Toutes les implémentations dans un fichier .h d'en-tête: [fast_mem_pool.h]
Chips, pourquoi cet allocateur est meilleur que des centaines d'autres similaires - sous la coupe.
Voilà comment fonctionne mon vélo.
1) Dans la version Release, il n'y a pas de mutex et pas de cycles d'attente pour atomic - mais l'allocateur est cyclique et régénère continuellement les ressources à mesure qu'elles sont libérées par les threads. Comment fait-il?
Chaque allocation de RAM que FastMemPool donne via fmalloc est en fait plus pour un en-tête:
struct AllocHeader {
// : tag_this = this + leaf_id
uint64_t tag_this { 2020071700 };
// :
int size;
// :
int leaf_id { -2020071708 };
};
Cet en-tête peut toujours être obtenu à partir du pointeur appartenant à l'utilisateur en revenant du pointeur (res_ptr) sizeof (AllocHeader):

Par le contenu de l'en-tête AllocHeader, la méthode ffree (void * ptr) reconnaît ses allocations et trouve dans laquelle des feuilles de la mémoire tampon circulaire est retournée :
void ffree(void *ptr)
{
char *to_free = static_cast<char *>(ptr)
- sizeof(AllocHeader);
AllocHeader *head = reinterpret_cast<AllocHeader *>(to_free);
Lorsque l'allocateur est invité à allouer de la mémoire, il regarde la feuille actuelle du tableau de feuilles pour voir s'il peut couper la taille requise + la taille de l'en-tête sizeof (AllocHeader).
Dans l'allocateur, les feuilles de mémoire Leaf_Cnt sont réservées à l'avance, chaque feuille de la taille Leaf_Size_Bytes (tout est traditionnel ici). À la recherche d'une opportunité d'allocation, la méthode fmalloc (std :: size_t allocation_size) fera le tour des feuilles du tableau leaf_array, et si tout est occupé partout, à condition que l'indicateur Do_OS_malloc soit activé, cela prendra de la mémoire du système d'exploitation plus grande que la taille requise par sizeof (AllocHeader) - out la mémoire est extraite du tampon circulaire interne ou de l'OS, l'allocateur crée toujours un en-tête avec des informations de service. Si l'allocateur manque de mémoire et que l'indicateur Do_OS_malloc == false, alors fmalloc retournera nullptr - ce comportement est utile pour contrôler la charge (par exemple, sauter les images d'une caméra vidéo lorsque les modules de traitement des images ne suivent pas le FPS de la caméra).
Comment le cyclisme est mis en œuvre
Les allocateurs cycliques sont conçus pour les tâches cycliques - les tâches ne doivent pas durer éternellement. Par exemple, cela peut être:
- allocations pour les sessions utilisateur
- traitement des images de flux vidéo pour l'analyse vidéo
- la vie des unités de combat dans le jeu
Puisqu'il peut y avoir n'importe quel nombre de feuilles de mémoire dans le tableau leaf_array, dans la limite, il est possible de créer une page pour le nombre théoriquement possible d'unités de combat dans le jeu, de sorte qu'avec la condition d'abandon des unités, nous sommes assurés d'obtenir une feuille de mémoire libre. En pratique, pour l'analyse vidéo, 16 grandes feuilles me suffisent généralement, dont les premières feuilles sont données pour des allocations non cycliques à long terme lorsque le détecteur est initialisé.
Comment la sécurité des threads est implémentée
Le tableau des feuilles d'allocation fonctionne sans mutex ... La protection contre les erreurs de type "data race" se fait comme suit:
char *buf;
// available == offset
std::atomic<int> available { Leaf_Size_Bytes };
// allocated ==
std::atomic<int> deallocated { 0 };
Chaque feuille mémoire possède 2 compteurs:
- disponibles initialisés par la taille du Leaf_Size_Bytes. A chaque allocation, ce compteur décroît, et le même compteur sert de décalage par rapport au début de la feuille mémoire == la mémoire est allouée à partir de la fin du buffer:
result_ptr = leaf_array[leaf_id].buf + available_after;
- la désallocation est initialisée {0} à zéro, et à chaque désallocation sur cette feuille (j'apprends d'AllocHeader sur quelle feuille ou quel système d'exploitation la transaction est traitée) le compteur est augmenté du volume libéré:
const int deallocated = leaf_array[head->leaf_id].deallocated.fetch_add(real_size, std::memory_order_acq_rel) + real_size;
Dès que les compteurs comme celui-ci (désalloué == (Leaf_Size_Bytes - available)) correspondent, cela signifie que tout ce qui a été alloué est maintenant libéré et vous pouvez réinitialiser la feuille à son état d'origine, mais voici un point subtil: que se passera-t-il si après la décision de réinitialiser la feuille retour à l'original, quelqu'un alloue un autre petit morceau de mémoire de la feuille ... Pour exclure cela, utilisez le contrôle compare_exchange_strong:
if (deallocated == (Leaf_Size_Bytes - available))
{ // ,
// , , Leaf
if (leaf_array[head->leaf_id].available
.compare_exchange_strong(available, Leaf_Size_Bytes))
{
leaf_array[head->leaf_id].deallocated -= deallocated;
}
}
La feuille mémoire n'est remise à son état initial que si au moment de la remise à zéro le même état du compteur disponible subsiste, qui était au moment de la décision. Ta-daa !!!
Un bon bonus est que vous pouvez attraper les bogues suivants en utilisant l'en-tête AllocHeader de chaque allocation:
- réallocation
- désallocation de la mémoire de quelqu'un d'autre
- débordement de tampon
- accès à la zone mémoire de quelqu'un d'autre
La deuxième fonctionnalité est implémentée sur ces opportunités.
2) La compilation Debug fournit les informations exactes sur l'emplacement de la précédente désallocation lors de la réallocation: nom de fichier, numéro de ligne de code, nom de méthode. Ceci est implémenté sous la forme de décorateurs autour des méthodes de base (fmallocd, ffreed, check_accessd - la version de débogage des méthodes a un d à la fin):
/**
* @brief FFREE - free
* @param iFastMemPool - FastMemPool
* @param ptr - fmaloc
*/
#if defined(Debug)
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffreed (__FILE__, __LINE__, __FUNCTION__, ptr)
#else
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffree (ptr)
#endif
Les macros du préprocesseur sont utilisées:
- __FILE__ - fichier source c ++
- __LINE__ - numéro de ligne dans le fichier source c ++
- __FUNCTION__ - le nom de la fonction où cela s'est produit
Ces informations sont stockées sous forme de correspondance entre le pointeur d'allocation et les informations d'allocation dans le médiateur:
struct AllocInfo {
// : , , :
std::string who;
// true - , false - :
bool allocated { false };
};
std::map<void *, AllocInfo> map_alloc_info;
std::mutex mut_map_alloc_info;
Puisque la vitesse n'est plus aussi importante pour le débogage, un mutex a été utilisé pour protéger le standard std :: map. Le paramètre de modèle (bool Raise_Exeptions = DEF_Raise_Exeptions) affecte s'il faut lever une exception en cas d'erreur.
Pour ceux qui veulent un maximum de confort dans la version Release, vous pouvez définir l'indicateur DEF_Auto_deallocate, puis toutes les allocations de malloc OS seront écrites (déjà sous le mutex dans std :: set <>) et publiées dans le destructeur FastMemPool (utilisé comme suivi d'allocation).
3)Pour éviter des erreurs comme "buffer overflow", je recommande d'utiliser la vérification FastMemPool :: check_access avant de commencer à travailler avec la mémoire allouée. Alors que le système d'exploitation ne se plaint que lorsque vous entrez dans la RAM de quelqu'un d'autre, la fonction check_access (ou la macro FCHECK_ACCESS) calcule par l'en-tête AllocHeader s'il y aura un dépassement de l'allocation donnée:
/**
* @brief check_access -
* @param base_alloc_ptr - FastMemPool
* @param target_ptr -
* @param target_size - ,
* @return - true FastMemPool
*/
bool check_access(void *base_alloc_ptr, void *target_ptr, std::size_t target_size)
// :
if (FCHECK_ACCESS(fastMemPool, elem.array,
&elem.array[elem.array_size - 1], sizeof (int)))
{
elem.array[elem.array_size - 1] = rand();
}
Connaissant le pointeur de l'allocation initiale, vous pouvez toujours obtenir l'en-tête, à partir de l'en-tête, nous trouvons la taille de l'allocation, puis nous calculons si l'élément cible sera dans l'allocation initiale. Il suffit de vérifier une fois avant de démarrer le cycle de traitement au maximum d'accès théoriquement possible. Il se peut très bien que les valeurs limites franchissent les limites d'allocation (par exemple, dans les calculs, il est supposé qu'une variable ne peut marcher que dans une certaine plage en raison de la physique du processus, et par conséquent, vous ne vérifiez pas la rupture de la frontière d'allocation).
Il vaut mieux vérifier une fois que de tuer une semaine plus tard à la recherche de quelqu'un qui écrit occasionnellement des données aléatoires dans vos structures ...
4) Définir le code du modèle par défaut au moment de la compilation via CMake.
CmakeLists.txt contient des paramètres configurables, par exemple:
set(DEF_Leaf_Size_Bytes "65536" CACHE PATH "Size of each memory pool leaf")
message("DEF_Leaf_Size_Bytes: ${DEF_Leaf_Size_Bytes}")
set(DEF_Leaf_Cnt "16" CACHE PATH "Memory pool leaf count")
message("DEF_Leaf_Cnt: ${DEF_Leaf_Cnt}")
Cela rend très pratique la modification des paramètres dans QtCreator:

ou CMake GUI:

Ensuite, les paramètres sont passés au code lors de la compilation comme suit:
set(SPEC_DEFINITIONS
${CMAKE_SYSTEM_NAME}
${CMAKE_BUILD_TYPE}
${SPEC_BUILD}
SPEC_VERSION="${Proj_VERSION}"
DEF_Leaf_Size_Bytes=${DEF_Leaf_Size_Bytes}
DEF_Leaf_Cnt=${DEF_Leaf_Cnt}
DEF_Average_Allocation=${DEF_Average_Allocation}
DEF_Need_Registry=${DEF_Need_Registry}
)
#
target_compile_definitions(${TARGET} PUBLIC ${TARGET_DEFINITIONS})
et dans le code, remplacez les valeurs du modèle par défaut:
#ifndef DEF_Leaf_Size_Bytes
#define DEF_Leaf_Size_Bytes 65535
#endif
template<int Leaf_Size_Bytes = DEF_Leaf_Size_Bytes,
int Leaf_Cnt = DEF_Leaf_Cnt,
int Average_Allocation = DEF_Average_Allocation,
bool Do_OS_malloc = DEF_Do_OS_malloc,
bool Need_Registry = DEF_Need_Registry,
bool Raise_Exeptions = DEF_Raise_Exeptions>
class FastMemPool
{
// ..
};
Ainsi, le modèle d'allocateur peut être ajusté confortablement avec la souris en activant / désactivant les cases à cocher des paramètres CMake.
5) Afin de pouvoir utiliser l'allocateur dans des conteneurs STL dans le même fichier .h, les capacités de std :: allocator sont partiellement implémentées dans le modèle FastMemPoolAllocator:
// compile time :
std::unordered_map<int, int, std::hash<int>,
std::equal_to<int>,
FastMemPoolAllocator<std::pair<const int, int>> > umap1;
// runtime :
std::unordered_map<int, int> umap2(
1024, std::hash<int>(),
std::equal_to<int>(),
FastMemPoolAllocator<std::pair<const int, int>>());
Des exemples d'utilisation peuvent être trouvés ici: test_allocator1.cpp et test_stl_allocator2.cpp .
Par exemple, le travail des constructeurs et des destructeurs sur les allocations:
bool test_Strategy()
{
/*
* Runtime
* ( )
*/
using MyAllocatorType = FastMemPool<333, 33>;
// instance of:
MyAllocatorType fastMemPool;
// inject instance:
FastMemPoolAllocator<std::string,
MyAllocatorType > myAllocator(&fastMemPool);
// 3 :
std::string* str = myAllocator.allocate(3);
// :
myAllocator.construct(str, "Mother ");
myAllocator.construct(str + 1, " washed ");
myAllocator.construct(str + 2, "the frame");
//-
std::cout << str[0] << str[1] << str[2];
// :
myAllocator.destroy(str);
myAllocator.destroy(str + 1);
myAllocator.destroy(str + 2);
// :
myAllocator.deallocate(str, 3);
return true;
}
6) Parfois, dans un grand projet, vous créez une sorte de module, tout testé à fond - cela fonctionne comme une montre suisse. Votre module est inclus dans le détecteur, mis en bataille - et là parfois, une fois par jour, la bibliothèque commence à tomber dans une décharge. En exécutant un vidage sur le débogueur, vous découvrez que dans l'une des traversées en boucle des pointeurs, au lieu de nullptr, quelqu'un a écrit le numéro 8 dans votre pointeur - en allant sur ce pointeur, vous avez naturellement irrité le système d'exploitation.
Comment réduire l'éventail des coupables possibles? Il est très simple d'exclure vos structures des suspects - elles doivent être déplacées vers la RAM vers un autre endroit (où le saboteur ne bombarde pas):
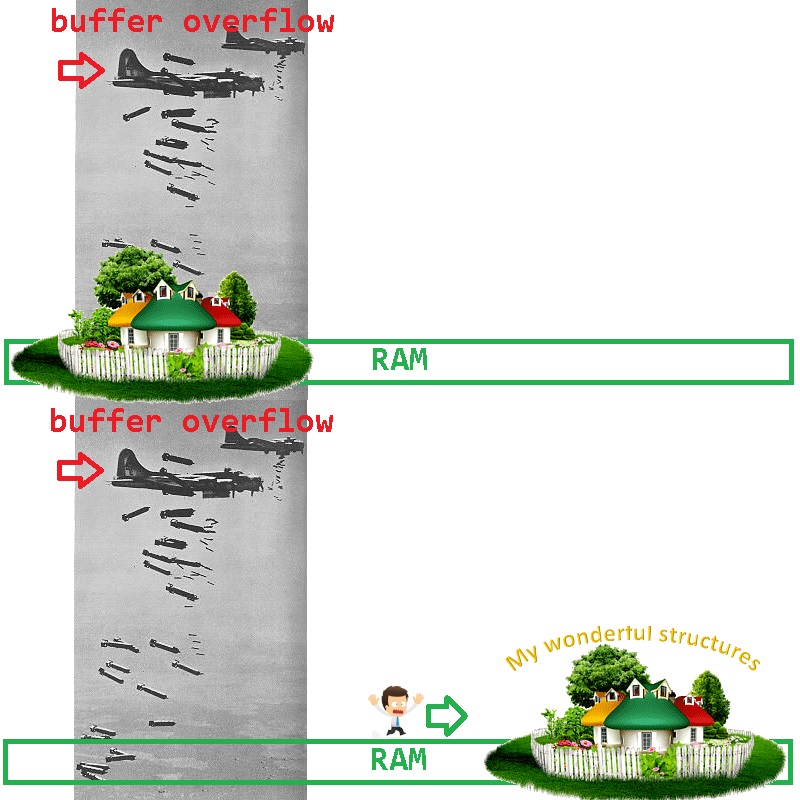
Comment cela peut-il être fait facilement avec FastMemPool? Très simple: dans FastMemPool, l'allocation se fait en mordant à partir de la fin d'une page mémoire - en demandant une page de mémoire plus que ce dont vous avez besoin pour travailler, vous garantissez que le début de la page mémoire reste un terrain d'essai pour les bombardements de bugs. Par exemple:
FastMemPool<100000000, 1, 1024, true, true> bulletproof_mempool;
void *ptr = bulletproof_mempool.fmalloc(1234567);
// ..
// - c ptr
// ..
bulletproof_mempool.ffree(ptr);
Si dans un nouvel endroit quelqu'un bombarde vos structures, alors c'est probablement vous-même ...
Sinon, si la bibliothèque se stabilise, l'équipe recevra plusieurs cadeaux à la fois:
- votre algorithme fonctionne à nouveau comme une montre suisse
- le codeur buggy peut maintenant bombarder en toute sécurité une zone mémoire vide (pendant que tout le monde la cherche), la bibliothèque est stable.
- la plage de bombardement peut être surveillée pour changer la mémoire - pour placer des pièges sur un encodeur buggy.
Au total , quels sont les avantages de ce vélo en particulier:
- ( / )
- , Debug ,
- , /
- , ( nullptr), — , ( FPS , FastMemPool -).
Dans notre entreprise, la mise en place de l'analyse de la géométrie 3D des tôles a nécessité un traitement multi-thread de trames vidéo (50FPS). Les feuilles passent sous la caméra et sur le reflet du laser je construis une carte 3D de la feuille. FastMemPool a été utilisé pour assurer une vitesse maximale de travail avec mémoire et sécurité. Si les flux ne peuvent pas gérer les trames entrantes, la sauvegarde des trames pour un traitement futur de la manière habituelle conduit à une consommation incontrôlée de RAM. Avec FastMemPool, en cas de débordement, nullptr sera simplement renvoyé lors de l'allocation et la trame sera ignorée - dans l'image 3D finale, un tel défaut sous la forme d'un saut dans une étape montre qu'il est nécessaire d'ajouter des threads CPU au traitement.
Le fonctionnement sans mutex des threads avec un allocateur de mémoire circulaire et une pile de tâches a permis de traiter les trames entrantes très rapidement, sans perte de trame et sans débordement de RAM. Maintenant, ce code s'exécute en 16 threads sur un processeur AMD Ryzen 9 3950X, aucune défaillance de la classe FastMemPool n'a été identifiée.
Un exemple de diagramme simplifié du processus d'analyse vidéo avec contrôle de débordement de RAM peut être vu dans le code source test_memcontrol1.cpp .
Et pour le dessert: dans le même schéma d'exemple, une pile non mutex est utilisée:
using TWorkStack = SpecSafeStack<VideoFrame>;
//..
// Video frames exchanger:
TWorkStack work_stack;
//..
work_staff->work_stack.push(frame);
//..
VideoFrame * frame = work_staff->work_stack.pop();
Un stand de démonstration fonctionnel avec toutes les sources est ici sur gihub .