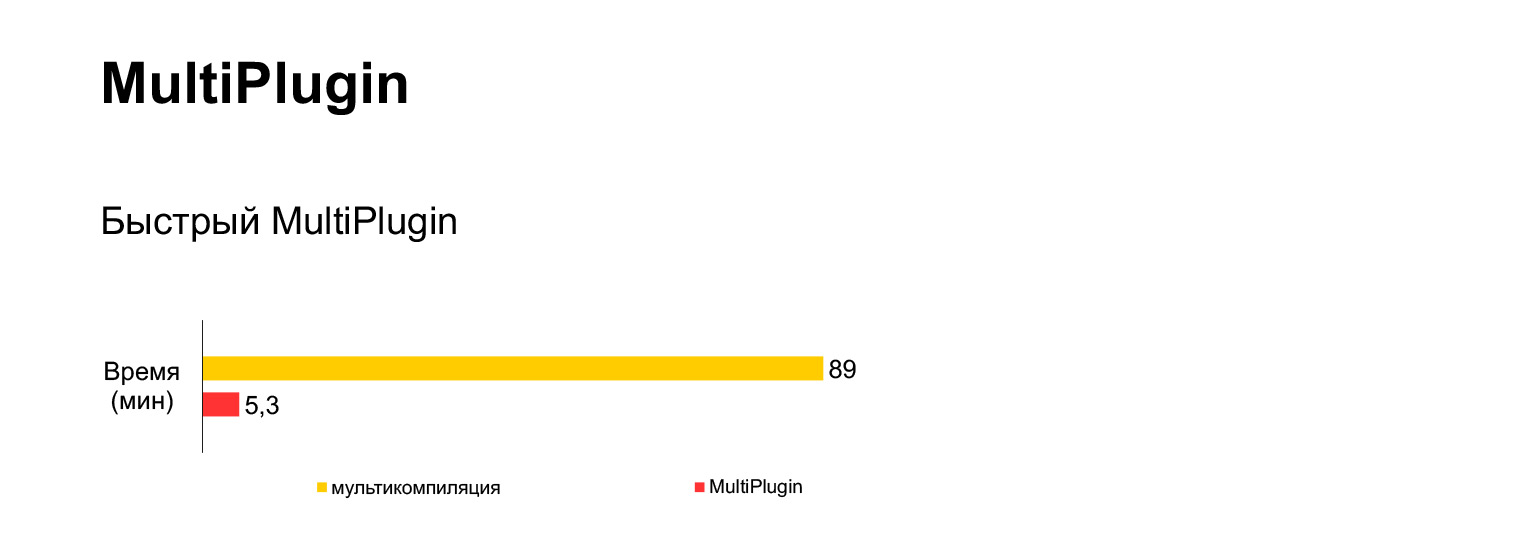
Autrement dit, au lieu d'une heure et demie avec une erreur, nous obtenons cinq minutes d'assemblage avec ce plugin qui est le nôtre.
Maintenant livraison et initialisation.

La livraison et l'initialisation sont simples. Ce que nous chargeons dans des ressources séparées, nous utilisons la précharge, comme tout le monde, je suppose. Ensuite, nous incluons CSS, JS, en fait HTML pour nos composants, et chargeons nos ressources, mais sans asynchronisation.
Nous avons expérimenté. Si nous utilisons async, le moment du début de l'interactivité est retardé, ce que nous ne voudrions pas. Utilisez donc simplement le préchargement et le chargement à la fin de la page. En général, rien de spécial.

En même temps, nous intégrons tout le reste. Autrement dit, c'est notre MainChunk, nous intégrons son CSS. Composants généraux, styles, en général, tout ce qui est écrit sur la diapositive, nous allons en ligne. C'était aussi une série d'expériences qui ont montré que "inline" donne le meilleur résultat pour le premier rendu et le début de l'interactivité.
Et maintenant aux chiffres. Pour parler de chiffres, vous devez dire deux mots sur les métriques.

Nous avons une équipe dédiée à la vitesse dédiée à faire fonctionner efficacement tout le code frontal. Cela concerne la création de modèles côté serveur, le chargement des ressources et l'initialisation sur le client, en général, tout cela.
Nous avons tout un tas de métriques qui sont envoyées de la production à notre système d'enregistrement spécial. Nous pouvons contrôler cela dans les expériences A / B. Nous avons des outils hors ligne, en général, nous suivons très activement tout cela.
Et nous avons utilisé ces outils lorsque nous avons implémenté notre nouveau code dans React et TypeScript.

Suivons maintenant à l'aide d'outils hors ligne (car je ne pouvais pas mettre sur pied une expérience en ligne honnête qui utiliserait toutes nos métriques). Voyons ce qui se passe si nous revenons de notre solution actuelle à Create React App sur ces métriques clés.
L'outil fonctionne très simplement. Une tranche de requêtes est prise, dans ce cas une requête avec des fonctionnalités dans React est prise, car tous les Serp n'ont pas encore été réécrits dans React. Ensuite, nos modèles sont bombardés, les mesures sont collectées, insérées dans un utilitaire spécial qui compare et trouve ces résultats et mesures. Dans ce cas, il ne reste que des résultats statistiquement significatifs. En général, tout y est raisonnable.
Voyons ce qui se passe.

La désactivation de MultiPlugin, qui, en fait, collecte toutes les traductions au lieu de seulement la traduction requise, n'a montré aucun changement statistiquement significatif.
Au début, j'étais un peu contrarié, puis j'ai réalisé qu'en fait, ce n'était pas un problème, car maintenant nous n'avons pas beaucoup de fonctionnalités qui ont de nombreuses traductions traduites en React. Par conséquent, quand il y aura plus de telles fonctionnalités, ces changements importants apparaîtront définitivement. C'est juste que maintenant il y a des fonctionnalités qui sont principalement montrées en Russie et qui n'ont pas de traduction. Et la quantité de code contenue dans les composants dépasse largement la quantité de traductions. Par conséquent, il est imperceptible que toutes les traductions soient en cours.
Ce serait peut-être perceptible dans des expériences plus honnêtes, si une expérience honnête était menée. Mais l'outil hors ligne n'a pas montré ces changements.

Si nous désactivons MainChunkPlugin, le temps de début de l'interactivité ralentit et le chargement HTML ralentit également beaucoup. Par conséquent, la chose est tout à fait nécessaire.
Pourquoi le chargement du HTML ralentit-il, car tout le code qui était auparavant chargé dans ce morceau séparé par une ressource distincte est maintenant incorporé dans HTML. C'est comme si nous intégrions tout, mais l'interactivité ralentit également. En principe, tout à fait attendu.
Et maintenant la question: que se passerait-il si vous mettiez tout dans un seul paquet, n'utilisez pas de morceaux avec des composants communs? Il s'avère que ce n'est pas du tout une image heureuse.

Le premier rendu ralentit considérablement. L'interactivité a également presque doublé. Cela rend le HTML plus petit car tout le code commence à être livré dans une ressource distincte. Mais l'interactivité, comme vous pouvez le voir, n'aide pas.
Et l'assemblage. Dernières diapositives.
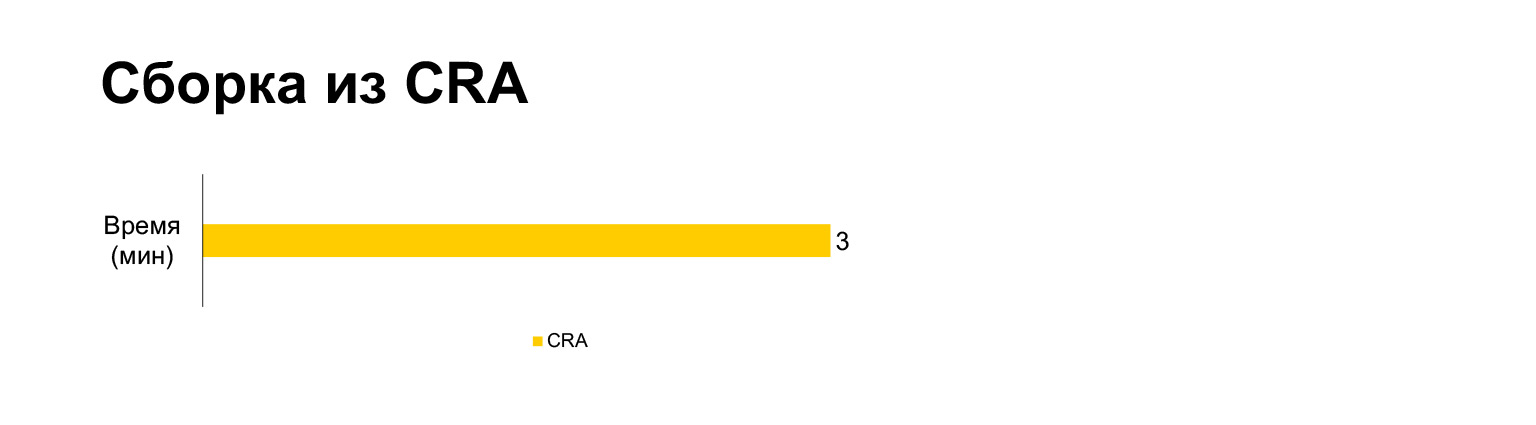
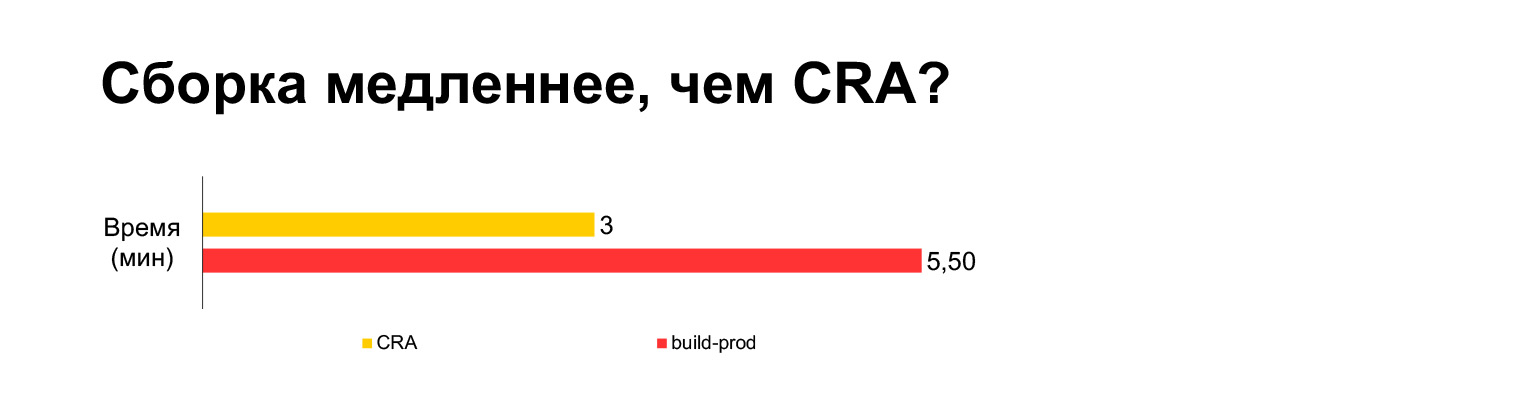
Le temps de génération de l'application Create React pour le projet actuel prend trois minutes sur un ordinateur portable. Et avec toutes nos cloches et sifflets - cinq minutes. Longue?
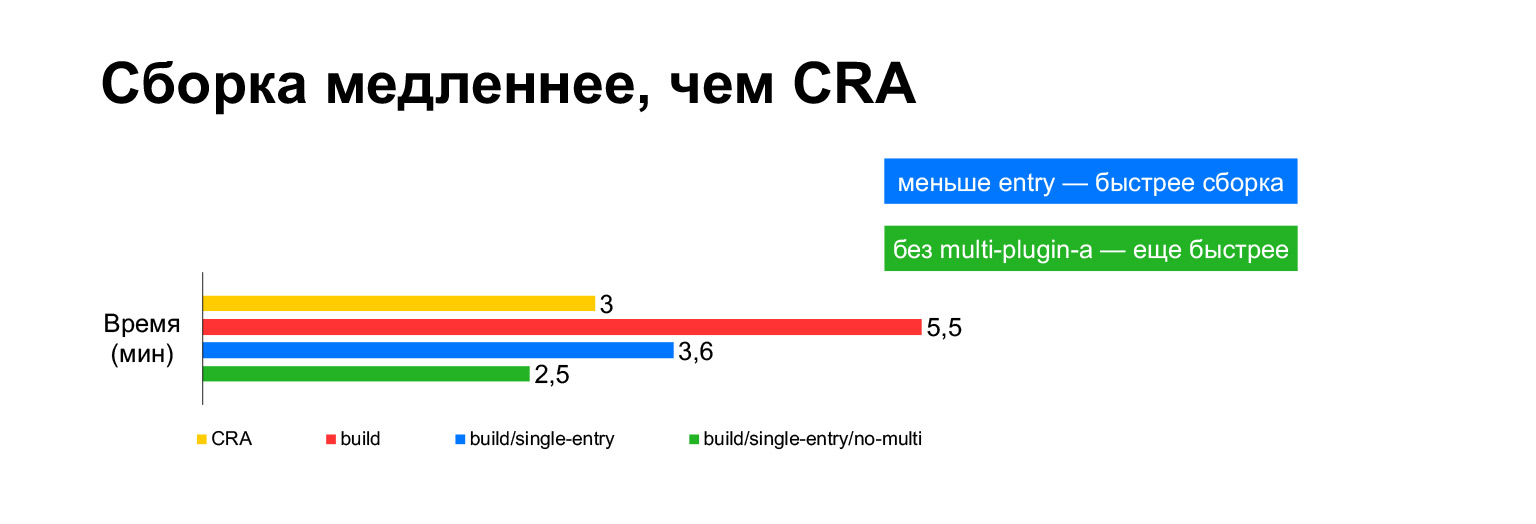
Cependant, en fait, si vous le mettez dans un seul paquet, cela prend trois minutes. Construire sans MultiPlugin le rend encore plus rapide que Create React App. Mais comme je l'ai montré dans les diapositives précédentes, nous ne pouvons pas refuser ces modifications aux scripts de construction d'origine, car sans eux, les métriques de vitesse deviendront très mauvaises.
Passons maintenant en revue ce qu'il est utile de tirer de ce rapport.

Babel n'est pas le seul moyen de travailler avec TypeScript. TSC, ts-node et ts-loader peuvent être utilisés. Cela fonctionne assez bien.
Cela étant dit, les vérifications de TypeScript, la vérification de type, ne doivent pas être effectuées à chaque fois que vous construisez. Cela ralentit beaucoup - comme vous vous en souvenez, deux fois. Par conséquent, il est préférable de placer ces éléments dans des contrôles séparés, des hooks de pré-validation, par exemple.
Il est préférable de rassembler les composants fréquemment utilisés dans un bloc séparé. Il est également souhaitable de collecter les composants communs dans des blocs séparés, car cela permet de charger uniquement ce qui est nécessaire, uniquement diff.
Le plus important est que si vous ne disposez pas de tout le code utilisé sur toutes les pages, vous devez le décomposer en entrées distinctes, collecter des lots séparés et les charger lorsque l'utilisateur voit les types de résultats de recherche correspondants. Téléchargez uniquement les fichiers dont vous avez besoin. Ceci, comme vous l'avez vu, donne le meilleur résultat. Chose assez évidente, mais je ne suis pas sûr que tout le monde le fasse, car ils restent toujours sur Create React App.
La multicompilation est très longue. Ne croyez pas si quelqu'un dit que la multicompilation est acceptable et que des caches quelque part à l'intérieur peuvent gérer tout cela. L'utilisation de la précharge et en ligne donne également des résultats.
Plusieurs liens sur la faucille:
- clck.ru/PdRdh et clck.ru/PdRjb - deux rapports sur la réécriture de Serp dans React, c'est la première étape, sur la façon dont nous en sommes arrivés à cela et pourquoi nous avons commencé à le faire. Le deuxième rapport porte sur la façon dont nous avons planifié et fait tout cela d'un point de vue managérial, quelles étaient les étapes.
- clck.ru/PdRnr - rapport sur nos métriques de vitesse. C'est pour ceux qui se sont soudainement demandé ce qu'il y avait d'autre, comment fonctionnent les outils en ligne.
Merci à tous.