Rappelons-nous le plan par lequel nous avançons:
1 partie . Nous avons décidé de la tâche technique et de l'architecture de la solution, écrit une application en golang.
Partie 2 (vous êtes ici maintenant). Nous mettons notre application en production, la rendons évolutive et testons la charge.
Partie 3. Essayons de comprendre pourquoi nous devons stocker les messages dans un tampon, et non dans des fichiers, et comparons également les services de file d'attente kafka, rabbitmq et yandex.
Partie 4. Nous allons déployer le cluster Clickhouse, écrire le streaming pour y transférer les données de la mémoire tampon, mettre en place la visualisation dans les datalens.
Partie 5.Mettons toute l'infrastructure en forme - configurez ci / cd à l'aide de gitlab ci, connectez la surveillance et la découverte de services à l'aide de consul et prometheus.

Eh bien, passons à nos tâches.
Nous versons dans la production
Dans la première partie, nous avons assemblé l'application , l' avons testée et avons également téléchargé l'image dans le registre de conteneurs privé, prête à être déployée.
En général, les prochaines étapes devraient être presque évidentes: nous créons des machines virtuelles, configurons un équilibreur de charge et écrivons un nom DNS avec proxy vers cloudflare. Mais je crains que cette option ne corresponde pas étroitement à notre mandat. Nous voulons pouvoir faire évoluer notre service en cas d'augmentation de la charge et éliminer les nœuds cassés qui ne peuvent pas répondre aux demandes.
Pour le scaling, nous utiliserons les groupes d'instances disponibles dans le cloud de calcul. Ils vous permettent de créer des machines virtuelles à partir d'un modèle, de surveiller leur disponibilité à l'aide de vérifications de l'état et également d'augmenter automatiquement le nombre de nœuds en cas d'augmentation de la charge.Plus de détails ici .
Il n'y a qu'une seule question - quel modèle utiliser pour la machine virtuelle? Bien sûr, vous pouvez installer Linux, le configurer, créer une image et la télécharger sur le stockage d'images de Yandex.Cloud. Mais pour nous, c'est un voyage long et difficile. En examinant les différentes images disponibles lors de la création d'une machine virtuelle, nous sommes tombés sur une instance intéressante: une image optimisée pour le conteneur ( https://cloud.yandex.ru/docs/cos/concepts/ ). Il vous permet d'exécuter un seul conteneur Docker dans un hôte en mode réseau. Autrement dit, lors de la création d'une machine virtuelle, approximativement la spécification suivante pour l'image optimisée du conteneur est indiquée:
spec:
containers:
- name: api
image: vozerov/events-api:v1
command:
- /app/app
args:
- -kafka=kafka.ru-central1.internal:9092
securityContext:
privileged: false
tty: false
stdin: false
restartPolicy: AlwaysEt après le démarrage de la machine virtuelle, ce conteneur sera téléchargé et lancé localement.
Le schéma est assez intéressant:
- Nous créons un groupe d'instances avec mise à l'échelle automatique lorsque l'utilisation du processeur dépasse 60%.
- En tant que modèle, nous spécifions une machine virtuelle avec une image optimisée pour le conteneur et des paramètres pour exécuter notre conteneur Docker.
- Nous créons un équilibreur de charge, qui examinera notre groupe d'instances et se mettra à jour automatiquement lors de l'ajout ou de la suppression de machines virtuelles.
- L'application sera surveillée à la fois en tant que groupe d'instances et par l'équilibreur lui-même, ce qui déséquilibrera les machines virtuelles inaccessibles.
Ça ma l'air bon!
Essayons de créer un groupe d'instances à l'aide de terraform. La description complète se trouve dans instance-group.tf, je commenterai les points principaux:
- L'ID de compte de service sera utilisé pour créer et supprimer des machines virtuelles. Au fait, nous devrons le créer.
service_account_id = yandex_iam_service_account.instances.id - spec.yml, , . registry , - — docker hub. , —
metadata = { docker-container-declaration = file("spec.yml") ssh-keys = "ubuntu:${file("~/.ssh/id_rsa.pub")}" } - service account id, container optimized image, container registry . registry , :
service_account_id = yandex_iam_service_account.docker.id - Scale policy. :
autoscale { initialsize = 3 measurementduration = 60 cpuutilizationtarget = 60 minzonesize = 1 maxsize = 6 warmupduration = 60 stabilizationduration = 180 }
. — fixed_scale , auth_scale.
:
initial size — ;
measurement_duration — ;
cpu_utilization_target — , ;
min_zone_size — — , ;
max_size — ;
warmup_duration — , , ;
stabilization_duration — — , .
. 3 (initial_size), (min_zone_size). cpu (measurement_duration). 60% (cpu_utilization_target), , (max_size). 60 (warmup_duration), cpu. 120 (stabilization_duration), 60% (cpu_utilization_target).
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#auto-scale-policy - Allocation policy. , , — .
allocationpolicy { zones = ["ru-central1-a", "ru-central1-b", "ru-central1-c"] } - :
deploy_policy { maxunavailable = 1 maxcreating = 1 maxexpansion = 1 maxdeleting = 1 }
max_creating — ;
max_deleting — ;
max_expansion — ;
max_unavailable — RUNNING, ;
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#deploy-policy - :
load_balancer { target_group_name = "events-api-tg" }
Lors de la création d'un groupe d'instances, vous pouvez également créer un groupe cible pour l'équilibreur de charge. Il ciblera les machines virtuelles associées. S'ils sont supprimés, les nœuds seront supprimés de l'équilibrage et, lors de leur création, ils seront ajoutés à l'équilibrage après avoir passé les vérifications d'état.
Il semble que tout est basique - créons un compte de service pour le groupe d'instances et, en fait, le groupe lui-même.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_iam_service_account.instances -target yandex_resourcemanager_folder_iam_binding.editor
... skipped ...
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_compute_instance_group.events_api_ig
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Le groupe a été créé - vous pouvez afficher et vérifier:
vozerov@mba:~/events/terraform (master *) $ yc compute instance-group list
+----------------------+---------------+------+
| ID | NAME | SIZE |
+----------------------+---------------+------+
| cl1s2tu8siei464pv1pn | events-api-ig | 3 |
+----------------------+---------------+------+
vozerov@mba:~/events/terraform (master *) $ yc compute instance list
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ef3huodj8g4gc6afl0jg | cl1s2tu8siei464pv1pn-ocih | ru-central1-c | RUNNING | 130.193.44.106 | 172.16.3.3 |
| epdli4s24on2ceel46sr | cl1s2tu8siei464pv1pn-ipym | ru-central1-b | RUNNING | 84.201.164.196 | 172.16.2.31 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmh4la5dj0m82ihoskd | cl1s2tu8siei464pv1pn-ahuj | ru-central1-a | RUNNING | 130.193.37.94 | 172.16.1.37 |
| fhmr401mknb8omfnlrc0 | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.14 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
vozerov@mba:~/events/terraform (master *) $Trois nœuds aux noms tordus constituent notre groupe. Nous vérifions que des applications sont disponibles pour eux:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.44.106:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:04 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://84.201.164.196:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:09 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.37.94:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:15 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $À propos, vous pouvez accéder aux machines virtuelles avec la connexion ubuntu et voir les journaux du conteneur et comment il est démarré.
Un groupe cible a également été créé pour l'équilibreur auquel les requêtes peuvent être envoyées:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer target-group list
+----------------------+---------------+---------------------+-------------+--------------+
| ID | NAME | CREATED | REGION ID | TARGET COUNT |
+----------------------+---------------+---------------------+-------------+--------------+
| b7rhh6d4assoqrvqfr9g | events-api-tg | 2020-04-13 16:23:53 | ru-central1 | 3 |
+----------------------+---------------+---------------------+-------------+--------------+
vozerov@mba:~/events/terraform (master *) $Créons déjà un équilibreur et essayons de lui envoyer du trafic! Ce processus est décrit dans load-balancer.tf, points clés:
- Nous indiquons le port externe que l'équilibreur écoutera et le port pour envoyer une requête aux machines virtuelles. Nous indiquons le type d'adresse externe - ip v4. Pour le moment, l'équilibreur de charge fonctionne au niveau du transport, de sorte qu'il ne peut équilibrer que les connexions tcp / udp. Il vous faudra donc visser ssl soit sur vos machines virtuelles, soit sur un service externe capable de gérer https, par exemple cloudflare.
listener { name = "events-api-listener" port = 80 target_port = 8080 external_address_spec { ipversion = "ipv4" } } healthcheck { name = "http" http_options { port = 8080 path = "/status" } }
Bilans de santé. Ici, nous spécifions les paramètres de vérification de nos nœuds - nous vérifions par http url / status sur le port 8080. Si la vérification échoue, la machine sera déséquilibrée.
Plus d'informations sur l'équilibreur de charge - cloud.yandex.ru/docs/load-balancer/concepts . Fait intéressant, vous pouvez connecter le service de protection DDOS sur l'équilibreur. Ensuite, le trafic déjà nettoyé arrivera sur vos serveurs.
Nous créons:
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_lb_network_load_balancer.events_api_lb
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Nous sortons l'ip de l'équilibreur créé et testons le travail:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer network-load-balancer get events-api-lb
id:
folder_id:
created_at: "2020-04-13T16:34:28Z"
name: events-api-lb
region_id: ru-central1
status: ACTIVE
type: EXTERNAL
listeners:
- name: events-api-listener
address: 130.193.37.103
port: "80"
protocol: TCP
target_port: "8080"
attached_target_groups:
- target_group_id:
health_checks:
- name: http
interval: 2s
timeout: 1s
unhealthy_threshold: "2"
healthy_threshold: "2"
http_options:
port: "8080"
path: /statusMaintenant, nous pouvons y laisser des messages:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:57 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":1}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:58 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":2}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:43:00 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":3}
vozerov@mba:~/events/terraform (master *) $Super, tout fonctionne. Il ne reste qu'une touche finale pour que nous puissions être accessibles via https - nous activerons cloudflare avec proxy. Si vous décidez de vous passer de cloudflare, vous pouvez ignorer cette étape.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target cloudflare_record.events
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Test via HTTPS:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' https://events.kis.im/post
HTTP/2 200
date: Mon, 13 Apr 2020 16:45:01 GMT
content-type: application/json
content-length: 41
set-cookie: __cfduid=d7583eb5f791cd3c1bdd7ce2940c8a7981586796301; expires=Wed, 13-May-20 16:45:01 GMT; path=/; domain=.kis.im; HttpOnly; SameSite=Lax
cf-cache-status: DYNAMIC
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
server: cloudflare
cf-ray: 5836a7b1bb037b2b-DME
{"status":"ok","partition":0,"Offset":5}
vozerov@mba:~/events/terraform (master *) $Tout fonctionne enfin.
Tester la charge
Il nous reste peut-être l'étape la plus intéressante - effectuer des tests de charge de notre service et obtenir des chiffres - par exemple, le 95e centile du temps de traitement d'une demande. Ce serait également bien de tester l'autoscaling de notre groupe de nœuds.
Avant de commencer les tests, il vaut la peine de faire une chose simple: ajoutez nos nœuds d'application à prometheus pour garder une trace du nombre de requêtes et du temps de traitement d'une requête. Comme nous n'avons encore ajouté aucune découverte de service (nous le ferons dans l'article 5 de cette série), nous écrirons simplement static_configs sur notre serveur de surveillance. Vous pouvez trouver son adresse IP de la manière standard via la liste d'instances de calcul yc, puis ajouter les paramètres suivants à /etc/prometheus/prometheus.yml:
- job_name: api
metrics_path: /metrics
static_configs:
- targets:
- 172.16.3.3:8080
- 172.16.2.31:8080
- 172.16.1.37:8080Les adresses IP de nos machines peuvent également être extraites de la liste des instances de yc compute. Redémarrez prometheus via systemctl restart prometheus et vérifiez que les nœuds sont interrogés avec succès en accédant à l'interface Web disponible sur le port 9090 (84.201.159.71:9090).
Ajoutons un tableau de bord au grafana à partir du dossier grafana. Nous allons à Grafana sur le port 3000 (84.201.159.71:3000) et avec un login / password - admin / Password. Ensuite, ajoutez un prometheus local et importez le tableau de bord. En fait, à ce stade, la préparation est terminée - vous pouvez envoyer des demandes à notre installation.
Pour les tests, nous utiliserons le réservoir yandex ( https://yandex.ru/dev/tank/ ) avec un plugin pour overload.yandex.netce qui nous permettra de visualiser les données reçues par le réservoir. Tout ce dont vous avez besoin pour travailler se trouve dans le dossier de chargement du référentiel git d'origine.
Un peu sur ce qu'il y a:
- token.txt - un fichier avec une clé API de overload.yandex.net - vous pouvez l'obtenir en vous inscrivant sur le service.
- load.yml - le fichier de configuration du tank, le domaine pour les tests y est enregistré - events.kis.im, le type de chargement rps et le nombre de requêtes 15 000 par seconde pendant 3 minutes.
- data - un fichier spécial pour générer une configuration au format ammo.txt. Nous y écrivons le type de requête, l'url, le groupe d'affichage des statistiques et les données réelles à envoyer.
- makeammo.py - script pour générer un fichier ammo.txt à partir d'un fichier de données. En savoir plus sur le script - yandextank.readthedocs.io/en/latest/ammo_generators.html
- ammo.txt - le fichier de munitions résultant qui sera utilisé pour envoyer des demandes.
Pour les tests, j'ai pris une machine virtuelle en dehors de Yandex.Cloud (pour que tout reste honnête) et j'ai créé un enregistrement DNS pour load.kis.im. J'ai roulé docker là-bas, puisque nous allons démarrer le tank en utilisant l'image https://hub.docker.com/r/direvius/yandex-tank/ .
Eh bien, commençons. Copiez notre dossier sur le serveur, ajoutez un jeton et démarrez le tank:
vozerov@mba:~/events (master *) $ rsync -av load/ cloud-user@load.kis.im:load/
... skipped ...
sent 2195 bytes received 136 bytes 1554.00 bytes/sec
total size is 1810 speedup is 0.78
vozerov@mba:~/events (master *) $ ssh load.kis.im -l cloud-user
cloud-user@load:~$ cd load/
cloud-user@load:~/load$ echo "TOKEN" > token.txt
cloud-user@load:~/load$ sudo docker run -v $(pwd):/var/loadtest --net host --rm -it direvius/yandex-tank -c load.yaml ammo.txt
No handlers could be found for logger "netort.resource"
17:25:25 [INFO] New test id 2020-04-13_17-25-25.355490
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a266850> added
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a20aa50> added
17:25:25 [INFO] Created a folder for the test. /var/loadtest/logs/2020-04-13_17-25-25.355490
17:25:25 [INFO] Configuring plugins...
17:25:25 [INFO] Loading plugins...
17:25:25 [INFO] Testing connection to resolved address 104.27.164.45 and port 80
17:25:25 [INFO] Resolved events.kis.im into 104.27.164.45:80
17:25:25 [INFO] Configuring StepperWrapper...
17:25:25 [INFO] Making stpd-file: /var/loadtest/ammo.stpd
17:25:25 [INFO] Default ammo type ('phantom') used, use 'phantom.ammo_type' option to override it
... skipped ...Voilà, le processus est en cours. Dans la console, cela ressemble à quelque chose comme ceci:

Et nous attendons la fin du processus et surveillons le temps de réponse, le nombre de requêtes et, bien sûr, la mise à l'échelle automatique de notre groupe de machines virtuelles. Vous pouvez surveiller un groupe de machines virtuelles via l'interface Web, dans les paramètres d'un groupe de machines virtuelles il y a un onglet «Surveillance».
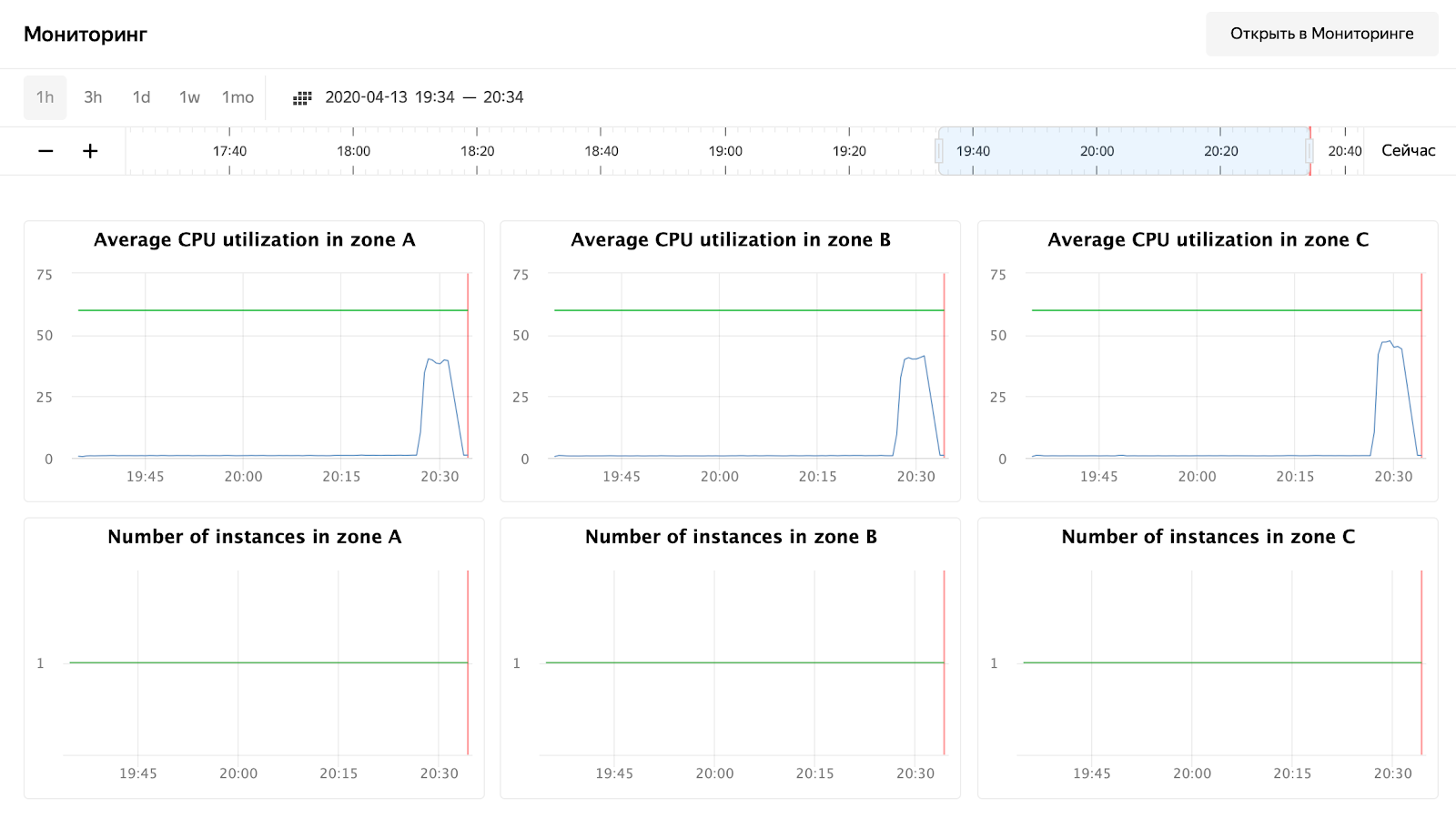
Comme vous pouvez le voir, nos nœuds n'ont pas chargé même jusqu'à 50% du processeur, le test d'autoscaling devra donc être répété. Pour l'instant, jetons un œil au temps de traitement de la requête dans Grafana:
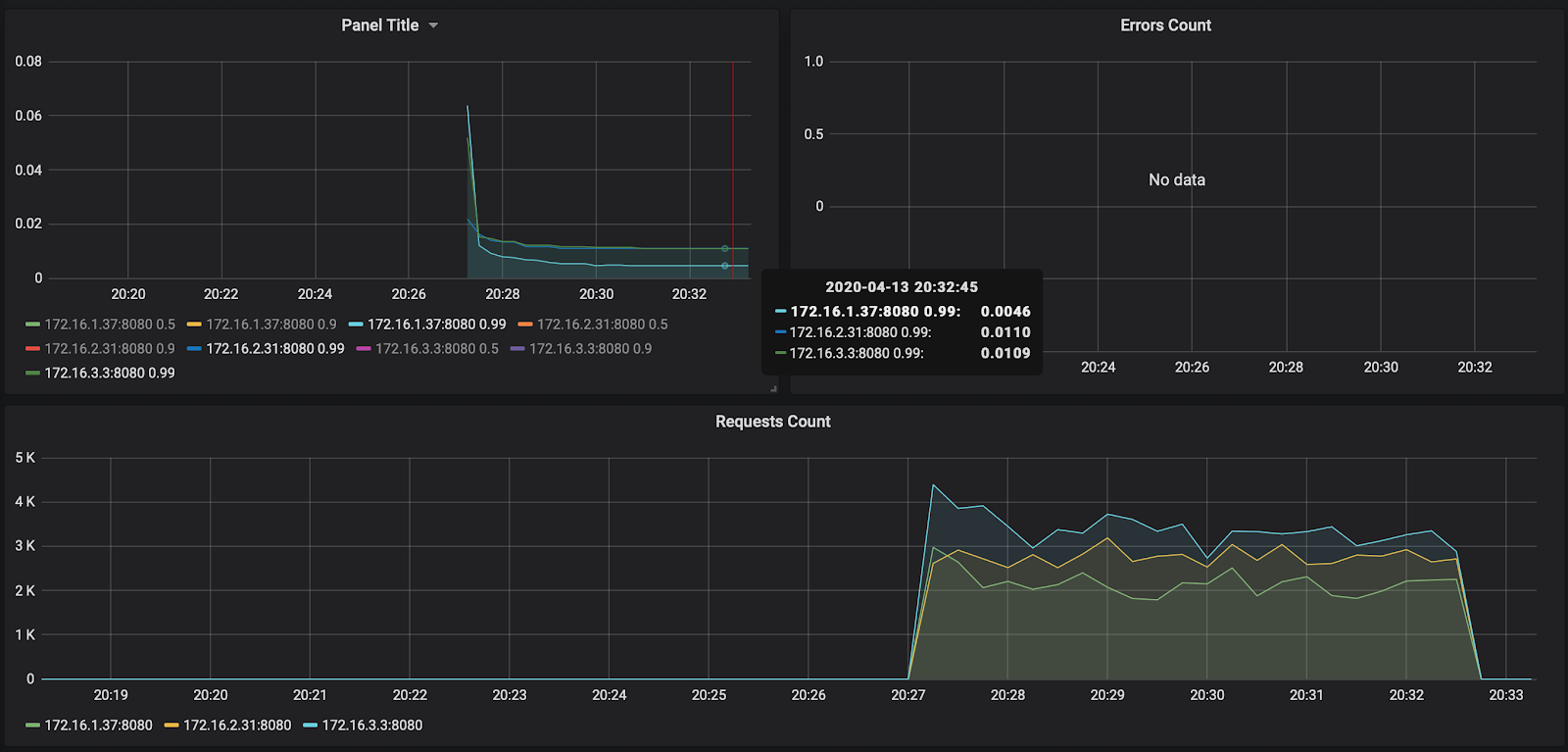
Le nombre de requêtes - environ 3000 par nœud - n'était pas un peu chargé à 10 000. Le temps de réponse plaît - environ 11 ms par requête. Le seul qui se démarque - 172.16.1.37 - a la moitié du temps pour traiter une demande. Mais c'est aussi logique - c'est dans la même zone de disponibilité ru-central1-a que kafka, qui stocke les messages.
À propos, le rapport sur le premier lancement est disponible sur le lien: https://overload.yandex.net/265967 .
Examinons donc un test plus amusant - ajoutez le paramètre instances: 2000 pour obtenir 15 000 requêtes par seconde et augmentez la durée du test à 10 minutes. Le fichier résultant ressemblera à ceci:
overload:
enabled: true
package: yandextank.plugins.DataUploader
token_file: "token.txt"
phantom:
address: 130.193.37.103
load_profile:
load_type: rps
schedule: const(15000, 10m)
instances: 2000
console:
enabled: true
telegraf:
enabled: falseLe lecteur attentif remarquera que j'ai changé l'adresse IP de l'équilibreur - cela est dû au fait que cloudflare a commencé à me bloquer pour un grand nombre de requêtes à partir d'une adresse IP. J'ai dû régler le réservoir directement sur l'équilibreur Yandex.Cloud. Après le lancement, vous pouvez observer l'image suivante:
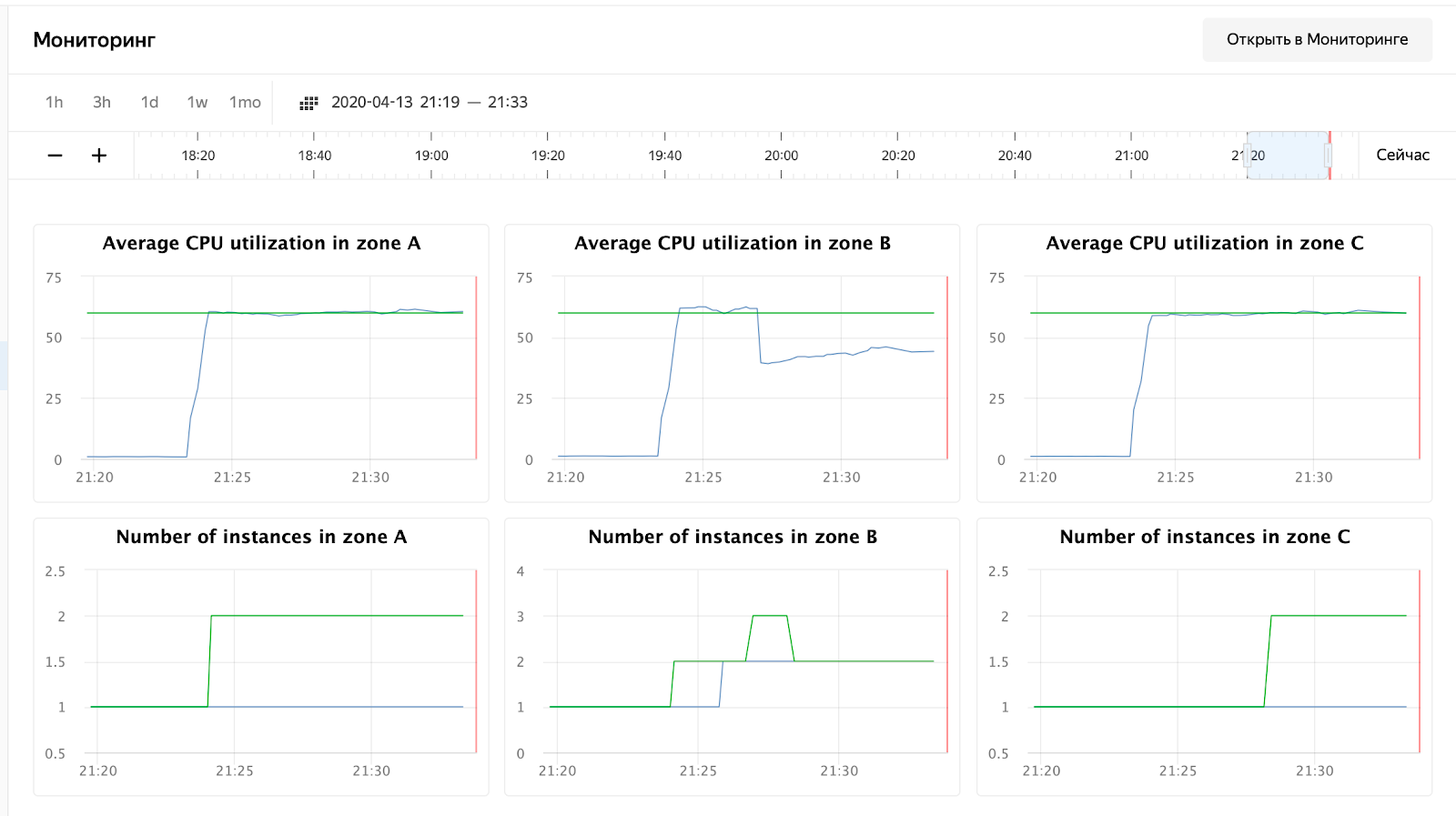
l'utilisation du processeur a augmenté et le planificateur a décidé d'augmenter le nombre de nœuds dans la zone B, ce qu'il a fait. Cela peut être vu dans les journaux du groupe d'instances:
vozerov@mba:~/events/load (master *) $ yc compute instance-group list-logs events-api-ig
2020-04-13 18:26:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 1m AWAITING_WARMUP_DURATION -> RUNNING_ACTUAL
2020-04-13 18:25:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 37s OPENING_TRAFFIC -> AWAITING_WARMUP_DURATION
2020-04-13 18:25:09 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 43s CREATING_INSTANCE -> OPENING_TRAFFIC
2020-04-13 18:24:26 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 6s DELETED -> CREATING_INSTANCE
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ozix.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-a: 1 -> 2
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-b: 1 -> 2
... skipped ...
2020-04-13 16:23:57 Balancer target group b7rhh6d4assoqrvqfr9g created
2020-04-13 16:23:43 Going to create balancer target group
Le planificateur a également décidé d'augmenter le nombre de serveurs dans d'autres zones, mais j'ai dépassé la limite des adresses IP externes :) D'ailleurs, elles peuvent être augmentées via une demande au support technique, en spécifiant les quotas et les valeurs souhaitées.
Conclusion
L'article n'a pas été facile - à la fois en volume et en quantité d'informations. Mais nous sommes passés par l'étape la plus difficile et avons fait ce qui suit:
- Surveillance accrue et kafka.
- , .
- load balancer’ cloudflare ssl .
La prochaine fois, comparons et testons le service de file d'attente rabbitmq / kafka / yandex.
Restez à l'écoute!
* Ce matériel se trouve dans l'enregistrement vidéo de l'atelier ouvert REBRAIN & Yandex.Cloud: Nous acceptons 10000 demandes par seconde sur Yandex Cloud - https://youtu.be/cZLezUm0ekE
Si vous souhaitez visiter de tels événements en ligne et poser des questions en temps réel, connectez-vous à canal DevOps par REBRAIN .
Nous tenons à remercier tout particulièrement Yandex.Cloud pour l'opportunité d'organiser un tel événement. Lien vers eux
Si vous avez besoin de passer au cloud ou avez des questions sur votre infrastructure, n'hésitez pas à laisser une demande .
PS Nous avons 2 audits gratuits par mois, peut-être que votre projet en fera partie.