
La journalisation est l'une de ces choses dont on se souvient seulement quand ils se cassent. Et ce n'est pas du tout une critique. Le fait est que les journaux ne rapportent pas d'argent en tant que tel. Ils donnent un aperçu de ce que les programmes sont (ou ont été en train de faire), aidant à maintenir les choses qui nous rapportent de l'argent. À petite échelle (ou pendant le développement), les informations nécessaires peuvent être obtenues en affichant simplement des messages dans
stdout... Mais dès que vous accédez à un système distribué, et immédiatement, il est nécessaire d'agréger ces messages et de les envoyer vers un référentiel central, où ils apporteront le plus grand bénéfice. Ce besoin est encore plus pertinent si vous traitez avec des conteneurs sur une plateforme comme Kubernetes, où les processus et le stockage local sont éphémères.
Une approche familière du traitement des journaux
Depuis les débuts des conteneurs et la publication du manifeste Twelve-Factor , un certain schéma général s'est formé dans le traitement des logs générés par les conteneurs:
- traite les messages de sortie vers
stdoutoustderr, -
containerd(Docker) redirige les flux standard vers des fichiers en dehors des conteneurs, - et la queue du transmetteur de journal lit ces fichiers (c'est-à-dire obtient les dernières lignes d'eux) et envoie les données à la base de données.
Le populaire transitaire de journaux fluentd est un projet CNCF (comme containerd). Au fil du temps, il est devenu la norme de facto pour la lecture, la transformation, le transfert et l'indexation des journaux. Lorsque vous créez un cluster Kubernetes sur GKE avec Cloud Logging (anciennement Stackdriver) connecté, vous obtiendrez presque le même modèle - uniquement avec la saveur fluide de Google.
C'est ce modèle qui est apparu quand Olark (la société pour laquelle l'auteur de l'article travaille - environ Transl.)a commencé à migrer des services vers les K8 en tant que GKE il y a quatre ans. Et lorsque nous avons dépassé la journalisation en tant que service, ce modèle a été suivi, créant notre propre système d'agrégation de journaux capable de traiter 15 à 20 000 lignes par seconde à la charge maximale.
Il y a des raisons pour lesquelles cette approche fonctionne bien et pour lesquelles les principes des 12 facteurs recommandent directement la sortie des journaux dans des flux standard . Le fait est qu'il permet à l'application de ne pas se soucier du routage des logs et rend les conteneurs facilement "observables" (on parle d'observabilité) pendant le développement ou en production. Et si votre système de journalisation est foutu, au moins il est possible que les journaux restent sur les disques hôtes du nœud de cluster.
L'inconvénient de cette approche est que le suivi des journaux est relativement coûteux en termes d'utilisation du processeur . Nous avons commencé à y prêter attention après, lors de la prochaine optimisation du système de journalisation, il s'est avéré que fluentd consomme 1/8 de la totalité du quota de requêtes CPU en production:
- Cela est en partie dû à la topologie du cluster: fluentd est placé sur chaque nœud pour personnaliser les fichiers locaux (comme DaemonSet , en termes K8s), vous avez des nœuds quad-core et vous devez réserver 50% du cœur pour le traitement des journaux, et ... eh bien, vous voyez l'idée.
- Une autre partie des ressources est consacrée au traitement de texte, que nous attribuons également à fluentd. En effet, qui laisserait passer l'occasion de nettoyer les entrées de journal obscurcies?
- Le reste va à inotifywait , qui surveille les fichiers sur le disque, traite les lectures et en assure le suivi.
Nous voulions savoir combien tout cela coûte: il existe d'autres moyens d'envoyer des journaux à fluentd. Par exemple, vous pouvez utiliser le port avant (nous parlons d'utiliser le type
forwardin source- environ Transl.). Sera-ce moins cher?
Expérience pratique
Pour isoler le coût de la récupération des lignes de bois à l'aide de résidus, j'ai mis en place un petit banc d'essai . Il comprend les composants suivants:
- Programme Python pour créer un certain nombre d' écrivains de journaux avec une fréquence et une taille de message configurables;
- fichier pour docker compose en cours d'exécution:
- fluentd pour le traitement des logs,
- c Conseiller pour la surveillance du conteneur fluent,
- Prometheus pour la collecte de métriques cAdvisor,
- Grafana pour la visualisation de données dans Prometheus.
Remarques sur ce diagramme:
- Les rédacteurs de journaux génèrent des messages dans un format JSON uniforme (que containerd utilise également) et peuvent soit les écrire dans des fichiers, soit les transmettre au port de transfert fluentd.
- Lors de l'écriture dans des fichiers, une classe est utilisée
RotatingFileHandlerpour mieux simuler les conditions de cluster. - Fluentd est configuré pour "jeter" tous les enregistrements
nullet ne pas traiter les expressions régulières ou vérifier les enregistrements pour les balises. Ainsi, son travail principal sera d'obtenir les lignes de journal. - , Prometheus cAdvisor, fluentd.
La sélection des paramètres de comparaison a été effectuée de manière assez subjective. J'ai écrit un autre utilitaire pour estimer le volume de journaux générés par les nœuds de notre cluster. Sans surprise, il varie considérablement: de quelques dizaines de lignes par seconde à 500 ou plus sur les nœuds les plus occupés.
Ceci est une autre source de problèmes: si vous utilisez un DaemonSet, alors fluentd doit être configuré pour gérer les nœuds les plus occupés du cluster. En principe, le déséquilibre peut être évité en attribuant des étiquettes appropriées aux principaux générateurs de journaux et en utilisant des règles anti-affinité souples pour les répartir uniformément, mais cela dépasse le cadre de cet article. Au départ, je prévoyais de comparer différents mécanismes de "livraison" des logsà une charge de 500/1000 lignes par seconde en utilisant 1 à 10 enregistreurs de journaux.
Résultats de test
Les premiers tests ont montré que les lignes par seconde étaient le principal contributeur à l'utilisation du processeur dans le suivi , quel que soit le nombre de fichiers journaux observés. Les deux graphiques ci-dessous comparent la charge à 1000 p / s d'un enregistreur de journal et de 10. On peut voir qu'ils sont presque les mêmes:
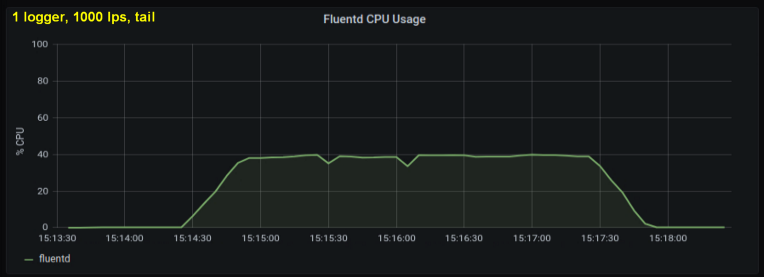
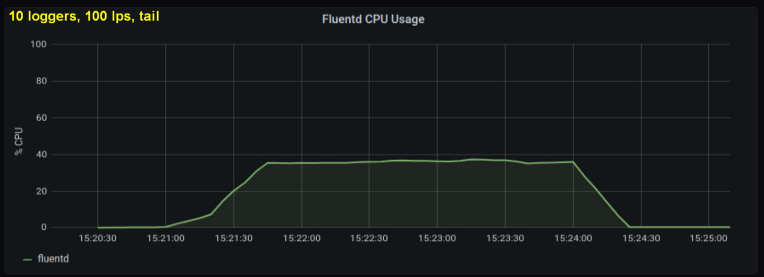
Une petite digression: je n'ai pas inclus le graphique correspondant ici, mais sur ma machine il s'est avéré que dix processus de journalisation l'écriture de 100 lignes par seconde a un débit global plus élevé qu'un seul processus d'écriture de 1 000 lignes par seconde. Cela peut être dû aux spécificités de mon code - je n'ai pas délibérément enquêté sur ce problème.
Dans tous les cas, je m'attendais à ce que le nombre de fichiers journaux ouverts soit un facteur important, mais il s'est avéré que cela n'affectait pas vraiment les résultats. Une autre variable aussi insignifiante est la longueur de la chaîne. Le test ci-dessus a utilisé une longueur de chaîne standard de 100 caractères. J'ai fait des courses avec des lignes dix fois plus longues, mais cela n'a pas eu d'effet notable sur la charge du processeur pendant le test, qui dans tous les cas était de 180 secondes.
Compte tenu de ce qui précède, j'ai décidé de tester 2 rédacteurs, car un processus, me semblait-il, atteignait une limite interne. D'un autre côté, plus de processus n'étaient pas non plus nécessaires. J'ai fait des tests avec 500 et 1000 lignes par seconde. L'ensemble de graphiques suivant montre les résultats pour les fichiers de fin et le port de transfert:

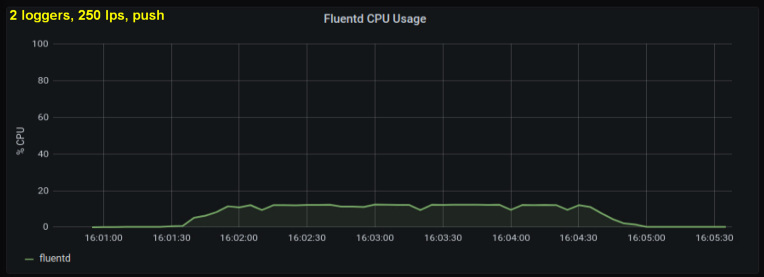
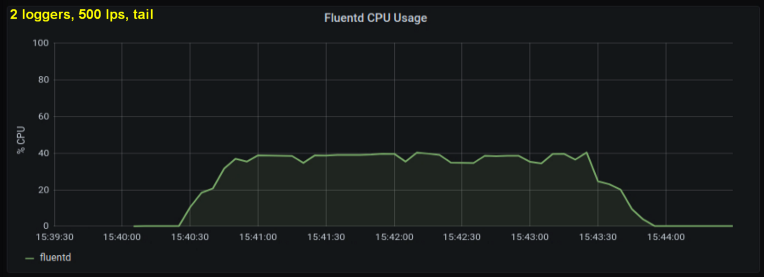

conclusions
Au cours d'une semaine, j'ai effectué ces tests de différentes manières et j'ai abouti à deux conclusions clés:
- La méthode de socket avant consomme 30 à 50% moins de puissance CPU que la lecture de lignes à partir de fichiers journaux de même taille. Une explication possible (pour au moins une partie de la différence observable) est qu'en sérialisant les données dans le paquet de messages - fluentd. fluentd , messagepack. , Python- forward-, . , : , fluentd, .
- , CPU , . tailing', forward-. , (1000 writer' 10 writer'), forward-:


Ces résultats signifient-ils que nous devrions tous écrire des journaux sur le socket au lieu de fichiers? Évidemment, ce n'est pas si simple ...
Si nous pouvions changer la façon dont nous collectons les journaux si facilement, alors la plupart des problèmes existants ne seraient pas des problèmes. La sortie de journaux
stdoutfacilite la surveillance et l'utilisation des conteneurs pendant le développement. La sortie des journaux dans les deux sens, selon le contexte, augmentera considérablement la complexité - de même, la configuration de fluentd pour rendre les journaux pendant le développement (par exemple, en utilisant le plugin de sortie stdout) l'augmentera .
Une interprétation plus pratique de ces résultats serait peut-être une recommandation d'élargir les nœuds... Puisque fluentd doit être configuré pour fonctionner avec les nœuds les plus occupés (les plus bruyants), il est logique de réduire le nombre de nœuds. Combiné avec un mécanisme anti-affinité qui répartirait uniformément les principaux générateurs de journaux, ce serait une excellente stratégie. Hélas, le redimensionnement des nœuds implique de nombreuses nuances et compromis qui vont bien au-delà des besoins du système de journalisation.
L'échelle compte évidemment aussi... À petite échelle, les inconvénients et la complexité supplémentaire ne sont peut-être pas pratiques. En outre, il existe généralement des problèmes plus urgents. Si vous débutez et que l'odeur de «peinture fraîche» n'a pas disparu du processus d'ingénierie, vous pouvez standardiser votre format de journalisation à l'avance et réduire les coûts en utilisant la méthode socket sans surcharger les développeurs.
Pour ceux qui travaillent sur des projets à grande échelle, les conclusions de cet article sont inappropriées, car des entreprises comme Google ont fait une analyse beaucoup plus approfondie et plus intensive du problème (par rapport à la mienne). À cette échelle, évidemment, vous déployez vos propres clusters et pouvez faire ce que vous voulez avec le pipeline de journalisation (en d'autres termes, tirez parti des deux approches).
En conclusion, permettez-moi d'anticiper quelques questions et d'y répondre à l'avance. Premièrement, «Cet article sur fluentd n'est-il pas vraiment? Et qu'est-ce que cela a à voir avec Kubernetes en général ? " ... La réponse aux deux côtés de cette question est: "Eh bien, peut-être ."
- Dans ma compréhension générale et mon expérience, cet outil est un phénomène courant lors de la queue de fichiers sous Linux dans des situations où vous avez beaucoup d'E / S disque. Je n'ai pas fait de tests avec un autre transitaire de journal comme Logstash , mais il serait intéressant de voir les résultats.
- Kubernetes, CPU, , . , , . , Kubernetes, tailing' Kubernetes-as-a-Service.
Enfin, quelques mots sur une autre ressource consommable - la mémoire . Au départ, j'allais l'inclure dans l'article: un tableau de bord spécialement préparé pour cela montre l'utilisation de la mémoire de fluentd. Mais à la fin, il s'est avéré que ce facteur n'est pas important. Selon les résultats des tests, la quantité maximale de mémoire utilisée ne dépassait pas 85 Mo, la différence entre les tests individuels dépassant rarement 10 Mo. Cette consommation de mémoire assez faible est évidemment due au fait que je n'ai pas utilisé de plugins de sortie tamponnés. Plus important encore, il s'est avéré être presque le même pour les deux méthodes. Et l'article devenait déjà trop volumineux ...
Il convient de noter qu'il existe de nombreux autres «coins» que vous pouvez examiner si vous souhaitez faire des tests plus approfondis. Par exemple, vous pouvez savoir dans quels états de processeur et quels appels système fluentd passe le plus clair de son temps, mais pour ce faire, vous devez créer le wrapper approprié.
PS du traducteur
Lisez aussi sur notre blog: