- Appareils embarqués et IoT.
- L'analyse des données.
- Transférer des données d'un système à un autre.
- Archivage des données et (ou) conditionnement des données dans des conteneurs.
- Stockage des données dans une base de données externe ou temporaire.
- Un substitut à une base de données d'entreprise utilisée à des fins de démonstration ou de test.
- Formation, maîtrise par des débutants des techniques pratiques de travail avec une base de données.
- Prototypage et recherche d'extensions expérimentales du langage SQL.
Vous pouvez trouver d' autres raisons d' utiliser cette base de données dans la documentation SQLite . Cet article concerne l'utilisation de SQLite dans le développement Python. Par conséquent, il est particulièrement important pour nous que ce SGBD, représenté par le module , soit inclus dans la bibliothèque standard du langage. Autrement dit, il s'avère que pour travailler avec SQLite à partir de code Python, vous n'avez pas besoin d'installer certains logiciels client-serveur, vous n'avez pas besoin de prendre en charge le fonctionnement de certains services chargés de travailler avec le SGBD. Tout ce que vous avez à faire est d'importer le module et de commencer à l'utiliser dans le programme, après avoir reçu le système de gestion de base de données relationnelle à votre disposition.
sqlite3sqlite3
Importation de module
Ci-dessus, j'ai dit que SQLite est un SGBD intégré à Python. Cela signifie que pour commencer à travailler avec lui, il suffit d'importer le module correspondant sans l'installer au préalable à l'aide d'une commande comme
pip install. La commande d'importation SQLite ressemble à ceci:
import sqlite3 as sl
Créer une connexion à la base de données
Pour établir une connexion à une base de données SQLite, vous n'avez pas à vous soucier de l'installation des pilotes, de la préparation des chaînes de connexion et autres. Il est très simple et rapide de créer une base de données et de mettre à votre disposition un objet de connexion à celle-ci:
con = sl.connect('my-test.db')
En exécutant cette ligne de code, nous allons créer une base de données et nous y connecter. Le fait ici est que la base de données à laquelle nous nous connectons n'existe pas encore, de sorte que le système crée automatiquement une nouvelle base de données vide. Si la base de données a déjà été créée (disons que cela provient
my-test.dbde l'exemple précédent), pour vous y connecter, il vous suffit d'utiliser exactement le même code.

Fichier de base de données nouvellement créé
Créer une table
Créons maintenant une table dans notre nouvelle base de données:
with con:
con.execute("""
CREATE TABLE USER (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT,
age INTEGER
);
""")
Ceci décrit comment ajouter une table
USERavec trois colonnes à la base de données . Comme vous pouvez le voir, SQLite est en effet un système de gestion de base de données très simple, mais il possède toutes les capacités de base que vous attendez d'un système de gestion de base de données relationnelle classique. Nous parlons de la prise en charge des types de données, y compris les types qui autorisent une valeur null, la prise en charge de la clé primaire et l'auto-incrémentation.
Si ce code fonctionne comme prévu (la commande ci-dessus, cependant, ne renvoie rien), nous aurons une table à notre disposition, prête à travailler avec elle.
Insertion d'enregistrements dans une table
Insérons quelques enregistrements dans la table que
USERnous venons de créer. Ceci, entre autres, nous donnera la preuve que la table a bien été créée par la commande ci-dessus.
Imaginons que nous devions ajouter plusieurs enregistrements à la table avec une seule commande. C'est très simple de faire cela dans SQLite:
sql = 'INSERT INTO USER (id, name, age) values(?, ?, ?)'
data = [
(1, 'Alice', 21),
(2, 'Bob', 22),
(3, 'Chris', 23)
]
Ici, nous devons définir une expression SQL avec des points d'interrogation (
?) comme espaces réservés. Étant donné que nous avons un objet de connexion à la base de données à notre disposition, nous, après avoir préparé l'expression et les données, pouvons insérer des enregistrements dans la table:
with con:
con.executemany(sql, data)
Après l'exécution de ce code, aucun message d'erreur n'est reçu, ce qui signifie que les données ont été ajoutées avec succès à la table.
Exécution de requêtes de base de données
Il est maintenant temps de savoir si les commandes que nous venons d'exécuter ont fonctionné correctement. Exécutons une requête dans la base de données et essayons d'obtenir
USERdes données de la table . Par exemple - nous obtenons des enregistrements relatifs aux utilisateurs dont l'âge ne dépasse pas 22 ans:
with con:
data = con.execute("SELECT * FROM USER WHERE age <= 22")
for row in data:
print(row)
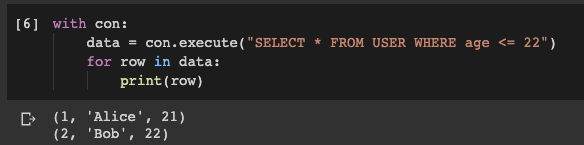
Le résultat de l'exécution d'une requête de base de données
Comme vous pouvez le voir, nous avons réussi à obtenir ce dont nous avions besoin. Et c'était très facile de le faire.
De plus, même si SQLite est un simple SGBD, il dispose d'un support extrêmement large. Par conséquent, vous pouvez l'utiliser en utilisant la plupart des clients SQL.
J'utilise DBeaver. Jetons un coup d'œil à quoi cela ressemble.
Connexion à la base de données SQLite à partir du client SQL (DBeaver)
J'utilise le service cloud de Google Colab et je souhaite télécharger un fichier
my-test.dbsur mon ordinateur. Si vous expérimentez SQLite sur un ordinateur, cela signifie que vous pouvez vous y connecter à l'aide du client SQL sans avoir à télécharger le fichier de base de données depuis quelque part.
Dans le cas de DBeaver, pour vous connecter à la base de données SQLite, vous devez créer une nouvelle connexion et sélectionner SQLite comme type de base de données.
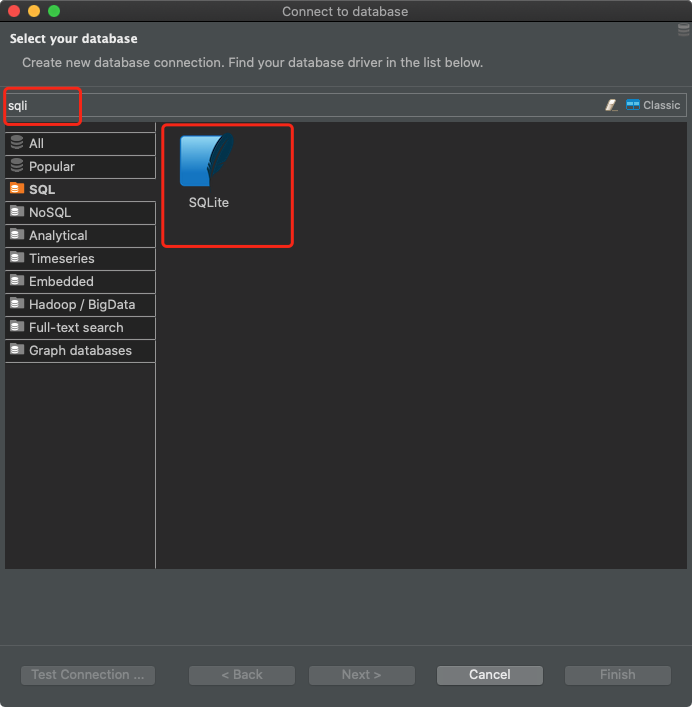
Préparation de la connexion dans DBeaver
Ensuite, vous devez trouver le fichier de base de données.
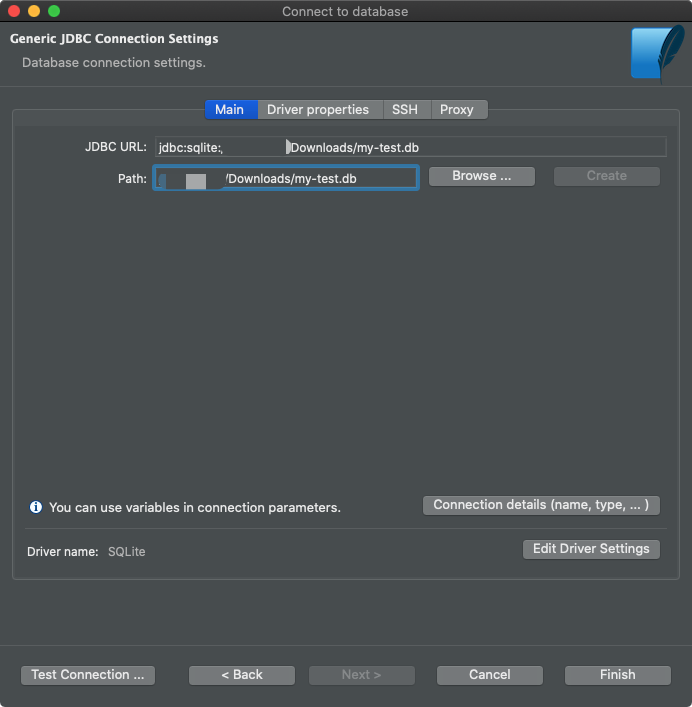
Connexion du fichier de base de données
Après cela, vous pouvez exécuter des requêtes SQL sur la base de données. Il n'y a rien de spécial ici qui diffère du travail avec des bases de données relationnelles régulières.
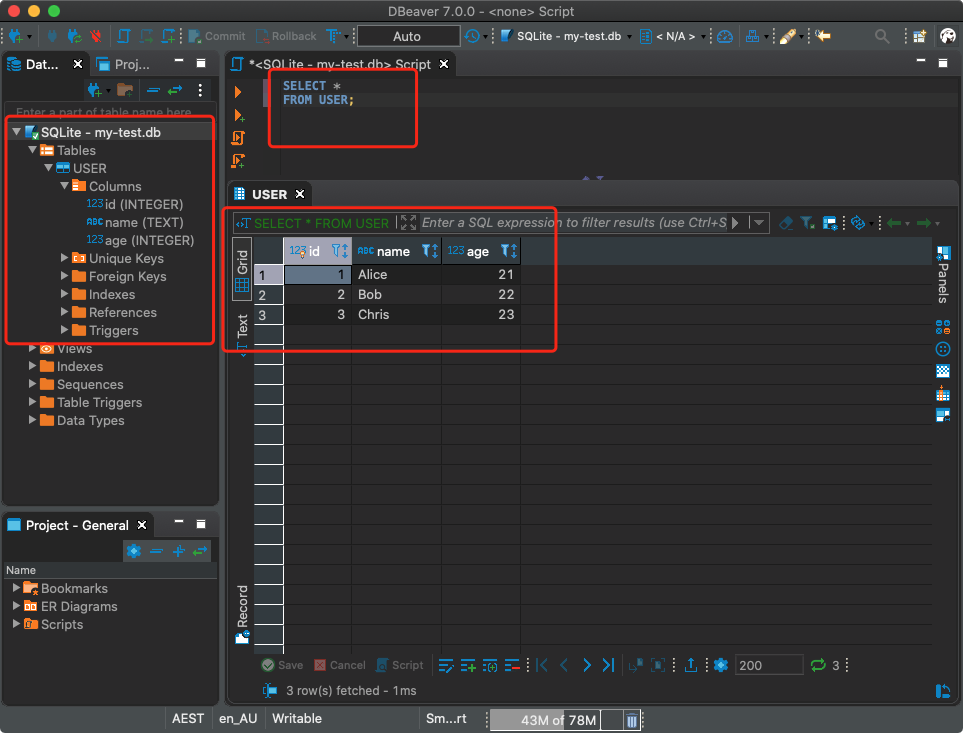
Exécution de requêtes de base de données
Intégration avec les pandas
Pensez-vous que c'est là que nous terminons notre conversation sur la prise en charge de SQLite en Python? Non, nous avons encore beaucoup à dire. À savoir, puisque SQLite est un module Python standard, il s'intègre facilement aux cadres de données pandas.
Déclarons le dataframe:
df_skill = pd.DataFrame({
'user_id': [1,1,2,2,3,3,3],
'skill': ['Network Security', 'Algorithm Development', 'Network Security', 'Java', 'Python', 'Data Science', 'Machine Learning']
})
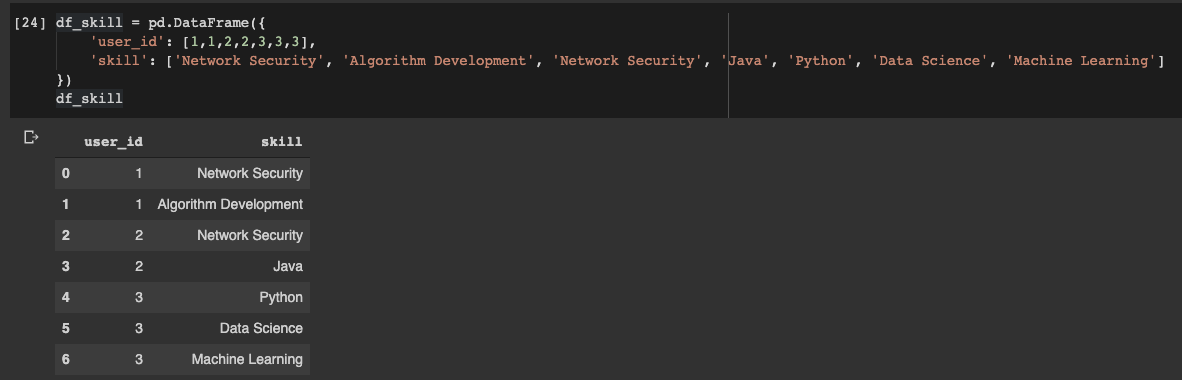
Dataframe Pandas
Pour enregistrer une dataframe dans la base de données, vous pouvez simplement utiliser sa méthode
to_sql():
df_skill.to_sql('SKILL', con)
C'est tout! Nous n'avons même pas besoin de créer une table au préalable. Les types de données et les caractéristiques des champs seront configurés automatiquement en fonction des caractéristiques de la trame de données. Bien sûr, vous pouvez tout personnaliser vous-même si nécessaire.
Supposons maintenant que nous devions obtenir l'union des tables
USERet SKILL, et écrire les données dans datafreym pandas. C'est très simple aussi:
df = pd.read_sql('''
SELECT s.user_id, u.name, u.age, s.skill
FROM USER u LEFT JOIN SKILL s ON u.id = s.user_id
''', con)
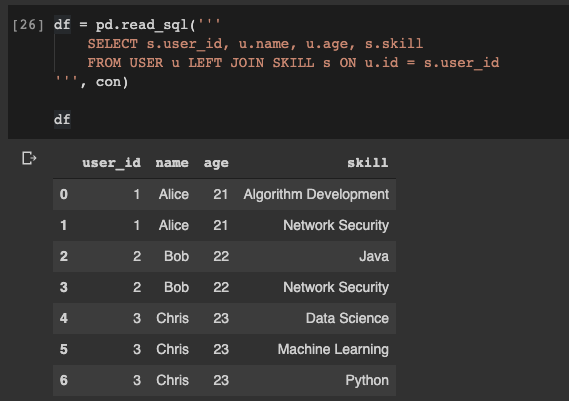
Lire les données d'une base de données dans un dataframe pandas Génial
! Maintenant, écrivons ce que nous avons obtenu dans une nouvelle table appelée
USER_SKILL:
df.to_sql('USER_SKILL', con)
Bien entendu, vous pouvez travailler avec cette table à l'aide du client SQL.
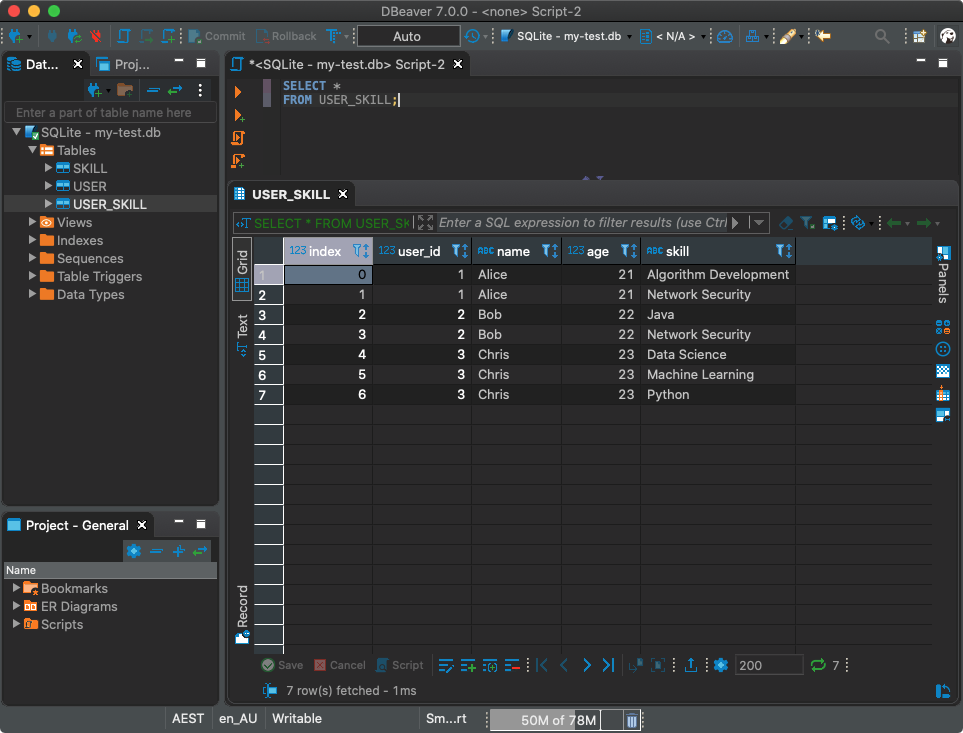
Utilisation d'un client SQL pour travailler avec une base de données
Résultat
Il y a certainement de nombreuses surprises agréables en Python que, à moins que vous ne les recherchiez spécifiquement, vous ne remarquerez peut-être pas. Personne n'a caché ces fonctionnalités spécialement, mais en raison du fait que beaucoup de choses sont intégrées à Python, vous ne pouvez tout simplement pas faire attention à certaines de ces fonctionnalités, ou, après les avoir appris quelque part, oubliez-les.
Ici, j'ai expliqué comment utiliser la bibliothèque intégrée de Python
sqlite3pour créer et travailler avec des bases de données. Bien entendu, ces bases de données prennent en charge non seulement l'opération d'ajout de données, mais également les opérations de modification et de suppression d'informations. Je crois que vous, après avoir appris sqlite3, vous en ferez l'expérience vous-même.
La chose très importante est que SQLite fait un excellent travail avec les pandas. Il est très facile de lire les données de la base de données en les plaçant dans des dataframes. L'opération de sauvegarde du contenu des dataframes dans une base de données n'est pas moins simple. Cela rend SQLite encore plus facile à utiliser.
J'invite tous ceux qui ont lu jusqu'ici à faire leurs propres recherches à la recherche de fonctionnalités Python intéressantes!
Le code que j'ai démontré dans cet article peut être trouvé ici .
Utilisez-vous SQLite dans vos projets Python?
