Pour les entreprises qui doivent gérer des données et des applications sur plus d'un serveur, l'infrastructure est primordiale.
Pour chaque entreprise, une partie importante du flux de travail consiste à surveiller les nœuds d'infrastructure, en particulier en l'absence d'accès direct pour résoudre les problèmes émergents. De plus, une utilisation intensive de certaines ressources peut être un indicateur de défaillances et de surcharges d'infrastructure. Cependant, la surveillance peut être utilisée non seulement pour la prévention, mais aussi pour évaluer les conséquences possibles de l'utilisation de nouveaux logiciels en production. Il existe actuellement sur le marché plusieurs solutions prêtes à l'emploi pour le suivi de la consommation des ressources, mais elles posent néanmoins deux problèmes majeurs: le coût élevé d'installation et de configuration et les problèmes de sécurité liés aux logiciels tiers.
Le premier enjeu est la question du prix: le coût peut aller de dix euros (tarifs consommateurs) à plusieurs milliers (tarifs entreprises) par mois, selon le nombre d'hôtes à surveiller. Par exemple, disons que je veux surveiller trois nœuds pendant un an. Avec un prix de 10 euros par mois, je dépenserai 120 euros, alors qu'une petite entreprise devra débourser dix à vingt mille euros, ce qui s'avérera une décision financièrement intenable et sapera tout simplement l'ensemble du budget.
Le deuxième problème concerne les logiciels tiers. Étant donné que pour l'analyse, les données des utilisateurs - qu'il s'agisse d'un particulier ou d'une entreprise - doivent être traitées par un tiers, la question se pose: comment le tiers collecte-t-il les données et les présente-t-il à l'utilisateur? Habituellement, pour cela, une application spéciale est installée sur le nœud, à travers laquelle la surveillance est effectuée, mais ces applications ont souvent le temps de devenir obsolètes ou de s'avérer incompatibles avec le système d'exploitation du client. L'expérience des chercheurs dans le domaine de la sécurité de l'information met en lumière les problèmes de travail avec des « logiciels propriétaires ». Feriez-vous confiance à un tel logiciel? Pas moi.
J'ai mes nœuds pour Tor et certaines crypto-monnaiesJe préfère donc les alternatives gratuites, open source et facilement personnalisables pour la surveillance. Dans cet article, nous examinerons trois de ces outils: Grafana, InfluxBD et CollectD.

surveillance
Pour analyser efficacement chaque métrique de notre infrastructure, nous avons besoin d'une application capable de collecter des statistiques sur les appareils qui nous intéressent. A cet égard, CollectD vient à la rescousse : ce démon regroupe et collecte ("collecte", donc un tel nom) tous les paramètres qui peuvent être stockés sur disque ou transmis sur le réseau.
Les données seront ensuite transférées vers l' instance InfluxDB : il s'agit d'une base de données chronologiques (TSBD) qui associe les données à l'heure (horodatage codé UNIX) à laquelle le serveur les a reçues. Ainsi, les données envoyées par CollectD arriveront sous la forme d'une séquence d'événements.
Enfin, nous utiliserons Grafana: Ce programme se connectera à InfluxDB et affichera les données sur des tableaux de bord colorés et conviviaux. Grâce à toutes sortes de graphiques et d'histogrammes, nous pourrons suivre en temps réel les données du CPU, de la RAM, etc.

InfluxDB

Commençons par InfluxDB, un TSBD gratuit pour stocker des données sous forme de séquence d'événements. Cette base de données développée par Go sera le cœur de notre «système» de surveillance.
Chaque fois que des données arrivent, une étiquette UNIX y est liée par défaut . La flexibilité de cette approche évite à l'utilisateur d'avoir à stocker la variable «temps», ce qui est par ailleurs assez compliqué. Imaginons que nous ayons plusieurs appareils situés sur différents continents. Comment gérons-nous la variable «temps»? Allons-nous lier toutes les données au temps moyen de Greenwich, ou allons-nous donner à chaque nœud son propre fuseau horaire? Si les données sont stockées dans des fuseaux horaires différents, comment les afficher correctement sur les graphiques? Comme vous pouvez le voir, les problèmes surviennent les uns après les autres.
Étant donné qu'InfluxDB garde une trace du temps et marque automatiquement chaque arrivée de données, il peut écrire des données de manière synchrone dans une base de données spécifique. C'est pourquoi InfluxDB est souvent présenté comme une chronologie: l'écriture de données n'affecte pas les performances de la base de données (ce qui arrive parfois avec MySQL), car l'écriture consiste simplement à ajouter un événement spécifique à la chronologie. Par conséquent, le nom du programme vient de la perception du temps comme un "flux" sans fin et illimité.
Installation et configuration
Un autre avantage d'InfluxDB est sa facilité d'installation et sa documentation complète fournie par la communauté du projet, qui le prend largement en charge . InfluxDB a deux types d'interface: la ligne de commande (un outil pratique pour les développeurs, mais mal préparé pour travailler avec de grandes quantités de données) et l' API HTTP pour une interaction directe avec la base de données.
Vous pouvez télécharger InfluxDB non seulement à partir du site officiel, mais également via le système de gestion de paquets (nous allons le démontrer via Debian). De plus, il est recommandé de vérifier les packages via GPG avant l'installation, donc ci-dessous nous importons les clés du package InfluxDB:
root@node#~: curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
root@node#~: source /etc/os-release
root@node#~: echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.listEnfin, nous mettrons à jour et installerons InfluxDB:
root@node#~: apt-get update
root@node#~: apt-get install influxdbPour courir, nous utiliserons
systemctl:
root@node#~: service start influxdb Pour empêcher quelqu'un avec des intentions néfastes de se connecter à nous, nous allons créer un utilisateur appelé "administrateur". Vous pouvez interagir avec la base de données via le langage de requête de type SQL InfluxDB " InfluxQL ". Pour créer un nouvel utilisateur, nous exécuterons une requête
create user.
root@node#~: influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGESDans la même interface CLI, nous créerons une base de données «métriques», dans laquelle nous stockerons nos métriques.
> CREATE DATABASE metricsEnsuite, nous allons configurer InfluxBD (
/etc/influxdb/influxdb.conf) pour ouvrir l'interface sur le port 24589 (UDP) avec une connexion directe à la base de données "metrics" pour prendre en charge CollectD. Nous devrons également télécharger le fichier types.dbet le placer à l'adresse /usr/share/collectd/(ou dans tout autre dossier) pour déterminer correctement les données que CollectD transmet dans son format natif .
root@node#~: nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"Vous pouvez en savoir plus sur CollectD dans la configuration dans la documentation .
CollectD

CollectD dans notre infrastructure de surveillance agira comme un agrégateur de données qui simplifie le transfert de données vers InfluxDB. Par définition, CollectD collecte des métriques à partir du CPU, de la RAM, des disques durs, des interfaces réseau, des processus ... Le potentiel de ce programme est illimité, surtout si l'on considère le large éventail de plugins déjà disponibles , ainsi qu'un ensemble de plugins prévus .
Comme vous pouvez le voir, l'installation de CollectD est simple:
root@node#~: apt-get install collectd collectd-utilsIllustrons comment CollectD fonctionne avec un exemple simplifié. Disons que je veux connaître le nombre de processus sur mon nœud. Pour vérifier cela, CollectD effectuera un appel API pour connaître le nombre de processus par unité de temps (5000 millisecondes par définition) et rien de plus. Dès que l'agrégateur reçoit les données, il les transfère vers InfluxDB pour configuration via un module (appelé «Réseau»), que nous devrons configurer.
Ouvrez le fichier avec notre éditeur
/etc/collectd.conf, faites défiler jusqu'à la section Networket modifiez-la comme indiqué ci-dessous. Assurez-vous de spécifier l'adresse IP où se trouve l'interface InfluxDB ( INFLUXDB_IP).
root@node#~: nano /etc/collectd.conf
...
<Plugin network>
<Server "INFLUXDB_IP" "24589">
</Server>
ReportStats true
</Plugin>
...
Je suggère de changer le nom d'hôte dans le fichier de configuration qui est transmis à InfluxDB (dans notre infrastructure, il s'agit d'une base de données "centralisée" puisqu'elle est située sur le même nœud). Ainsi, nous ne recevrons pas de données inutiles et le risque d'écrasement des données par d'autres nœuds disparaîtra.

Grafana

Un graphique vaut mille images
Compte tenu de la citation paraphrasée, l'observation des métriques d'infrastructure en temps réel à travers des graphiques et des tableaux nous permet d'agir efficacement et en temps opportun. Nous utiliserons Grafana pour créer et personnaliser le tableau de bord de nos graphiques et tableaux.
Grafana est un outil de métrique graphique gratuit, compatible avec un large éventail de bases de données (y compris InfluxDB), dans lequel l'utilisateur peut créer des alertes lorsqu'une partie des données répond à une condition spécifique. Par exemple, si votre processeur atteint son maximum, vous pouvez recevoir une alerte dans Slack, Mattermost, e-mail, etc. De plus, j'ai configuré mes alertes pour surveiller activement chaque cas lorsque quelqu'un «entre» dans mon infrastructure.
Grafana ne nécessite aucun paramétrage particulier: comme nous l'avons noté précédemment, InfluxDB "scanne" la variable "time". L'intégration elle-même est très simple: nous commencerons par importer la clé publique pour ajouter le package depuis le site officiel de Grafana (cela dépend de votre système d'exploitation):
root@node#~: wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
root@node#~: echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
root@node#~: apt-get update && apt-get install grafanaEnsuite, exécutons-le via systemctl:
root@node#~: systemctl start grafana-webMaintenant, lorsque nous naviguons vers la page localhost: 3000 dans le navigateur, nous devrions voir l'interface de connexion Grafana. Par définition, vous pouvez passer par le login administrateur et mot de passe administrateur (après les premières informations de connexion est recommandé de changer).

Allons à la section Sources et y ajoutons notre base de données Influx:


Nous voyons maintenant un petit rectangle vert sous l'étiquette Nouveau tableau de bord. Passez votre curseur dessus et sélectionnez Ajouter un panneau, puis Graphique:

Vous pouvez maintenant voir un graphique avec des données de test. Cliquez sur le titre de ce diagramme et cliquez sur Modifier. Avec Grafana, vous pouvez créer des requêtes intelligentes: vous n'avez pas besoin de connaître tous les champs de la base de données, Grafana vous les proposera à partir d'une liste de paramètres adaptés à l'analyse.
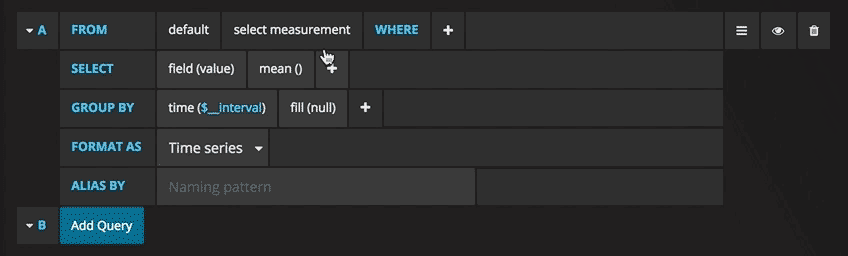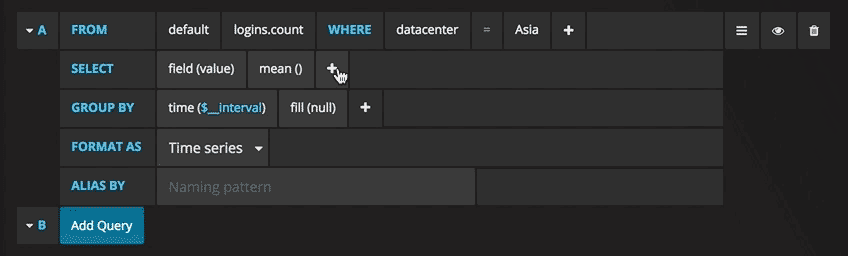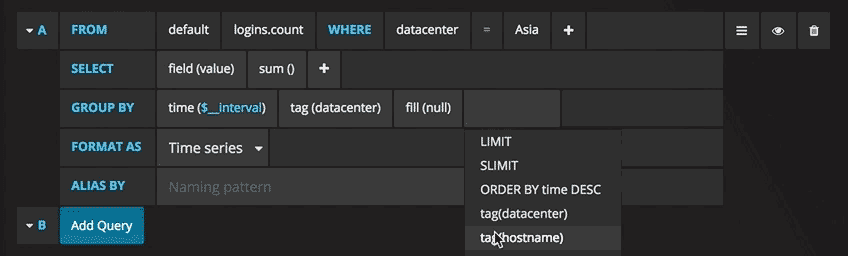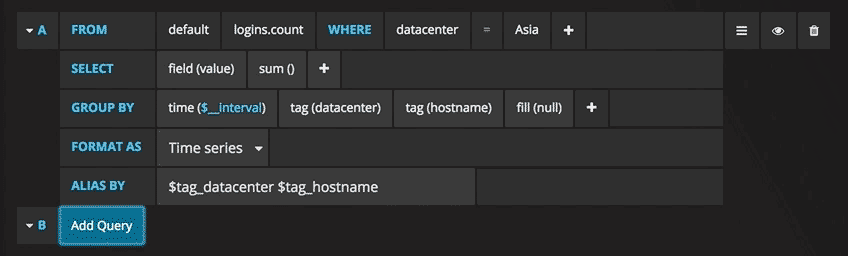
Rédiger des requêtes n'a jamais été aussi simple: sélectionnez simplement la métrique qui vous intéresse et cliquez sur Actualiser. Je recommande également de diviser les métriques par hôte pour faciliter l'isolement des problèmes. Si vous êtes intéressé par d'autres idées de tableaux de bord, vous pouvez consulter le site Web de Grafana pour toutes sortes d'exemples d'inspiration.
Nous avons remarqué que Grafana est un outil très extensible, et il nous permet de comparer des données très différentes les unes des autres. Il n'y a pas une seule métrique qui ne puisse être obtenue, donc seule votre ingéniosité vous limite. Suivez vos appareils et obtenez la vue d'ensemble la plus complète de votre infrastructure en temps réel!
