
Quand j'ai commencé ma carrière en tant que développeur, mon premier emploi était un DBA (administrateur de base de données, DBA). Au cours de ces années, même avant AWS RDS, Azure, Google Cloud et d'autres services cloud, il existait deux types de DBA:
- , . « », , .
- : , , SQL. ETL- . , .
Les administrateurs de base de données d'applications font généralement partie des équipes de développement. Ils avaient une connaissance approfondie d'un sujet spécifique, de sorte qu'ils ne travaillaient généralement que sur un ou deux projets. Les administrateurs de base de données d'infrastructure faisaient généralement partie de l'équipe informatique et pouvaient travailler sur plusieurs projets en même temps.
Je suis l'administrateur de la base de données des applications
Je n'ai jamais eu envie de jouer avec les sauvegardes ou de modifier le stockage (je suis sûr que c'est amusant!). À ce jour, j'aime dire que je suis un administrateur DB qui sait comment développer des applications, pas un développeur qui comprend les bases de données.
Dans cet article, je vais partager quelques-unes des astuces de développement de bases de données que j'ai apprises au cours de ma carrière.
Contenu:
- Mettre à jour uniquement ce qui doit être mis à jour
- Désactiver les contraintes et les index pour les charges lourdes
- Utiliser des tables NON LOGGÉES pour les données intermédiaires
- Implémentez des processus entiers avec WITH et RETURNING
- Évitez les indices dans les colonnes à faible sélectivité
- Utiliser des index partiels
- Toujours charger les données triées
- Index des colonnes hautement corrélées avec BRIN
- Rendre les index "invisibles"
- Ne planifiez pas de longs processus pour démarrer au début d'une heure
- Conclusion
Mettre à jour uniquement ce qui doit être mis à jour
L'opération
UPDATEconsomme beaucoup de ressources. La meilleure façon de l'accélérer est de mettre à jour uniquement ce qui doit être mis à jour.
Voici un exemple de demande de normalisation d'une colonne d'e-mail:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
Ça a l'air innocent, non? La demande met à jour les adresses électroniques de 1 010 000 utilisateurs. Mais toutes les lignes doivent-elles être mises à jour?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
Seules 10 000 lignes ont dû être mises à jour. En réduisant la quantité de données traitées, nous avons réduit le temps d'exécution de 1,5 seconde à moins de 300 ms. Cela nous évitera également des efforts supplémentaires pour maintenir la base de données.
Mettez à jour uniquement ce qui doit être mis à jour.
Ce type de mise à jour volumineuse est très courant dans les scripts de migration de données. La prochaine fois que vous écrivez un script comme celui-ci, assurez-vous de ne mettre à jour que ce qui est nécessaire.
Désactiver les contraintes et les index pour les charges lourdes
Les contraintes sont un élément important des bases de données relationnelles: elles préservent la cohérence et la fiabilité des données. Mais tout a son propre prix, et le plus souvent, vous devez payer lors du chargement ou de la mise à jour d'un grand nombre de lignes.
Définissons un petit schéma de stockage:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
Il définit différents types de contraintes telles que "non nul" ainsi que des contraintes uniques ...
Pour définir le point de départ, commençons par ajouter
saledes clés étrangères à la table
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
Après avoir défini les contraintes et les index, le chargement d'un million de lignes dans la table a pris environ 15,4 secondes.
Maintenant, commençons par charger les données dans la table, puis ajoutons ensuite des contraintes et des index:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
Le chargement était beaucoup plus rapide, 2,27 secondes. au lieu de 15,4. Les index et les limites ont été créés beaucoup plus longtemps après le chargement des données, mais l'ensemble du processus a été beaucoup plus rapide: 3,1 s. au lieu de 15,4.
Malheureusement, dans PostgreSQL, vous ne pouvez pas faire la même chose avec les index, vous ne pouvez que les lancer et les recréer. Dans d'autres bases de données, telles qu'Oracle, vous pouvez désactiver et activer les index sans reconstruction.
UNLOGGED-
Lorsque vous modifiez des données dans PostgreSQL, les modifications sont écrites dans le journal d'écriture anticipée (WAL ). Il est utilisé pour maintenir la cohérence, réindexer rapidement pendant la restauration et maintenir la réplication.
L'écriture sur WAL est souvent nécessaire, mais il existe certaines circonstances dans lesquelles vous pouvez désactiver WAL pour accélérer les choses. Par exemple, dans le cas des tables de transfert.
Les tables intermédiaires sont appelées tables à usage unique, qui stockent des données temporaires utilisées pour implémenter certains processus. Par exemple, dans les processus ETL, il est très courant de charger des données à partir de fichiers CSV dans des tables de transfert, d'effacer les informations, puis de les charger dans la table cible. Dans ce scénario, la table intermédiaire est à usage unique et n'est pas utilisée dans les sauvegardes ou les réplicas.
Table NON ENREGISTRÉE.
Les tables intermédiaires qui n'ont pas besoin d'être récupérées en cas d'échec et qui ne sont pas nécessaires dans les réplicas peuvent être définies comme UNLOGGED :
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
Attention : avant d'utiliser
UNLOGGED, assurez-vous de bien comprendre toutes les implications.
Implémentez des processus entiers avec WITH et RETURNING
Supposons que vous ayez une table users et que vous trouviez qu'elle contient des données en double:
Table setup
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
L'utilisateur haki benita s'est inscrit deux fois, avec mail
ME@hakibenita.comet me@hakibenita.com. Comme nous ne normalisons pas les adresses e-mail lors de leur saisie dans le tableau, nous devons maintenant gérer les doublons.
Nous avons besoin:
- Identifiez les adresses en double en lettres minuscules et reliez les utilisateurs en double les uns aux autres.
- Mettez à jour les commandes afin qu'elles ne se réfèrent qu'à l'un des doublons.
- Supprimez les doublons du tableau.
Vous pouvez lier des utilisateurs en double à l'aide d'une table intermédiaire:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
La table intermédiaire contient des liens entre les prises. Si un utilisateur avec une adresse e-mail normalisée apparaît plus d'une fois, nous lui attribuons un ID utilisateur minimum, dans lequel nous réduisons tous les doublons. Le reste des utilisateurs est stocké dans la colonne du tableau et tous les liens vers eux seront mis à jour.
À l'aide du tableau intermédiaire, nous mettons à jour les liens vers les doublons dans le tableau
orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
Vous pouvez désormais supprimer en toute sécurité les doublons de
users:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
Notez que nous avons utilisé la fonction unnest pour "transformer" le tableau , qui transforme chaque élément en une chaîne.
Résultat:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
Génial, toutes les instances user
3( ME@hakibenita.com) sont converties en user 2( me@hakibenita.com).
Nous pouvons également vérifier que les doublons sont supprimés du tableau
users:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
Maintenant, nous pouvons nous débarrasser de la table de préparation:
db=# DROP TABLE duplicate_users;
DROP TABLE
Ce n'est pas grave, mais cela prend trop de temps et doit être nettoyé! Y a-t-il un meilleur moyen?
Expressions de table généralisées (CTE)
Avec les expressions de table génériques , également appelées expressions
WITH, nous pouvons exécuter toute la procédure avec une seule expression SQL:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
Au lieu d'une table intermédiaire, nous avons créé une expression de table générique et l'avons réutilisée.
Retour des résultats de CTE
L'un des avantages de l'exécution de DML dans une expression
WITHest que vous pouvez en renvoyer des données à l'aide du mot clé RETURNING . Disons que nous avons besoin d'un rapport sur le nombre de lignes mises à jour et supprimées:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
Résultat:
orders_updated | users_deleted
----------------+---------------
2 | 1
La beauté de cette approche est que l'ensemble du processus est effectué avec une seule commande, il n'est donc pas nécessaire de gérer les transactions ou de se soucier de vider la table intermédiaire en cas d'échec du processus.
Avertissement : Un lecteur Reddit m'a signalé le possible comportement imprévisible de l'exécution DML dans les expressions de table génériques :
Les sous-expressions dansWITHsont exécutées simultanément les unes avec les autres et avec la requête principale. Par conséquent, lorsqu'il est utilisé dansWITHdes expressions de modification de données, l'ordre réel des mises à jour sera imprévisible.
Cela signifie que vous ne pouvez pas vous fier à l'ordre dans lequel les sous-expressions indépendantes sont exécutées. Il s'avère que s'il existe une dépendance entre eux, comme dans l'exemple ci-dessus, vous pouvez vous fier à l'exécution de la sous-expression dépendante avant de les utiliser.
Évitez les indices dans les colonnes à faible sélectivité
Disons que vous avez un processus d'inscription où un utilisateur se connecte à une adresse e-mail. Pour activer votre compte, vous devez vérifier votre messagerie. Le tableau pourrait ressembler à ceci:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
La plupart de vos utilisateurs sont conscients des citoyens, ils s'inscrivent avec la bonne adresse postale et activent immédiatement le compte. Remplissons le tableau avec les données utilisateur et supposons que 90% des utilisateurs sont activés:
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
Pour interroger le nombre d'utilisateurs activés et non activés, vous pouvez créer un index par colonne
activated:
db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
Et si vous demandez le nombre d'utilisateurs non activés , la base utilisera l'index:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
La base a décidé que le filtre renverrait 102 567 éléments, soit environ 10% du tableau. Ceci est cohérent avec les données que nous avons chargées, donc la table a fait du bon travail.
Cependant, si nous interrogeons le nombre d' utilisateurs activés , nous constatons que la base de données a décidé de ne pas utiliser l'index :
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
De nombreux développeurs sont confus lorsque la base de données n'utilise pas l'index. Pour expliquer pourquoi il fait cela, vous pouvez le faire: si vous aviez besoin de lire la table entière, utiliseriez-vous un index ?
Probablement pas, pourquoi est-ce nécessaire? La lecture à partir du disque coûte cher, vous voudrez donc en lire le moins possible. Par exemple, si la table fait 10 Mo et que l'index est de 1 Mo, alors pour lire la table entière, vous devrez lire 10 Mo à partir du disque. Et si vous ajoutez un index, vous obtenez 11 Mo. C'est du gaspillage.
Jetons maintenant un coup d'œil aux statistiques que PostgreSQL a collectées sur notre table:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
Lorsque PostgreSQL a analysé la table, il a constaté qu'il
activatedy avait deux valeurs différentes dans la colonne . La valeur tde la colonne most_common_valscorrespond à la fréquence 0.89743334de la colonne most_common_freqset la valeur fcorrespond à la fréquence 0.10256667. Après avoir analysé le tableau, la base de données a déterminé que 89,74% des enregistrements étaient des utilisateurs activés et que les 10,26% restants n'étaient pas activés.
Sur la base de ces statistiques, PostgreSQL a décidé qu'il vaut mieux analyser la table entière que de supposer que 90% des lignes satisfont à la condition. Le seuil au-delà duquel une base peut décider d'utiliser ou non un index dépend de nombreux facteurs et il n'y a pas de règle empirique.
Index des colonnes à sélectivité faible et élevée.
Utiliser des index partiels
Dans le chapitre précédent, nous avons créé un index pour une colonne booléenne contenant environ 90% des enregistrements
true(utilisateurs activés).
Lorsque nous avons demandé le nombre d'utilisateurs actifs, la base de données n'a pas utilisé l'index. Et lorsqu'on lui a demandé le nombre de non-activés, la base de données a utilisé l'index.
La question se pose: si la base de données n'utilise pas l'index pour filtrer les utilisateurs actifs, pourquoi les indexerons-nous en premier lieu?
Avant de répondre à cette question, regardons le poids de l'index complet par colonne
activated:
db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
L'indice pèse 21 Mo. Juste pour référence: le tableau avec les utilisateurs est de 65 Mo. Autrement dit, le poids de l'indice est d'environ 32% du poids de base. Cela étant dit, nous savons que ~ 90% du contenu de l'index est peu susceptible d'être utilisé.
Dans PostgreSQL, vous pouvez créer un index uniquement sur une partie d'une table - le soi-disant index partiel :
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
Nous utilisons une expression
WHEREpour contraindre les chaînes couvertes par l'index. Vérifions si cela fonctionne:
db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
Génial, la base de données s'est avérée suffisamment intelligente pour réaliser que l'expression booléenne que nous avons utilisée dans notre requête pourrait fonctionner pour un index partiel.
Cette approche présente un autre avantage:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
L'index de colonne complet pèse 21 Mo et l'index partiel n'est que de 2,2 Mo. Soit 10%, ce qui correspond à la proportion d'utilisateurs non activés dans le tableau.
Toujours charger les données triées
C'est l'un de mes commentaires les plus fréquents lors de l'analyse du code. Les conseils ne sont pas aussi intuitifs que les autres et peuvent avoir un impact énorme sur la productivité.
Disons que vous avez une énorme table avec des ventes spécifiques:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
Chaque nuit pendant le processus ETL, vous chargez des données dans une table:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Pour simuler le téléchargement, nous utilisons des données aléatoires. Nous avons inséré 100000 lignes avec des noms aléatoires et les dates de vente pour la période du 1er janvier 2020 et deux ans à venir.
Dans la plupart des cas, le tableau est utilisé pour les rapports de ventes récapitulatifs. Le plus souvent, ils filtrent par date pour voir les ventes pour une période spécifique. Pour accélérer le balayage de portée, créons un index par
sold_at:
db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
Jetons un coup d'œil au plan d'exécution de la demande de récupération de toutes les ventes en juin 2020:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
Après avoir exécuté la requête plusieurs fois pour réchauffer le cache, le temps d'exécution s'est stabilisé au niveau de 6 ms.
Analyse Bitmap
En termes d'exécution, on voit que la base utilisait le scan bitmap. Il se déroule en deux temps:
(Bitmap Index Scan): la base parcourt tout l'indexsale_fact_sold_at_ixet trouve toutes les pages du tableau qui contiennent les lignes pertinentes.(Bitmap Heap Scan): la base lit les pages contenant les chaînes pertinentes et trouve celles qui satisfont à la condition.
Les pages peuvent contenir plusieurs lignes. Dans la première étape, l'index est utilisé pour rechercher des pages . La deuxième étape recherche des lignes dans les pages, d'où l'opération
Recheck Conddans le plan d'exécution suit .
À ce stade, de nombreux administrateurs de bases de données et développeurs arrondiront et passeront à la requête suivante. Mais il existe un moyen d'améliorer cette requête.
Balayage d'index
Modifions légèrement le chargement des données.
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Cette fois, nous avons chargé les données triées par
sold_at.
Maintenant, le plan d'exécution pour la même requête ressemble à ceci:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
Après plusieurs exécutions, le temps d'exécution s'est stabilisé à 2,3 ms. Nous avons réalisé des économies durables d'environ 60%.
Nous voyons également que cette fois, la base de données n'a pas utilisé l'analyse bitmap, mais a appliqué une analyse d'index "normale". Pourquoi?
Corrélation
Lorsque la base de données analyse la table, elle collecte toutes les statistiques qu'elle peut obtenir. L'un des paramètres est la corrélation :
Corrélation statistique entre l'ordre physique des lignes et l'ordre logique des valeurs dans les colonnes. Si la valeur est autour de -1 ou +1, une analyse d'index sur la colonne est considérée comme plus avantageuse que lorsque la valeur de corrélation est autour de 0, car le nombre d'accès aléatoires au disque est réduit.
Comme expliqué dans la documentation officielle, la corrélation est une mesure de la façon dont les valeurs d'une colonne particulière du disque sont «triées».
Corrélation = 1.
Si la corrélation est égale à 1 ou plus, cela signifie que les pages sont stockées sur le disque à peu près dans le même ordre que les lignes de la table. Ceci est très courant. Par exemple, les ID à incrémentation automatique ont tendance à avoir une corrélation proche de 1. Les colonnes de date et d'horodatage qui indiquent le moment où les lignes ont été créées ont également une corrélation proche de 1.
Si la corrélation est -1, les pages sont triées dans l'ordre inverse des colonnes.
Corrélation ~ 0.
Si la corrélation est proche de 0, cela signifie que les valeurs de la colonne ne sont pas corrélées ou peu corrélées avec l'ordre des pages dans le tableau.
Revenons à
sale_fact. Lorsque nous avons chargé les données dans la table sans pré-tri, les corrélations étaient comme ceci:
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
L'ID de colonne généré automatiquement a une corrélation de 1. La colonne a une
sold_attrès faible corrélation: les valeurs consécutives sont dispersées dans le tableau.
Lorsque nous avons chargé les données triées dans la table, elle a calculé les corrélations:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
La corrélation
sold_atest maintenant égale 1.
Alors, pourquoi la base a-t-elle utilisé des analyses bitmap lorsque la corrélation était faible, mais des analyses d'index lorsque la corrélation était élevée?
- Lorsque la corrélation était de 1, la base a déterminé que les lignes de la plage demandée étaient susceptibles de se trouver dans des pages consécutives. Ensuite, il est préférable d'utiliser une analyse d'index pour lire plusieurs pages.
- Lorsque la corrélation était proche de 0, la base a déterminé que les lignes de la plage demandée étaient susceptibles d'être dispersées dans le tableau. Ensuite, il est conseillé d'utiliser une analyse bitmap des pages contenant les lignes requises, puis de les extraire uniquement à l'aide de la condition.
La prochaine fois que vous chargez des données dans une table, pensez à la quantité d'informations qui sera demandée et triez afin que les index puissent analyser rapidement les plages.
Commande CLUSTER
Une autre façon de "trier une table sur le disque" par un index spécifique consiste à utiliser la commande CLUSTER .
Par exemple:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
Nous avons chargé les données dans la table dans un ordre aléatoire, de sorte que la corrélation
sold_atest proche de zéro.
Pour "recomposer" la table par
sold_at, nous utilisons la commande CLUSTERpour trier la table sur disque en fonction de l'index sale_fact_sold_at_ix:
db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
Après avoir regroupé la table, la corrélation
sold_atest devenue 1.
Commande CLUSTER.
Points à noter:
- Le regroupement d'une table sur une colonne spécifique peut affecter la corrélation d'une autre colonne. Par exemple, regardez la corrélation des ID après le clustering par
sold_at. CLUSTEREst une opération lourde et bloquante, ne l'appliquez donc pas à une table en direct.
Pour ces raisons, il est préférable d'insérer des données déjà triées et de ne pas compter sur
CLUSTER.
Index des colonnes hautement corrélées avec BRIN
En ce qui concerne les index, de nombreux développeurs pensent aux arbres-B. Mais PostgreSQL propose d'autres types d'index, tels que BRIN :
BRIN est conçu pour fonctionner avec de très grands tableaux dans lesquels certaines colonnes sont naturellement en corrélation avec leur emplacement physique dans le tableau
BRIN signifie Block Range Index. Selon la documentation, BRIN fonctionne mieux avec des colonnes hautement corrélées. Comme nous l'avons vu dans les chapitres précédents, les ID et les horodatages auto-incrémentés sont naturellement en corrélation avec la structure physique de la table, donc BRIN est plus avantageux pour eux.
Dans certaines conditions, le BRIN peut offrir un meilleur «rapport qualité-prix» en termes de taille et de performances par rapport à un indice B-tree comparable.
BRIN.
BRIN est une plage de valeurs dans plusieurs pages adjacentes d'un tableau. Disons que nous avons les valeurs suivantes dans une colonne, chacune sur une page distincte:
1, 2, 3, 4, 5, 6, 7, 8, 9
BRIN fonctionne avec des plages de pages adjacentes. Si vous spécifiez trois pages adjacentes, l'index divise le tableau en plages:
[1,2,3], [4,5,6], [7,8,9]
Pour chaque plage, BRIN stocke la valeur minimale et maximale :
[1–3], [4–6], [7–9]
Utilisons cet index pour rechercher la valeur 5:
- [1-3] - il n'est certainement pas ici.
- [4–6] - peut-être ici.
- [7–9] - il n'est certainement pas ici.
Avec BRIN, nous avons limité la zone de recherche au bloc 4-6.
Prenons un autre exemple. Laissez les valeurs de la colonne avoir une corrélation proche de zéro, c'est-à-dire qu'elles ne sont pas triées:
[2,9,5], [1,4,7], [3,8,6]
L'indexation de trois blocs adjacents nous donnera les plages suivantes:
[2–9], [1–7], [3–8]
Cherchons la valeur 5:
- [2-9] - peut être ici.
- [1-7] - peut être ici.
- [3–8] - peut être ici.
Dans ce cas, l'index ne restreint pas du tout la recherche, il est donc inutile.
Comprendre pages_per_range
Le nombre de pages adjacentes est déterminé par le paramètre
pages_per_range. Le nombre de pages dans une plage affecte la taille et la précision du BRIN:
- Un
pages_per_rangeindex plus petit et moins précis donnera une grande valeur . - Une petite valeur
pages_per_rangedonnera un index plus grand et plus précis.
La valeur par défaut
pages_per_rangeest 128.
BRIN avec un nombre inférieur de pages_par_plage.
Pour illustrer, créons un BRIN avec des plages de deux pages et cherchons une valeur de 5:
- [1–2] - il n'est certainement pas là.
- [3-4] - il n'est certainement pas là.
- [5-6] - peut être ici.
- [7–8] - il n'est certainement pas ici.
- [9] - ici, ce n'est certainement pas le cas.
Avec une plage de deux pages, nous pouvons limiter la recherche aux blocs 5 et 6. Si la plage est de trois pages, l'index limitera la recherche aux blocs 4, 5 et 6.
Une autre différence entre les deux index est que lorsque la plage était de trois pages, nous devions stocker trois plages , et avec deux pages dans une plage, nous obtenons déjà cinq plages et l'index augmente.
Créer BRIN
Prenons un tableau
sales_factet créons un BRIN par colonne sold_at:
db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
La valeur par défaut est
pages_per_range = 128.
Interrogons maintenant la période de date de vente:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
La base a obtenu la période de date en utilisant BRIN, mais cela n'a rien d'intéressant ...
Optimisation de pages_per_range
Selon le plan d'exécution, la base de données a supprimé 23 130 lignes des pages, qu'elle a trouvées à l'aide de l'index. Cela peut indiquer que la plage que nous avons spécifiée pour l'index est trop grande pour cette requête. Créons un index avec la moitié du nombre de pages de la plage:
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
Avec 64 pages dans la plage, la base a supprimé moins de lignes trouvées à l'aide de l'index - 9 434. Cela signifie qu'elle a dû effectuer moins d'opérations d'E / S, et la requête a été exécutée un peu plus rapidement, en ~ 5,5 ms au lieu de ~ 8,9.
Testons l'index avec différentes valeurs
pages_per_range:
| pages_per_range | Lignes supprimées lors de la revérification de l'index |
| 128 | 23130 |
| 64 | 9 434 |
| 8 | 874 |
| 4 | 446 |
| 2 | 446 |
La diminution de l'
pages_per_rangeindex devient plus précise et supprime moins de lignes des pages trouvées.
Veuillez noter que nous avons optimisé une requête très spécifique. C'est bien pour l'illustration, mais dans la vraie vie, il est préférable d'utiliser des valeurs qui répondent aux besoins de la plupart des requêtes.
Estimer la taille de l'index
Un autre avantage majeur de BRIN est sa taille. Dans les chapitres précédents, nous avons
sold_atcréé un index B-tree pour le champ . Sa taille était de 2224 Ko. Et la taille BRIN avec le paramètre n'est pages_per_range=128que de 48 Ko: 46 fois plus petite.
Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
La taille du BRIN est également affectée
pages_per_range. Par exemple, BRIN pages_per_range=2pèse 56 Ko, soit un peu plus de 48 Ko.
Rendre les index "invisibles"
PostgreSQL a une fonctionnalité DDL transactionnelle intéressante . Au fil des années avec Oracle, je me suis habitué à utiliser des commandes DDL comme
CREATE, DROPet ALTER. Mais dans PostgreSQL, vous pouvez exécuter des commandes DDL dans une transaction, et les modifications ne seront appliquées qu'après la validation de la transaction.
J'ai récemment découvert que l'utilisation de DDL transactionnel peut rendre les index invisibles! Ceci est utile lorsque vous souhaitez voir un plan d'exécution sans index.
Par exemple, dans une table,
sale_factnous avons créé un index sur une colonne sold_at. Le plan d'exécution de la demande de récupération des ventes de juillet ressemble à ceci:
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
Pour voir à quoi ressemblerait le plan s'il n'y avait pas d'index
sale_fact_sold_at_ix, vous pouvez placer l'index dans une transaction et revenir immédiatement en arrière:
db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
Commençons par lancer une transaction avec
BEGIN. Ensuite, nous supprimons l'index et générons le plan d'exécution. Notez que le plan utilise désormais une analyse complète de la table comme si l'index n'existait pas. À ce stade, la transaction est toujours en cours, donc l'indice n'a pas encore été supprimé. Pour terminer la transaction sans supprimer l'index, annulez-le à l'aide de la commande ROLLBACK.
Vérifions que l'index existe toujours:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
D'autres bases de données qui ne prennent pas en charge le DDL transactionnel peuvent atteindre l'objectif différemment. Par exemple, Oracle vous permet de marquer un index comme invisible et l'optimiseur l'ignorera alors.
Avertissement : si vous laissez tomber l'index dans une transaction, elle conduira au blocage des activités concurrentielles
SELECT, INSERT, UPDATEet DELETEdans le tableau jusqu'à ce que la transaction est active. Utiliser avec prudence dans les environnements de test et éviter l'utilisation dans les installations de production.
Ne planifiez pas de longs processus pour démarrer au début d'une heure
Les investisseurs savent que des choses étranges peuvent se produire lorsque le cours de l'action atteint de belles valeurs rondes, par exemple 10 $, 100 $, 1000 $. Voici ce qu'ils écrivent à ce sujet :
[...] le prix des actifs peut changer de façon imprévisible, croisant des valeurs rondes comme 50 $ ou 100 $ par action. De nombreux traders inexpérimentés aiment acheter ou vendre des actifs lorsque le prix atteint des chiffres ronds parce qu'ils pensent que ce sont des prix équitables.
De ce point de vue, les développeurs ne sont pas très différents des investisseurs. Lorsqu'ils ont besoin de planifier un long processus, ils choisissent généralement une heure.
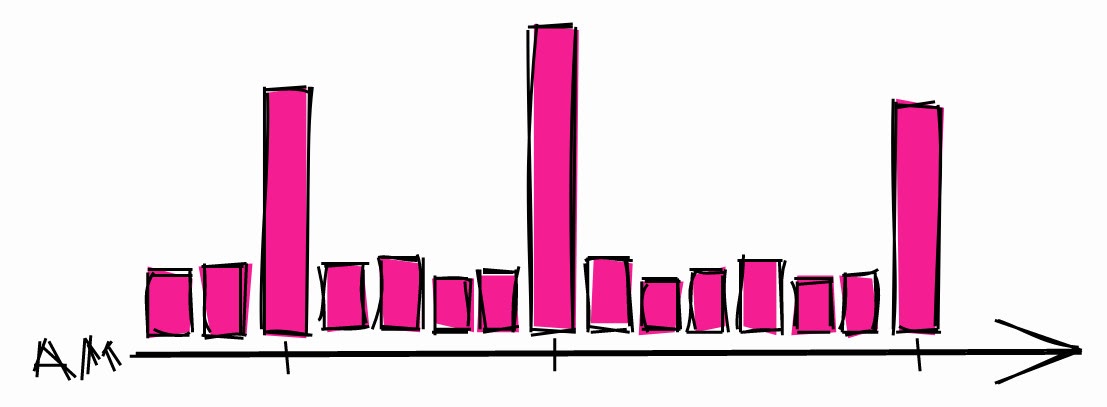
Charge système typique pendant la nuit.
Cela peut entraîner des pics de charge pendant ces heures. Ainsi, si vous devez planifier un long processus, il y a plus de chances que le système soit inactif à d'autres moments.
Il est également recommandé d'utiliser des retards aléatoires dans les horaires afin de ne pas démarrer en même temps à chaque fois. Alors même si une autre tâche est prévue pour cette heure, ce ne sera pas un gros problème. Si vous utilisez une minuterie systemd, vous pouvez utiliser l'option RandomizedDelaySec .
Conclusion
Cet article fournit des conseils de différents degrés de preuve basés sur mon expérience. Certains sont faciles à mettre en œuvre, d'autres nécessitent une compréhension approfondie du fonctionnement des bases de données. Les bases de données sont l'épine dorsale de la plupart des systèmes modernes, donc le temps passé à apprendre à travailler est un bon investissement pour tout développeur!