
Poursuite de la collection d'histoires sur Internet sur la façon dont les bogues ont parfois des manifestations complètement incroyables. La première partie est ici .
Plus de magie
Il y a quelques années, j'ai fouillé dans les placards qui abritaient un ordinateur PDP-10 qui appartenait au laboratoire d'intelligence artificielle du MIT. J'ai remarqué un petit interrupteur collé au cadre de l'une des armoires. Il était clair qu'il s'agissait d'un produit fait maison, ajouté par l'un des artisans du laboratoire (personne ne savait qui exactement).
Vous ne toucherez pas un interrupteur inconnu sur votre ordinateur sans savoir ce qu'il fait, car vous pourriez casser votre ordinateur. L'interrupteur a été signé de manière totalement inintelligible. Il avait deux positions, et les mots «magie» et «plus de magie» étaient griffonnés sur le corps métallique au crayon. L'interrupteur était dans la position la plus magique. J'ai appelé l'un des techniciens pour y jeter un œil. Il n'avait jamais vu une chose pareille auparavant. En y regardant de plus près, il s'est avéré qu'un seul fil va à l'interrupteur! L'autre extrémité du fil a disparu dans le fouillis de câbles à l'intérieur de l'ordinateur, mais la nature de l'électricité veut qu'un interrupteur ne fasse rien tant que vous n'y branchez pas deux fils.
Il était évident que c'était la blague stupide de quelqu'un. Après nous être assurés que le commutateur ne fait rien, nous le basculons. L'ordinateur s'est immédiatement évanoui.
Imaginez notre étonnement. Nous l'avons considéré comme une coïncidence, mais nous avons tout de même remis le bouton en position «plus magique» avant de démarrer l'ordinateur.
Un an plus tard, j'ai raconté cette histoire à un autre technicien, David Moon, pour autant que je me souvienne. Il a mis en doute mon adéquation, ou soupçonné de croire en la nature surnaturelle de cet interrupteur, ou a pensé que je plaisantais avec sa fausse histoire. Pour prouver mon point, je lui ai montré cet interrupteur, toujours collé au cadre et avec un seul fil, toujours dans la position "plus magique". Nous avons examiné de près l'interrupteur et le fil et avons constaté qu'il était mis à la terre. Cela semblait doublement dénué de sens: l'interrupteur était non seulement électriquement inopérant, mais également branché dans un endroit qui n'affectait rien. Nous l'avons déplacé dans une position différente.
L'ordinateur est devenu vide immédiatement.
Nous avons contacté Richard Greenblatt, qui était un technicien de longue date au MIT, qui était à proximité. Lui aussi n'avait jamais vu l'interrupteur. Je l'ai examiné, je suis arrivé à la conclusion que l'interrupteur était inutile, j'ai sorti le coupe-fil et j'ai coupé le fil. Ensuite, nous avons allumé l'ordinateur et il a commencé à fonctionner tranquillement.
Nous ne savons toujours pas comment ce commutateur a arrêté l'ordinateur. Il existe une hypothèse selon laquelle un petit court-circuit s'est produit près du contact de masse et la translation des positions des interrupteurs a changé la capacité électrique de sorte que le circuit a été interrompu lorsque des impulsions d'une durée d'un millionième de seconde le traversaient. Mais nous ne le saurons pas avec certitude. Nous pouvons seulement dire que le changement était magique.
Il est toujours dans mon sous-sol. C'est probablement idiot, mais je le garde généralement dans la position «plus magique».
En 1994, une autre explication de cette histoire a été proposée. Notez que le corps de l'interrupteur était en métal. Supposons qu'un contact sans deuxième fil soit connecté au corps (généralement le corps est mis à la terre, mais il y a des exceptions). Le corps de l'interrupteur était connecté au boîtier de l'ordinateur, qui était probablement mis à la terre. Ensuite, le circuit de masse à l'intérieur de la machine peut avoir un potentiel différent de celui du circuit de masse du châssis, et le changement de position de l'interrupteur a entraîné une chute ou une surtension de tension, et la machine a été redémarrée. Cet effet a probablement été découvert par quelqu'un qui connaissait la différence potentielle et a décidé de faire une telle blague.
OpenOffice n'imprime pas les mardis
Aujourd'hui, sur le blog, je suis tombé sur une mention d'un bug intéressant. Certaines personnes avaient du mal à imprimer des documents. Plus tard, quelqu'un a noté que sa femme se plaignait de ne pas pouvoir imprimer le mardi!
Dans les rapports de bogues, certains se sont d'abord plaints qu'il devait s'agir d'un bogue OpenOffice, car à partir de toutes les autres applications, il s'imprimait sans problème. D'autres ont noté que le problème va et vient. Un utilisateur a trouvé une solution: désinstallez OpenOffice et essuyez le système, puis réinstallez (n'importe quelle tâche simple sur Ubuntu). L'utilisateur a signalé mardi que son problème d'impression avait été résolu.
Deux semaines plus tard, il a écrit (mardi) que sa solution n’avait pas fonctionné. Environ quatre mois plus tard, la femme du hacker Ubuntu s'est plainte qu'OpenOffice n'imprimait pas les mardis. Imaginez cette situation:
Femme: Steve, l'imprimante est fermée le mardi.
Steve: C'est un jour de congé à l'imprimante, bien sûr, il n'imprime pas le mardi.
Femme: Je suis sérieuse! Je ne peux pas imprimer depuis OpenOffice les mardis.
Steve: (incrédule) D'accord, montre-moi.
Femme: Je ne peux pas te montrer.
Steve: (roulant des yeux) Pourquoi?
Épouse: Aujourd'hui, c'est mercredi!
Steve: (acquiesce, parle lentement) D'accord.
Le problème a été attribué à un programme appelé
file. Cet utilitaire * NIX utilise des modèles pour détecter les types de fichiers. Par exemple, si le fichier commence par%!et puis ça passe PS-Adobe-, puis c'est PostScript. On dirait qu'OpenOffice écrit des données dans un tel fichier. Mardi, il prend son uniforme %%CreationDate: (Tue MMM D hh:mm:...). Une erreur dans le modèle des fichiers Erlang JAM signifiait que Tuele fichier PostScript était reconnu comme un fichier Erlang JAM et, par conséquent, vraisemblablement, il n'était pas envoyé à l'impression.
Le modèle du fichier Erlang JAM ressemble à ceci:
4 string Tue Jan 22 14:32:44 MET 1991 Erlang JAM file - version 4.2
Et cela devrait ressembler à ceci:
4 string Tue\ Jan\ 22\ 14:32:44\ MET\ 1991 Erlang JAM file - version 4.2
Compte tenu de la multitude de types de fichiers que ce programme tente de reconnaître (plus de 1 600), les erreurs de modèle ne sont pas surprenantes. Mais l'ordre de comparaison conduit également à de fréquents faux positifs. Dans ce cas, le type Erlang JAM a été mappé sur le type PostScript.
Paquets de la mort
J'ai commencé à les appeler ainsi parce que c'étaient exactement des paquets de mort.
Star2Star s'est associé à un fabricant de matériel qui a créé les deux dernières versions de notre système client local.
Il y a environ un an, nous avons publié une mise à jour pour ce matériel. Tout a commencé assez simple, suivant la loi habituelle de Moore. Plus gros, meilleur, plus rapide, moins cher. Le nouveau matériel était 64 bits, avait 8 fois plus de mémoire, avait plus de disques et avait quatre ports Intel Gigabit Ethernet (mon fabricant préféré de contrôleurs Ethernet). Nous avions (et avons encore) de nombreuses idées sur la façon d'utiliser ces ports. En général, le morceau de fer était incroyable.
La nouveauté a traversé des tests de performances et de fonctionnalités. La vitesse est élevée et la fiabilité. Idéalement. Ensuite, nous avons déployé lentement l'équipement sur plusieurs sites de test. Bien sûr, des problèmes ont commencé à se poser.
Une recherche rapide sur Google suggère que le contrôleur Ethernet Intel 82574L avait au moins quelques problèmes. En particulier, des problèmes avec l'EEPROM, des bogues dans ASPM, des astuces avec MSI-X, etc. Nous résolvons chacun d'eux depuis plusieurs mois. Et nous pensions que nous avions terminé.
Mais non. Cela n'a fait qu'empirer.
Je pensais avoir conçu et déployé l'image logicielle parfaite (et le BIOS). Cependant, la réalité était différente. Les modules ont continué à échouer. Parfois, ils ont récupéré après un redémarrage, parfois non. Cependant, une fois le module restauré, il a dû être testé.
Sensationnel. La situation devenait bizarre.
Les bizarreries ont continué et j'ai finalement décidé de retrousser mes manches. J'ai eu la chance de trouver un revendeur très patient et serviable qui est resté avec moi sur mon téléphone pendant trois heures pendant que je collectais des données. À ce point client, pour une raison quelconque, le contrôleur Ethernet pourrait tomber lors de la transmission du trafic vocal sur le réseau.
Je vais m'arrêter là-dessus plus en détail. Quand je dis que le contrôleur Ethernet «aurait pu tomber en panne», cela signifie qu'il PEUT ÊTRE FALLED. Le système et l'interface Ethernet semblaient bien, et après l'envoi d'une quantité aléatoire de trafic, l'interface pouvait signaler une erreur matérielle (perte de communication avec le PHY) et perdre la connexion. Les voyants du commutateur et de l'interface se sont littéralement éteints. Le contrôleur était mort.
Il était possible de le ramener à la vie uniquement en éteignant et en rallumant l'appareil. La tentative de redémarrage d'un module de noyau ou d'une machine a entraîné une erreur d'analyse PCI. L'interface est restée morte jusqu'à ce que la machine soit physiquement débranchée et rebranchée. Dans la plupart des cas, pour nos clients, cela signifiait retirer du matériel.
Lors du débogage avec ce revendeur très patient, j'ai commencé à arrêter de recevoir des paquets lorsque l'interface s'est plantée. À la fin, j'ai identifié un modèle: le dernier paquet de l'interface était toujours
100 Trying provisional response, et il avait toujours une certaine longueur. Ce n'est pas tout, j'ai finalement retracé cette réponse (d'Asterisk) à la demande INVITE originale spécifique à l'un des téléphones des fabricants.
J'ai appelé le revendeur, rassemblé les gens et montré les preuves. Même si c'était vendredi soir, tout le monde a pris part aux travaux et assemblé un banc d'essai à partir de nos nouveaux équipements et téléphones de ce fabricant.
Nous nous sommes assis dans une salle de conférence et avons commencé à composer des numéros aussi vite que nos doigts le pouvaient. Il s'est avéré que nous pouvons reproduire le problème! Pas à chaque appel et pas sur chaque appareil, mais de temps en temps, nous avons réussi à mettre le contrôleur Ethernet sous tension, et de temps en temps, nous ne l'avons pas fait. Après avoir perdu de la puissance, nous avons réessayé et nous avons réussi. Dans tous les cas, comme le sait quiconque a tenté de diagnostiquer des problèmes techniques, la première étape consiste à reproduire le problème. Nous avons enfin réussi.
Croyez-moi, cela a pris du temps. Je sais comment fonctionne la pile OSI. Je sais comment les logiciels sont segmentés. Je sais que le contenu des paquets SIP ne devrait pas affecter l'adaptateur Ethernet. Tout cela n'a aucun sens.
Enfin, nous avons réussi à isoler le problème des paquets dans l'intervalle entre leur arrivée sur notre appareil et sur le port de mise en miroir du commutateur. Il s'est avéré que le problème venait de la demande
INVITE, pas de la réponse 100 Trying. Il n'y avait 100 Tryingpas de réponse dans les données capturées sur le port en miroir .
Il était nécessaire de gérer cela
INVITE. Le problème était-il lié à la gestion de ce paquet par le démon de l'espace utilisateur? Peut-être que la transmission était le problème 100 Trying? Un de mes collègues a suggéré de fermer l'application SIP et de voir si le problème persiste. Sans cette application, les packages100 Tryingn'ont pas été transmises.
Il était nécessaire d'améliorer d'une manière ou d'une autre la transmission des paquets problématiques. Nous avons isolé le paquet transmis par le téléphone
INVITEet l' avons joué en utilisant tcpreplay. Ça a marché. Pour la première fois depuis des mois, nous avons pu supprimer des ports sur commande avec un seul paquet. C'était un progrès significatif, et il était temps de rentrer chez soi, c'est-à-dire de refaire le banc d'essai dans le laboratoire à domicile!
Avant de continuer mon histoire, je veux vous parler d'une excellente application open source que j'ai trouvée. Ostinato fait de vous un maître des paquets. Ses possibilités sont littéralement infinies. Sans cette application, je n'aurais pas pu progresser davantage.
Armé de cet outil de package polyvalent, j'ai commencé à expérimenter. J'ai été étonné de ce que j'ai trouvé.
Tout a commencé par une étrange bizarrerie SIP / SDP. Jetez un œil à ce SDP:
v=0
o=- 20047 20047 IN IP4 10.41.22.248
s=SDP data
c=IN IP4 10.41.22.248
t=0 0
m=audio 11786 RTP/AVP 18 0 18 9 9 101
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:0 PCMU/8000
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:9 G722/8000
a=rtpmap:9 G722/8000
a=fmtp:101 0-15
a=rtpmap:101 telephone-event/8000
a=ptime:20
a=sendrecv
Oui c'est vrai. La proposition de transmission du son est dupliquée. C'est un problème, mais encore une fois, qu'est-ce que le contrôleur Ethernet a à voir avec cela?! Eh bien, à part le fait que rien d'autre n'augmente la taille de la trame Ethernet ... Mais attendez, il y avait beaucoup de trames Ethernet réussies dans les paquets transmis. Certains d'entre eux étaient plus petits, d'autres plus. Il n'y a eu aucun problème avec eux. J'ai dû creuser davantage. Après quelques tours de kung-fu avec Ostinato et un tas de reconnexions électriques, j'ai pu identifier la relation problématique (avec le cadre du problème). Remarque: nous examinerons les valeurs hexadécimales.
Une panne d'interface a été déclenchée par une valeur d'octet spécifique à un décalage spécifique. Dans notre cas, c'était la valeur hexadécimale
32c 0x47f. En ASCII, hexadécimal 32est2... Devinez d'où ça vient 2.
a=ptime:20
Tous nos SDP étaient identiques (y compris
ptime). Tous les URI source et destination étaient identiques. Les seules différences étaient le numéro de l'appelant, les balises et les identifiants de session uniques. Les paquets problématiques avaient une telle combinaison d'identifiants d'appel, d'étiquettes et de branches, ce qui ptimeaboutissait à une valeur 2avec un décalage 0x47f.
Boom! Avec les bons identifiants, tags et branches (ou tout autre indésirable aléatoire), un "bon paquet" pourrait se transformer en un paquet "tueur" dès que la ligne se
ptimeterminait à une certaine adresse. C'était très étrange.
Lors de la génération de packages, j'ai expérimenté différentes valeurs hexadécimales. La situation s'est avérée encore plus compliquée. Il s'est avéré que le comportement du contrôleur dépendait entièrement de cette valeur particulière située à l'adresse spécifiée dans le premier paquet reçu. L'image était comme ça:
0x47f = 31 HEX (1 ASCII) -
0x47f = 32 HEX (2 ASCII) -
0x47f = 33 HEX (3 ASCII) -
0x47f = 34 HEX (4 ASCII) - (inoculation)
Quand j'ai dit "n'affecte pas", je voulais dire non seulement ne tue pas l'interface, mais aussi n'inocule pas (plus ou moins). Et quand je dis que "l'interface plante", eh bien, souvenez-vous de ma description? L'interface est en train de mourir. Complètement.
Après de nouveaux tests, j'ai constaté que le problème persiste avec toutes les versions de Linux que j'ai pu trouver, avec FreeBSD, et même en allumant la machine sans support de démarrage! Il s'agissait du matériel, pas du système d'exploitation. Sensationnel.
De plus, avec l'aide d'Ostinato, j'ai pu créer différentes versions du package killer: HTTP POST, ICMP echo request, et autres. Presque tout ce que je voulais. Avec un serveur HTTP modifié qui générait des données en octets (en fonction des en-têtes, de l'hôte, etc.), il était facile de créer la 200e requête HTTP pour contenir le paquet de mort et tuer les machines clientes derrière le pare-feu!
J'ai déjà expliqué à quel point la situation était étrange. Mais le plus étrange était avec le vaccin. Il s'est avéré que si le premier paquet reçu contenait une valeur (parmi celles que j'ai essayées), à l'exception de
1, 2ou 3, alors l'interface devenait invulnérable à tous les paquets de mort (contenant les valeurs 2ou 3). De plus, les codes et les attributs ptimeont été multiples de 10: 10, 20, 30, 40. En fonction de la combinaison de l'ID d'appel, de la balise, de la branche, de l'adresse IP, de l'URI, etc. (avec ce SDP bogué), ces attributs valides ptimes'alignent dans une séquence parfaite. Incroyable!
Il est soudainement devenu clair pourquoi le problème se produisait sporadiquement. C'est incroyable que j'ai pu le comprendre. Je travaille avec des réseaux depuis 15 ans et je n'ai jamais rien vu de tel. Et je doute que je vous reverrai. J'espère ...
J'ai contacté deux ingénieurs d'Intel et leur ai envoyé une démo afin qu'ils puissent reproduire le problème. Après avoir expérimenté pendant quelques semaines, ils ont compris que le problème venait de l'EEPROM des contrôleurs 82574L. Ils m'ont envoyé une nouvelle EEPROM et un outil d'écriture. Malheureusement, nous n'avons pas pu le distribuer, et en plus, il était nécessaire de décharger et recharger le module noyau e1000e, donc l'outil n'était pas adapté à notre environnement. Heureusement (avec un peu de connaissance du schéma EEPROM) j'ai pu écrire un script bash puis par magie
ethtoola sauvegardé les valeurs "fixes" et les a enregistrées dans les systèmes où le bogue s'est manifesté. Maintenant, nous pouvons identifier les périphériques problématiques. Nous avons contacté notre fournisseur pour appliquer le correctif à tous les appareils avant de nous l'envoyer. On ne sait pas combien de ces contrôleurs Intel Ethernet ont déjà été vendus.
Une palette de plus
En 2005, j'ai eu un problème inexpliqué au travail. Un jour après l'arrêt non planifié (en raison de l'ouragan), j'ai commencé à recevoir des appels d'utilisateurs qui se plaignaient de délais d'attente lors de la connexion à la base de données. Comme nous avions un réseau très simple pour 32 nœuds et avec une bande passante pratiquement inutilisée, j'ai été alarmé par le fait que le serveur avec la base de données envoyait un ping normalement pendant 15 à 20 minutes, puis que les réponses "demande expirée" arrivaient en deux minutes environ. Ce serveur exécutait la surveillance des performances et d'autres outils et effectuait un ping à partir de divers emplacements. À l'exception du serveur, le reste des machines pourrait communiquer avec d'autres membres du réseau à tout moment. J'ai recherché un commutateur ou une connexion défectueux, mais je n'ai pas trouvé d'explication pour les échecs aléatoires et intermittents.
J'ai demandé à un collègue de regarder les LED sur l'interrupteur dans l'entrepôt pendant que je traçais et reconnectais divers appareils. Cela a pris 45 à 50 minutes, un collègue m'a dit à la radio "celui-ci est éteint, celui-là s'est levé". J'ai demandé s'il avait remarqué un motif.
- Oui j'ai remarqué. Mais vous penserez que je suis fou. Chaque fois qu'un chariot élévateur sort une palette du hall d'expédition, un timeout se produit après deux secondes sur le serveur.
- QUELLE???
- Ouais. Et le serveur est restauré lorsque le chargeur commence à expédier une nouvelle commande.
J'ai couru pour regarder le chariot élévateur et j'étais sûr qu'il marquait la réussite de la commande en allumant un magnétron géant. Incontestablement, les ondes électromagnétiques du condensateur entraînent une rupture du continuum spatio-temporel et interrompent temporairement le fonctionnement de la carte réseau serveur située dans une autre pièce à 50 mètres. Non. Le chariot élévateur empilait simplement des boîtes plus grandes sur la palette, avec des boîtes plus petites sur le dessus, tout en scannant chaque boîte avec un lecteur de codes-barres sans fil. Ah! C'est probablement le scanner qui accède au serveur de base de données, provoquant l'échec des autres requêtes. Nan. J'ai vérifié et j'ai découvert que le scanner n'avait rien à voir avec cela. Le routeur sans fil et son onduleur dans le hall d'expédition étaient correctement configurés et fonctionnaient normalement. La raison était autre chose, car avant la fermeture due à l'ouragan, tout fonctionnait bien.
Dès que le prochain délai a commencé, j'ai couru vers le hall d'expédition et j'ai regardé le chargeur remplir la palette suivante. Dès qu'il avait placé quatre grandes boîtes de shampoing sur un plateau vide, le serveur était à nouveau en panne! Je ne croyais pas à l'absurdité de ce qui se passait, et pendant encore cinq minutes j'ai enlevé et mis des boîtes de shampoing, avec le même résultat. J'étais sur le point de tomber à genoux et de prier pour la miséricorde du Dieu intranet lorsque j'ai remarqué que le routeur dans le hall d'expédition était suspendu à environ 30 cm sous le niveau des cartons sur la palette. Il y a un indice!
Lorsque de grandes boîtes étaient placées sur une palette, le routeur sans fil perdait la vue de l'entrepôt extérieur. Après dix minutes, j'ai résolu le problème. Voici ce qui s'est passé. Pendant l'ouragan, il y a eu une panne de courant qui a laissé tomber le seul appareil non connecté à l'onduleur - un routeur sans fil de test dans mon bureau. Les paramètres par défaut l'ont transformé en un répéteur pour le seul autre routeur sans fil suspendu dans le hall d'expédition. Les deux appareils ne pouvaient communiquer entre eux que lorsqu'il n'y avait pas de palette entre eux, mais même dans ce cas, le signal n'était pas trop fort. Lorsque les routeurs ont parlé, ils ont créé une boucle dans mon petit réseau, puis tous les autres paquets envoyés au serveur de base de données ont été perdus. Le serveur avait son propre commutateur depuis le routeur principal, donc, en tant que nœud de réseau, il était beaucoup plus éloigné.La plupart des autres ordinateurs étaient sur le même commutateur 16 ports, donc je pouvais envoyer un ping entre eux sans aucun problème.
En une seconde, j'ai résolu un problème que je tourmentais depuis quatre heures: j'ai mis le routeur de test hors tension. Il n'y avait plus de délais d'attente sur le serveur.
Comme le film Tron, uniquement sur un ordinateur Apple IIgs
Un de mes films préférés quand j'étais enfant était Tron, qui a été tourné au début des années 1980. Il parlait d'un programmeur qui était «numérisé» et absorbé dans le monde informatique habité par des programmes personnalisés. Le protagoniste a rejoint un groupe de résistance pour tenter de renverser l'oppresseur Master Control Program (MCP), un programme rebelle qui a évolué, a acquis une soif de pouvoir et a tenté de prendre le contrôle du système informatique du Pentagone.
Dans l'une des scènes les plus impressionnantes du programme, les personnages courent sur des cycles légers - des voitures à deux roues qui ressemblent à des motos qui laissent des murs derrière eux. L'un des protagonistes a forcé les pepelats ennemis à s'écraser dans le mur de l'arène, faisant un trou traversant. Les héros ont affronté leurs adversaires et ont fui par le trou vers la liberté - le premier pas vers le renversement du MCP.
Quand j'ai regardé le film, je n'avais aucune idée que des années plus tard, je recréerais par inadvertance le monde de Tron, des programmes rebelles et tout le reste sur un ordinateur Apple IIgs.
Voici comment ça s'est passé. Quand j'ai commencé à apprendre à programmer, j'ai décidé de créer un jeu de cycle lumineux avec Tron. Avec mon ami Marco, j'ai écrit un programme sur Apple IIgs en ORCA / Pascal et assembleur 65816. Pendant le jeu, l'écran a été peint en noir avec une bordure blanche. Chaque ligne représente l'un des joueurs. Nous avons affiché les scores du jeu dans une rangée en bas de l'écran. Graphiquement, ce n'était pas le programme le plus avancé, mais c'était simple et amusant. Elle ressemblait à ceci:

Le jeu supportait jusqu'à quatre joueurs s'ils étaient assis devant un clavier. Ce n'était pas pratique, mais cela fonctionnait. Nous étions rarement en mesure d'obtenir suffisamment de personnes pour utiliser les quatre cycles d'éclairage, alors Marco a ajouté des joueurs contrôlés par ordinateur qui pouvaient raisonnablement rivaliser.
Course aux armements
Le jeu était déjà très drôle, mais nous voulions expérimenter. Nous avons ajouté des roquettes pour donner aux joueurs une chance d'échapper à un accident imminent. Comme Marco l'a décrit plus tard:
Les humains et l'IA avaient chacun trois fusées qui pouvaient être utilisées pendant le jeu. Lorsque la fusée a heurté le mur, il y a eu une «explosion» dont le fond était peint en noir, supprimant ainsi des sections de la traînée laissées par les cycles d'éclairage précédents.
Bientôt, les joueurs et les ordinateurs pourraient se frayer un chemin dans des situations difficiles avec des fusées. Bien que les puristes de Tron se moquent de cela, les programmes du film n'avaient pas le luxe de fusées.
L'évasion
Comme pour tous les événements inhabituels et bizarres, c'était aussi inattendu.
Une fois, alors que Marco et moi jouions contre deux joueurs informatiques, nous avons piégé l'une des boucles d'IA entre son propre mur et le bord inférieur de l'écran. Anticipant un accident imminent, il a tiré une roquette, comme toujours auparavant. Mais cette fois, au lieu d'un mur, il a tiré sur le bord de l'écran, qui ressemblait à la traînée d'un des cycles lumineux. Le missile a frappé la frontière, a laissé un trou de la taille d'un cycle de lumière et l'ordinateur est immédiatement sorti du terrain de jeu à travers. Nous avons regardé avec confusion le cycle lumineux alors qu'il traversait la ligne de score. Il évitait facilement d'entrer en collision avec les symboles, puis quittait complètement l'écran.
Et immédiatement après cela, le système s'est écrasé.

Nos esprits oscillaient alors que nous essayions de comprendre ce qui s'était passé. L'ordinateur a trouvé un moyen de sortir du jeu. Lorsque le cycle lumineux a quitté l'écran, il s'est échappé dans la mémoire de l'ordinateur, tout comme dans le film. Nos mâchoires sont tombées quand nous avons réalisé ce qui s'était passé.
Qu'avons-nous fait lorsque nous avons découvert un défaut dans notre programme qui pouvait régulièrement planter tout le système? Nous avons recommencé. Nous avons d'abord essayé de sortir des limites nous-mêmes. Puis ils ont forcé l'ordinateur à s'enfuir à nouveau. Chaque fois que nous avons été récompensés par des plantages enchanteurs du système. Parfois, le voyant du lecteur clignotait alors que le lecteur grognait sans cesse. D'autres fois, l'écran était rempli de personnages dénués de sens, ou le locuteur faisait un grincement ou un bourdonnement sourd. Et parfois, tout arrivait en même temps, et l'ordinateur était dans un état de désarroi complet.
Pourquoi est-ce arrivé? Pour comprendre cela, regardons l'architecture de l'ordinateur Apple IIgs.
Mémoire (non) protégée
Le système d'exploitation Apple IIgs n'avait pas de mémoire protégée, qui est apparue dans les systèmes d'exploitation ultérieurs lorsque des zones de mémoire ont été attribuées à un programme et protégées contre tout accès extérieur. Par conséquent, un programme sous Apple IIgs pouvait lire et écrire n'importe quoi (sauf ROM). IIgs utilisait des E / S liées à la mémoire pour accéder à des périphériques comme le lecteur de disquette, il était donc possible d'activer le lecteur de disquette en lisant à partir d'une zone spécifique de la mémoire. Cette architecture permettait aux programmes graphiques de lire et d'écrire directement dans la mémoire de l'écran.
Le jeu utilisait l'un des modes graphiques Apple IIgs - Super Hi-Res: une résolution étonnante de 320x200 pixels avec une palette de 16 couleurs. Pour sélectionner une palette, le programmeur a spécifié 16 entrées (numérotées de 0 à 15 ou de 0 $ à F au format hexadécimal) pour les valeurs de couleur 12 bits. Pour dessiner sur l'écran, vous pouvez lire et écrire des couleurs directement dans la mémoire vidéo.
Algorithme de détection de collision
Nous avons profité de cette fonctionnalité et implémenté un détecteur de crash en lisant directement à partir de la mémoire vidéo. Le jeu a calculé pour chaque cycle de lumière sa prochaine position en fonction de la direction actuelle, et a lu ce pixel dans la mémoire vidéo. Si la position était vide, c'est-à-dire représentée par un pixel noir (entrée dans la palette $ 0), alors le jeu continuait. Mais si la position a été prise, le joueur s'est écrasé dans le cycle lumineux ou le cadre blanc de l'écran (entrée dans la palette 15 ou $ F). Exemple:
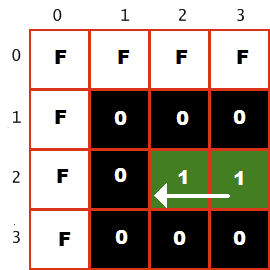
Le coin supérieur gauche de l'écran est affiché ici. La couleur $ F indique une bordure blanche et la couleur $ 1 indique le cycle de lumière verte du joueur. Il se déplace vers la gauche comme indiqué par la flèche, c'est-à-dire que le pixel suivant est vide, sa couleur est 0 $. Si le joueur continue à se déplacer dans cette direction pendant plus d'un tour, il heurtera un mur (couleur $ F) et se brisera.
Aller plus loin
L'algorithme de détermination du pixel suivant à l'aide des mathématiques assembleur a rapidement calculé l'adresse mémoire d'un pixel au-dessus, en dessous, à gauche ou à droite du pixel actuel. Comme tout pixel de l'écran était une adresse en mémoire, l'algorithme a simplement calculé une nouvelle adresse à lire. Et lorsque le cycle lumineux a quitté l'écran, l'algorithme a déterminé une place dans la mémoire du système pour rechercher une collision avec un mur. Cela signifiait que le cycle de lumière traversait maintenant la mémoire du système, activant inutilement des bits et «écrasant» la mémoire.
L'écriture à des emplacements aléatoires dans la mémoire système n'est pas une sage décision architecturale. Sans surprise, le jeu s'est écrasé à cause de cela. Un joueur humain ne roulera pas à l'aveuglette et se plantera généralement immédiatement, ce qui limite la portée des problèmes du système. Et l'IA n'a pas une telle faiblesse. L'ordinateur scanne instantanément les positions autour de lui pour déterminer s'il heurte un mur et change de direction. Autrement dit, selon l'ordinateur, la mémoire système n'était pas différente de la mémoire d'écran. Comme Marco l'a décrit:
, , . , , 0. «» , . «», - - , , — . , - , .
En conséquence, nous avons non seulement recréé la course du cycle léger du film, mais aussi l'évasion elle-même. Comme dans le film, l'évasion a eu de grandes conséquences.
C'est difficile à répéter aujourd'hui, car les systèmes d'exploitation ont acquis une mémoire protégée. Mais je me demande toujours s'il existe des programmes comme Tron qui essaient d'échapper à leurs «espaces protégés» pour tenter d'empêcher le code rebelle de l'IA de prendre le contrôle du Pentagone.
Je suppose que pour le savoir, nous devons attendre l'invention de la numérisation de la conscience.
Asseyez-vous pour vous connecter
Chaque programmeur sait que le débogage est difficile. Bien que, pour les excellents débogueurs, le travail semble d'une simplicité trompeuse. Les programmeurs affolés décrivent un bug qu'ils passent des heures à attraper, le maître pose quelques questions et après quelques minutes, les programmeurs voient le code défectueux devant eux. Un expert en débogage n'oublie pas qu'il y a toujours une explication logique, quel que soit le comportement mystérieux du système à première vue.
Cette attitude est illustrée par une histoire qui a eu lieu au IBM Yorktown Heights Research Center. Le programmeur a récemment installé un nouveau poste de travail. Tout allait bien quand il était assis devant l'ordinateur, mais il ne pouvait pas se connecter alors qu'il était debout. Ce comportement était toujours reproduit: le programmeur se connectait toujours assis, debout - il ne pouvait même pas une seule fois.
Beaucoup d'entre nous restaient assis là et se demandaient. Comment l'ordinateur pouvait-il savoir s'ils se tenaient devant lui ou s'ils étaient assis? Cependant, les bons débogueurs savent qu'il doit y avoir une raison. La première chose qui me vient à l'esprit est l'électricité. Fil cassé sous le tapis ou électricité statique? Mais les problèmes électriques sont rarement reproduits à 100% du temps. L'un des collègues a finalement posé la bonne question: comment le programmeur s'est-il connecté assis et debout? Essayez-le vous-même.
La raison était le clavier: les deux boutons étaient inversés. Lorsque le programmeur était assis, il tapait à l'aveugle et le problème passait inaperçu. Et quand il se leva, cela le troubla, il chercha des boutons et les appuya. Armé de cet indice et d'un tournevis, l'expert en débogage a échangé les boutons et tout a fonctionné.
Le système bancaire déployé à Chicago a bien fonctionné pendant de nombreux mois. Mais il s'est arrêté de manière inattendue lorsqu'il a été utilisé pour la première fois pour traiter des données internationales. Les programmeurs ont fouillé le code pendant des jours, mais n'ont pas pu trouver une seule commande ayant conduit à l'arrêt du programme. Lorsqu'ils ont examiné de plus près son comportement, ils ont constaté que le programme prendrait fin si les données de l'Équateur y étaient entrées. L'analyse a montré que lorsque l'utilisateur tapait le nom de la majuscule (Quito), le programme l'interprétait comme une commande de sortie!
Un jour, Bob Martin est tombé sur un système qui «fonctionnait une fois deux fois». Il a traité correctement la première transaction et il y a eu des problèmes mineurs dans toutes les transactions suivantes. Lorsque le système a été redémarré, il a de nouveau traité correctement la première transaction et a échoué sur toutes les suivantes. Lorsque Bob a décrit ce comportement comme «s'exécutant une fois deux fois», les développeurs ont immédiatement réalisé qu'ils devaient rechercher une variable correctement initialisée lorsque le programme était chargé, mais qui n'avait pas été réinitialisée après la première transaction. Dans tous les cas, les bonnes questions ont permis aux programmeurs avisés d'identifier rapidement les erreurs désagréables: «Qu'avez-vous fait différemment lorsque vous étiez debout et assis? Montrez-moi comment vous vous connectez dans les deux cas "," Qu'as-tu entré exactement avant la fin du programme? " «Le programme fonctionnait-il correctement avant le début des plantages? Combien de fois?"
Rick Lemons a déclaré que la meilleure leçon qu'il avait apprise sur le débogage était quand il a regardé le magicien jouer. Il avait fait une douzaine de tours impossibles, et Lemons sentit qu'il y croyait. Il s'est alors rappelé que l'impossible n'est pas possible, et il a testé chaque astuce pour prouver cette incohérence évidente. Citrons a commencé avec ce qui était une vérité inébranlable - les lois de la physique, et à partir d'elles, il a commencé à chercher des explications simples pour chaque astuce. Cette attitude fait de Lemons l'un des meilleurs débogueurs que j'ai rencontrés.
Le meilleur livre de débogage à mon avis est The Medical Detectives, écrit par Berton Roueche et publié par Penguin en 1991. Les héros du livre déboguent des systèmes complexes, d'une personne modérément malade à des villes très malades. Les méthodes de résolution de problèmes utilisées ici peuvent être directement utilisées dans le débogage des systèmes informatiques. Ces vraies histoires sont aussi fascinantes que n'importe quelle fiction.
Le boîtier de courrier électronique de 500 milles
Voilà une situation qui me paraissait inconcevable ... J'ai failli refuser d'en parler car c'est un super vélo pour les conférences. J'ai légèrement modifié l'histoire pour protéger le coupable, pour écarter les détails inutiles et ennuyeux, et dans l'ensemble pour rendre l'histoire plus engageante.
Il y a plusieurs années, je maintenais un système de messagerie sur le campus. Le chef du département des statistiques m'a appelé.
- Nous avons un problème avec l'envoi de lettres.
- Quel est le problème?
«Nous ne pouvons pas envoyer de lettres à plus de 500 miles.
Je me suis étouffé avec mon café.
- Pas compris.
«Nous ne pouvons pas envoyer de lettres du département à plus de 500 miles. En fait, un peu plus loin. Environ 520 miles. Mais c'est la limite.
"Hmm ... En fait, le courrier électronique ne fonctionne pas de cette façon," répondis-je, essayant de contrôler la panique dans ma voix. Vous ne pouvez pas montrer de panique dans une conversation avec le chef d'un département, même un tel que le département des statistiques. - Pourquoi avez-vous décidé que vous ne pouvez pas envoyer de lettres à plus de 500 miles?
«Je n'ai pas décidé ,» répondit-il d'un ton sérieux. - Tu vois, quand on a remarqué ce qui se passait il y a quelques jours…
- Tu as attendu quelques JOURS? Je l'interrompis d'une voix tremblante. - Et tu ne pouvais pas envoyer de lettres tout ce temps?
- Nous pourrions envoyer. Juste pas plus…
»« Cinq cents milles, oui », finis-je pour lui. - Clair. Mais pourquoi n'avez-vous pas appelé plus tôt?
«Eh bien, jusqu'à présent, nous n'avions pas suffisamment de données pour être sûrs de ce qui se passait.
Exactement, c'est le chef des statistiques .
- Quoi qu'il en soit, j'ai demandé à l'un des géostatisticiens de travailler avec ça ...
- Les géostatisticiens ...
- Oui, et elle a fait une carte montrant le rayon dans lequel on peut envoyer des lettres, un peu plus de 500 milles. Il y a plusieurs endroits dans cette zone où nos lettres n'arrivent pas du tout ou périodiquement, mais en dehors du rayon nous ne pouvons rien envoyer du tout.
«Je vois», ai-je dit, et j'ai laissé tomber ma tête dans mes mains. - Quand ça a commencé? Vous l'avez dit il y a quelques jours, mais nous n'avons rien changé à vos systèmes.
- Un consultant est venu, a corrigé et redémarré notre serveur. Mais je l'ai appelé et il m'a dit qu'il n'avait pas touché au système de messagerie.
"D'accord, laissez-moi jeter un coup d'œil et vous rappeler," répondis-je, à peine croyant que je participais à une telle chose. Aujourd'hui n'était pas le premier avril. J'ai essayé de me souvenir si quelqu'un me devait une farce.
Je me suis connecté au serveur de leur service et j'ai envoyé quelques courriels de vérification. Cela a eu lieu dans le Triangle de recherche de la Caroline du Nord et la lettre est arrivée dans ma boîte aux lettres sans aucun problème. Tout comme les lettres envoyées à Richmond, Atlanta et Washington. Une lettre a également été envoyée à Princeton (400 miles).
Mais ensuite j'ai envoyé une lettre à Memphis (600 miles). Cela n'est pas venu. À Boston, cela n'est pas venu. À Detroit, il n'est pas venu. J'ai sorti mon carnet d'adresses et j'ai commencé à y envoyer des lettres. Il est venu à New York (420 milles), mais n'est pas venu à Providence (580 milles).
J'ai commencé à douter de ma santé mentale. Écrit à un ami en Caroline du Nord dont le fournisseur était à Seattle. Heureusement, la lettre n'est pas arrivée. Si le problème était lié à l'emplacement des destinataires, et non à leurs serveurs de messagerie, j'éclaterais probablement en sanglots.
Après avoir compris que le problème existait (incroyablement) et reproductible, j'ai commencé à analyser le fichier sendmail.cf. Il avait l'air bien. Comme d'habitude. Je l'ai comparé à sendmail.cf dans mon répertoire personnel. Il n'y avait aucune différence - c'était le fichier que j'ai écrit. Et j'étais à peu près sûr de ne pas avoir inclus l'option
FAIL_MAIL_OVER_500_MILES. Dans la confusion, j'ai telnetted le port SMTP. Le serveur a répondu avec joie avec une bannière Sendmail de SunOS.
Attendez ... la bannière Sendmail de SunOS? À l'époque, Sun expédiait toujours Sendmail 5 avec son système d'exploitation, même si Sendmail 8 était déjà complètement dopé. Comme j'étais un bon administrateur système, j'ai introduit Sendmail 8 comme standard. De plus, comme j'étais un bon administrateur système, j'ai écrit sendmail.cf, qui utilisait les longues options d'auto-documentation et les noms de variables disponibles dans Sendmail 8, plutôt que les codes de ponctuation cryptiques utilisés dans Sendmail 5.
Tout s'est mis en place. et je me suis de nouveau étouffé avec mon café déjà refroidi. Il semble que lorsque le consultant a "patché le serveur", il a mis à jour la version SunOS à partir de laquelle il a déployé une ancienne version de Sendmail. Heureusement, le fichier sendmail.cf a survécu, mais maintenant il ne correspond pas.
Il s'est avéré que Sendmail 5 - au moins la version livrée par Sun qui avait un certain nombre d'améliorations - pouvait fonctionner avec sendmail.cf pour Sendmail 8, car la plupart des règles étaient les mêmes. Mais les nouvelles options de configuration longues n'étaient plus reconnues et ignorées. Et comme il n'y avait pas de valeurs par défaut pour la plupart d'entre eux dans le binaire Sendmail, le programme n'a pas trouvé de valeurs appropriées dans sendmail.cf et les a réinitialisées à zéro.
L'une de ces valeurs remises à zéro était le délai d'expiration de la connexion à un serveur SMTP distant. Après quelques expérimentations, il s'est avéré que sur cette machine particulière, sous charge normale, un timeout nul conduit à une déconnexion en un peu plus de trois millisecondes.
À l'époque, le réseau du campus était entièrement basé sur des commutateurs. Le paquet sortant n'a pas été retardé jusqu'à ce qu'il atteigne le routeur de l'autre côté via POP. Autrement dit, la durée d'une connexion à un hôte distant faiblement chargé dans un réseau voisin dépendait principalement de la distance parcourue à la vitesse de la lumière, et non des retards aléatoires des routeurs.
Me sentant un peu étourdi, je suis entré sur la ligne de commande:
$ units
1311 units, 63 prefixes
You have: 3 millilightseconds
You want: miles
* 558.84719
/ 0.0017893979
"500 miles ou plus."
À suivre.