
Photo du site Unsplash . Auteur: Hitesh Choudhary
Obtenir le même résultat en Python qu'avec une requête SQL
Souvent, lorsque nous travaillons sur le même projet, nous devons basculer entre SQL et Python. Cela étant dit, certains d'entre nous connaissent la manipulation des données dans les requêtes SQL, mais pas en Python, ce qui nuit à notre efficacité et à notre productivité. En fait, en utilisant Pandas, vous pouvez obtenir le même résultat en Python que dans les requêtes SQL.
Début des travaux
Vous devez installer le package Pandas s'il n'y est pas.
conda install pandasNous utiliserons le célèbre jeu de données Titanic de Kaggle .
Après avoir installé le package et téléchargé les données, nous devons l'importer dans notre environnement Python.

Nous utiliserons un DataFrame pour stocker des données. Diverses fonctions Pandas nous aideront à gérer cette structure de données.
SELECT, DISTINCT, COUNT, LIMIT
Commençons par des requêtes SQL simples que nous utilisons beaucoup.
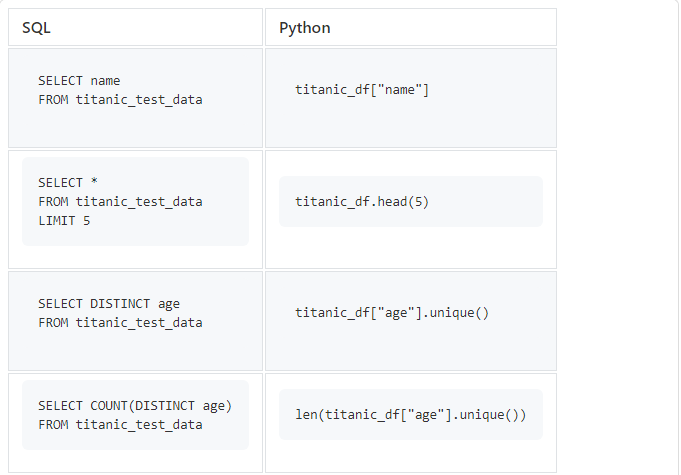
titanic_df["age"].unique()renverra un tableau de valeurs uniques, nous devrons donc utiliser len()pour compter leur nombre.
SELECT, WHERE, OR, AND, IN (SELECT avec conditions)
Après la première partie, vous avez appris à explorer un DataFrame de manière simple. Essayons maintenant de le faire avec certaines conditions (c'est une instruction
WHEREen SQL).

Si nous voulons uniquement sélectionner des colonnes spécifiques du DataFrame, nous pouvons le faire avec une paire supplémentaire de crochets.
Remarque: si vous sélectionnez plusieurs colonnes, vous devez placer le tableau
["name","age"]entre crochets.
isin()fonctionne exactement de la même manière que INdans les requêtes SQL. Pour l'utiliser NOT IN, en Python, nous devons utiliser la négation (~).
GROUP BY, ORDER BY, COUNT
GROUP BYet ORDER BYsont également des instructions SQL populaires pour l'exploration de données. Essayons maintenant de les utiliser en Python.

Si nous voulons trier une seule colonne COUNT, nous pouvons simplement passer une valeur booléenne à la méthode
sort_values. Si nous allons trier plusieurs colonnes, nous devons passer un tableau de booléens à la méthode sort_values.
La méthode
sum()renvoie les sommes pour chacune des colonnes du DataFrame, qui peuvent être agrégées numériquement. Si nous ne voulons qu'une colonne spécifique, nous devons spécifier le nom de la colonne en utilisant des crochets.
MIN, MAX, MOYEN, MOYEN
Enfin, essayons certaines des fonctions statistiques standard qui sont importantes lors de l'exploration de données.
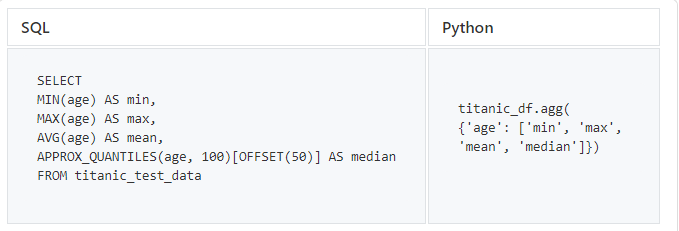
SQL ne contient pas d'opérateurs qui renvoient la valeur médiane, nous utilisons donc BigQuery pour obtenir la valeur médiane de la colonne d'âge.Dans
APPROX_QUANTILES
Pandas, la méthode d'agrégation
.agg()prend également en charge d'autres fonctions, par exemple sum.
Vous avez maintenant appris à réécrire des requêtes SQL en Python à l'aide de Pandas . J'espère que vous trouverez cet article utile.
Tout le code se trouve dans mon référentiel Github .
Merci de votre attention!