
Poursuivant le cycle de notes sur des problèmes réels en Data Science, nous allons aujourd'hui traiter d'un problème vivant et voir quels problèmes nous attendent en cours de route.
Par exemple, en plus de la Data Science, je suis fanatique de l'athlétisme depuis longtemps et l'un des objectifs de la course à pied pour moi, bien sûr, est le marathon. Et où est le marathon là-bas et la question est - combien courir? Souvent, la réponse à cette question est donnée à l'œil nu - "eh bien, en moyenne, ils courent" ou "c'est un bon moment!"
Et aujourd'hui, nous serons engagés dans une affaire importante - nous appliquerons la science des données dans la vie réelle et répondrons à la question:
que nous disent les données sur le marathon de Moscou?
Plus précisément, comme il ressort du tableau au début, nous collecterons des données, déterminerons qui a couru et comment. Et en même temps, cela nous aidera à comprendre si nous devons intervenir et nous permettra d'évaluer raisonnablement notre force!
TL; DR: J'ai collecté des données sur les courses marathon de Moscou pour 2018/2019, analysé le temps et les performances des participants, et rendu le code et les données accessibles au public.
Collecte de données
Grâce à une recherche rapide sur Google, nous avons trouvé les résultats des deux dernières années, 2019 et 2018 .
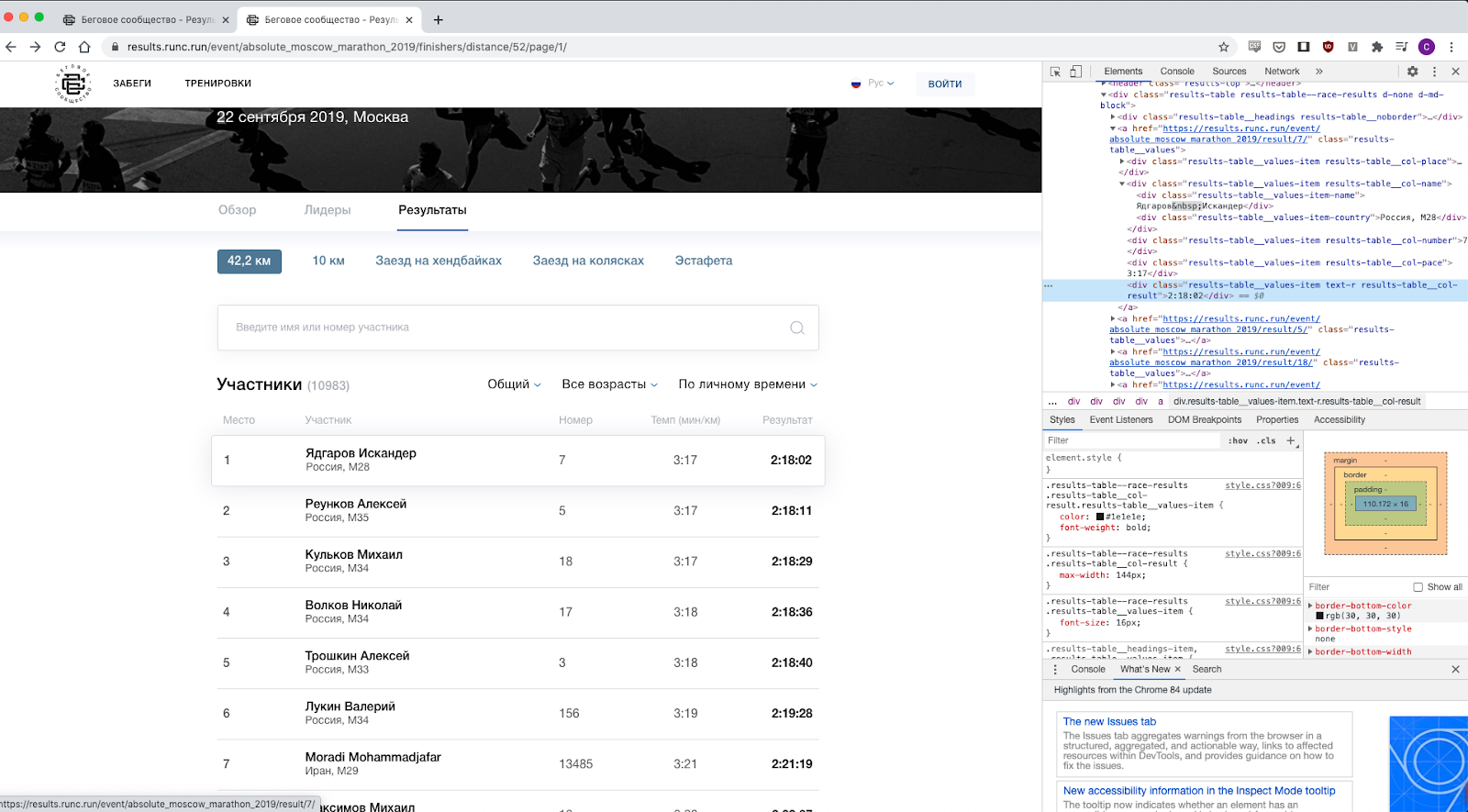
J'ai regardé attentivement la page Web, il est devenu clair que les données sont assez faciles à obtenir - il vous suffit de déterminer quelles classes sont responsables de ce que, par exemple, la classe «results-table__col-result», bien sûr, pour le résultat, etc.
Il reste à comprendre comment obtenir toutes les données à partir de là.
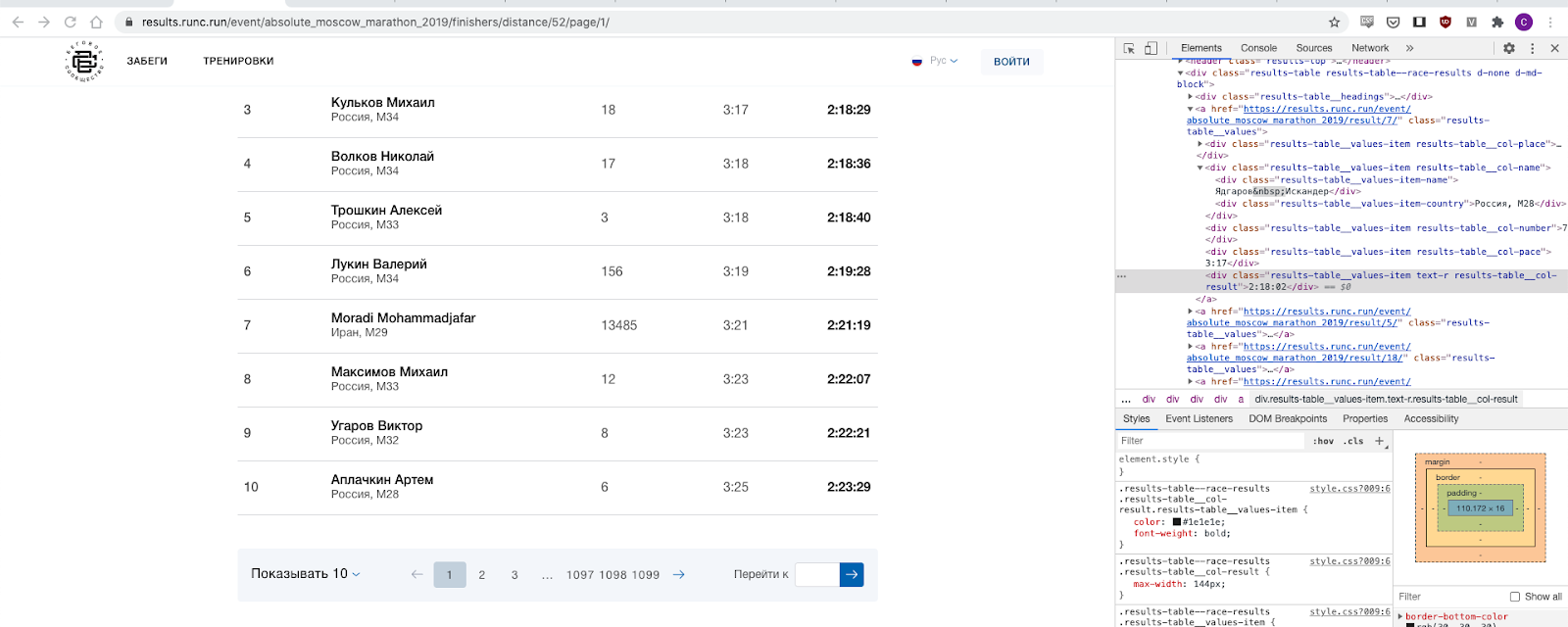
Et cela, il s'avère, n'est pas difficile, car il y a une pagination directe et nous itérons en fait sur tout le segment de nombres. Bingo, je poste les données collectées pour 2019 et 2018 ici, si quelqu'un est intéressé par une analyse plus approfondie, les données elles-mêmes peuvent être téléchargées ici: ici et ici .
Qu'est-ce que j'avais à bricoler?
- — - , , - (, ).
- - , — « ».
- Url- — - , url — , — .
- — — 2016, 2017… , 2019 — , — , — , , .
- NA: DNF, DQ, "-" — , , .
- Types de données: le temps ici est un delta temporel, mais en raison de redémarrages et de valeurs invalides, nous devons travailler avec des filtres et effacer les valeurs de temps afin de fonctionner sur des résultats en temps pur pour calculer des moyennes - tous les résultats ici sont en moyenne sur ceux qui ont terminé et qui a un temps valide.
Et voici le code spoiler au cas où quelqu'un déciderait de continuer à collecter des données de fonctionnement intéressantes.
Code analyseur
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
Analyse du temps et des résultats
Passons à l'analyse des données et des résultats réels de la course.
Pandas d'occasion, numpy, matplotlib et seaborn - tous dans les classiques.
En plus des valeurs moyennes pour tous les tableaux, nous considérerons séparément les groupes suivants:
- Hommes - puisque j'appartiens à ce groupe, ces résultats m'intéressent.
- Les femmes sont pour la symétrie.
- 35 — «» , — .
- 2018 2019 — ?.
Tout d'abord, jetons un coup d'œil au tableau ci-dessous - là encore, pour ne pas faire défiler: il y a plus de participants, 95% en moyenne atteignent la ligne d'arrivée, et la plupart des participants sont des hommes. D'accord, cela signifie que je suis dans le groupe principal en moyenne et que les données en moyenne devraient bien représenter le temps moyen pour moi. Nous allons continuer.
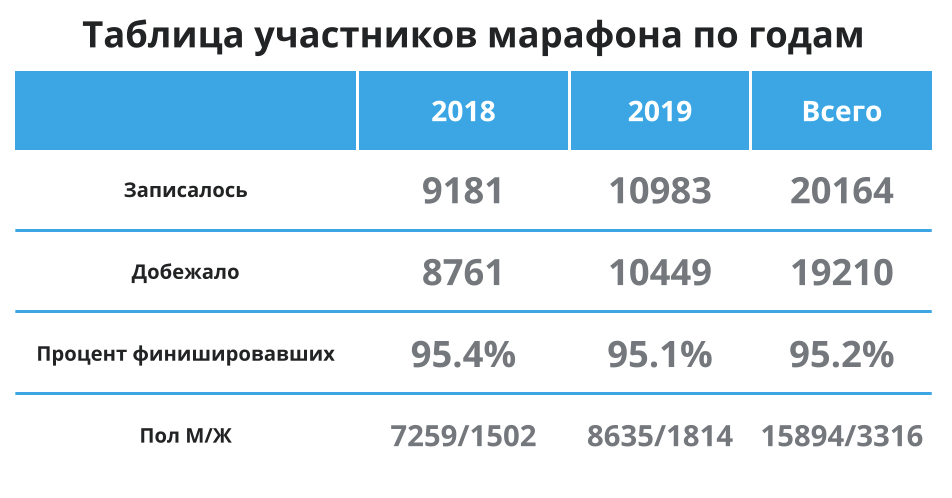

Comme nous pouvons le voir, les moyennes pour 2018 et 2019 n'ont pratiquement pas changé - environ 1,5 minute étaient plus rapides pour les coureurs en 2019. La différence entre les groupes qui m'intéressent est négligeable.
Passons aux distributions dans leur ensemble. Et d'abord le temps total de la course.
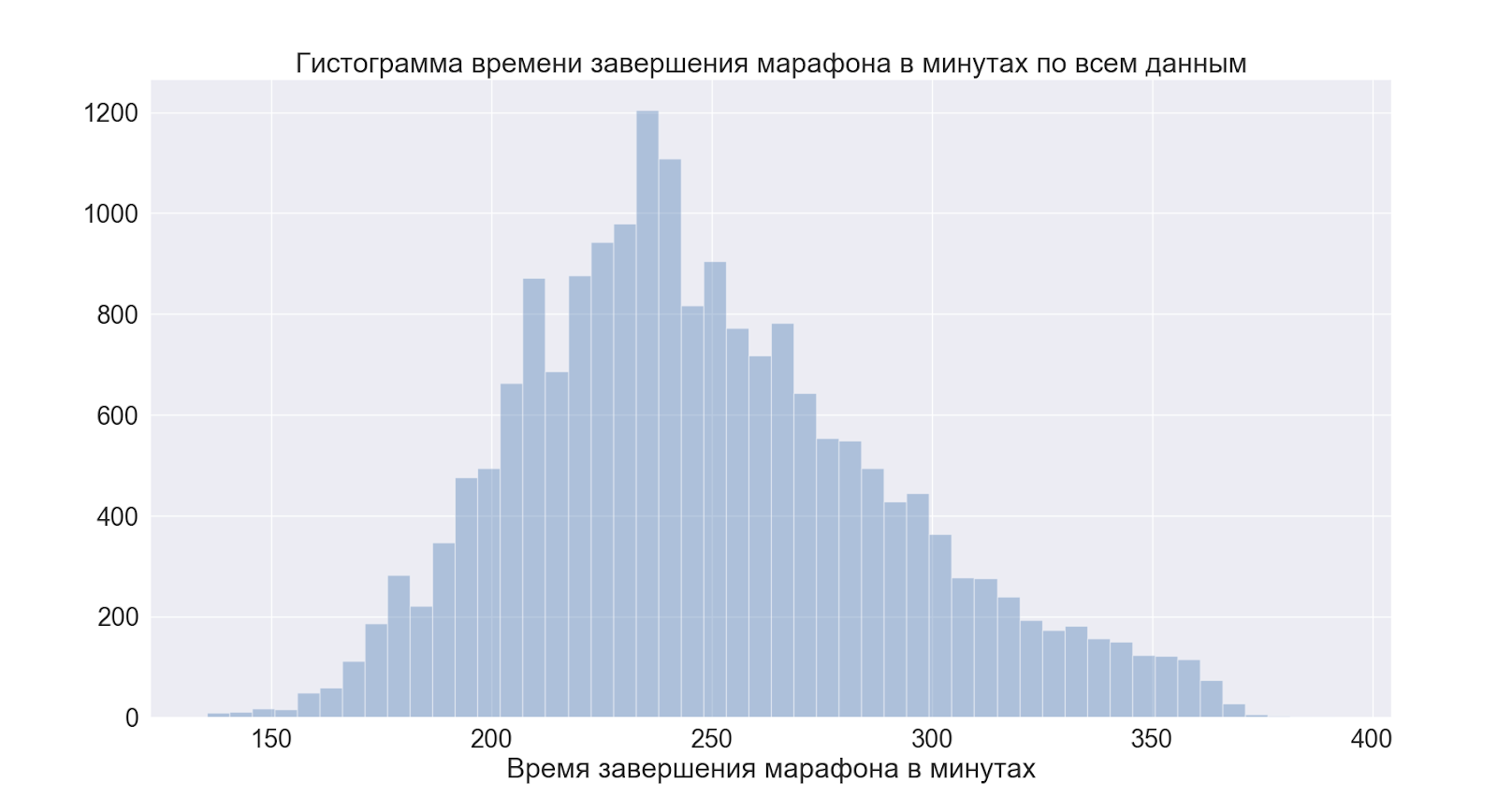
Comme nous pouvons voir le pic juste avant 4 heures - c'est une marque conditionnelle pour ceux qui aiment «bien courir» = «manquer de 4 heures», les données confirment la rumeur populaire.
Voyons ensuite comment la situation a évolué en moyenne au cours de l'année.
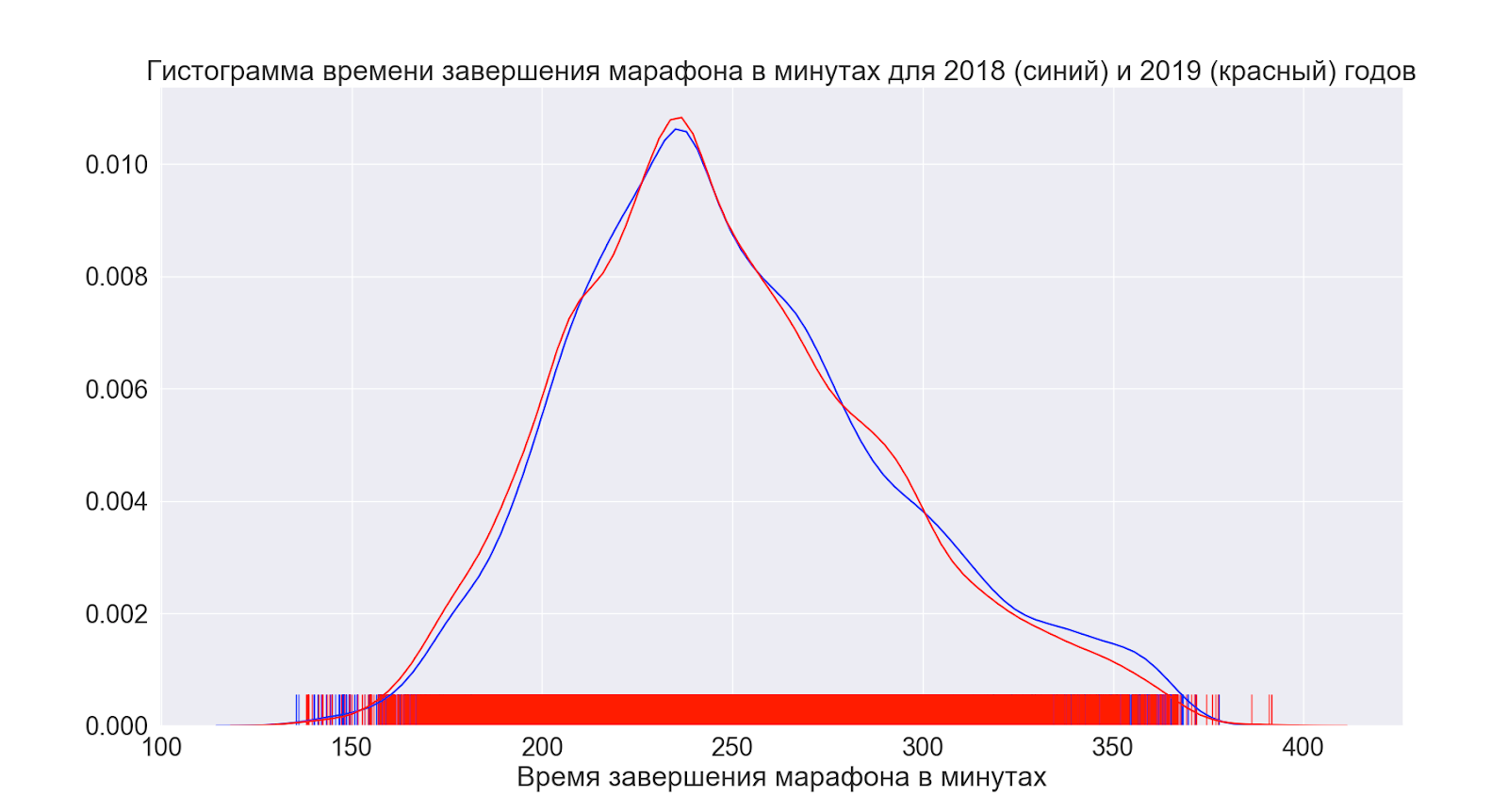
Comme nous pouvons le voir, en fait, rien n'a changé du tout - les distributions semblent pratiquement identiques.
Ensuite, considérons les distributions par sexe:

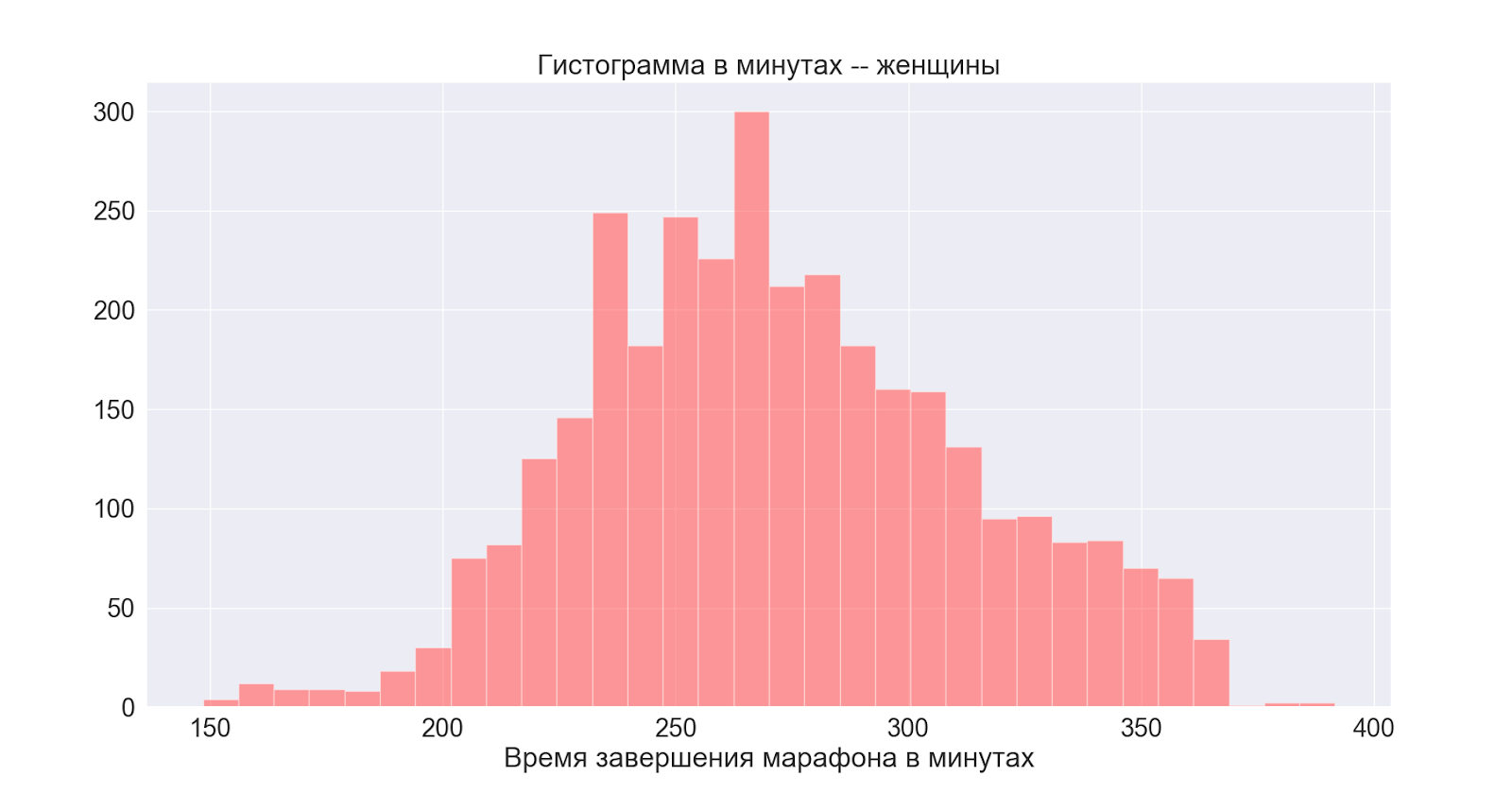
En général, les deux distributions sont normales avec des centres légèrement différents - nous voyons que le pic chez le mâle se manifeste également sur la distribution principale (générale).
Séparément, passons au groupe qui m'intéresse le plus:
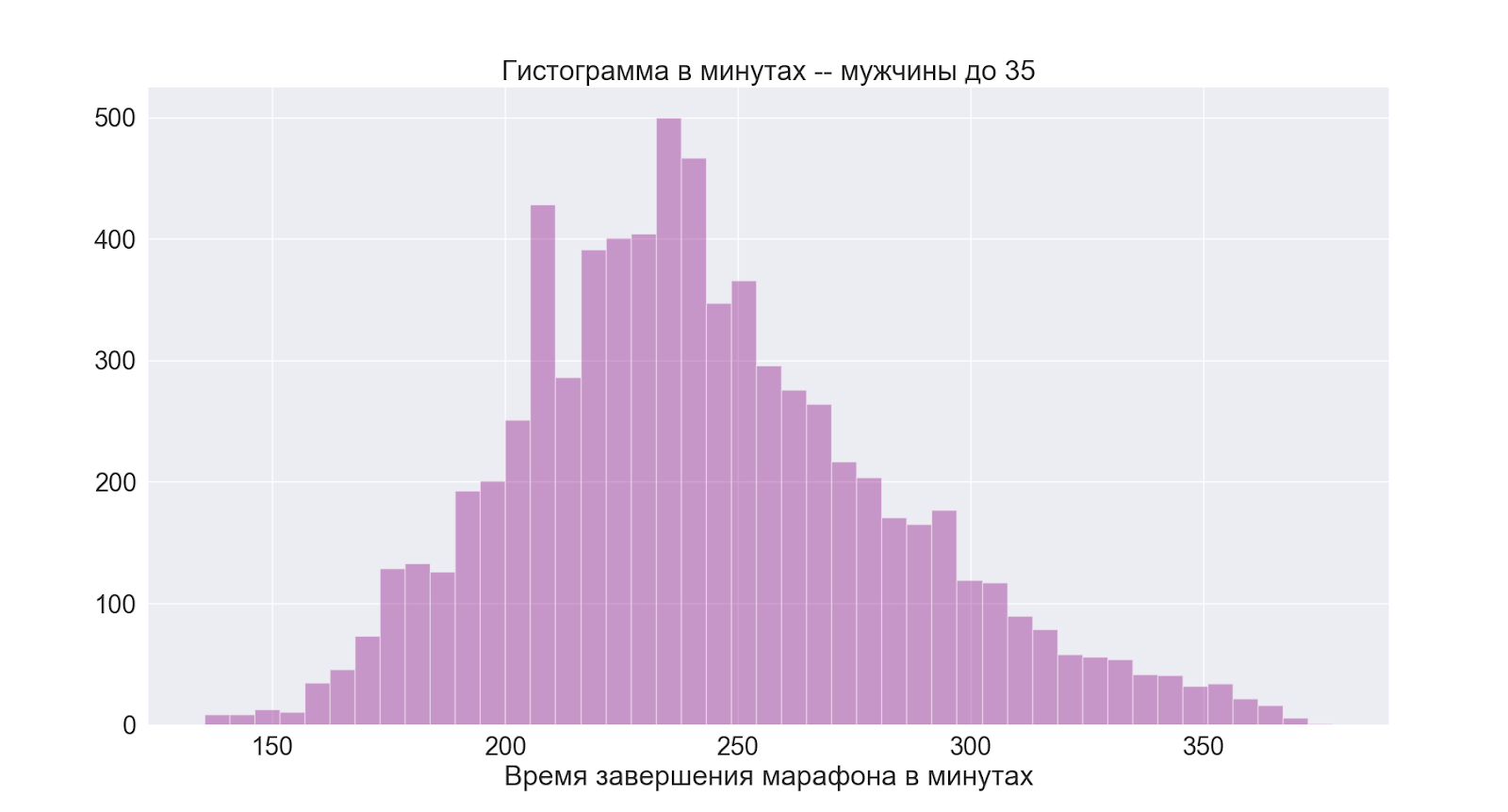
comme nous pouvons le voir, l'image est fondamentalement la même que dans le groupe masculin dans son ensemble.
De cela, nous concluons que 4 heures est également un bon temps moyen pour moi.
Etudier les améliorations des participants 2018 → 2019
Intéressant: pour une raison quelconque, je pensais que maintenant je collecterais rapidement des données et que je pourrais approfondir l'analyse, y rechercher des modèles pendant des heures, etc. Il s'est avéré que c'était l'inverse, la collecte de données s'est avérée plus difficile que l'analyse elle-même - selon les classiques, travailler avec le réseau, les données brutes, le nettoyage, le formatage, la diffusion, etc., a pris beaucoup plus de temps que l'analyse et la visualisation. N'oubliez pas que les petites choses prennent un peu de temps - mais il y en a pas mal de [petites choses], et à la fin, elles mangeront toute votre soirée.
Séparément, je voulais voir comment les personnes qui ont participé les deux fois ont amélioré leurs résultats, en comparant les données entre les années, j'ai pu établir ce qui suit:
- 14 personnes ont participé les deux années et n'ont jamais fini
- 89 personnes ont couru à 18 m, mais ont échoué à 19
- 124 vice versa
- Ceux qui ont pu courir les deux fois ont amélioré leur résultat de 4 minutes en moyenne
Mais ici, tout s'est avéré assez intéressant:
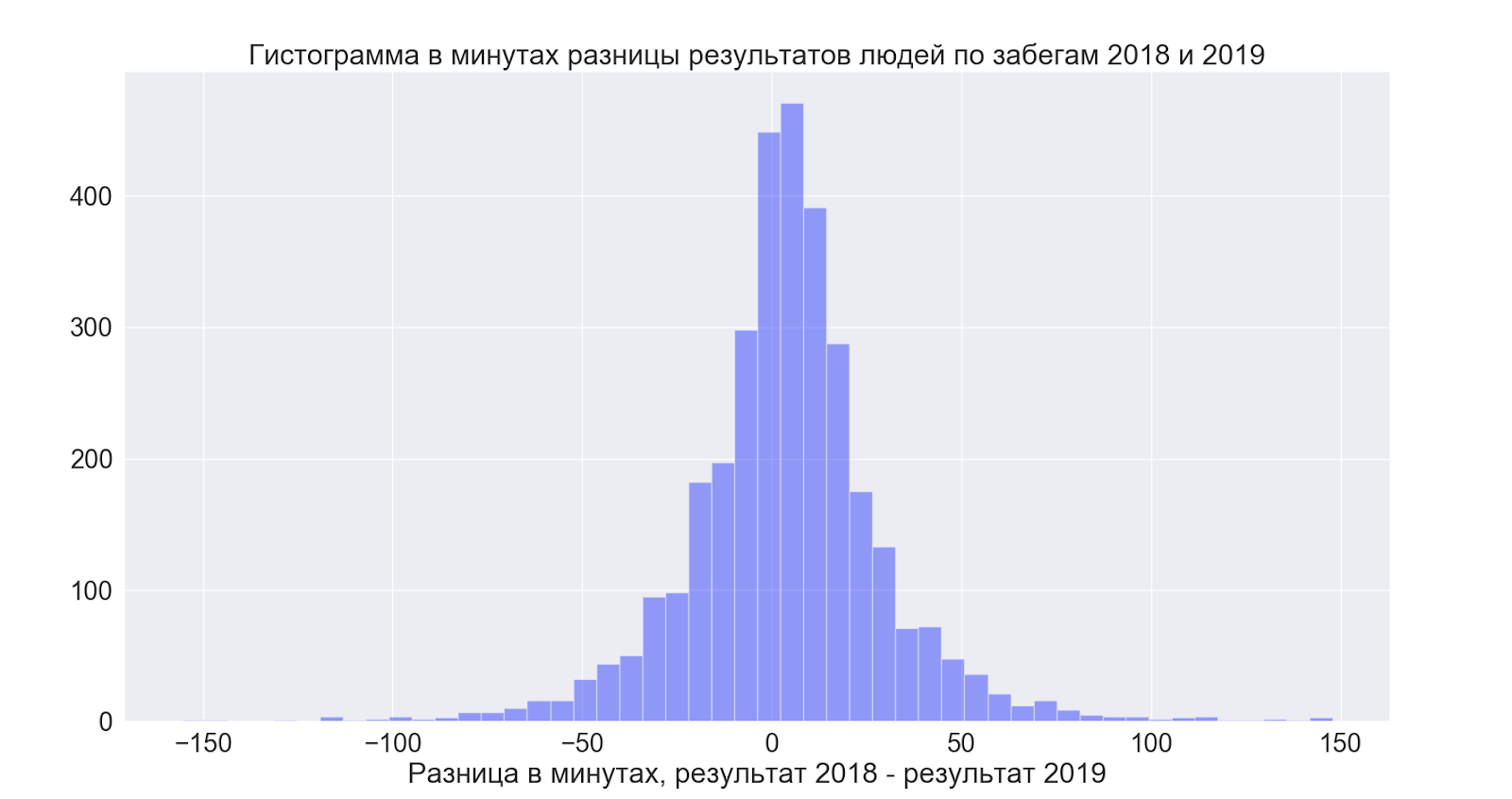
c'est-à-dire qu'en moyenne, les gens améliorent légèrement les résultats - mais en général, la propagation est incroyable et dans les deux sens - c'est-à-dire qu'il est bon d'espérer que ce sera mieux - mais à en juger par les données, cela s'avère en général comme vous le souhaitez!
conclusions
J'ai tiré les conclusions suivantes pour moi-même à partir des données analysées
- Dans l'ensemble, 4 heures est un bon objectif moyen.
- Le groupe principal de coureurs est déjà à l'âge très compétitif (et dans le même groupe que moi).
- En moyenne, les gens améliorent légèrement leurs résultats, mais en général, à en juger par les données, comment ils y parviennent.
- Les résultats moyens pour toute la course sont à peu près les mêmes pour les deux années.
- Il est très confortable de parler du marathon depuis le canapé.
