 Bonjour les Habitants! Nous avons publié un guide pratique sur le traitement et la génération de textes en langage naturel. Le livre est équipé de tous les outils et techniques nécessaires pour créer des systèmes PNL appliqués afin de garantir le fonctionnement d'un assistant virtuel (chat bot), d'un filtre anti-spam, d'un programme de modérateur de forum, d'un analyseur de sentiments, d'un programme de création de base de connaissances, d'un analyseur de texte intelligent en langage naturel, ou à peu près n'importe quelle autre application PNL que vous pouvez imaginer.
Bonjour les Habitants! Nous avons publié un guide pratique sur le traitement et la génération de textes en langage naturel. Le livre est équipé de tous les outils et techniques nécessaires pour créer des systèmes PNL appliqués afin de garantir le fonctionnement d'un assistant virtuel (chat bot), d'un filtre anti-spam, d'un programme de modérateur de forum, d'un analyseur de sentiments, d'un programme de création de base de connaissances, d'un analyseur de texte intelligent en langage naturel, ou à peu près n'importe quelle autre application PNL que vous pouvez imaginer.
Le livre est destiné aux développeurs Python intermédiaires à avancés. Une partie importante du livre sera utile pour les lecteurs qui savent déjà comment concevoir et développer des systèmes complexes, car il contient de nombreux exemples de solutions recommandées et révèle les capacités des algorithmes de PNL les plus modernes. Bien que la connaissance de la programmation orientée objet en Python puisse vous aider à construire de meilleurs systèmes, il n'est pas nécessaire d'utiliser les informations de ce livre.
Que trouverez-vous dans le livre
I . , . , , , , , . -, , 2–4, . , 90%- 1990- — .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
Réseaux de neurones à rétroaction: réseaux de neurones récurrents
Le chapitre 7 démontre les possibilités d'analyser un fragment ou une phrase entière à l'aide d'un réseau neuronal convolutif, en suivant les mots adjacents dans une phrase en leur appliquant un filtre de poids partagé (effectuant une convolution). Les mots apparaissant en groupes peuvent également être trouvés dans un paquet. La toile résiste également aux petits changements de position de ces mots. Dans le même temps, les concepts adjacents peuvent affecter considérablement le réseau. Mais si vous avez besoin d'avoir une vue d'ensemble de ce qui se passe, de prendre en compte les relations sur une plus longue période de temps, une fenêtre couvrant plus de 3-4 jetons de l'offre? Comment introduire le concept d'événements passés dans le réseau? Mémoire?
Pour chaque exemple d'apprentissage (ou lot d'exemples désordonnés) et sortie (ou lot de sorties) du réseau neuronal à anticipation, les poids du réseau neuronal doivent être ajustés pour les neurones individuels en fonction de la méthode de rétropropagation. Nous l'avons déjà démontré. Mais les résultats de la phase d'apprentissage pour l'exemple suivant sont pour la plupart indépendants de l'ordre des données d'entrée. Les réseaux de neurones convolutifs cherchent à capturer ces relations d'ordre en capturant les relations locales, mais il existe un autre moyen.
Dans un réseau neuronal convolutif, chaque exemple d'apprentissage est transmis au réseau sous la forme d'un ensemble groupé de jetons de mots. Les vecteurs de mots sont regroupés dans une matrice sous la forme (longueur du vecteur de mots × nombre de mots dans l'exemple), comme le montre la Fig. 8.1.

Mais cette séquence de vecteurs de mots peut être tout aussi facilement transmise au réseau neuronal normal à anticipation du chapitre 5 (figure 8.2), n'est-ce pas?
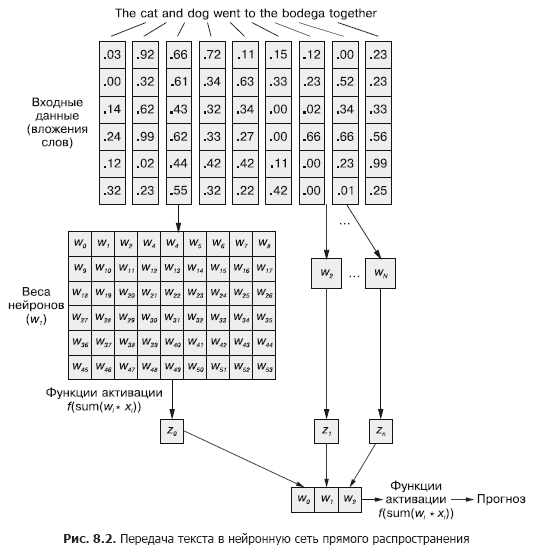
Bien sûr, c'est un modèle parfaitement réalisable. Avec cette méthode de transfert de données d'entrée, le réseau de neurones par anticipation sera en mesure de répondre aux occurrences conjointes de jetons, ce dont nous avons besoin. Mais en même temps, il réagira à toutes les occurrences conjointes de la même manière, qu'elles soient séparées par un long texte ou qu'elles soient côte à côte. En outre, les réseaux de neurones à réaction, comme les CNN, sont médiocres pour gérer les documents de longueur variable. Ils ne peuvent pas traiter le texte à la fin du document s'il dépasse la largeur du Web.
Les réseaux de neurones à feedforward fonctionnent le mieux dans la modélisation de la relation d'un échantillon de données dans son ensemble avec son étiquette correspondante. Les mots au début et à la fin d'une phrase ont le même effet sur le signal de sortie qu'au milieu, malgré le fait qu'il est peu probable qu'ils soient sémantiquement liés les uns aux autres.
Une telle uniformité (uniformité de l'influence) peut clairement poser des problèmes dans le cas, par exemple, de jetons de négation sévères et de modificateurs (adjectifs et adverbes) tels que "non" ou "bon". Dans un réseau de neurones à réaction directe, les mots de négation affectent le sens de tous les mots d'une phrase, même s'ils sont très éloignés de l'endroit où ils devraient réellement influencer.
Les convolutions unidimensionnelles sont un moyen de résoudre ces relations entre les jetons en analysant plusieurs mots dans les fenêtres. Les couches de sous-échantillonnage décrites au chapitre 7 sont spécifiquement conçues pour s'adapter à de petits changements dans l'ordre des mots. Dans ce chapitre, nous examinerons une autre approche qui nous aidera à faire le premier pas vers le concept de mémoire de réseau neuronal. Au lieu de désassembler un langage comme un gros morceau de données, nous allons commencer à regarder sa formation séquentielle, jeton par jeton, au fil du temps.
8.1. Mémorisation dans les réseaux de neurones
Bien entendu, les mots d'une phrase sont rarement complètement indépendants les uns des autres; leurs occurrences sont influencées ou influencées par les occurrences d'autres mots dans le document. Par exemple: la voiture volée est entrée dans l'arène et la voiture de clown a filé dans l'arène.
Vous pouvez avoir des impressions complètement différentes des deux phrases lorsque vous lisez jusqu'à la fin. La construction de la phrase en eux est la même: adjectif, nom, verbe et phrase prépositionnelle. Mais le remplacement de l'adjectif en eux change radicalement l'essence de ce qui se passe du point de vue du lecteur.
Comment simuler une telle relation? Comment comprendre que l'arène et même la vitesse peuvent avoir des connotations légèrement différentes s'il y a un adjectif devant eux dans la phrase qui n'est une définition directe d'aucune d'entre elles?
S'il y avait un moyen de se souvenir de ce qui s'est passé un instant plus tôt (surtout de se souvenir de ce qui s'est passé à l'étape t à l'étape t + 1), il serait possible d'identifier des modèles qui surviennent lorsque certains jetons apparaissent dans une séquence de modèles associés à d'autres jetons. Les réseaux de neurones récurrents (RNN) permettent à un réseau de neurones de mémoriser les mots passés d'une séquence.
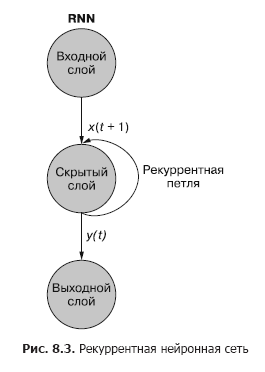
Comme vous pouvez le voir sur la fig. 8.3, un neurone récurrent séparé de la couche cachée ajoute une boucle récurrente au réseau pour "réutiliser" la sortie de la couche cachée au temps t. La sortie au temps t est ajoutée à l'entrée suivante au temps t + 1. Le réseau traite cette nouvelle entrée au pas de temps t + 1 pour produire une sortie de couche cachée au temps t + 1. Cette sortie au temps t + 1 puis il est réutilisé par le réseau et inclus dans le signal d'entrée à un pas de temps t + 2, etc.
Alors que l'idée d'influencer un État à travers le temps semble un peu déroutante, le concept de base est simple. Les résultats de chaque signal à l'entrée d'un réseau neuronal conventionnel à anticipation à un pas de temps t sont utilisés comme signal d'entrée supplémentaire avec la prochaine donnée fournie à l'entrée du réseau à un pas de temps t + 1. Le réseau reçoit des informations non seulement sur ce qui se passe maintenant, mais aussi sur ce qui s'est passé auparavant. ...
. , . , . , . , . , , . . , .
t . , t = 0 — , t + 1 — . () . , . — .
t, — t + 1.
Un réseau neuronal récurrent peut être visualisé comme le montre la Fig. 8.3: Les cercles correspondent à des couches entières d'un réseau de neurones à anticipation, constitué d'un ou plusieurs neurones. La sortie de la couche cachée est fournie par le réseau comme d'habitude, mais revient ensuite comme sa propre entrée (couche cachée) avec les données d'entrée habituelles du pas de temps suivant. Dans le diagramme, cette boucle de rétroaction est représentée comme un arc menant de la sortie de la couche à l'entrée.
Un moyen plus simple (et plus couramment utilisé) d'illustrer ce processus consiste à utiliser le déploiement réseau. La figure 8.4 montre un réseau à l'envers avec deux balayages de la variable de temps (t) - couches pour les étapes t + 1 et t + 2.
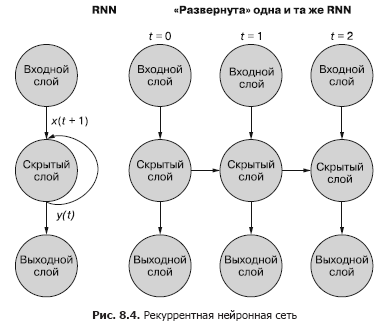
Chacun des pas de temps correspond à une version étendue du même réseau de neurones sous la forme d'une colonne de neurones. C'est comme regarder un script ou des images vidéo individuelles d'un réseau neuronal à un moment donné. Le réseau de droite représente une future version du réseau de gauche. Le signal de sortie de la couche cachée au temps (t) est renvoyé à l'entrée de la couche cachée avec les données d'entrée pour le pas de temps suivant (t + 1) sur la droite. Encore une fois. Le diagramme montre deux itérations de ce déploiement, un total de trois colonnes de neurones pour t = 0, t = 1 et t = 2.
Toutes les routes verticales de ce diagramme sont complètement analogues, elles montrent les mêmes neurones. Ils reflètent le même réseau neuronal à différents moments. Cette visualisation est utile pour démontrer le mouvement vers l'avant et vers l'arrière des informations sur le réseau lors de la propagation arrière d'une erreur. Mais rappelez-vous lorsque vous regardez ces trois réseaux déployés: ce sont des instantanés différents du même réseau avec le même ensemble de pondérations.
Examinons de plus près la représentation originale du réseau de neurones récurrent avant de le déployer et montrons la relation entre les signaux d'entrée et les poids. Les couches individuelles de ce RNN ressemblent à celles illustrées à la Fig. 8.5 et 8.6.

Tous les neurones à l'état latent ont un ensemble de poids appliqués à chacun des éléments de chacun des vecteurs d'entrée, comme dans un réseau d'anticipation classique. Mais dans ce schéma, un ensemble supplémentaire de poids entraînables est apparu, qui sont appliqués aux signaux de sortie des neurones cachés du pas de temps précédent. Le réseau, par formation, sélectionne les pondérations appropriées (importance) des événements précédents lors de la saisie de la séquence jeton par jeton.
«», t = 0 t – 1. «» , , . t = 0 . , .
Revenons aux données, imaginez que vous avez un ensemble de documents, dont chacun est un exemple étiqueté. Et au lieu de transmettre l'ensemble des vecteurs de mots au réseau de neurones convolutifs pour chaque échantillon, comme dans le chapitre précédent (Figure 8.7), nous transférons les données de l'échantillon au RNN, un jeton à la fois (Figure 8.8).

Nous passons un vecteur de mots pour le premier jeton et obtenons la sortie de notre réseau de neurones récurrent. Ensuite, nous transférons le deuxième jeton, et avec lui le signal de sortie du premier! Après cela, nous transférons le troisième jeton avec le signal de sortie du deuxième! Etc. Maintenant, dans notre réseau de neurones, il y a des concepts «avant» et «après», de cause à effet, une certaine notion, quoique vague, de temps (voir Fig. 8.8).
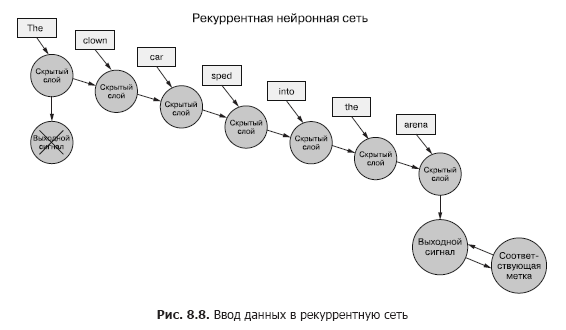
Maintenant, notre réseau se souvient déjà de quelque chose! Eh bien, dans une certaine mesure. Il reste encore quelques choses à résoudre. Premièrement, comment la rétro-propagation d'une erreur peut-elle se produire dans une telle structure?
8.1.1. Rétro propagation d'une erreur dans le temps
Tous les réseaux discutés ci-dessus ont eu l'étiquette cible (variable cible), et RNN ne fait pas exception. Mais nous n'avons pas le concept d'étiquette pour chaque jeton, mais il n'y a qu'une seule étiquette pour tous les jetons pour chacun des exemples de texte. Nous n'avons que des étiquettes pour les exemples de documents.
Nous parlons de jetons comme entrée du réseau à chaque pas de temps, mais les réseaux de neurones récurrents peuvent également fonctionner avec toutes les données de séries temporelles. Les jetons peuvent être quelconques, discrets ou continus: relevés de stations météorologiques, notes, symboles dans une phrase, etc.
Ici, nous comparons d'abord la sortie du réseau au dernier pas de temps avec le repère. C'est ce que nous appellerons (pour l'instant) une erreur, à savoir que notre réseau essaie de la minimiser. Mais il y a une légère différence avec les chapitres précédents. Un échantillon donné de données est divisé en morceaux plus petits qui sont introduits dans le réseau neuronal de manière séquentielle. Cependant, au lieu d'utiliser directement la sortie de chacun de ces sous-exemples, nous la renvoyons au réseau.
Jusqu'à présent, nous ne nous intéressons qu'au signal de sortie final. Chacun des jetons de la séquence est introduit dans le réseau et les pertes sont calculées en fonction de la sortie du dernier pas de temps (jeton) (Figure 8.9).
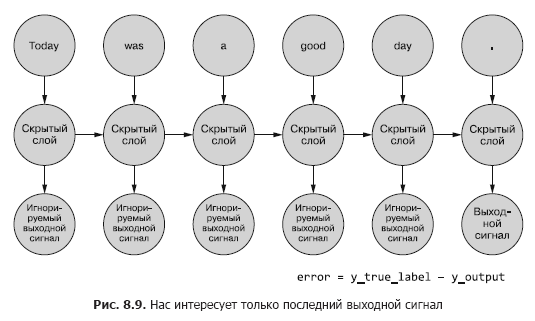
Il est nécessaire de déterminer, s'il y a une erreur pour un exemple donné, quels poids mettre à jour et combien. Dans le chapitre 5, nous vous avons montré comment rétropropropager une erreur sur un réseau normal. Et nous savons que le montant de la correction de poids dépend de sa contribution (de ce poids) à l'erreur. Nous pouvons appliquer un jeton d'une séquence d'échantillons à l'entrée du réseau, en calculant l'erreur pour le pas de temps précédent en fonction de son signal de sortie. C'est là que l'idée de rétropropagation d'une erreur dans le temps semble tout confondre.
Cependant, on peut simplement le considérer comme un processus limité dans le temps. À chaque pas de temps, les jetons, en commençant par le premier à t = 0, sont alimentés un par un à l'entrée du neurone caché situé en face - la colonne suivante de la Fig. 8.9. Dans le même temps, le réseau se développe, révélant la colonne suivante du réseau, déjà prête à recevoir le jeton suivant de la séquence. Les neurones latents se déploient un par un, comme une boîte à musique ou un piano mécanique. Au final, lorsque tous les éléments des exemples seront introduits dans le réseau, il n'y aura plus rien à déployer et nous obtiendrons l'étiquette finale de la variable cible qui nous intéresse, qui peut être utilisée pour calculer l'erreur et ajuster les poids. Nous venons de parcourir le graphe de calcul pour ce réseau déroulé.
Pour l'instant, nous considérons que les données d'entrée sont généralement statiques. Vous pouvez tracer à travers tout le graphique quel signal d'entrée va à quel neurone. Et puisque nous savons comment fonctionne quel neurone, nous pouvons propager l'erreur le long de la chaîne, le long du même chemin, comme dans le cas d'un réseau de neurones conventionnel.
Pour propager l'erreur à la couche précédente, nous utiliserons la règle de chaîne. Au lieu de la couche précédente, nous propagerons l'erreur à la même couche dans le passé, comme si toutes les variantes de réseau déployées étaient différentes (Figure 8.10). Cela ne change pas les mathématiques de calcul.

L'erreur se propage à partir de la dernière étape. Le gradient d'un pas de temps antérieur par rapport à un plus récent est calculé. Après avoir calculé tous les gradients individuels sur les jetons, jusqu'à l'étape t = 0 pour cet exemple, les modifications sont agrégées et appliquées à un ensemble de poids.
8.1.2. Quand mettre à jour quoi
Nous avons transformé notre étrange RNN en quelque chose comme un réseau neuronal normal, donc la mise à jour des poids ne devrait pas être trop difficile. Cependant, il y a une mise en garde. L'astuce est que les poids ne sont pas du tout mis à jour dans une autre branche du réseau neuronal. Chaque branche représente le même réseau à des moments différents. Les poids pour chaque pas de temps sont les mêmes (voir Figure 8.10).
Une solution simple à ce problème consiste à calculer les corrections des pondérations à chacun des pas de temps avec un retard dans la mise à jour. Dans un réseau à anticipation, toutes les mises à jour des poids sont calculées dès que tous les gradients sont calculés pour un signal d'entrée particulier. Et ici, c'est exactement la même chose, mais les mises à jour sont différées jusqu'à ce que nous arrivions au pas de temps initial (zéro) pour un échantillon de données d'entrée spécifique.
Le calcul du gradient doit être basé sur les valeurs des poids auxquels ils ont contribué à l'erreur. Voici la partie la plus écrasante: le poids au pas de temps t a contribué d'une manière ou d'une autre à l'erreur. Et le même poids reçoit un signal d'entrée différent au pas de temps t + 1, ce qui signifie qu'il apporte une contribution différente à l'erreur.
Vous pouvez calculer les différentes modifications des pondérations à chaque pas de temps, les additionner, puis appliquer les modifications groupées aux pondérations de la couche masquée lors de la dernière étape de la phase d'apprentissage.
, . , , . , , . , .
De la vraie magie. Dans le cas de la propagation vers l'arrière de l'erreur dans le temps, un poids individuel peut être corrigé dans un sens à un pas de temps t (en fonction de sa réponse au signal d'entrée à un pas de temps t), puis dans l'autre sens à un pas de temps t - 1 (conformément à comment il a réagi au signal d'entrée au pas de temps t - 1) pour un échantillon de données! N'oubliez pas que les réseaux de neurones en général sont basés sur la minimisation de la fonction de perte quelle que soit la complexité des étapes intermédiaires. Collectivement, le réseau optimise cette fonctionnalité complexe. Puisque la mise à jour de poids n'est appliquée qu'une seule fois pour les données d'exemple, le réseau (s'il converge, bien sûr) s'arrête finalement au poids le plus optimal dans ce sens pour un signal d'entrée spécifique et un neurone spécifique.
Les résultats des étapes précédentes sont toujours importants
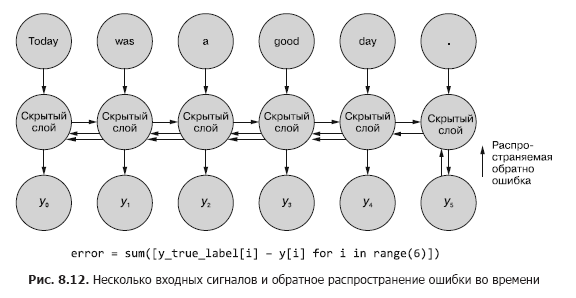
Parfois, toute la séquence de valeurs générées à tous les pas de temps intermédiaires est importante. Dans le chapitre 9, nous donnerons des exemples de situations dans lesquelles la sortie d'un pas de temps particulier, t, est tout aussi importante que la sortie du dernier pas de temps. En figue. 8.11 montre une méthode pour collecter les données d'erreur pour n'importe quel pas de temps et les propager à nouveau pour corriger tous les poids du réseau.

Ce processus ressemble à la rétro-propagation habituelle d'une erreur dans le temps pendant n pas de temps. Dans ce cas, nous propageons le bogue à partir de plusieurs sources en même temps. Mais, comme dans le premier exemple, les ajustements des poids sont additifs. L'erreur se propage du dernier pas de temps au début au premier avec la somme des changements dans chacun des poids. Ensuite, la même chose se produit avec l'erreur calculée à l'avant-dernier pas de temps, additionnant tous les changements jusqu'à t = 0. Ce processus est répété jusqu'à ce que nous atteignions le pas de temps zéro avec une rétro-propagation de l'erreur pour elle comme si c'était la seule. Ensuite, les modifications cumulatives sont appliquées en une seule fois au calque masqué correspondant.
En figue. La Figure 8.12 montre comment l'erreur se propage depuis chaque signal de sortie jusqu'à t = 0, puis est agrégée avant la correction finale des poids. C'est l'idée principale de cette section. Comme dans le cas d'un réseau de neurones à anticipation classique, les poids sont mis à jour uniquement après avoir calculé le changement de poids proposé pour toute l'étape de rétropropagation pour un signal d'entrée donné (ou un ensemble de signaux d'entrée). Dans le cas de RNN, la rétro-propagation de l'erreur comprend des mises à jour jusqu'à l'instant t = 0.
La mise à jour des poids plus tôt aurait faussé les calculs de gradient avec des erreurs de rétro-propagation à des moments antérieurs. N'oubliez pas que les dégradés sont calculés par rapport à un poids spécifique. Si ce poids est mis à jour trop tôt, disons au pas de temps t, alors lors du calcul du gradient au pas de temps t - 1, la valeur du poids (rappelons qu'il s'agit de la même position du poids dans le réseau) changera. Et lors du calcul du gradient basé sur le signal d'entrée du pas de temps t - 1, les calculs seront déformés. En fait, dans ce cas, le poids sera condamné à une amende (ou récompensé) pour ce qui n'est "pas à blâmer"!
À propos des auteurs
Hobson Lane(Hobson Lane) a 20 ans d'expérience dans la construction de systèmes autonomes qui prennent des décisions critiques au profit des gens. Chez Talentpair, Hobson a appris aux machines à lire et à comprendre les curriculum vitae d'une manière moins biaisée que la plupart des responsables du recrutement. Chez Aira, il a aidé à construire leur premier chatbot conçu pour interpréter le monde autour des aveugles. Hobson est un admirateur passionné de l'ouverture d'IA et de l'orientation communautaire. Il contribue activement à des projets open source tels que Keras, scikit-learn, PyBrain, PUGNLP et ChatterBot. Il est actuellement impliqué dans la recherche ouverte et des projets éducatifs pour Total Good, y compris la création d'un assistant virtuel open source. Il a publié de nombreux articles, a donné des conférences à l'AIAA, PyCon,PAIS et IEEE et a obtenu plusieurs brevets dans le domaine de la robotique et de l'automatisation.
Hannes Max Hapke est un ingénieur électricien devenu ingénieur en apprentissage automatique. Au lycée, il s'est intéressé aux réseaux de neurones lorsqu'il a étudié les moyens de calculer des réseaux de neurones sur des microcontrôleurs. Plus tard à l'université, il a appliqué les principes des réseaux neuronaux à la gestion efficace des centrales à énergie renouvelable. Hannes est passionné par l'automatisation du développement de logiciels et des pipelines d'apprentissage automatique. Il a co-écrit des modèles d'apprentissage en profondeur et des pipelines d'apprentissage automatique pour les secteurs du recrutement, de l'énergie et de la santé. Hannes a donné des présentations sur l'apprentissage automatique lors de diverses conférences, notamment OSCON, Open Source Bridge et Hack University.
Cole Howard(Cole Howard) est un praticien de l'apprentissage automatique, un praticien de la PNL et un écrivain. Chercheur éternel de modèles, il s'est retrouvé dans le monde des réseaux de neurones artificiels. Parmi ses développements figurent des systèmes de recommandation à grande échelle pour le trading sur Internet et des réseaux de neurones avancés pour des systèmes d'intelligence artificielle ultra-dimensionnels (réseaux de neurones profonds), qui sont classés au premier rang des compétitions Kaggle. Il a donné des conférences sur les réseaux de neurones convolutifs, les réseaux de neurones récurrents et leur rôle dans le traitement du langage naturel lors des conférences Open Source Bridge et Hack University.
À propos de l'illustration de la couverture
« -, ». (Balthasar Hacquet) Images and Descriptions of Southwestern and Eastern Wends, Illyrians and Slavs (« - , »), () 2008 . (1739–1815) — , , — , - . .
200 . , , . , . , .
200 . , , . , . , .
»Plus de détails sur le livre peuvent être trouvés sur le site de la maison d'édition
» Table des matières
» Extrait
Pour Habitants un rabais de 25% sur le coupon - PNL
Lors du paiement de la version papier du livre, un e-book est envoyé à l'e-mail.