Il ne s’agit pas d’une analyse systématique ni d’un tableau. Une vision individuelle, également du point de vue d'un géophysicien. Mais je suis toujours curieux de lire Gartner MQ, ils formulent parfaitement certains points. Il y a donc des choses auxquelles j'ai prêté attention à la fois sur le plan technique, sur le marché et sur le plan philosophique.
Ce n'est pas pour les personnes qui s'intéressent profondément au ML, mais pour les personnes qui s'intéressent à ce qui se passe généralement sur le marché.
Le marché DSML lui-même s'imbrique logiquement entre les services de développement BI et Cloud AI.
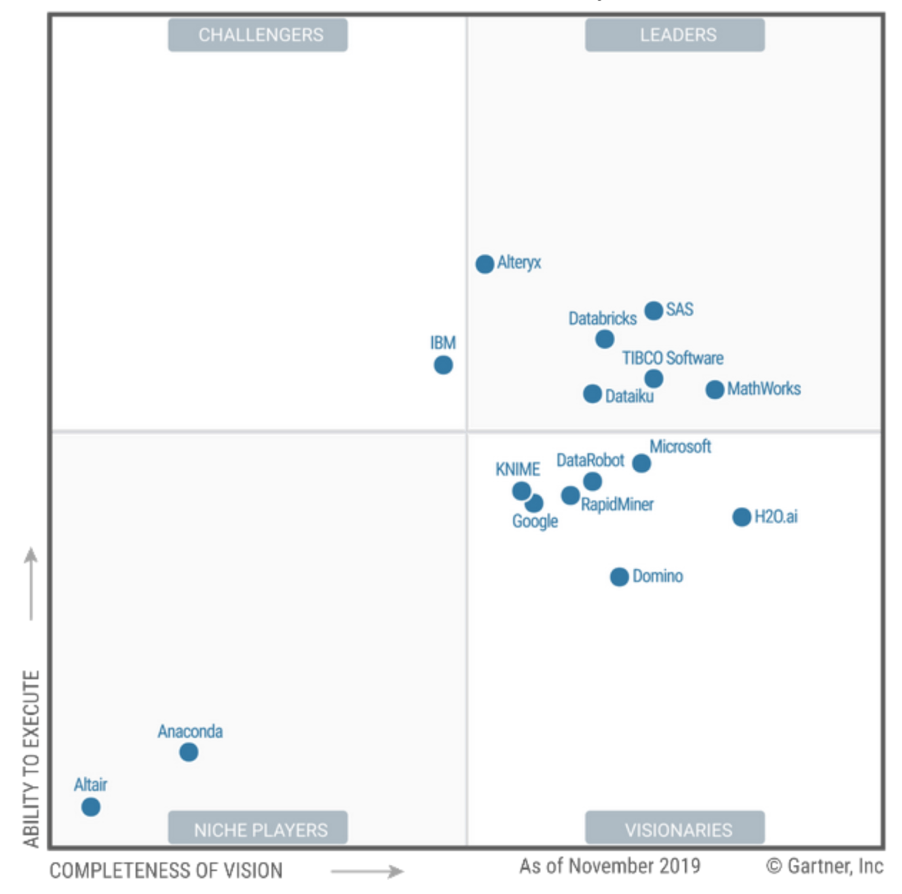
J'ai aimé les premières citations et termes:
- «Un leader n'est peut-être pas le meilleur choix» - Le leader du marché n'est pas nécessairement ce dont vous avez besoin. Très urgent! En raison du manque de client fonctionnel, ils sont toujours à la recherche de la «meilleure» solution, pas de la «adaptée».
- L'opérationnalisation du modèle est abrégée en MOP. Et les carlins sont difficiles pour tout le monde! - (le thème du carlin cool fait fonctionner le modèle).
- L'environnement Notebook est un concept important où le code, les commentaires, les données et les résultats sont rassemblés. Ceci est très clair, prometteur et peut réduire considérablement la quantité de code d'interface utilisateur.
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- «Reproductibilité» - préservation maximale de tous les paramètres de l'environnement, entrées et sorties, de sorte que vous puissiez répéter l'expérience une fois réalisée. Le terme le plus important pour un environnement de test expérimental!
Alors:
Alteryx
L'interface sympa n'est qu'un jouet. L'évolutivité, bien sûr, est un peu serrée. En conséquence, la communauté citoyenne d'ingénieurs autour de la même chose avec tsatski à jouer. Analytics a son propre tout dans une bouteille. Cela m'a rappelé le complexe d' analyse des données de corrélation spectrale Coscad qui a été programmé dans les années 90.
Anaconda
Une communauté autour d'experts Python et R. L'open source est important, respectivement. Il s'est avéré que mes collègues l'utilisent constamment. Je ne savais pas.
DataBricks
Se compose de trois projets open source - Les développeurs Spark ont collecté énormément d'argent depuis 2013. Je dois lire le wiki directement:
«En septembre 2013, Databricks a annoncé avoir levé 13,9 millions de dollars auprès d'Andreessen Horowitz. La société a levé 33 millions de dollars supplémentaires en 2014, 60 millions de dollars en 2016, 140 millions de dollars en 2017, 250 millions de dollars en 2019 (février) et 400 millions de dollars en 2019 (octobre) »!!!Certaines personnes formidables Spark ont scié. Pas familier désolé!
Et les projets sont:
- Delta Lake - ACID on Spark est sorti récemment (ce dont nous rêvions avec Elasticsearch) - il le transforme en base de données: un schéma rigide, ACID, audit, versions ...
- ML Flow - suivi des modèles, emballage, gestion et stockage.
- Koalas - API Pandas DataFrame sur Spark - Pandas - API Python pour travailler avec des tables et des données en général.
Vous pouvez voir à propos de Spark, qui soudain ne sait pas ou a oublié: lien . Vidosiki a regardé avec des exemples de pics de consultation un peu ennuyeux mais détaillés: DataBricks pour la science des données ( lien ) et pour l'ingénierie des données ( lien ).
En bref, Databricks sort Spark. Qui veut utiliser Spark normalement dans le cloud prend DataBricks sans hésitation, comme prévu :) Spark est le principal différenciateur ici.
J'ai découvert que Spark Streaming n'est pas un vrai faux temps réel ou microbatching. Et si vous avez besoin de temps réel réel, c'est dans Apache STORM. Tout le monde dit et écrit que Spark est plus cool que MapReduce. Le slogan est le suivant.
DATAIKU
Cool chose de bout en bout. Il y a beaucoup de publicité. Vous ne comprenez pas en quoi il diffère d'Alteryx?
DataRobot
Paxata pour la préparation des données est cool est une société distincte qui a été achetée par Data Robots en décembre 2019. Levé 20 MUSD et vendu. Tout en 7 ans.
Préparation des données dans Paxata, pas Excel - voir ici: lien .
Il existe des spoofs automatiques et des propositions de jointure entre deux ensembles de données. Une bonne chose - pour trier les données, encore plus l'accent sur les informations textuelles ( lien ).
Le catalogue de données est un excellent catalogue d'ensembles de données «en direct» dont personne n'a besoin.
La formation des répertoires dans Paxata est également intéressante ( lien ).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
Le produit principal de Data Robot est ici . Leur slogan va du modèle à l'application d'entreprise! Découverte du conseil pour l'industrie pétrolière en lien avec la crise, mais très banal et sans intérêt: lien . Regardé leurs vidéos sur Mops ou MLops ( lien ). Il s'agit d'un Frankenstein composé de 6-7 acquisitions de divers produits.
Bien sûr, il devient clair qu'une grande équipe de Data Scientists devrait disposer d'un tel environnement pour travailler avec des modèles, sinon ils en produiront beaucoup et ne déploieront jamais rien. Et dans notre réalité pétrolière et gazière en amont - un modèle pourrait être créé avec succès et c'est déjà un grand progrès!
Le processus lui-même rappelait beaucoup le travail des systèmes de conception en géologie-géophysique, par exemple, Petrel... Tous et divers font et modifient des modèles. Collectez des données dans le modèle. Ensuite, ils ont fabriqué un modèle de référence et l'ont mis en production! Il existe de nombreuses similitudes entre, par exemple, un modèle géologique et un modèle ML.
Domino
Accent sur la plateforme ouverte et la collaboration. Les utilisateurs professionnels sont autorisés à entrer gratuitement. Leur Data Lab ressemble fortement à un Sharepoint. (Et du nom donne fortement IBM). Toutes les expériences sont liées à l'ensemble de données d'origine. Comme c'est familier :) Comme dans notre pratique - certaines données ont été glissées dans le modèle, puis elles ont été nettoyées et mises en ordre dans le modèle, et tout cela existe déjà dans le modèle et vous ne pouvez pas trouver les extrémités dans les données initiales.
Domino a une virtualisation d'infrastructure cool. J'ai assemblé la machine autant de cœurs par seconde et je suis allé compter. Comment cela a été fait n'est pas tout à fait clair tout de suite. Docker partout. Beaucoup de liberté! Tous les espaces de travail des dernières versions peuvent être connectés. Faites des expériences en parallèle. Suivi et sélection des succès.
Identique à DataRobot - les résultats sont publiés pour les utilisateurs professionnels sous la forme d'applications. Pour les «parties prenantes» particulièrement douées. Et l'utilisation réelle des modèles est également surveillée. Tout pour les Pugs!
Je ne comprenais pas complètement comment les modèles complexes entraient en production. Certaines API sont fournies pour les alimenter en données et obtenir des résultats.
H2O
Driveless AI est un système très compact et simple pour le ML supervisé. Tout dans une seule boîte. Ce n'est pas clair sur le backend tout de suite.
Le modèle est automatiquement intégré dans un serveur REST ou une application Java. C'est une bonne idée. Beaucoup a été fait pour l'interprétabilité et l'explicabilité. Interprétation et explication des résultats de l'opération du modèle (Qu'est-ce qui, dans son essence, ne devrait pas être explicable, sinon une personne peut calculer la même chose?).
Pour la première fois, une étude de cas sur les données non structurées et la PNL est examinée en détail . Image architecturale de haute qualité. En général, j'ai aimé les images.
Il existe un grand framework H2O open source qui n'est pas tout à fait clair (un ensemble d'algorithmes / bibliothèques?). Posséder un ordinateur portable visuel sans programmation comme Jupiter ( lien). J'ai aussi lu sur les modèles Pojo et Mojo - H2O enveloppés dans la réalité. Le premier est sur le front, le second est optimisé. H20 sont les seuls (!) À qui Gartner a écrit l'analyse de texte et la PNL dans leurs forces, ainsi que leurs efforts d'explicabilité. Il est très important!
Ibid: Norme de haute performance, d'optimisation et de l'industrie pour l'intégration du fer et du cloud.
Et c'est logique dans la faiblesse - Driverles AI est faible et étroit par rapport à leur propre open source. La préparation des données est boiteuse par rapport à la même Paxata! Et ignorez les données industrielles - flux, graphiques, géo. Eh bien, tout ne peut pas être bien.
KNIME
J'ai aimé 6 cas d'affaires très spécifiques très intéressants sur la page d'accueil. OpenSource fort.
Gartner est passé de leader à visionnaire. Gagner de l'argent médiocrement est un bon signe pour les utilisateurs, étant donné que Leader n'est pas toujours le meilleur choix.
Le mot-clé est comme dans H2O - augmenté, cela signifie aider les pauvres scientifiques des données citoyens. C'est la première fois que quelqu'un est grondé pour sa performance dans une critique! Intéressant? Autrement dit, il y a tellement de puissance de calcul que les performances ne peuvent pas du tout être un problème systémique? Gartner a un article séparé sur ce mot «Augmenté» , auquel je n'ai pas pu accéder.
Et KNIME semble être le premier non-américain dans la revue! (Et nos designers ont vraiment aimé leur page de destination. Des gens étranges.
MathWorks
MatLab est un vieil ami honoraire connu de tous! Des boîtes à outils pour tous les domaines de la vie et les situations. Quelque chose de très différent. En fait, beaucoup, beaucoup, beaucoup de mathématiques pour toutes les occasions en général!
Produit complémentaire Simulink pour la conception de systèmes. Je creusais dans les boîtes à outils pour Twins numérique - Je ne comprends rien à ce sujet, mais un grand nombre a été écrit ici. Pour l' industrie pétrolière . En général, il s'agit d'un produit fondamentalement différent des profondeurs des mathématiques et de l'ingénierie. Pour sélectionner des boîtes à outils mathématiques spécifiques. Selon Gartner, ils ont tous des problèmes comme des ingénieurs intelligents - pas de collaboration - chacun fouille dans son modèle, pas de démocratie, pas d'exploitabilité.
RapidMiner
J'ai rencontré et entendu beaucoup de choses auparavant (avec Matlab) dans le contexte d'un bon open source. Enterré un peu dans TurboPrep comme d'habitude. Je suis intéressé par la façon d'obtenir des données propres à partir de données sales.
Encore une fois, vous pouvez voir que les gens sont bons dans les supports marketing de 2018 et de terribles anglophones dans la démo des fonctionnalités.
Et des gens de Dortmund depuis 2001 avec un fort passé allemand)

Je n'ai pas compris sur le site ce qui est exactement disponible dans l'open source - vous devez creuser plus profondément. Bonnes vidéos sur le déploiement et les concepts AutoML.
Le backend du serveur RapidMiner n'a rien de spécial non plus. Il sera probablement compact et fonctionnera bien sur site hors de la boîte. Il emballe dans Docker. Environnement partagé uniquement sur le serveur RapidMiner. Et puis il y a Radoop, les données de hadup, comptant les rimes de Spark dans le workflow Studio.
Les poussé vers le bas comme prévu par les jeunes vendeurs chauds "vendeurs de bâtons rayés". Gartner, cependant, prédit un succès futur dans l'espace Entreprise. Vous pouvez y collecter des fonds. Les Allemands savent combien saint et saint :) Ne parlez pas de SAP !!!
Ils font beaucoup pour les citoyens! Mais sur la page, vous pouvez voir comment Gartner dit qu'ils ont du mal à innover en matière de vente et qu'ils ne se battent pas pour une couverture étendue, mais pour la rentabilité. J'ai
laissé les fournisseurs de BI typiques de SAS et de Tibco ... Et les deux sont au sommet, ce qui confirme ma conviction que la DataScience normale se développe logiquement à
partir de la BI, et non des clouds et de l'infrastructure Hadoop. De l'entreprise, c'est-à-dire pas de l'informatique. Comme dans Gazpromneft par exemple: link , un environnement DSML mature est issu d'une solide pratique de BI. Mais peut-être qu'elle a une connotation et un parti pris sur le MDM et d'autres choses, qui sait.
SAS
Pas grand chose à dire. Seulement des choses évidentes.
TIBCO
La stratégie est lue dans la liste de courses sur une page Wiki d'une page. Oui, longue histoire, mais 28 !!! Charles. soudoyé BI Spotfire (2007) dans ma jeunesse techno. Et aussi des rapports de Jaspersoft (2014), puis jusqu'à trois fournisseurs d'analyses prédictives Insightful (S-plus) (2008), Statistica (2017) et Alpine Data (2017), traitement d'événements et streaming Streambase System (2013), MDM Orchestra Networks (2018) ) et la plate-forme en mémoire Snappy Data (2019).
Salut Frankie!
