je suis le créateur de Dependency Injector . Il s'agit d'un framework d'injection de dépendances pour Python.
Ceci est le guide définitif pour créer des applications avec Dependency Injector. Les didacticiels précédents expliquent comment créer une application Web avec Flask , l' API REST avec Aiohttp et la surveillance d'un démon avec Asyncio à l' aide de l'injection de dépendances.
Aujourd'hui, je veux montrer comment vous pouvez créer une application console (CLI).
De plus, j'ai préparé des réponses aux questions fréquemment posées et publierai leur post-scriptum.
Le manuel comprend les parties suivantes:
- Qu'allons-nous construire?
- Préparer l'environnement
- Structure du projet
- Installer les dépendances
- Agencements
- Récipient
- Travailler avec CSV
- Travailler avec sqlite
- Sélecteur de fournisseur
- Des tests
- Conclusion
- PS: questions et réponses
Le projet terminé peut être trouvé sur Github .
Pour commencer, vous devez avoir:
- Python 3.5+
- Environnement virtuel
Et il est souhaitable d'avoir une compréhension générale du principe de l'injection de dépendances.
Qu'allons-nous construire?
Nous allons créer une application CLI (console) qui recherche des films. Appelons ça Movie Lister.
Comment fonctionne Movie Lister?
- Nous avons une base de données de films
- Les informations suivantes sont connues sur chaque film:
- Nom
- Année d'émission
- Nom du directeur
- La base de données est distribuée sous deux formats:
- Fichier CSV
- Base de données SQLite
- L'application recherche la base de données à l'aide des critères suivants:
- Nom du directeur
- Année d'émission
- D'autres formats de base de données peuvent être ajoutés à l'avenir
Movie Lister est un exemple d'application utilisé dans l'article de Martin Fowler sur l'injection de dépendances et l'inversion de contrôle.
Voici à quoi ressemble le diagramme de classes de l'application Movie Lister:
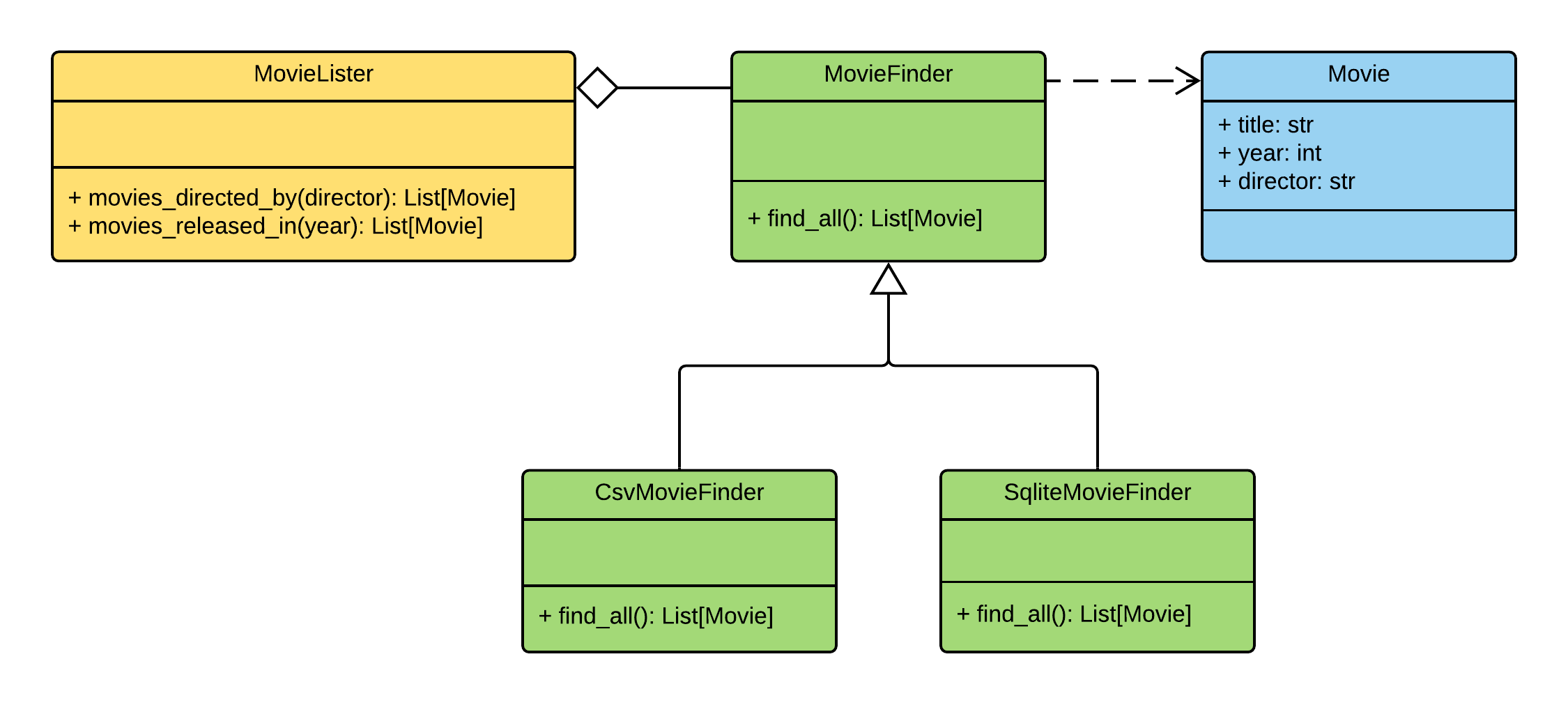
Les responsabilités entre les classes sont réparties comme suit:
MovieLister- responsable de la rechercheMovieFinder- responsable de l'extraction des données de la base de donnéesMovie- classe d'entité "movie"
Préparer l'environnement
Commençons par préparer l'environnement.
Tout d'abord, nous devons créer un dossier de projet et un environnement virtuel:
mkdir movie-lister-tutorial
cd movie-lister-tutorial
python3 -m venv venv
Maintenant, activons l'environnement virtuel:
. venv/bin/activate
L'environnement est prêt. Passons maintenant à la structure du projet.
Structure du projet
Dans cette section, nous organiserons la structure du projet.
Créons la structure suivante dans le dossier actuel. Laissez tous les fichiers vides pour le moment.
Structure initiale:
./
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
Installer les dépendances
Il est temps d'installer les dépendances. Nous utiliserons des packages comme celui-ci:
dependency-injector- framework d'injection de dépendancespyyaml- bibliothèque d'analyse des fichiers YAML, utilisée pour lire la configurationpytest- cadre de testpytest-cov- bibliothèque d'aide pour mesurer la couverture de code par des tests
Ajoutons les lignes suivantes au fichier
requirements.txt:
dependency-injector
pyyaml
pytest
pytest-cov
Et exécutez dans le terminal:
pip install -r requirements.txt
L'installation des dépendances est terminée. Passons aux luminaires.
Agencements
Dans cette section, nous ajouterons des appareils. Les données de test sont appelées appareils.
Nous allons créer un script qui créera des bases de données de test.
Ajoutez un répertoire
data/à la racine du projet et ajoutez un fichier à l'intérieur fixtures.py:
./
├── data/
│ └── fixtures.py
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
Ensuite, modifiez
fixtures.py:
"""Fixtures module."""
import csv
import sqlite3
import pathlib
SAMPLE_DATA = [
('The Hunger Games: Mockingjay - Part 2', 2015, 'Francis Lawrence'),
('Rogue One: A Star Wars Story', 2016, 'Gareth Edwards'),
('The Jungle Book', 2016, 'Jon Favreau'),
]
FILE = pathlib.Path(__file__)
DIR = FILE.parent
CSV_FILE = DIR / 'movies.csv'
SQLITE_FILE = DIR / 'movies.db'
def create_csv(movies_data, path):
with open(path, 'w') as opened_file:
writer = csv.writer(opened_file)
for row in movies_data:
writer.writerow(row)
def create_sqlite(movies_data, path):
with sqlite3.connect(path) as db:
db.execute(
'CREATE TABLE IF NOT EXISTS movies '
'(title text, year int, director text)'
)
db.execute('DELETE FROM movies')
db.executemany('INSERT INTO movies VALUES (?,?,?)', movies_data)
def main():
create_csv(SAMPLE_DATA, CSV_FILE)
create_sqlite(SAMPLE_DATA, SQLITE_FILE)
print('OK')
if __name__ == '__main__':
main()
Maintenant, exécutons dans le terminal:
python data/fixtures.py
Le script devrait sortir
OKen cas de succès.
Nous vérifions que les fichiers
movies.csvet movies.dbapparaissaient dans le répertoire data/:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
Les appareils sont créés. Nous allons continuer.
Récipient
Dans cette section, nous ajouterons la partie principale de notre application - le conteneur.
Le conteneur vous permet de décrire la structure de l'application dans un style déclaratif. Il contiendra tous les composants de l'application et leurs dépendances. Toutes les dépendances seront spécifiées explicitement. Les fournisseurs sont utilisés pour ajouter des composants d'application au conteneur. Les fournisseurs contrôlent la durée de vie des composants. Lors de la création d'un fournisseur, aucun composant n'est créé. Nous disons au fournisseur comment créer l'objet, et il le créera dès que nécessaire. Si la dépendance d'un fournisseur est un autre fournisseur, il sera appelé et ainsi de suite le long de la chaîne de dépendances.
Éditons
containers.py:
"""Containers module."""
from dependency_injector import containers
class ApplicationContainer(containers.DeclarativeContainer):
...
Le conteneur est toujours vide. Nous ajouterons des fournisseurs dans les sections suivantes.
Ajoutons une autre fonction
main(). Sa responsabilité est d'exécuter l'application. Pour l'instant, elle ne créera qu'un conteneur.
Éditons
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
if __name__ == '__main__':
main()
Le conteneur est le premier objet de l'application. Il est utilisé pour récupérer tous les autres objets.
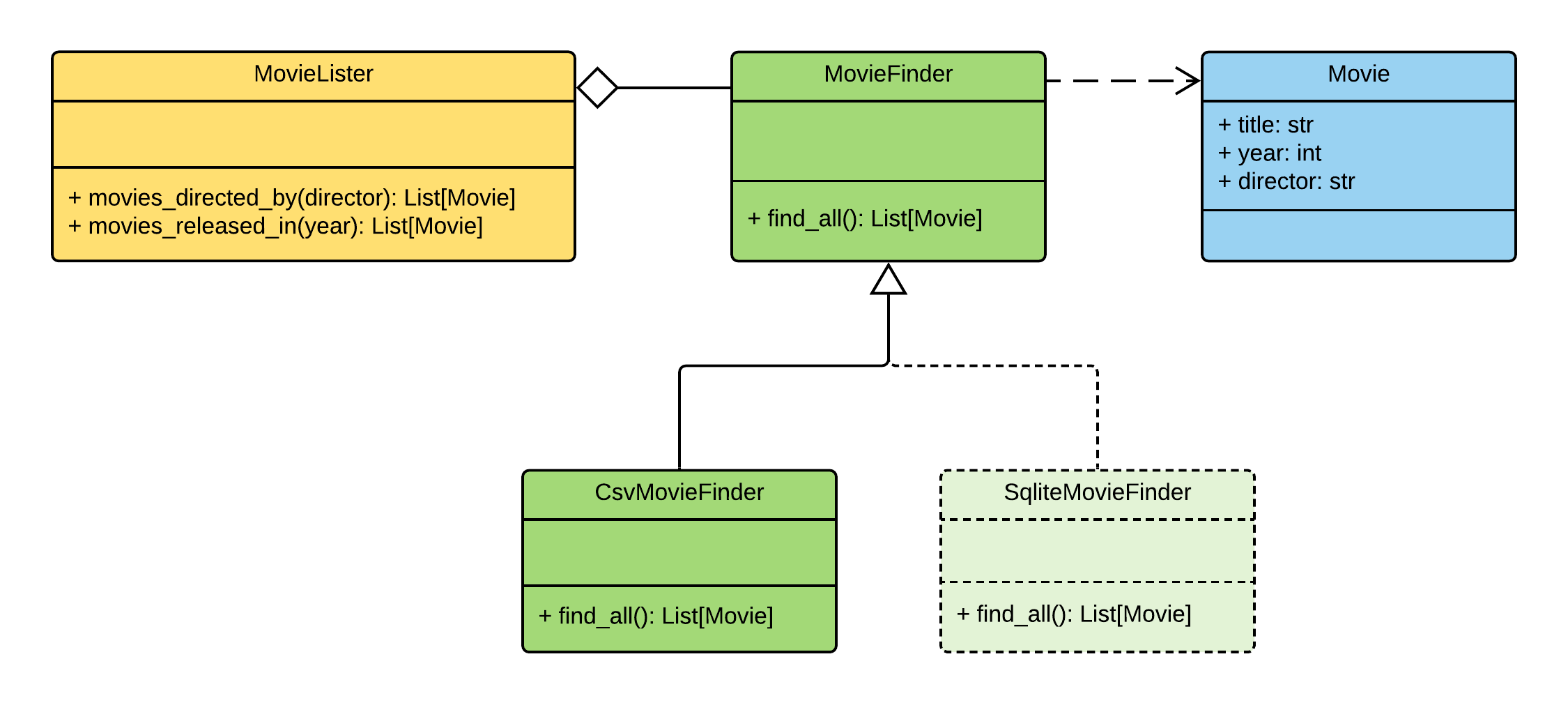
Travailler avec CSV
Ajoutons maintenant tout ce dont nous avons besoin pour travailler avec des fichiers csv.
Nous avons besoin:
- L'essence
Movie - Classe de base
MovieFinder - Sa mise en œuvre
CsvMovieFinder - Classe
MovieLister
Après avoir ajouté chaque composant, nous l'ajouterons au conteneur.
Créez un fichier
entities.pydans un package movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ └── entities.py
├── venv/
├── config.yml
└── requirements.txt
et ajoutez les lignes suivantes à l'intérieur:
"""Movie entities module."""
class Movie:
def __init__(self, title: str, year: int, director: str):
self.title = str(title)
self.year = int(year)
self.director = str(director)
def __repr__(self):
return '{0}(title={1}, year={2}, director={3})'.format(
self.__class__.__name__,
repr(self.title),
repr(self.year),
repr(self.director),
)
Nous devons maintenant ajouter une usine
Movieau conteneur. Pour cela, nous avons besoin d'un module providersde dependency_injector.
Éditons
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import entities
class ApplicationContainer(containers.DeclarativeContainer):
movie = providers.Factory(entities.Movie)
N'oubliez pas de supprimer les points de suspension ( ...). Le conteneur a déjà des fournisseurs et n'est plus nécessaire.
Passons à la création
finders.
Créez un fichier
finders.pydans un package movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ └── finders.py
├── venv/
├── config.yml
└── requirements.txt
et ajoutez les lignes suivantes à l'intérieur:
"""Movie finders module."""
import csv
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
Maintenant, ajoutons
CsvMovieFinderau conteneur.
Éditons
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
Vous
CsvMovieFinderavez une dépendance à l'usine Movie. CsvMovieFindera besoin d'une usine car il créera des objets Movieen lisant les données d'un fichier. Afin de passer l'usine, nous utilisons l'attribut .provider. Cela s'appelle la délégation de fournisseur. Si nous spécifions une fabrique moviecomme dépendance, elle sera appelée lors de sa csv_findercréation CsvMovieFinderet un objet sera passé en injection Movie. L'utilisation de l'attribut .providercomme injection sera transmise par le fournisseur lui-même.
Il a
csv_finderégalement une dépendance sur plusieurs options de configuration. Nous avons ajouté un fournisseur onfigurationpour transmettre ces dépendances.
Nous avons utilisé les paramètres de configuration avant de définir leurs valeurs. C'est le principe selon lequel le fournisseur fonctionneConfiguration.
Nous utilisons d'abord, puis nous définissons les valeurs.
Ajoutons maintenant les valeurs de configuration.
Éditons
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
Les valeurs sont définies dans le fichier de configuration. Mettons à jour la fonction
main()pour indiquer son emplacement.
Éditons
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
if __name__ == '__main__':
main()
Allons-y
listers.
Créez un fichier
listers.pydans un package movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ └── listers.py
├── venv/
├── config.yml
└── requirements.txt
et ajoutez les lignes suivantes à l'intérieur:
"""Movie listers module."""
from .finders import MovieFinder
class MovieLister:
def __init__(self, movie_finder: MovieFinder):
self._movie_finder = movie_finder
def movies_directed_by(self, director):
return [
movie for movie in self._movie_finder.find_all()
if movie.director == director
]
def movies_released_in(self, year):
return [
movie for movie in self._movie_finder.find_all()
if movie.year == year
]
Nous mettons à jour
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=csv_finder,
)
Tous les composants sont créés et ajoutés au conteneur.
Enfin, nous mettons à jour la fonction
main().
Éditons
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
Tout est prêt. Lançons maintenant l'application.
Exécutons dans le terminal:
python -m movies
Tu verras:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
Notre application fonctionne avec une base de données de films au format
csv. Nous devons également ajouter la prise en charge du format sqlite. Nous traiterons de cela dans la section suivante.
Travailler avec sqlite
Dans cette section, nous ajouterons un autre type
MovieFinder- SqliteMovieFinder.
Éditons
finders.py:
"""Movie finders module."""
import csv
import sqlite3
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
class SqliteMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
) -> None:
self._database = sqlite3.connect(path)
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with self._database as db:
rows = db.execute('SELECT title, year, director FROM movies')
return [self._movie_factory(*row) for row in rows]
Ajoutez le fournisseur
sqlite_finderau conteneur et spécifiez-le en tant que dépendance pour le fournisseur lister.
Éditons
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=sqlite_finder,
)
Le fournisseur
sqlite_findera une dépendance sur les options de configuration que nous n'avons pas encore définies. Mettons à jour le fichier de configuration:
Edit
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
sqlite:
path: "data/movies.db"
Terminé. Allons vérifier.
Nous exécutons dans le terminal:
python -m movies
Tu verras:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
Notre application prend en charge les deux formats de base de données:
csvet sqlite. Chaque fois que nous devons changer le format, nous devons changer le code dans le conteneur. Nous améliorerons cela dans la section suivante.
Sélecteur de fournisseur
Dans cette section, nous rendrons notre application plus flexible.
Vous n'avez plus besoin de modifier le code pour basculer entre les formats
csvet sqlite. Nous allons implémenter un commutateur basé sur une variable d'environnement MOVIE_FINDER_TYPE:
- Lorsqu'une
MOVIE_FINDER_TYPE=csvapplication utilise lecsv. - Lorsqu'une
MOVIE_FINDER_TYPE=sqliteapplication utilise lesqlite.
Le fournisseur nous aidera avec cela
Selector. Il choisit un fournisseur en fonction de l'option de configuration ( documentation ).
Éditons
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
Nous avons créé un fournisseur
finderet l' avons spécifié comme dépendance pour le fournisseur lister. Le fournisseur finderchoisit entre les fournisseurs csv_finderet sqlite_finderau moment de l'exécution. Le choix dépend de la valeur du commutateur.
Le commutateur est l'option de configuration
config.finder.type. Lorsque sa valeur est csvutilisée par le fournisseur à partir de la clé csv. De même pour sqlite.
Nous devons maintenant lire la valeur
config.finder.typede la variable d'environnement MOVIE_FINDER_TYPE.
Éditons
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
container.config.finder.type.from_env('MOVIE_FINDER_TYPE')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
Terminé.
Exécutez les commandes suivantes dans le terminal:
MOVIE_FINDER_TYPE=csv python -m movies
MOVIE_FINDER_TYPE=sqlite python -m movies
La sortie de chaque commande ressemblera à ceci:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
Dans cette section, nous avons fait connaissance avec le fournisseur
Selector. Avec ce fournisseur, vous pouvez rendre votre application plus flexible. La valeur du commutateur peut être définie à partir de n'importe quelle source: fichier de configuration, dictionnaire, autre fournisseur.
Conseil: le
remplacement d'une valeur de configuration d'un autre fournisseur vous permet d'implémenter la surcharge de configuration dans votre application sans redémarrage à chaud.
Pour ce faire, vous devez utiliser la délégation de fournisseur et le.override().
Dans la section suivante, nous ajouterons quelques tests.
Des tests
Enfin, ajoutons quelques tests.
Créez un fichier
tests.pydans un package movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ ├── listers.py
│ └── tests.py
├── venv/
├── config.yml
└── requirements.txt
et ajoutez-y les lignes suivantes:
"""Tests module."""
from unittest import mock
import pytest
from .containers import ApplicationContainer
@pytest.fixture
def container():
container = ApplicationContainer()
container.config.from_dict({
'finder': {
'type': 'csv',
'csv': {
'path': '/fake-movies.csv',
'delimiter': ',',
},
'sqlite': {
'path': '/fake-movies.db',
},
},
})
return container
def test_movies_directed_by(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_directed_by('Jon Favreau')
assert len(movies) == 1
assert movies[0].title == 'The Jungle Book'
def test_movies_released_in(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_released_in(2015)
assert len(movies) == 1
assert movies[0].title == 'The 33'
Commençons maintenant les tests et vérifions la couverture:
pytest movies/tests.py --cov=movies
Tu verras:
platform darwin -- Python 3.8.3, pytest-5.4.3, py-1.9.0, pluggy-0.13.1
plugins: cov-2.10.0
collected 2 items
movies/tests.py .. [100%]
---------- coverage: platform darwin, python 3.8.3-final-0 -----------
Name Stmts Miss Cover
------------------------------------------
movies/__init__.py 0 0 100%
movies/__main__.py 10 10 0%
movies/containers.py 9 0 100%
movies/entities.py 7 1 86%
movies/finders.py 26 13 50%
movies/listers.py 8 0 100%
movies/tests.py 24 0 100%
------------------------------------------
TOTAL 84 24 71%
Nous avons utilisé la méthode du.override()fournisseurfinder. Le fournisseur est remplacé par mock. Lorsque vous contactez le fournisseur, lafindermaquette de remplacement sera désormais renvoyée.
Le travail est terminé. Maintenant, résumons.
Conclusion
Nous avons construit une application CLI en utilisant le principe d'injection de dépendances. Nous avons utilisé Dependency Injector comme cadre d'injection de dépendances.
L'avantage que vous obtenez avec Dependency Injector est le conteneur.
Le conteneur commence à porter ses fruits lorsque vous devez comprendre ou modifier la structure de votre application. Avec un conteneur, c'est facile car tous les composants de l'application et leurs dépendances sont explicitement définis en un seul endroit:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
Un conteneur comme carte de votre application. Vous savez toujours ce qui dépend de quoi.
PS: questions et réponses
Dans les commentaires du didacticiel précédent, des questions intéressantes ont été posées: "Pourquoi est-ce nécessaire?", "Pourquoi avons-nous besoin d'un cadre?", "Comment le cadre aide-t-il à l'implémentation?"
J'ai préparé des réponses:
Qu'est-ce que l'injection de dépendances?
- c'est le principe qui réduit le couplage et augmente la cohésion
Pourquoi devrais-je utiliser l'injection de dépendances?
- votre code devient plus flexible, compréhensible et mieux testable
- vous avez moins de problèmes lorsque vous avez besoin de comprendre comment cela fonctionne ou de le modifier
Comment commencer à appliquer l'injection de dépendances?
- vous commencez à écrire du code en suivant le principe d' injection de dépendances
- vous enregistrez tous les composants et leurs dépendances dans le conteneur
- lorsque vous avez besoin d'un composant, vous le récupérez dans le conteneur
Pourquoi ai-je besoin d'un cadre pour cela?
- vous avez besoin d'un cadre pour ne pas créer le vôtre. Le code de création d'objet sera dupliqué et difficile à modifier. Pour éviter cela, vous avez besoin d'un conteneur.
- le framework vous donne un conteneur et des fournisseurs
- les fournisseurs contrôlent la durée de vie des objets. Vous aurez besoin d'usines, de singletons et d'objets de configuration
- le conteneur sert de collection de fournisseurs
Quel prix suis-je en train de payer?
- vous devez spécifier explicitement les dépendances dans le conteneur
- c'est un travail supplémentaire
- il commencera à rapporter des dividendes lorsque le projet commencera à se développer
- ou 2 semaines après son achèvement (lorsque vous oubliez quelles décisions vous avez prises et quelle est la structure du projet)
Concept d'injecteur de dépendance
En outre, je décrirai le concept d'injecteur de dépendance en tant que cadre.
Dependency Injector est basé sur deux principes:
- Explicite vaut mieux qu'implicite (PEP20).
- Ne faites aucune magie avec votre code.
En quoi Dependency Injector est-il différent des autres frameworks?
- Pas de lien automatique. Le framework ne lie pas automatiquement les dépendances. Introspection, la liaison par noms d'arguments et / ou types n'est pas utilisée. Parce que "explicite vaut mieux qu'implicite (PEP20)".
- Ne pollue pas le code de votre application. Votre application ne connaît pas et est indépendante de l'injecteur de dépendances. Pas de
@injectdécorateurs, annotations, patchs ou autres tours de magie.
Dependency Injector propose un contrat simple:
- Vous montrez au framework comment collecter des objets
- Le cadre les rassemble
La force de l'injecteur de dépendance réside dans sa simplicité et sa simplicité. C'est un outil simple pour mettre en œuvre un principe puissant.
Et après?
Si vous êtes intéressé, mais hésitez, ma recommandation est la suivante:
essayez cette approche pendant 2 mois. Il n'est pas intuitif. Il faut du temps pour s'y habituer et se sentir. Les avantages deviennent tangibles lorsque le projet passe à plus de 30 composants dans un conteneur. Si vous ne l'aimez pas, ne perdez pas grand-chose. Si vous l'aimez, obtenez un avantage significatif.
- En savoir plus sur Dependency Injector sur GitHub
- Consultez la documentation sur Lire les documents
Je serais heureux de recevoir des commentaires et de répondre aux questions dans les commentaires.