Google: Google: 90% de nos ingénieurs utilisent un programme que vous avez écrit (Homebrew), mais vous ne peut pas inverser un arbre binaire sur un tableau, alors au revoir.
Bien que je n'ai jamais eu besoin d'inverser un arbre binaire, je suis tombé sur des exemples d'utilisation réelle de structures de données et d'algorithmes dans mon travail quotidien, lorsque je travaillais chez Skype / Microsoft, Skyscanner et Uber . Cela comprenait le codage et la prise de décision basés sur les spécificités des structures de données et des algorithmes. Mais, pour la plupart, j'ai utilisé les connaissances pertinentes pour comprendre comment certains systèmes ont été créés et pourquoi ils ont été créés de cette façon. La connaissance des concepts pertinents facilite la compréhension de l'architecture et de la mise en œuvre des systèmes dans lesquels ces concepts sont utilisés.

Dans cet article, j'ai inclus des histoires sur des situations dans lesquelles des structures de données telles que des arbres et des graphiques, ainsi que divers algorithmes, ont été utilisées dans de vrais projets. J'espère montrer ici au lecteur qu'une connaissance de base des structures de données et des algorithmes n'est pas une théorie inutile nécessaire uniquement pour les entretiens, mais quelque chose qui est très susceptible d'être vraiment nécessaire à quelqu'un qui travaille dans des entreprises technologiques innovantes à croissance rapide.
Nous parlerons ici d'un très petit nombre d'algorithmes, mais en ce qui concerne les structures de données, je peux noter que je vais les aborder presque tous ici. Cela ne devrait surprendre personne que je ne sois pas fan du genre de questions d'entrevue qui mettent trop l'accent sur les algorithmes, sont déconnectées de la pratique et ciblent des structures de données exotiques comme les arbres rouge-noir ou les arbres AVL. Je n'ai jamais posé de telles questions dans les entretiens et je ne les poserai pas. À la fin de cet article, je partagerai mes réflexions sur ces entretiens. Malgré ce qui précède, la connaissance des structures de données sous-jacentes est d'une immense valeur. Cette connaissance vous permet de sélectionner exactement ce qui est nécessaire pour résoudre certains problèmes pratiques.
Passons maintenant à des exemples d'utilisation de structures de données et d'algorithmes dans la vie réelle.
Arbres et traversée des arbres: frameworks Skype, Uber et UI
Lorsque nous développions Skype pour Xbox One, le code devait être écrit pour un système d'exploitation Xbox pur qui ne disposait pas des bibliothèques dont nous avions besoin. Nous avons développé l'une des premières applications à part entière pour cette plate-forme. Nous avions besoin d'un système de navigation d'application qui pourrait être utilisé à la fois en utilisant l'écran tactile et en donnant des commandes vocales à l'application.
Nous avons créé un cadre de navigation basé sur WinJS. Pour ce faire, nous devions maintenir un graphe de type DOM, qui était nécessaire pour organiser l'observation des éléments avec lesquels l'utilisateur pouvait interagir. Pour trouver de tels éléments, nous avons effectué une traversée DOM, qui se résumait à une traversée d'arbre, c'est-à-dire la structure existante des éléments DOM. Il s'agit d'un exemple classique de BFS ou DFS (recherche en largeur d'abord ou recherche en profondeur d'abord - recherche en largeur d'abord ou recherche en profondeur d'abord).
Si vous faites du développement Web, cela signifie que vous travaillez déjà avec une structure arborescente, à savoir le DOM. Tous les nœuds DOM peuvent avoir des nœuds enfants. Le navigateur affiche les nœuds après avoir parcouru l'arborescence DOM. Si vous avez besoin de trouver un élément spécifique, vous pouvez utiliser les méthodes DOM intégrées pour résoudre ce problème. Par exemple, la méthode getElementById. Une alternative consiste à développer votre propre solution BFS ou DFS pour parcourir les nœuds et trouver ce dont vous avez besoin. Par exemple, quelque chose de similaire est fait ici .
De nombreux frameworks qui rendent des éléments d'interface utilisateur utilisent des arborescences dans leurs profondeurs. Ainsi, React prend en charge le DOM virtuel et utilise un algorithme de réconciliation intelligent(comparaisons). Cela vous permet d'obtenir des performances élevées en raison du fait que seules les parties modifiées de l'interface sont de nouveau rendues. Une visualisation de ce processus peut être trouvée ici.
Dans l'architecture mobile Uber, RIB, les arbres sont également utilisés. Cela rend cette architecture similaire à la plupart des autres frameworks d'interface utilisateur qui affichent des structures hiérarchiques d'éléments. L'architecture des RIB maintient une arborescence RIB à des fins de gestion d'état. Le fait d'attacher et de détacher des RIB contrôle leur rendu. Tout en travaillant avec des RIB, nous avons parfois esquissé, essayant de comprendre si les RIB s'inscrivent dans la hiérarchie existante, et avons discuté si les RIB en question devraient avoir des éléments visibles. Autrement dit, ils ont discuté de la question de savoir si cette structure participera à la formation de la présentation visuelle de l'interface ou si elle ne sera utilisée que pour la gestion de l'état.

Transitions d'état lors de l'utilisation de RIB. Vous pouvez trouver plus de détails sur les RIB ici.
Si jamais vous avez besoin de rendre des éléments hiérarchiques, sachez que les arborescences sont généralement utilisées pour cela, les traversant et le rendu des éléments visités. J'ai rencontré de nombreux outils internes qui adoptent cette approche. Un exemple d'un tel outil est le moteur de rendu RIBs créé par l'équipe Mobile Platform d'Uber. Voici un rapport sur ce sujet.
Graphiques pondérés et recherche de chemin le plus court: Skyscanner
Skyscanner est un projet qui vise à trouver les meilleures offres sur les billets d'avion. La recherche de telles propositions se fait en visualisant et en analysant tous les itinéraires existants dans le monde et en les combinant. L'essence de cette tâche est davantage liée à la collecte automatique de données par un robot de recherche, et non à la mise en cache de toutes ces données, car les compagnies aériennes calculent indépendamment le temps d'attente pour le prochain vol. Mais la possibilité de planifier un voyage avec une visite dans plusieurs villes se résume à la tâche de trouver le chemin le plus court.
La planification de voyages multi-villes était l'une des possibilités que Skyscanner a mis du temps à mettre en œuvre. Dans le même temps, les difficultés concernaient principalement le système en cours de développement. Les meilleures offres de ce type sont trouvées en utilisant des algorithmes de chemin le plus court comme Dijkstra ou A *. Les itinéraires de vol sont présentés sous la forme d'un graphique orienté. Chacun de ses bords se voit attribuer un poids sous la forme d'un prix de billet. Lors de la recherche du meilleur itinéraire, la recherche de l'itinéraire le moins cher entre deux villes est effectuée à l'aide de l'implémentation de l'algorithme A * modifié . Si le sujet de la sélection des billets d'avion et de la recherche des itinéraires les plus courts vous intéresse, voici un bon article sur l'utilisation de BFS pour résoudre de tels problèmes.
Cependant, dans le cas de Skyscanner, quel algorithme a été utilisé pour résoudre le problème n'était pas particulièrement important. Mettre en cache, utiliser des robots de recherche, organiser le travail avec différents sites - tout cela était beaucoup plus difficile que de choisir un algorithme. Mais en même temps, différentes variantes du problème de la recherche du chemin le plus court se posent dans de nombreuses sociétés de planification de voyages et d'optimisation du coût de ces voyages. Sans surprise, ce sujet a également fait l'objet de discussions en coulisses chez Skyscanner.
Trier: Skype (ou quelque chose comme ça)
J'avais rarement une raison d'implémenter moi-même des algorithmes de tri ou d'étudier en profondeur les subtilités de leur structure. Mais malgré cela, il était intéressant de comprendre le fonctionnement de ces algorithmes - du tri à bulles, du tri par insertion, du tri par fusion et du tri par sélection, à l'algorithme le plus complexe - quicksort. J'ai constaté qu'il est rarement nécessaire d'implémenter de tels algorithmes, surtout si vous n'avez pas besoin d'écrire une fonction de tri faisant partie d'une bibliothèque.
Dans Skype, cependant, j'ai dû recourir à l'utilisation pratique de mes connaissances des algorithmes de tri. Un de nos programmeurs a décidé de mettre en place le tri par insertions pour afficher les contacts. En 2013, lorsque Skype était en ligne, les contacts étaient téléchargés par lots. Il a fallu un certain temps pour tous les télécharger. En conséquence, ce programmeur a pensé qu'il serait préférable de créer une liste de contacts triés par nom en utilisant le tri par insertion. Nous avons beaucoup discuté de cet algorithme, en nous demandant pourquoi ne pas simplement utiliser quelque chose qui a déjà été implémenté. En conséquence, il nous a fallu le plus de temps pour tester correctement notre implémentation de l'algorithme et vérifier ses performances. Personnellement, je ne voyais pas grand chose à créer ma propre implémentation de cet algorithme. Mais alors le projet était à un tel stadeoù nous avions le temps pour de telles choses.
Bien sûr, il existe des situations réelles dans lesquelles un tri efficace joue un rôle très important dans un projet. Et si le développeur peut indépendamment, en fonction des caractéristiques des données, choisir l'algorithme le plus approprié, cela peut donner une augmentation notable des performances de la solution. Le tri par insertion peut être très utile lorsque vous travaillez avec de grands ensembles de données transmis quelque part en temps réel et visualisez immédiatement ces données. Le tri par fusion peut bien fonctionner pour les approches de division et de conquête lors du traitement de grandes quantités de données stockées dans différents nœuds. Je n'ai jamais travaillé avec de tels systèmes, donc pour l'instant je continue à considérer les algorithmes de tri comme quelque chose qui a une utilisation limitée dans le travail quotidien. C'est vrai,il ne s'agit pas de comprendre comment fonctionnent les différents algorithmes de tri.
Tables de hachage et hachage: partout
La structure de données que j'utilise régulièrement est une table de hachage. Cela inclut également les fonctions de hachage. C'est un outil très utile qui peut être utilisé pour résoudre une variété de tâches - du comptage du nombre de certaines entités, la détection des doublons, la mise en cache, aux scénarios comme le sharding utilisé dans les systèmes distribués . Les tables de hachage sont, après les tableaux, la structure de données la plus courante en programmation. Je l'ai utilisé dans d'innombrables situations. Il est présent dans presque tous les langages de programmation, et si nécessaire, il est facile de l'implémenter vous-même.
Piles et files d'attente: de temps en temps
Une pile est une structure de données familière à quiconque a débogué du code écrit dans un langage prenant en charge les traces de pile. Si nous parlons de la pile comme d'une structure de données, alors, au cours du travail, j'ai rencontré plusieurs problèmes pour la solution desquels elle était nécessaire. Mais il convient de noter que j'ai appris à connaître correctement les piles lors du débogage et du profilage des performances du code. Les piles sont également un choix naturel pour la structure de données à utiliser lors de l'exécution de DFS.
J'ai rarement eu recours à l'utilisation de files d'attente, mais je les ai rencontrées assez souvent dans les bases de code de divers projets. Disons que quelque chose a été placé dans la file d'attente et que quelque chose en a été récupéré. En règle générale, les files d'attente sont utilisées pour implémenter la traversée d'arborescence en largeur en premier, et elles sont idéales pour cette tâche. Les files d'attente peuvent également être utilisées dans de nombreuses autres situations. Une fois que je suis tombé sur un code de planification de tâches dans lequel j'ai trouvé un exemple d'utilisation décente de la file d'attente prioritaire implémentée par le module Python heapq , lorsque les tâches les plus courtes ont été exécutées en premier.
Algorithmes cryptographiques: Uber
Les données importantes que les utilisateurs entrent dans les applications mobiles ou les applications Web doivent être cryptées avant d'être transmises sur le réseau. Et ils ne les déchiffrent que là où ils sont nécessaires. Afin d'organiser un tel schéma de travail, la mise en œuvre d'algorithmes cryptographiques doit être présente sur les parties client et serveur des applications.
Comprendre les algorithmes cryptographiques est très intéressant. Dans le même temps, vous ne devez pas proposer vos propres algorithmes pour résoudre certains problèmes. C'est l'une des pires idées auxquelles un programmeur puisse penser. Au lieu de cela, il prend une norme existante et bien documentée et utilise les primitives natives des frameworks respectifs. Habituellement, AES agit comme la norme choisie lors de la mise en œuvre de solutions cryptographiques.... Il est suffisamment sécurisé pour l'utiliser pour crypter des informations classifiées aux États-Unis . Il n'y a pas d'attaques fonctionnelles connues sur le protocole. AES-192 et AES-256 sont généralement assez fiables pour la plupart des tâches pratiques.
Quand je suis arrivé à Uber, le système de cryptage mobile et le système de cryptage pour l'application Web étaient déjà implémentés, ils étaient basés sur les mécanismes ci-dessus, donc j'avais une excuse pour étudier les détails sur AES (Advanced Encryption Standard), sur HMAC (Hashed Message Authentication Codes) , sur l'algorithme RSA et d'autres choses similaires. Il était également intéressant de comprendre comment la force cryptographique de la séquence d'actions utilisée dans le cryptage est prouvée. Par exemple, si nous parlons de cryptage authentifié avec des données jointes, il s'avère qu'en analysant les modes cryptage et MAC, MAC-puis-cryptage et cryptage-puis-MAC, on peut prouver la force cryptographique d'un seul d'entre eux , bien que cela ne signifie pas les autres ne sont pas sécurisés par cryptographie.
Vous n'aurez presque jamais besoin d'implémenter vous-même des primitives cryptographiques, à moins que vous n'implémentiez un tout nouveau cadre cryptographique. Mais vous pourriez bien être confronté à la nécessité de prendre des décisions sur les primitives à utiliser et comment les combiner. Vous pouvez également avoir besoin de connaissances dans le domaine des algorithmes cryptographiques afin de comprendre pourquoi un certain système utilise une certaine approche du cryptage des données.
Arbres de décision: Uber
Tout en travaillant sur l'un des projets, nous avons dû implémenter une logique métier complexe dans une application mobile. À savoir, sur la base d'une demi-douzaine de règles, l'un des nombreux écrans devait être montré. Ces règles étaient très complexes car les résultats de la séquence de test et la préférence de l'utilisateur devaient être pris en compte.
Le programmeur qui a commencé à résoudre ce problème a d'abord essayé d'exprimer toutes ces règles sous la forme d'instructions if-else. Cela a abouti à un code extrêmement déroutant. En conséquence, il a été décidé d'utiliser l'arbre de décision. Avec son aide, il a été facile d'effectuer tous les contrôles nécessaires. C'était relativement facile à mettre en œuvre. De plus, si nécessaire, il pourrait être changé sans trop de problèmes. Nous devions créer notre propre implémentation de l'arbre de décision, de sorte que les conditions soient vérifiées sur ses bords. C'est tout ce dont nous avions besoin de cet arbre. Bien que nous aurions pu gagner du temps à implémenter l'arbre en adoptant une approche différente, l'équipe a décidé que l'arbre particulier serait plus facile à entretenir et s'est mis au travail. Cet arbre ressemble à ceci:les arêtes symbolisent les résultats de la vérification des conditions (ce sont des résultats binaires, ou les résultats représentés par des plages de valeurs), et les nœuds feuilles de l'arborescence décrivent les écrans vers lesquels vous devez naviguer.
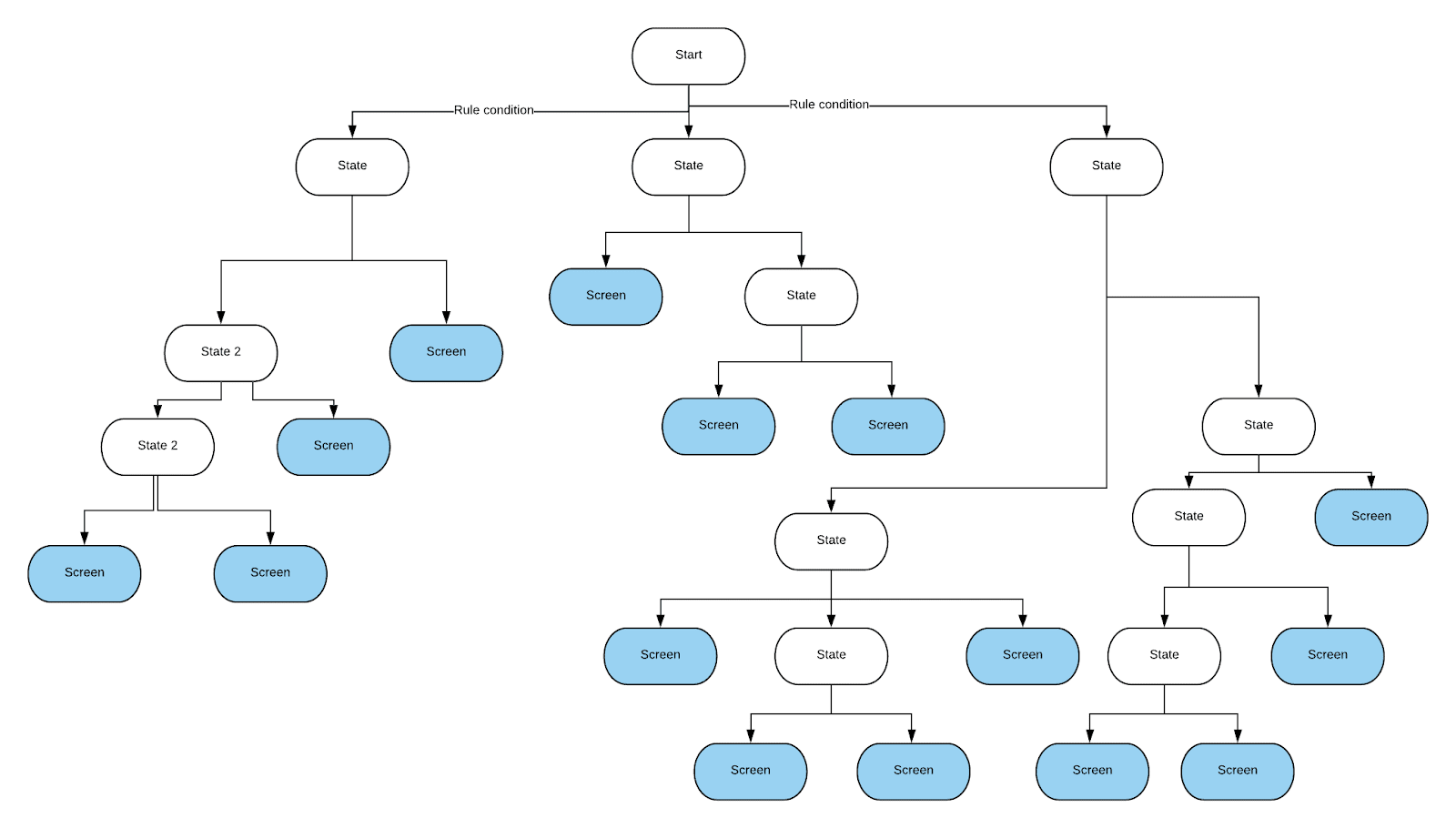
, , .
Le système de construction de l'application mobile d'Uber, appelé SubmitQueue, a également utilisé un arbre de décision, mais il a été généré de manière dynamique. L'équipe Developer Experience a dû s'attaquer au difficile problème de la fusion quotidienne de centaines de branches sources avec la branche cible. Dans le même temps, chaque assemblage a duré environ 30 minutes. Cela comprenait la compilation, l'exécution de tests unitaires et d'intégration, ainsi que des tests d'interface. La mise en parallèle d'assemblys n'était pas une solution suffisante, car il y avait souvent des modifications qui se chevauchaient dans différents assemblys, ce qui provoquait des conflits de fusion. En pratique, cela signifiait que parfois les programmeurs devaient attendre 2 à 3 heures, recourir au rebase et redémarrer à nouveau le processus de fusion, espérant que cette fois, ils ne seraient pas confrontés à un conflit.
L'équipe Developer Experience a adopté une approche innovante pour prédire les conflits de fusion et les assemblages de files d'attente en conséquence. Cela a été fait en utilisant un arbre de décision binaire spécial (arbre de spéculation).

SubmitQueue utilise un arbre de décision binaire avec des arêtes annotées avec des probabilités prédites. Cette approche vous permet de déterminer quels ensembles d'assemblys peuvent être exécutés en parallèle. Ceci est fait afin de réduire le temps entre la réception et l'exécution des tâches et afin d'augmenter le débit du système. Dans ce cas, seul le code entièrement testé et exploitable doit entrer dans la branche principale. L'
équipe Developer Experience, qui a créé ce système, a rédigé d'excellents documents à ce sujet. Mais ici- un autre article sur le même sujet, bien illustré. Le résultat de la mise en œuvre de ce système a été la création d'un système d'assemblage de projets beaucoup plus rapide qu'auparavant. Cela nous a permis d'optimiser le temps de construction des projets et de faciliter la vie de centaines de programmeurs mobiles.
Grilles hexagonales, index hiérarchiques: Uber
C'est le dernier projet dont je veux parler ici. Il était entièrement basé sur une structure de données particulière. C'est en faisant cela que j'ai découvert cette structure de données. Nous parlons d'une grille hexagonale avec des indices hiérarchiques.
L'un des problèmes les plus difficiles et les plus intéressants chez Uber était l'optimisation du coût des déplacements et la répartition des commandes entre les partenaires. Les tarifs des trajets peuvent évoluer de manière dynamique, les chauffeurs sont constamment en mouvement. Les ingénieurs d'Uber ont créé le système de grille H3. Il est conçu pour visualiser et analyser les données dans les villes à différentes échelles. La structure de données utilisée pour résoudre les problèmes ci-dessus est une grille hexagonale avec des indices hiérarchiques. Quelques outils internes spécialisés sont utilisés pour visualiser les données.

Fractionnement de la carte en cellules hexagonales
Cette structure de données a son propre système d'indexation, parcours, ses propres définitions de zones individuelles de la grille, ses propres fonctions. Une description détaillée de tout cela peut être trouvée dans la documentation de l'API correspondante. En savoir plus sur H3 ici . Voici le code source. Ici vous pouvez trouver une histoire sur comment et pourquoi ce système a été créé.
L'expérience de ce système m'a permis de me faire une idée du fait que la création de vos propres structures de données spécialisées peut avoir un sens pour résoudre des problèmes très spécifiques. Il y a très peu de problèmes dans la solution desquels vous pouvez appliquer une grille hexagonale, si vous ne prenez pas en compte la division en fragments de carte avec une comparaison avec chaque fragment de données résultant de différents niveaux. Mais comme dans d'autres cas, si vous êtes familier avec d'autres structures de données, cela sera beaucoup plus facile à comprendre. Et pour une personne qui a eu affaire à une grille hexagonale, il sera plus facile de créer une nouvelle structure de données conçue pour résoudre des problèmes similaires à ceux qui sont résolus à l'aide d'une telle grille.
Structures de données et algorithmes dans les entretiens
Ci-dessus, j'ai parlé des structures de données et des algorithmes que j'ai rencontrés en travaillant pendant longtemps dans diverses entreprises. Je propose maintenant de revenir sur ce tweet de Max Howell, que j'ai mentionné au tout début de l'article. Là, Max s'est plaint que lors d'une interview avec Google, on lui a demandé d'inverser un arbre binaire sur un tableau. Il ne l'a pas fait. On lui a montré la porte. Dans cette situation, je suis du côté de Max.
Je pense que savoir comment fonctionnent les algorithmes populaires ou comment fonctionnent les structures de données exotiques n'est pas le type de connaissances dont vous avez besoin pour travailler pour une entreprise de technologie. Vous devez savoir ce qu'est un algorithme, vous devez être capable de trouver indépendamment des algorithmes simples, par exemple, en travaillant sur le principe "gourmand". Vous devez également connaître les structures de données les plus courantes telles que les tables de hachage, les files d'attente et les piles. Mais quelque chose d'assez spécifique, comme l'algorithme de Dijkstra ou A *, ou quelque chose d'encore plus complexe, n'est pas quelque chose qui doit être appris par cœur. Si vous avez vraiment besoin de ces algorithmes, vous pouvez facilement y trouver des documents de référence. Par exemple, si nous parlons d'algorithmes qui ne sont pas liés aux algorithmes de tri, j'ai généralement essayé de les comprendre en termes généraux et de comprendre leur essence.Il en va de même pour les structures de données exotiques comme les arbres rouge-noir et les arbres AVL. Je n'ai jamais eu besoin de les utiliser. Et si j'en avais besoin, je pourrais toujours rafraîchir mes connaissances à leur sujet en recourant aux publications appropriées. Lors des entretiens, comme je l'ai dit, je ne pose jamais de telles questions et je n'ai pas l'intention de les poser.
Je suis en faveur des problèmes pratiques liés à la programmation, qui peuvent être résolus en utilisant une variété d'approches, des algorithmes de "force brute" et "gourmands" aux idées algorithmiques plus avancées. Par exemple, je pense qu'il est parfaitement normal d'avoir une tâche d'alignement de texte comme celle-ci . Par exemple, j'ai dû résoudre ce problème lors de la création d'un composant pour le rendu de texte sur Windows Phone. Vous pouvez résoudre ce problème simplement en utilisant un tableau et quelques instructions if-else, sans recourir à des structures de données délicates.
En fait, de nombreuses équipes et entreprises exagèrent l'importance des problèmes algorithmiques. Je comprends l'attrait des questions d'algorithme. Ils vous permettent d'évaluer le candidat en peu de temps, les questions sont faciles à refaire, ce qui signifie que si les questions qui ont été posées à quelqu'un deviennent publiques, cela ne posera pas de problèmes particuliers. Les questions d'algorithme sont utiles pour organiser des essais pour un grand nombre de candidats. Par exemple, vous pouvez créer un pool de plus d'une centaine de questions et les distribuer au hasard aux candidats. Les questions concernant la programmation dynamique et les structures de données exotiques sont de plus en plus courantes. Surtout dans la Silicon Valley. Ces questions peuvent aider les entreprises à embaucher des programmeurs performants. Mais ces mêmes questions peuvent fermer la voie dans l'entreprise à ceux qui ont réussi en affaires,où une connaissance approfondie des algorithmes n'est pas nécessaire.
Si vous êtes issu d'une entreprise qui n'embauche que des personnes qui ont une connaissance approfondie des algorithmes complexes presque depuis la naissance, je vous suggère de réfléchir attentivement à la question de savoir si ce sont les personnes dont vous avez besoin. Par exemple, j'ai embauché de grandes équipes chez Skyscanner (Londres) et Uber (Amsterdam) sans poser de questions délicates sur l'algorithme. Je me suis limité aux structures de données les plus courantes et à tester les capacités des personnes interrogées en matière de résolution de problèmes. Autrement dit, ils devaient connaître les structures de données communes et être capables de proposer des algorithmes simples pour résoudre les problèmes auxquels ils sont confrontés. Les structures de données et les algorithmes ne sont que des outils.
Conclusion: les structures de données et les algorithmes sont des outils
Si vous travaillez pour une entreprise de technologie dynamique et innovante, vous rencontrerez probablement des implémentations d'une grande variété de structures de données et d'algorithmes dans le code des produits de cette entreprise. Si vous développez quelque chose de complètement nouveau, vous devez souvent rechercher des structures de données qui facilitent la résolution des problèmes auxquels vous êtes confrontés. Dans de telles situations, vous avez besoin d'une connaissance générale des algorithmes et des structures de données et de leurs avantages et inconvénients pour faire le bon choix.
Les structures de données et les algorithmes sont des outils que vous devez utiliser avec confiance lors de l'écriture de programmes. Lorsque vous connaissez ces outils, vous verrez beaucoup de ce que vous savez déjà dans les bases de code qui les utilisent. De plus, ces connaissances vous permettront de résoudre des problèmes complexes avec beaucoup plus de confiance. Vous serez conscient des limites théoriques des algorithmes et de la manière dont ils peuvent être optimisés. Cela vous aidera finalement à arriver à une solution qui, avec tous les compromis nécessaires, s'avère être aussi bonne que possible.
Si vous souhaitez mieux comprendre les structures de données et les algorithmes, voici quelques conseils et ressources:
- -, , , , , , . , , . , . — , .
- « ». , , , . — , , . , , , .
- Voici quelques livres supplémentaires: « Algorithms. Guide de développement »et« Algorithmes en Java, 4e édition ». Je les ai utilisés pour rafraîchir mes connaissances universitaires en algorithmes. Certes, je ne les ai pas lus jusqu'au bout. Ils me paraissaient plutôt secs et inapplicables à mon travail quotidien.
Quelles structures de données et quels algorithmes avez-vous rencontrés dans la pratique?
