Partie 2
Partie 3
Dans cet article, vous apprendrez:
- Qu'est-ce que l' apprentissage par transfert et comment cela fonctionne
- Qu'est-ce que la segmentation sémantique / d'instance et comment cela fonctionne
- À propos de la détection d'objets et de son fonctionnement
introduction
Pour les tâches de détection d'objets, deux méthodes sont distinguées (voir la source et plus de détails ici ):
- Méthodes à deux étapes, ce sont aussi des «méthodes basées sur les régions» (ing. Méthodes basées sur les régions) - une approche divisée en deux étapes. Dans un premier temps, par recherche sélective ou en utilisant une couche spéciale du réseau neuronal, des régions d'intérêt (RoI) sont identifiées - des régions avec une forte probabilité de contenir des objets. À la deuxième étape, les régions sélectionnées sont considérées par le classifieur pour déterminer l'appartenance aux classes d'origine et par le régresseur, qui spécifie l'emplacement des boîtes englobantes.
- Méthode en une étape (méthodes en une étape Engl.) - approche, ne pas utiliser un algorithme séparé pour générer des régions à la place, prédire les coordonnées d'une certaine quantité de boîtes englobantes avec des caractéristiques différentes, telles que les résultats de classification et le degré de confiance, et ajuster davantage le cadre de localisation.
Cet article décrit les méthodes en une étape.
Apprentissage par transfert
L'apprentissage par transfert est une méthode d'apprentissage des réseaux de neurones, dans laquelle nous prenons un modèle déjà formé sur certaines données pour une formation supplémentaire supplémentaire afin de résoudre un autre problème. Par exemple, nous avons un modèle EfficientNet-B5 formé sur un ensemble de données ImageNet (1000 classes). Maintenant, dans le cas le plus simple, nous changeons sa dernière couche de classification (par exemple, pour classer les objets de 10 classes).
Regardez l'image ci-dessous:
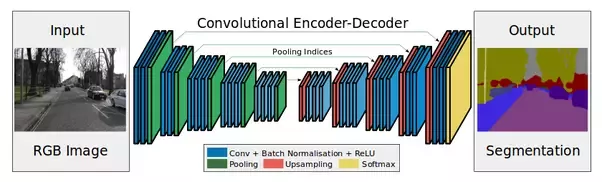
Encodeur - ce sont des couches de sous-échantillonnage (convolutions et pools).
Le remplacement de la dernière couche du code ressemble à ceci (framework - pytorch, environnement - google colab):
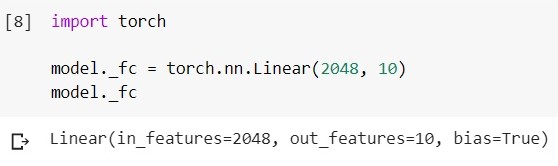
Chargez le modèle EfficientNet-b5 entraîné et regardez sa couche de classification:

changez cette couche en une autre: le
décodeur est nécessaire, en particulier, dans la tâche de segmentation (à propos de Plus loin).
Transférer des stratégies d'apprentissage
Il convient d'ajouter que par défaut, toutes les couches du modèle que nous souhaitons entraîner davantage peuvent être entraînées. Nous pouvons "geler" les poids de certaines couches.
Pour geler toutes les couches:

moins nous entraînons de couches, moins nous avons besoin de ressources de calcul pour entraîner le modèle. Cette technique est-elle toujours justifiée?
En fonction de la quantité de données sur laquelle nous voulons former le réseau, et des données sur lesquelles le réseau a été formé, il existe 4 options pour le développement d'événements pour l'apprentissage par transfert (sous "peu" et "beaucoup" vous pouvez prendre la valeur conditionnelle 10k):
- Vous disposez de peu de données et elles sont similaires aux données sur lesquelles le réseau a été formé auparavant. Vous pouvez essayer de n'entraîner que les dernières couches.
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
La segmentation sémantique est lorsque nous alimentons une image en entrée, et à la sortie, nous voulons obtenir quelque chose comme:

Plus formellement, nous voulons classer chaque pixel de notre image d'entrée - pour comprendre à quelle classe il appartient.
Il y a beaucoup d'approches et de nuances ici. Qu'est-ce que l'architecture du réseau ResNeSt-269 :)
Intuition - en entrée l'image (h, w, c), en sortie on veut obtenir un masque (h, w) ou (h, w, c), où c est le nombre de classes (dépend de données et modèle). Ajoutons maintenant un décodeur après notre encodeur et formons-les.
Le décodeur sera notamment constitué de couches de suréchantillonnage. Vous pouvez augmenter la dimension simplement en "étirant" notre carte des caractéristiques en hauteur et en largeur à une étape ou à une autre. En tirant, vous pouvez utiliserinterpolation bilinéaire (dans le code, ce ne sera qu'un des paramètres de la méthode).
Architecture réseau Deeplabv3 +:
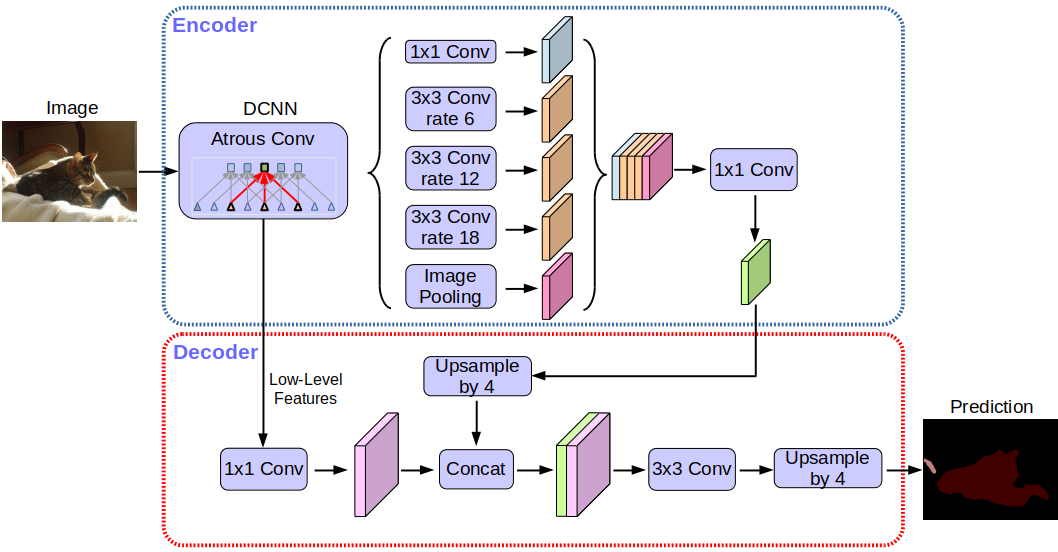
Sans entrer dans les détails, vous remarquerez que le réseau utilise l'architecture encodeur-décodeur.
Une version plus classique, l'architecture du réseau U-net:
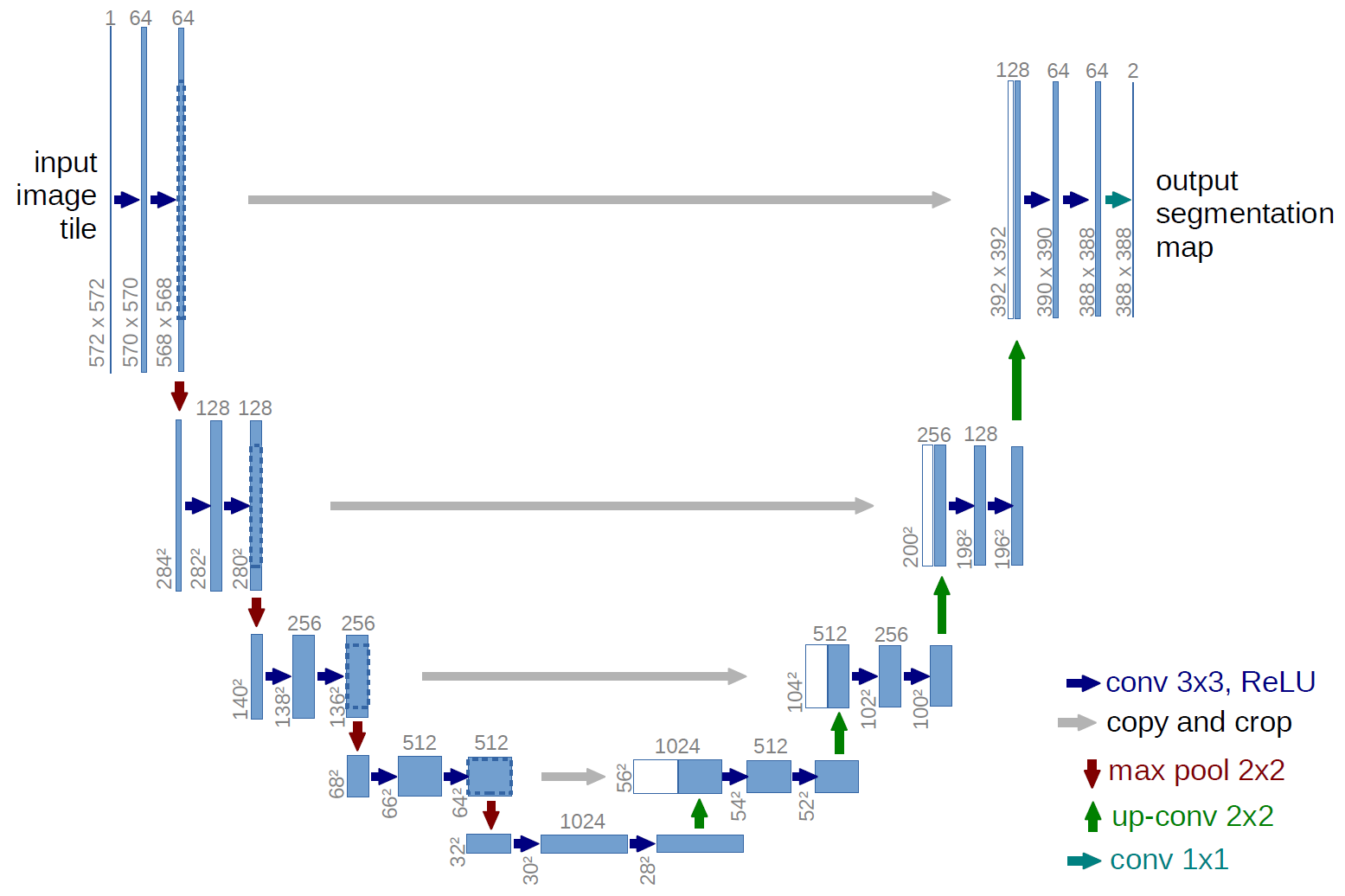
quelles sont ces flèches grises? Ce sont les soi-disant connexions de saut. Le fait est que l'encodeur «code» notre image d'entrée avec perte. Afin de minimiser ces pertes, ils utilisent des connexions par sauts.
Dans cette tâche, nous pouvons utiliser l'apprentissage par transfert - par exemple, nous pouvons prendre un réseau avec un encodeur déjà entraîné, ajouter un décodeur et le former.
Sur quelles données et quels modèles fonctionnent le mieux dans cette tâche pour le moment - vous pouvez voir ici...
Segmentation d'instance
Une version plus complexe du problème de segmentation. Son essence est que nous voulons non seulement classer chaque pixel de l'image d'entrée, mais aussi sélectionner en quelque sorte différents objets de la même classe:
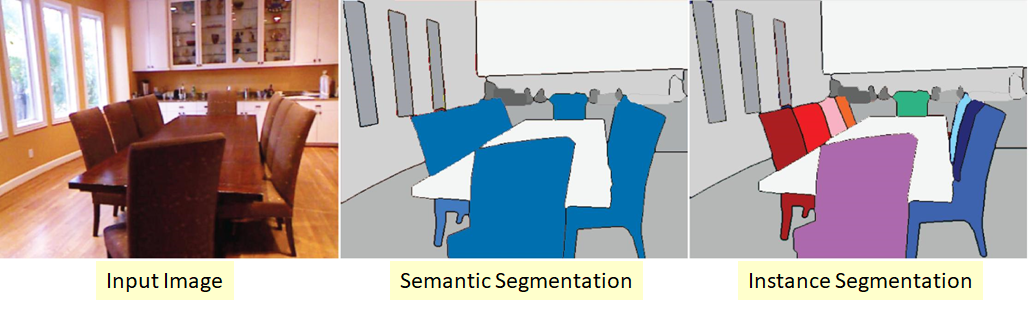
il se trouve que les classes sont "collantes" ou qu'il n'y a pas de frontière visible entre elles, mais nous voulons délimiter les objets de la même classe une part.
Il existe également plusieurs approches ici. Le plus simple et le plus intuitif est que nous formons deux réseaux différents. Nous apprenons au premier à classer les pixels pour certaines classes (segmentation sémantique), et au second à classer les pixels entre les objets de classe. Nous obtenons deux masques. Maintenant, nous pouvons soustraire le second du premier et obtenir ce que nous voulions :)
Sur quelles données et quels modèles fonctionnent le mieux dans cette tâche pour le moment - vous pouvez voir ici...
Object detection
Nous envoyons une image à l'entrée, et à la sortie, nous voulons voir quelque chose comme:

La chose la plus intuitive qui puisse être faite est de «parcourir» l'image avec différents rectangles et, en utilisant un classificateur déjà entraîné, de déterminer s'il y a un objet qui nous intéresse dans ce domaine. Il existe un tel système, mais ce n'est évidemment pas le meilleur. Nous avons des couches convolutives qui interprètent en quelque sorte la carte des caractéristiques "avant" (A) dans la carte des caractéristiques "après" (B). Dans ce cas, on connaît les dimensions des filtres de convolution => on sait quels pixels de A vers quels pixels B ont été convertis.
Jetons un coup d'œil à YOLO v3:
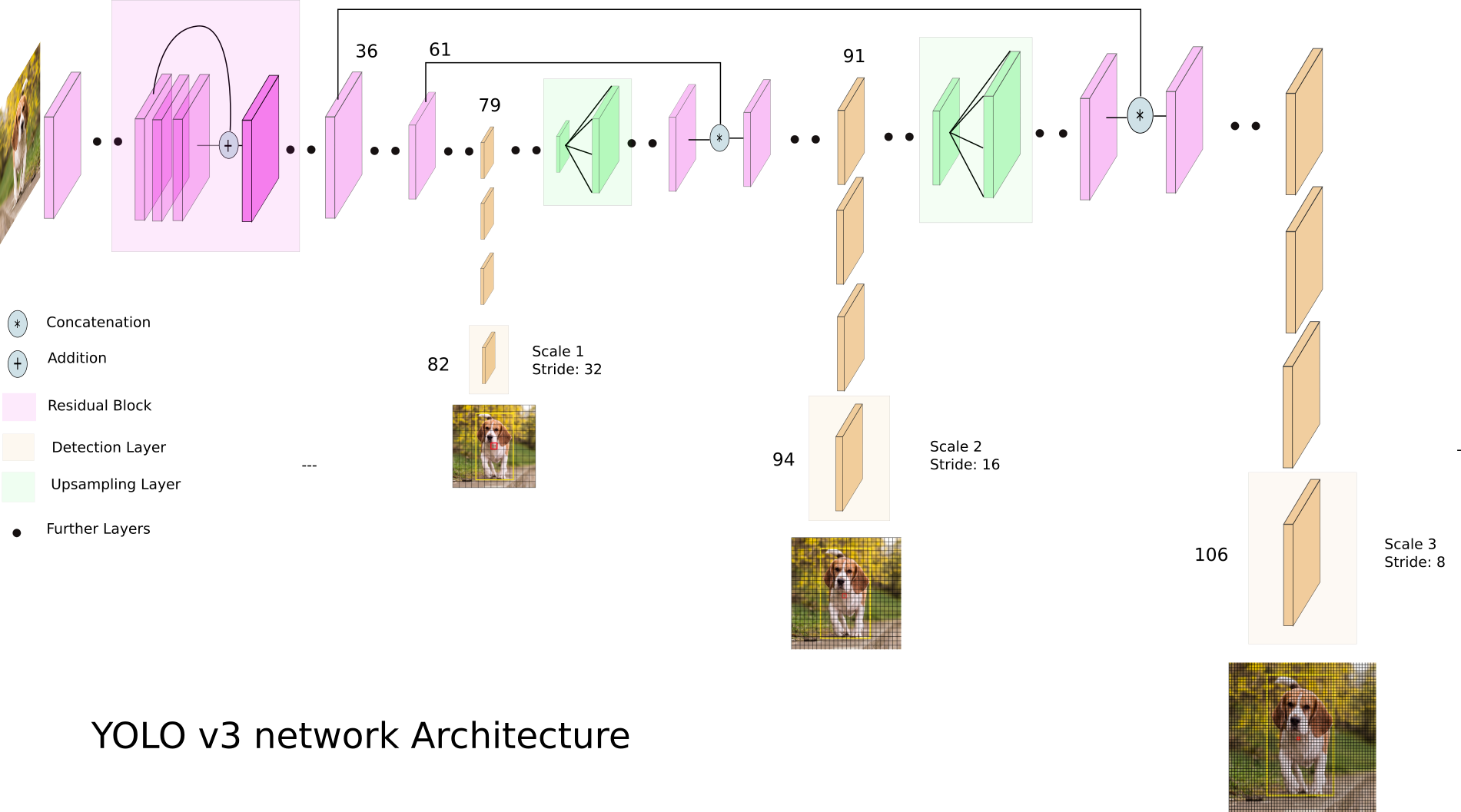
YOLO v3 utilise différentes cartes d'entités dimensionnelles. Ceci est fait, en particulier, afin de détecter correctement des objets de différentes tailles.
Ensuite, les trois échelles sont concaténées:
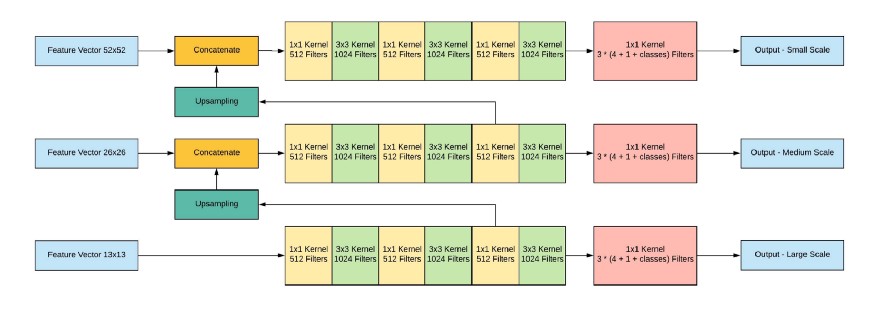
Sortie réseau, avec une image d'entrée de 416x416, 13x13x (B * (5 + C)), où C est le nombre de classes, B est le nombre de boîtes pour chaque région (YOLO v3 en a 3). 5 - ce sont des paramètres tels que: Px, Py - coordonnées du centre de l'objet, Ph, Pw - hauteur et largeur de l'objet, Pobj - la probabilité que l'objet se trouve dans cette région.
Regardons l'image, donc ce sera un peu plus clair:

YOLO filtre les données de prédiction initialement par score d'objectivité d'une certaine valeur (généralement 0,5-0,6), puis par suppression non maximale .
Sur quelles données et quels modèles fonctionnent le mieux dans cette tâche pour le moment - vous pouvez voir ici .
Conclusion
Il existe de nombreux modèles et approches différents des tâches de segmentation et de localisation d'objets de nos jours. Il y a certaines idées qui, une fois comprises, faciliteront le démontage de ce zoo de modèles et d'approches. J'ai essayé d'exprimer ces idées dans cet article.
Dans les prochains articles, nous parlerons des transferts de style et des GAN.