Allons dans l'ordre. Et immédiatement un petit avertissement: l'article a été écrit sur la base de mon discours à Ya Subbotnik Pro pour les développeurs front-end. Si vous êtes impliqué dans le backend, vous ne découvrirez peut-être rien de nouveau pour vous-même. Ici, je vais essayer de résumer mon expérience du frontend dans une grande entreprise, expliquer pourquoi et comment nous utilisons Node.js.
Définissons ce que nous considérerons comme une interface dans cet article. Laissons de côté les disputes sur les tâches et concentrons-nous sur l'essence.
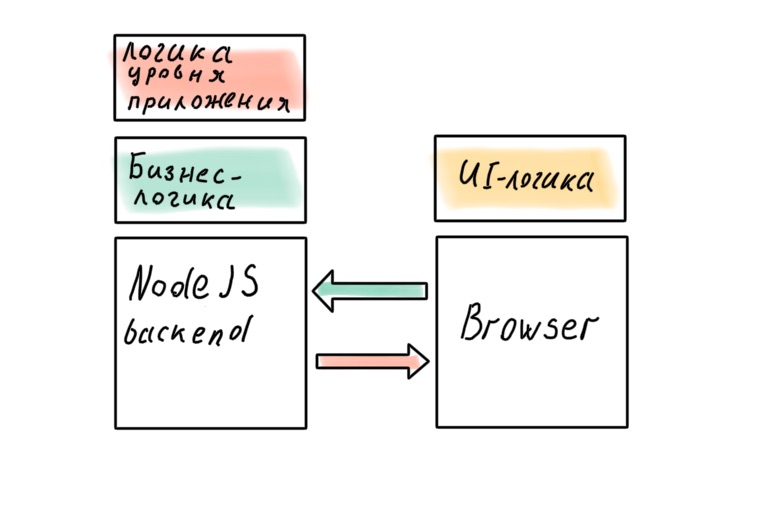
Frontend est la partie de l'application responsable de l'affichage. Cela peut être différent: navigateur, ordinateur de bureau, mobile. Mais il y a toujours une caractéristique importante - le frontend a besoin de données. Sans un backend qui fournit ces données, c'est inutile. Voici une frontière assez claire. Le backend sait comment accéder aux bases de données, appliquer des règles métier aux données reçues et donner le résultat au frontend, qui recevra les données, les modélisera et donnera de la beauté à l'utilisateur.
Nous pouvons dire que conceptuellement, le backend est nécessaire au frontend pour recevoir et enregistrer des données. Exemple: un site moderne typique avec une architecture client-serveur. Le client dans le navigateur (pour l'appeler mince, la langue ne tournera plus) frappe sur le serveur sur lequel le backend est en cours d'exécution. Et bien sûr, il y a des exceptions partout. Il existe des applications de navigateur complexes qui n'ont pas besoin d'un serveur (nous ne considérerons pas ce cas), et il est nécessaire d'exécuter une interface sur le serveur - ce que l'on appelle le serveur de rendu côté serveur ou SSR. Commençons par cela, car c'est le cas le plus simple et le plus compréhensible.
SSR
Le monde idéal pour le backend ressemble à ceci: les requêtes HTTP avec des données arrivent à l'entrée de l'application, et à la sortie, nous avons une réponse avec de nouvelles données dans un format pratique. Par exemple JSON. Les API HTTP sont faciles à tester et à comprendre comment se développer. Cependant, la vie fait des ajustements: parfois, l'API seule ne suffit pas.
Le serveur doit répondre avec du HTML prêt à l'emploi pour le transmettre au robot d'exploration du moteur de recherche, afficher un aperçu avec des balises méta pour l'insertion dans le réseau social ou, plus important encore, accélérer la réponse sur les appareils faibles. Tout comme dans les temps anciens lorsque nous développions le Web 2.0 en PHP.
Tout est familier et décrit depuis longtemps, mais le client a changé - les moteurs de modèles impératifs côté client y sont venus. Dans le Web moderne, JSX domine la balle, dont les avantages et les inconvénients peuvent être discutés pendant longtemps, mais une chose ne peut être niée - dans le rendu serveur, vous ne pouvez pas vous passer du code JavaScript.
Il s'avère que lorsque vous devez implémenter SSR par développement back-end:
- Les domaines de responsabilité sont mixtes. Les programmeurs backend commencent à être en charge du rendu.
- Les langues sont mixtes. Les programmeurs backend se lancent avec JavaScript.
La solution consiste à séparer le SSR du backend. Dans le cas le plus simple, nous prenons un runtime JavaScript, y mettons une solution auto-écrite ou un framework (Next, Nuxt, etc.) qui fonctionne avec le moteur de template JavaScript dont nous avons besoin, et y passons le trafic. Un modèle familier dans le monde moderne.
Nous avons donc déjà un peu autorisé les développeurs frontaux sur le serveur. Passons à une question plus importante.
Réception de données
Une solution populaire consiste à créer des API génériques. Ce rôle est le plus souvent assumé par API Gateway, qui est capable d'interroger une variété de microservices. Cependant, des problèmes se posent ici aussi.
Premièrement, le problème des équipes et des domaines de responsabilité. Une grande application moderne est développée par de nombreuses équipes. Chaque équipe est focalisée sur son domaine métier, possède son propre microservice (voire plusieurs) sur le backend et ses propres affichages sur le client. Nous n'entrerons pas dans le problème du micro-front et de la modularité, il s'agit d'un sujet complexe à part. Supposons que les vues client soient complètement séparées et soient des mini-SPA (Single Page Application) dans un seul grand site.
Chaque équipe a des développeurs front-end et back-end. Chacun travaille sur sa propre application. API Gateway peut être une pierre d'achoppement. Qui en est responsable? Qui ajoutera de nouveaux points de terminaison? Une super équipe API dédiée qui sera toujours occupée à résoudre les problèmes de tous les autres participants au projet? Quel sera le coût d'une erreur? La chute de cette passerelle mettra tout le système en panne.
Deuxièmement, le problème des données redondantes / insuffisantes. Jetons un coup d'œil à ce qui se passe lorsque deux interfaces différentes utilisent la même API générique.

Ces deux interfaces sont très différentes. Ils ont besoin de différents ensembles de données, ils ont des cycles de publication différents. La variabilité des versions du frontend mobile est maximale, nous sommes donc obligés de concevoir des API avec une compatibilité ascendante maximale. La variabilité du client web est faible, en fait nous n'avons besoin de supporter qu'une seule version précédente pour réduire le nombre de bogues au moment de la publication. Mais même si l'API «générique» ne sert que les clients web, nous sommes toujours confrontés au problème des données redondantes ou insuffisantes.
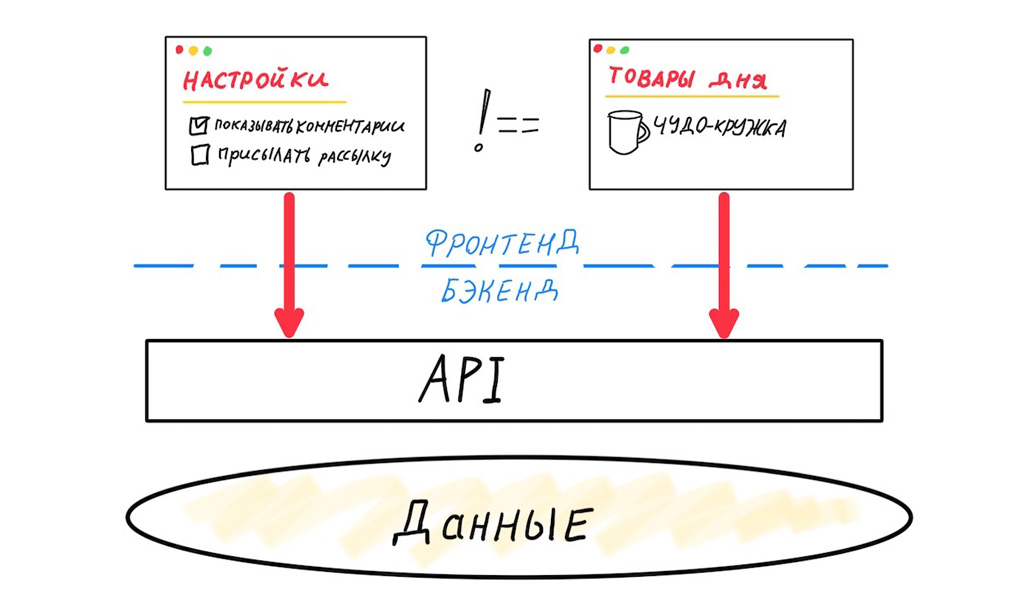
Chaque mappage nécessite un ensemble distinct de données, qu'il est souhaitable de retirer avec une requête optimale.
Dans ce cas, une API universelle ne fonctionnera pas pour nous, nous devrons séparer les interfaces. Cela signifie que vous avez besoin de votre propre passerelle API pour chaquel'extrémité avant. Le mot «chacun» désigne ici une cartographie unique qui opère sur son propre jeu de données.

On peut confier la création d'une telle API à un développeur backend qui devra travailler avec le frontend et mettre en œuvre ses souhaits, ou, ce qui est beaucoup plus intéressant et à bien des égards plus efficace, confier la mise en œuvre de l'API à l'équipe frontend. Cela supprimera le mal de tête dû à l'implémentation SSR: vous n'avez plus besoin d'installer une couche qui frappe sur l'API, tout sera intégré dans une seule application serveur. De plus, en contrôlant le SSR, nous pouvons mettre toutes les données primaires nécessaires sur la page au moment du rendu, sans faire de requêtes supplémentaires au serveur.
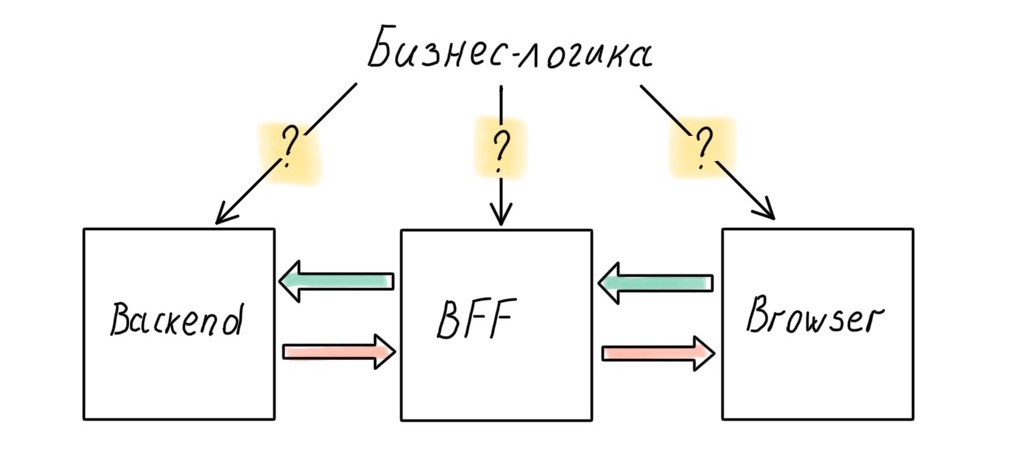
Cette architecture est appelée Backend For Frontend ou BFF. L'idée est simple: une nouvelle application apparaît sur le serveur qui écoute les demandes des clients, interroge les backends et renvoie la réponse optimale. Et bien sûr, cette application est contrôlée par le développeur front-end.

Plus d'un serveur dans le backend? Pas de problème!

Peu importe ce que le développement backend de protocole de communication préfère, nous pouvons utiliser n'importe quel moyen pratique pour communiquer avec le client Web. REST, RPC, GraphQL - nous choisissons nous-mêmes.
Mais GraphQL lui-même n'est-il pas la solution au problème de l'obtention de données en une seule requête? Peut-être n'avez-vous pas besoin de clôturer des services intermédiaires?
Malheureusement, travailler efficacement avec GraphQL est impossible sans une coopération étroite avec les développeurs backend qui se chargent du développement de requêtes de base de données efficaces. En choisissant une telle solution, nous perdrons à nouveau le contrôle des données et reviendrons là où nous avons commencé.

C'est possible, bien sûr, mais pas intéressant (pour un frontend)
Eh bien, implémentons BFF. Bien sûr, dans Node.js. Pourquoi? Nous avons besoin d'un langage unique sur le client et le serveur pour réutiliser l'expérience des développeurs frontaux et JavaScript pour travailler avec des modèles. Qu'en est-il des autres environnements d'exécution?

GraalVM et d'autres solutions exotiques ont des performances inférieures au V8 et sont trop spécifiques. Deno est encore une expérience et n'est pas utilisé en production.
Et un instant. Node.js est une solution étonnamment bonne pour implémenter API Gateway. L'architecture Node permet un interpréteur JavaScript monothread combiné à libuv, une bibliothèque d'E / S asynchrone qui à son tour utilise un pool de threads.
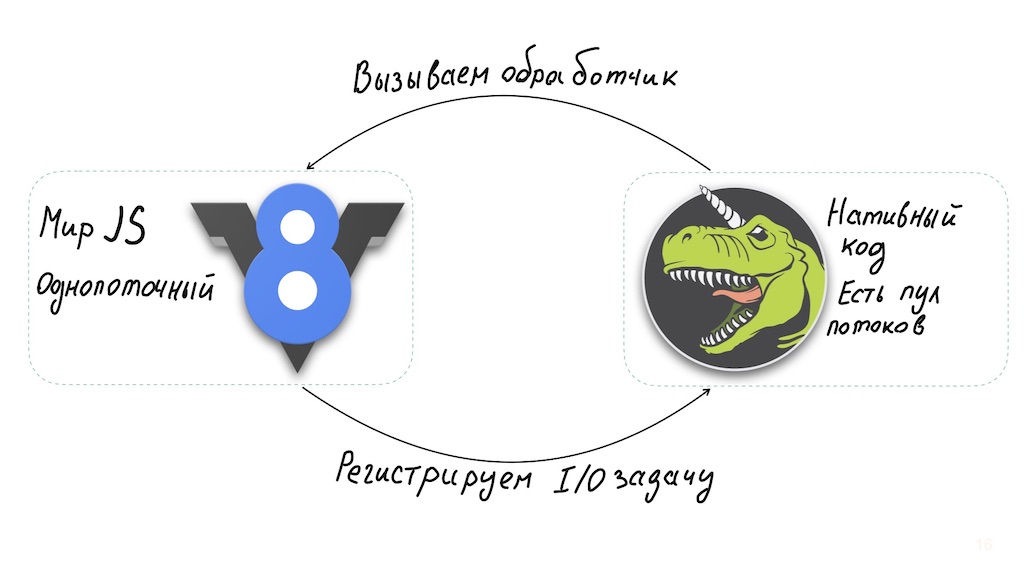
De longs calculs du côté JavaScript ont affecté les performances du système. Vous pouvez contourner ce problème: exécutez-les dans des nœuds de calcul séparés ou amenez-les au niveau des modules binaires natifs.
Mais dans le cas de base, Node.js n'est pas adapté aux opérations gourmandes en ressources processeur, et en même temps, il fonctionne très bien avec les E / S asynchrones, offrant des performances élevées. Autrement dit, nous obtenons un système qui peut toujours répondre rapidement à l'utilisateur, quel que soitsur l'occupation du backend. Vous pouvez gérer cette situation en notifiant instantanément à l'utilisateur d'attendre la fin de l'opération.
Où stocker la logique métier
Notre système comprend maintenant trois grandes parties: le backend, le frontend et BFF entre les deux. Une question raisonnable (pour un architecte) se pose: où garder la logique métier?

Bien sûr, un architecte ne veut pas étaler les règles métier à toutes les couches du système; il doit y avoir une source de vérité. Et cette source est le backend. Où stocker les politiques de haut niveau, sinon dans la partie du système la plus proche des données?

Mais en réalité, cela ne fonctionne pas toujours. Par exemple, un problème commercial survient qui peut être mis en œuvre efficacement et rapidement au niveau BFF. Une conception parfaite du système est excellente, mais le temps c'est de l'argent. Parfois, vous devez sacrifier la propreté de l'architecture et les couches commencent à fuir.
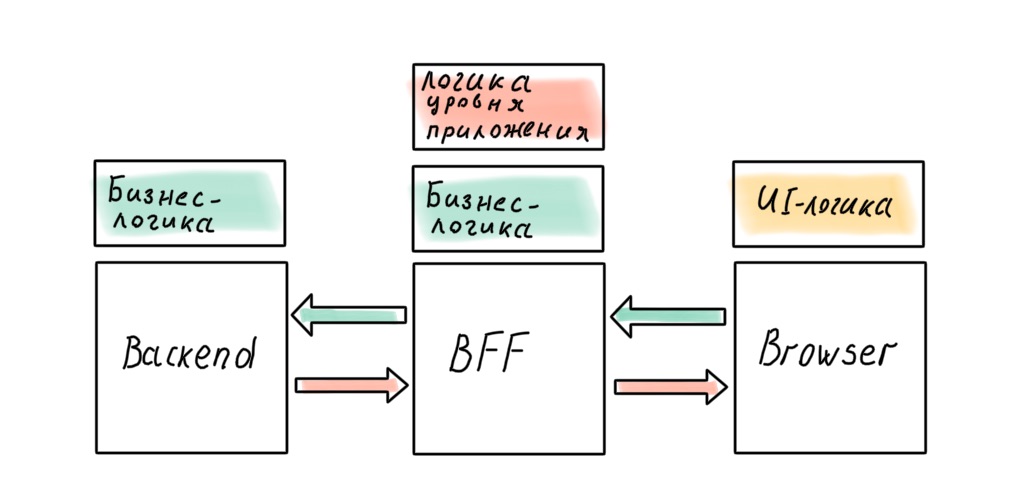
Pouvons-nous obtenir l'architecture parfaite en abandonnant le BFF au profit d'un backend Node.js "complet"? Il semble que dans ce cas, il n'y aura pas de fuite.
N'est pas un fait. Il y aura des règles métier dont le transfert vers le serveur affectera la réactivité de l'interface. Vous pouvez résister jusqu'à la fin, mais vous ne pourrez probablement pas l'éviter complètement. La logique au niveau de l'application pénétrera également le client: dans le SPA moderne, elle est étalée entre le client et le serveur, même dans le cas où il y a un BFF.

Peu importe nos efforts, la logique métier infiltrera la passerelle API sur Node.js. Fixons cette conclusion et passons à la mise en œuvre la plus délicieuse!
Grosse boule de boue
La solution la plus populaire pour les applications Node.js ces dernières années est Express. Prouvé, mais de niveau trop bas et n'offre pas de bonnes approches architecturales. Le modèle principal est le middleware. Une application typique dans l'Express comme un gros morceau de boue (ce n'est pas insultant, et anti - modèle ).
const express = require('express');
const app = express();
const {createReadStream} = require('fs');
const path = require('path');
const Joi = require('joi');
app.use(express.json());
const schema = {id: Joi.number().required() };
app.get('/example/:id', (req, res) => {
const result = Joi.validate(req.params, schema);
if (result.error) {
res.status(400).send(result.error.toString()).end();
return;
}
const stream = createReadStream( path.join('..', path.sep, `example${req.params.id}.js`));
stream
.on('open', () => {stream.pipe(res)})
.on('error', (error) => {res.end(error.toString())})
});Toutes les couches sont mélangées, dans un fichier il y a un contrôleur, où tout est là: logique d'infrastructure, validation, logique métier. C'est pénible de travailler avec ça, vous ne voulez pas maintenir un tel code. Pouvons-nous écrire du code au niveau de l'entreprise dans Node.js?

Cela nécessite une base de code facile à maintenir et à développer. En d'autres termes, vous avez besoin d'une architecture.
Architecture d'application Node.js (enfin)
"Le but de l'architecture logicielle est de réduire l'effort humain impliqué dans la construction et la maintenance d'un système."
Robert "Oncle Bob" Martin
L'architecture se compose de deux choses importantes: les couches et les connexions entre elles. Nous devons diviser notre application en couches, éviter les fuites de l'une à l'autre, organiser correctement la hiérarchie des couches et les connexions entre elles.
Couches
Comment diviser mon application en couches? Il existe une approche classique à trois niveaux: données, logique, présentation.
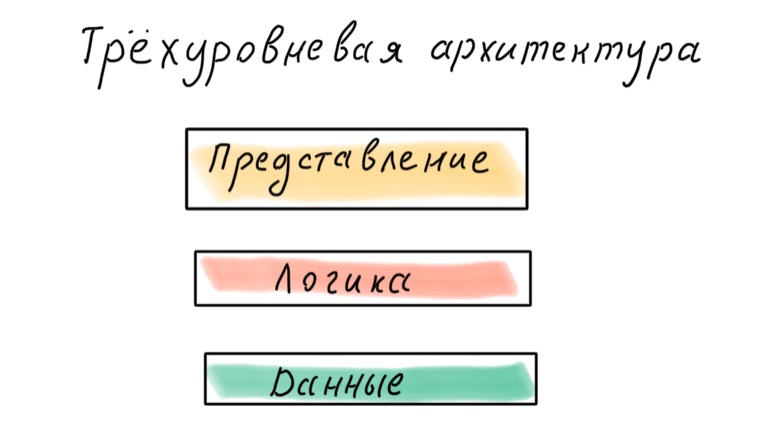
Cette approche est désormais considérée comme obsolète. Le problème est que les données sont la base, ce qui signifie que l'application est conçue en fonction de la façon dont les données sont présentées dans la base de données et non des processus métier auxquels elles participent.
Une approche plus moderne suppose que l'application dispose d'une couche de domaine dédiée qui fonctionne avec la logique métier et est une représentation de processus métier réels dans le code. Cependant, si nous nous tournons vers le travail classique d'Eric Evans Domain-Driven Design , nous y trouvons le schéma de couche application suivant:

Quel est le problème ici? Il semblerait que la base d'une application conçue par DDD devrait être un domaine - des politiques de haut niveau, la logique la plus importante et la plus précieuse. Mais sous cette couche se trouve toute l'infrastructure: couche d'accès aux données (DAL), journalisation, surveillance, etc. C'est-à-dire des politiques d'un niveau beaucoup plus bas et de moindre importance.
L'infrastructure est au centre de l'application, et un remplacement banal de l'enregistreur peut conduire à un bouleversement de toute logique métier.
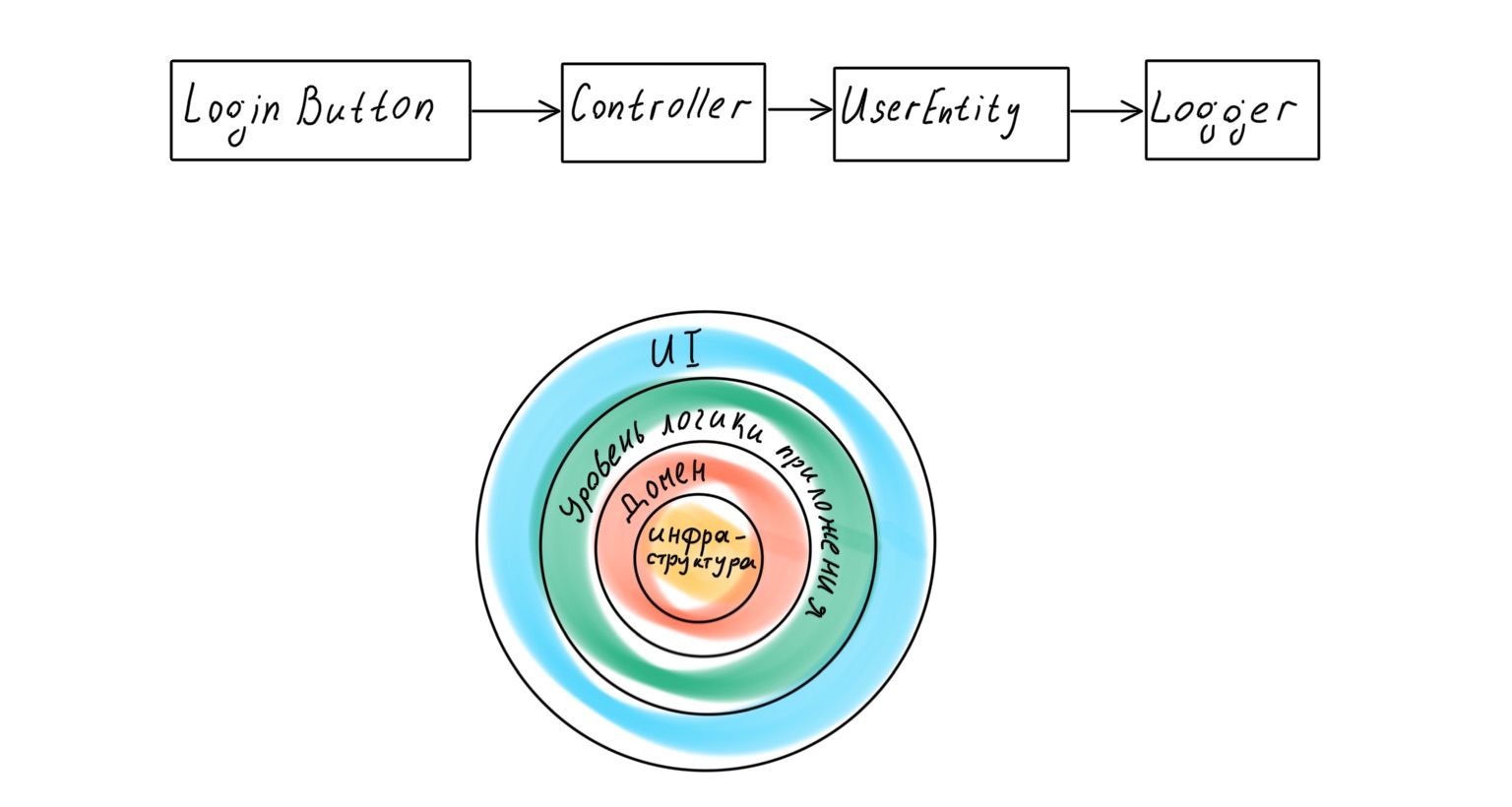
Si nous nous tournons à nouveau vers Robert Martin, nous constatons que dans le livre Clean Architecture, il postule une hiérarchie de couches différente dans l'application, avec le domaine au centre.
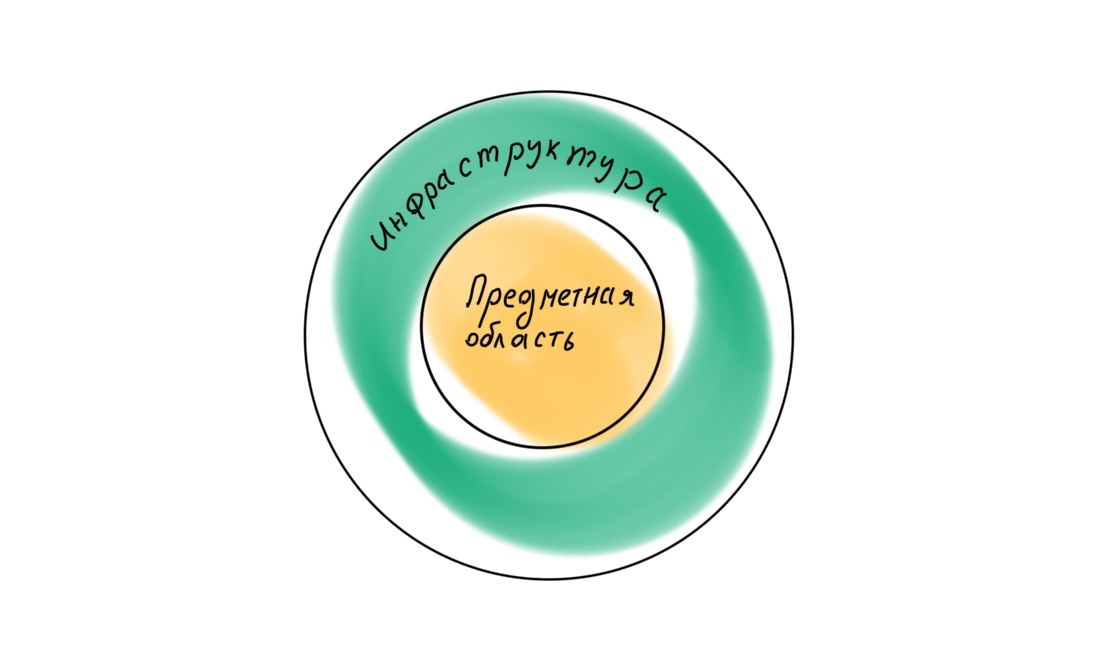
En conséquence, les quatre couches doivent être disposées différemment:
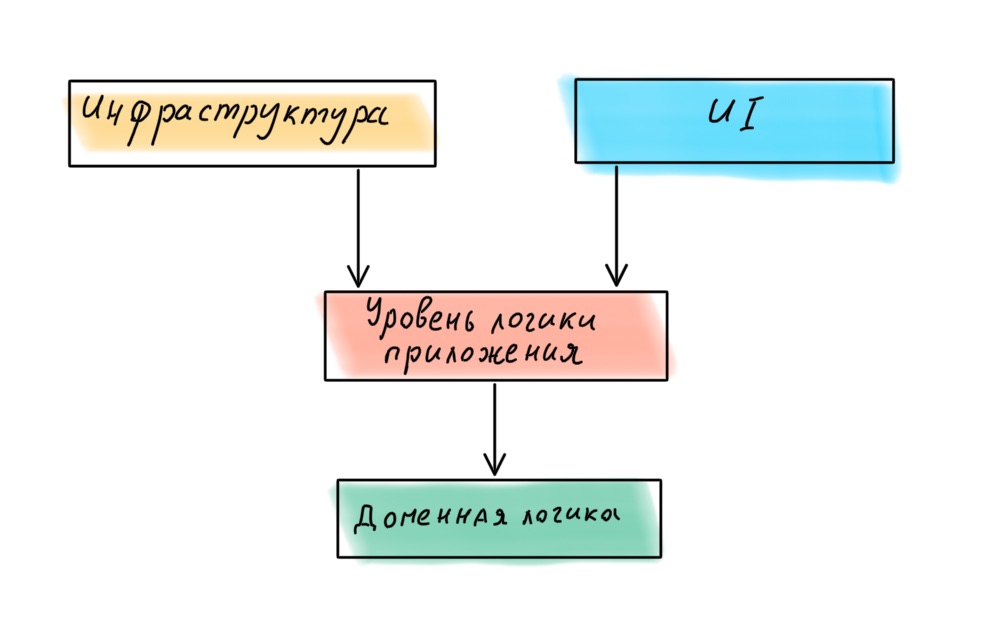
Nous avons sélectionné les couches et défini leur hiérarchie. Passons maintenant aux connexions.
Connexions
Revenons à l'exemple avec l'appel de logique utilisateur. Comment se débarrasser de la dépendance directe à l'infrastructure pour assurer la bonne hiérarchie des couches? Il existe un moyen simple et bien connu d'inverser les dépendances - les interfaces.

Désormais, la UserEntity de haut niveau ne dépend pas du Logger de bas niveau. Au contraire, il dicte le contrat qui doit être mis en œuvre pour inclure le Logger dans le système. Le remplacement de l'enregistreur dans ce cas revient à connecter une nouvelle implémentation qui respecte le même contrat. Une question importante est de savoir comment le connecter?
import {Logger} from ‘../core/logger’;
class UserEntity {
private _logger: Logger;
constructor() {
this._logger = new Logger();
}
...
}
...
const UserEntity = new UserEntity();Les couches sont liées de manière rigide. Il existe un lien avec la structure et l'implémentation du fichier. Nous avons besoin de l'inversion de dépendance, ce que nous ferons en utilisant l'injection de dépendance.
export class UserEntity {
constructor(private _logger: ILogger) { }
...
}
...
const logger = new Logger();
const UserEntity = new UserEntity(logger);Désormais, UserEntity "domaine" ne sait plus rien de l'implémentation de l'enregistreur. Il fournit un contrat et s'attend à ce que la mise en œuvre soit conforme à ce contrat.
Bien entendu, générer manuellement des instances d'entités d'infrastructure n'est pas la chose la plus agréable. Nous avons besoin d'un fichier racine dans lequel nous allons tout préparer, nous devrons en quelque sorte faire glisser l'instance créée de l'enregistreur à travers toute l'application (il est avantageux d'en avoir un, pas d'en créer beaucoup). Fatigant. Et c'est là que les conteneurs IoC entrent en jeu et peuvent reprendre ce travail de bollerplate.
À quoi pourrait ressembler l'utilisation d'un conteneur? Par exemple, comme ceci:
export class UserEntity {
constructor(@Inject(LOGGER) private readonly _logger: ILogger){ }
}Que se passe t-il ici? Nous avons utilisé la magie des décorateurs et avons écrit l'instruction: «Lors de la création d'une instance de UserEntity, injectez dans son champ privé _logger une instance de l'entité qui se trouve dans le conteneur IoC sous le jeton LOGGER. On s'attend à ce qu'il soit conforme à l'interface ILogger. " Et puis le conteneur IoC fera tout par lui-même.
Nous avons sélectionné les couches, décidé comment nous les détacherons. Il est temps de choisir un cadre.
Cadres et architecture
La question est simple: en quittant Express pour un framework moderne, obtiendrons-nous une bonne architecture? Jetons un coup d'œil à Nest:
- écrit en TypeScript,
- construit sur Express / Fastify, il existe une compatibilité au niveau du middleware,
- déclare la modularité de la logique,
- fournit un conteneur IoC.
Il semble y avoir tout ce dont nous avons besoin ici! Ils ont également laissé le concept d'application comme une chaîne middleware. Mais qu'en est-il de la bonne architecture?
Injection de dépendances dans Nest
Essayons de suivre les instructions . Étant donné que dans Nest, le terme Entity est généralement appliqué à ORM, renommez UserEntity en UserService. Le logger est fourni par le framework, nous allons donc injecter le résumé FooService à la place.
import {FooService} from ‘../services/foo.service’;
@Injectable()
export class UserService {
constructor(
private readonly _fooService: FooService
){ }
}Et ... il semble que nous ayons pris du recul! Il y a injection, mais il n'y a pas d'inversion, la dépendance
vise l'implémentation, pas l'abstraction.
Essayons de le réparer. Option numéro un:
@Injectable()
export class UserService {
constructor(
private _fooService: AbstractFooService
){ } }Nous décrivons et exportons ce service abstrait quelque part à proximité:
export {AbstractFooService};FooService utilise maintenant AbstractFooService. En tant que tel, nous l'enregistrons manuellement dans l'IoC.
{ provide: AbstractFooService, useClass: FooService }Deuxième option. Essayons l'approche décrite précédemment avec les interfaces. Comme il n'y a pas d'interfaces en JavaScript, il ne sera plus possible d'extraire l'entité requise d'IoC au moment de l'exécution à l'aide de la réflexion. Nous devons déclarer explicitement ce dont nous avons besoin. Nous utiliserons le décorateur @ Inject pour cela.
@Injectable()
export class UserService {
constructor(
@Inject(FOO_SERVICE) private readonly _fooService: IFooService
){ } }Et inscrivez-vous par jeton:
{ provide: FOO_SERVICE, useClass: FooService }Nous avons gagné le cadre! Mais à quel prix? Nous avons éteint pas mal de sucre. Ceci est suspect et suggère que vous ne devriez pas regrouper l'ensemble de l'application dans un cadre. Si je ne vous ai pas encore convaincu, il y a d'autres problèmes.
Des exceptions
Nest est flashé avec des exceptions. De plus, il suggère d'utiliser le lancement d'exceptions pour décrire la logique du comportement de l'application.
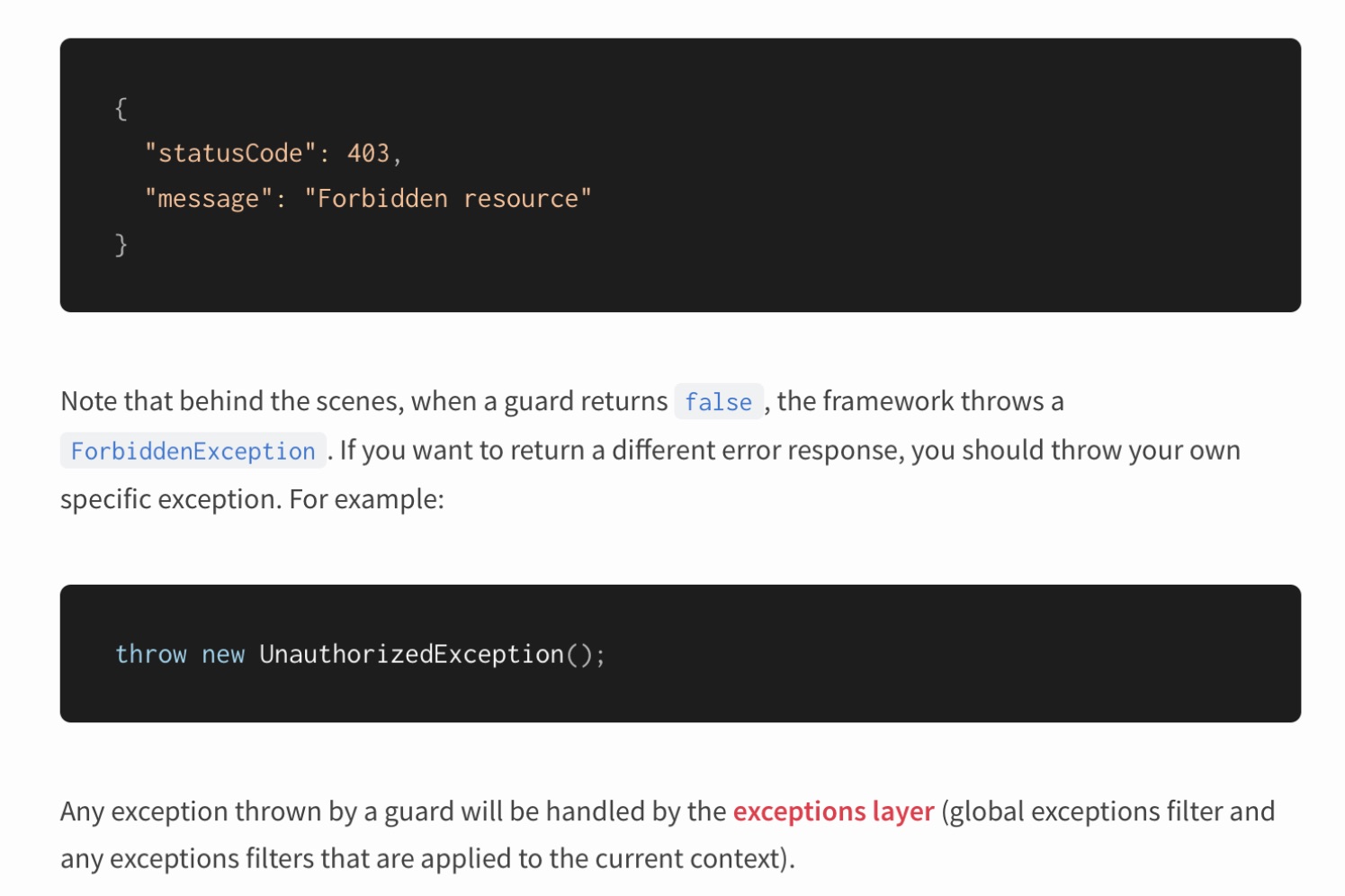
Est-ce que tout va bien ici en termes d'architecture? Tournons-nous à nouveau vers les luminaires:
"Si l'erreur est le comportement attendu, vous ne devriez pas utiliser d'exceptions."Les exceptions suggèrent une situation exceptionnelle. Lors de l'écriture de la logique métier, nous devons éviter de lancer des exceptions. Ne serait-ce que pour la raison que ni JavaScript ni TypeScript ne garantissent que l'exception sera gérée. De plus, cela obscurcit le flux d'exécution, nous commençons à programmer dans le style GOTO, ce qui signifie qu'en examinant le comportement du code, le lecteur devra sauter à travers tout le programme.
Martin Fowler

Il existe une règle empirique simple pour vous aider à comprendre si l'utilisation d'exceptions est légale:
"Le code fonctionnera-t-il si je supprime tous les gestionnaires d'exceptions?" Si la réponse est non, des exceptions sont peut-être utilisées dans des circonstances non exceptionnelles. "Est-il possible d'éviter cela dans la logique métier? Oui! Il est nécessaire de minimiser le déclenchement d'exceptions, et pour renvoyer commodément le résultat d'opérations complexes, utilisez la monade Either , qui fournit un conteneur en état de succès ou d'erreur (un concept très proche de Promise).
Le programmeur pragmatique
const successResult = Result.ok(false);
const failResult = Result.fail(new ConnectionError())Malheureusement, dans les entités fournies par Nest, nous ne pouvons souvent pas agir autrement - nous devons lever des exceptions. C'est ainsi que fonctionne le framework, et c'est une fonctionnalité très désagréable. Et encore une fois la question se pose: peut-être ne devriez-vous pas flasher l'application avec un framework? Peut-être sera-t-il possible de séparer le cadre et la logique métier en différentes couches architecturales?
Allons vérifier.
Nest entités et couches architecturales
La dure vérité de la vie: tout ce que nous écrivons avec Nest peut être empilé en une seule couche. Il s'agit de la couche d'application.
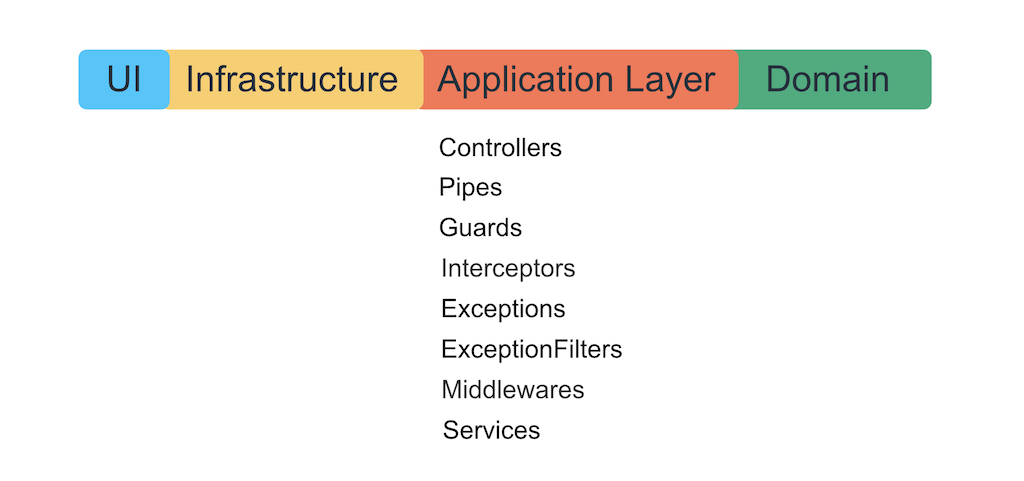
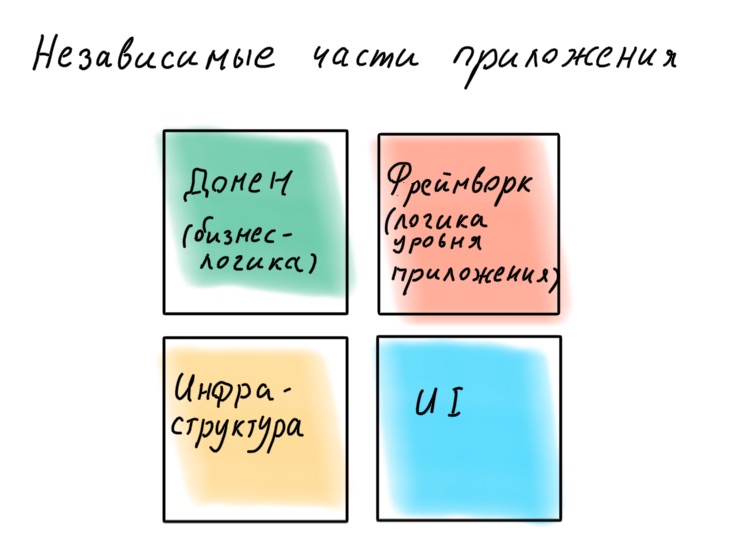
Nous ne voulons pas laisser le framework aller plus loin dans la logique métier, afin qu'il ne s'y développe pas avec ses exceptions, décorateurs et conteneur IoC. Les auteurs du framework vous expliqueront à quel point il est bon d'écrire une logique métier en utilisant son sucre, mais leur tâche est de vous lier à eux-mêmes pour toujours. N'oubliez pas qu'un framework n'est qu'un moyen d'organiser de manière pratique la logique au niveau de l'application, d'y connecter l'infrastructure et l'interface utilisateur.

"Un cadre est un détail."
Robert «Oncle Bob» Martin
Il est préférable de concevoir une application en tant que constructeur, dans lequel il est facile de remplacer des composants. Un exemple d'une telle implémentation est l'architecture hexagonale (architecture de port et d'adaptateur ). L'idée est intéressante: le noyau de domaine avec toute la logique métier fournit des ports pour communiquer avec le monde extérieur. Tout ce qui est nécessaire est connecté en externe via des adaptateurs.
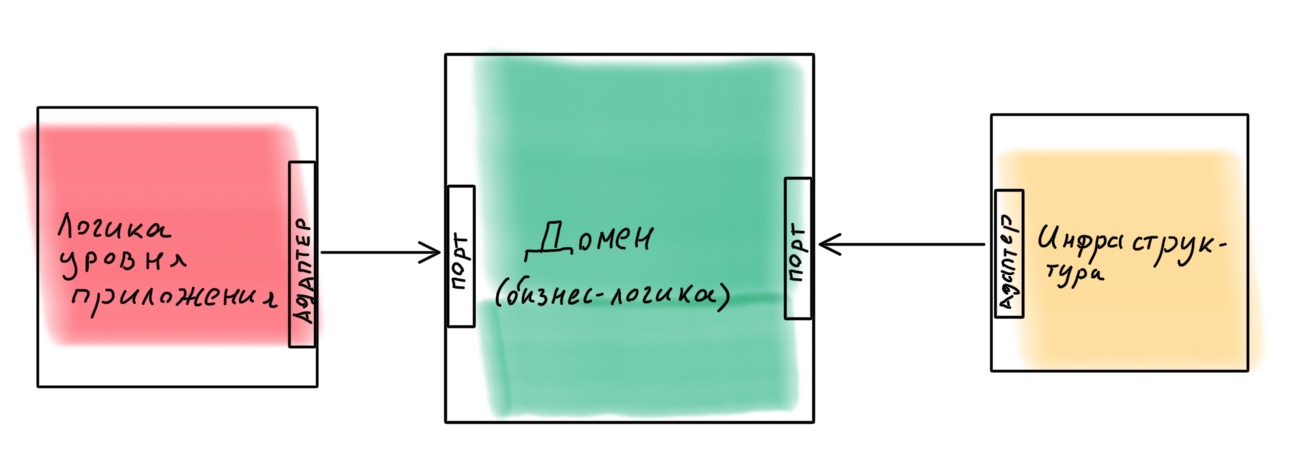
Est-il réaliste de mettre en œuvre une telle architecture dans Node.js en utilisant Nest comme cadre? Assez. J'ai fait une leçon avec un exemple, si vous êtes intéressé - vous pouvez le trouver ici .
Résumons
- Node.js est bon pour les BFF. Tu peux vivre avec elle.
- Il n’existe pas de solutions toutes faites.
- Les cadres ne sont pas importants.
- Si votre architecture devient trop complexe, si vous vous heurtez à la saisie, vous avez peut-être choisi le mauvais outil.
Je recommande ces livres:
- Robert Martin, "Architecture propre",
- Vaughn Vernon, Domain-Driven Design Distilled,
- Khalil Stemmler, khalilstemmler.com,
- Martin Fowler, martinfowler.com/architecture.