
Ces lacs (lacs de données ) deviennent en fait la norme pour les entreprises et les sociétés qui essaient d'utiliser toutes les informations dont elles disposent. Les composants open source sont souvent une option intéressante lors du développement de grands lacs de données. Nous examinerons les modèles architecturaux généraux nécessaires pour créer un lac de données pour les solutions cloud ou hybrides, et mettrons également en évidence un certain nombre de détails critiques à surveiller lors de la mise en œuvre de composants clés.
Conception de flux de données
Un flux de lac de données logique typique comprend les blocs fonctionnels suivants:
- Les sources de données;
- Réception de données;
- Nœud de stockage;
- Traitement et enrichissement des données;
- L'analyse des données.
Dans ce contexte, les sources de données sont généralement des flux ou des collections de données d'événements brutes (par exemple, journaux, clics, télémétrie IoT, transactions).
La principale caractéristique de ces sources est que les données brutes sont stockées dans leur forme originale. Le bruit dans ces données consiste généralement en des enregistrements dupliqués ou incomplets avec des champs redondants ou erronés.
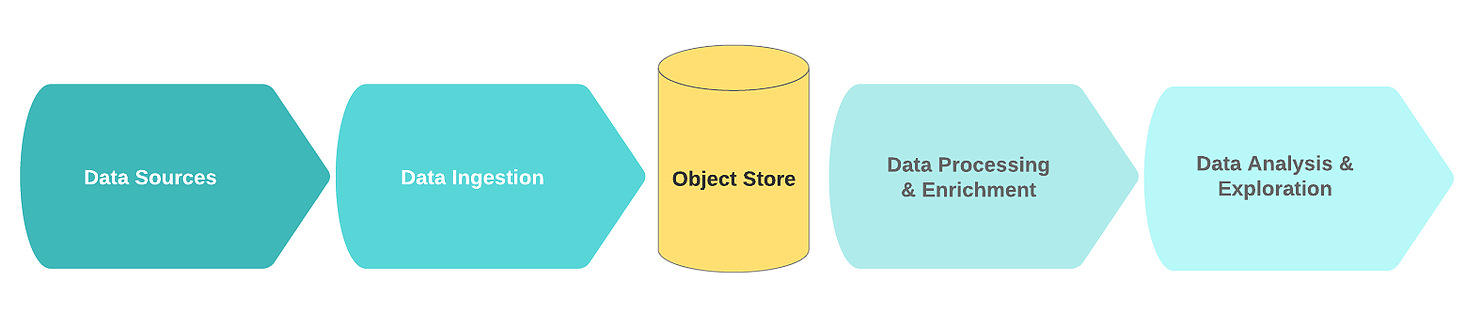
Au stade de l'ingestion, les données brutes proviennent d'une ou plusieurs sources de données. Le mécanisme de réception est le plus souvent mis en œuvre sous la forme d'une ou plusieurs files d'attente de messages avec un simple composant destiné au nettoyage primaire et à la sauvegarde des données. Afin de créer un lac de données efficace, évolutif et cohérent, il est recommandé de faire la distinction entre le nettoyage simple des données et les tâches d'enrichissement de données plus complexes. Une bonne règle de base est que les tâches de nettoyage nécessitent des données provenant d'une seule source dans une fenêtre glissante.
Texte masqué
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
Une fois les données reçues et nettoyées, elles sont stockées dans le système de fichiers distribué (pour améliorer la tolérance aux pannes). Les données sont souvent écrites sous forme de tableau. Lorsque de nouvelles informations sont écrites sur le nœud de stockage, le catalogue de données contenant le schéma et les métadonnées peut être mis à jour à l'aide d'un robot d'exploration hors ligne. Le lancement du robot d'exploration est généralement déclenché par un événement, par exemple, lorsqu'un nouvel objet arrive dans le stockage. Les référentiels sont généralement intégrés à leurs catalogues. Ils déchargent le schéma sous-jacent afin que les données soient accessibles.
Ensuite, les données vont dans une zone spéciale dédiée aux «données or». À partir de ce moment, les données sont prêtes à être enrichies par d'autres processus.
Texte masqué
, , .
Pendant le processus d'enrichissement, les données sont en outre modifiées et nettoyées conformément à la logique métier. En conséquence, ils sont stockés dans un format structuré dans un entrepôt de données ou une base de données utilisée pour récupérer rapidement des informations, des analyses ou un modèle de formation.
Enfin, l'utilisation des données relève de l'analyse et de la recherche. C'est là que les informations extraites sont converties en idées commerciales via des visualisations, des tableaux de bord et des rapports. De plus, ces données sont une source de prévisions utilisant l'apprentissage automatique, dont le résultat aide à prendre de meilleures décisions.
Composants de la plateforme
L'infrastructure cloud Data Lake nécessite une couche d'abstraction robuste et, dans le cas des systèmes cloud hybrides, une couche d'abstraction unifiée pour aider à déployer, coordonner et exécuter des tâches de calcul sans les contraintes des fournisseurs d'API.
Kubernetes est un excellent outil pour ce travail. Il vous permet de déployer, d'organiser et d'exécuter efficacement divers services et tâches de calcul d'un lac de données de manière fiable et rentable. Il offre une API unifiée qui fonctionnera à la fois sur site et dans n'importe quel cloud public ou privé.
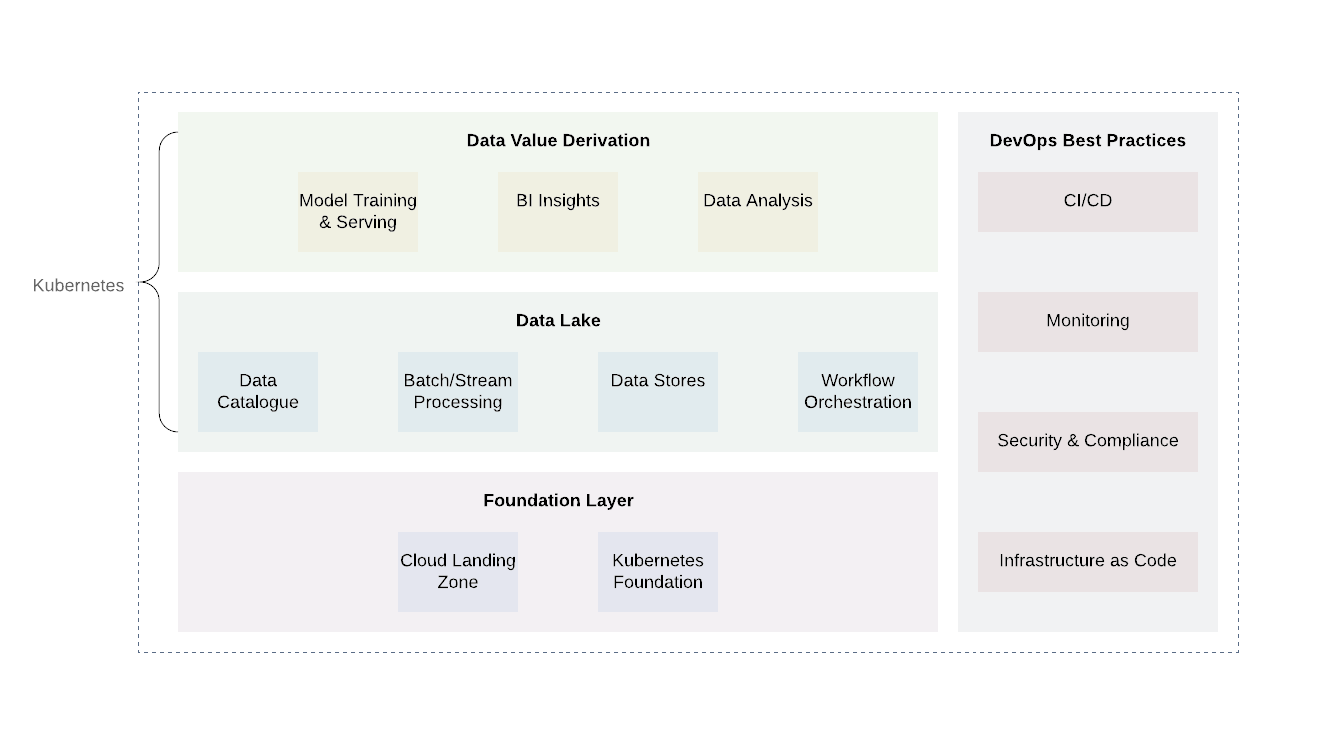
La plate-forme peut être grossièrement divisée en plusieurs couches. La couche de base est l'endroit où nous déployons Kubernetes ou son équivalent. La couche de base peut également être utilisée pour gérer des tâches de calcul en dehors du domaine du lac de données. Lors de l'utilisation de fournisseurs de cloud, il serait prometteur d'utiliser les pratiques déjà établies des fournisseurs de cloud (journalisation et audit, conception d'un accès minimal, analyse et rapport de vulnérabilité, architecture réseau, architecture IAM, etc.) Cela permettra d'atteindre le niveau de sécurité et de conformité requis. ...
Il existe deux niveaux supplémentaires au-dessus du niveau de base: le lac de données lui-même et le niveau de sortie de valeur. Ces deux couches sont responsables du cœur de la logique métier ainsi que du traitement des données. Bien qu'il existe de nombreuses technologies pour ces deux niveaux, Kubernetes se révélera à nouveau être une bonne option en raison de sa flexibilité pour prendre en charge une variété de tâches informatiques.
La couche data lake comprend tous les services nécessaires pour la réception ( Kafka , Kafka Connect ), le filtrage, l'enrichissement et le traitement ( Flink et Spark ), la gestion des flux de travail ( Airflow ). De plus, il inclut le stockage de données et les systèmes de fichiers distribués ( HDFS) ainsi que les bases de données SGBDR et NoSQL .
Le niveau le plus élevé obtient les valeurs de données. En gros, c'est le niveau de consommation. Il comprend des composants tels que des outils de visualisation pour comprendre l'intelligence d'affaires, des outils d'exploration de données ( Jupyter Notebooks ). Un autre processus important qui se déroule à ce niveau est l'apprentissage automatique à l'aide d'échantillons d'apprentissage d'un lac de données.
Il est important de noter que la mise en œuvre de pratiques DevOps communes fait partie intégrante de chaque lac de données: infrastructure en tant que code, observabilité, audit et sécurité. Ils jouent un rôle important dans la résolution des problèmes quotidiens et doivent être appliqués à tous les niveaux pour garantir la standardisation, la sécurité et la facilité d'utilisation.
, — , opensource-.
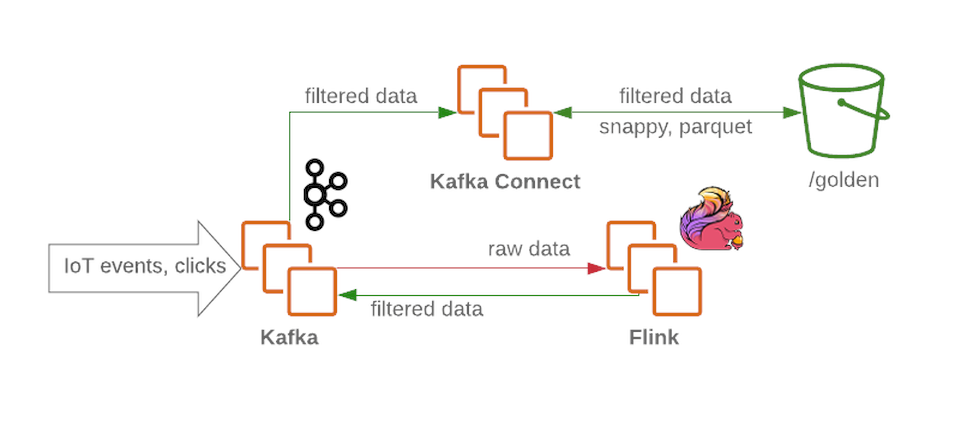
Le cluster Kafka recevra des messages non filtrés et non traités et fonctionnera comme un nœud de réception dans le lac de données. Kafka fournit un débit de messages élevé de manière fiable. Un cluster contient généralement plusieurs sections pour les données brutes, traitées (pour la diffusion en continu) et les données non livrées ou mal formées.
Flink accepte un message d'un nœud de données brutes de Kafka , filtre les données et pré-enrichit les données si nécessaire. Les données sont ensuite renvoyées à Kafka (dans une section distincte pour les données filtrées et riches). En cas d'échec ou lorsque la logique métier change, ces messages peuvent être rappelés, car dans lequel ils sont sauvésKafka . Il s'agit d'une solution courante pour les processus de streaming. Pendant ce temps, Flink écrit tous les messages mal formés dans une autre section pour une analyse plus approfondie.
En utilisant Kafka Connect, nous avons la possibilité d'enregistrer des données sur les backends de stockage de données requis (comme la zone d'or dans HDFS ). Kafka Connect évolue facilement et vous aidera à augmenter rapidement le nombre de processus simultanés en augmentant le débit sous une charge de travail importante:
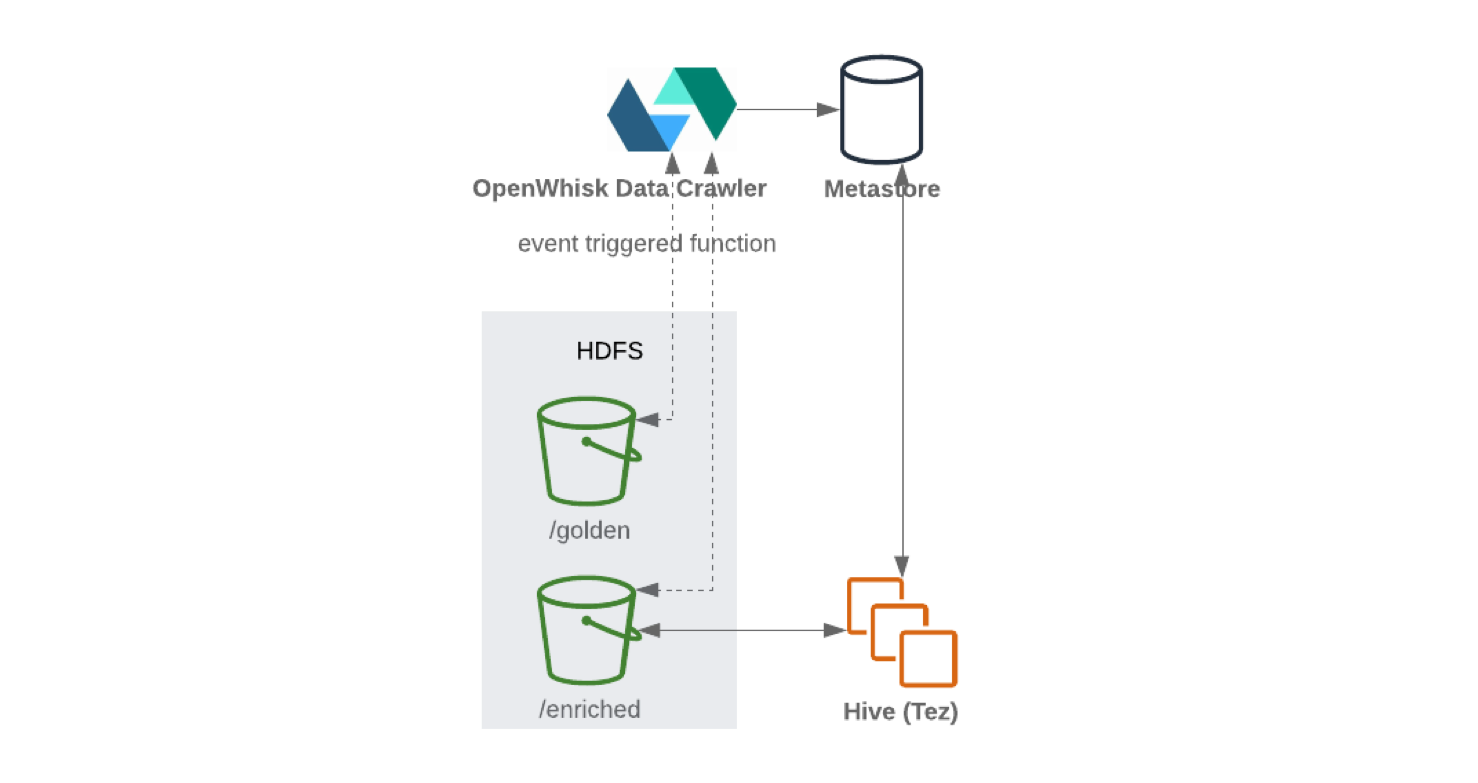
Lors de l'écriture de Kafka Connect vers HDFS, il est recommandé d'effectuer une division du contenu pour une gestion efficace des données (moins il y a de données à analyser, moins il y a de demandes et de réponses). Une fois les données écrites sur HDFS , la fonctionnalité sans serveur (comme OpenWhisk ou Knative ) mettra régulièrement à jour les métadonnées et le magasin de paramètres de schéma. En conséquence, le schéma mis à jour est accessible via une interface de type SQL (par exemple, Hive ou Presto ).
Apache Airflow peut être utilisé pour les flux de données ultérieurs et le contrôle des processus ETL . Il permet aux utilisateurs d'exécuter des piplines en plusieurs étapes à l' aide d' objets Python et Directed Acyclic Graph ( DAG ). L'utilisateur peut définir des dépendances, programmer des processus complexes et suivre les tâches via une interface graphique. Apache Airflow peut également gérer toutes les données externes. Par exemple, pour recevoir des données via une API externe et les stocker dans un stockage persistant. Spark alimenté par Apache Airflow
grâce à un plug-in spécial, il peut enrichir périodiquement les données brutes filtrées conformément aux objectifs commerciaux et préparer les données pour la recherche par les scientifiques des données et les analystes commerciaux. Les data scientists peuvent utiliser JupyterHub pour gérer plusieurs notebooks Jupyter . Par conséquent, il vaut la peine d'utiliser Spark pour configurer des interfaces multi-utilisateurs pour travailler avec les données, les collecter et les analyser.

Pour l'apprentissage automatique, vous pouvez utiliser des frameworks tels que Kubeflow , en tirant parti de l' évolutivité de Kubernetes . Les modèles de formation résultants peuvent être renvoyés au système.
Si nous assemblons le puzzle, nous obtenons quelque chose comme ceci:

L'excellence opérationnelle
Nous avons dit que les principes de DevOps et DevSecOps sont des composants essentiels de tout lac de données et ne doivent jamais être négligés. Avec beaucoup de puissance, il y a beaucoup de responsabilités, en particulier lorsque toutes les données structurées et non structurées sur votre entreprise se trouvent au même endroit.
Les principes de base seront les suivants:
- Restreindre l'accès des utilisateurs;
- Surveillance;
- Cryptage des données;
- Solutions sans serveur;
- Utilisation des processus CI / CD.
Les principes de DevOps et DevSecOps sont des composants essentiels de tout lac de données et ne doivent jamais être négligés. Avec beaucoup de puissance, il y a beaucoup de responsabilités, en particulier lorsque toutes les données structurées et non structurées sur votre entreprise se trouvent au même endroit.
L'une des méthodes recommandées consiste à autoriser l'accès à certains services uniquement en attribuant les droits appropriés et à refuser l'accès direct aux utilisateurs afin que les utilisateurs ne puissent pas modifier les données (cela s'applique également aux commandes). Une surveillance complète en enregistrant les actions est également importante pour protéger les données.
Le cryptage des données est un autre mécanisme de protection des données. Les données stockées peuvent être cryptées à l'aide d'un système de gestion de clés ( KMS). Cela cryptera votre système de stockage et son état actuel. À son tour, le chiffrement de la transmission peut être effectué à l'aide de certificats pour toutes les interfaces et tous les points de terminaison de services tels que Kafka et ElasticSearch .
Et dans le cas des moteurs de recherche qui peuvent ne pas respecter la politique de sécurité, il vaut mieux privilégier les solutions sans serveur . Il est également nécessaire d'abandonner les déploiements manuels, les changements de situation dans tout composant du lac de données; chaque changement doit provenir du contrôle à la source et passer par une série de tests CI avant d'être déployé sur un lac de données produit ( test de fumée , régression, etc.).
Épilogue
Nous avons couvert les principes de conception de base d'une architecture de lac de données open source. Comme cela arrive souvent, le choix de l'approche n'est pas toujours évident et peut être dicté par des exigences commerciales, budgétaires et temporelles différentes. Mais tirer parti de la technologie cloud pour créer des lacs de données, qu'il s'agisse d'une solution hybride ou entièrement cloud, est une tendance émergente dans l'industrie. Cela est dû au grand nombre d'avantages que cette approche offre. Il a un haut niveau de flexibilité et ne limite pas le développement. Il est important de comprendre qu'un modèle de travail flexible apporte des avantages économiques significatifs, vous permettant de combiner, de mettre à l'échelle et d'améliorer les processus appliqués.