
Grands problèmes de texture
L'idée de rendre des textures géantes n'est pas nouvelle en soi. Il semblerait que ce qui pourrait être plus facile - charger une énorme texture d'un million de mégapixels et dessiner un objet avec. Mais, comme toujours, il y a des nuances:
- Les API graphiques limitent la taille maximale d'une texture en largeur et en hauteur. Cela peut dépendre à la fois du matériel et des pilotes. La taille maximale pour aujourd'hui est de 32768x32768 pixels.
- Même si nous sommes dans ces limites, la texture RGBA 32768x32768 prendra 4 gigaoctets de mémoire vidéo. La mémoire vidéo est rapide, repose sur un bus large, mais est relativement chère. Par conséquent, il est généralement inférieur à la mémoire système et bien inférieur à la mémoire disque.
1. Rendu moderne de grandes textures
Comme l'image ne rentre pas dans les limites, une solution se suggère naturellement - il suffit de la casser en morceaux (tuiles):

diverses variantes de cette approche sont encore utilisées pour la géométrie analytique. Ce n'est pas une approche universelle; cela nécessite des calculs non triviaux sur le processeur. Chaque tuile est dessinée comme un objet séparé, ce qui ajoute une surcharge et exclut la possibilité d'appliquer un filtrage de texture bilinéaire (il y aura une ligne visible entre les limites de tuiles). Cependant, la limitation de la taille de la texture peut être contournée par des tableaux de texture! Oui, cette texture a encore une largeur et une hauteur limitées, mais des couches supplémentaires sont apparues. Le nombre de couches est également limité, mais vous pouvez compter sur 2048, bien que la spécification du volcan ne promette que 256. Sur une carte vidéo 1060 GTX, vous pouvez créer une texture contenant 32768 * 32768 * 2048 pixels. Il ne sera tout simplement pas possible de le créer, car il prend 8 téraoctets et il n'y a pas beaucoup de mémoire vidéo. Si vous lui appliquez le bloc de compression matérielle BC1 , une telle texture n'occuperait "que" 1 téraoctet. Il ne rentrera toujours pas dans une carte vidéo, mais je vous dirai quoi en faire plus loin.
Donc, nous coupons toujours l'image originale en morceaux. Mais maintenant, ce ne sera pas une texture distincte pour chaque tuile, mais juste un morceau à l'intérieur d'un énorme tableau de texture contenant toutes les tuiles. Chaque pièce a son propre index, toutes les pièces sont disposées séquentiellement. D'abord par colonnes, puis par lignes, puis par couches:
Une petite digression sur les sources de la texture de test
Par exemple - j'ai pris une image de la terre d'ici . J'ai augmenté sa taille d'origine de 43200x2160 à 65536x32768. Ceci, bien sûr, n'a pas ajouté de détails, mais j'ai obtenu l'image dont j'avais besoin, qui ne rentre pas dans une couche de texture. Ensuite, je l'ai réduit de moitié de manière récursive avec un filtrage bilinéaire jusqu'à obtenir une tuile de 512 par 256 pixels. Ensuite, j'ai battu les couches résultantes en 512x256 tuiles. Les a compressés BC1 et les a écrits séquentiellement dans un fichier. Quelque chose comme ceci:
En conséquence, nous avons obtenu un fichier de 1 431 633 920 octets, composé de 21845 tuiles. La taille 512 par 256 n'est pas aléatoire. Une image compressée de 512 x 256 BC1 fait exactement 65536 octets, ce qui correspond à la taille de bloc de l'image clairsemée - le héros de cet article. La taille de la tuile n'est pas importante pour le rendu.
Description de la technique de peinture de grandes textures
Nous avons donc chargé un tableau de textures dans lequel les tuiles sont séquentiellement disposées en colonnes / lignes / couches.
Ensuite, le shader qui dessine cette texture même peut ressembler à ceci:
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
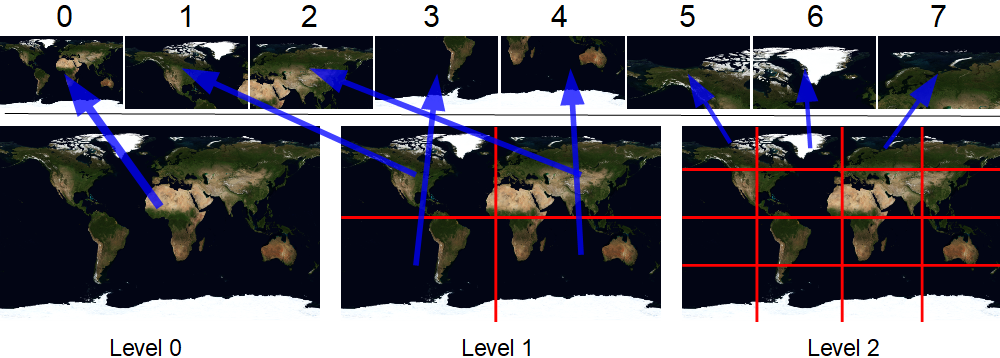
Jetons un coup d'œil à ce shader. Tout d'abord, nous devons déterminer le niveau de détail à choisir. La merveilleuse fonction dFdx nous y aidera . Pour simplifier grandement, il renvoie la valeur par laquelle l'attribut passé est plus grand dans le pixel voisin. Dans la démo, je dessine un rectangle plat avec des coordonnées de texture dans la plage 0..1. Lorsque ce rectangle a une largeur de X pixels, dFdx (v_uv.x) renverra 1 / X. Ainsi, la tuile du premier niveau tombera pixel à pixel avec dFdx == 1/512. Le deuxième au 1/1024, le troisième au 1/2048, etc. Le niveau de détail lui-même peut être calculé comme suit: log2 (1.0f / (512.0f * dFdx (v_uv.x))). Coupons-en la partie fractionnaire. Ensuite, nous comptons le nombre de tuiles en largeur / hauteur dans le niveau.
Considérons le calcul du reste à l'aide d'un exemple:

ici lod = 2, u = 0,65, v = 0,37
puisque lod est égal à deux, alors cellsSize est égal à quatre. L'image montre que ce niveau se compose de 16 tuiles (4 lignes 4 colonnes) - tout est correct.
tX = int (0,65 * 4) = int (2,6) = 2
tY = int (0,37 * 4) = int (1,48) = 1
soit à l'intérieur du niveau, cette tuile est sur la troisième colonne et la deuxième ligne (indexation à partir de zéro).
Nous avons également besoin des coordonnées locales du fragment (flèches jaunes sur l'image). Ils peuvent être facilement calculés en multipliant simplement les coordonnées de texture d'origine par le nombre de cellules dans une ligne / colonne et en prenant la partie fractionnaire. Dans les calculs ci-dessus, ils sont déjà là - 0,6 et 0,48.
Nous avons maintenant besoin d'un index global pour cette tuile. Pour cela, j'utilise le tableau précalculé lodBase. Dans celui-ci, par index, les valeurs du nombre de tuiles présentes dans tous les niveaux précédents (plus petits) sont stockées. Ajoutez-y l'index local de la tuile à l'intérieur du niveau. Par exemple, il s'avère que lodBase [2] + 1 * 4 + 2 = 5 + 4 + 2 = 11. Ce qui est également correct.
Connaissant l'index global, nous devons maintenant trouver les coordonnées de la tuile dans notre tableau de texture. Pour ce faire, nous devons savoir combien de carreaux nous avons en largeur et en hauteur. Leur produit est le nombre de carreaux qui entrent dans la couche. Dans cet exemple, j'ai cousu ces constantes directement dans le code du shader, pour plus de simplicité. Ensuite, nous obtenons les coordonnées de texture et lisons le texel à partir d'elles. Notez que sampler2DArray est utilisé comme échantillonneur . Par conséquent, texelFetch nous passons un vecteur à trois composants, dans la troisième coordonnée - le numéro de couche.
Textures pas complètement chargées (images de résidence partielle)
Comme je l'ai écrit ci-dessus, les textures énormes consomment beaucoup de mémoire vidéo. De plus, un très petit nombre de pixels sont utilisés à partir de cette texture. La solution au problème - Les textures de résidence partielle sont apparues en 2011. Son essence est en bref - la tuile peut ne pas être physiquement en mémoire! En même temps, la spécification garantit que l'application ne plante pas et toutes les implémentations connues garantissent que des zéros sont renvoyés. En outre, la spécification garantit que si l'extension est prise en charge, alors la taille de bloc garantie en octets est prise en charge - 64 Ko. Les résolutions des blocs de construction dans la texture sont liées à cette taille:
| TAILLE TEXEL (bits) | Forme de bloc (2D) | Forme de bloc (3D) |
|---|---|---|
| ? 4 bits? | ? 512 × 256 × 1 | pas de support |
| 8 bits | 256 × 256 × 1 | 64 × 32 × 32 |
| 16 bits | 256 × 128 × 1 | 32 × 32 × 32 |
| 32 bits | 128 × 128 × 1 | 32 × 32 × 16 |
| 64 bits | 128 × 64 × 1 | 32 × 16 × 16 |
| 128 bits | 64 × 64 × 1 | 16 × 16 × 16 |
En fait, il n'y a rien dans la spécification sur les texels 4 bits, mais nous pouvons toujours les découvrir en utilisant vkGetPhysicalDeviceSparseImageFormatProperties .
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
La création d'une telle texture clairsemée est différente de celle habituelle.
Tout d'abord dans VkImageCreateInfo dans les indicateurs doivent être spécifiés VK_IMAGE_CREATE_SPARSE_BINDING_BIT et VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT
Deuxièmement, la liaison via la mémoire vkBindImageMemory n'est pas nécessaire.
Vous devez savoir quels types de mémoire peuvent être utilisés via vkGetImageMemoryRequirements . Il vous indiquera également la quantité de mémoire nécessaire pour charger la texture entière, mais nous n'avons pas besoin de ce chiffre.
Au lieu de cela, nous devons décider au niveau de l'application, combien de tuiles peuvent être visibles simultanément?
Après avoir chargé certaines tuiles, d'autres seront déchargées, car elles ne sont plus nécessaires. Dans la démo, j'ai juste pointé mon doigt vers le ciel et alloué de la mémoire pour mille vingt quatre tuiles. Cela semble inutile, mais ce n'est que 50 mégaoctets contre 1,4 Go d'une texture entièrement chargée. Vous devez également allouer de la mémoire sur l'hôte, pour la mise en scène - un tampon.
const int sparseBlockSize = 65536;
int numHotPages = 512; //
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); // memoryTypeBits. -
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
De cette façon, nous aurons une énorme texture dans laquelle seules certaines parties sont chargées. Cela ressemblera à quelque chose comme ceci:

Gestion des tuiles
Dans ce qui suit, j'utiliserai le terme tuile pour désigner un morceau de texture (carrés vert foncé et gris sur la figure) et le terme page pour désigner un morceau dans un grand bloc pré-alloué en mémoire vidéo (rectangles vert clair et bleu clair sur la figure).
Après avoir créé un tel VkImage clairsemé , il peut être utilisé via VkImageView dans le shader. Bien sûr, ce sera inutile - l'échantillonnage renverra des zéros, il n'y a pas de données, mais contrairement à la VkImage habituelle , rien ne tombera et les couches de débogage ne jureront pas. Les données de cette texture devront être non seulement chargées, mais également déchargées, car nous économisons la mémoire vidéo.
L'approche OpenGL, qui prévoit l'allocation de mémoire par le pilote pour chaque bloc, ne me semble pas correcte. Oui, peut-être qu'un allocateur intelligent et rapide y est utilisé, car la taille du bloc est fixe. Ceci est suggéré par le fait qu'une approche similaire est utilisée dans l' exemple des textures de résidence clairsemées dans un volcan. Mais dans tous les cas, sélectionnez un grand bloc linéaire de pages et, côté application, liez ces pages à des carreaux de texture spécifiques et remplissez-les de données ne sera certainement pas plus lent.
Ainsi, l'interface de notre texture éparse comprendra des méthodes comme:
void CommitTile(int tileID, void* dataPtr); // 64
void FreeTile(int tileID);
void Flush();
La dernière méthode est nécessaire pour regrouper le remplissage / la libération des tuiles. La mise à jour des tuiles une à la fois coûte assez cher, une seule fois par image. Regardons-les dans l'ordre.
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
Tout d'abord, nous devons trouver un bloc gratuit. Je viens de parcourir le tableau de ces mêmes pages et cherche la première, qui contient le numéro de stub -1. Ce sera l'index de la page gratuite. Je copie les données du disque vers le tampon de préparation en utilisant memcpy. La source est un fichier mappé en mémoire avec un décalage pour une tuile spécifique. De plus, par l'ID de la tuile, je considère sa position (x, y, couche) dans le tableau de texture.
Ensuite, la partie la plus intéressante commence - remplir la structure VkSparseImageMemoryBind . C'est elle qui lie la mémoire vidéo à la tuile. Ses domaines importants sont: la
mémoire . Il s'agit d'un objet VkDeviceMemory . Il a pré-alloué de la mémoire pour toutes les pages.
memoryOffset . C'est le décalage en octets par rapport à la page dont nous avons besoin.
Ensuite, nous devrons copier les données du tampon de transfert dans cette mémoire fraîchement liée. Ceci est fait en utilisant vkCmdCopyBufferToImage .
Comme nous allons copier plusieurs sections à la fois, à cet endroit, nous ne remplissons que la structure, avec une description de l'endroit et de l'endroit où nous allons copier. Ici, bufferOffset est important , ce qui indique le décalage déjà dans le tampon de transfert . Dans ce cas, il coïncide avec le décalage dans la mémoire vidéo, mais les stratégies peuvent être différentes. Par exemple, divisez les carreaux en chaud, chaud et froid. Les chauds sont dans la mémoire vidéo, les chauds sont dans la mémoire opérationnelle et les froids sont sur le disque. Ensuite, le tampon de transfert peut être plus grand et le décalage sera différent.
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
C'est là que nous découplons la mémoire de la tuile. Pour ce faire, affectez la mémoire VK_NULL_HANDLE .
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
Le travail principal se déroule dans cette méthode. Au moment de son appel, nous avons déjà deux tableaux avec VkSparseImageMemoryBind et VkBufferImageCopy. Nous remplissons les structures pour appeler vkQueueBindSparse et l'appelons. Ce n'est pas une fonction de blocage (comme presque toutes les fonctions de Vulkan), nous devrons donc attendre explicitement son exécution. Pour cela, le dernier paramètre lui est passé VkFence , dont nous attendrons l'exécution. En fait, dans mon cas, attendre cette fenza n'affectait en rien les performances du programme. Mais, en théorie, c'est nécessaire ici.
Après avoir attaché de la mémoire aux tuiles, nous devons y ajouter des images. Cela se fait avec la fonction vkCmdCopyBufferToImage .
Vous pouvez remplir les données dans la texture avec mise en pageVK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL , et obtenez-les dans un shader avec la disposition VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL . Par conséquent, nous avons besoin de deux barrières. Veuillez noter que dans VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, noustraduisons strictement à partir de VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL , et non de VK_IMAGE_LAYOUT_UNDEFINED . Puisque nous ne remplissons qu'une partie de la texture, il est important pour nous de ne pas perdre les parties de celle-ci qui ont été remplies plus tôt.
Voici une vidéo de son fonctionnement. Une texture. Un objet. Des dizaines de milliers de carreaux.
Ce qui reste dans les coulisses est de savoir comment déterminer dans l'application comment trouver réellement quelle tuile il est temps de charger et laquelle décharger. Dans la section décrivant les avantages de la nouvelle approche, l'un des points était que vous pouvez utiliser une géométrie complexe. Dans le même test, j'utilise moi-même la projection orthographique et le rectangle les plus simples. Et je compte analytiquement l'identifiant des tuiles. Anti-sportif.
En fait, les identifiants des tuiles visibles sont comptés deux fois. Analytiquement sur le CPU et honnêtement sur le fragment shader. Il semblerait, pourquoi ne pas les récupérer dans le fragment shader? Mais ce n’est pas si simple. Ce sera le deuxième article.