Le but de cet article est de parler de régression linéaire, c'est-à-dire de recueillir et de montrer les formulations et interprétations du problème de régression en termes d'analyse mathématique, statistique, algèbre linéaire et théorie des probabilités. Bien que les manuels définissent ce sujet de manière stricte et exhaustive, un autre article scientifique populaire ne fera pas de mal.
! Attention au trafic! L'article contient un nombre notable d'images pour les illustrations, certaines au format gif.
Contenu
- introduction
- Méthode des moindres carrés
- Régression multilinéaire
- Base arbitraire
- Remarques finales
- Publicité et conclusion
introduction
Il existe trois concepts similaires, trois sœurs: l'interpolation, l'approximation et la régression.
Ils ont un objectif commun: à partir d'une famille de fonctions, choisissez celle qui possède une certaine propriété.
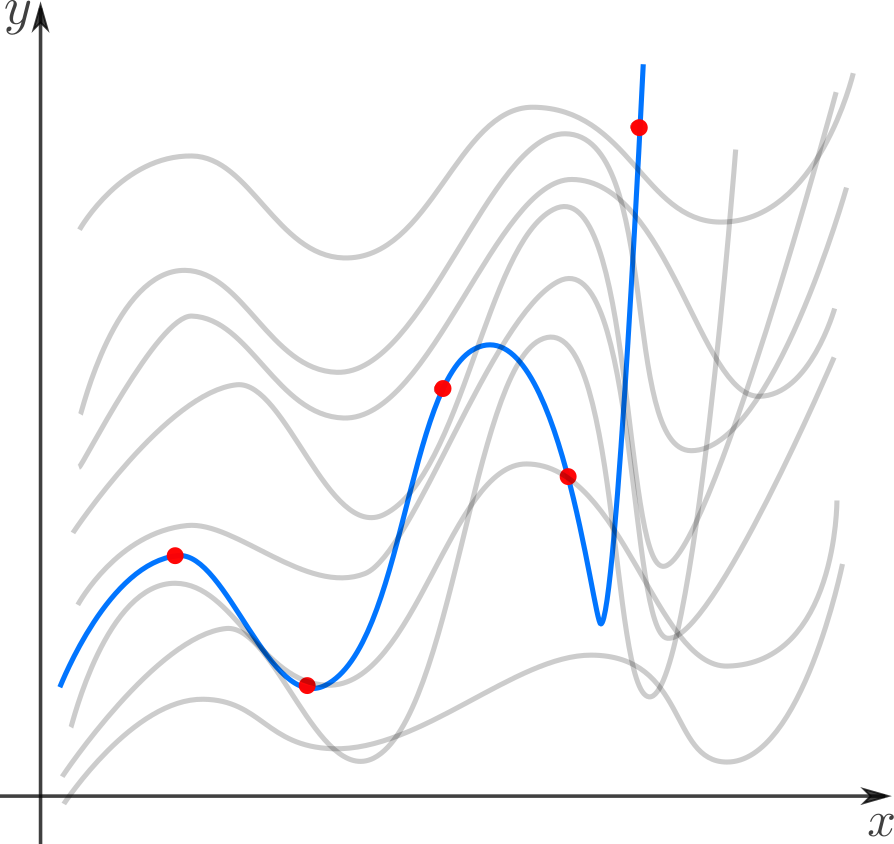
Interpolation- un moyen de sélectionner dans une famille de fonctions celle qui passe par les points donnés. La fonction est alors généralement utilisée pour calculer aux points intermédiaires. Par exemple, nous définissons manuellement la couleur sur plusieurs points et voulons que les couleurs des points restants forment des transitions douces entre les points donnés. Ou nous définissons des images clés pour l'animation et souhaitons des transitions fluides entre elles. Exemples classiques: interpolation polynomiale de Lagrange, interpolation spline, interpolation multidimensionnelle (bilinéaire, trilinéaire, plus proche voisin, etc.). Il existe également un concept lié d'extrapolation - prédire le comportement d'une fonction en dehors d'un intervalle. Par exemple, prédire le taux du dollar en fonction des fluctuations précédentes est une extrapolation.
 Approximation- une manière de choisir dans une famille de fonctions "simples" une approximation pour une fonction "complexe" sur un segment, alors que l'erreur ne doit pas dépasser une certaine limite. L'approximation est utilisée lorsque vous avez besoin d'obtenir une fonction similaire à une fonction donnée, mais plus pratique pour les calculs et les manipulations (différenciation, intégration, etc.). Lors de l'optimisation de sections critiques du code, une approximation est souvent utilisée: si la valeur d'une fonction est calculée plusieurs fois par seconde et qu'une précision absolue n'est pas nécessaire, alors un approximant plus simple avec un «coût» de calcul inférieur peut être supprimé. Les exemples classiques incluent les séries de Taylor sur un segment, l'approximation polynomiale orthogonale, l'approximation de Padé, l'approximation sinusoïdale de Bhaskar, etc.
Approximation- une manière de choisir dans une famille de fonctions "simples" une approximation pour une fonction "complexe" sur un segment, alors que l'erreur ne doit pas dépasser une certaine limite. L'approximation est utilisée lorsque vous avez besoin d'obtenir une fonction similaire à une fonction donnée, mais plus pratique pour les calculs et les manipulations (différenciation, intégration, etc.). Lors de l'optimisation de sections critiques du code, une approximation est souvent utilisée: si la valeur d'une fonction est calculée plusieurs fois par seconde et qu'une précision absolue n'est pas nécessaire, alors un approximant plus simple avec un «coût» de calcul inférieur peut être supprimé. Les exemples classiques incluent les séries de Taylor sur un segment, l'approximation polynomiale orthogonale, l'approximation de Padé, l'approximation sinusoïdale de Bhaskar, etc.
 Régression- une manière de choisir parmi une famille de fonctions celle qui minimise la fonction de perte. Ce dernier caractérise dans quelle mesure la fonction d'essai s'écarte des valeurs aux points donnés. Si des points sont obtenus dans une expérience, ils contiennent inévitablement une erreur de mesure, du bruit, il est donc plus raisonnable d'exiger que la fonction transmette la tendance générale, et ne passe pas exactement par tous les points. Dans un sens, la régression est un «ajustement interpolant»: nous voulons dessiner la courbe aussi près que possible des points et la garder aussi simple que possible pour capturer la tendance globale. La fonction de perte (dans la littérature anglaise «loss function» ou «cost function») est responsable de l'équilibre entre ces désirs contradictoires.
Régression- une manière de choisir parmi une famille de fonctions celle qui minimise la fonction de perte. Ce dernier caractérise dans quelle mesure la fonction d'essai s'écarte des valeurs aux points donnés. Si des points sont obtenus dans une expérience, ils contiennent inévitablement une erreur de mesure, du bruit, il est donc plus raisonnable d'exiger que la fonction transmette la tendance générale, et ne passe pas exactement par tous les points. Dans un sens, la régression est un «ajustement interpolant»: nous voulons dessiner la courbe aussi près que possible des points et la garder aussi simple que possible pour capturer la tendance globale. La fonction de perte (dans la littérature anglaise «loss function» ou «cost function») est responsable de l'équilibre entre ces désirs contradictoires.
Dans cet article, nous examinerons la régression linéaire. Cela signifie que la famille de fonctions dans laquelle nous choisissons est une combinaison linéaire de fonctions de base prédéterminéesf i
f = ∑ i w i f i .
La régression est avec nous depuis longtemps: la méthode a été publiée pour la première fois par Legendre en 1805, bien que Gauss y soit venu plus tôt et l'utilise avec succès pour prédire l'orbite de la "comète" (en fait une planète naine) Cérès. Il existe de nombreuses variantes et généralisations de la régression linéaire: CONTRE, Moindres carrés, Régression Ridge, Régression Lasso, ElasticNet, et bien d'autres.

Méthode des moindres carrés
Commençons par le cas bidimensionnel le plus simple. Donnons-nous des points dans l'avion{ ( x 1 , y 1 ) , ⋯ , ( x N , y N ) } et nous recherchons une telle fonction affine
f ( x ) = a + b ⋅ x ,
 afin que son graphe soit le plus proche des points. Ainsi, notre base se compose d'une fonction constante et d'un linéaire( 1 , x )...
afin que son graphe soit le plus proche des points. Ainsi, notre base se compose d'une fonction constante et d'un linéaire( 1 , x )...
Comme vous pouvez le voir sur l'illustration, la distance d'un point à une ligne droite peut être comprise de différentes manières, par exemple, géométriquement - c'est la longueur d'une perpendiculaire. Cependant, dans le cadre de notre tâche, nous avons besoin d'une distance fonctionnelle et non géométrique. Nous nous intéressons à la différence entre la valeur expérimentale et la prédiction du modèle pour chaquex i , par conséquent, vous devez mesurer le long de l'axe y...
La première chose qui me vient à l'esprit est d'essayer une expression qui dépend des valeurs absolues des différences en tant que fonction de perte| f ( x i ) - y i |... L'option la plus simple est la somme des modules d'écart∑i|f(xi)−yi|entraîne une régression de la distance la moins absolue (LAD).
Cependant, la fonction de perte la plus populaire est la somme des carrés des écarts du régressant par rapport au modèle. Dans la littérature anglaise, on l'appelle Sum of Squared Errors (SSE)
SSE(a,b)=SSres[iduals]=N∑i=1i2=N∑i=1(yi−f(xi))2=N∑i=1(yi−a−b⋅xi)2,

Ce choix est avant tout pratique: la dérivée d'une fonction quadratique est une fonction linéaire, et les équations linéaires sont facilement résolues. Cependant, j'indiquerai en outre d'autres considérations en faveur deSSE ( a , b )...

Analyse mathematique
Le moyen le plus simple de trouver argmin a , bSSE ( a , b ) - calculer des dérivées partielles par rapport à une et b, assimilez-les à zéro et résolvez le système d'équations linéaires
∂∂ un SSE(a,b)= - 2 N ∑je=1(yje-une-bXje),∂∂bSSE(une,b)=-2N∑je=1(yje-une-bXje)Xje...
0=-2N∑je=1(yje-ˆune-ˆbXje),0=-2N∑je=1(yje-ˆune-ˆbXje)Xje,
ˆune=∑jeyjeN-ˆb∑jeXjeN,ˆb=∑jeXjeyjeN-∑jeXje∑jeyjeN2∑jeX2jeN-(∑jeX2jeN)2...
Statistiques
Les formules résultantes peuvent être rédigées de manière compacte à l'aide d'estimateurs statistiques: moyenne ⟨⋅⟩, variations σ⋅ (écart-type), covariance σ(⋅,⋅) et corrélations ρ(⋅,⋅)
ˆune=⟨y⟩-ˆb⟨X⟩,ˆb=⟨Xy⟩-⟨X⟩⟨y⟩⟨X2⟩-⟨X⟩2...
ˆb=σ(X,y)σ2X,
ρ(X,y)=σ(X,y)σXσy
ˆb=ρ(X,y)σyσX...

y-⟨y⟩=ρ(X,y)σyσX(X-⟨X⟩)...
- la ligne droite passe par le centre de gravité (⟨X⟩,⟨y⟩);
- si le long de l'axe X par unité de longueur choisir σX, et le long de l'axe y - σy, alors l'angle d'inclinaison de la ligne droite sera de -45∘ avant 45∘... Cela est dû au fait que-1≤ρ(X,y)≤1...
Deuxièmement, on comprend maintenant pourquoi la méthode de régression est appelée ainsi. En unités d'écart typey s'écarte de sa moyenne de moins de X, parce que |ρ(X,y)|≤1... C'est ce qu'on appelle la régression (du latin regressus - "retour") par rapport à la moyenne. Ce phénomène a été décrit par Sir Francis Galton à la fin du 19e siècle dans son article «Regression to Mediocrity in the Inheritance of Growth». L'article montre que les traits (comme la hauteur) qui s'écartent fortement de la moyenne sont rarement hérités. Les caractéristiques de la progéniture semblent tendre vers la moyenne - la nature repose sur les enfants des génies.
En mettant au carré le coefficient de corrélation, on obtient le coefficient de déterminationR=ρ2... Le carré de cette mesure statistique montre dans quelle mesure le modèle de régression s'adapte aux données.R2égal à 1, signifie que la fonction s'adapte parfaitement à tous les points - les données sont parfaitement corrélées. On peut prouver queR2montre dans quelle mesure la variance des données est due au meilleur modèle linéaire. Pour comprendre ce que cela signifie, nous introduisons les définitions
Varréunetune=1N∑je(yje-⟨y⟩)2,Varres=1N∑je(yje-modèle(Xje))2,Varreg=1N∑je(modèle(Xje)-⟨y⟩)2...
Varres - variation des résidus, c'est-à-dire variation des écarts par rapport au modèle de régression - de yje vous devez soustraire la prédiction du modèle et trouver la variation.
Varreg - variation de régression, c'est-à-dire variation des prédictions du modèle de régression en points Xje (notez que la moyenne des prédictions du modèle correspond à ⟨y⟩).

Varréunetune=Varres+Varreg...
σ2réunetune=σ2res+σ2reg...

Nous nous efforçons de nous débarrasser de la variabilité associée au bruit et de ne laisser que la variabilité expliquée par le modèle - nous voulons séparer le blé de l'ivraie. La mesure dans laquelle le meilleur des modèles linéaires a réussi est attestée parR2égal à un moins la fraction de la variation d'erreur dans la variation totale
R2=Varréunetune-VarresVarréunetune=1-VarresVarréunetune
R2=VarregVarréunetune...
Théorie des probabilités
Plus tôt, nous sommes arrivés à la fonction de perte SSE(une,b)pour des raisons de commodité, mais il peut également être atteint en utilisant la théorie des probabilités et la méthode du maximum de vraisemblance (MMP). Permettez-moi de rappeler brièvement son essence. Supposons que nous ayonsNvariables aléatoires indépendantes à distribution identique (dans notre cas, résultats de mesure). Nous connaissons la forme de la fonction de distribution (par exemple, la distribution normale), mais nous voulons déterminer les paramètres qui y sont inclus (par exempleμ et σ). Pour ce faire, vous devez calculer la probabilité d'obtenirNpoints de données sous l'hypothèse de paramètres constants, mais inconnus. Du fait de l'indépendance des mesures, on obtient le produit des probabilités de réalisation de chaque dimension. Si nous pensons à la valeur résultante en fonction de paramètres (fonction de vraisemblance) et trouvons son maximum, nous obtenons une estimation des paramètres. Souvent, au lieu de la fonction de vraisemblance, ils utilisent son logarithme - il est plus facile de le différencier, mais le résultat est le même.
Revenons au simple problème de régression. Disons que les valeursX nous savons exactement, mais dans la mesure yil y a un bruit aléatoire (propriété exogène faible ). De plus, nous supposons que tous les écarts par rapport à la ligne droite (propriété de linéarité ) sont causés par du bruit avec une distribution constante ( distribution constante ). Puis
y=une+bX+ϵ,
ϵ∼N(0,σ2),p(ϵ)=1√2πσ2e-ϵ22σ2...

Sur la base des hypothèses ci-dessus, nous écrivons la fonction de vraisemblance
L(une,b|y)=P(y|une,b)=∏jeP(yje|une,b)=∏jep(yje-une-bX|une,b)==∏je1√2πσ2e-(yje-une-bX)22σ2=1√2πσ2e-∑je(yje-une-bX)22σ2==1√2πσ2e-SSE(une,b)2σ2
l(une,b|y)=JournalL(une,b|y)=-SSE(une,b)+const...
(ˆune,ˆb)=argmaxune,bl(une,b|y)=argminune,bSSE(une,b),
ϵ∼Laplace(0,α),pL(ϵ;μ,α)=α2e-α|ϵ-μ|
ELUNEré(une,b)=∑je|yje-une-bXje|,
L'approche que nous avons utilisée dans cette section est une approche possible. Il est possible d'obtenir le même résultat en utilisant des propriétés plus générales. En particulier, la propriété de constance de distribution peut être affaiblie en la remplaçant par les propriétés d'indépendance, de constance de variation (homoscédasticité) et d'absence de multicolinéarité. En outre, au lieu de l'estimation MMP, vous pouvez utiliser d'autres méthodes, par exemple l'estimation MMSE linéaire.
Régression multilinéaire
Jusqu'à présent, nous avons considéré le problème de régression pour une caractéristique scalaire X, mais généralement le régresseur est n-vecteur dimensionnel X... En d'autres termes, pour chaque dimension, nous enregistronsnfonctionnalités, en les combinant dans un vecteur. Dans ce cas, il est logique d'accepter le modèle avecn+1 fonctions de base indépendantes de l'argument vectoriel - n les degrés de liberté correspondent n fonctionnalités et un autre - régressant y... Le choix le plus simple est celui des fonctions de base linéaires(1,X1,⋯,Xn)... Quandn=1 nous obtenons la base déjà familière (1,X)...
Donc, nous voulons trouver un tel vecteur (ensemble de coefficients)w, quelle
n∑j=0wjX(je)j=w⊤X(je)≃yje,je=1...N...
ˆw=argminwN∑je=1(yje-w⊤X(je))2
X=(-X(1)⊤-⋯⋯⋯-X(N)⊤-)=(|||X0X1⋯Xn|||)=(1X(1)1⋯X(1)n⋯⋯⋯⋯1X(N)1⋯X(N)n)...
Xw≃y...
SSE(w)=‖y-Xw‖2,w∈Rn+1;y∈RN,
ˆw=argminwSSE(w)=argminw(y-Xw)⊤(y-Xw)==argminw(y⊤y-2w⊤X⊤y+w⊤X⊤Xw)...
∂SSE(w)∂w=-2X⊤y+2X⊤Xw,
X⊤Xˆw=X⊤y...
ˆw=(X⊤X)-1X⊤y=X+y,
X+=(X⊤X)-1X⊤
pseudo-inverse à X... Le concept de matrice pseudo-inverse a été introduit en 1903 par Fredholm et a joué un rôle important dans les travaux de Moore et Penrose.
Laisse moi te rappeler quoi tournerX⊤X et trouve X+ seulement possible si les colonnes Xsont linéairement indépendants. Cependant, si les colonnesX proche de la dépendance linéaire, calcul (X⊤X)-1devient déjà numériquement instable. Le degré de dépendance linéaire des caractéristiques dansXou, comme on dit, la multicolinéarité de la matriceX⊤X, peut être mesuré par le nombre de conditionnalité - le rapport de la valeur propre maximale au minimum. Plus il est gros, plus il est procheX⊤X calcul dégénéré et instable de la pseudo-inverse.
Algèbre linéaire
La solution au problème de la régression multilinéaire peut être atteinte tout naturellement à l'aide de l'algèbre linéaire et de la géométrie, car même le fait que la norme du vecteur d'erreur apparaisse dans la fonction de perte laisse déjà entendre que le problème a un côté géométrique. Nous avons vu qu'une tentative de trouver un modèle linéaire décrivant les points expérimentaux conduit à l'équation
Xw≃y...
(|||X0X1⋯Xn|||)w=w0X0+w1X1+⋯wnXn...
Si en plus des vecteursC(X) nous considérons tous les vecteurs perpendiculaires à eux, puis nous obtenons un sous-espace supplémentaire et nous pouvons tout vecteur de RNse décomposer en deux composants, dont chacun vit dans son propre sous-espace. Le second espace perpendiculaire peut être caractérisé comme suit (nous en aurons besoin plus tard). Laisser allerv∈RNpuis
X⊤v=(-X⊤0-⋯⋯⋯-X⊤n-)v=(X⊤0⋅v⋯X⊤n⋅v)

Où ker(X⊤)={v|X⊤v=0}... Chacun des sous-espaces peut être atteint en utilisant l'opérateur de projection correspondant, mais plus d'informations ci-dessous.

y=yproj+y⊥,yproj∈C(X),y⊥∈ker(X⊤)...

argminw||y-Xw||=argminw||y⊥+yproj-Xw||=argminw√||y⊥||2+||yproj-Xw||2,
Xˆw=yproj,

X⊤Xw=X⊤yproj=X⊤yproj+X⊤y⊥=X⊤y,
w=(X⊤X)-1X⊤y=X+y,
yproj=Xw=XX+y=ProjXy,
Clarifions la signification géométrique du coefficient de détermination.

y-ˆy⋅1=y-ˉy+ˆy-ˉy⋅1...
‖y-ˆy⋅1‖2=‖y-ˉy‖2+‖ˆy-ˉy⋅1‖2...
Varréunetune=Varres+Varreg...
R2=VarregVarréunetune,
R=cosθ...
Base arbitraire
Comme nous le savons, la régression est effectuée sur des fonctions de base Fje et son résultat est le modèle
F=∑jewjeFje,
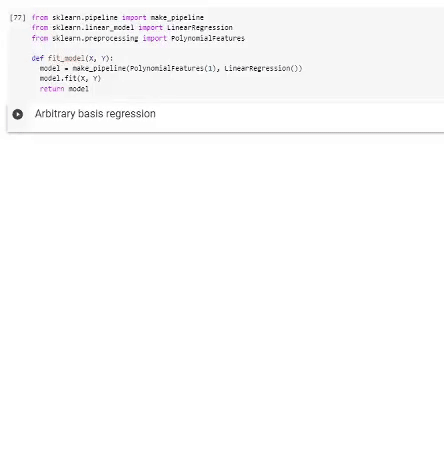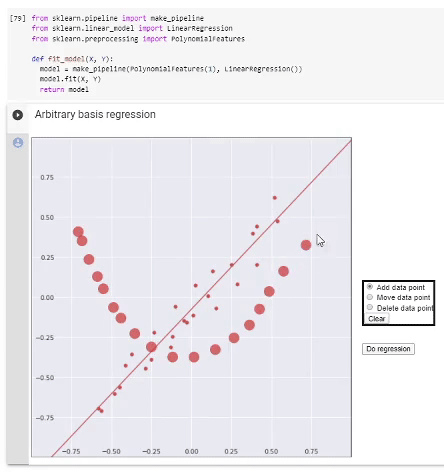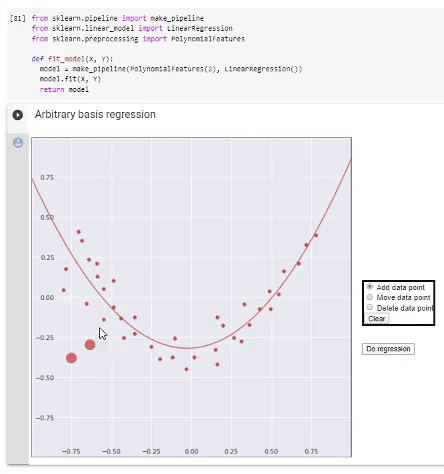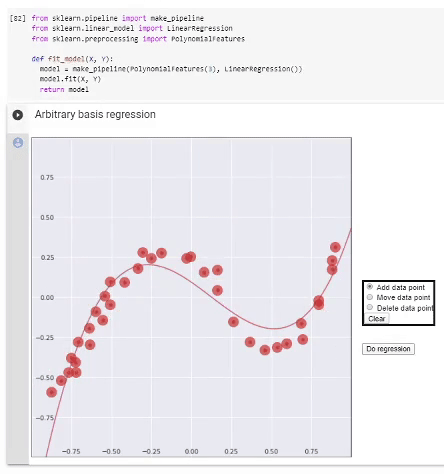
Si nous avons décidé sur la base, nous procédons comme suit. Nous formons une matrice d'informations
Φ=(-F(1)⊤-⋯⋯⋯-F(N)⊤-)=(F0(X(1))F1(X(1))⋯Fn(X(1))⋯⋯⋯⋯F0(X(N))F1(X(N))⋯Fn(X(N))),
E(w)=‖ϵ(w)‖2=‖y-Φw‖2
ˆw=argminwE(w)=(Φ⊤Φ)-1Φ⊤y=Φ+y
Remarques finales
Problème de sélection de dimension
Dans la pratique, il est souvent nécessaire de construire indépendamment un modèle du phénomène, c'est-à-dire de déterminer combien et quelles fonctions de base doivent être prises. La première impulsion pour «obtenir plus» peut jouer une blague cruelle: le modèle sera trop sensible au bruit dans les données (overfitting). En revanche, si vous contraignez trop le modèle, il sera trop grossier (sous-ajustement).
Il y a deux façons de sortir de la situation. La première consiste à augmenter systématiquement le nombre de fonctions de base, à vérifier la qualité de la régression et à s'arrêter dans le temps. Ou la seconde: choisissez une fonction de perte qui déterminera automatiquement le nombre de degrés de liberté. Comme critère de succès de la régression, vous pouvez utiliser le coefficient de détermination, qui a déjà été mentionné ci-dessus, cependant, le problème est queR2croît de manière monotone avec la dimension croissante de la base. Par conséquent, le coefficient ajusté est introduit
ˉR2=1-(1-R2)[N-1N-(n+1)],
Le deuxième groupe d'approches est la régularisation, dont la plus connue est Ridge (L2/ crête / régularisation de Tikhonov), Lasso (L1régularisation) et Elastic Net (Ridge + Lasso). L'idée principale de ces méthodes est de modifier la fonction de perte avec des termes supplémentaires qui ne permettront pas le vecteur de coefficientsw grandir indéfiniment et ainsi empêcher le recyclage
Ecrête(w)=SSE(w)+α∑je|wje|2=SSE(w)+α‖w‖2L2,ELasso(w)=SSE(w)+β∑je|wje|=SSE(w)+β‖w‖L1,ERU(w)=SSE(w)+α‖w‖2L2+β‖w‖L1,
y=une+bX+ϵ,ϵ∼N(0,σ2),{b∼N(0,τ2)←crête,b∼Laplace(0,α)←Lasso...

Méthodes numériques
Permettez-moi de dire quelques mots sur la façon de minimiser la fonction de perte dans la pratique. SSE est une fonction quadratique ordinaire qui est paramétrée par les données d'entrée, donc en principe elle peut être minimisée par la méthode de descente la plus raide ou d'autres méthodes d'optimisation. Bien entendu, les meilleurs résultats sont montrés par des algorithmes qui prennent en compte la forme de la fonction SSE, par exemple la méthode de descente de gradient stochastique. L'implémentation de la régression par Lasso dans scikit-learn utilise la méthode de descente de coordonnées.
Vous pouvez également résoudre des équations normales à l'aide de méthodes d'algèbre linéaire numérique. Une méthode efficace utilisée par scikit-learn pour OLS consiste à trouver la pseudo-inverse en utilisant la décomposition de valeurs singulières. Les champs de cet article sont trop étroits pour aborder ce sujet, pour plus de détails je vous conseille de vous référer au cours des conférences de K.V. Vorontsov.
Publicité et conclusion
Cet article est un récit abrégé de l'un des chapitres d'un cours sur l'apprentissage automatique classique à l' Université universitaire de Kiev (successeur de la branche de Kiev de l'Institut de physique et de technologie de Moscou, KO MIPT). L'auteur de l'article a aidé à créer ce cours. Le cours se déroule techniquement sur la plate-forme Google Colab, qui vous permet de combiner des formules au format LaTeX, du code exécutable Python et des démonstrations interactives en Python + JavaScript, afin que les étudiants puissent travailler avec le matériel du cours et exécuter le code à partir de n'importe quel ordinateur équipé d'un navigateur. La page d'accueil contient des liens vers des résumés, des cahiers d'exercices pratiques et des ressources supplémentaires. Le cours est basé sur les principes suivants:
- tout le matériel doit être disponible pour les étudiants de la première paire;
- la conférence est nécessaire pour comprendre, pas pour prendre des notes (les notes sont déjà prêtes, il ne sert à rien de les écrire si vous ne le souhaitez pas);
- une conférence est plus qu'une conférence (il y a plus de matière dans les notes que ce qui a été annoncé lors de la conférence, en fait, les notes sont un manuel à part entière);
- visibilité et interactivité (illustrations, photos, démos, gifs, code, vidéos de youtube).
Si vous voulez voir le résultat, jetez un œil à la page du cours sur GitHub .
J'espère que vous avez été intéressé, merci de votre attention.