 Beaucoup de gens savent qu'ABBYY est engagé dans le traitement et l'extraction de données à partir de divers documents. Mais nos produits ont également d'autres possibilités intéressantes. En particulier, la solution ABBYY Intelligent Search vous permet de rechercher rapidement et facilement des informations significatives dans des documents électroniques à partir de systèmes d'entreprise. Cela est déjà utilisé par de grandes entreprises russes, par exemple NPO Energomash , un fabricant de moteurs de fusée .
Beaucoup de gens savent qu'ABBYY est engagé dans le traitement et l'extraction de données à partir de divers documents. Mais nos produits ont également d'autres possibilités intéressantes. En particulier, la solution ABBYY Intelligent Search vous permet de rechercher rapidement et facilement des informations significatives dans des documents électroniques à partir de systèmes d'entreprise. Cela est déjà utilisé par de grandes entreprises russes, par exemple NPO Energomash , un fabricant de moteurs de fusée .
La pratique à long terme montre que le temps nécessaire pour mettre sur le marché des moteurs spatiaux dès le début des travaux est de 5 à 7 ans. Dans le même temps, afin de maintenir la position de leader, il est nécessaire de réduire le temps de développement et de production à 3-4 ans. En outre, l'intensification de la concurrence a conduit à la nécessité de réduire considérablement le coût des moteurs fabriqués de 30 à 50%.
Ces indicateurs ne peuvent être atteints sans l'introduction des technologies numériques modernes. Les entreprises les plus avancées utilisent des approches innovantes non seulement à toutes les étapes de la production, mais également à toutes les étapes du cycle de vie de leurs produits. Plus les entreprises passent au numérique, plus la question devient aiguë: comment utiliser le big data au maximum pour elles-mêmes?
Plus de 90 ans de travail NPO Energomash a accumulé un volume centenaire de documents (papier et électroniques) contenant des informations précieuses sur les développements des testeurs et des concepteurs. La plupart des documents sont déjà stockés dans les systèmes d'information (SI) de l'entreprise. Selon les recherches IDC, en moyenne, les employés des grandes organisations utilisent 5 à 6 SI internes. En moyenne, environ 36% du temps est consacré à la recherche d'informations - dans une grande entreprise, cela représente des milliers d'heures de travail par jour.
Aujourd'hui, nous vous expliquerons comment nous avons aidé NPO Energomash à créer un système intelligent de recherche d'informations (KIIPS) d'entreprise basé sur ABBYY Intelligent Search - aussi pratique et rapide que les moteurs de recherche populaires.
Que fait Energomash et qu'est-ce que Gagarine a à voir avec
 Depuis le jour de sa fondation, le 15 mai 1929, Energomash a fabriqué plus de 12 mille moteurs pour lanceurs non seulement en Russie, mais aussi à l'étranger. Ces "moteurs" ont été utilisés pour lancer le premier satellite artificiel de la Terre, sont allés dans l'espace "Vostok-1" avec le premier cosmonaute Youri Gagarine à bord, ont piloté l'avion spatial "Bourane" et les lanceurs américains Atlas et Antares sont toujours en cours de lancement. Par exemple, la fusée Atlas V du 26 mars 2020, équipée de moteurs russes, a mis en orbite un système de communications par satellite stratégique militaire américain. Au premier semestre 2020, les moteurs développés par Energomash ont fonctionné avec succès dans 11 lancements spatiaux, soit 24,4% de tous les lancements dans le monde.
Depuis le jour de sa fondation, le 15 mai 1929, Energomash a fabriqué plus de 12 mille moteurs pour lanceurs non seulement en Russie, mais aussi à l'étranger. Ces "moteurs" ont été utilisés pour lancer le premier satellite artificiel de la Terre, sont allés dans l'espace "Vostok-1" avec le premier cosmonaute Youri Gagarine à bord, ont piloté l'avion spatial "Bourane" et les lanceurs américains Atlas et Antares sont toujours en cours de lancement. Par exemple, la fusée Atlas V du 26 mars 2020, équipée de moteurs russes, a mis en orbite un système de communications par satellite stratégique militaire américain. Au premier semestre 2020, les moteurs développés par Energomash ont fonctionné avec succès dans 11 lancements spatiaux, soit 24,4% de tous les lancements dans le monde.
Aujourd'hui, Energomash fait partie de la société d'État Roscosmos et dirige la structure intégrée de propulsion de fusée, qui comprend les principales entreprises de ce secteur.
Au cours des dernières années, la société a lancé activement des solutions informatiques à grande échelle qui utilisent largement l'analyse des données, l'apprentissage automatique et toutes les capacités des technologies de traitement du langage naturel. L'entreprise s'est fixé un objectif stratégique de fabrication entièrement numérique d'ici 2021.
Par exemple, dans le cadre du projet " Technologies de conception et de production numériques»L'une des tâches clés était la mise en place d'un système PLM (système automatisé de gestion du cycle de vie des produits). Son objectif est d'assurer la création de la documentation de conception électronique (ECD) et de modéliser sur sa base le fonctionnement du moteur et d'autres processus de travail dans les départements technologiques et de production de NPO Energomash et la disponibilité à l'échange d'ECD entre les entreprises de l'industrie.
Pourquoi était-il nécessaire de chercher dans l'univers d'Energomash
Pour atteindre l'objectif stratégique de création de production numérique, l'entreprise mène toute une série de projets basés sur le travail avec de grandes quantités de données. L'un d'eux est un projet visant à créer un système intelligent de recherche d'informations d'entreprise.
Le but du projet est de préserver, augmenter et mettre au service de la production numérique les connaissances et compétences de l'entreprise, accumulées au fil des décennies de travail.
Dans le cadre du projet, deux tâches ont été résolues:
1). Aidez les concepteurs et les ingénieurs à trouver plus facilement des informations utiles dans les documents des années précédentes.
De nombreux développements ont été créés en URSS, mais tous n'ont pas été mis en œuvre, car les investissements ne leur étaient pas toujours alloués ou le niveau de développement technologique ne permettait pas de compléter le plan. A notre époque, de tels développements peuvent trouver une seconde vie. Pour ce faire, l'entreprise demande à des designers expérimentés de partager leurs travaux de recherche et leurs dessins, qui sont encore sur papier. Cela aidera à numériser des données précieuses, à les préserver pendant de nombreuses années et à transférer les connaissances à la jeune génération de scientifiques et d'ingénieurs.
Bien sûr, la recherche de documents dans des systèmes électroniques existait auparavant dans Energomash, mais il n'était pas facile pour les employés de trouver les informations dont ils avaient besoin pour travailler.
Sous le spoiler, nous vous expliquerons plus en détail comment ce processus a été organisé plus tôt.
7 . , - , , - – , , . , , :
, , , , . , , : . , .
:
. « » () , . , « », , , , , , . , , . - , «».
, , , , , .
- ;
- ;
- , , .
, , , , . , , : . , .
:
- . , , ;
- , , .
. « » () , . , « », , , , , , . , , . - , «».
, , , , , .
2). Simplifiez et accélérez la recherche de données pour les services: comptables, avocats et autres spécialistes qui composent, éditent, coordonnent des documents dans les systèmes comptables et échangent des informations.
L'entreprise souhaitait que les employés puissent collecter et analyser les informations financières, de fabrication et autres informations pertinentes dont ils ont besoin pour effectuer leur travail à partir de systèmes d'entreprise disparates en saisissant simplement des requêtes dans une seule chaîne de recherche. Il était nécessaire de créer un point d'accès unique aux données stockées dans les systèmes d'information de l'entreprise, avec la fourniture d'un accès délimité aux informations, en fonction de l'autorité de l'utilisateur dans chaque système.
Pourquoi c'est important? Dans 7 ans, plus de la moitié de toutes les données dans le monde seront stockées dans les systèmes d'entreprise, il résulte deRapport d'âge Seagate et IDC Data . Pour toujours avoir les informations nécessaires à portée de main, vous devez les trouver rapidement. Ainsi, selon une étude d'IDC et d'ABBYY «Le marché de l'intelligence artificielle en Russie», les représentants de l'informatique (48%) et des unités commerciales (33%) voient de grandes opportunités dans l'utilisation de l'IA pour la recherche d'entreprise et la classification de documents au cours des deux prochaines années.
Pour faire face à ces tâches, l'entreprise avait besoin d'une recherche de bout en bout pratique sur de nombreuses adresses IP. Energomash a envisagé plusieurs moteurs de recherche, mais a finalement décidé d'essayer ABBYY Intelligent Search. Le choix a été influencé, tout d'abord, par la disponibilité de technologies de traitement du langage naturel qui vous permettent de trouver des documents pertinents pour les requêtes de recherche par sens, et pas seulement par mots-clés. Deuxièmement, la possibilité de différencier les droits d'accès des utilisateurs aux résultats de recherche. Nous vous en dirons plus un peu plus tard, et maintenant - comment nous avons commencé.
La première "sortie" de la recherche
Energomash a décidé de vérifier le travail de recherche intelligente sur 3 mille documents de la base de données d'information (BID) des travaux de recherche, de conception et de calcul.
Pour cela, ABBYY a développé un prototype de connecteur à l'IDB, qui reliait ABBYY Intelligent Search à la base de données de documents. Un connecteur est un programme java utilisé pour charger des documents dans un index. Comment ça fonctionne?
1). Nous construisons d'abord un index de recherche en texte intégral
Un index de texte intégral est, grosso modo, une liste de tous les mots d'un document et ses métadonnées (numéro du document, titre, date de création). L'index de texte intégral est créé assez rapidement et vous permet de rechercher les informations nécessaires par mots-clés - ceux qui apparaissent dans le texte.


Pour créer un index de texte intégral, vous avez besoin d'un connecteur. Il relie la solution de recherche à un système d'information spécifique et collecte («indexe») les caractéristiques de chaque document, par exemple:
- le nom de l'IP où le fichier est stocké,
- la date de la dernière modification du document,
- la version du document dans la source,
- format de document,
- les codes des langues dans lesquelles le document est rédigé,
- chemin d'accès au document dans le SI,
- date de la dernière indexation du document
- et etc.
À l'avenir, ces caractéristiques aideront non seulement à accélérer la recherche d'un document, mais également à simplifier la logique de leur utilisation pour le connecteur. En particulier, le connecteur analyse différentes versions d'un même document afin de ne mettre que la dernière dans l'index. Le connecteur reçoit également des informations sur les documents qui ont été supprimés de la source.
Un robot d'exploration (robot de recherche) intégré à ABBYY Intelligent Search aide à créer un index de recherche. À intervalles réguliers, il interroge les connecteurs, vérifie si de nouveaux documents sont apparus dans le SI, quels documents ont été supprimés, comment les droits d'accès aux documents ont changé. En conséquence, l'indice est mis à jour à une fréquence donnée.
Non seulement les documents texte sont indexés, mais également les fichiers graphiques. Par exemple, il peut s'agir de copies numérisées de dessins au format JPEG ou PDF sans calque de texte. Lorsque vous travaillez avec des images, la solution de recherche reconnaît d'abord automatiquement le texte et l'ajoute à l'index de recherche.
De plus, le système peut gérer les fichiers d'archive ZIP, RAR, TAR - à condition qu'ils ne soient pas protégés par mot de passe. Les archives sont décompressées, leurs images sont reconnues, le texte est indexé.
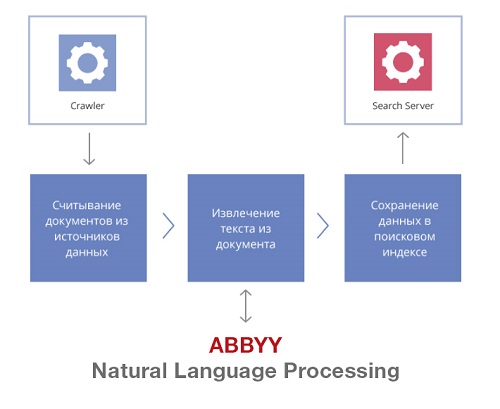

L'index de recherche contient un ensemble arbitraire de champs, qui peuvent également être utilisés pour filtrer les résultats de la recherche (auteur du document, date de création, numéro de produit, etc.).
2). Ensuite, nous appliquons les technologies de traitement du langage naturel
En arrière-plan, l' index de recherche est enrichi d'informations sémantiques . Pour ce faire, nous avons utilisé l'ontologie sémantique-linguistique que nous avons déjà, c'est-à-dire des descriptions d'objets et de phénomènes du monde réel. Nous avons déjà parlé de la façon dont nous avons créé ce modèle sur Habré ici et ici .
À l'aide de technologies d'apprentissage automatique et de traitement du langage naturel, chaque document analyse la syntaxe des phrases, la morphologie et les significations sémantiques de littéralement chaque mot du texte. Ces informations complètent l'index de recherche et permettent de rechercher non pas par mots-clés, mais par synonymes, hyponymeset d'autres constructions qui véhiculent le même sens mais dans des expressions différentes. Ainsi, le moteur de recherche recherche plus précisément les informations dans les sources de l'entreprise.


C'est très pratique si un de nos pairs a formulé une requête de recherche dans ses propres mots, et veut trouver des documents il y a 40 ans, là où, peut-être, le sujet dont il avait besoin était appelé par d'autres termes. Par exemple, pour la requête "frame defect", le système sélectionnera toutes les expressions sémantiques possibles associées à ce terme. Les résultats peuvent inclure «la déviation », « trou », « pli » ou «le fait de violation de la documentation technologique de conception ».
Voici un autre exemple:

Les résultats de la recherche pour « fluctuations de poussée » afficheront également des textes contenant l'expression « variance de poussée ».
Les technologies de traitement du langage naturel aident également le moteur de recherche à corriger automatiquement les fautes d'orthographe dans le texte de la requête. Par exemple, le système comprendra qu'il y a des erreurs dans le mot «portant» et recherchera immédiatement les documents qui mentionnent «portant».
Résultats du premier lancement
Pour évaluer le travail d'un moteur de recherche intelligent, les spécialistes d'Energomash ont répondu à une trentaine de requêtes de documents IDB à l'aide du moteur de recherche intégré à l'IDB et à l'aide d' ABBYY Intelligent Search . Ensuite, ils ont comparé les résultats de la recherche: quels documents ont été trouvés par les deux systèmes, quelles phrases ont été mises en évidence dans des extraits. En conséquence, la recherche intégrée à l'IDB n'a pas renvoyé de résultats pour certaines requêtes, car elle est capable de détecter uniquement des mots clés et non des mots associés. ABBYY Intelligent Search a renvoyé des documents pertinents pour toutes les requêtes.
Quant à la vitesse, tout en répondant aux exigences de la plate-forme matériellela réponse à la recherche n'a pas dépassé une fraction de seconde, comme les moteurs de recherche populaires. Les requêtes les plus complexes prenaient jusqu'à 3 secondes au maximum.
Après un projet pilote réussi, Energomash a décidé d'utiliser la solution ABBYY Intelligent Search au cœur du Corporate Intelligent Information Search System.
Allons plus loin
Energomash a connecté 7 sources d'entreprise à la recherche: système de gestion électronique de documents LanDocs, stockage de fichiers, IDB, système de support du cycle de vie des produits TeamCenter, système de gestion des ressources Galaxy ERP et AMM, système d'information de gestion de projet. Un index distinct a été créé pour chaque système d'information. Cela rend le moteur de recherche flexible dans l'administration et permet de reconstruire l'index pour chaque système séparément, en définissant de nouvelles conditions. L'accès au système de recherche d'entreprise est organisé via le portail interne de l'entreprise sur la page principale. Le projet a été mis en œuvre conjointement avec un partenaire, LANIT , le plus grand groupe diversifié russe de sociétés informatiques.
Les principaux modules du système de recherche d'entreprise:
- page principale des requêtes de recherche et des résultats de recherche;
- panneau d'administration (mise en place d'index, de filtres, de métadonnées pour chaque système d'information);
- statistiques du nombre de documents (affiche le nombre de documents dans l'index pour chaque système d'information pour la période).
Le système de recherche d'entreprise est mis en service commercial depuis le 1er juillet 2020. Au moment du lancement, 500 000 documents étaient indexés. On s'attend à ce que d'ici la fin de l'année, avec l'utilisation active du système et la connexion de nouvelles sources d'information, le nombre de documents dans l'index atteindra plus d'un million.
Comment assurer la sécurité
Comme toute grande entreprise, NPO Energomash dispose de documents qui ne sont pas destinés à l'accès de tous les employés. La principale exigence de sécurité lors du lancement du projet était de fournir un accès aux documents conformément au modèle de chaque système d'information. Pour cela a été fait:
1). Stockage local d'informations
La solution de recherche ABBYY est déployée sur un serveur distinct dans le circuit interne de NPO Energomash. Tous les index de recherche et leurs sauvegardes en cas de perte et leurs paramètres y sont stockés.
2). Modèle de rôle du système d'information
Par sécurité, la différenciation des droits d'accès des utilisateurs aux résultats de recherche pour chaque système d'information est organisée. Tous les systèmes d'entreprise connectés à ABBYY Intelligent Search prennent en charge l'autorisation de domaine. L'utilisateur se connecte au système sous un compte de domaine, exécute une requête et voit le document dans les résultats de la recherche, en tenant compte des paramètres de prévisualisation du document pour chaque système d'information et du niveau d'accès effectué directement dans le système de recherche d'entreprise lui-même, et en tenant compte de l'accès au document dans le système d'information source lui-même. ... Si l'utilisateur a le droit de travailler avec le document dans le système source, la transition vers le document d'origine peut être effectuée directement à partir du système de recherche d'entreprise en cliquant sur le lien.
Projets pour le futur
Selon l'idée d'Energomash, la récupération intelligente des informations contribuera à simplifier et à accélérer les processus commerciaux de l'entreprise, par exemple, à accélérer indirectement l'entrée de nouveaux produits sur le marché, à améliorer leur qualité et à réduire les coûts. Les idées et les projets qui ont été conservés dans des documents anciens peuvent être utilisés dans les développements modernes de l'entreprise. Par exemple, créez quelque chose de complètement nouveau sur la base des développements et devancez vos concurrents sur le marché mondial.
Citons également nos projets d'avenir:
- À l'avenir, il est prévu de connecter les sources d'informations d'autres entreprises faisant partie de la structure Energomash au système de recherche d'entreprise. Dans ce cas, l'index de recherche peut s'étendre jusqu'à 2 millions de documents.
- , , – . , - . , , : , - , . , , . , , .
- Energomash prévoit également d'explorer la possibilité de créer des rapports analytiques complexes à l'aide de la fonction de recherche.
À votre avis, quelles autres tâches pouvez-vous résoudre avec l'aide de la recherche d'entreprise?