Bonjour, Habr! Nous continuons à publier des critiques d'articles scientifiques de membres de la communauté Open Data Science du canal #article_essense. Si vous voulez les recevoir avant tout le monde, rejoignez la communauté !
Articles pour aujourd'hui:
- PointRend: Segmentation d'image en tant que rendu (Facebook AI Research, 2020)
- Natural- To Formal-Language Generation Using Tensor Product Representations (USA, 2019)
- Linformer: Self-Attention with Linear Complexity (Facebook AI, 2020)
- DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution (Johns Hopkins University, Google, 2020)
- Training Generative Adversarial Networks with Limited Data (NVIDIA, 2020)
- Multi-Modal Dense Video Captioning (Tampere University, Finland, 2020
- Are we done with ImageNet? (DeepMind, 2020)
1. PointRend: Image Segmentation as Rendering
: Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick (Facebook AI Research, 2019)
:: GitHub project
: ( evgeniyzh, habr Randl)
, , . , , AP (average precision).
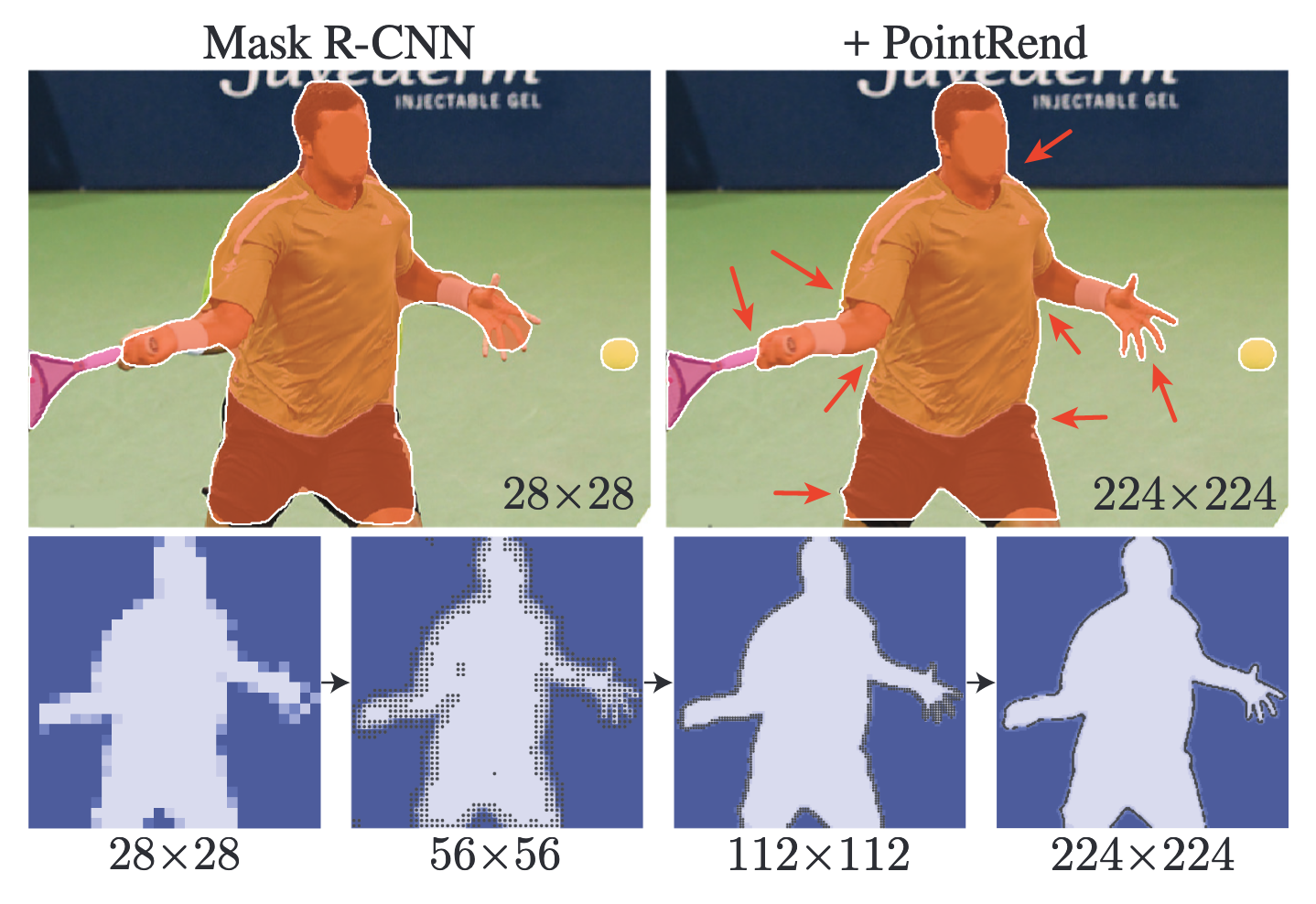
, . : () occupancy map "" () . PointRend , . , . , .
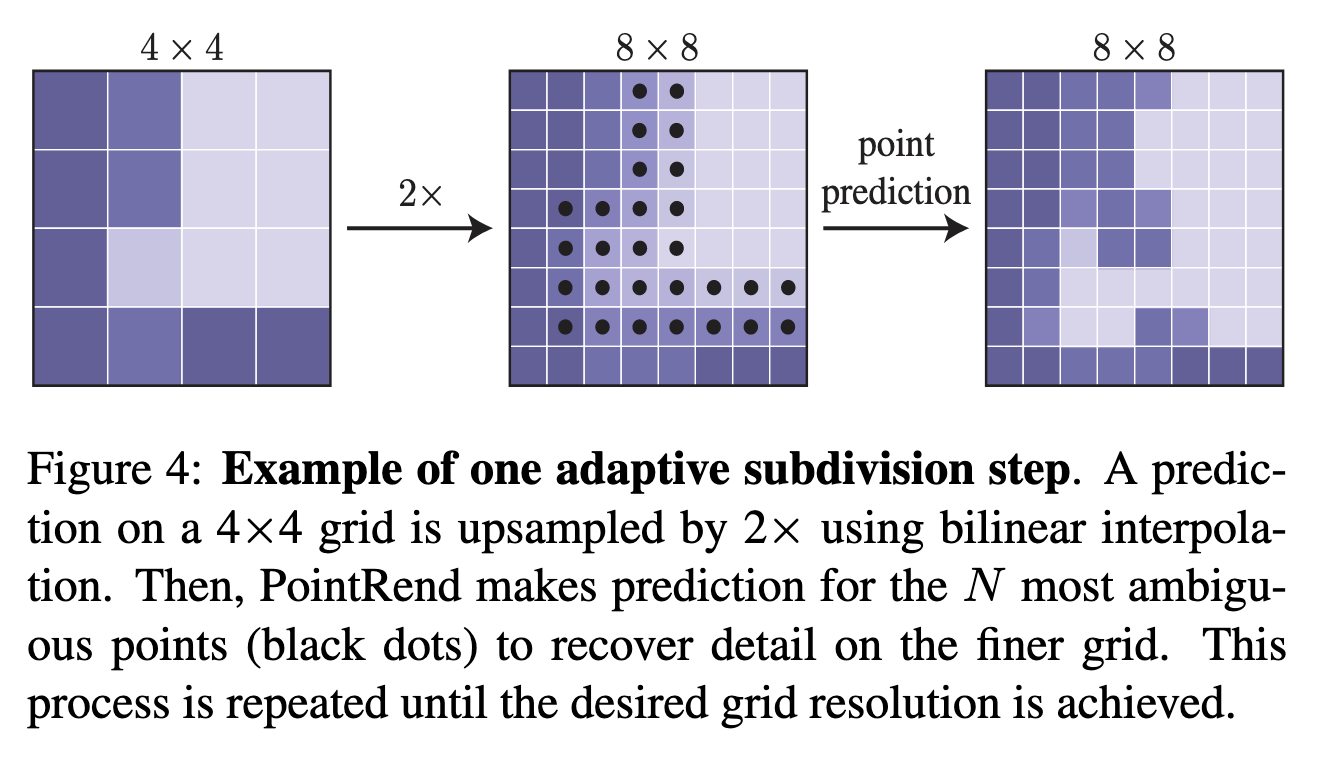
, adaptive subdivision. feature map . , N 0.5 MLP ( ) . , N * log (M/M_0) M^2 (M — , M0 — , N — ).
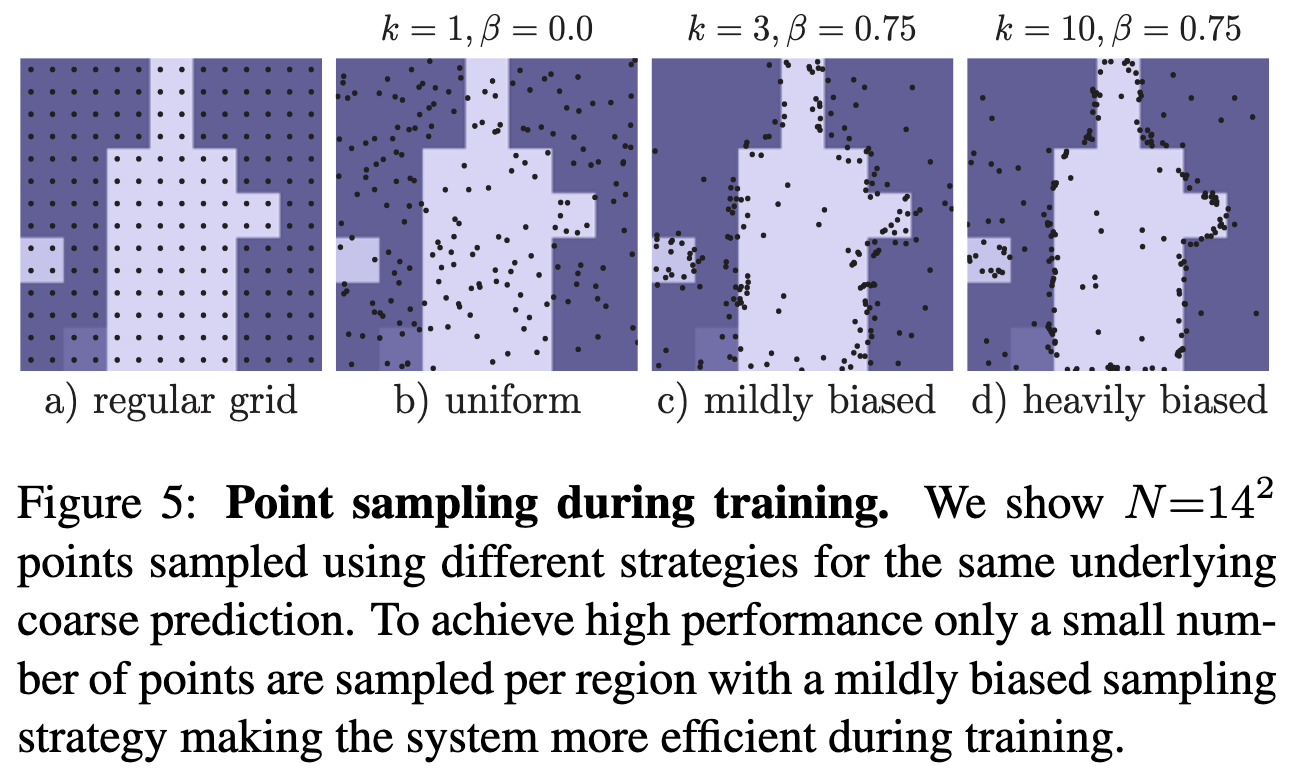
- , . , , confidence.
( ) ( CNN).
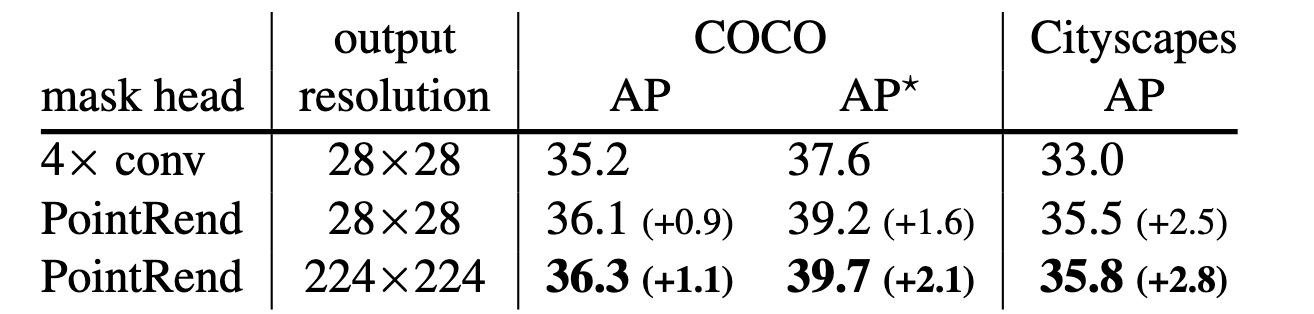
Mask R-CNN ResNet-50 + FPN. 7x7. , bounding box, Mask R-CNN, PointRend . Mask R-CNN 28x28 2 (0.5 vs. 0.9 GFLOPS), 224x224 (34 GFLOPS).
PointRend , AP . (LVIS) . ablation study: (N), , , .
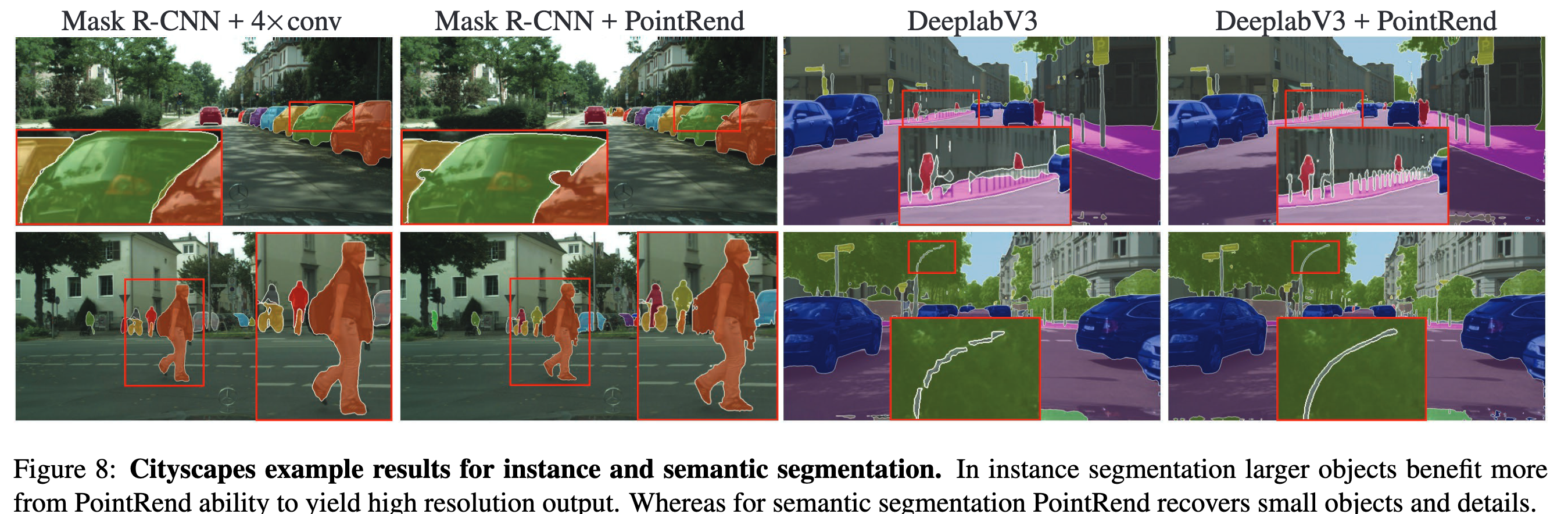
, DeeplabV3 SemanticFPN. , mIoU , .
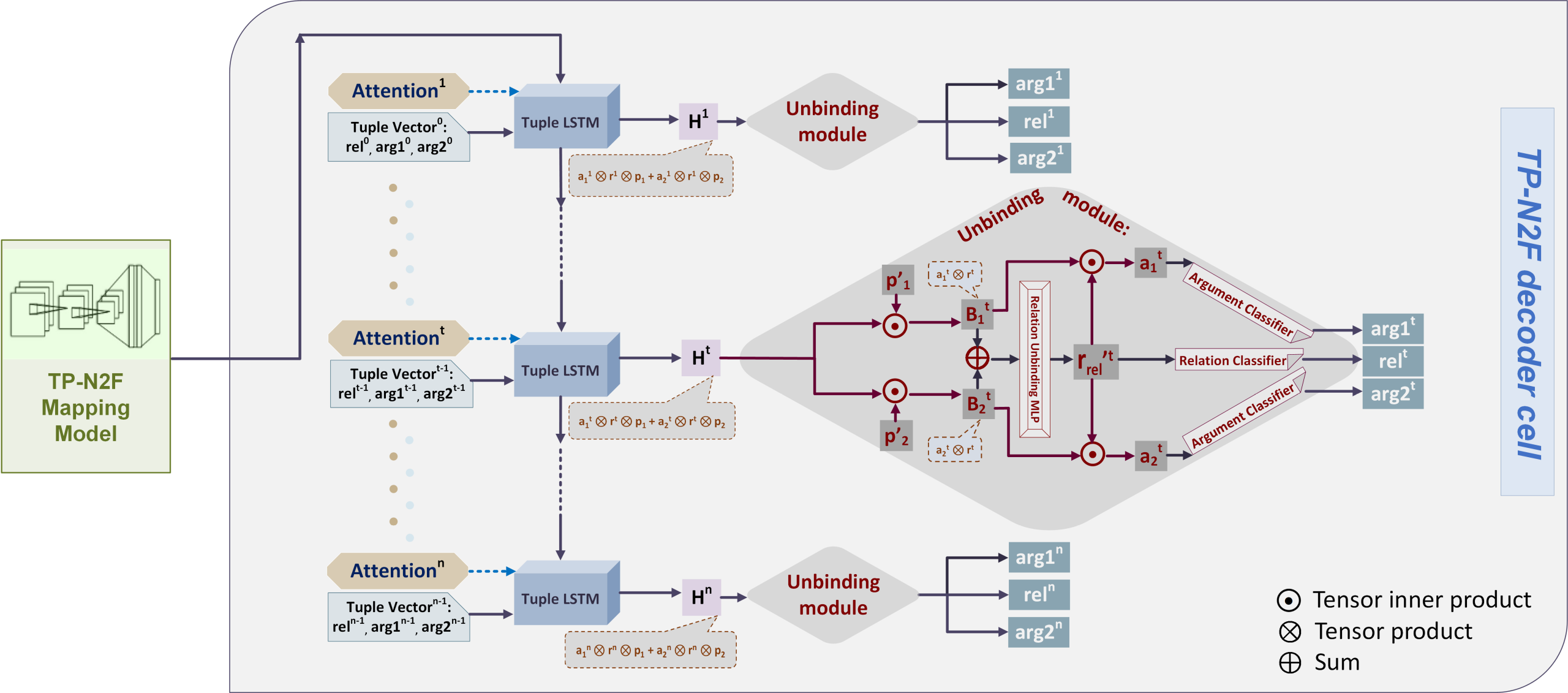
2. Natural- To Formal-Language Generation Using Tensor Product Representations
: Kezhen Chen, Qiuyuan Huang, Hamid Palangi, Paul Smolensky, Kenneth D. Forbus, Jianfeng Gao (USA, 2019)
:: GitHub project ::
: ( Max Plevako)
- .
, , . , , /, . (LSTM) MathQA AlgoLisp.
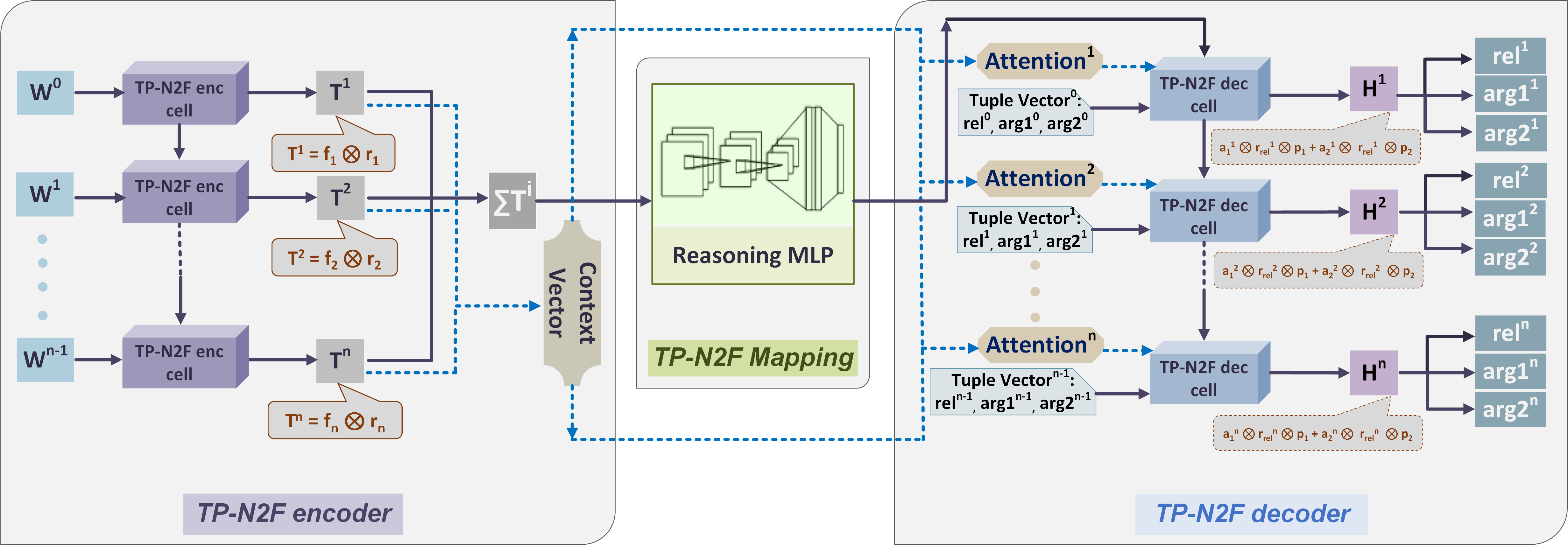
"" " ", . , "" "" .
, , . .
, , , , .
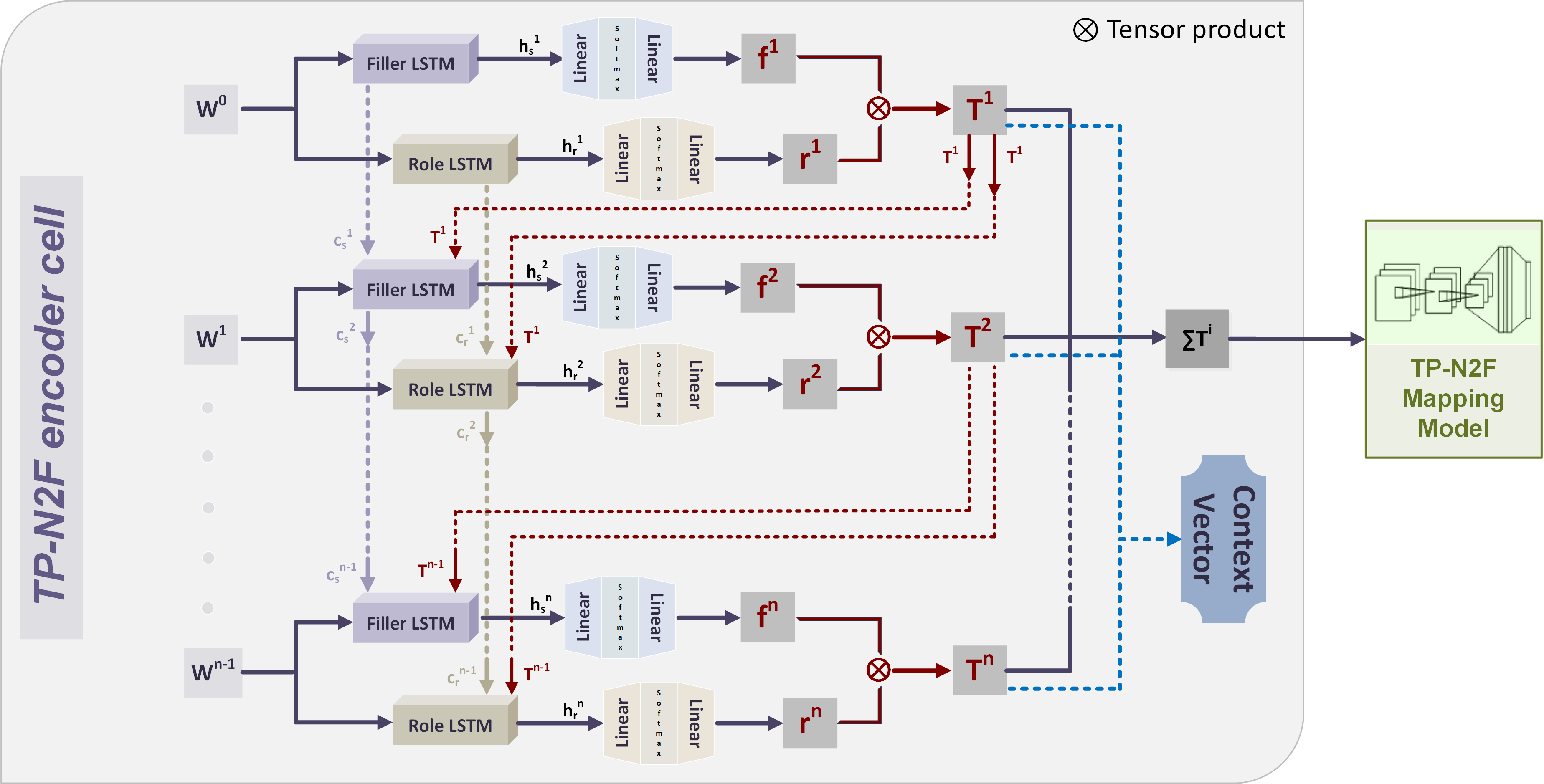
"" "" . , () , .
, , , .
, , MathQA / , 71.89% 55.95% . AlgoLisp 84.02% 93.48% .
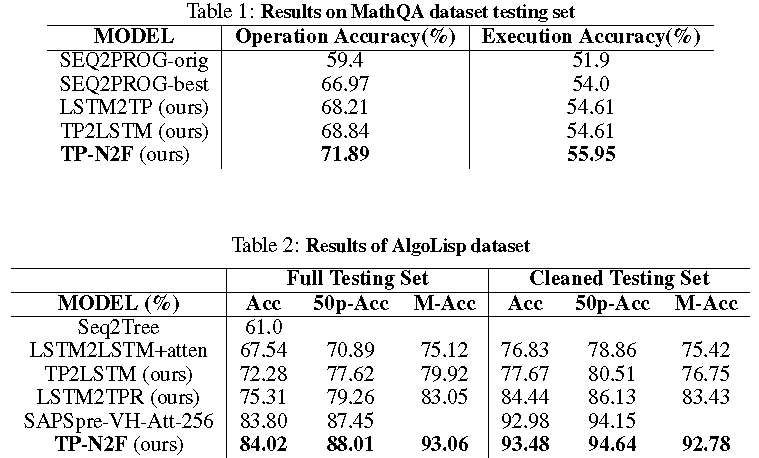
:

3. Linformer: Self-Attention with Linear Complexity
: Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma (Facebook AI, 2020)
: ( artgor, habr artgor)
, self-attention . self-attention, O(N^2) O(N) .
. 64 V100 .
: scaled dot-product attention attention , low-rank factorization attention.
Self-Attention is Low Rank
P — the context mapping matrix. RoBERTa-base RoBERTa-large, masked-language-modeling tasks. SVD , 10 . , , .
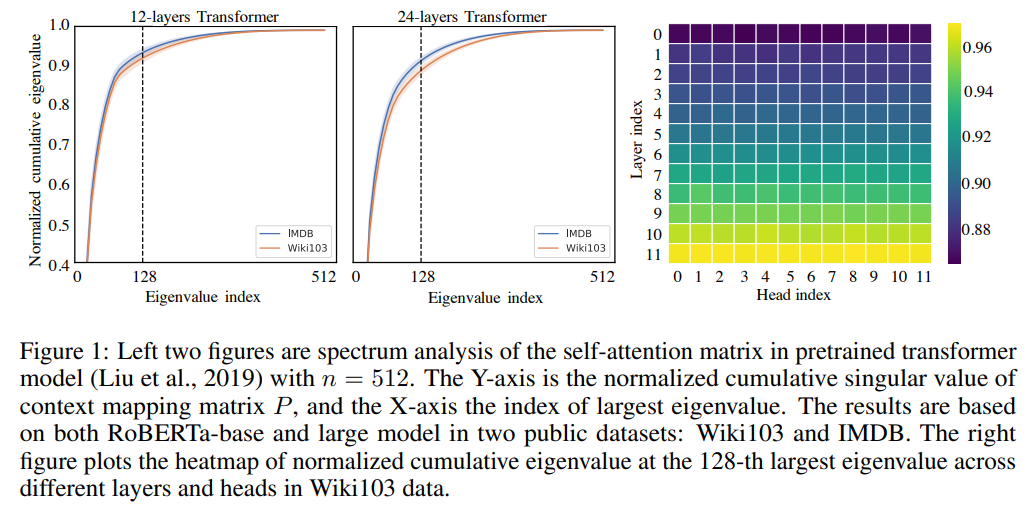
P , SVD self-attention, .
Model
: . KW VW ( n x d) k x d, n x k P scaled attention.
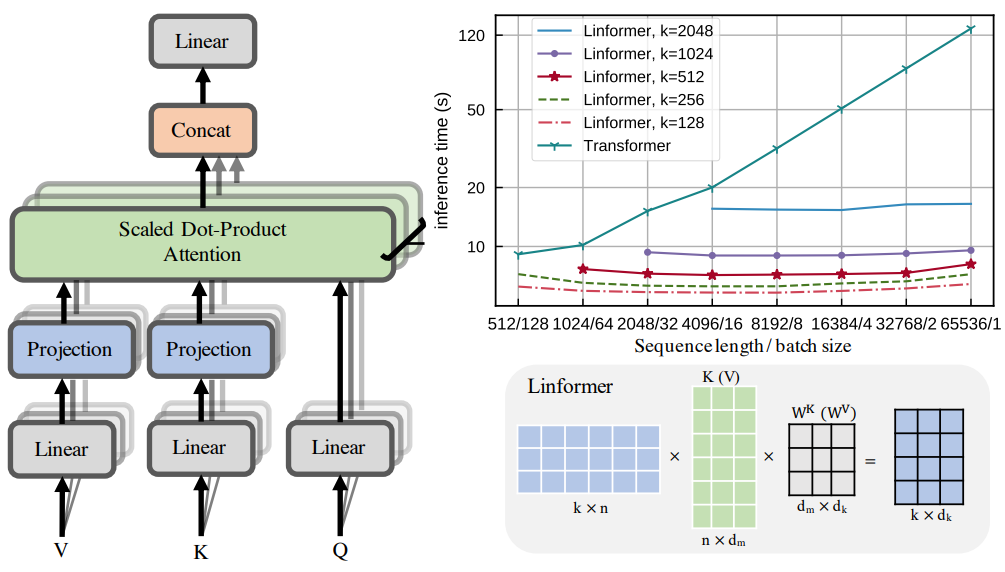
:
- : Headwise, layerwise or key-value.
- . .
- — pooling convolution n stride k.
RoBERTa. 64 Tesla V100 GPUs 250k . -, , - , . , .
Fine-tuning , .
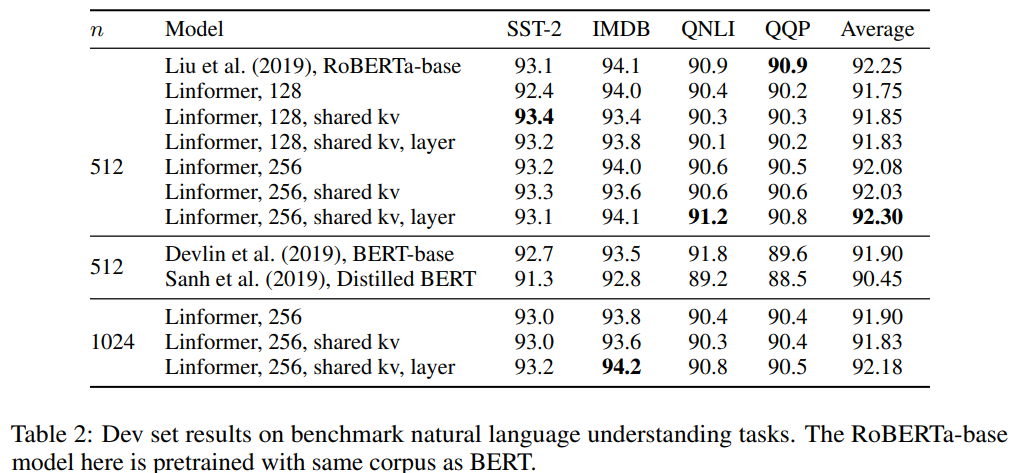
—
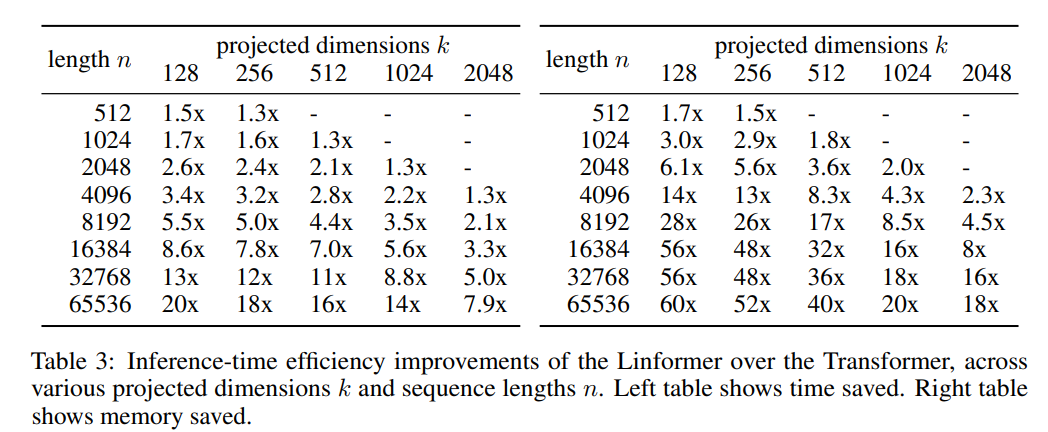
.
4. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
: Siyuan Qiao, Liang-Chieh Chen, Alan Yuille (Johns Hopkins University, Google, 2020)
:: GitHub project :: sotabench
: ( evgeniyzh, habr Randl)
object detection (54.7% AP COCO test-dev), instance (47.1% AP COCO test-dev) panoptic segmentation (49.6% PQ COCO test-dev). — Feature Pyramid, SE dilation ( atrous), () .
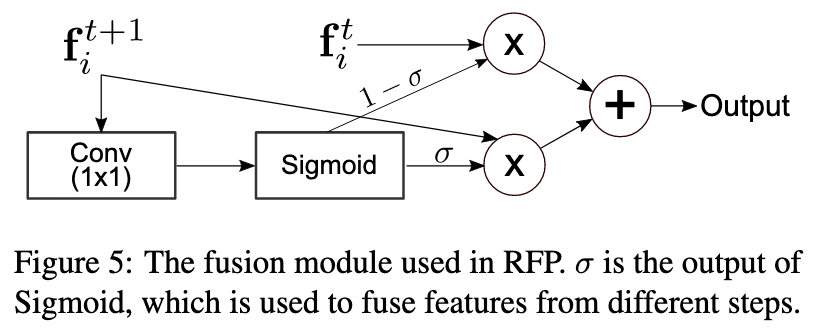
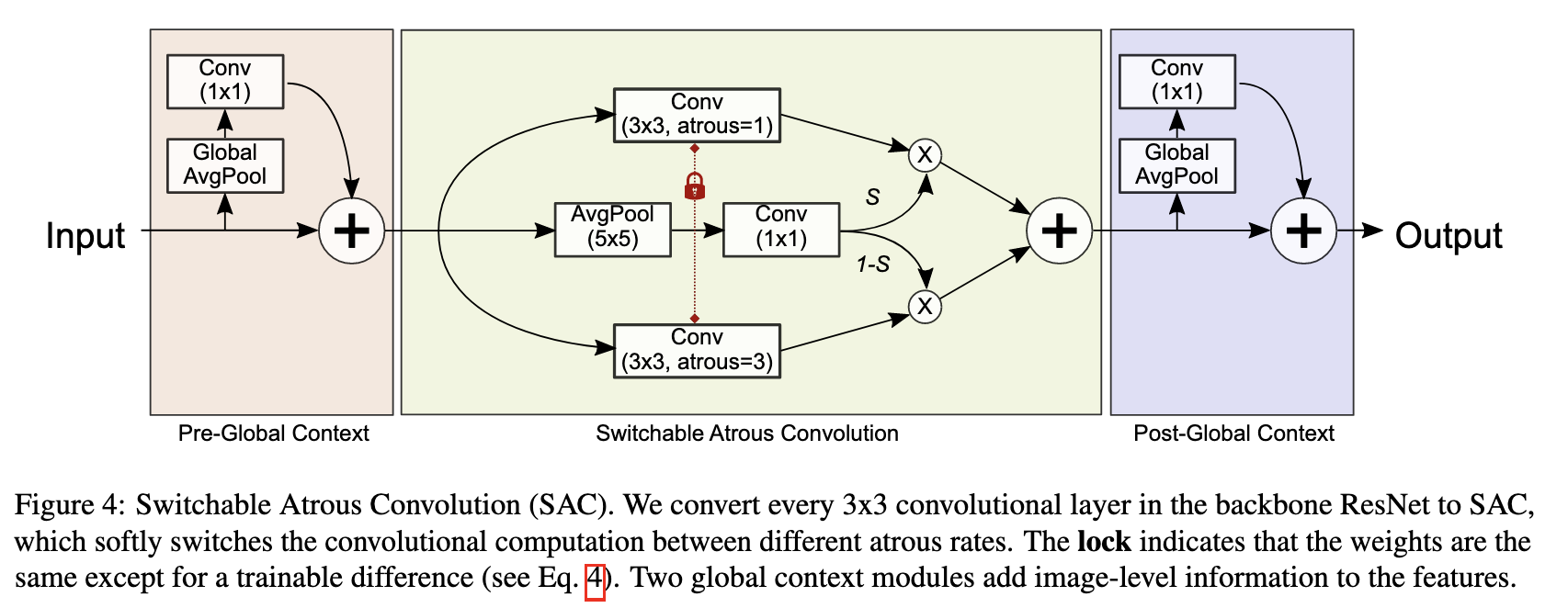
Recursive Feature Pyramid (RFP)Switchable Atrous Convolution ( ), .
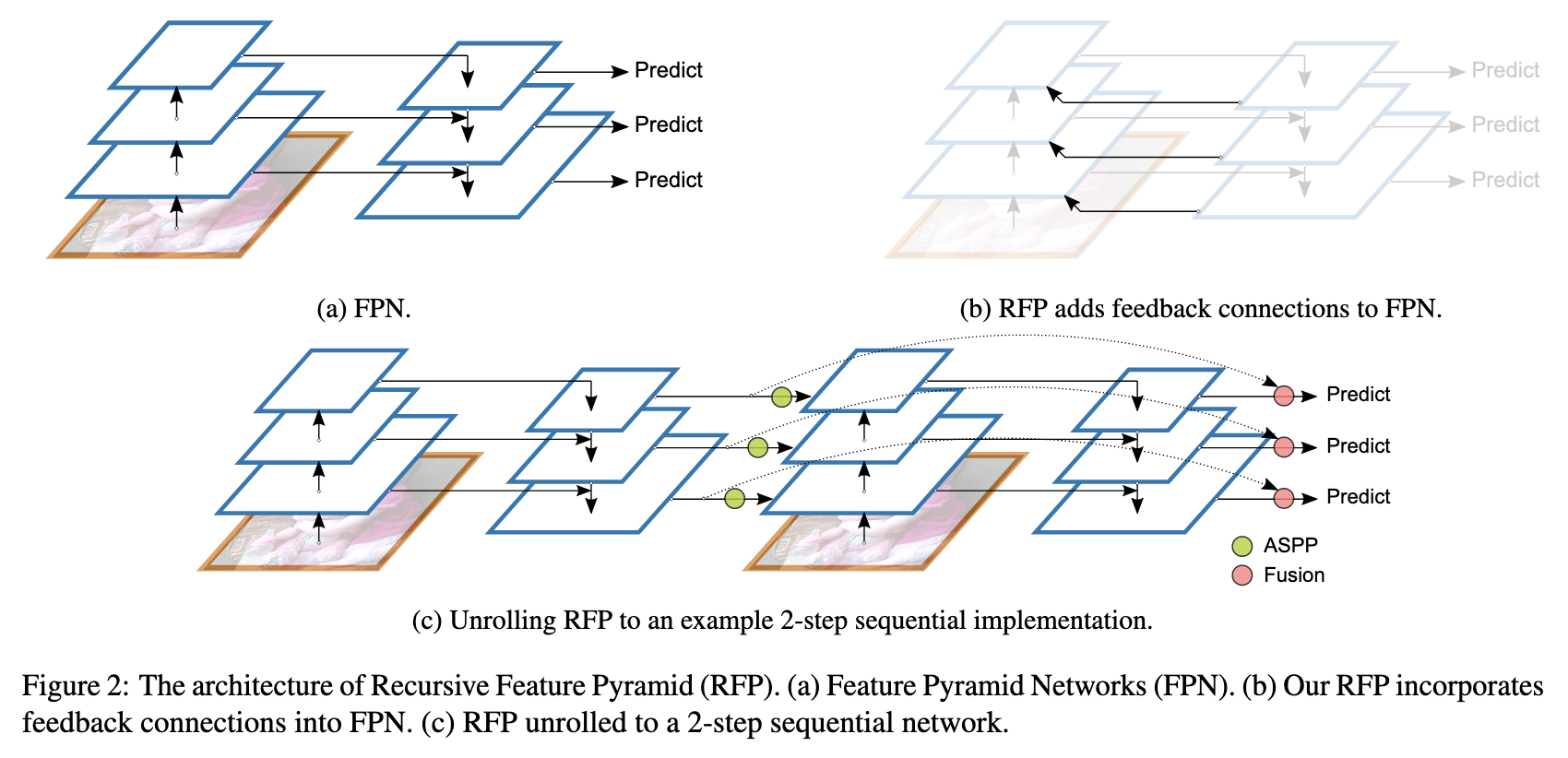
, 4 ResNet, , (Atrous Spatial Pyramid Pooling): 4 1/4 , (1x1, 3x3 c dilation 3, 3x3 c dilation 6) + ReLU, global average pooling + (1x1) + ReLU. .
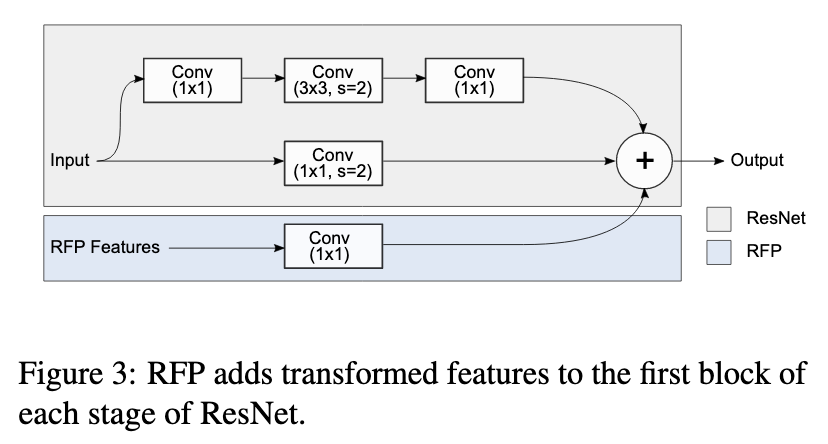
, t+1- t- attention (σ).
Switchable Atrous Convolution (SAC)
dilation ( ∆w , 0.1% , ). , 1*1 . SE , .
, detection, instance panoptic segmentation. HTC.
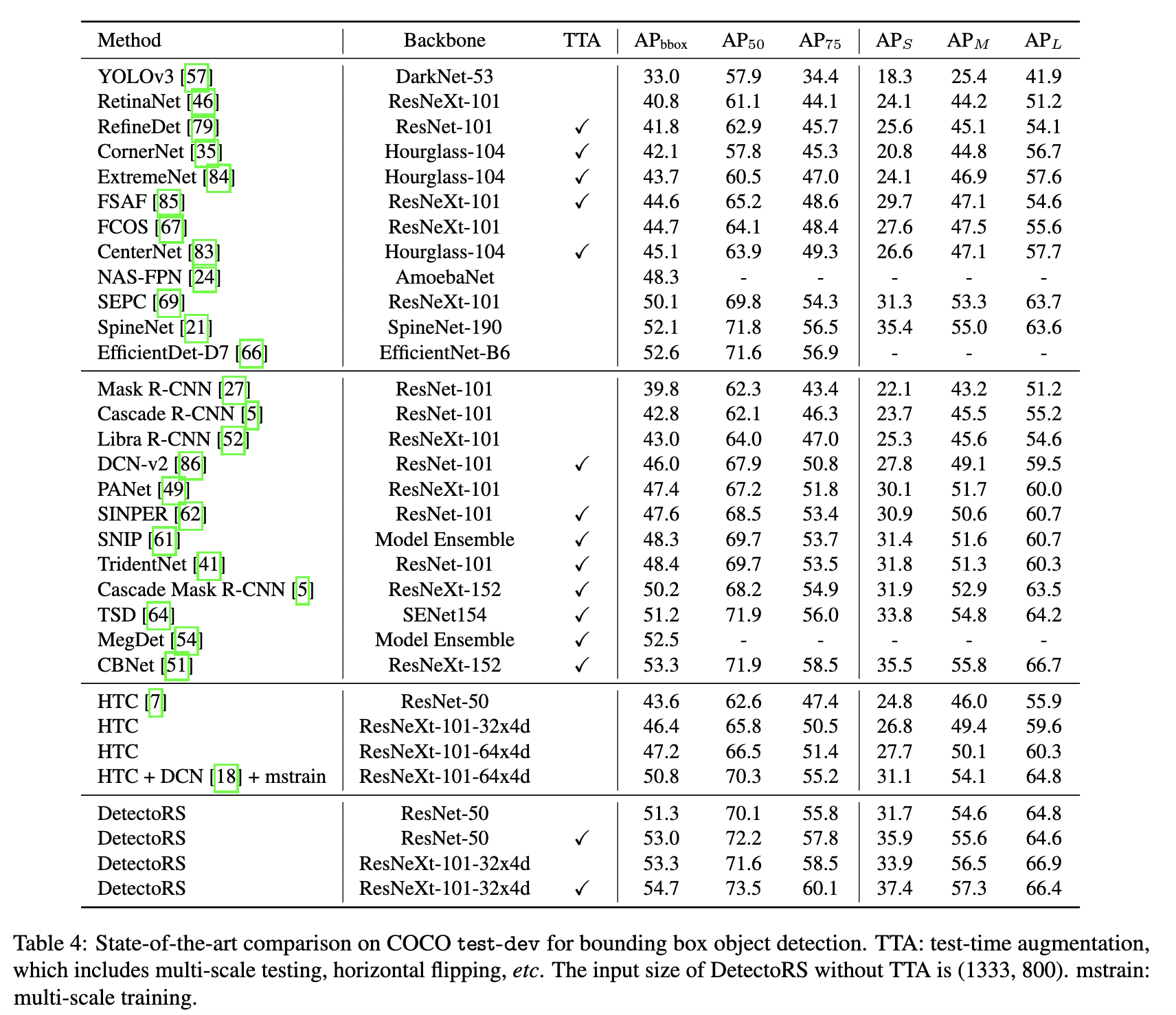
ablation study. RFP SAC 4.2 4.3 AP ResNet-50 , 7%. RFP SAC.
c dilation 3 SAC. , c dilation 1 (, , AP DetectoRS EfficientNet).

5. Training Generative Adversarial Networks with Limited Data
: Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, Timo Aila (NVIDIA, 2020)
: ( digitman, habr digitman)
stylegan, , . — , . StyleGAN2 ( ).
— . ( BigGAN — D , ). , , — Fréchet inception distance (FID). (b) () , , D real fake, fake — .
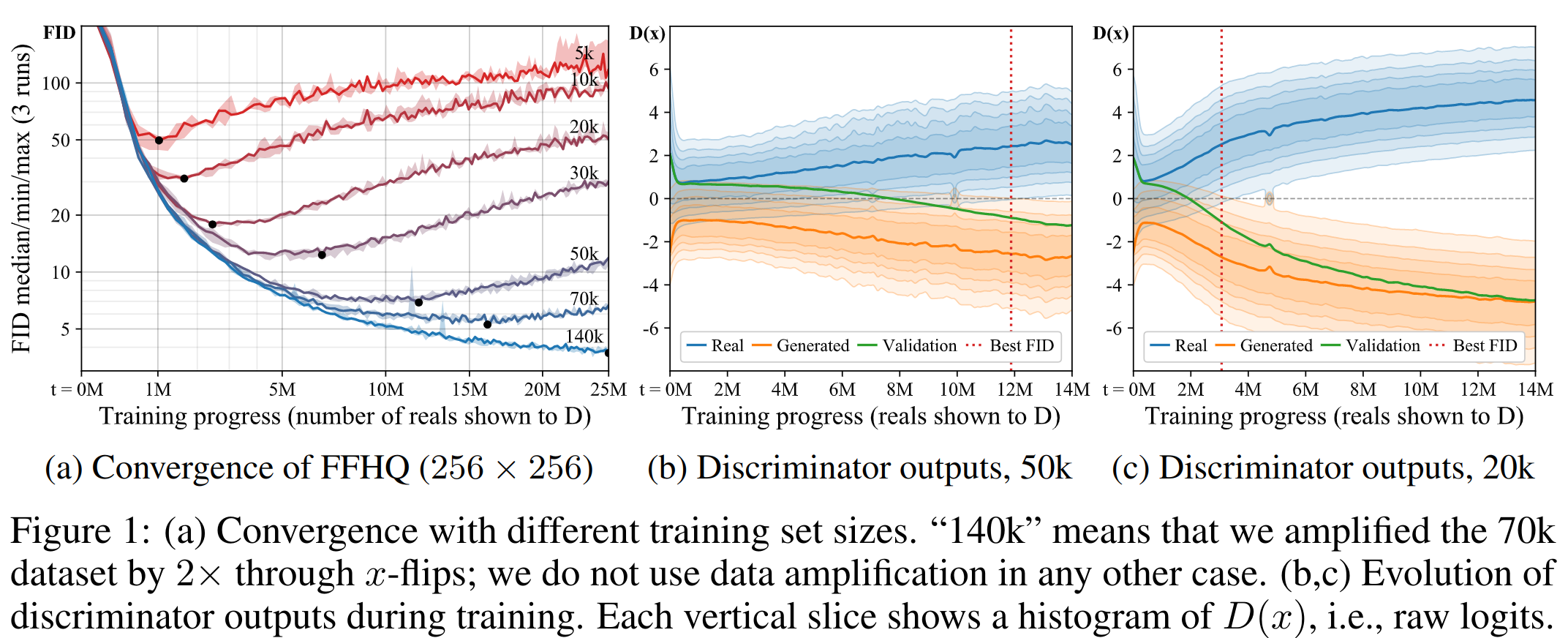
, .. "" . Consistency regularization, D , . "" .
. . D . G , . 2(b).
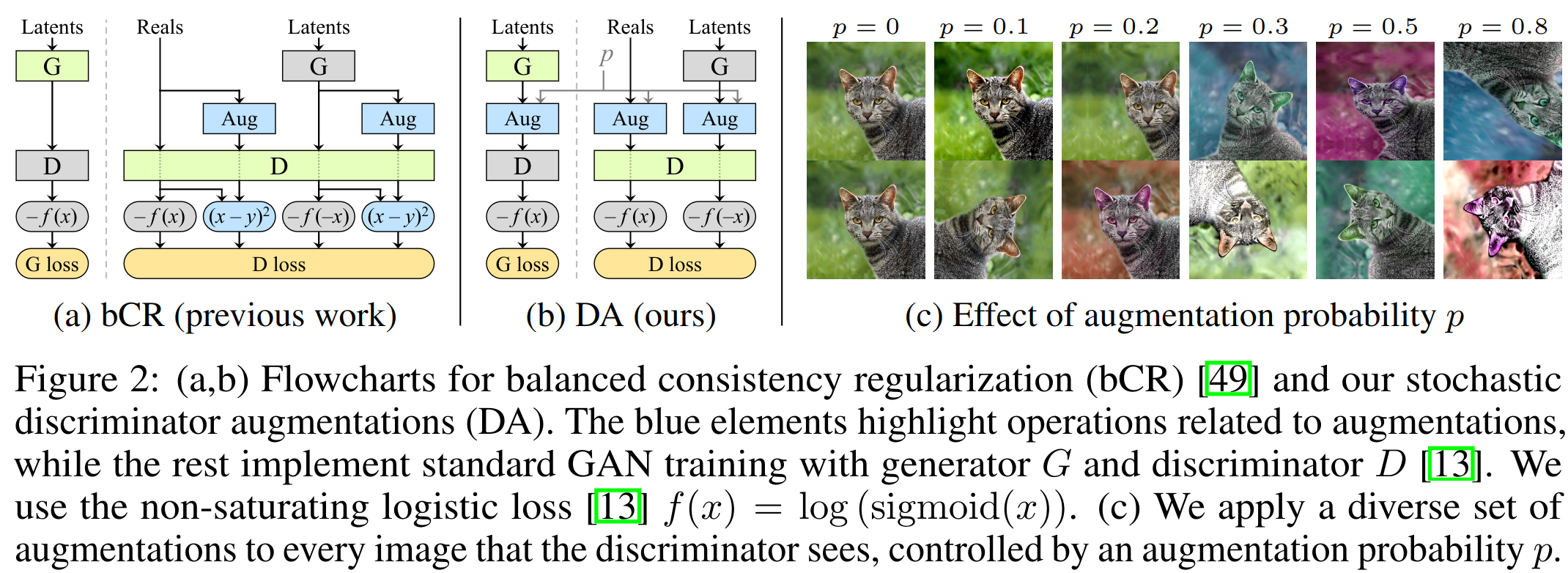
— , , "". non-leaking. , , . 90% ( , , ), [0, 90, 180, 270] ( ). , p < 1. , , p=0.5, 0 . , ( , , ).
(, ) , , cutout, . , .. G D , . non-leaking non-leaking. , p. p 2(). , , . p. ( p).
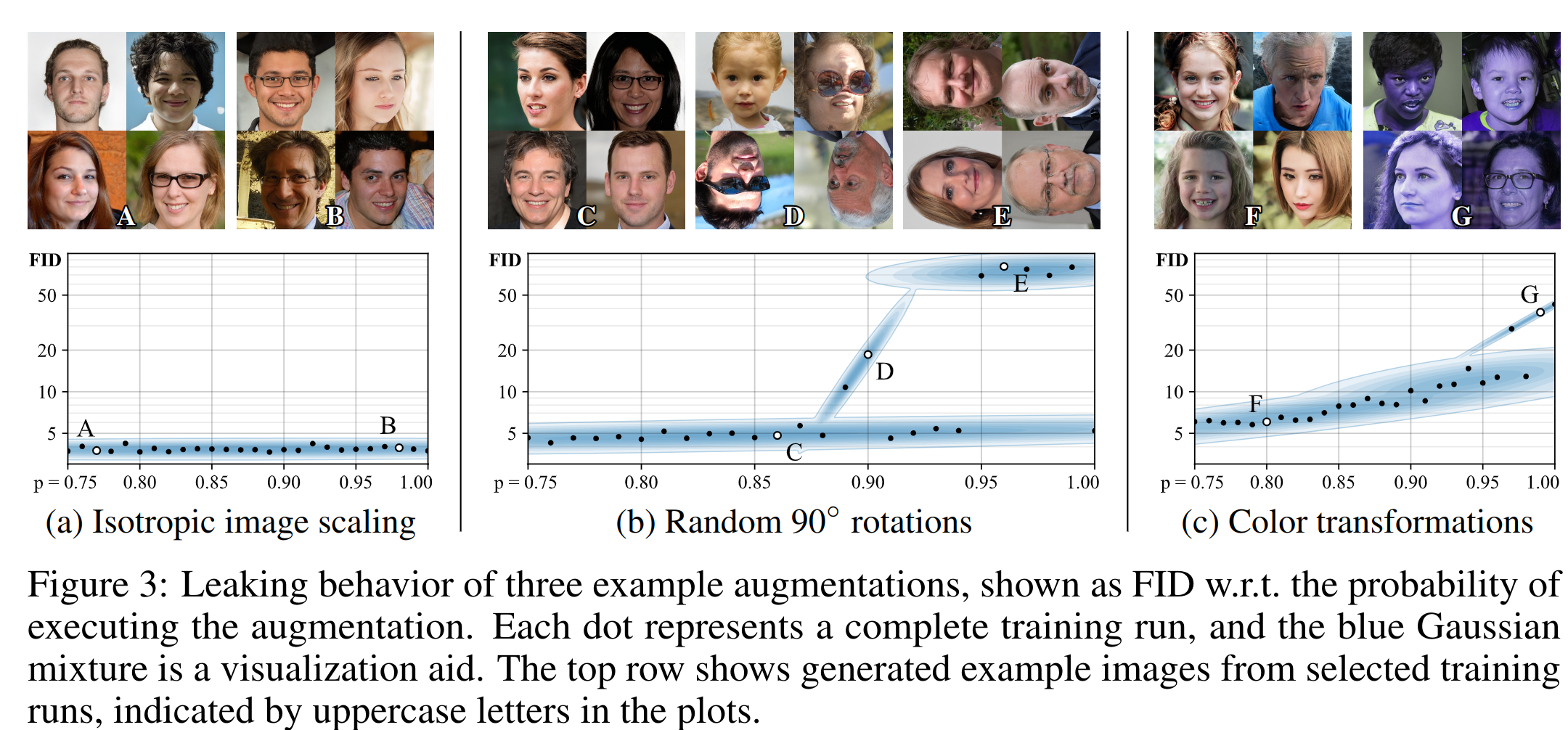
, p. , , . (0 — , 1 — ):
- (): r_v = (E[Dtrain]-E[Dval])/(E[Dtrain]-E[Dgen]);
- — D ( D): r_t = E[sign(Dtrain)].
4 p . , , p, . adaptive discriminator augmentation(ADA).
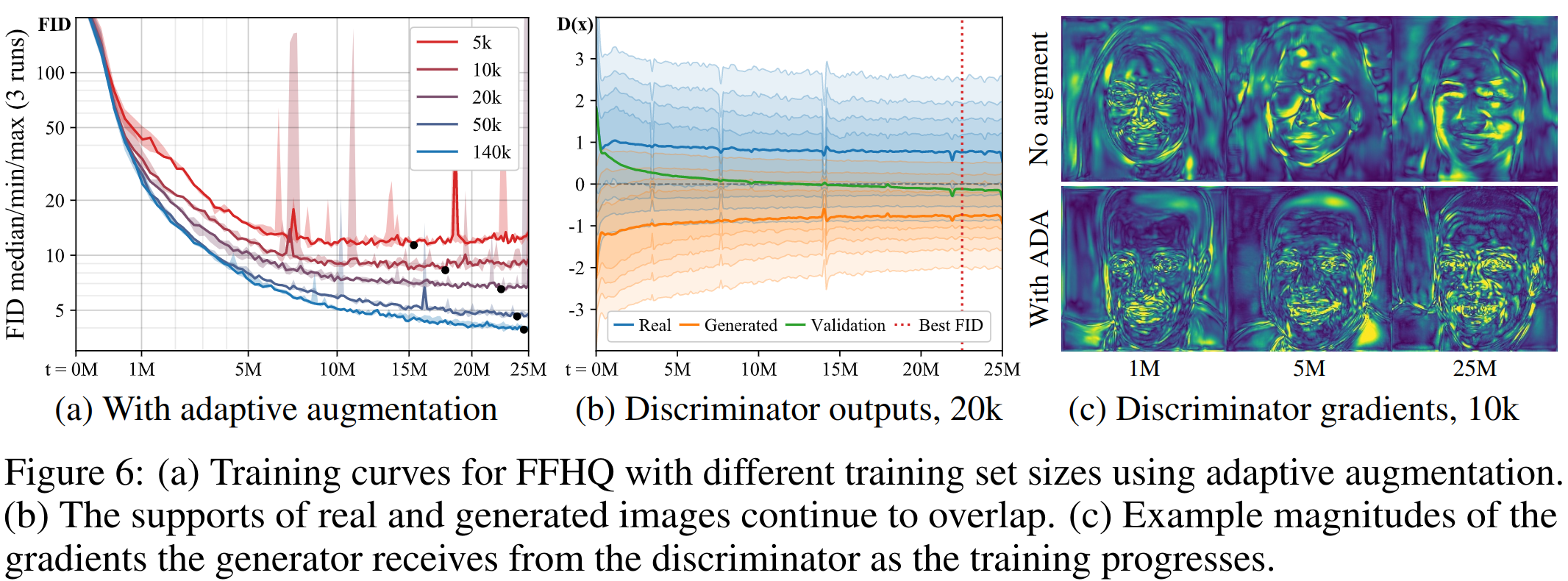
, , ADA , G . , . sample-efficiency StyleGAN2 1 .
, transfer learning. - .
FFHQ. , .
6. Multi-Modal Dense Video Captioning
: Vladimir Iashin, Esa Rahtu (Tampere University, Finland, 2020)
:: GitHub project
: ( vdyashin)
(Dense) Video Captioning?
, Video Captioning. , . , 120 . , "" , . Dense Video Captioning.

?
. , . , . , . , , , , ( "How to do ..."). ( ) domain Dense Video Captioning.
Dense Video Captioning? event localization , seq-to-seq .
Event Localization
Event localization . event localization LSTM, (forward) anchors , event . LSTM , (backward). , (proposals), .
Caption Generation
, . I3D, VGGish . seq-to-seq , .
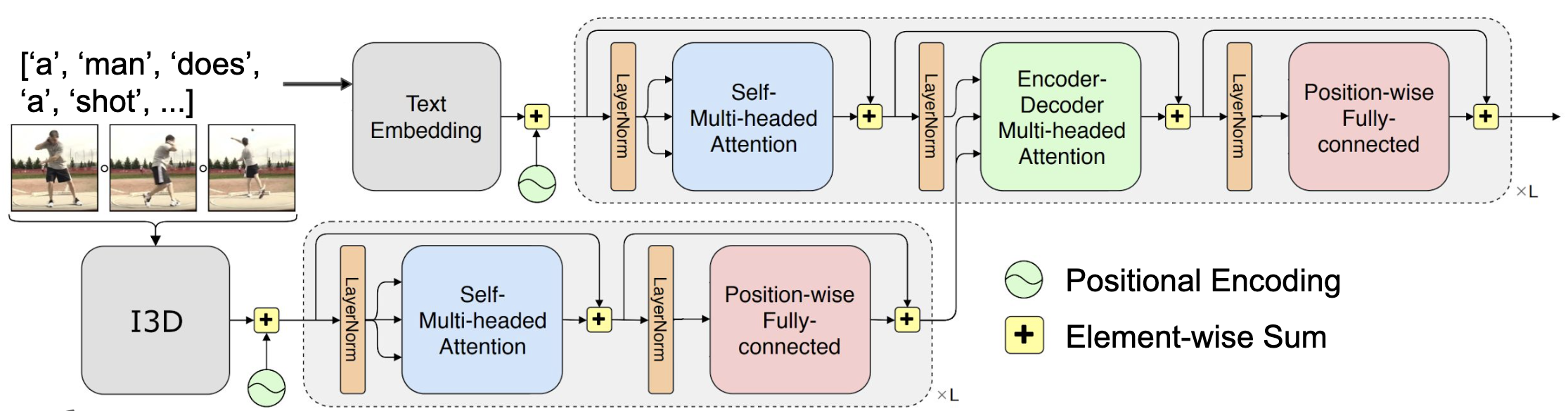
, .
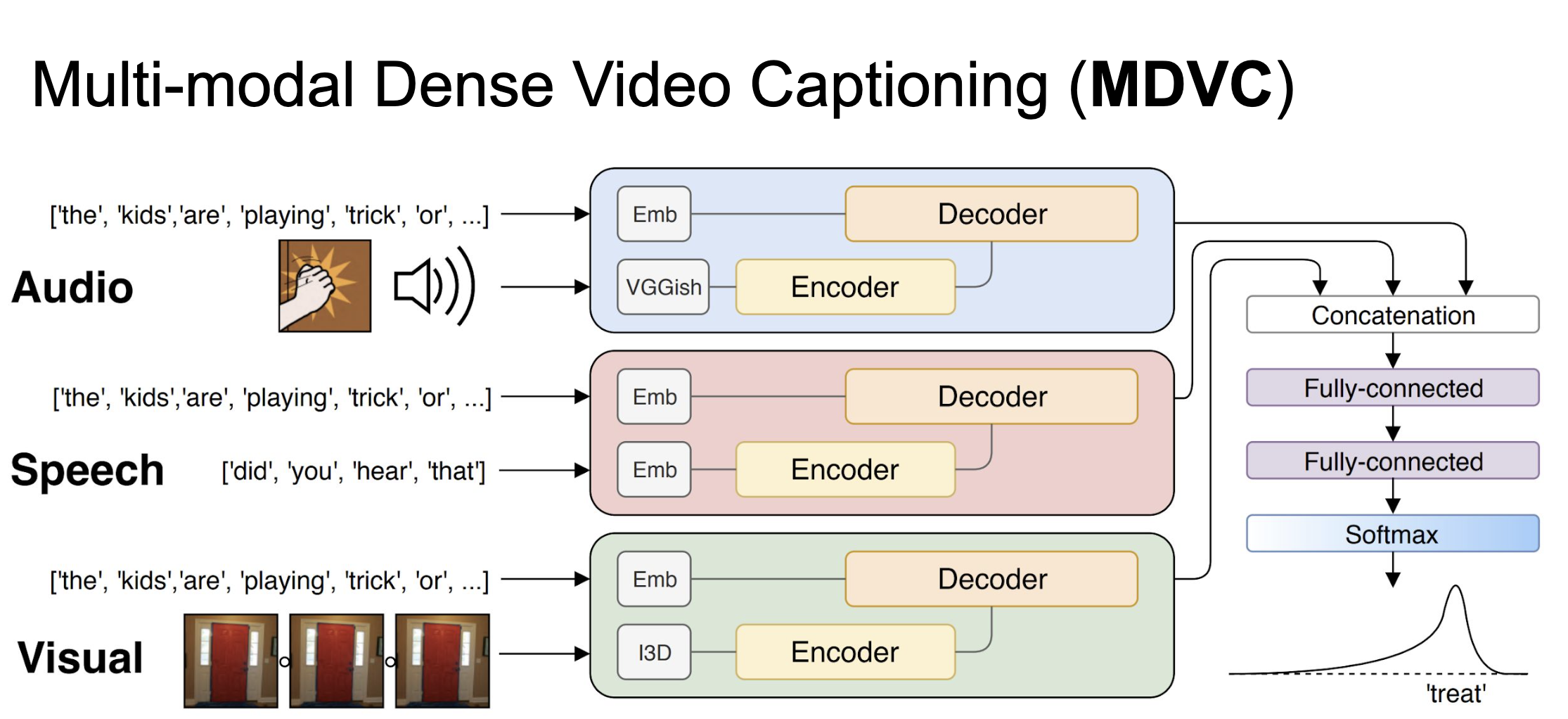
ActivityNet Captions. , , , 90% , 10 % (. ). .
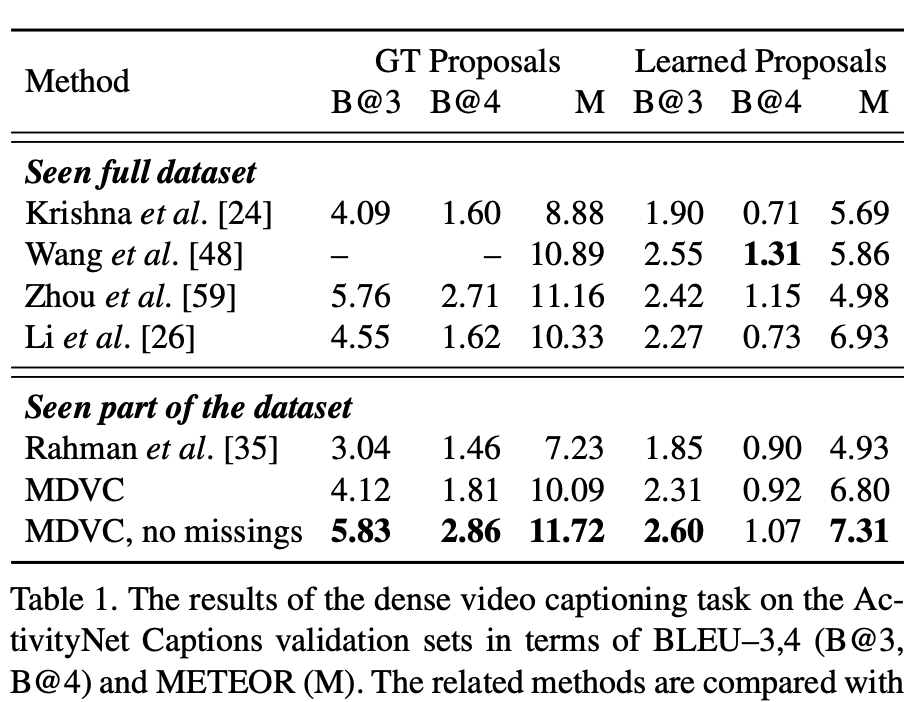
- , .
- , , , , , .
: . ? .mp4 GPU , . I3D ( PWC-Net optical flow) VGGish .
7. Are we done with ImageNet?
: Lucas Beyer, Olivier J. Hénaff, Alexander Kolesnikov, Xiaohua Zhai, Aäron van den Oord (DeepMind, 2020)
:: GitHub project
: ( evgeniyzh, habr Randl)
: " 0.1% 10 GPU-", " ImageNet "? ImageNet, .
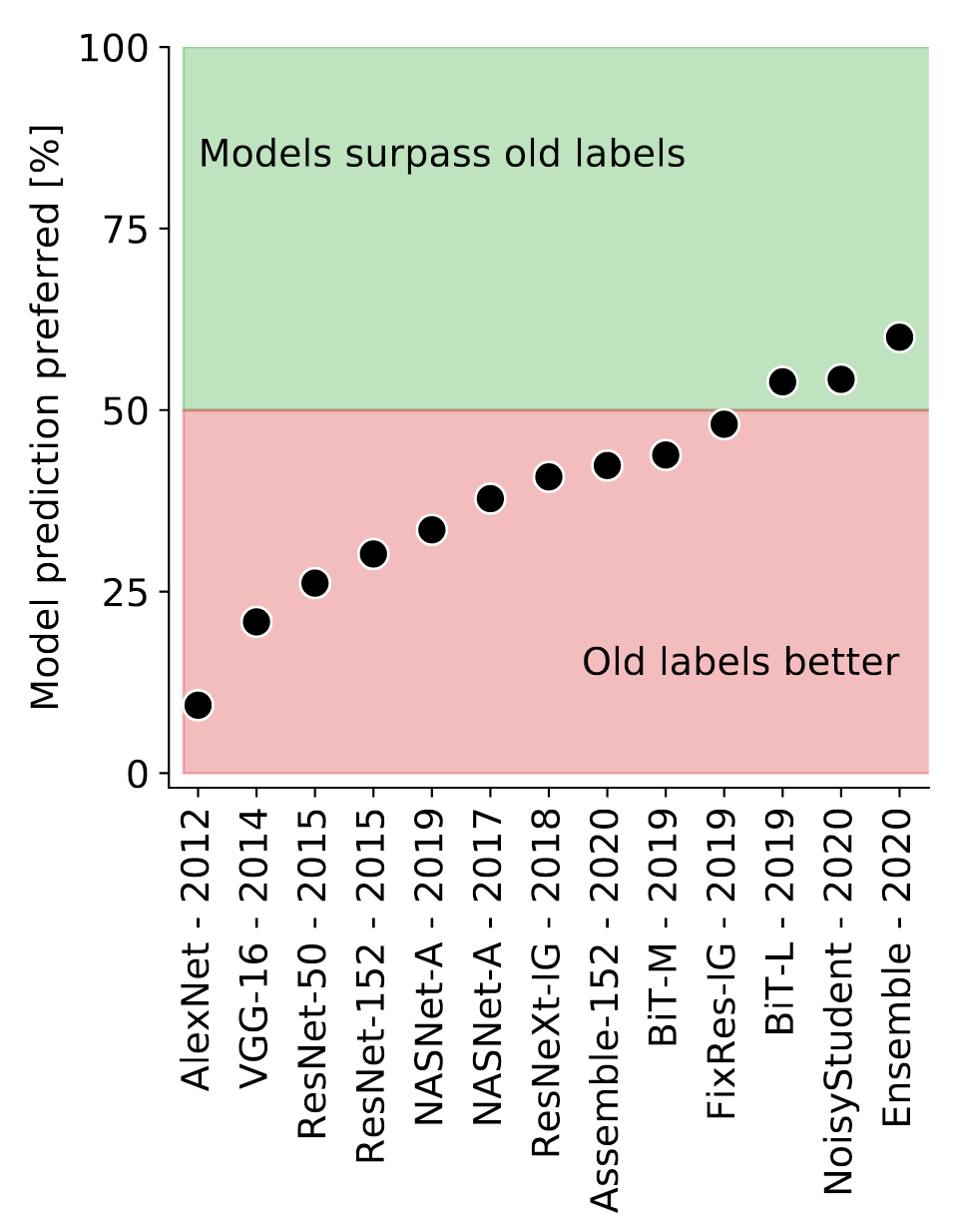
ImageNet?
- , .
- : , .
- : “sunglasses” “sunglass”, “laptop” “notebook”, “projectile, missile” “missile”.

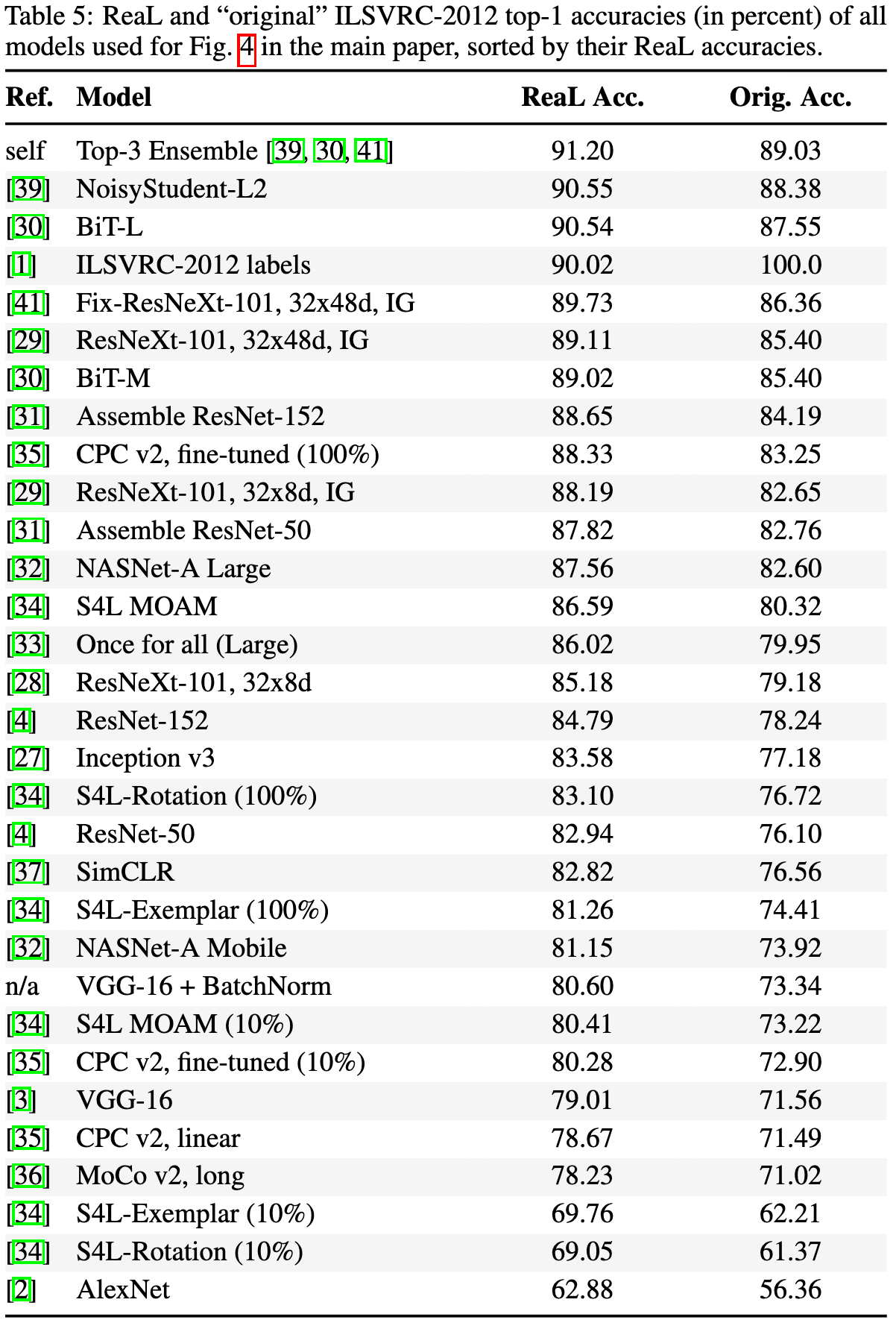
. 19 (VGG-16; Inception v3; ResNet-50; ResNet-152; ResNeXt-101, 32x8d; ResNeXt-101, 32x8d, IG; ResNeXt-101, 32x48d, IG; BiT-M; BiT-L; Assemble ResNet-50; Assemble ResNet-152; NASNet-A Large; NASNet-A Mobile; Once for all (Large); S4L MOAM; CPC v2, fine-tuned; CPC v2, linear; MoCo v2, long; SimCLR). - . 150000 . , . -1 ImageNet. , 256 5 , Recall 97% (VGG-16; Inception v3; BiT-M; BiT-L; CPC v2, fine-tuned), 13 7.4.
, ( 24 889) . ( 8 ), , 37 998 . 5 .
, maximum-likelihood. , , . , 57 553 46 837 , . "ReaL labels" .
ReaL . 2 : ~81% 0.86, — 0.51. Z-test , p<0.001. , ImageNet. , ReaL .
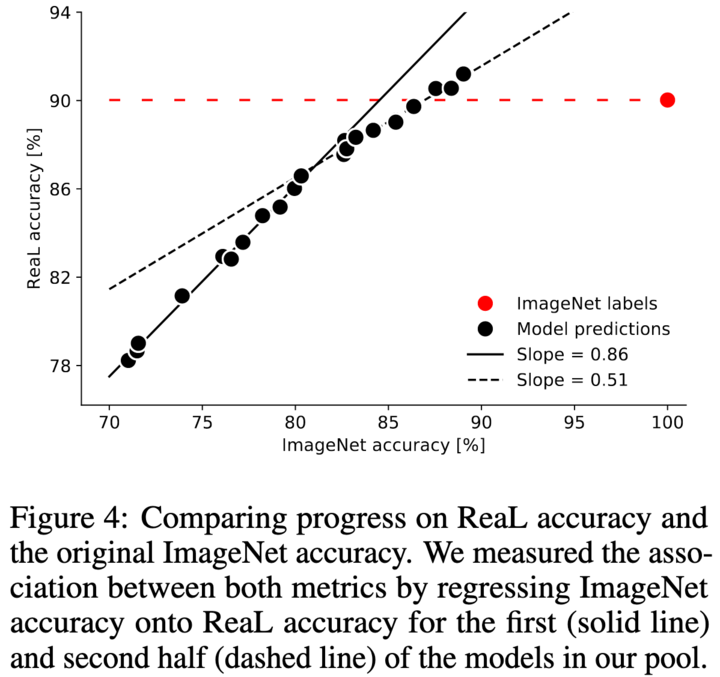
, , . — BiT-L NoisyStudent-L2 . : NoisyStudent-L2; BiT-L; Fix-ResNeXt-101, 32x48d, IG. 89.03% 91.20% ReaL.
, -2 -3 . , ReaL.
: ? bias ? , ReaL 90%. (253): : (sunglass, sunglasses), (bathtub, tub), (promontory, cliff), (laptop,notebook); : (keyboard, desk), (cucumber, zucchini), (hammer, nail).
, .
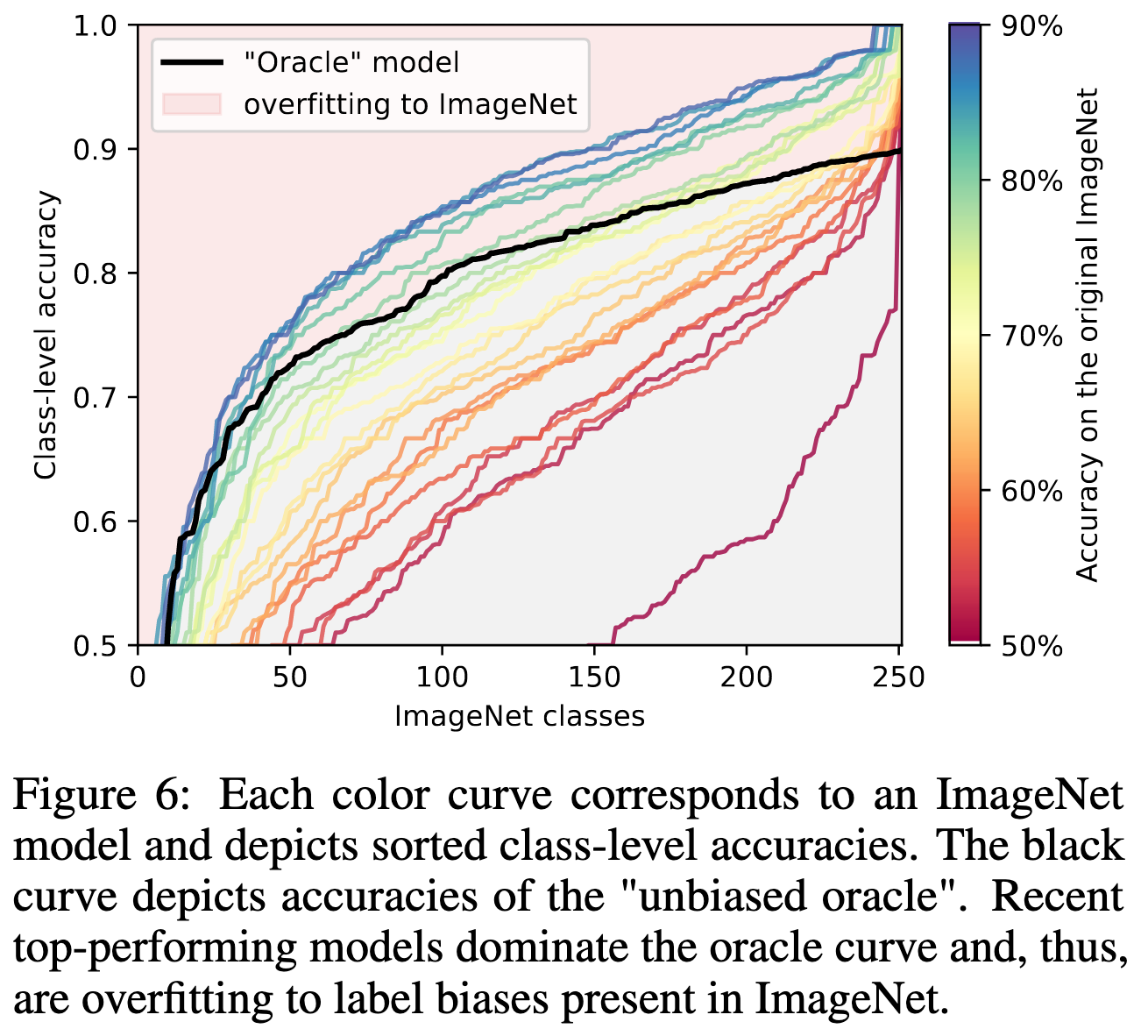
, . " ?" , . "-" ReaL.
. , softmax sigmoid. 10-fold BiT-L ( ~10% ). 0.5-2% baseline.
ReaL .