
Les ASIC dédiés pour des domaines spécifiques sont un moyen de «redémarrer» la loi de Moore et de surmonter les limitations des processeurs à usage général. C'est maintenant un domaine de développement très prometteur de la microélectronique. Google, Amazon et d'autres entreprises ont leurs propres projets. Par exemple, Google fabrique des processeurs Google TPU Tensor et les centres de données Amazon exécutent des puces AWS Graviton sur le cœur ARM.
Les premiers sont des ASIC pour les réseaux de neurones, et les seconds sont des ARM 64 bits à usage général pour optimiser le rapport qualité-prix dans les charges de travail intensives en calcul.
Une autre classe d'ASIC à usage général, où des expériences actives ont été menées récemment, sont les coprocesseurs spécialisés pour le traitement de données (unité de traitement de données, DPU), une sorte de cartes réseau à puce (SmartNIC). Quelques exemples de cette espèce sont Nvidia BlueField 2, Fungible et Pensando DSC-25.
Qu'est-ce qu'ils aiment? Pour quelles tâches conviennent-ils? Jetons un coup d'oeil.

Qu'est-ce que SmartNIC
Les cartes réseau conventionnelles (NIC) sont construites sur un circuit intégré à usage spécial (ASIC), qui est conçu pour fonctionner comme un contrôleur Ethernet. Souvent, ces microcircuits sont conçus pour remplir des fonctions secondaires. Par exemple, les contrôleurs Mellanox ConnectX prennent également en charge le protocole Infiniband haute vitesse. Ce sont d'excellentes puces spécialisées, mais leur fonctionnalité ne peut pas être modifiée.
Contrairement aux cartes réseau simples, SmartNIC permet à l'utilisateur de télécharger des logiciels supplémentaires sur le contrôleur, c'est-à-dire après l'achat du matériel. Cela étend ou modifie la fonctionnalité de l'ASIC. La procédure est un peu similaire à l'achat d'un smartphone et à l'installation de diverses applications.
Pour rendre cela possible, les SmartNIC nécessitent plus de puissance de traitement et de mémoire supplémentaire que les NIC conventionnels. Nous parlons de processeurs ARM multicœurs plus puissants, de l'installation de processeurs réseau spécialisés (coeurs de traitement de flux, FPC) et de matrices de portes programmables sur site (FPGA).
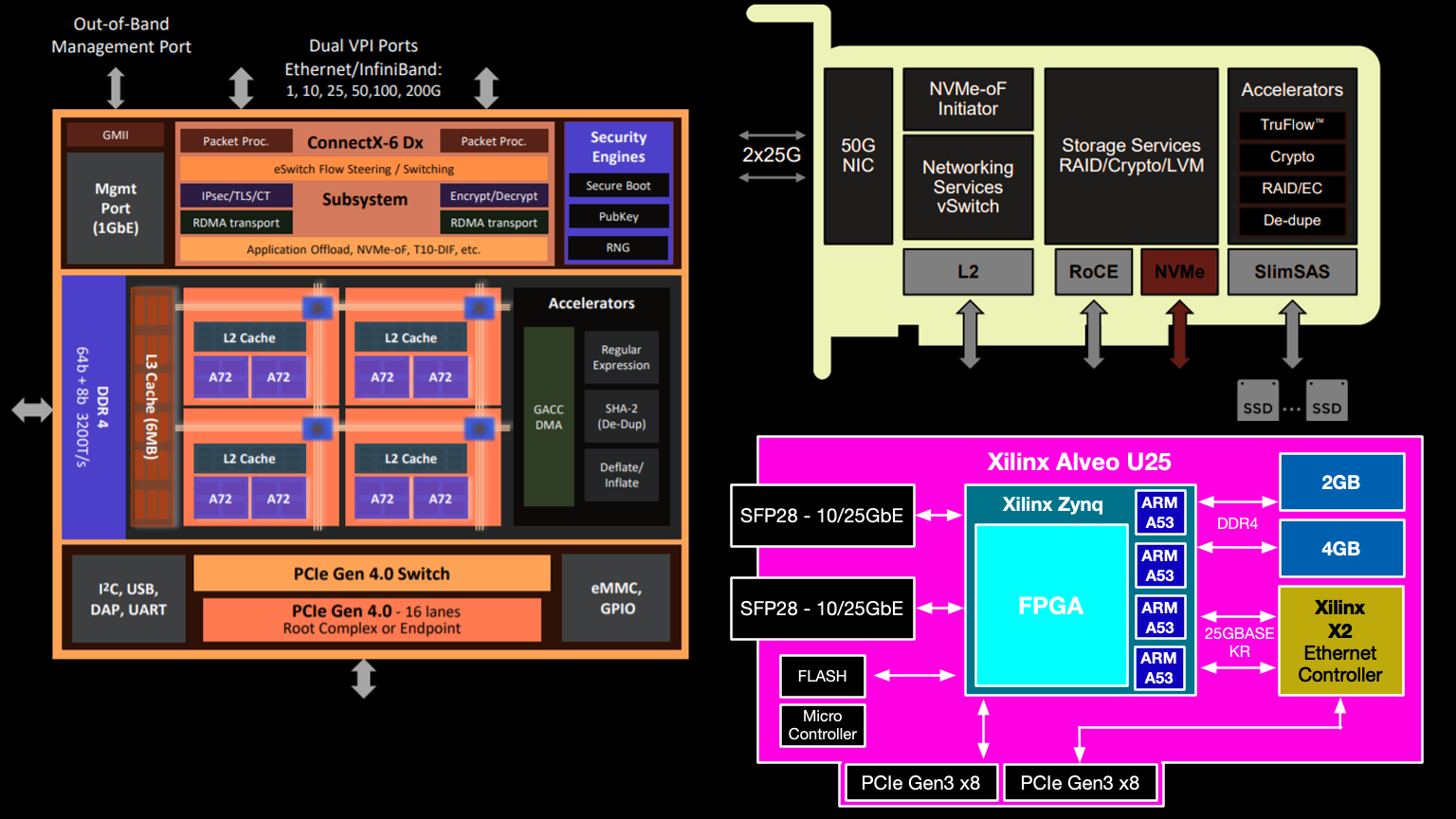
Les SmartNIC
schématiques Xilinx Alveo U25 ont souvent un noyau ARM séparé pour la couche de contrôle, certaines cartes permettent de charger un noyau Linux modifié. Ces cœurs ARM dédiés répartissent la charge sur le reste des modules de calcul, collectent des statistiques et des journaux, et surveillent l'état du SmartNIC. Le trafic réseau direct ne les traverse pas.
À quelles tâches les DPU conviennent-ils?
Les coprocesseurs de données (DPU) sont une extension typique des SmartNIC qui ajoutent la fonctionnalité NVMe ou NVMe over Fabrics (NVMe-oF). Une telle carte vous permet de décharger le processeur central, prenant en charge toutes les tâches d'E / S.
Par exemple, considérons le périphérique SmartNIC du microcontrôleur Broadcom NetXtreme-S BCM58800 . Il fonctionne comme une carte réseau programmable et prend en charge (NVMe-oF).
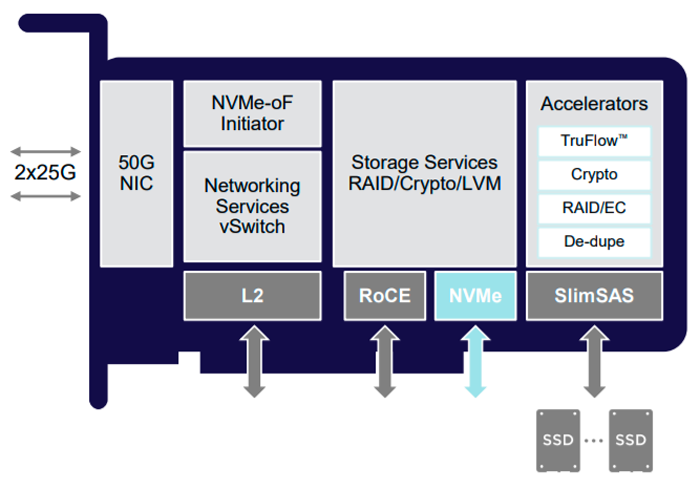
Architecture de la carte Broadcom Stingray basée sur le microcontrôleur BCM58800
Broadcom Stingray a huit cœurs ARM v8 A72 à 3 GHz, sans doute la vitesse d'horloge la plus élevée de tout ARM sur n'importe quel SmartNIC. La carte réseau est livrée avec jusqu'à 16 Go de mémoire DDR4. Le chiffrement jusqu'à 90 Gbps est pris en charge au niveau matériel et certaines fonctions de traitement des données sont prises en charge: la déduplication, qui supprime le codage de RAID 5 et RAID 6.
Le diagramme montre également l'accélérateur TruFlow. Il s'agit d'une technologie propriétaire de Broadcom pour l'accélération matérielle des opérations réseau, y compris Open vSwitch (OvS) et plus encore.
Nvidia BlueField 2
Nvidia s'est traditionnellement spécialisée dans les accélérateurs graphiques, mais cette année, elle a réalisé une acquisition de 7 milliards de dollars du fabricant de puces spécialisé Mellanox, elle cible désormais sérieusement un nouveau domaine du calcul haute performance des centres de données.
Mellanox est l'un des pionniers dans le développement de cartes réseau à puce, et la carte BlueField 2 , commercialisée sous le nom d'unité de traitement de données (DPU), est désormais considérée comme le produit phare . Applications principales du DPU de l'
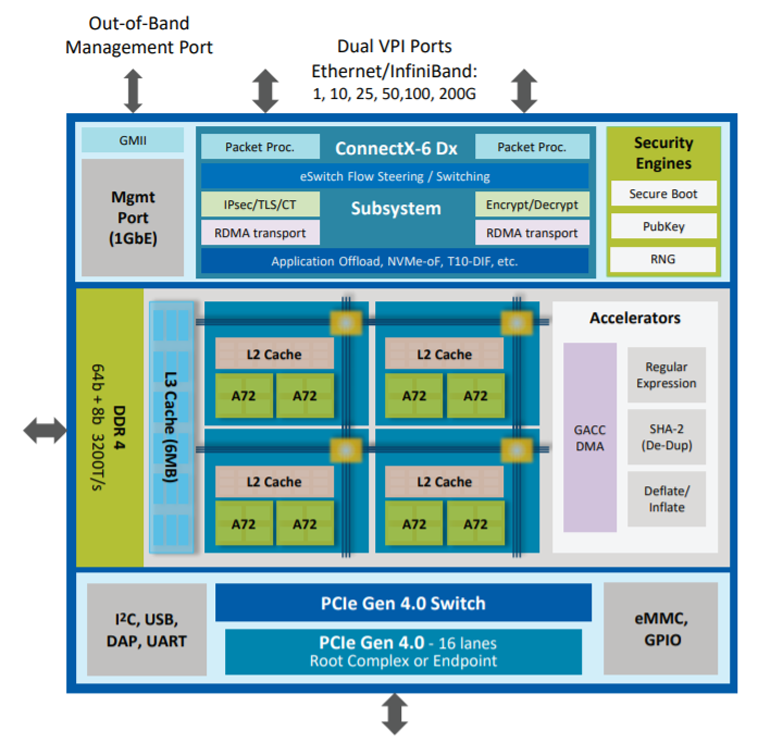
architecture Nvidia / Mellanox BlueField 2
:
- Clouds virtuels et matériels.
- Stockage NVMe dans les machines virtuelles.
- Applications de virtualisation des fonctions réseau (NFV).
- Applications de sécurité de l'information telles que Deep Packet Inspection (DPI).
- Microserveurs pour l'edge computing

Nvidia / Mellanox BlueField 2
Il comprend un tableau de huit cœurs ARM v8 A72, un contrôleur de mémoire DDR4 et un adaptateur réseau Ethernet ou InfiniBand à double port (deux à 100 Gbps ou un à 200 Gbps), ainsi que des ASIC spécialisés pour accélérer diverses fonctions: expressions régulières, hachage SHA-2, etc.
Pensando
L'une des nouvelles startups dans le domaine SmartNIC est Pensando, qui propose sur le marché la carte dite de services distribués, Pensando DSC-25 (pour les serveurs d'entreprise) et Pensando DSC-100 (pour les fournisseurs de cloud).

Pensando DSC-25 et Pensando DSC-100
Le produit principal est le Pensando DSC-25. Il s'agit d'une carte avec un DPU P4 (Capri) pour le traitement des données, des noyaux ARM supplémentaires et des accélérateurs matériels pour les fonctions sélectionnées.

Circuit Pensando DSC-25
Les principaux cœurs DPU et ARM sont connectés via un bus d'interconnexion commun à un contrôleur PCIe et à une matrice de RAM (jusqu'à 4 Go).
Les accélérateurs matériels individuels sont appelés ici décharges de traitement de service. Comme avec la carte Mellanox, ils gèrent le cryptage, le traitement du disque et d'autres tâches.
Fongible
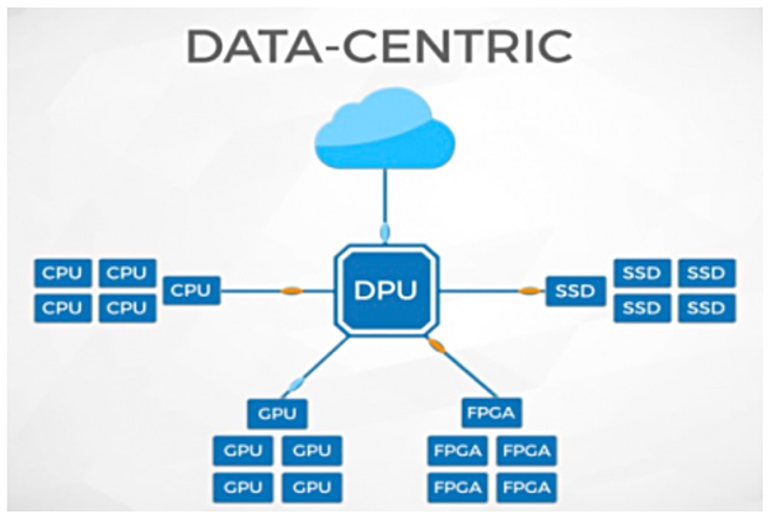
L'architecture de haut niveau de Fungible
Une autre start-up montante, Fungible, affirme avoir inventé le terme DPU en 2016. La société annonce un processeur appelé F1 DPU, mais l'architecture réelle de ces puces est inconnue. Fungible ne peut démontrer que des schémas généraux pour le moment, comme dans l'illustration ci-dessus. Certains experts ont exprimé leur soupçon que Fungible utilise simplement le terme hype DPU pour attirer des investissements en capital-risque. Soit dit en passant, 500 millions de dollars y ont déjà été investis à diverses reprises.
Et après?
Il y a eu beaucoup de battage médiatique autour du concept DPU ces derniers temps. Toutes les entreprises qui tentent de pénétrer ce marché (Intel, Xilinx et autres) ne sont pas mentionnées dans cette revue.
Le fait est que le concept SmartNIC existe depuis longtemps et que de grandes entreprises comme Google et Amazon ont développé et mis en œuvre leurs propres solutions internes. Dans le même temps, un marché a été formé, qui a été rempli par des acteurs tiers.
Le SmartNIC de deuxième génération basé sur FPGA fait son apparition. La technologie de réseau de portes programmables par l'utilisateur a mûri au point qu'elle peut désormais devenir la technologie de base des SmartNIC. Il y a dix ans, le marché était littéralement inondé d'accélérateurs graphiques - c'était la première vague significative de technologie d'accélération matérielle. Maintenant que les FPGA ont dépassé la barre des trois millions de blocs logiques, ces puces sont étroitement intégrées à d'autres blocs de construction pour gérer le trafic réseau, la mémoire, le stockage et les cœurs de calcul. Les technologies SmartNIC et FPGA se complètent parfaitement.
Dans ce contexte, on peut s'attendre à une deuxième vague d'accélérateurs matériels. Et puis un troisième élément sera ajouté à l'ensemble CPU + GPU - DPU. Le coprocesseur de données libérera les processeurs de serveur des tâches d'infrastructure. La recherche montre que dans les environnements hautement virtualisés, les processus réseau tels que les transactions OvS peuvent consommer plus de 30% du temps processeur de l'hôte. Imaginez les opérations de disque, le chiffrement, le DPI et le routage complexe effectués dans un module séparé. Cela supprimera potentiellement une partie importante de la charge du processeur.
Des startups comme Pensando et Fungible ont affronté des leaders technologiques comme Xilinx, Intel, Broadcom et Nvidia avec leurs innovations. Il s'agit d'une compétition technologique toujours agréable à regarder.