Attributs avec des méta-informations
Titre (attribut title)
Le titre décrit brièvement l'essence de la règle. Ce champ de texte peut contenir jusqu'à 256 caractères. Ici, vous devriez donner la description la plus courte et la plus vaste. Suivez ces directives:
- N'utilisez pas de constructions comme "Détecte ..." comme titre. Et sans cela, il est clair que la règle détecte quelque chose.
- Utilisez des titres volumineux ne dépassant pas 50 caractères.
- Écrivez toutes les explications et commentaires importants dans le champ de description (nous les examinerons plus loin).
Description détaillée et explications supplémentaires de la règle (attribut description)
Si le titre contient une brève description de la règle pour une compréhension générale de son objectif, dans le champ de description, vous pouvez spécifier toutes les nuances et fonctionnalités que l'auteur met dans cette règle. Il décrit également brièvement l'attaque qu'il est proposé de détecter à l'aide de cette règle. La longueur maximale de ce champ est de 65 535 caractères.
Identifiant unique de la règle et identifiants des règles associées (id, relatif)
Étant donné que les valeurs spécifiques des attributs title et description peuvent être arbitraires, y compris les mêmes pour deux règles différentes (ne le faites jamais), elles ne conviennent pas pour identifier de manière unique une règle. Un identifiant unique plus formel est nécessaire. L'identifiant universel unique (UUID) est utilisé dans la grande majorité des produits pour résoudre ce problème. Les auteurs de Sigma conseillent aux développeurs de règles de suivre le même chemin, cependant, tout schéma de génération d'identifiant peut être utilisé pour les règles privées. Dans le référentiel public, l'UUID susmentionné est sélectionné comme schéma de création d'identificateurs. Nous avons suivi la même approche dans l'exemple de règle dans la première partie de l'article. Si vous souhaitez publier votre règle à l'avenir ou envoyer une demande pour l'ajouter au référentiel officiel,alors nous vous conseillons de suivre le même schéma pour créer un identifiant de règle.
L'identifiant unique peut être généré de plusieurs manières, sous Windows, le moyen le plus simple consiste à exécuter le code PowerShell suivant:
PS C:\> "id: $(New-Guid)"
id: b2ddd389-f676-4ac4-845a-e00781a48e5fSur un système d'exploitation basé sur un noyau Linux, vous pouvez utiliser l'utilitaire uuidgen:
$ echo “id: `uuidgen`”
id: b2ddd389-f676-4ac4-845a-e00781a48e5fLors de modifications importantes d'une règle, son identifiant doit être modifié. Situations dans lesquelles créer un nouvel identifiant:
- changer la logique de la règle;
- héritage d'une règle d'une règle existante tout en préservant la règle d'origine (c'est également vrai pour la situation d'amélioration de la règle);
- fusion des règles.
Pour les cas d'héritage et de fusion de règles, il existe un identifiant spécial lié à quatre valeurs possibles du type (l'attribut type).
Considérons des situations hypothétiques dans lesquelles nous pourrions trouver utile d'utiliser l'identifiant associé. Pour plus de clarté, au lieu de longs identifiants au format UUID, nous écrirons simplement X, Y, Z.
Dans le premier cas, la nouvelle règle (id: X) est dérivée de l'existante (id: Y). Cela peut arriver si nous avons amélioré la logique de travail dans une nouvelle règle, mais pour une raison quelconque, nous voulons conserver l'ancienne règle. Ainsi, notre règle a une règle parent qui est enregistrée et peut être utilisée à l'avenir:

Le second cas est similaire au premier sauf pour un fait: l'ancienne règle n'est pas conservée. Autrement dit, nous avons réécrit la règle radicalement, et l'attribution d'un nouvel identifiant était nécessaire, et l'ancien est obsolète (obsolète) et ne sera plus utilisé. Nous avons donc eu une règle (id: Y) que nous avons réécrite, et nous avons décidé que nous n'en avions plus besoin. La nouvelle règle a reçu un identifiant (id: X). Dans la règle Sigma, une situation similaire ressemblera à ceci:

Dans le troisième cas, considérons une situation où une nouvelle règle est apparue à la suite de la fusion de deux ou plusieurs règles existantes. La nouvelle règle (id: X) est le résultat de la fusion de deux règles (id: Y, Z). Il est important de noter que les deux règles parentes impliquées dans la fusion sont conservées et peuvent être utilisées ultérieurement. Dans une règle Sigma, une situation similaire pourrait ressembler à ceci: bien

que l'ordre des règles ne soit pas défini lors de la fusion, nous les avons numérotées dans les commentaires pour plus de clarté.
Le quatrième type est renommer. Comme son nom l'indique, ce type d'association entre identifiants est appliqué lors du changement de nom d'une ancienne règle. En fait, ce type n'est pas utilisé dans la pratique. A titre d'exemple d'utilisation, les auteurs citent un cas de changement de schéma de création d'identifiants (on se souvient que l'UUID n'est pas le seul schéma de dénomination possible).
État prêt pour la règle (attribut d'état)
Selon la spécification, une règle peut être dans l'un des trois états suivants:
- stable - la règle peut être utilisée dans une infrastructure réelle pour détecter les attaques, aucune modification n'est requise;
- test - la règle est presque stable, mais un petit ajustement est nécessaire;
- expérimental - une telle règle peut générer un grand nombre de faux positifs, mais en même temps elle révèle des événements intéressants.
Habituellement, avant d'exécuter une règle sur une infrastructure réelle, la règle a le statut expérimental, car on ne sait pas encore exactement à quelle fréquence elle générera des erreurs. De plus, après plusieurs mois de test, si la règle est bien écrite et ne génère pas d'erreurs (ou s'il y en a des négligeables), elle est transférée dans la catégorie stable. Sinon, des corrections sont apportées et vérifiées à nouveau. Il n'y a pas de règles avec un statut de test dans le référentiel officiel Sigma.
La licence sous laquelle la règle est distribuée (l'attribut de licence)
La licence sous laquelle la règle est distribuée. Ce domaine est issu du monde du logiciel libre. Ce paramètre est rarement spécifié, mais s'il est spécifié, il doit être conforme à la spécification d'ID SPDX.
Créateurs de règles (attribut d'auteur)
Ce champ répertorie tous les auteurs de la règle. Il est considéré comme une bonne forme d'indiquer non seulement la personne qui a écrit la règle elle-même, mais également l'auteur de l'idée originale de détection.
Liens vers des études qui ont aidé à développer la règle (attribut références)
Lors de la rédaction des règles Sigma, il est habituel d'inclure des liens vers des articles originaux, des tweets et des recherches qui ont aidé ou inspiré la création de la règle. En plus d'exprimer du respect pour le travail de quelqu'un d'autre, ces liens aident plus tard à comprendre le fonctionnement de la règle.
Champs d'événement utiles pour afficher des analyses lorsqu'une règle est déclenchée (attribut fields)
Étant donné que l'auteur de la règle a une compréhension approfondie de l'algorithme d'attaque et des événements générés lors de son exécution, il peut sélectionner une liste de champs parmi les événements qui aideront l'opérateur SOC ou un autre employé de l'équipe de sécurité de l'information à comprendre l'incident.
Cas de faux positifs de la règle (attribut falsepositives)
Le champ falsepositives est plutôt inhabituel pour les règles de détection. Cela n'affecte en aucun cas le déroulement de la validation des événements, mais il fait deux choses utiles:
- Aidez l'utilisateur à déterminer si un déclencheur de règle donné est une erreur.
- Rappelez à nouveau au développeur de la règle que sa règle peut être déclenchée à tort. De telles pensées peuvent aider le développeur à rédiger une règle plus précise.
Diverses balises et balises (attribut balises)
En général, ce champ est utilisé pour les balises MITRE ATT & CK et CAR. Nous vous recommandons vivement de classer immédiatement votre règle, car un tel balisage vous permet d'intégrer des règles Sigma à d'autres projets de sécurité de l'information. Cependant, le format ne limite pas les auteurs des règles uniquement à de telles étiquettes, vous pouvez en mettre.
Collections de règles
Selon la norme YAML, un fichier (dans son flux terminologique) peut contenir plusieurs documents YAML. Ceci est réalisé grâce à la balise de document YAML - trois tirets («---»). Pour le format Sigma, ces documents peuvent être des règles Sigma indépendantes ou des documents d'action.
Dans le premier cas, tout est simple: un fichier contient des règles Sigma complètes qui séparés les uns des autres par une étiquette de document YAML (exemple rules / proxy / proxy_ursnif_malware.yml ) Le
deuxième cas est plus compliqué: un document YAML est traité comme un document d'action si l'attribut d'action de niveau supérieur a l'une des trois valeurs suivantes:
- global — , YAML- . action- . : , Sigma- ;
- reset — , action-;
- repeat — repeat .
Remarque : l'attribut d'action peut apparaître n'importe où dans la règle.
Le cas d'utilisation le plus courant pour une collection de règles consiste à définir plusieurs règles Sigma pour des événements similaires, tels que l'ID d'événement de sécurité Windows 4688 et l'ID d'événement Sysmon 1. Les deux événements apparaissent à la suite de la création de processus, ils ont juste des sources différentes. La collection de règles Sigma pour un scénario donné peut contenir trois documents d'action:
- Un document d'action global qui définit les champs de métadonnées et les indicateurs de détection communs.
- Règle qui définit la source du journal des événements de sécurité Windows et de l'événement EventID = 4688.
- Une règle qui définit la source du journal des événements Windows Sysmon et de l'événement EventID = 1.
Une solution alternative pourrait être:
- Un document d'action global qui définit les champs de métadonnées communs.
- Windows Security Event Log ( EventID=4688) .
- Action- repeat, logsource EventID , . 2.
action-
Dans cette section, nous détaillerons exactement comment Sigma génère des règles récapitulatives basées sur les valeurs de l'attribut action. Les documents YAML qui contiennent un attribut d'action avec la valeur global sont considérés comme des documents globaux dans ce fichier, et leurs champs seront ajoutés à tous les autres documents.
Remarque : si le document actuel contient l'attribut action avec la valeur de réinitialisation, les champs de document global ne lui seront pas ajoutés.
La logique de travail avec des documents globaux est la suivante: dès que l'analyseur rencontre un document global (un document qui contient un attribut d'action avec la valeur globale), il ajoute ses champs à un tampon spécial et passe au document suivant. Appelons ce tampon spécial GLOBALYAML, cela aidera à l'avenir de s'y référer dans les diagrammes.
Important: Les limites du document étant définies par la marque «---», il est important de placer correctement ces marques dans le fichier.
Dans l'exemple ci-dessous, le premier document YAML contient un attribut d'action avec la valeur global. Les limites de ce document s'étendent jusqu'à la première marque de document. Ainsi, le premier document entier est écrit dans le tampon global. Les champs de ce tampon sont ensuite ajoutés à chaque document suivant. En conséquence, nous obtenons deux règles en sortie. Schéma 1. Traitement d'une règle simple avec la définition correcte des étiquettes de document YAML Mais si vous supprimez ou oubliez la première étiquette, alors tous les champs de YAML DOCUMENT 2 seront inclus dans le document global. En conséquence, nous n'obtenons qu'une seule règle avec un ensemble incorrect d'identificateurs de recherche en sortie. Par conséquent, il est très important d'étiqueter correctement les documents YAML dans de telles règles composées.
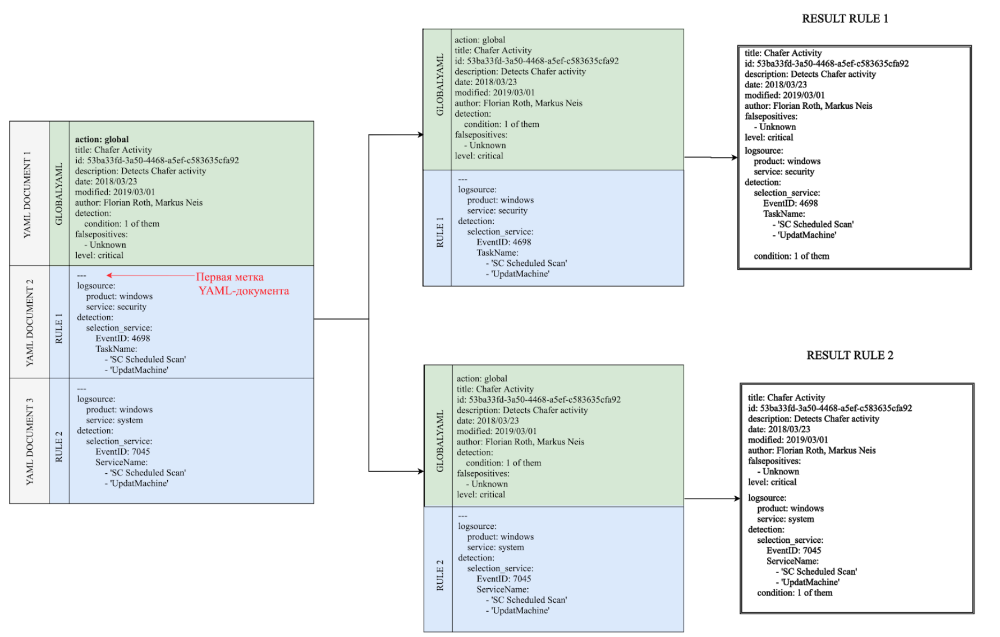

Schéma 2. Traitement de la règle précédente - si vous oubliez de mettre la première étiquette du document YAML
Il faut noter que le document global ne vient pas forcément au début. Si vous regardez les deux schémas précédents, alors ce n'est pas toujours YAML DOCUMENT 1. De plus, il n'est pas nécessaire qu'il soit au singulier. Le diagramme suivant illustre cela clairement. Schéma 3. Traitement d'une règle contenant diverses options pour spécifier un document YAML global Nous avons donc examiné les problèmes liés au placement correct des balises dans un document YAML. Nous avons également vu que vous pouvez définir le document YAML global de différentes manières en utilisant l'attribut action avec la valeur globale. Ensuite, examinons le schéma de transformation d'une règle en utilisant les deux valeurs restantes de l'attribut action - réinitialiser et répéter.


Schéma 4. Traitement d'une règle contenant les attributs d'action avec les valeurs de réinitialisation et de répétition
Que dire d'autre du projet Sigma
Sigma n'est pas seulement un ensemble de règles formatées que nous avons couvertes dans cette série.
Dans nos publications, nous nous sommes concentrés sur la description du format et de la syntaxe des règles. Mais les règles ne représentent que la moitié du projet, la seconde concerne les backends utilisés par le convertisseur sigmac. Classiquement, ces convertisseurs peuvent être considérés comme des "adaptateurs" avec une entrée universelle et une sortie spécifique. C'est la présence de tels «adaptateurs» qui rend le format de description universel si utile. Dans cette situation, peu importe le système pris en charge que vous utilisez, Sigma vous permet de décrire l'idée et l'algorithme de détection, tandis que l'un ou l'autre backend du convertisseur sigmac est responsable de la syntaxe spécifique du système cible et du mappage des champs.
Cependant, ne supposez pas qu'en téléchargeant les règles et en les convertissant dans la syntaxe du système cible requis, vous résoudrez tous les problèmes associés au remplissage de votre système avec l'expertise. Nous expliquerons brièvement pourquoi Sigma n'est pas une solution prête à l'emploi pour le moment, et pourquoi il est nécessaire de comprendre la syntaxe des règles.
Défis Sigma actuels
Sigma est un projet en développement actif, et comme tout projet en croissance, Sigma a ses propres défis. Personnellement, je les perçois comme des points de développement et des axes de croissance. Eh bien, puisqu'il s'agit d'un projet open source, unir nos forces peut apporter une contribution significative au développement de certaines parties du projet. Je vais énumérer ce à quoi je me réfère pour le moment aux principaux appels du framework:
- . .
- , Windows- (. ). , .
- Wiki , . .
- experimental — , .
- .
- , .
D'après ma propre expérience, je dirai que lorsque je me suis familiarisé avec le projet Sigma et que j'ai participé à OSCD, le premier élément de la liste s'est avéré être le plus important. Il s'est avéré que les différences entre la syntaxe de MaxPatrol SIEM et de Sigma ne s'arrêtent pas uniquement à la sémantique des mots-clés et à la conception des règles de corrélation. Certaines de nos idées ne peuvent être décrites en termes de syntaxe Sigma, car à ce stade, il n'y a aucune possibilité de corrélation d'événements. Le mécanisme de corrélation vous permet de rechercher des valeurs communes des champs d'événement et de relier ces événements les uns aux autres. Ceci est utile lorsque nous voulons établir avec précision la relation entre les événements. Par exemple, pour suivre les événements dans une session utilisateur. Pour ce faire, vous devez lier les événements par la valeur du champ LogonID ou son équivalent.
Il convient de noter que les détections ponctuelles ou les détections basées sur des événements non directement liés sont décrites avec beaucoup de succès à l'aide de Sigma.
Une façon d'aider à résoudre ces problèmes et d'autres est de participer activement à l'un des Sprints OSCD. Et comme il y a beaucoup de tâches, chacun pourra trouver ce qui l'intéresse.
Nouveau sprint à venir, rejoignez-nous!
Nous exprimons notre gratitude aux organisateurs du premier sprint pour le déroulement de grande qualité de l'événement et l'attitude attentive envers les participants. Quelles sont les seules cartes postales personnalisées remplies à la main et envoyées à chaque participant! Pour notre part, nous prévoyons de continuer à participer à de nouveaux sprints et d'apporter une contribution réalisable au référentiel Sigma.
Après avoir lu notre série d'articles et vous être familiarisé avec le format des règles, vous pourrez mettre votre expertise au service de l'ensemble de la communauté de la sécurité de l'information.
Assurez-vous de rejoindre le deuxième sprint. Participez individuellement et rassemblez des équipes, rendons le monde plus sûr ensemble!
Contacts de l'Initiative OSCD:
Auteur : Anton Kutepov, spécialiste du département des services experts et du développement des technologies positives (PT Expert Security Center)