Dans notre entreprise, nous travaillons activement sur l'auto-abstraction des documents, cet article ne reprenait pas tous les détails et le code, mais décrivait les principales approches et résultats à l'aide de l'exemple d'un jeu de données neutre: 30000 articles d'actualité sportive du football collectés depuis le portail d'information de Sport-Express.
Ainsi, la synthèse peut être définie comme la création automatique d'un résumé (titre, résumé, annotation) du texte original. Il existe deux approches significativement différentes de ce problème: extractive et abstraite.
Récapitulation extractive
L'approche extractive consiste à extraire les blocs d'information les plus «significatifs» du texte source. Un bloc peut être constitué de paragraphes simples, de phrases ou de mots-clés.

Les méthodes de cette approche sont caractérisées par la présence d'une fonction d'évaluation de l'importance du bloc d'information. En classant ces blocs par ordre d'importance et en choisissant un nombre préalablement spécifié, nous formons le résumé final du texte.
Passons à la description de certaines approches extractives.
Sommation extractive basée sur l'occurrence de mots courants
Cet algorithme est très simple à la fois pour sa compréhension et sa mise en œuvre ultérieure. Ici, nous travaillons uniquement avec le code source, et dans l'ensemble, nous n'avons pas besoin de former un modèle d'extraction. Dans mon cas, les blocs d'informations récupérés représenteront certaines phrases de texte.
Ainsi, à la première étape, nous divisons le texte d'entrée en phrases et divisons chaque phrase en jetons (mots séparés), procédons à la lemmatisation pour eux (amenant le mot à la forme «canonique»). Cette étape est nécessaire pour que l'algorithme combine des mots dont le sens est identique, mais qui diffèrent dans les formes de mots.
Ensuite, nous définissons la fonction de similarité pour chaque paire de phrases. Il sera calculé comme le rapport du nombre de mots communs trouvés dans les deux phrases à leur longueur totale... En conséquence, nous obtenons les coefficients de similarité pour chaque paire de phrases.
Ayant précédemment éliminé les phrases qui n'ont pas de mots communs avec d'autres, nous construisons un graphe où les sommets sont les phrases elles-mêmes, les arêtes entre lesquelles montrent la présence de mots communs.
Ensuite, nous classons toutes les propositions en fonction de leur importance.

En sélectionnant plusieurs phrases avec les coefficients les plus élevés et en les triant par le nombre d'occurrences dans le texte, nous obtenons le résumé final.
Somme extractive basée sur des représentations vectorielles entraînées
Des données d'actualité en texte intégral collectées précédemment ont été utilisées pour construire l'algorithme suivant.
Nous divisons les mots de tous les textes en jetons et les combinons en une liste. Au total, les textes contenaient 2 270 778 mots, dont 114 247 étaient uniques.
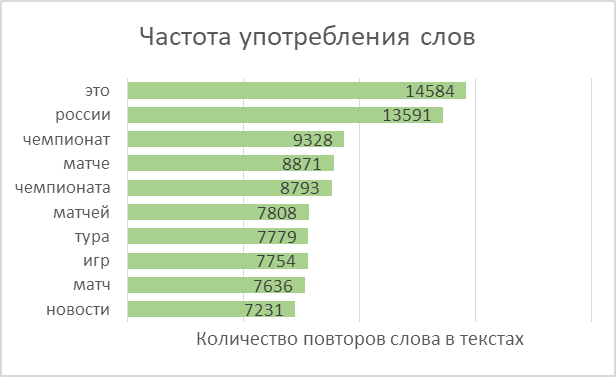
En utilisant le modèle populaire Word2Vec, nous trouverons sa représentation vectorielle pour chaque mot unique. Le modèle attribue des vecteurs aléatoires à chaque mot puis, à chaque étape de l'apprentissage, «étudier le contexte», corrige leurs valeurs. La dimension du vecteur, qui est capable de "se souvenir" de la caractéristique du mot, vous pouvez en définir une. Sur la base du volume de l'ensemble de données disponible, nous prendrons des vecteurs composés de 100 nombres. Je note également que Word2Vec est un modèle recyclable, qui vous permet de soumettre de nouvelles données à l'entrée et, sur leur base, de corriger les représentations vectorielles existantes des mots.
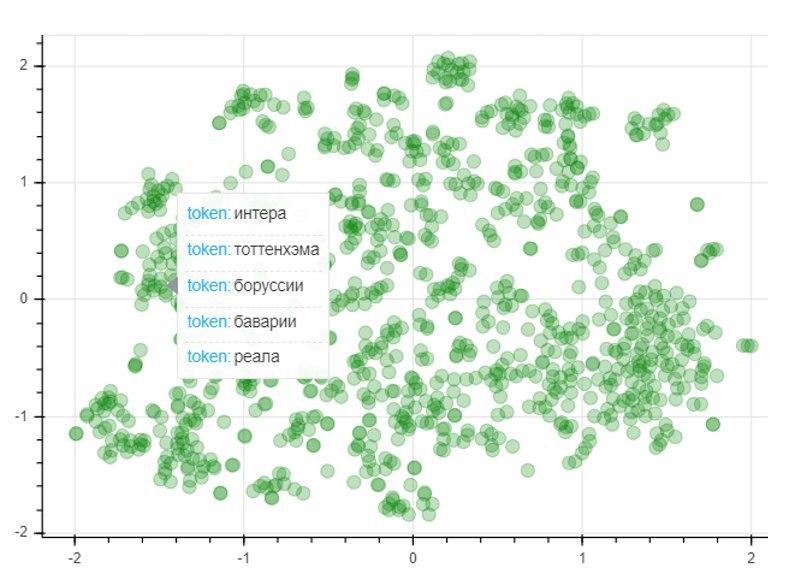
Pour évaluer la qualité du modèle, nous appliquerons la méthode de réduction de dimensionnalité T-SNE, qui construit de manière itérative une cartographie vectorielle pour les 1000 mots les plus utilisés dans un espace bidimensionnel. Le graphe résultant représente l'emplacement des points, dont chacun correspond à un certain mot de telle sorte que des mots de sens similaire sont situés à proximité les uns des autres, et différents au contraire. Ainsi, sur le côté gauche du graphique se trouvent les noms des clubs de football, et les points dans le coin inférieur gauche représentent les noms et prénoms des joueurs de football et des entraîneurs:
Après avoir obtenu les représentations vectorielles entraînées des mots, vous pouvez passer à l'algorithme lui-même. Comme dans le cas précédent, à l'entrée, nous avons un texte que nous divisons en phrases. En tokenisant chaque phrase, nous composons des représentations vectorielles pour elles. Pour ce faire, nous prenons le rapport de la somme des vecteurs pour chaque mot de la phrase à la longueur de la phrase elle-même. Les vecteurs de mots précédemment formés nous aident ici. S'il n'y a pas de mot dans le dictionnaire, un vecteur zéro est ajouté au vecteur de phrase courant. Ainsi, nous neutralisons l'influence de l'apparition d'un nouveau mot qui n'est pas dans le dictionnaire sur le vecteur général de la phrase.
Ensuite, nous composons une matrice de similarité de phrases qui utilise la formule de similarité cosinus pour chaque paire de phrases.
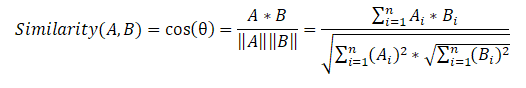
À la dernière étape, sur la base de la matrice de similarité, nous créons également un graphique et effectuons un classement des phrases par importance. Comme dans l'algorithme précédent, nous obtenons une liste de phrases triées en fonction de leur importance dans le texte.

À la fin, je vais schématiser et décrire à nouveau les principales étapes de la mise en œuvre de l'algorithme (pour le premier algorithme d'extraction, la séquence d'actions est exactement la même, sauf que nous n'avons pas besoin de trouver des représentations vectorielles des mots, et la fonction de similarité pour chaque paire de phrases est calculée en fonction de l'occurrence de common mots):

- Diviser le texte d'entrée en phrases séparées et les traiter.
- Recherchez une représentation vectorielle pour chaque phrase.
- Calcul et stockage de la similitude entre les vecteurs de phrases dans une matrice.
- Transformation de la matrice résultante en un graphe avec des phrases sous forme de sommets et des estimations de similarité sous forme d'arêtes pour calculer le rang des phrases.
- Sélection des propositions avec le score le plus élevé pour le CV final.
Comparaison des algorithmes extractifs
En utilisant le microframework Flask (un outil pour créer des applications Web minimalistes ), un service Web de test a été développé pour comparer visuellement la sortie de modèles extractifs en utilisant l'exemple d'une variété de textes de nouvelles sources. J'ai analysé le résumé généré par les deux modèles (en récupérant les 2 phrases les plus significatives) pour 100 articles d'actualité sportive différents.

Sur la base des résultats de la comparaison des résultats de la détermination des offres les plus pertinentes par les deux modèles, je peux proposer les recommandations suivantes pour l'utilisation des algorithmes:
- . , . , .
- . , , , . , , , .
Synthèse abstraite
L'approche abstractive diffère considérablement de son prédécesseur et consiste à générer un résumé avec la génération d'un nouveau texte, résumant de manière significative le document principal.
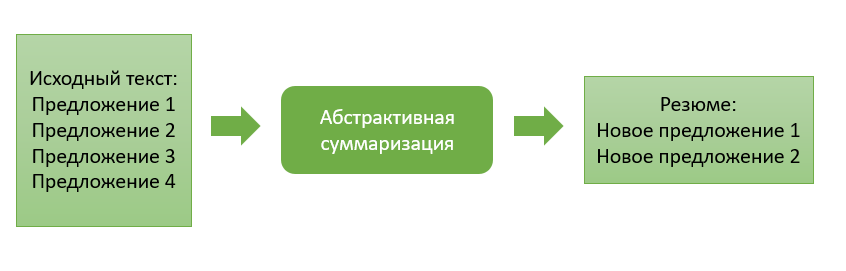
L'idée principale de cette approche est que le modèle est capable de générer un résumé complètement unique, qui peut contenir des mots qui ne sont pas dans le texte d'origine. L'inférence de modèle est une sorte de récit du texte, qui est plus proche de la compilation manuelle d'un résumé du texte par des personnes.
Phase d'apprentissage
Je ne m'attarderai pas sur la justification mathématique de l'algorithme, tous les modèles que je connais sont basés sur l'architecture «encodeur-décodeur», qui à son tour est construite en utilisant des couches LSTM récurrentes (vous pouvez lire le principe de leur travail ici ). Je décrirai brièvement les étapes de décodage de la séquence de test.
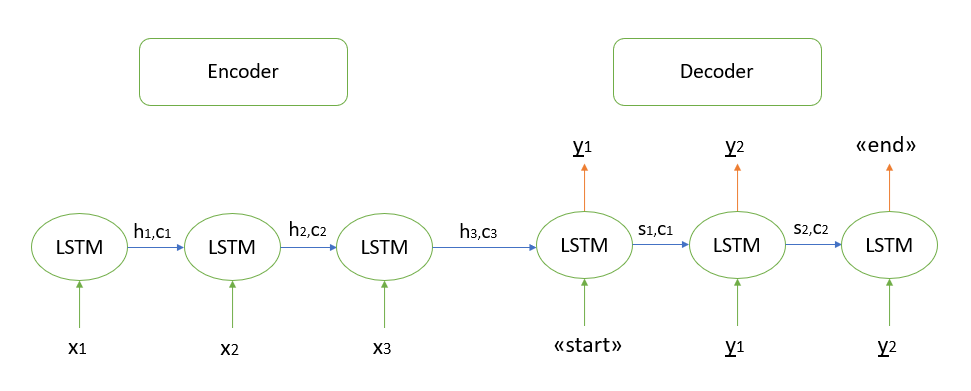
- Nous encodons toute la séquence d'entrée et initialisons le décodeur avec les états internes du codeur
- Passez le jeton "start" comme entrée au décodeur
- Nous démarrons le décodeur avec les états internes de l'encodeur pour un pas de temps, en conséquence nous obtenons la probabilité du mot suivant (mot avec la probabilité maximale)
- Passez le mot sélectionné comme entrée au décodeur au prochain pas de temps et mettez à jour les états internes
- Répétez les étapes 3 et 4 jusqu'à ce que nous générions le jeton «fin»
Plus de détails sur l'architecture "encodeur-décodeur" peuvent être trouvés ici .
Implémentation de la synthèse abstractive
Pour construire un modèle abstractif plus complexe d'extraction de résumé, les textes d'actualité complets et leurs titres sont nécessaires. Le titre de l'actualité servira de résumé, puisque le modèle «ne se souvient pas bien» de longues séquences de texte.
Lors du nettoyage des données, nous utilisons la traduction en minuscules et supprimons les caractères non russes. La lemmatisation des mots, la suppression des prépositions, des particules et d'autres parties non informatives du discours auront un impact négatif sur la sortie finale du modèle, car la relation entre les mots d'une phrase sera perdue.
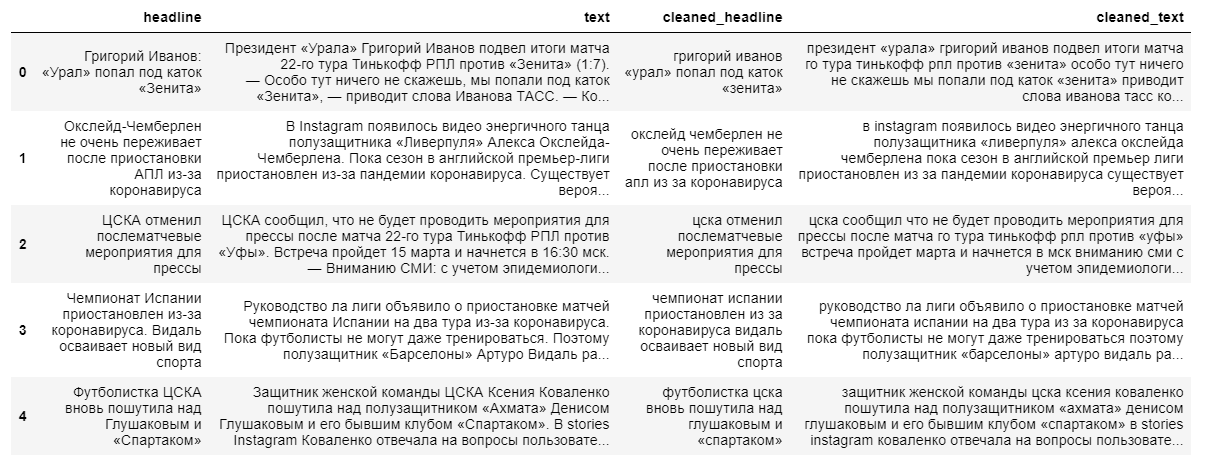
Ensuite, nous divisons les textes et leurs titres en échantillons d'apprentissage et testons dans un rapport de 9 à 1, après quoi nous les transformons en vecteurs (au hasard).
A l'étape suivante, nous créons le modèle lui-même, qui va lire les vecteurs de mots qui lui sont transmis et effectuer leur traitement à l'aide de 3 couches récurrentes du codeur LSTM et 1 couche du décodeur.
Après avoir initialisé le modèle, nous l'entraînons à l'aide d'une fonction de perte d'entropie croisée qui montre l'écart entre le titre cible réel et celui prédit par notre modèle.

Enfin, nous sortons le résultat du modèle pour l'ensemble d'apprentissage. Comme vous pouvez le voir dans les exemples, les textes sources et les résumés contiennent des inexactitudes dues à la suppression de mots rares avant la construction du modèle (nous les rejetons afin de «simplifier l'apprentissage»).

La sortie du modèle à ce stade laisse beaucoup à désirer. Le modèle «se souvient avec succès» de certains noms de clubs et de noms de joueurs de football, mais n'a pratiquement pas saisi le contexte lui-même.
Malgré l'approche plus moderne pour reprendre l'extraction, cet algorithme est toujours très inférieur aux modèles d'extraction créés précédemment. Néanmoins, afin d'améliorer la qualité du modèle, vous pouvez entraîner le modèle sur un ensemble de données plus grand, mais, à mon avis, pour obtenir une très bonne sortie de modèle, il est nécessaire de changer ou, éventuellement, de changer complètement l'architecture même des réseaux de neurones utilisés.
Alors, quelle approche est la meilleure?
Pour résumer cet article, je vais énumérer les principaux avantages et inconvénients des approches examinées pour l'extraction d'un résumé:
1. Approche extractive:
Avantages:
- L'essence de l'algorithme est intuitive
- Facilité relative de mise en œuvre
Désavantages:
- La qualité du contenu peut dans de nombreux cas être pire que le contenu manuscrit humain
2. Approche abstraite:
avantages:
- Un algorithme bien implémenté est capable de produire un résultat qui se rapproche le plus de l'écriture manuelle de CV
Désavantages:
- Difficultés à percevoir les principales idées théoriques de l'algorithme
- Coûts de main-d'œuvre importants dans la mise en œuvre de l'algorithme
Il n'y a pas de réponse définitive à la question de savoir quelle approche formera le mieux le CV final. Tout dépend de la tâche et des objectifs spécifiques de l'utilisateur. Par exemple, un algorithme d'extraction est probablement mieux adapté pour générer le contenu de documents de plusieurs pages, où l'extraction de phrases pertinentes peut effectivement transmettre correctement l'idée d'un texte volumineux.
À mon avis, l'avenir appartient aux algorithmes abstractifs. Malgré le fait qu'ils sont actuellement peu développés et à un certain niveau de qualité de sortie, ils ne peuvent être utilisés que pour générer de petits résumés (1-2 phrases), il vaut la peine de s'attendre à une percée des méthodes de réseau neuronal. À l'avenir, ils sont capables de former du contenu pour absolument n'importe quelle taille de texte et, surtout, le contenu lui-même sera aussi proche que possible de la rédaction manuelle d'un CV par un expert dans un domaine particulier.
Veklenko Vlad, analyste des systèmes,
Consortium du Codex