
Je m'appelle Alexander Deulin, je travaille dans le département de développement de notre propre développement "Factory of Microservices" chez MegaFon. Et je veux vous parler du chemin épineux de l'émergence des caches Tarantool dans le paysage de notre entreprise, ainsi que de la façon dont nous avons mis en œuvre la réplication à partir d'Oracle. Et j'expliquerai immédiatement que dans ce cas, le cache signifie une application avec une base de données.
Caches Tarantool
Nous avons déjà beaucoup parlé de la façon dont nous avons mis en œuvre la facturation unifiée chez MegaFon , nous ne nous attarderons pas là-dessus en détail, mais maintenant le projet est en phase d'achèvement. Par conséquent, juste un peu de statistiques:
avec ce que nous avons abordé notre tâche:
- 80 millions d'abonnés;
- 300 millions de profils d'abonnés;
- 2 milliards d'événements transactionnels pour modifier le solde par jour;
- 250 To de données actives;
- > 8 Po d'archives;
- et tout cela est situé sur 5000 serveurs dans différents centres de données.
Autrement dit, nous parlons d'un système très chargé, dans lequel chaque sous-système a commencé à desservir 80 millions d'abonnés. Si auparavant nous avions 7 instances et une mise à l'échelle horizontale conditionnelle, nous sommes maintenant passés au domaine. Il y avait autrefois un monolithe, mais maintenant nous avons DDD. Le système est bien couvert par l'API, divisé en sous-systèmes, mais pas partout où il y a un cache. Nous sommes maintenant confrontés au fait que les sous-systèmes créent une charge toujours croissante. De plus, de nouveaux canaux apparaissent, qui nécessitent de leur fournir 5000 requêtes par seconde et par opération avec une latence de 50 ms dans 95% des cas, et d'assurer une disponibilité au niveau de 99,99%.
En parallèle, nous avons commencé à créer une architecture de microservices.

Nous avons une couche séparée de caches dans laquelle les données de chaque sous-système sont levées. Cela facilite l'assemblage des composites et isole les systèmes maîtres des lourdes charges de travail de lecture.
Comment créer un cache pour les sous-systèmes fermés?
Nous avons décidé que nous devions créer des caches nous-mêmes, sans compter sur le fournisseur. La facturation unifiée est un écosystème fermé. Il contient de nombreux modèles de microservices, qui ont de nombreuses API et leurs propres bases de données. Cependant, en raison de la nature fermée, il est impossible de modifier quoi que ce soit.
Nous avons commencé à réfléchir à la manière dont nous pouvons aborder nos systèmes maîtres. Une approche très populaire est la conception événementielle, lorsque nous recevons des données d'un type de bus: soit il s'agit d'un sujet Kafka, soit l'échange de RabbitMQ. Vous pouvez également obtenir des données d'Oracle: par déclencheurs, en utilisant CQN (un outil gratuit d'Oracle) ou Golden Gate. Étant donné que nous ne pouvons pas intégrer l'application, les options d'écriture directe et d'écriture différée ne nous étaient pas disponibles.
Réception des données du bus du répartiteur de messages
Nous aimons vraiment l'option avec les files d'attente et les gestionnaires de messages. RabbitMQ et Kafka sont déjà utilisés dans la "facturation unifiée". Nous avons piloté l'un des systèmes et obtenu un excellent résultat. Nous recevons tous les événements de RabbitMQ et effectuons un chargement à froid, la quantité de données n'est pas très grande.
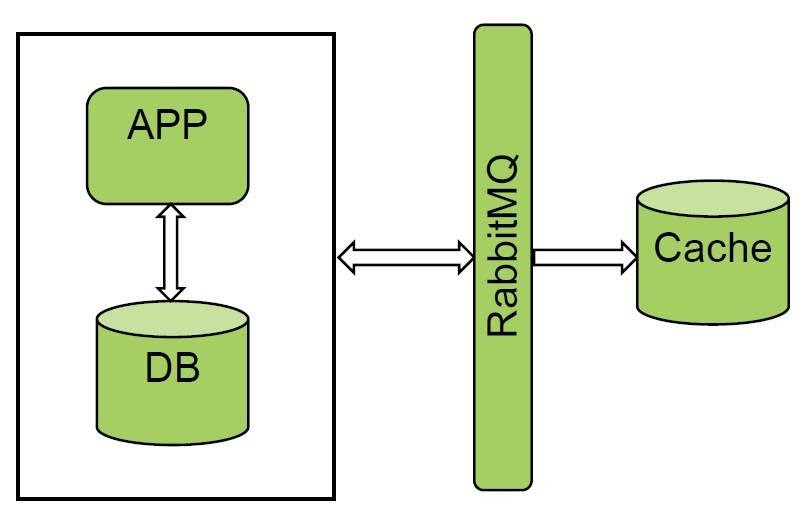
La solution fonctionne bien, mais tous les systèmes ne peuvent pas notifier les bus, donc cette option n'a pas fonctionné pour nous.
Récupération des données de la base de données: déclencheurs
Il y avait encore un moyen d'obtenir des données pour remplir le cache à partir de la base de données.
L'option la plus simple est les déclencheurs. Mais ils ne conviennent pas aux applications à forte charge, car, d'une part, nous modifions le système maître lui-même, et d'autre part, il s'agit d'un point de défaillance supplémentaire. Si le déclencheur était soudainement incapable d'écrire sur une sorte de plaque temporaire, nous obtenons une dégradation complète, y compris le système maître.

Récupération des données de la base de données: CQN
La deuxième option pour obtenir des données de la base de données. Nous utilisons Oracle, et le fournisseur ne prend actuellement en charge qu'un seul outil gratuit pour obtenir des données de la base de données - CQN.
Ce mécanisme vous permet de vous abonner aux notifications de modification d'opération DDL ou DML. Tout y est assez simple. Il existe des notifications de style JDBC et PL / SQL.
JDBC signifie que nous notifions la file d'attente avancée et que cet événement est envoyé au système externe. En fait, un connecteur OSI externe est nécessaire. Nous n'avons pas aimé cette option, car si nous perdons notre connexion avec Oracle, nous ne pouvons pas lire notre message.
Nous avons choisi PL / SQL car il nous permet d'intercepter la notification et de la stocker dans une table temporaire dans la même base de données Oracle. Autrement dit, de cette manière, vous pouvez fournir une certaine intégrité transactionnelle.
Tout a bien fonctionné au début jusqu'à ce que nous pilotions une base assez chargée. Les lacunes suivantes sont apparues:
- Charge transactionnelle sur la base. Lorsque nous interceptons un message de la file d'attente de notification, nous devons le mettre dans la base. Autrement dit, la charge d'écriture double.
- Il utilise également une file d'attente avancée interne. Et si votre système maître l'utilise également, la concurrence pour la file d'attente peut survenir.
- Nous avons eu une erreur intéressante sur les tables partitionnées. Si une validation ferme plus de 100 modifications, CQN ne détecte pas ces modifications. Nous avons ouvert un ticket dans Oracle, modifié les paramètres système - cela n'a pas aidé.
Pour les applications lourdes, CQN n'est certainement pas adapté. C'est bon pour les petites installations, pour travailler avec des types de dictionnaires, des données de référence.
Récupération des données de la base de données: Golden Gate
Le bon vieux Golden Gate demeure. Au départ, nous ne voulions pas l'utiliser, puisqu'il s'agit d'une solution à l'ancienne, nous avons été intimidés par la complexité du système lui-même.

Dans GG lui-même, il y avait deux instances supplémentaires qui devaient être maintenues, et nous n'avons pas beaucoup de connaissances Oracle. Au départ, c'était assez difficile, même si nous avons vraiment aimé les possibilités de la solution.
La combinaison SCN + XID nous a permis de surveiller l'intégrité transactionnelle. La solution s'est avérée universelle, elle a un faible impact sur le système maître à partir duquel nous pouvons recevoir tous les événements. Bien que la solution nécessite l'achat d'une licence, cela ne nous a pas posé de problème puisque la licence était déjà disponible. De plus, les inconvénients de la solution incluent une implémentation complexe et le fait que GG est un sous-système supplémentaire.
conclusions
Quelles conclusions peut-on tirer de ce qui précède?
Si vous avez un système fermé, vous devez rechercher la nature de votre charge et les modes d'utilisation, puis sélectionner la solution appropriée. L'optimal, à notre avis, est la conception événementielle, lorsque nous notifions un sujet dans Kafka, et le courtier de messages devient le système maître. Un sujet est un record d'or, le reste des données est pris par le système. Pour les systèmes fermés de notre paysage, GG s'est avéré être la solution la plus réussie.
PIM - vitrine alimentaire
Et maintenant, en utilisant l'exemple de l'un des produits, je vais vous dire comment nous avons appliqué cette solution. PIM est une vitrine de produits basée sur SID. Autrement dit, ce sont tous les produits de l'abonné qui lui sont actuellement connectés. Sur leur base, les dépenses sont calculées et la logique de travail est construite.
Architecture
Permettez-moi de vous rappeler que dans cet article, «cache» signifie une combinaison d'une application et d'une base de données, c'est le principal modèle d'utilisation de Tarantool.
La particularité du projet PIM est que le système maître Oracle d'origine est "petit", seulement 10 milliards d'enregistrements. Il doit être lu. Et le plus gros problème que nous avons résolu était le réchauffement du cache.
Où avons-nous commencé?

Les 10 tableaux principaux donnent 10 milliards d'enregistrements. Nous voulions les lire de front. Puisque nous ne levons que les données chaudes dans le cache et qu'Oracle stocke, entre autres, des données historiques, nous avons dû définir une clause where et extraire ces 10 milliards. Une tâche non triviale. Oracle nous a dit que cela ne devrait pas être fait: il a augmenté la charge du processeur à 100%. Nous avons décidé d'aller dans l'autre sens.
Mais d'abord, quelques mots sur l'architecture du cluster.
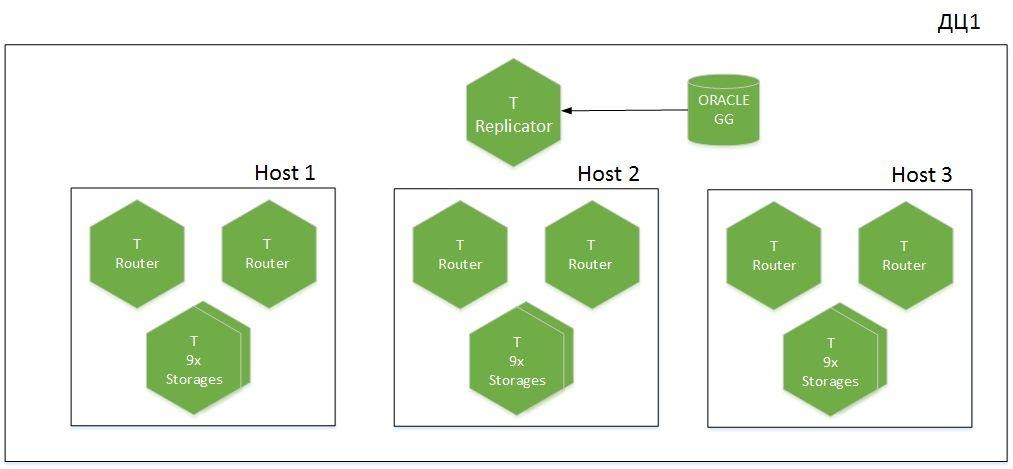
Il s'agit d'une application partitionnée, 9 fragments dans 6 hôtes, répartis sur deux centres de données. Nous avons Tarantool avec le rôle de Replicator, qui reçoit des données d'Oracle, et une autre instance appelée Importer est utilisée pour le démarrage à froid. Un total de 1,1 To de données chaudes est généré dans le cache.
Démarrage à froid
Comment avons-nous résolu le problème du démarrage à froid? Tout s'est avéré assez trivial.

Comment fonctionne tout le mécanisme? Nous avons supprimé la clause where et tout lu. Tout d'abord, nous démarrons le flux de journalisation pour recevoir réellement les modifications en ligne de la base de données. Par analyse complète, nous parcourons des sous-sections, en prenant les données par lots avec normalisation et filtrage. Nous enregistrons les modifications, commençons simultanément à réchauffer à froid le cache et téléchargeons tout dans des fichiers CSV. Il y a 10 instances Importer en cours d'exécution dans le cache, qui, après avoir été lues à partir d'Oracle, envoient des données aux instances Tarantool. Pour ce faire, chaque importateur calcule la partition requise et place les données dans le stockage nécessaire lui-même, sans charger les routeurs.
Après avoir chargé toutes les données d'Oracle, nous lisons le flux de sentiers de GG qui se sont accumulés pendant ce temps. Lorsque SCN + XID atteint des valeurs acceptables avec le système maître, nous considérons que le cache est réchauffé et activons la charge lors de la lecture à partir de systèmes externes.
Quelques statistiques. Chez Oracle, nous disposons d'environ 2,5 To de données brutes. Nous les lisons pendant 5 heures, les importons en CSV. Le chargement dans Tarantool avec filtrage et normalisation prend 8 heures. Et pendant six heures, nous jouons les journaux accumulés qui nous viennent du sentier. Vitesse de pointe à partir de 600 mille enregistrements / s. jusqu'à 1 million de pics. Tarantool insère 1,1 To de données à 200 000 enregistrements / s.
Désormais, le réchauffement à froid du cache sur de gros volumes est devenu courant pour nous, car nous n'avons pas beaucoup d'impact sur Oracle.

Au lieu de la base, nous chargeons les E / S et le réseau, nous devons donc d'abord nous assurer que nous avons une marge suffisante de bande passante réseau, dans nos pics elle atteint 400 Mbps.
Fonctionnement de la chaîne de réplication d'Oracle vers Tarantool
Lors de la conception du cache, nous avons décidé d'économiser de la mémoire. Nous avons supprimé toute redondance, combiné cinq tables en une seule et obtenu un système de stockage très compact, mais nous avons perdu le contrôle de la cohérence. Nous sommes arrivés à la conclusion qu'il est nécessaire de répéter le DDL d'Oracle. Cela nous a permis de contrôler les SCN + XID en les stockant dans un espace technologique distinct pour chaque plaque. En les vérifiant périodiquement, nous pouvons comprendre où la réplication est tombée en panne, et en cas de problème, relire les journaux d'archivage.
Sharding
Un peu sur le stockage logique des données. Pour éliminer Map Reduce, nous avons dû introduire une redondance de données supplémentaire et décomposer les dictionnaires dans nos propres stockages. Nous avons choisi cela délibérément, car notre cache fonctionne principalement pour la lecture. Nous ne pouvons pas l'intégrer dans le système maître, car cette application isole la charge des canaux externes du système maître. Nous lisons toutes les données sur les abonnés à partir d'un stockage. Dans ce cas, nous perdons en performance d'écriture, mais ce n'est pas si important pour nous, les dictionnaires sont mis à jour rarement.
Ce qui est arrivé à la fin?
Nous avons créé un cache pour notre système fermé. Il y a eu des erreurs de filtrage, mais nous les avons déjà corrigées. Nous nous sommes préparés à l'émergence de nouveaux consommateurs à forte charge. L'été dernier, un nouveau système est apparu, qui a ajouté 5 à 10 000 requêtes par seconde, et nous n'avons pas laissé cette charge dans la «facturation unifiée». Nous avons également appris comment préparer la réplication d'Oracle vers Tarantool, travaillé sur le transfert de grandes quantités de données sans charger le système maître.
Que devons-nous encore faire?
Ce sont principalement des scénarios opérationnels:
- Contrôle automatique de la cohérence des données.
- Élaborez le script de basculement Oracle Active-Standby, à la fois basculement et basculement.
- Lecture des journaux d'archive depuis GG.
- — DDL- -. , DDL , .
- «»: ? https://habr.com/ru/article/470842/
- : Tarantool https://habr.com/ru/company/mailru/blog/455694/
- Telegram Tarantool https://t.me/tarantool_news
- Tarantool - https://t.me/tarantoolru