
Au cours des trois dernières années, Nvidia a créé des puces graphiques dans lesquelles, en plus des cœurs habituels utilisés pour les shaders, d'autres sont installés. Ces cœurs, appelés cœurs tensoriels, se trouvent déjà dans des milliers d'ordinateurs de bureau, d'ordinateurs portables, de stations de travail et de centres de données à travers le monde. Mais que font-ils et à quoi servent-ils? Sont-ils même nécessaires dans les cartes graphiques?
Aujourd'hui, nous allons expliquer ce qu'est un tenseur et comment les noyaux tensoriels sont utilisés dans le monde du graphisme et du deep learning.
Une petite leçon de mathématiques
Pour comprendre ce que font les noyaux tensoriels et à quoi ils peuvent être utilisés, nous commençons par comprendre ce que sont les tenseurs. Tous les microprocesseurs, quelle que soit la tâche qu'ils exécutent, effectuent des opérations mathématiques sur les nombres (addition, multiplication, etc.).
Parfois, ces nombres doivent être regroupés car ils ont une certaine signification les uns pour les autres. Par exemple, lorsque la puce traite des données pour rendre des graphiques, elle peut traiter des valeurs entières uniques (par exemple, +2 ou +115) comme facteur de mise à l'échelle, ou un groupe de flottants (+0,1, -0,5, +0,6) comme un coordonnées d'un point dans l'espace 3D. Dans le second cas, les trois éléments de données sont nécessaires pour la position du point.
TenseurEst un objet mathématique qui décrit les relations entre d'autres objets mathématiques liés les uns aux autres. Ils sont généralement affichés sous forme de tableau de nombres dont les dimensions sont indiquées ci-dessous.

Le type de tenseur le plus simple a une dimension zéro et se compose d'une seule valeur; sinon, on l'appelle un scalaire . À mesure que le nombre de dimensions augmente, nous rencontrons d'autres structures mathématiques courantes:
- 1 dimension = vecteur
- 2 dimensions = matrice
À proprement parler, un scalaire est un tenseur 0 x 0, un vecteur est 1 x 0 et une matrice est 1 x 1, mais par souci de simplicité et de référence aux noyaux tensoriels du GPU, nous ne considérerons les tenseurs que sous forme de matrices.
L'une des opérations mathématiques les plus importantes effectuées sur les matrices est la multiplication (ou produit). Voyons comment deux matrices avec quatre lignes et colonnes de données sont multipliées l'une par l'autre:
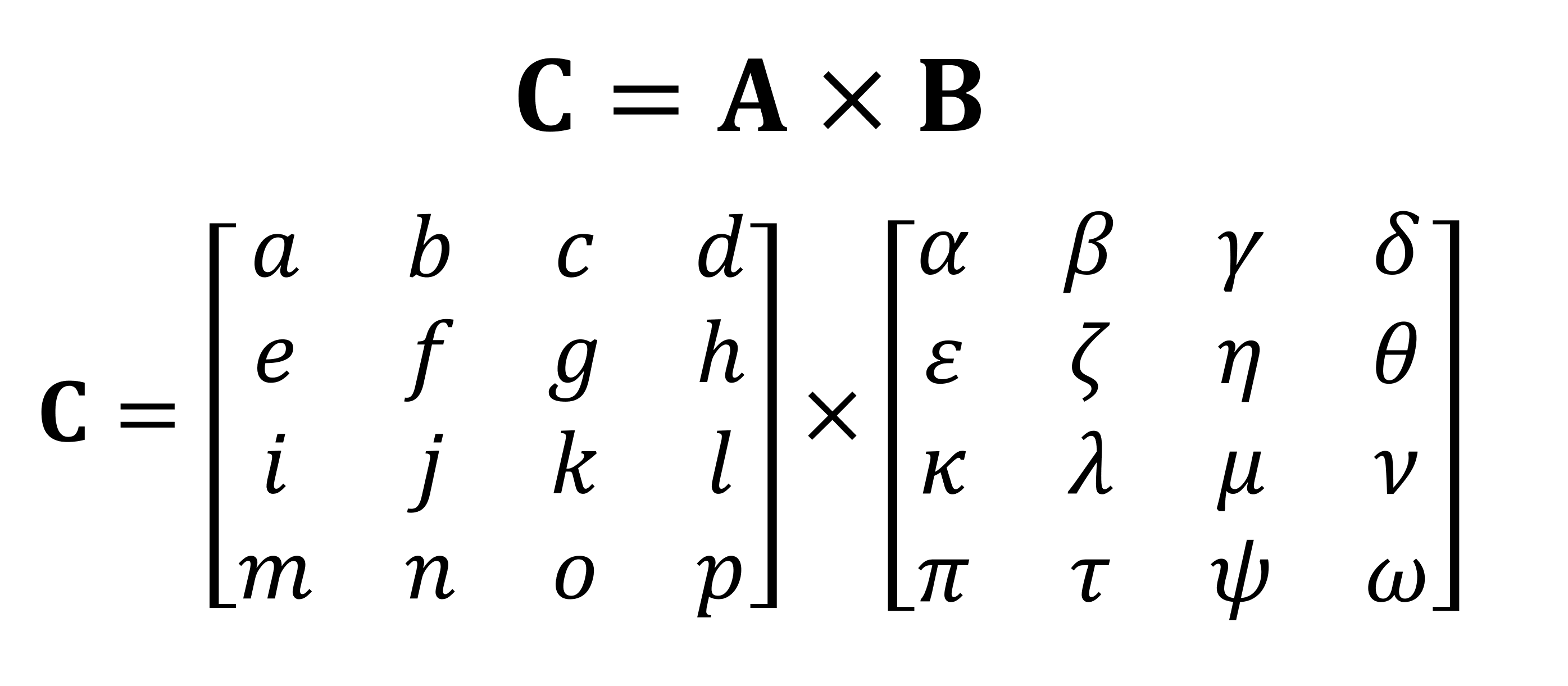
Le résultat final de la multiplication sera toujours le même nombre de lignes que dans la première matrice et le même nombre de colonnes que dans la seconde. Comment multipliez-vous ces deux tableaux? Comme ça:
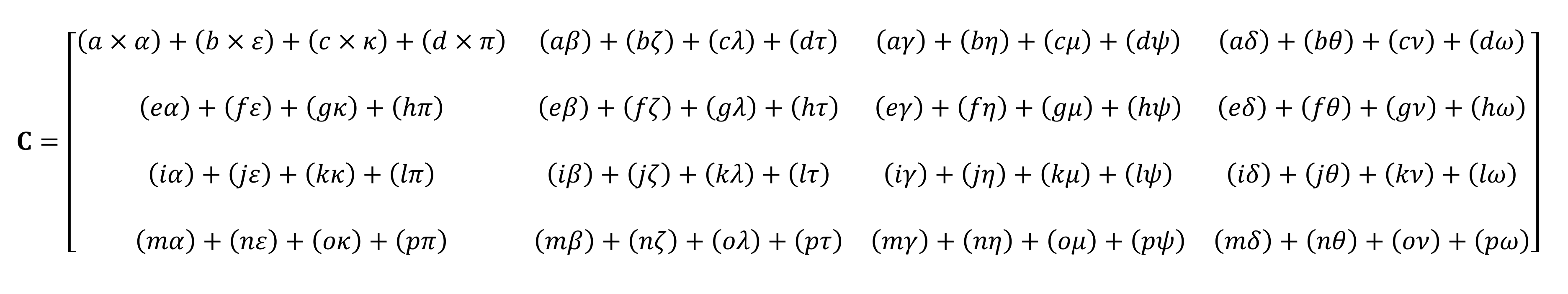
Il ne sera pas possible de le calculer sur les doigts
Comme vous pouvez le voir, le calcul du produit "simple" de matrices consiste en tout un tas de petites multiplications et additions. Étant donné que toute unité centrale moderne peut effectuer ces deux opérations, les tenseurs les plus simples peuvent être effectués par chaque ordinateur de bureau, ordinateur portable ou tablette.
Cependant, l'exemple ci-dessus contient 64 multiplications et 48 additions; chaque petit produit donne une valeur qui doit être stockée quelque part avant de pouvoir être ajoutée aux trois autres petits produits afin que la valeur tenseur finale puisse être stockée plus tard. Par conséquent, malgré la simplicité mathématique des multiplications matricielles, elles sont coûteuses en calcul . - il est nécessaire d'utiliser beaucoup de registres, et le cache doit être capable de faire face à un tas d'opérations de lecture et d'écriture.

Architecture Intel Sandy Bridge, qui a introduit pour la première fois les extensions AVX
Au fil des ans, les processeurs AMD et Intel ont eu diverses extensions (MMX, SSE et maintenant AVX - qui sont toutes SIMD, données multiples à instruction unique ), permettant au processeur de traiter simultanément de nombreux nombres point flottant; c'est exactement ce qui est requis pour la multiplication matricielle.
Mais il existe un type spécial de processeur spécialement conçu pour gérer les opérations SIMD: l'unité de traitement graphique (GPU).
Plus intelligent qu'une calculatrice ordinaire?
Dans le monde du graphisme, il est nécessaire de transmettre et de traiter simultanément d'énormes quantités d'informations sous forme de vecteurs. En raison de leur capacité de traitement parallèle, les GPU sont idéaux pour le traitement des tenseurs; tous les GPU modernes prennent en charge une fonctionnalité appelée GEMM ( General Matrix Multiplication ).
Il s'agit d'une opération "collée" dans laquelle deux matrices sont multipliées et le résultat est ensuite accumulé avec une autre matrice. Il existe des restrictions importantes sur le format des matrices, et elles sont toutes liées au nombre de lignes et de colonnes de chaque matrice.

Conditions requises pour les lignes et colonnes GEMM: matrice A (mxk), matrice B (kxn), matrice C (mxn)
Les algorithmes utilisés pour effectuer des opérations sur les matrices fonctionnent généralement mieux lorsque les matrices sont carrées (par exemple, un tableau 10 x 10 fonctionnera mieux que 50 x 2) et plutôt de petite taille. Mais ils seront toujours plus performants s'ils sont traités sur des équipements exclusivement conçus pour de telles opérations.
En décembre 2017, Nvidia a sorti une carte graphique avec un GPU doté de la nouvelle architecture Volta . Elle était destinée aux marchés professionnels, donc cette puce n'était pas utilisée dans les modèles GeForce. Il était unique car il est devenu le premier GPU avec des cœurs uniquement pour effectuer des calculs de tenseurs.

Une carte graphique Nvidia Titan V avec une puce GV100 Volta. Oui, vous pouvez exécuter Crysis dessus Les
cœurs de tenseur de Nvidia ont été conçus pour exécuter 64 GEMM par cycle d'horloge avec des matrices 4 x 4 contenant des valeurs FP16 (nombres à virgule flottante de 16 bits) ou une multiplication FP16 avec addition FP32. Ces tenseurs sont de très petite taille, donc lors du traitement d'ensembles réels de données, les noyaux traitent de petites parties de grandes matrices, construisant la réponse finale.
Moins d'un an plus tard, Nvidia a publié l'architecture Turing . Cette fois, des cœurs tenseurs ont également été installés dans le modèle GeForceniveau du consommateur. Le système a été amélioré pour prendre en charge d'autres formats de données, tels que INT8 (valeur entière de 8 bits), mais sinon, ils fonctionnaient de la même manière que dans Volta.

Plus tôt cette année, l'architecture Ampere a fait ses débuts dans le GPU du centre de données A100 , et cette fois Nvidia a amélioré les performances (256 GEMM par cycle au lieu de 64), ajouté de nouveaux formats de données et la possibilité de traiter très rapidement des tenseur épars (matrices avec zéros).
Les programmeurs peuvent accéder très facilement aux cœurs de tenseur des puces Volta, Turing et Ampère: le code doit simplement utiliser un indicateur indiquant à l'API et aux pilotes d'utiliser des cœurs de tenseur, le type de données doit être pris en charge par les cœurs et les dimensions de la matrice doivent être des multiples de 8. Lors de l'exécution Toutes ces conditions seront prises en charge par l'équipement.
C'est génial, mais à quel point les cœurs Tensor sont-ils meilleurs pour traiter le GEMM que les cœurs GPU ordinaires?
Lorsque la Volta est sortie, Anandtech a effectué des tests de mathématiques sur trois cartes Nvidia: la nouvelle Volta, la plus puissante de la gamme Pascal, et l'ancienne carte Maxwell.
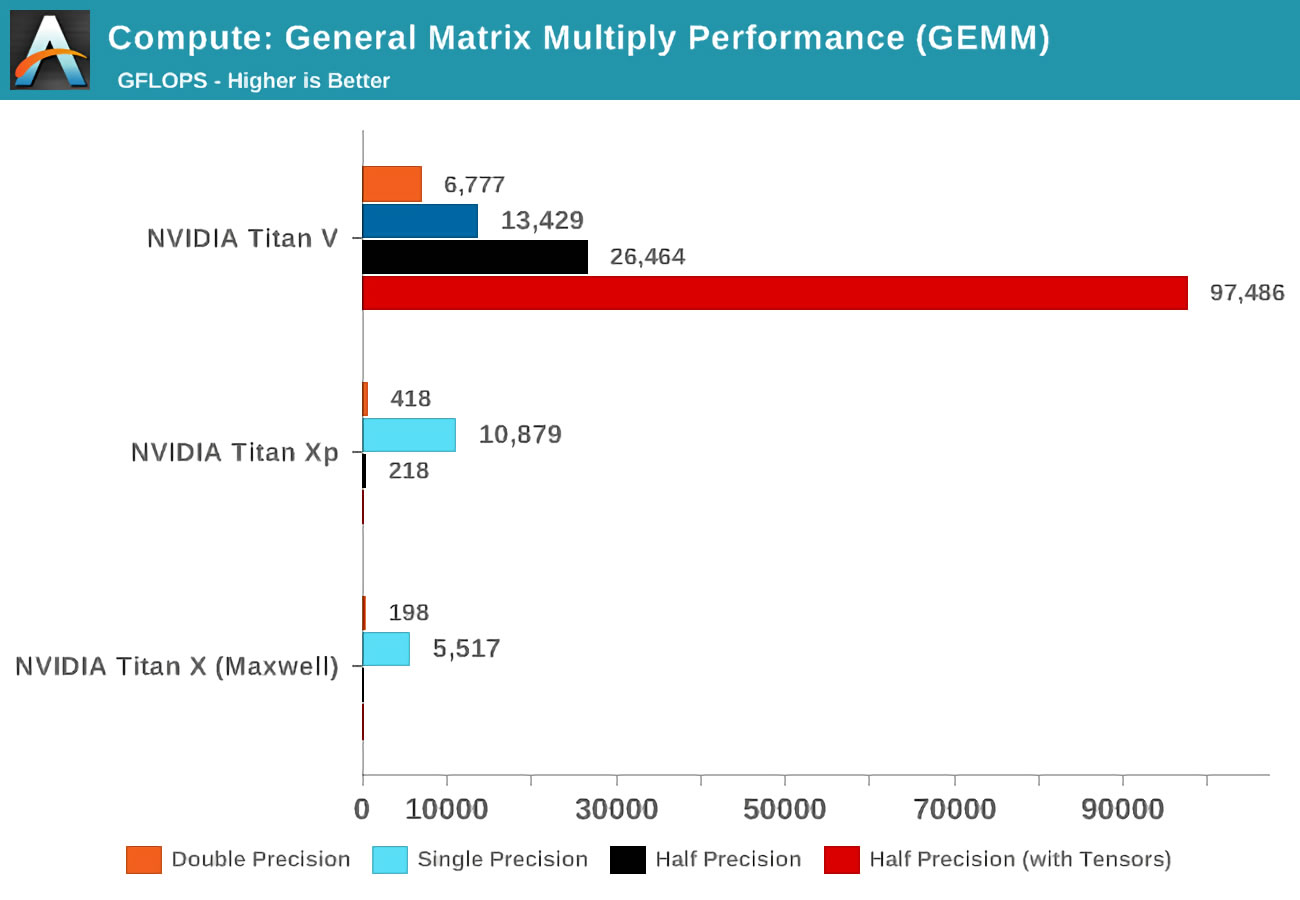
Le concept de précision (précision) fait référence au nombre de bits utilisés pour les nombres à virgule flottante dans les matrices: double (double) désigne 64, un simple (simple) - 32, et ainsi de suite. L'axe horizontal est le nombre maximum d'opérations en virgule flottante effectuées par seconde, ou FLOP en abrégé (rappelez-vous qu'un GEMM correspond à 3 FLOP).
Jetez un œil aux résultats lorsque vous utilisez des noyaux tensoriels au lieu des noyaux CUDA! Évidemment, ils sont incroyables dans ce métier, mais que pouvons-nous faire avec les noyaux tensoriels?
Les maths qui améliorent tout
Le calcul tensoriel est extrêmement utile en physique et en ingénierie, il est utilisé pour résoudre toutes sortes de problèmes complexes en mécanique des fluides , électromagnétisme et astrophysique , mais les ordinateurs utilisés pour traiter ces nombres effectuaient généralement des opérations matricielles dans de grands groupes à partir d'unités centrales de traitement.
Un autre domaine dans lequel les tenseurs sont populaires est l'apprentissage automatique , en particulier sa sous-section «apprentissage en profondeur». Sa signification se résume au traitement d'énormes ensembles de données dans des tableaux géants appelés réseaux de neurones . Les connexions entre différentes valeurs de données se voient attribuer un certain poids - un nombre qui exprime l'importance d'une connexion particulière.
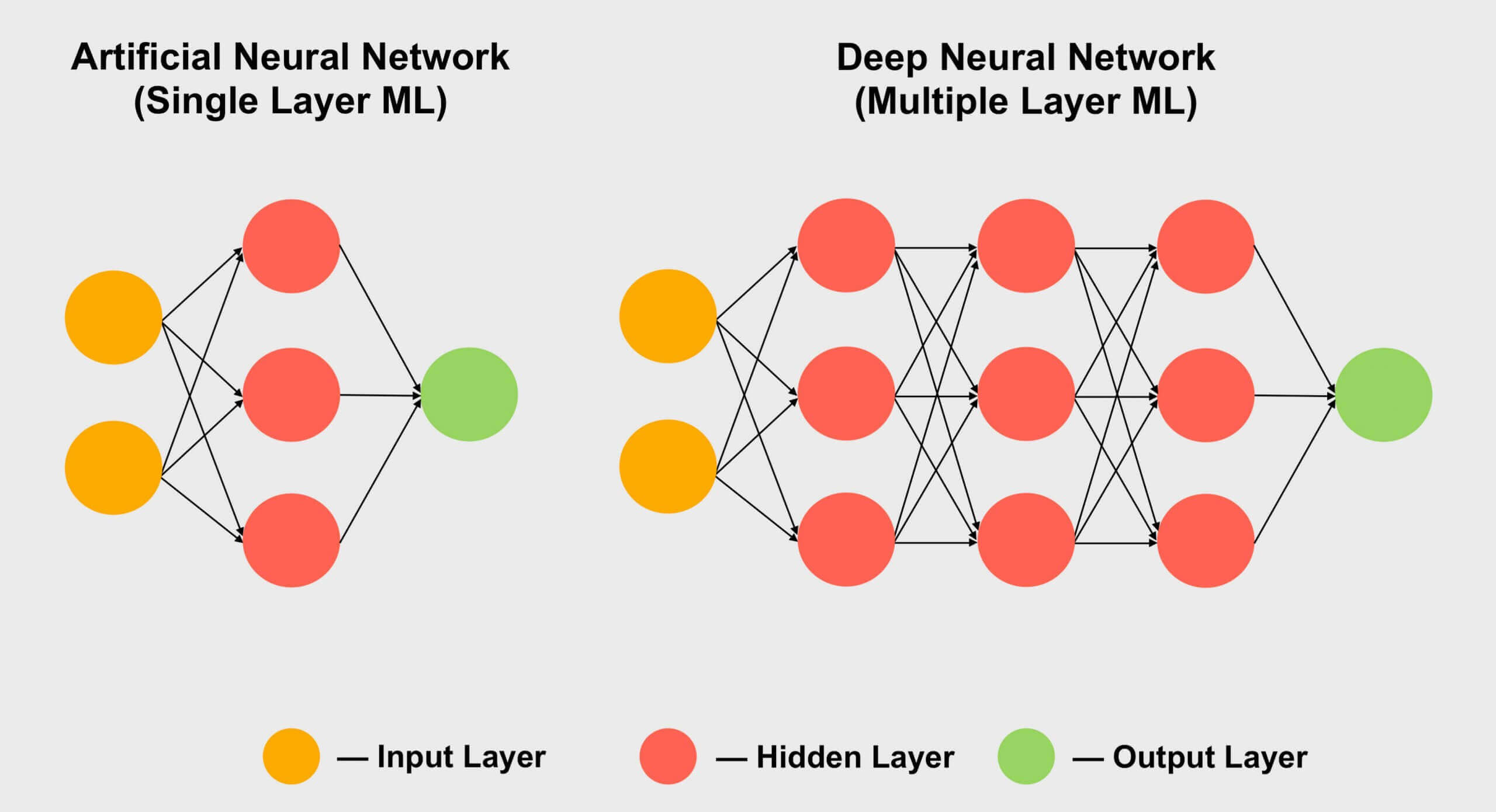
Ainsi, lorsque nous devons comprendre comment ces centaines, voire milliers de connexions interagissent, nous devons multiplier chaque élément de données du réseau par tous les poids de connexion possibles. En d'autres termes, multipliez deux matrices, ce qui est des mathématiques tensorielles classiques!

Chips Google TPU 3.0 refroidis à l'eau
C'est pourquoi tous les supercalculateurs d'apprentissage en profondeur utilisent des GPU, et presque toujours Nvidia. Cependant, certaines entreprises ont même développé leurs propres processeurs à partir de cœurs tensoriels. Google, par exemple, a annoncé le développement de son premier TPU ( unité de traitement des tenseurs ) en 2016 , mais ces puces sont tellement spécialisées qu'elles ne peuvent rien faire d'autre que des opérations avec des matrices.
Tensor Core dans les GPU grand public (GeForce RTX)
Mais que se passe-t-il si j'achète une carte graphique Nvidia GeForce RTX, sans être un astrophysicien résolvant des problèmes multiples riemanniens, ou un expert expérimentant les profondeurs de réseaux de neurones convolutifs ...? Comment puis-je utiliser les noyaux tensoriels?
Le plus souvent, ils ne s'appliquent pas au rendu, au codage ou au décodage vidéo ordinaires, il peut donc sembler que vous avez gaspillé de l'argent sur une fonctionnalité inutile. Cependant, Nvidia a intégré des cœurs de tenseur dans ses produits grand public en 2018 (Turing GeForce RTX) tout en implémentant DLSS - Deep Learning Super Sampling .

Le principe est simple: restituer le cadre à une résolution assez basse, et après avoir terminé, augmenter la résolution du résultat final pour qu'il corresponde aux dimensions de l'écran «natif» du moniteur (par exemple, rendre à 1080p, puis redimensionner à 1400p). Cela améliore les performances car moins de pixels sont traités et l'écran produit toujours une belle image.
Les consoles ont cette fonctionnalité depuis des années, et de nombreux jeux PC modernes offrent également cette fonctionnalité. Dans Assassin's Creed: Odyssey d'Ubisoft, vous pouvez réduire la résolution de rendu à 50% de la résolution du moniteur. Malheureusement, les résultats ne sont pas si beaux. Voici à quoi ressemble le jeu en 4K avec des paramètres graphiques maximum:

Les textures sont plus belles à haute résolution car elles conservent plus de détails. Cependant, il faut beaucoup de traitement pour afficher ces pixels à l'écran. Maintenant, regardez ce qui se passe lorsque le rendu est réglé sur 1080p (25% du nombre de pixels précédent), en utilisant les shaders à la fin pour étirer l'image à 4K.

En raison de la compression jpeg, la différence peut ne pas être immédiatement perceptible, mais vous pouvez voir que l'armure du personnage et le rocher au loin semblent flous. Zoomons sur une partie de l'image pour la regarder de plus près:

L'image de gauche est rendue en 4K; l'image de droite est de 1080p étirée en 4K. La différence est beaucoup plus perceptible dans le mouvement, car l'adoucissement de tous les détails se transforme rapidement en un désordre flou. Une partie de la netteté peut être restaurée grâce à l'effet de netteté des pilotes de la carte graphique, mais ce serait mieux si nous n'avions pas à le faire du tout.
C'est là que DLSS entre en jeu - dans la première versionCette technologie Nvidia a analysé plusieurs jeux sélectionnés; ils fonctionnaient à haute résolution, basse résolution, avec et sans anti-aliasing. Dans tous ces modes, un ensemble d'images a été généré, puis chargé dans les supercalculateurs de l'entreprise, qui ont utilisé un réseau neuronal pour déterminer la meilleure façon de transformer une image 1080p en une image idéale de plus haute résolution.

Je dois dire que DLSS 1.0 n'était pas parfait : les détails étaient souvent perdus et des scintillements étranges apparaissaient à certains endroits. De plus, il n'utilisait pas les cœurs tenseurs de la carte graphique eux-mêmes (il fonctionnait sur le réseau Nvidia) et chaque jeu compatible DLSS nécessitait une recherche Nvidia distincte pour générer l'algorithme de mise à l'échelle.

Lors de la sortie de la version 2.0 au début de 2020, des améliorations majeures y ont été apportées. Plus important encore, les supercalculateurs de Nvidia n'étaient plus utilisés que pour créer un algorithme général de mise à l'échelle - la nouvelle version de DLSS utilise les données d'une image rendue pour traiter les pixels à l'aide d'un modèle neuronal (cœurs de tenseurs GPU).

Nous sommes impressionnés par les capacités de DLSS 2.0 , mais jusqu'à présent, très peu de jeux le supportent - au moment d'écrire ces lignes, il n'y en avait que 12. De plus en plus de développeurs veulent l'implémenter dans leurs futurs jeux, et pour une bonne raison.
Toute augmentation d'échelle peut générer des gains de productivité significatifs, vous pouvez donc être sûr que DLSS continuera d'évoluer.
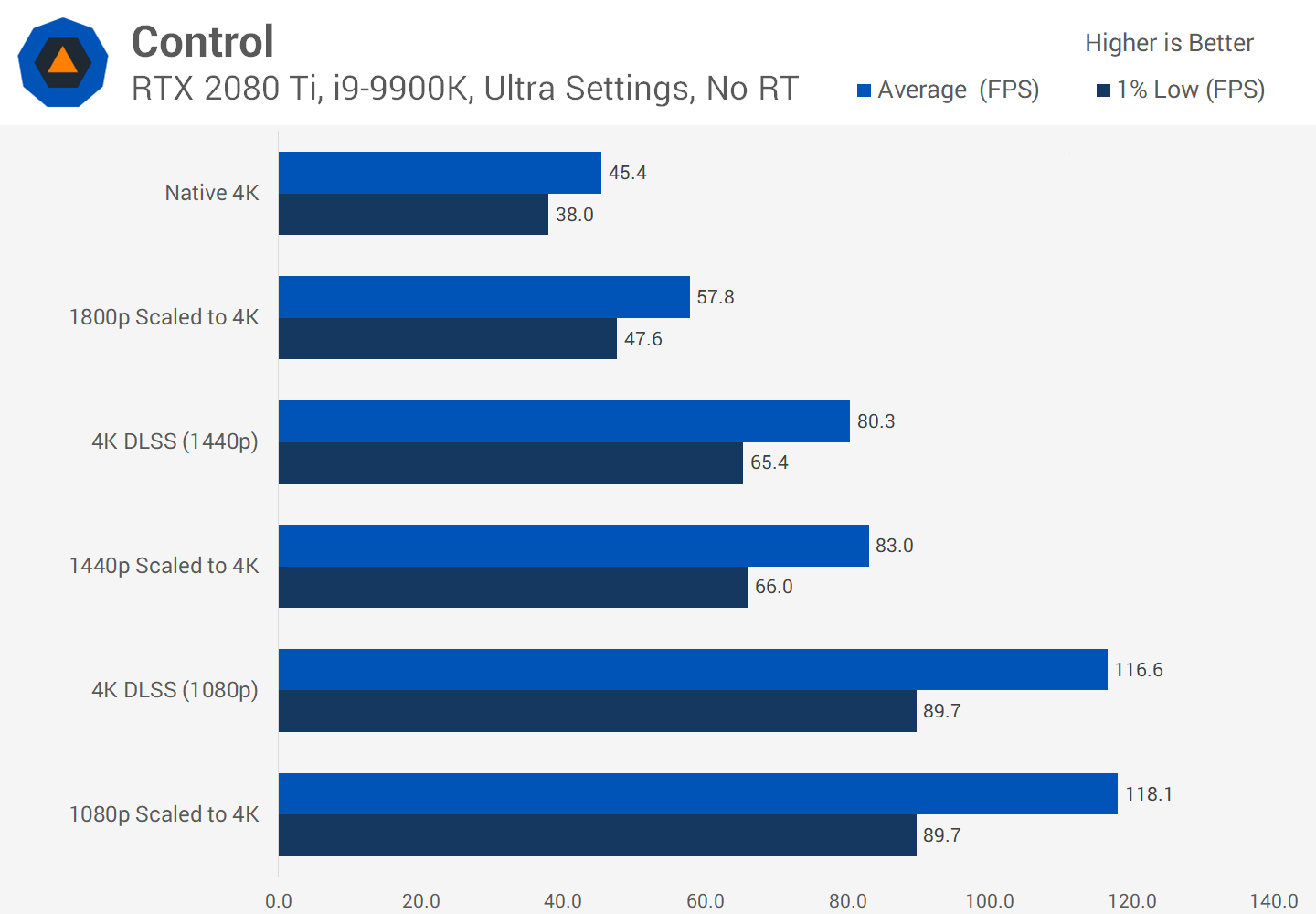
Bien que les résultats visuels de DLSS ne soient pas toujours parfaits, en libérant des ressources de rendu, les développeurs peuvent ajouter plus d'effets visuels ou fournir un niveau de graphiques sur une plus large gamme de plates-formes.
Par exemple, DLSS est souvent annoncé avec le traçage de rayons dans les jeux «RTX-enabled». Les cartes GeForce RTX contiennent des blocs de calcul supplémentaires appelés coeurs RT, qui sont des blocs logiques spécialisés pour accélérer les intersections rayon-triangle et la traversée de la hiérarchie des volumes englobants (BVH). Ces deux processus sont des procédures très longues qui déterminent comment la lumière interagit avec les autres objets de la scène.
Comme nous l'avons découvert, le lancer de rayonsEst un processus très long, donc pour assurer un niveau acceptable de fréquence d'images dans les jeux, les développeurs doivent limiter le nombre de rayons et de réflexions effectués dans la scène. Ce processus peut créer des images granuleuses, donc un algorithme de réduction du bruit doit être appliqué, ce qui augmente la complexité du traitement. On s'attend à ce que les noyaux tensoriels améliorent les performances de ce processus grâce à l'annulation du bruit de l'IA, mais cela n'a pas encore été réalisé: la plupart des applications modernes utilisent encore les noyaux CUDA pour cette tâche. D'autre part, étant donné que DLSS 2.0 devient une technique de conversion ascendante très pratique, les noyaux Tensor peuvent être utilisés efficacement pour augmenter les fréquences d'images après le lancer de rayons dans une scène.
Il existe d'autres plans pour utiliser les cœurs tenseurs des cartes GeForce RTX, comme l'amélioration des animations de personnages ou la simulation de tissus . Mais comme avec DLSS 1.0, il faudra longtemps avant qu'il y ait des centaines de jeux qui utilisent l'informatique matricielle spécialisée sur le GPU.
Un début prometteur
La situation est donc la suivante: des cœurs de tenseur, d'excellentes unités matérielles, qui, cependant, ne se trouvent que dans certaines cartes grand public. Est-ce que quelque chose changera à l'avenir? Étant donné que Nvidia a déjà considérablement amélioré les performances de chaque Tensor Core dans son architecture Ampere, il y a de fortes chances qu'ils soient également installés dans le modèle de bas à milieu de gamme.
Bien que ces cœurs ne soient pas encore dans les GPU d'AMD et d'Intel, nous les verrons peut-être à l'avenir. AMD dispose d'un système pour affûter ou améliorer les détails dans les cadres finis au prix d'une légère diminution des performances, de sorte que l'entreprise peut s'en tenir à ce système, d'autant plus qu'il n'a pas besoin d'être intégré par les développeurs, il suffit de l'activer dans les pilotes.
Il y a également une opinion selon laquelle l'espace sur les cristaux dans les puces graphiques serait mieux dépensé pour des cœurs de shader supplémentaires - c'est ce que Nvidia a fait lors de la création de versions budgétaires de ses puces Turing. Dans des produits tels que la GeForce GTX 1650 , la société a complètement abandonné les cœurs de tenseur et les a remplacés par des shaders FP16 supplémentaires.
Mais pour l'instant, si vous souhaitez fournir un traitement GEMM ultra-rapide et en tirer pleinement parti, vous avez deux options: acheter un tas d'énormes processeurs multicœurs ou juste un GPU avec des cœurs de tenseurs.
Voir également: