Je travaille actuellement chez ManyChat. En fait, il s'agit d'une startup - nouvelle, ambitieuse et en croissance rapide. Et quand j'ai rejoint l'entreprise pour la première fois, la question classique s'est posée: "Que devrait maintenant tirer une jeune startup du marché des SGBD et des bases de données?"
Dans cet article, sur la base de ma présentation au festival en ligne RIT ++ 2020 , je répondrai à cette question. Une version vidéo du rapport est disponible sur YouTube .
Bases de données bien connues de 2020
Nous sommes en 2020, j'ai regardé autour de moi et j'ai vu trois types de bases de données.
Le premier type est les bases de données OLTP classiques : PostgreSQL, SQL Server, Oracle, MySQL. Ils ont été écrits il y a longtemps, mais sont toujours pertinents car ils sont familiers à la communauté des développeurs.
Le deuxième type - bases de "zéro" . Ils ont essayé de s'éloigner des modèles classiques en s'éloignant de SQL, des structures traditionnelles et d'ACID, en ajoutant du sharding en ligne et d'autres fonctionnalités attrayantes. Par exemple, il s'agit de Cassandra, MongoDB, Redis ou Tarantool. Toutes ces solutions voulaient offrir au marché quelque chose de fondamentalement nouveau et occupaient leur niche, car dans certaines tâches, elles se sont révélées extrêmement pratiques. Ces bases seront désignées par le terme générique NOSQL.
Les "zéro" sont terminés, ils se sont habitués aux bases de données NOSQL, et le monde, de mon point de vue, a franchi l'étape suivante - les bases de données gérées . Ces bases de données ont le même noyau que les bases de données OLTP classiques ou les nouvelles bases de données NoSQL. Mais ils n'ont pas besoin de DBA et de DevOps et ils fonctionnent sur du matériel géré dans les nuages. Pour un développeur, c'est "juste une base" qui fonctionne quelque part, mais comment elle est installée sur le serveur, qui a configuré le serveur et qui le met à jour, personne ne s'en soucie.
Exemples de telles bases:
- AWS RDS est un wrapper géré sur PostgreSQL / MySQL.
- DynamoDB est un analogue AWS d'une base de données documentaire, similaire à Redis et MongoDB.
- Amazon Redshift est une base d'analyse gérée.
Au fond, ce sont d'anciennes bases, mais élevées dans un environnement géré, sans avoir besoin de travailler avec du matériel.
Remarque. Les exemples sont pris pour l'environnement AWS, mais leurs homologues existent également dans Microsoft Azure, Google Cloud ou Yandex.Cloud.

Alors, quoi de neuf? En 2020, rien de tout cela.
Concept sans serveur
Ce qui est vraiment nouveau sur le marché en 2020, ce sont les solutions sans serveur ou sans serveur.
Je vais essayer d'expliquer ce que cela signifie en utilisant l'exemple d'un service régulier ou d'une application backend.
Pour déployer une application backend classique, nous achetons ou louons un serveur, nous y copions le code, publions le point de terminaison à l'extérieur et payons régulièrement le loyer, l'électricité et les services de centre de données. Ceci est la disposition standard.
Est-ce qu'il y a un autre moyen? Avec les services sans serveur, c'est possible.
Sur quoi porte cette approche: il n'y a pas de serveur, il n'y a même pas de bail d'instance virtuelle dans le cloud. Pour déployer le service, copiez le code (fonctions) dans le référentiel et publiez le point de terminaison à l'extérieur. Ensuite, nous payons juste pour chaque appel de cette fonction, en ignorant complètement le matériel où elle est exécutée.
J'essaierai d'illustrer cette approche en images.
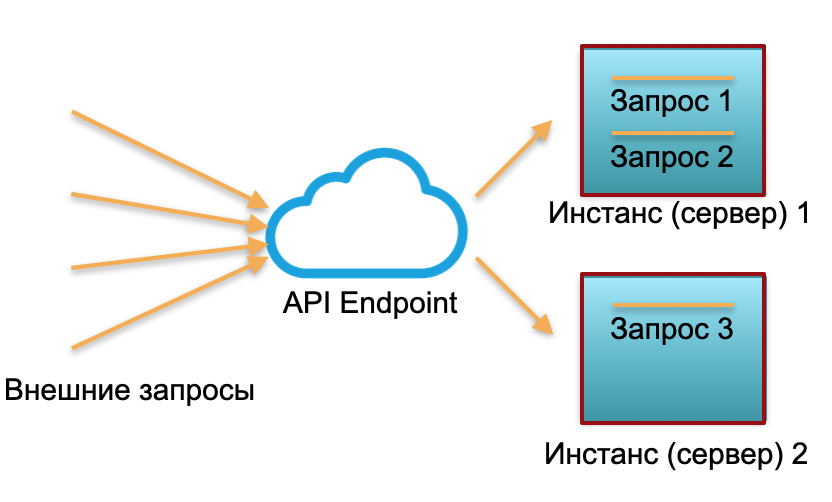
Déploiement classique . Nous avons un service avec une certaine charge. Nous élevons deux instances: des serveurs physiques ou des instances dans AWS. Les demandes externes sont envoyées à ces instances et y sont traitées.
Comme vous pouvez le voir sur l'image, les serveurs sont utilisés différemment. L'un est utilisé à 100%, il y a deux demandes et l'autre n'est que partiellement inactif à 50%. Si ce n'est pas trois demandes, mais 30, alors le système entier ne fera pas face à la charge et commencera à ralentir.

Déploiement sans serveur... Dans un environnement sans serveur, un tel service n'a ni instance ni serveur. Il existe un pool de ressources préchauffées - de petits conteneurs Docker préparés avec un code de fonction déployé. Le système reçoit des requêtes externes et pour chacune d'entre elles, le framework sans serveur lève un petit conteneur avec du code: il traite cette requête particulière et tue le conteneur.
Une demande - un conteneur levé, 1000 demandes - 1000 conteneurs. Et le déploiement sur des serveurs de fer est déjà le travail d'un fournisseur de cloud. Il est complètement caché par le framework sans serveur. Dans ce concept, nous payons pour chaque appel. Par exemple, un appel par jour est arrivé - nous avons payé pour un appel, un million est arrivé en une minute - nous avons payé un million. Ou en une seconde, cela se produit également.
Le concept de publication d'une fonction sans serveur est approprié pour un service sans état. Et si vous avez besoin d'un service complet (état), ajoutez une base de données au service. Dans ce cas, lorsqu'il s'agit de travailler avec l'état, avec l'état, chaque fonction statefull écrit et lit simplement à partir de la base de données. De plus, à partir d'une base de données de l'un des trois types décrits au début de l'article.
Quelle est la limitation générale de toutes ces bases? Ce sont les coûts d'un serveur cloud ou de fer constamment utilisé (ou de plusieurs serveurs). Peu importe que nous utilisions une base de données classique ou gérée, que nous ayons Devops et un administrateur ou non, nous payons toujours 24/7 pour le loyer du matériel, de l'électricité et du centre de données. Si nous avons une base classique, nous payons le maître et l'esclave. S'il s'agit d'une base partitionnée très chargée - nous payons pour 10, 20 ou 30 serveurs, et nous payons constamment.
La présence de serveurs réservés en permanence dans la structure de coûts était auparavant perçue comme un mal nécessaire. Les bases de données ordinaires ont également d'autres difficultés, telles que les limites du nombre de connexions, les limites de mise à l'échelle, le consensus géo-distribué - elles peuvent en quelque sorte être résolues dans certaines bases de données, mais pas toutes en même temps et pas idéales.
Base de données sans serveur - théorie
Question 2020: la base de données peut-elle également être rendue sans serveur? Tout le monde a entendu parler du backend sans serveur ... mais essayons également de rendre la base de données sans serveur?
Cela semble étrange car une base de données est un service complet, peu adapté à une infrastructure sans serveur. Dans le même temps, l'état de la base de données est très volumineux: gigaoctets, téraoctets et même pétaoctets dans les bases de données analytiques. Il n'est pas si facile de le soulever dans des conteneurs Docker légers.
D'un autre côté, presque toutes les bases de données modernes sont une énorme quantité de logique et de composants: transactions, négociation d'intégrité, procédures, dépendances relationnelles et beaucoup de logique. Une grande partie de la logique de la base de données est un état assez petit. Les gigaoctets et les téraoctets ne sont directement utilisés que par une petite partie de la logique de base de données associée à l'exécution directe des requêtes.
En conséquence, l'idée: si une partie de la logique permet une exécution sans état, pourquoi ne pas couper la base en parties avec état et sans état.
Sans serveur pour les solutions OLAP
Voyons à quoi pourrait ressembler une base de données découpée en parties avec état et sans état avec des exemples pratiques.
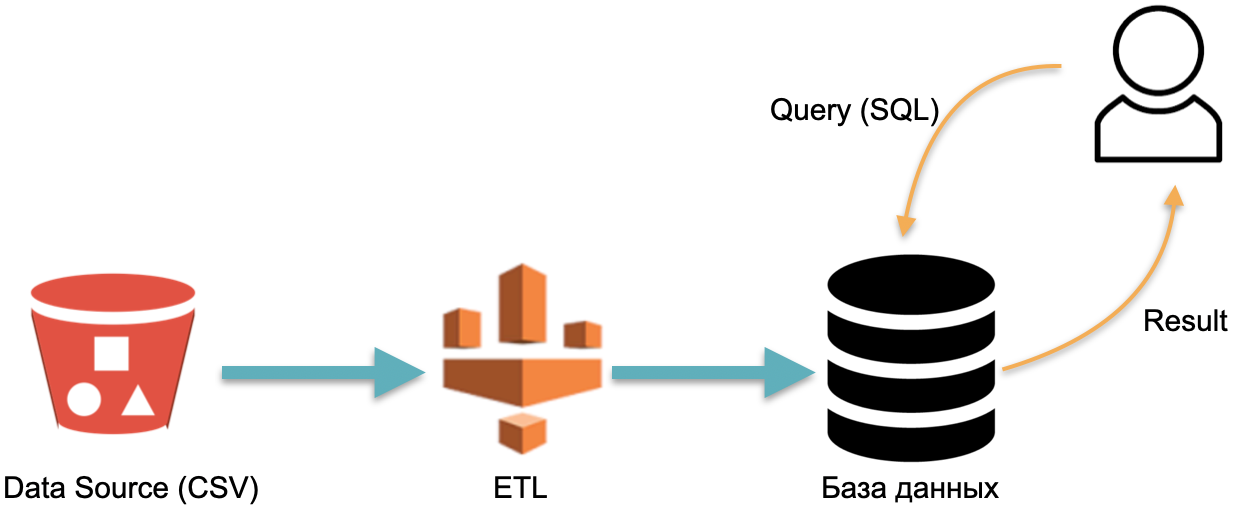
Par exemple, nous avons une base de données analytique : des données externes (cylindre rouge à gauche), un processus ETL qui charge les données dans la base de données et un analyste qui envoie des requêtes SQL à la base de données. C'est le fonctionnement classique d'un entrepôt de données.
Dans ce schéma, par convention, ETL est exécuté une fois. Ensuite, vous devez payer tout le temps pour les serveurs exécutant la base de données avec des données inondées d'ETL, afin que vous ayez quelque chose à lancer des requêtes.
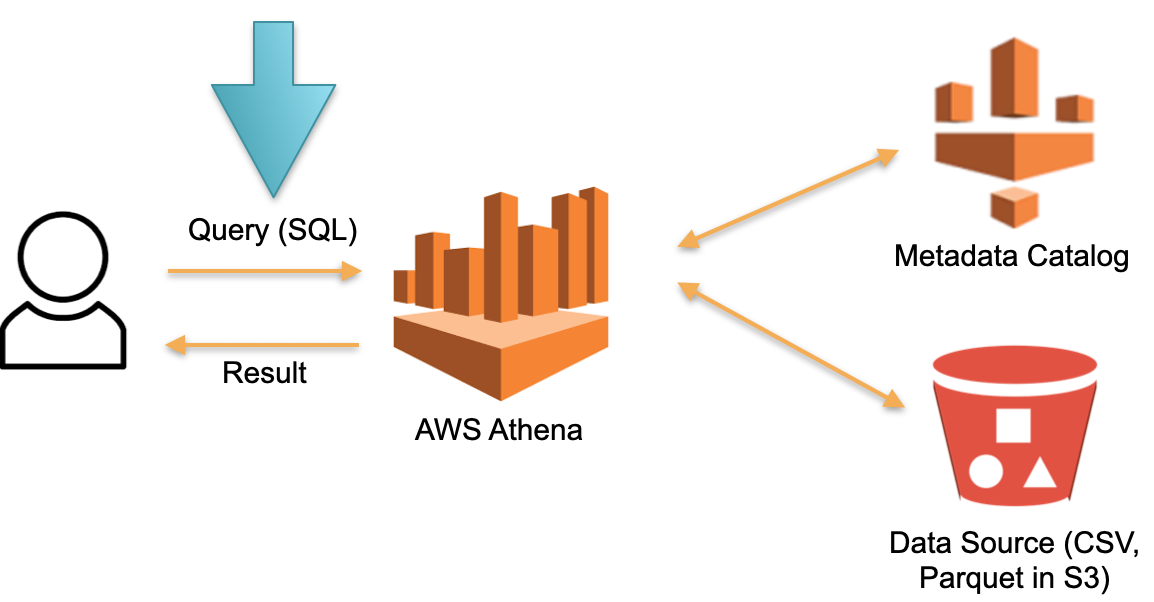
Examinons une approche alternative implémentée dans AWS Athena Serverless. Il n'y a pas de matériel dédié en permanence sur lequel les données téléchargées sont stockées. Au lieu de cela:
- SQL- Athena. Athena SQL- (Metadata) , .
- , , ( ).
- SQL- , .
- , .
Dans cette architecture, nous ne payons que le processus d'exécution de la requête. Aucune demande - aucun frais.
Il s'agit d'une approche fonctionnelle qui est implémentée non seulement dans Athena Serverless, mais également dans Redshift Spectrum (sur AWS).
L'exemple Athena montre que la base de données Serverless fonctionne sur des requêtes réelles avec des dizaines et des centaines de téraoctets de données. Des centaines de téraoctets nécessiteront des centaines de serveurs, mais nous n'avons pas à payer pour eux - nous payons pour les demandes. La vitesse de chaque requête est (très) lente par rapport aux bases de données analytiques spécialisées comme Vertica, mais nous ne payons pas les temps d'arrêt.
Une telle base de données est utile pour les rares requêtes analytiques ad hoc. Par exemple, lorsque nous décidons spontanément de tester une hypothèse sur une quantité gigantesque de données. Athena est parfaite pour ces cas. Pour les demandes régulières, un tel système est coûteux. Dans ce cas, mettez les données en cache dans une solution spécialisée.
Sans serveur pour les solutions OLTP
Dans l'exemple précédent, les tâches OLAP (analytiques) ont été prises en compte. Regardons maintenant les tâches OLTP.
Imaginez PostgreSQL ou MySQL évolutif. Lançons une instance gérée régulière PostgreSQL ou MySQL sur des ressources minimales. Quand plus de charge arrivera sur l'instance, nous connecterons des répliques supplémentaires auxquelles nous distribuerons une partie de la charge de lecture. S'il n'y a aucune demande et aucune charge, nous désactivons les répliques. La première instance est le maître et les autres sont des répliques.
Cette idée est mise en œuvre dans une base de données appelée Aurora Serverless AWS. Le principe est simple: les demandes provenant d'applications externes sont acceptées par proxy flotte. Voyant une augmentation de la charge, il alloue des ressources informatiques à partir d'instances minimales préchauffées - la connexion est aussi rapide que possible. La déconnexion des instances est la même chose.
Au sein d'Aurora, il y a le concept de l'unité de capacité Aurora, ACU. Il s'agit (conditionnellement) d'une instance (serveur). Chaque ACU spécifique peut être maître ou esclave. Chaque unité de capacité a sa propre RAM, son processeur et son disque minimum. En conséquence, l'un est maître, les autres sont des répliques en lecture seule.
Le nombre de ces unités de capacité Aurora en fonctionnement est configurable. La quantité minimale peut être un ou zéro (dans ce cas, la base ne fonctionne pas s'il n'y a pas de demandes).

Lorsque la base reçoit des demandes, la flotte de proxy augmente Aurora CapacityUnits, augmentant ainsi les ressources productives du système. La capacité d'augmenter et de diminuer les ressources permet au système de «jongler» avec les ressources: afficher automatiquement les ACU individuelles (en les remplaçant par de nouvelles) et déployer toutes les mises à jour pertinentes sur les ressources supprimées.
La base Aurora Serverless peut mettre à l'échelle la charge de lecture. Mais la documentation ne le dit pas directement. On peut avoir l'impression qu'ils peuvent choisir un multi-maître. Il n'y a pas de magie.
Cette base est bien adaptée pour ne pas dépenser beaucoup d'argent sur des systèmes avec un accès imprévisible. Par exemple, lors de la création de sites de marketing MVP ou de cartes de visite, nous ne nous attendons généralement pas à une charge constante. Par conséquent, en l'absence d'accès, nous ne payons pas pour les instances. Lorsqu'une charge survient de manière inattendue, par exemple après une conférence ou une campagne publicitaire, des foules de personnes visitent le site et que la charge augmente considérablement, Aurora Serverless prend automatiquement en charge cette charge et connecte rapidement les ressources manquantes (ACU). Puis la conférence continue, tout le monde oublie le prototype, les serveurs (ACU) sortent et les coûts tombent à zéro - c'est pratique.
Cette solution n'est pas adaptée aux charges élevées stables car elle ne peut pas faire évoluer la charge d'écriture. Toutes ces connexions et déconnexions de ressources se produisent au moment du soi-disant "point d'échelle" - au moment où la base de données n'est pas détenue par la transaction, les tables temporaires ne sont pas conservées. Par exemple, pendant une semaine, le point d'échelle peut ne pas se produire, et la base fonctionne sur les mêmes ressources et ne peut tout simplement pas s'étendre ou se réduire.
Il n'y a pas de magie - c'est PostgreSQL normal. Mais le processus d'ajout de voitures et de déconnexion est partiellement automatisé.
Sans serveur par conception
Aurora Serverless est une ancienne base réécrite pour le cloud afin de profiter des avantages individuels de Serverless. Et maintenant, je vais vous parler de la base, qui a été initialement écrite pour le cloud, pour l'approche sans serveur - Serverless-by-design. Il a été développé tout de suite sans supposer qu'il fonctionne sur des serveurs physiques.
Cette base s'appelle Snowflake. Il comporte trois blocs clés.
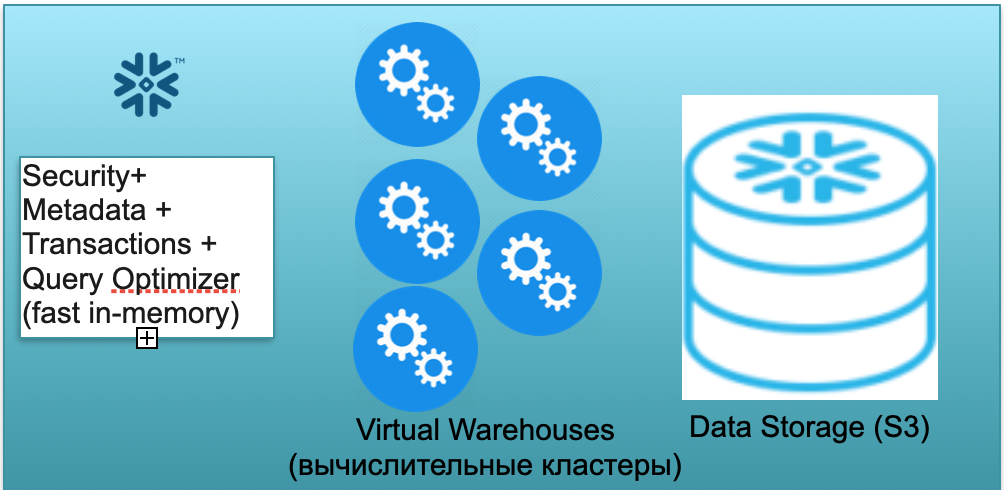
Le premier est un bloc de métadonnées. C'est un service en mémoire rapide qui résout les problèmes de sécurité, de métadonnées, de transactions, d'optimisation des requêtes (dans l'illustration de gauche).
Le deuxième bloc est un ensemble de clusters de calcul virtuels pour les calculs (dans l'illustration - un ensemble de cercles bleus).
Le troisième bloc est un système de stockage basé sur S3. S3 est le stockage d'objets sans dimension d'AWS, semblable à Dropbox sans dimension pour les entreprises.
Jetons un coup d'œil au fonctionnement de Snowflake sous l'hypothèse d'un démarrage à froid. Autrement dit, la base de données est là, les données y sont chargées, il n'y a pas de requêtes de travail. En conséquence, s'il n'y a pas de requêtes dans la base de données, nous avons créé un service rapide de métadonnées en mémoire (premier bloc). Et nous avons un stockage S3, où les données de table sont stockées, divisées en soi-disant micropartitions. Pour plus de simplicité: si le tableau contient des offres, alors les micro-lots sont les jours des offres. Chaque jour est un micro-lot séparé, un fichier séparé. Et lorsque la base de données fonctionne dans ce mode, vous ne payez que pour l'espace occupé par les données. De plus, le taux par siège est très faible (surtout compte tenu de la compression importante). Le service de métadonnées fonctionne également en permanence, mais il n'a pas besoin de beaucoup de ressources pour optimiser les requêtes, et le service peut être considéré comme un shareware.
Imaginons maintenant qu'un utilisateur accède à notre base de données et lance une requête SQL. La requête SQL est immédiatement envoyée au service de métadonnées pour traitement. Ainsi, à la réception d'une demande, ce service analyse la demande, les données disponibles, l'autorité des utilisateurs et, si tout va bien, établit un plan de traitement des demandes.
Ensuite, le service lance le lancement du cluster de calcul. Un cluster de calcul est un cluster de serveurs qui effectuent des calculs. Autrement dit, il s'agit d'un cluster qui peut contenir 1 serveur, 2 nord, 4, 8, 16, 32 - autant que vous le souhaitez. Vous lancez une requête et le lancement de ce cluster démarre instantanément en dessous. Cela prend vraiment quelques secondes.
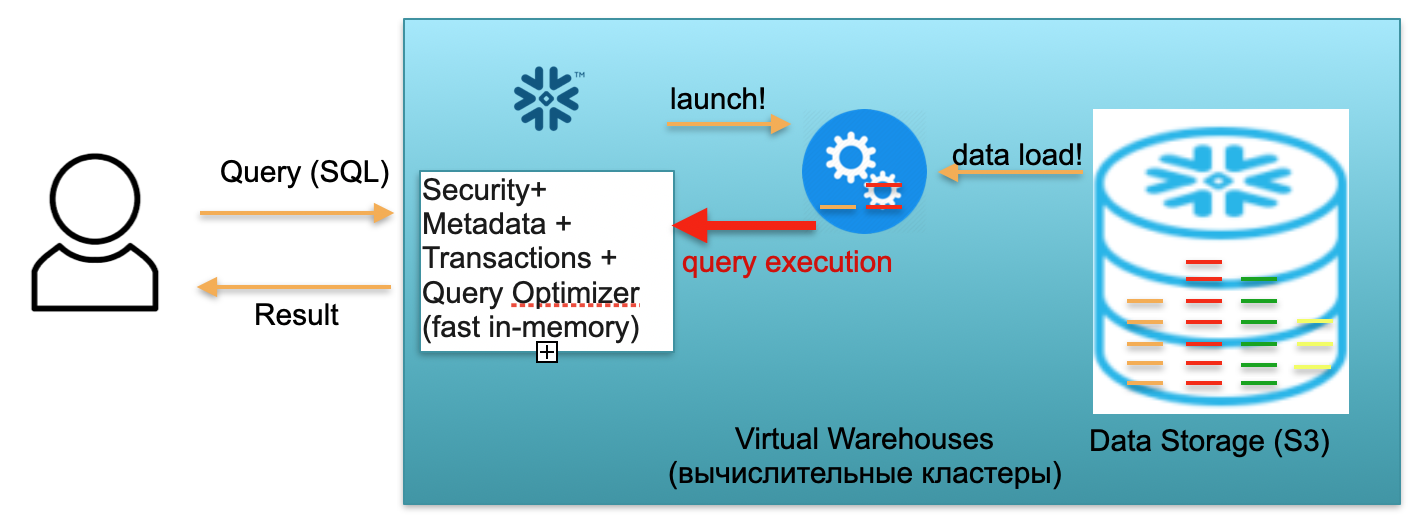
De plus, une fois le cluster démarré, les micropartitions sont copiées de S3 vers le cluster, ce qui est nécessaire pour traiter votre demande. Autrement dit, imaginez que pour exécuter une requête SQL, vous avez besoin de deux partitions d'une table et d'une de la seconde. Dans ce cas, seules les trois partitions nécessaires seront copiées dans le cluster, et non toutes les tables dans leur ensemble. C'est pourquoi et précisément parce que tout est dans le cadre d'un data center et est connecté par des canaux très rapides, l'ensemble du processus de pompage se déroule très rapidement: en quelques secondes, très rarement - en quelques minutes, si l'on ne parle pas de demandes monstrueuses ... En conséquence, les micropartitions sont copiées dans un cluster de calcul et, à la fin, une requête SQL est exécutée sur ce cluster de calcul. Le résultat de cette requête peut être une ligne, plusieurs lignes ou un tableau - ils sont envoyés à l'utilisateur,afin qu'il puisse être téléchargé, affiché dans son outil BI ou utilisé d'une autre manière.
Chaque requête SQL peut non seulement lire des agrégats à partir de données précédemment chargées, mais également charger / former de nouvelles données dans la base de données. Autrement dit, il peut s'agir d'une requête qui, par exemple, insère de nouveaux enregistrements dans une autre table, ce qui conduit à l'apparition d'une nouvelle partition sur le cluster de calcul, qui, à son tour, est automatiquement stockée dans un seul stockage S3.
Le scénario décrit ci-dessus, de l'arrivée d'un utilisateur à la montée du cluster, au chargement de données, à l'exécution de requêtes, à l'obtention de résultats, est rémunéré au tarif par minute d'utilisation du cluster de calcul virtuel surélevé, l'entrepôt virtuel. Le taux varie en fonction de la zone AWS et de la taille du cluster, mais en moyenne, il est de quelques dollars par heure. Un groupe de quatre voitures coûte deux fois plus cher qu'un groupe de deux voitures, et de huit voitures est deux fois plus cher. Options disponibles à partir de 16, 32 voitures, en fonction de la complexité des demandes. Mais vous ne payez que pour ces minutes où le cluster fonctionne réellement, car quand il n'y a pas de demandes, vous prenez en quelque sorte vos mains, et après 5 à 10 minutes d'attente (un paramètre configurable), il s'éteindra de lui-même, libèrera des ressources et deviendra libre.
Le scénario est tout à fait réel, lorsque vous lancez une requête, le cluster apparaît, relativement parlant, en une minute, il compte une autre minute, puis cinq minutes pour s'arrêter, et vous payez en conséquence pour sept minutes de fonctionnement de ce cluster, et non pendant des mois et des années.
Le premier scénario décrit l'utilisation de Snowflake dans un scénario mono-utilisateur. Imaginons maintenant qu'il y ait beaucoup d'utilisateurs, ce qui est plus proche d'un scénario réel.
Supposons que nous ayons beaucoup d'analystes et de rapports Tableau qui bombardent constamment notre base de données avec un grand nombre de requêtes SQL analytiques simples.
De plus, disons que nous avons des Data Scientists ingénieux qui essaient de faire des choses monstrueuses avec des données, opèrent sur des dizaines de téraoctets, analysent des milliards et des billions de lignes de données.
Pour les deux types de charge décrits ci-dessus, Snowflake vous permet de soulever plusieurs clusters de calcul indépendants de capacités différentes. De plus, ces clusters de calcul fonctionnent indépendamment, mais avec des données cohérentes communes.
Pour un grand nombre de requêtes légères, vous pouvez générer 2 à 3 petits clusters, de taille conventionnelle, de 2 machines chacun. Ce comportement est réalisable, entre autres, à l'aide de paramètres automatiques. Autrement dit, vous dites: «Flocon de neige, élevez un petit groupe. Si la charge sur celui-ci dépasse un certain paramètre, augmentez un deuxième, troisième similaire. Lorsque la charge commence à diminuer - éteignez les autres. " Pour que peu importe le nombre d'analystes qui viennent et commencent à consulter les rapports, chacun dispose de suffisamment de ressources.
En même temps, si les analystes dorment et que personne ne regarde les rapports, les clusters peuvent complètement disparaître et vous arrêtez de les payer.
Dans le même temps, pour les requêtes lourdes (de Data Scientists), vous pouvez générer un très grand cluster par 32 machines conditionnelles. Ce cluster sera également facturé uniquement pour les minutes et les heures pendant lesquelles votre requête géante y est exécutée.
La fonctionnalité décrite ci-dessus permet de diviser en clusters non seulement 2, mais aussi plusieurs types de charge (ETL, monitoring, matérialisation de rapports, ...).
Résumons le flocon de neige. La base combine une belle idée et une mise en œuvre réalisable. Chez ManyChat, nous utilisons Snowflake pour analyser toutes les données dont nous disposons. Nous n'avons pas trois clusters, comme dans l'exemple, mais de 5 à 9, de tailles différentes. Nous avons 16 machines conditionnelles, 2 machines, il existe également de très petites machines 1 pour certaines tâches. Ils distribuent avec succès la charge et nous permettent d'économiser beaucoup.
La base met à l'échelle avec succès la charge de travail de lecture et d'écriture. C'est une énorme différence et une énorme avancée par rapport au même "Aurora", qui n'a tiré que la charge de lecture. Snowflake permet à ces clusters de calcul de mettre à l'échelle et d'écrire des charges de travail. Autrement dit, comme je l'ai mentionné, nous utilisons plusieurs clusters dans ManyChat, les clusters petits et très petits sont principalement utilisés pour ETL, pour le chargement de données. Et les analystes vivent déjà sur des clusters de taille moyenne qui ne sont absolument pas affectés par la charge ETL, ils travaillent donc très rapidement.
En conséquence, la base est bien adaptée aux tâches OLAP. Dans le même temps, malheureusement, il n'est pas encore applicable pour les charges de travail OLTP. Premièrement, cette base est colonnaire, avec toutes les conséquences qui en découlent. Deuxièmement, l'approche elle-même, lorsque pour chaque demande, si nécessaire, vous soulevez un cluster de calcul et le répandez avec des données, malheureusement, pour les charges de travail OLTP, ce n'est toujours pas assez rapide. Attendre quelques secondes pour les tâches OLAP est normal, mais pour les tâches OLTP, c'est inacceptable, 100 ms serait mieux, et même mieux - 10 ms.
Résultat
Une base de données sans serveur est possible en séparant la base de données en parties sans état et avec état. Vous devez avoir remarqué que dans tous les exemples donnés, la partie Stateful stocke, relativement parlant, des micropartitions dans S3, et Stateless est un optimiseur, travaillant avec des métadonnées, gérant les problèmes de sécurité qui peuvent être soulevés comme un poids léger indépendant. Services apatrides.
L'exécution de requêtes SQL peut également être considérée comme des services à l'état léger qui peuvent apparaître en mode sans serveur, comme les clusters de calcul Snowflake, télécharger uniquement les données dont vous avez besoin, exécuter la requête et «sortir».
Les bases de données au niveau de la production sans serveur sont déjà disponibles, elles fonctionnent. Ces bases de données sans serveur sont déjà prêtes à gérer les tâches OLAP. Malheureusement, ils sont utilisés pour les tâches OLTP ... avec des nuances, car il y a des limitations. D'une part, c'est un inconvénient. Mais d'un autre côté, c'est une opportunité. Certains lecteurs trouveront peut-être un moyen de rendre la base de données OLTP complètement sans serveur, sans les limitations d'Aurora.
J'espère que vous l'avez trouvé intéressant. L'avenir est sans serveur :)