Avantages de l'utilisation de TensorFlow.js dans un navigateur
- interactivité - le navigateur dispose de nombreux outils pour visualiser les processus en cours (graphiques, animations, etc.);
- capteurs - le navigateur a un accès direct aux capteurs de l'appareil (appareil photo, GPS, accéléromètre, etc.);
- sécurité des données utilisateur - il n'est pas nécessaire d'envoyer les données traitées au serveur;
- compatibilité avec les modèles créés en Python .
Performance
L'un des principaux problèmes est la performance.
Étant donné que l'apprentissage automatique consiste en fait à effectuer divers types d'opérations mathématiques avec des données matricielles (tenseurs), la bibliothèque pour ce type de calculs dans le navigateur utilise WebGL. Cela améliore considérablement les performances si les mêmes opérations ont été effectuées en JS pur. Naturellement, la bibliothèque a une solution de secours au cas où WebGL n'est pas pris en charge dans le navigateur pour une raison quelconque (au moment de la rédaction de cet article, caniuse montre que 97,94% des utilisateurs ont le support WebGL).
Pour améliorer les performances, Node.js utilise la liaison native avec TensorFlow. Ici, CPU, GPU et TPU ( Tensor Processing Unit ) peuvent servir d'accélérateurs
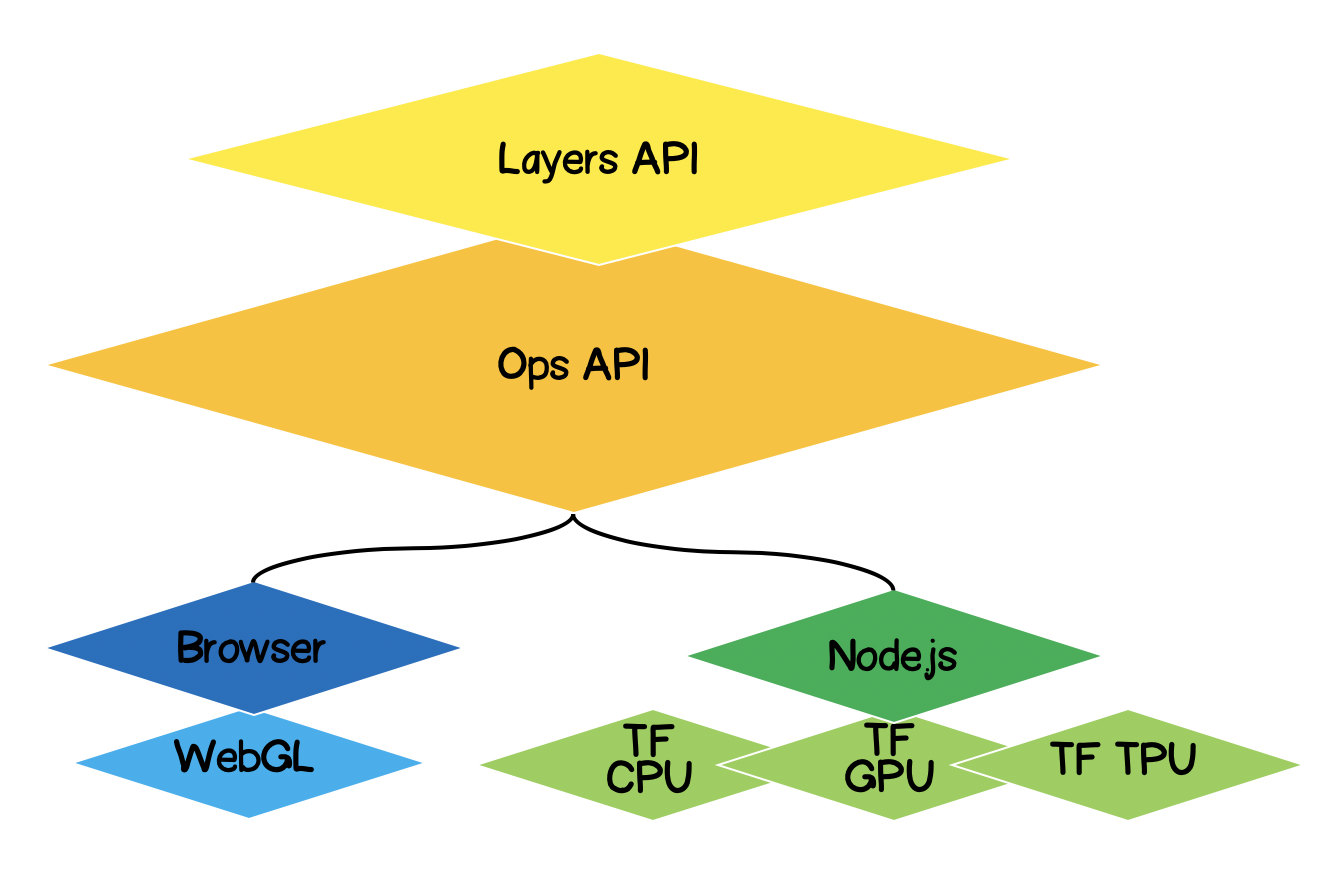
Architecture de TensorFlow.js
- Couche la plus basse - cette couche est responsable de la parallélisation des calculs lors de l'exécution d'opérations mathématiques sur des tenseurs.
- L'API Ops - Fournit une API pour effectuer des opérations mathématiques sur des tenseurs.
- API de couches - vous permet de créer des modèles complexes de réseaux de neurones en utilisant différents types de couches (denses, convolutives). Cette couche est similaire à l'API Keras Python et a la capacité de charger des réseaux Keras Python pré-entraînés.
Formulation du problème
Il est nécessaire de trouver l'équation de la fonction linéaire approximative pour un ensemble donné de points expérimentaux. En d'autres termes, nous devons trouver une telle courbe linéaire qui serait la plus proche des points expérimentaux.

Formalisation de la solution
Le cœur de tout apprentissage automatique sera un modèle, dans notre cas, il s'agit de l'équation d'une fonction linéaire:
En fonction de la condition, nous avons également un ensemble de points expérimentaux:
Supposons que sur -ème étape de la formation, les coefficients suivants de l'équation linéaire ont été calculés ... Nous devons maintenant exprimer mathématiquement la précision des coefficients sélectionnés. Pour ce faire, nous devons calculer l'erreur (perte), qui peut être déterminée, par exemple, par l'écart type. Tensorflow.js propose un ensemble de fonctions de perte couramment utilisées: tf.metrics.meanAbsoluteError , tf.metrics.meanSquaredError et autres.
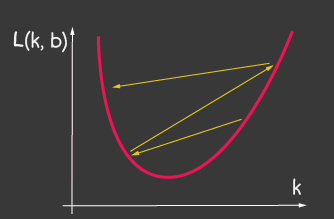
Le but de l'approximation est de minimiser la fonction d'erreur ... Utilisons la méthode de descente de gradient pour cela. Il est nécessaire:
- — -, ;
- — -. , :
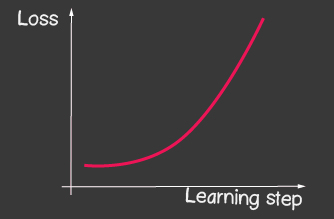
— (learning rate) . . learning rate ( 2), — , 1.
|


|
|---|---|
| 1: (learning-rate) | 2: (learning-rate) |
Tensorflow.js
Par exemple, le calcul de la valeur de la fonction de perte (écart type) ressemblerait à ceci:
function loss(ysPredicted, ysReal) {
const squaredSum = ysPredicted.reduce(
(sum, yPredicted, i) => sum + (yPredicted - ysReal[i]) ** 2,
0);
return squaredSum / ysPredicted.length;
}
Cependant, la quantité de données d'entrée peut être importante. Lors de l'apprentissage du modèle, nous devons calculer non seulement la valeur de la fonction de perte à chaque itération, mais également effectuer des opérations plus sérieuses - le calcul du gradient. Par conséquent, il est judicieux d'utiliser tensorflow, qui optimise les calculs à l'aide de WebGL. De plus, le code devient beaucoup plus expressif, comparez:
function loss(ysPredicted, ysReal) => {
const ysPredictedTensor = tf.tensor(ysPredicted);
const ysRealTensor = tf.tensor(ysReal);
const loss = ysPredictedTensor.sub(ysRealTensor).square().mean();
return loss.dataSync()[0];
};
Solution avec TensorFlow.js
La bonne nouvelle est que nous n'aurons pas à écrire des optimiseurs pour une fonction d'erreur donnée (perte), nous ne développerons pas de méthodes numériques pour calculer les dérivées partielles, nous avons déjà implémenté l'algorithme de rétro-propogation pour nous. Nous avons juste besoin de suivre ces étapes:
- définir un modèle (fonction linéaire, dans notre cas);
- décrire la fonction d'erreur (dans notre cas, il s'agit de l'écart type)
- choisissez l'un des optimiseurs implémentés (il est possible d'étendre la bibliothèque avec votre propre implémentation)
Qu'est-ce que le tenseur
Absolument tout le monde a rencontré des tenseurs en mathématiques - ce sont des tenseurs scalaires, vectoriels, 2D - matrice, 3D - matrice. Un tenseur est un concept généralisé de tout ce qui précède. C'est un conteneur de données qui contient des données de type homogène (tensorflow supporte int32, float32, bool, complex64, string) et a une forme spécifique (le nombre d'axes (rang) et le nombre d'éléments dans chacun des axes). Ci-dessous, nous allons considérer les tenseurs jusqu'aux matrices 3D, mais comme il s'agit d'une généralisation, un tenseur peut avoir autant d'axes que l'on veut: 5D, 6D, ... ND.
TensorFlow a l'API suivante pour la génération de tenseur:
tf.tensor (values, shape?, dtype?)où shape est la forme du tenseur et est donnée par un tableau, dans lequel le nombre d'éléments est le nombre d'axes, et chaque valeur du tableau détermine le nombre d'éléments le long de chacun des axes. Par exemple, pour définir une matrice 4x2 (4 lignes, 2 colonnes), le formulaire prendra la forme [4, 2].
| Visualisation | La description |
|---|---|

|
Rang scalaire : 0 Forme: [] Structure JS: API TensorFlow: |

|
Rang du vecteur : 1 Forme: [4] Structure JS: API TensorFlow: |
 |
Rang de la matrice : 2 Forme: [4,2] Structure JS: API TensorFlow: |
 |
Rang de la matrice : 3 Forme: [4,2,3] Structure JS: API TensorFlow: |
Approximation linéaire avec TensorFlow.js
Dans un premier temps, nous parlerons de rendre le code extensible. On peut transformer l'approximation linéaire en une approximation des points expérimentaux par une fonction de toute nature. La hiérarchie des classes ressemblera à ceci:

Commençons par implémenter les méthodes de la classe abstraite, à l'exception des méthodes abstraites qui seront définies dans les classes enfants, et ici nous ne laisserons que les stubs avec des erreurs, si pour une raison quelconque la méthode n'est pas définie dans la classe enfant.
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
}Ainsi, dans le constructeur du modèle, nous avons défini la largeur et la hauteur - ce sont la largeur et la hauteur réelles du plan sur lequel nous placerons les points expérimentaux. Ceci est nécessaire pour normaliser les données d'entrée. Ceux. si nous avons, puis après normalisation nous aurons:
optimizerFunction - nous allons rendre la tâche de l'optimiseur flexible, afin de pouvoir essayer d'autres optimiseurs disponibles dans la bibliothèque, par défaut, nous avons défini la méthode Stochastic Gradient Descent tf.train.sgd . Je recommanderais également de jouer avec d'autres optimiseurs disponibles qui peuvent modifier le learningRate pendant la formation et le processus d'apprentissage est grandement amélioré, par exemple, essayez les optimiseurs suivants: tf.train.momentum , tf.train.adam .
Afin que le processus d'apprentissage ne se prolonge pas, nous avons défini deux paramètres maxEpochPerTrainSesion et expectedLoss- de cette manière, nous arrêterons le processus d'apprentissage soit lorsque le nombre maximum d'itérations d'apprentissage est atteint, soit lorsque la valeur de la fonction d'erreur devient inférieure à l'erreur attendue (nous prendrons tout en compte dans la méthode train ci-dessous).
Dans le constructeur, nous appelons la méthode initModelVariables - mais comme convenu, nous la stubons et la définissons dans la classe enfant plus tard.
initModelVariables() {
throw Error('Model variables should be defined')
}
Maintenant, implémentons la méthode principale du modèle de train:
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert array into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
trainSession est essentiellement un identifiant unique pour la session de formation au cas où l'API externe appelle la méthode train, alors que la session de formation précédente n'est pas encore terminée.
À partir du code, vous pouvez voir que nous créons tensor1d à partir de tableaux à une dimension, alors que les données doivent être normalisées au préalable, les fonctions de normalisation sont ici:
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
En boucle, pour chaque étape d'entraînement, nous appelons l'optimiseur de modèle, auquel nous devons passer la fonction de perte. Comme convenu, la fonction de perte sera définie par l'écart type. Ensuite, en utilisant l'API tensorflow.js, nous avons:
/**
* Calculate loss function as mean-square deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
// L = sum ((x_pred_i - x_real_i)^2) / N
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
Le processus d'apprentissage se poursuit pendant
- la limite du nombre d'itérations ne sera pas atteinte
- la précision d'erreur souhaitée ne sera pas atteinte
- un nouveau processus de formation n'a pas commencé
Notez également comment la fonction de perte est appelée. Pour obtenir prédictedValue - nous appelons la fonction f - qui, en fait, définira la forme selon laquelle la régression sera effectuée, et dans la classe abstraite, comme convenu, nous mettons un stub:
f(x) {
throw Error('Model should be defined')
}
A chaque étape de l'apprentissage, dans la propriété de l'objet du modèle historique, nous sauvegardons la dynamique du changement d'erreur à chaque époque d'apprentissage.
Après le processus d'apprentissage du modèle, nous devons avoir une méthode qui accepte les entrées et les sorties des sorties calculées à l'aide du modèle entraîné. Pour ce faire, dans l'API, nous avons défini la méthode prédire et cela ressemble à ceci:
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
Faites attention à arraySync , par analogie avec node.js, s'il existe une méthode arraySync , alors il existe certainement une méthode de tableau asynchrone qui renvoie une promesse. Une promesse est nécessaire ici, car comme nous l'avons dit précédemment, les tenseurs sont tous migrés vers WebGL pour accélérer les calculs et le processus devient asynchrone, car il faut du temps pour déplacer les données de WebGL vers une variable JS.
Nous avons terminé avec la classe abstraite, vous pouvez voir la version complète du code ici:
AbstractRegressionModel.js
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
initModelVariables() {
throw Error('Model variables should be defined')
}
f() {
throw Error('Model should be defined')
}
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
/**
* Calculate loss function as mean-squared deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert data into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
stop() {
this.trainSession++;
}
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
}
Pour la régression linéaire, nous définissons une nouvelle classe qui héritera de la classe abstraite, où il suffit de définir deux méthodes initModelVariables et f .
Puisque nous travaillons sur une approximation linéaire, nous devons spécifier deux variables k, b - et ce seront des tenseurs scalaires. Pour l'optimiseur, nous devons indiquer qu'ils sont personnalisables (variables), et attribuer des nombres arbitraires comme valeurs initiales.
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}Considérez l'API pour la variable ici :
tf.variable (initialValue, trainable?, name?, dtype?)Faites attention au deuxième argument de trainable - une variable booléenne et par défaut c'est vrai . Il est utilisé par les optimiseurs, qui leur indique s'il est nécessaire de configurer cette variable lors de la minimisation de la fonction de perte. Cela peut être utile lorsque nous construisons un nouveau modèle basé sur un modèle pré-entraîné téléchargé depuis Keras Python, et nous sommes sûrs qu'il n'est pas nécessaire de recycler certaines couches de ce modèle.
Ensuite, nous devons définir l'équation de la fonction d'approximation à l'aide de l'API tensorflow, jetez un œil au code et vous comprendrez intuitivement comment l'utiliser:
f(x) {
// y = kx + b
return x.mul(this.k).add(this.b);
}Par exemple, de cette façon, vous pouvez définir une approximation quadratique:
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f(x) {
// y = ax^2 + bx + c
return this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}Ici, vous pouvez consulter les modèles de régression linéaire et quadratique:
LinearRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class LinearRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}
f = x => x.mul(this.k).add(this.b);
}
QuadraticRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class QuadraticRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f = x => this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}
Vous trouverez ci-dessous un code écrit en React qui utilise le modèle de régression linéaire écrit et crée l'UX pour l'utilisateur:
Regression.js
import React, { useState, useEffect } from 'react';
import Canvas from './components/Canvas';
import LossPlot from './components/LossPlot_v3';
import LinearRegressionModel from './model/LinearRegressionModel';
import './RegressionModel.scss';
const WIDTH = 400;
const HEIGHT = 400;
const LINE_POINT_STEP = 5;
const predictedInput = Array.from({ length: WIDTH / LINE_POINT_STEP + 1 })
.map((v, i) => i * LINE_POINT_STEP);
const model = new LinearRegressionModel(WIDTH, HEIGHT);
export default () => {
const [points, changePoints] = useState([]);
const [curvePoints, changeCurvePoints] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
if (points.length > 0) {
const input = points.map(({ x }) => x);
const output = points.map(({ y }) => y);
model.train(input, output, () => {
changeCurvePoints(() => model.predict(predictedInput));
changeLossHistory(() => model.history);
});
}
}, [points]);
return (
<div className="regression-low-level">
<div className="regression-low-level__top">
<div className="regression-low-level__workarea">
<div className="regression-low-level__canvas">
<Canvas
width={WIDTH}
height={HEIGHT}
points={points}
curvePoints={curvePoints}
changePoints={changePoints}
/>
</div>
<div className="regression-low-level__toolbar">
<button
className="btn btn-red"
onClick={() => model.stop()}>Stop
</button>
<button
className="btn btn-yellow"
onClick={() => {
model.stop();
changePoints(() => []);
changeCurvePoints(() => []);
}}>Clear
</button>
</div>
</div>
<div className="regression-low-level__loss">
<LossPlot
loss={lossHistory}/>
</div>
</div>
</div>
)
}Résultat:
Je recommande vivement d'effectuer les tâches suivantes:
- pour implémenter l'approximation de fonction par la fonction logarithmique
- pour l'optimiseur tf.train.sgd, essayez de jouer avec learningRate et observez comment le processus d'apprentissage change. Essayez de définir le learningRate très grand pour obtenir l'image illustrée à la figure 2.
- définissez l'optimiseur sur tf.train.adam. Le processus d'apprentissage s'est-il amélioré? Si le processus d'apprentissage dépend de la modification de la valeur learningRate dans le constructeur de modèle.