
Diverses options de visualisation nous aideront à cela :
Vue de texte réduite
Le texte original d'un plan assez simple pose déjà des problèmes dans l'analyse: par
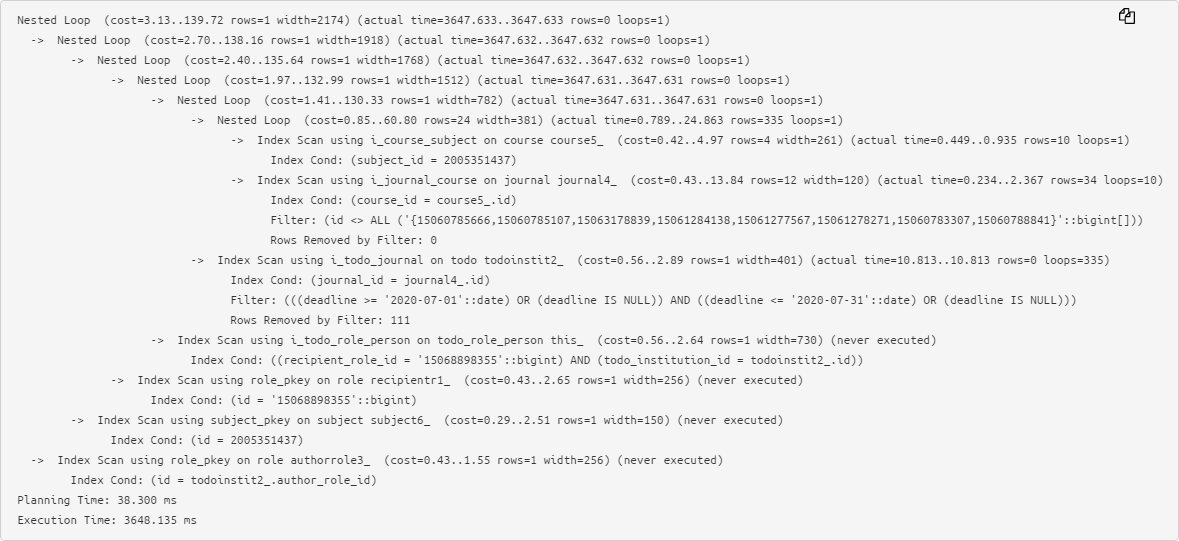
conséquent, nous préférons la forme abrégée, lorsque les informations clés sur le temps d'exécution et les tampons utilisés de chaque nœud sont extraites à gauche et à droite , et il est très facile de remarquer les maxima:
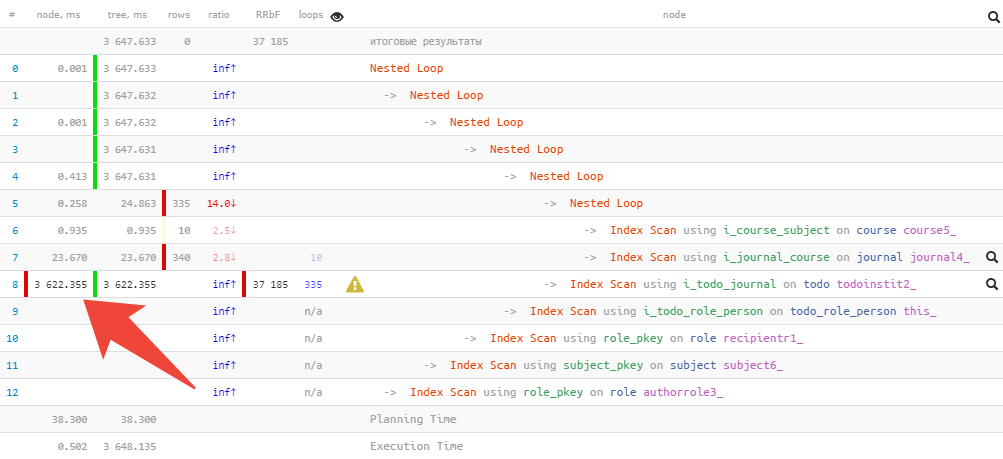
Diagramme circulaire
Mais parfois même juste comprendre «là où ça fait le plus mal» n'est pas facile, surtout s'il contient plusieurs dizaines de nœuds et même la forme raccourcie du plan prend 2-3 écrans.

Dans ce cas, le camembert habituel viendra à la rescousse:
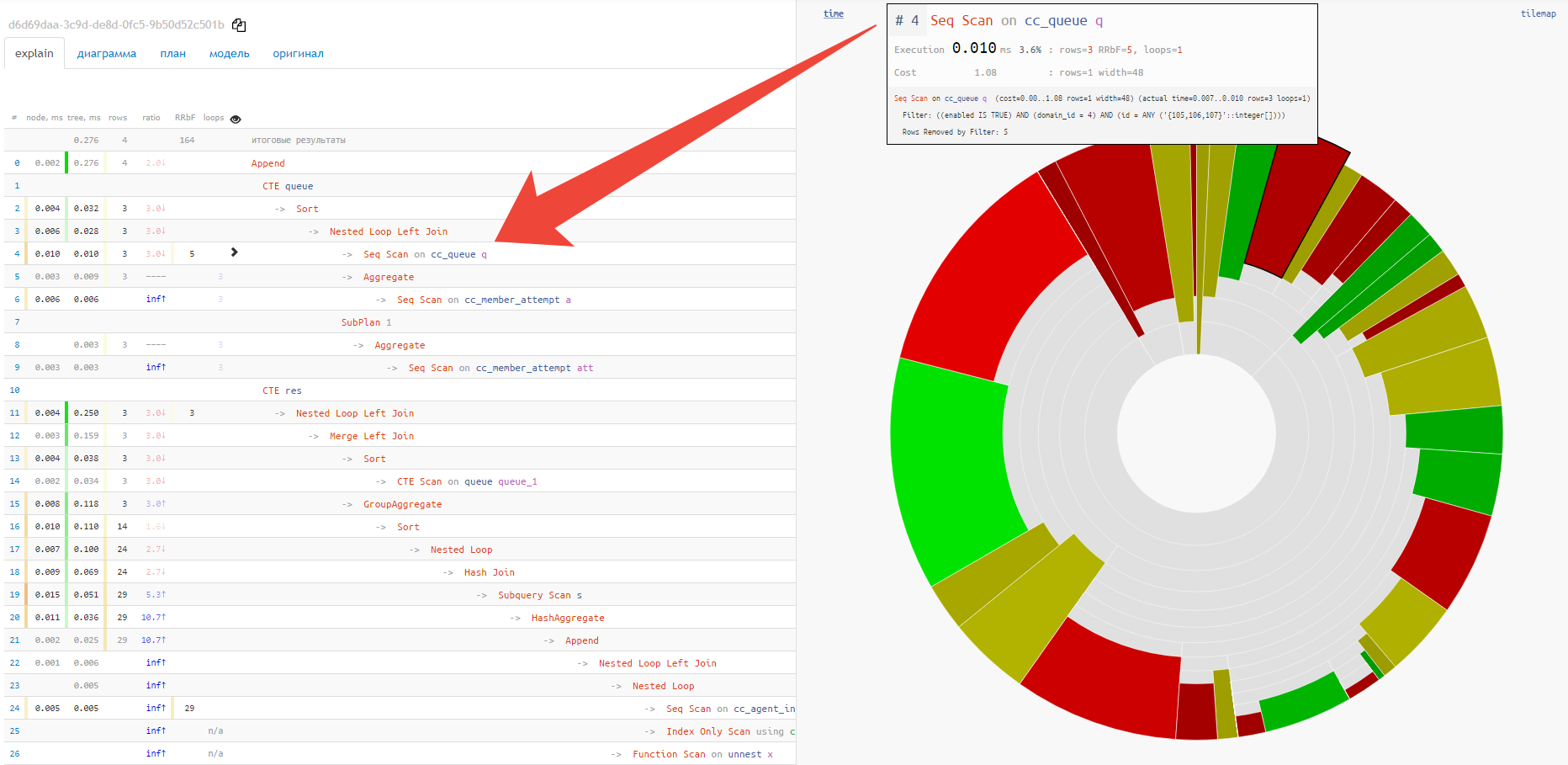
Immédiatement, désinvolte, vous pouvez voir la part approximative de la consommation de ressources par chacun des nœuds. Lorsque nous le survolons, à gauche dans la vue texte, nous verrons une icône pour le nœud sélectionné.
Tuile
Hélas, le diagramme à coup ne montre pas la relation entre les différents nœuds et les points "les plus chauds". Pour cela, l'option "tuile" est bien mieux adaptée:
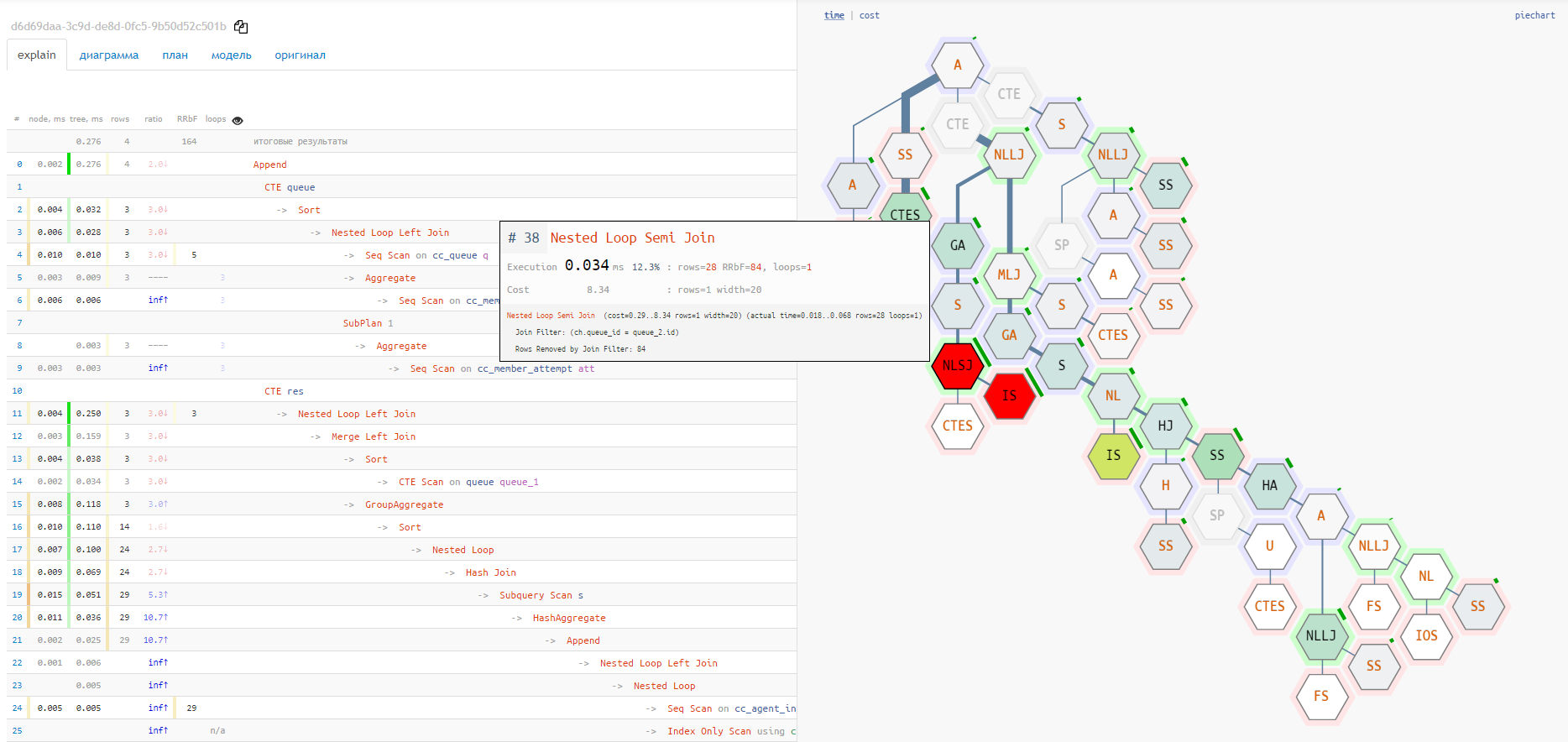
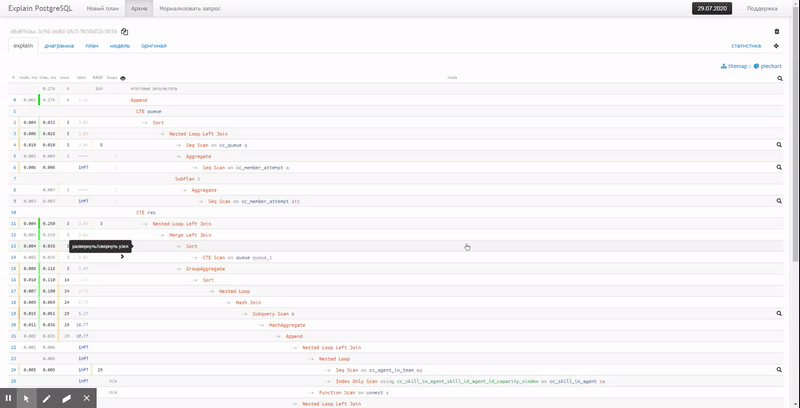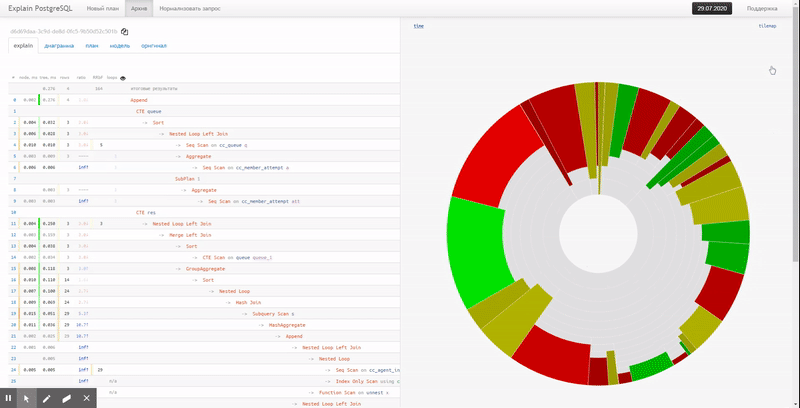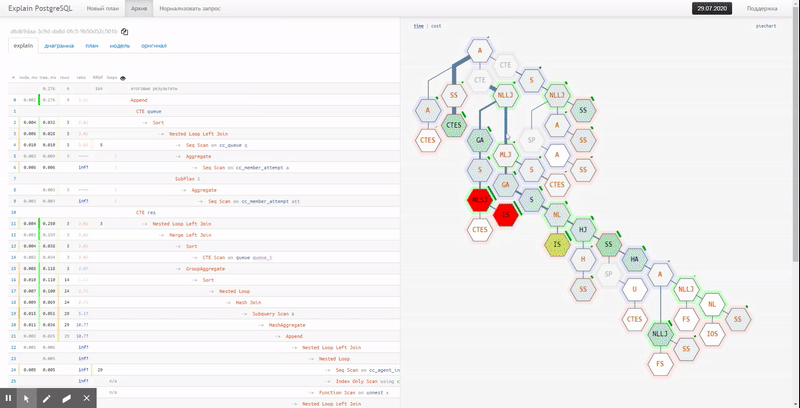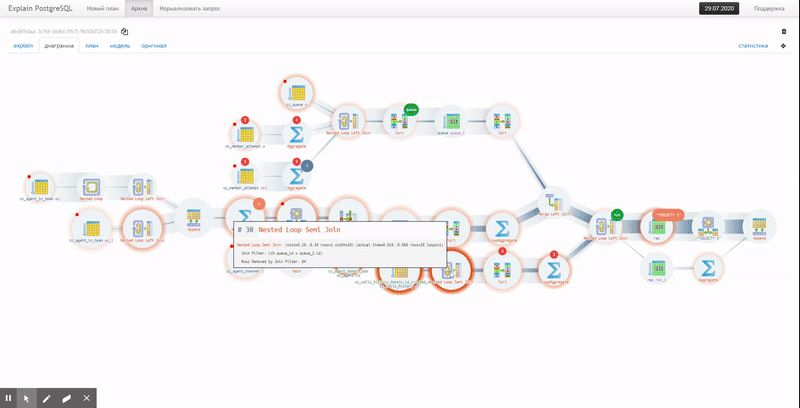
Diagramme d'exécution
Mais ces deux options ne montrent pas la chaîne complète des pièces jointes des nœuds de service
CTE/InitPlain/SubPlan- cela ne peut être vu que dans le diagramme d'exécution réel:

Plus de métriques nécessaires!
Si vous tirez le plan de l'exécution réelle de la requête comme
EXPLAIN (ANALYZE), vous n'y verrez que le temps écoulé . Mais très souvent, cela ne suffit pas pour des conclusions correctes!
Par exemple, en exécutant une requête sur un cache "froid", vous recevrez (mais vous ne verrez pas!) L'heure de réception des données du média, et pas du tout le travail de la requête elle-même.
Par conséquent, quelques recommandations:
- Utilisez pour voir le volume de pages de données soustraites. Cette valeur n'est pratiquement pas sujette aux fluctuations de la charge du serveur lui-même et peut être utilisée comme mesure pour l'optimisation.
EXPLAIN (ANALYZE, BUFFERS) - Utilisez
track_io_timingpour comprendre exactement combien de temps il a fallu pour travailler avec le transporteur .
Et si votre plan contient non seulement du temps , mais aussi
buffersou i/o timings, sur chacune des options du diagramme, vous pouvez passer en mode d'analyse pour ces métriques. Parfois, vous pouvez voir immédiatement, par exemple, que plus de la moitié de toutes les lectures sont tombées sur un seul nœud de problème:

Articles précédents sur le sujet: