
La dernière partie d'une collection d'histoires sur Internet sur la façon dont les bogues ont parfois des manifestations complètement incroyables. Première partie , deuxième partie .
Petit SSH qui (parfois) ne pouvait pas
C'est une histoire sur l'une des chasses aux insectes les plus excitantes auxquelles j'ai eu la chance de participer.
Chez AdGear Technologies Inc., où je travaillais, tout était conservé sur SSH. Nous l'avons utilisé pour la gestion, la surveillance, le déploiement, la collecte de journaux, même pour la diffusion en direct. Ce protocole est robuste et fiable, a la prévisibilité d'un outil Unix natif et fonctionne tout simplement.
Mais une fois, des lettres sans heure précise ni référence d'hôte nous ont dit que le protocole ne fonctionnait pas.
Temps libre
Les machines de notre centre de données de Londres ont eu des pannes occasionnelles lors de l'envoi de fichiers journaux au centre de données de Montréal. Cette tâche était périodiquement exécutée à partir de Cron et l'échec se présentait comme ceci:
- Les e-mails Cron ont signalé des problèmes avec SSH.
- Parfois ça gèle.
- Parfois, il se termine sans erreur de temporisation.
- Lors d'un bilan de santé interne, Nagios met en garde contre des données manquantes à Montréal.
Nous nous sommes connectés aux voitures de Londres, avons lancé manuellement la commande
pushet cela a fonctionné avec succès. Nous l'avons attribué à un problème de réseau temporaire.
Timeouts
Mais les accidents se répètent au hasard. Une fois par jour, quelques fois par jour, le vendredi matin, plusieurs fois par heure. Il était clair que la situation empirait. Nous avons continué à pousser manuellement les fichiers jusqu'à ce que nous comprenions quel était le problème.
Il y a eu 17 sauts entre Londres et Montréal. Nous avons créé un profil de retard et de perte de paquets. Il s'est avéré que 1 à 3% des paquets étaient perdus en quelques sauts. En collaboration avec le service des opérations du centre de données de Londres, nous avons demandé un réacheminement.
Pendant que les Londoniens vérifiaient les informations de perte de paquets, nous avons commencé à rechercher des délais d'attente aléatoires sur le chemin de Londres à notre deuxièmeCentre de données à Montréal. Les sauts sur cette route étaient différents, pas ceux qui ont perdu des paquets. Nous avons décidé que la perte n'était pas le problème principal, et d'ailleurs les Londoniens ont signalé qu'ils ne pouvaient pas reproduire la perte de paquets ou de timeouts, et que tout allait bien de leur côté.
apocalypse
Lors du transfert manuel de mauvais messages Cron, nous avons remarqué un modèle intéressant. Les fichiers ont été soit transférés avec succès à haute vitesse, soit ils n'ont pas été transférés du tout et ont été suspendus à l'expiration du délai. Il n'y a eu aucun cas de téléchargement de fichiers à faible vitesse.
En supprimant la plupart des données de l'équation, nous avons pu recréer le script en utilisant un simple SSH vanilla. Dans le centre de données de Londres, le serveur «SSH mtl-machine» a terminé immédiatement la tâche ou s'est arrêté et n'a pas pu établir de connexion. La surprise a commencé à grandir.
Où sont passés les colis?
Nous avons vérifié la configuration et les systèmes du serveur SSH à Montréal trois fois:
- Les serveurs DNS ont répondu rapidement.
- La zone de recherche DNS inversée a été désactivée.
- Le nombre maximum de connexions client était suffisamment élevé.
- Nous n'avons pas été attaqués.
- Le canal n'était pas obstrué.
De plus, même si quelque chose ne fonctionnait pas, on observerait des gels en travaillant avec deux centres de données différents à Montréal. De plus, nos centres de données non londoniens ont communiqué avec succès avec Montréal. Autrement dit, le problème était lié à Londres.
Nous avons exécuté tcpdump et regardé les paquets. Nous nous sommes intéressés à la dynamique générale et aux données obtenues à l'aide de Pcaps et chargées dans Wireshark. Nous avons vu des signes de perte de paquets et de renvoi, mais tout était minime et pas préoccupant.
Ensuite, nous avons analysé l'ensemble de la connexion dans des situations où la communication SSH a été établie avec succès, puis - des connexions dans des situations où la communication SSH était suspendue.
Lorsque la connexion entre Londres et Montréal a été bloquée, nous sommes arrivés aux conclusions suivantes:
- L'établissement d'une connexion TCP s'est bien passé.
- Les informations de service SSH ont été envoyées dans les deux sens. Si nécessaire, il y avait des paquets TCP ack normaux.
- Un colis spécifique a été envoyé de Londres et reçu à Montréal.
- Le même colis a été renvoyé plusieurs fois de Londres et reçu à Montréal.
- Montréal ne répond tout simplement pas à cela!
On ne savait pas pourquoi Montréal ne répondait pas (à cause de cela, Londres envoie à nouveau les données). La connexion a été suspendue car le protocole de couche 4 était suspendu. Encore plus excitant était le fait que si vous interrompez l'envoi SSH répété à Londres et le redémarrez immédiatement, cela fonctionnera avec succès. Dans ce cas, tcpdump a indiqué que Montréal a reçu le colis et y a répondu, et le travail s'est poursuivi.
Sur le client SSH à Londres, nous avons activé le débogage détaillé (
-vvv), et après ces entrées de journal, la connexion s'est arrêtée:
debug2: kex_parse_kexinit: first_kex_follows 0
debug2: kex_parse_kexinit: reserved 0
debug2: mac_setup: found hmac-md5
debug1: kex: server->client aes128-ctr hmac-md5 none
debug2: mac_setup: found hmac-md5
debug1: kex: client->server aes128-ctr hmac-md5 none
debug1: SSH2_MSG_KEX_DH_GEX_REQUEST(1024<1024<8192) sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_GROUP
Nous avons googlé "SSH bloque SSH2_MSG_KEX_DH_GEX_GROUP" et avons obtenu beaucoup de résultats, des problèmes Wi-Fi aux bogues TCP dans Windows et aux routeurs bogués perdant des fragments TCP. L'une des solutions pour le réseau local était de calculer le MSS du chemin et de définir cette valeur comme MTU aux deux extrémités de l'itinéraire.
J'ai continué à diminuer le MTU sur le serveur de Londres à partir de 1500 - cela n'a pas aidé jusqu'à ce que j'aie atteint la valeur magique de 576. Après cela, SSH ne s'est plus suspendu. J'exécutais un script avec une boucle SSH, et si je le voulais, je pourrais provoquer des délais d'attente en renvoyant MTU à 1500, ou m'en débarrasser en définissant 576. Malheureusement, ce sont des serveurs publicitaires publics, et attribuer globalement un MTU de 1500 ne résoudra pas le problème. Cependant, il a déjà été mentionné ci-dessus que le processus de fragmentation ou de réassemblage des paquets est probablement interrompu quelque part.
Revenons à la vérification des paquets reçus avec tcpdump: il n'y avait aucun signe de fragmentation. La taille du paquet reçu correspondait entièrement à la taille du paquet envoyé. Si quelque chose fragmentait le paquet sur l'octet 576+, alors quelque chose le réassemblait avec succès.
Scintillement scintillant, étoile courbe
En approfondissant l'analyse, j'ai examiné les vidages de paquets complets (
tcpdump -s 0 -X), pas seulement les en-têtes. En comparant le paquet magique de l'envoi réussi avec le paquet de l'envoi échoué, je n'ai trouvé presque aucune différence, sauf pour les en-têtes TCP / IP. Mais il était évident que c'était le premier paquet sur une connexion TCP qui contenait suffisamment de données pour passer par la marque 576 octets. Tous les packages précédents étaient beaucoup plus petits.
En comparant le même paquet de l'envoi raté, sous la forme dans laquelle il a quitté Londres et est arrivé à Montréal, mes yeux ont attrapé quelque chose. Pour quelque chose de subtil, et je l'ai agité à cause de la fatigue (c'était tard vendredi soir). Mais après plusieurs mises à jour et comparaisons, je n'imaginais plus.
Voici à quoi ressemblait le paquet après avoir quitté Londres (moins les premiers octets identifiant les adresses IP)
0x0040: 0b7c aecc 1774 b770 ad92 0000 00b7 6563 .|...t.p......ec
0x0050: 6468 2d73 6861 322d 6e69 7374 7032 3536 dh-sha2-nistp256
0x0060: 2c65 6364 682d 7368 6132 2d6e 6973 7470 ,ecdh-sha2-nistp
0x0070: 3338 342c 6563 6468 2d73 6861 322d 6e69 384,ecdh-sha2-ni
0x0080: 7374 7035 3231 2c64 6966 6669 652d 6865 stp521,diffie-he
0x0090: 6c6c 6d61 6e2d 6772 6f75 702d 6578 6368 llman-group-exch
0x00a0: 616e 6765 2d73 6861 3235 362c 6469 6666 ange-sha256,diff
0x00b0: 6965 2d68 656c 6c6d 616e 2d67 726f 7570 ie-hellman-group
0x00c0: 2d65 7863 6861 6e67 652d 7368 6131 2c64 -exchange-sha1,d
0x00d0: 6966 6669 652d 6865 6c6c 6d61 6e2d 6772 iffie-hellman-gr
0x00e0: 6f75 7031 342d 7368 6131 2c64 6966 6669 oup14-sha1,diffi
0x00f0: 652d 6865 6c6c 6d61 6e2d 6772 6f75 7031 e-hellman-group1
0x0100: 2d73 6861 3100 0000 2373 7368 2d72 7361 -sha1...#SSH-rsa
0x0110: 2c73 7368 2d64 7373 2c65 6364 7361 2d73 ,SSH-dss,ecdsa-s
0x0120: 6861 322d 6e69 7374 7032 3536 0000 009d ha2-nistp256....
0x0130: 6165 7331 3238 2d63 7472 2c61 6573 3139 aes128-ctr,aes19
0x0140: 322d 6374 722c 6165 7332 3536 2d63 7472 2-ctr,aes256-ctr
0x0150: 2c61 7263 666f 7572 3235 362c 6172 6366 ,arcfour256,arcf
0x0160: 6f75 7231 3238 2c61 6573 3132 382d 6362 our128,aes128-cb
0x0170: 632c 3364 6573 2d63 6263 2c62 6c6f 7766 c,3des-cbc,blowf
0x0180: 6973 682d 6362 632c 6361 7374 3132 382d ish-cbc,cast128-
0x0190: 6362 632c 6165 7331 3932 2d63 6263 2c61 cbc,aes192-cbc,a
0x01a0: 6573 3235 362d 6362 632c 6172 6366 6f75 es256-cbc,arcfou
0x01b0: 722c 7269 6a6e 6461 656c 2d63 6263 406c r,rijndael-cbc@l
0x01c0: 7973 6174 6f72 2e6c 6975 2e73 6500 0000 ysator.liu.se...
0x01d0: 9d61 6573 3132 382d 6374 722c 6165 7331 .aes128-ctr,aes1
0x01e0: 3932 2d63 7472 2c61 6573 3235 362d 6374 92-ctr,aes256-ct
0x01f0: 722c 6172 6366 6f75 7232 3536 2c61 7263 r,arcfour256,arc
0x0200: 666f 7572 3132 382c 6165 7331 3238 2d63 four128,aes128-c
0x0210: 6263 2c33 6465 732d 6362 632c 626c 6f77 bc,3des-cbc,blow
0x0220: 6669 7368 2d63 6263 2c63 6173 7431 3238 fish-cbc,cast128
0x0230: 2d63 6263 2c61 6573 3139 322d 6362 632c -cbc,aes192-cbc,
0x0240: 6165 7332 3536 2d63 6263 2c61 7263 666f aes256-cbc,arcfo
0x0250: 7572 2c72 696a 6e64 6165 6c2d 6362 6340 ur,rijndael-cbc@
0x0260: 6c79 7361 746f 722e 6c69 752e 7365 0000 lysator.liu.se..
0x0270: 00a7 686d 6163 2d6d 6435 2c68 6d61 632d ..hmac-md5,hmac-
0x0280: 7368 6131 2c75 6d61 632d 3634 406f 7065 sha1,umac-64@ope
0x0290: 6e73 7368 2e63 6f6d 2c68 6d61 632d 7368 nSSH.com,hmac-sh
0x02a0: 6132 2d32 3536 2c68 6d61 632d 7368 6132 a2-256,hmac-sha2
0x02b0: 2d32 3536 2d39 362c 686d 6163 2d73 6861 -256-96,hmac-sha
0x02c0: 322d 3531 322c 686d 6163 2d73 6861 322d 2-512,hmac-sha2-
0x02d0: 3531 322d 3936 2c68 6d61 632d 7269 7065 512-96,hmac-ripe
0x02e0: 6d64 3136 302c 686d 6163 2d72 6970 656d md160,hmac-ripem
0x02f0: 6431 3630 406f 7065 6e73 7368 2e63 6f6d d160@openSSH.com
0x0300: 2c68 6d61 632d 7368 6131 2d39 362c 686d ,hmac-sha1-96,hm
0x0310: 6163 2d6d 6435 2d39 3600 0000 a768 6d61 ac-md5-96....hma
0x0320: 632d 6d64 352c 686d 6163 2d73 6861 312c c-md5,hmac-sha1,
0x0330: 756d 6163 2d36 3440 6f70 656e 7373 682e umac-64@openSSH.
0x0340: 636f 6d2c 686d 6163 2d73 6861 322d 3235 com,hmac-sha2-25
0x0350: 362c 686d 6163 2d73 6861 322d 3235 362d 6,hmac-sha2-256-
0x0360: 3936 2c68 6d61 632d 7368 6132 2d35 3132 96,hmac-sha2-512
0x0370: 2c68 6d61 632d 7368 6132 2d35 3132 2d39 ,hmac-sha2-512-9
0x0380: 362c 686d 6163 2d72 6970 656d 6431 3630 6,hmac-ripemd160
0x0390: 2c68 6d61 632d 7269 7065 6d64 3136 3040 ,hmac-ripemd160@
0x03a0: 6f70 656e 7373 682e 636f 6d2c 686d 6163 openSSH.com,hmac
0x03b0: 2d73 6861 312d 3936 2c68 6d61 632d 6d64 -sha1-96,hmac-md
0x03c0: 352d 3936 0000 0015 6e6f 6e65 2c7a 6c69 5-96....none,zli
0x03d0: 6240 6f70 656e 7373 682e 636f 6d00 0000 b@openSSH.com...
0x03e0: 156e 6f6e 652c 7a6c 6962 406f 7065 6e73 .none,zlib@opens
0x03f0: 7368 2e63 6f6d 0000 0000 0000 0000 0000 sh.com..........
0x0400: 0000 0000 0000 0000 0000 0000 ............
Et voici à quoi ressemblait le même colis lorsqu'il est arrivé à Montréal
0x0040: 0b7c aecc 1774 b770 ad92 0000 00b7 6563 .|...t.p......ec
0x0050: 6468 2d73 6861 322d 6e69 7374 7032 3536 dh-sha2-nistp256
0x0060: 2c65 6364 682d 7368 6132 2d6e 6973 7470 ,ecdh-sha2-nistp
0x0070: 3338 342c 6563 6468 2d73 6861 322d 6e69 384,ecdh-sha2-ni
0x0080: 7374 7035 3231 2c64 6966 6669 652d 6865 stp521,diffie-he
0x0090: 6c6c 6d61 6e2d 6772 6f75 702d 6578 6368 llman-group-exch
0x00a0: 616e 6765 2d73 6861 3235 362c 6469 6666 ange-sha256,diff
0x00b0: 6965 2d68 656c 6c6d 616e 2d67 726f 7570 ie-hellman-group
0x00c0: 2d65 7863 6861 6e67 652d 7368 6131 2c64 -exchange-sha1,d
0x00d0: 6966 6669 652d 6865 6c6c 6d61 6e2d 6772 iffie-hellman-gr
0x00e0: 6f75 7031 342d 7368 6131 2c64 6966 6669 oup14-sha1,diffi
0x00f0: 652d 6865 6c6c 6d61 6e2d 6772 6f75 7031 e-hellman-group1
0x0100: 2d73 6861 3100 0000 2373 7368 2d72 7361 -sha1...#SSH-rsa
0x0110: 2c73 7368 2d64 7373 2c65 6364 7361 2d73 ,SSH-dss,ecdsa-s
0x0120: 6861 322d 6e69 7374 7032 3536 0000 009d ha2-nistp256....
0x0130: 6165 7331 3238 2d63 7472 2c61 6573 3139 aes128-ctr,aes19
0x0140: 322d 6374 722c 6165 7332 3536 2d63 7472 2-ctr,aes256-ctr
0x0150: 2c61 7263 666f 7572 3235 362c 6172 6366 ,arcfour256,arcf
0x0160: 6f75 7231 3238 2c61 6573 3132 382d 6362 our128,aes128-cb
0x0170: 632c 3364 6573 2d63 6263 2c62 6c6f 7766 c,3des-cbc,blowf
0x0180: 6973 682d 6362 632c 6361 7374 3132 382d ish-cbc,cast128-
0x0190: 6362 632c 6165 7331 3932 2d63 6263 2c61 cbc,aes192-cbc,a
0x01a0: 6573 3235 362d 6362 632c 6172 6366 6f75 es256-cbc,arcfou
0x01b0: 722c 7269 6a6e 6461 656c 2d63 6263 406c r,rijndael-cbc@l
0x01c0: 7973 6174 6f72 2e6c 6975 2e73 6500 0000 ysator.liu.se...
0x01d0: 9d61 6573 3132 382d 6374 722c 6165 7331 .aes128-ctr,aes1
0x01e0: 3932 2d63 7472 2c61 6573 3235 362d 6374 92-ctr,aes256-ct
0x01f0: 722c 6172 6366 6f75 7232 3536 2c61 7263 r,arcfour256,arc
0x0200: 666f 7572 3132 382c 6165 7331 3238 2d63 four128,aes128-c
0x0210: 6263 2c33 6465 732d 6362 632c 626c 6f77 bc,3des-cbc,blow
0x0220: 6669 7368 2d63 6263 2c63 6173 7431 3238 fish-cbc,cast128
0x0230: 2d63 6263 2c61 6573 3139 322d 6362 632c -cbc,aes192-cbc,
0x0240: 6165 7332 3536 2d63 6263 2c61 7263 666f aes256-cbc,arcfo
0x0250: 7572 2c72 696a 6e64 6165 6c2d 6362 7340 ur,rijndael-cbs@
0x0260: 6c79 7361 746f 722e 6c69 752e 7365 1000 lysator.liu.se..
0x0270: 00a7 686d 6163 2d6d 6435 2c68 6d61 732d ..hmac-md5,hmas-
0x0280: 7368 6131 2c75 6d61 632d 3634 406f 7065 sha1,umac-64@ope
0x0290: 6e73 7368 2e63 6f6d 2c68 6d61 632d 7368 nSSH.com,hmac-sh
0x02a0: 6132 2d32 3536 2c68 6d61 632d 7368 7132 a2-256,hmac-shq2
0x02b0: 2d32 3536 2d39 362c 686d 6163 2d73 7861 -256-96,hmac-sxa
0x02c0: 322d 3531 322c 686d 6163 2d73 6861 322d 2-512,hmac-sha2-
0x02d0: 3531 322d 3936 2c68 6d61 632d 7269 7065 512-96,hmac-ripe
0x02e0: 6d64 3136 302c 686d 6163 2d72 6970 756d md160,hmac-ripum
0x02f0: 6431 3630 406f 7065 6e73 7368 2e63 7f6d d160@openSSH.c.m
0x0300: 2c68 6d61 632d 7368 6131 2d39 362c 786d ,hmac-sha1-96,xm
0x0310: 6163 2d6d 6435 2d39 3600 0000 a768 7d61 ac-md5-96....h}a
0x0320: 632d 6d64 352c 686d 6163 2d73 6861 312c c-md5,hmac-sha1,
0x0330: 756d 6163 2d36 3440 6f70 656e 7373 782e umac-64@openssx.
0x0340: 636f 6d2c 686d 6163 2d73 6861 322d 3235 com,hmac-sha2-25
0x0350: 362c 686d 6163 2d73 6861 322d 3235 362d 6,hmac-sha2-256-
0x0360: 3936 2c68 6d61 632d 7368 6132 2d35 3132 96,hmac-sha2-512
0x0370: 2c68 6d61 632d 7368 6132 2d35 3132 3d39 ,hmac-sha2-512=9
0x0380: 362c 686d 6163 2d72 6970 656d 6431 3630 6,hmac-ripemd160
0x0390: 2c68 6d61 632d 7269 7065 6d64 3136 3040 ,hmac-ripemd160@
0x03a0: 6f70 656e 7373 682e 636f 6d2c 686d 7163 openSSH.com,hmqc
0x03b0: 2d73 6861 312d 3936 2c68 6d61 632d 7d64 -sha1-96,hmac-}d
0x03c0: 352d 3936 0000 0015 6e6f 6e65 2c7a 7c69 5-96....none,z|i
0x03d0: 6240 6f70 656e 7373 682e 636f 6d00 0000 b@openSSH.com...
0x03e0: 156e 6f6e 652c 7a6c 6962 406f 7065 6e73 .none,zlib@opens
0x03f0: 7368 2e63 6f6d 0000 0000 0000 0000 0000 sh.com..........
0x0400: 0000 0000 0000 0000 0000 0000 ............
Avez-vous remarqué quelque chose? Sinon, ça va. Vous pouvez copier dans deux fenêtres dans un éditeur de texte et basculer rapidement entre elles pour voir les changements de symbole.
Bien bien. Ce n'est pas une perte de paquets, mais une corruption de paquets! Très peu de dégâts très prévisibles. Observations intéressantes:
- La partie initiale du paquet (<576 octets) est intacte.
- Tous les 15 octets sur 16 sont endommagés.
- Les dégâts sont prévisibles. Tout
hest devenux, toutcest devenus.
Vous avez peut-être déjà consulté la table ASCII et conclu qu'un bit est bloqué sur la valeur
1. La conversion vers le 1quatrième bit d'un octet gâche les lettres précédentes sur la gauche en valeurs sur la droite.
Les coupables évidents dans notre champ de vision (NIC acceptant les serveurs) sont au-delà de tout soupçon car la panne a un modèle (plusieurs machines londoniennes → plusieurs centres de données et machines montréalais). La raison doit être sur la route et plus proche de Londres.
La situation a commencé à prendre un sens. J'ai aussi remarqué un petit indice en mode tcpdump verbeux (
tcp cksum bad), ce que je n'avais pas remarqué auparavant. Le serveur de Montréal a laissé tomber un paquet au niveau du noyau lorsqu'il s'est rendu compte qu'il était corrompu et n'a pas transmis le paquet au démon SSH dans l'espace utilisateur. Puis Londres a renvoyé le paquet, il a de nouveau été endommagé et Montréal l'a rejeté en silence. Du point de vue de SSH et SSHd, la connexion est bloquée. Du point de vue de tcpdump, il n'y a pas eu de perte et les serveurs de Montréal ignorent simplement les données.
Nous avons rapporté nos résultats au service des opérations du centre de données de Londres et, en quelques minutes, ils ont radicalement changé leurs itinéraires de sortie. Le premier saut et la plupart des suivants étaient différents. Le problème du gel a disparu.
Les correctifs tard le vendredi soir sont bien, car le week-end, vous pouvez vous détendre et ne pas penser aux problèmes et au soutien :)
Où est Wally?
Heureux que nous ne souffrions plus de ce problème et que nos systèmes rattrapaient leur retard, j'ai décidé de trouver le périphérique responsable de cette corruption de paquets.
La mise à jour des itinéraires de Londres pour empêcher la circulation de l'ancien itinéraire signifiait que je ne pouvais pas reproduire facilement le problème. J'ai trouvé un ami à Montréal avec une machine FreeBSD appropriée qui était disponible depuis Londres via les anciennes routes.
Je voulais m'assurer que les dégâts étaient prévisibles même sans SSH impliqué. J'ai géré cela facilement avec quelques pipelines.
À Montreal:
nc -l -p 4000 > /dev/null
Puis à Londres:
cat /dev/zero | nc mtl 4000
Compte tenu du facteur aléatoire et des ajustements dans le cycle de relance, j'ai reçu plusieurs paquets qui dissipaient les doutes sur les conclusions précédentes. Voici une partie de l'un des packages:
Nous venons d'envoyer un paquet de zéros
0x0210 .....
0x0220 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0230 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0240 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0250 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0260 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0270 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0280 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0290 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02a0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02b0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02c0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02d0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02e0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02f0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0300 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0310 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0320 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0330 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0340 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0350 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0360 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0370 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0380 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0390 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03a0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03b0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03c0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03d0 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x03e0 .....
En reproduisant le bogue, j'avais besoin de trouver celui des 17 sauts sur lequel le dommage s'est produit. Je ne pouvais pas simplement appeler les fournisseurs de tous les clusters et leur demander de vérifier leurs systèmes.
J'ai décidé de cingler chaque routeur séquentiellement, cela pourrait aider. Écrit des paquets ICMP spéciaux suffisamment gros pour dépasser la limite de sécurité de 576 octets et les a remplis de zéros. Puis, avec l'aide de ces paquets, j'ai envoyé une requête ping au serveur de Montréal depuis Londres.
Les colis sont retournés intacts.
J'ai essayé toutes les combinaisons de vitesse, de contenu, de taille - en vain. Je n'ai trouvé aucun dommage dans les paquets ping ICMP retournés.
Dans les pipelines Netcat, j'ai remplacé TCP par UDP. Encore une fois, aucun dommage.
Il fallait TCP pour reproduire les dégâts et TCP avait besoin de deux points de terminaison communicants. J'ai essayé en vain de savoir si tous les routeurs ont un port TCP ouvert avec lequel je peux communiquer directement.
Il semblait impossible d'identifier le saut défectueux de l'extérieur. Ou est-ce possible?
Miroir miroir sur le mur
Pour déterminer si des dommages surviennent, l'un des scénarios suivants a dû être utilisé:
- Vérifiez le paquet à la destination via le nœud TCP avec lequel il communique.
- Pas dans l'espace utilisateur, où le paquet ne sera pas livré en cas d'erreur lors de la vérification de la somme de contrôle, mais vérifiez si le paquet reçu est endommagé en utilisant root et tcpdump.
- À l'aide d'un nœud TCP qui agit comme un serveur d'écho et reflète les données reçues, vérifiez le paquet sur le nœud d'envoi.
Il s'est soudainement avéré qu'un deuxième point de mesure était à notre disposition. Pas directement accessible, mais quand même: dans la toute première approche pour résoudre le problème, nous avons remarqué que les clients SSH se bloquent lors de la communication avec les serveurs SSH via un saut dommageable. C'est un bon signal passif qui peut être utilisé à la place du signal "écho" actif.
Et en cela, nous pouvons être aidés par de nombreux serveurs SSH ouverts sur Internet.
Nous n'avons pas besoin de comptes courants sur ces serveurs, il suffit de démarrer une connexion SSH, voir si la phase d'échange de chiffrement réussira (avec un nombre raisonnable de tentatives pour prendre en compte les dégâts accidentels).
Le plan était le suivant:
- Utilisez le merveilleux outil nmap en mode "IP aléatoire" pour compiler une liste de serveurs SSH ouverts géographiquement répartis.
- :
- , → .
- N- → «».
- telltale N- → «».
- «» «».
J'ai pensé ainsi: dans les traces de tous les "mauvais" serveurs, plusieurs des mêmes sauts seront utilisés. Nous pourrons identifier les sauts suspects et identifier ceux qui sont utilisés dans les traces de "bons" serveurs. Dans l'espoir qu'il en restera un ou deux.
Après avoir passé une heure à classer manuellement les serveurs, j'ai arrêté d'explorer les données. J'avais 16 "mauvais" et 25 "bons" serveurs.
La première étape a été de faire une liste des sauts qui se trouvent dans toutes les traces des mauvais serveurs. Après avoir nettoyé la liste, j'ai réalisé que je n'avais même pas besoin d'aller à la liste des "bons" pour supprimer les faux sauts positifs. Les méchants n'avaient qu'un seul saut en commun.
Cependant, il y avait deux fournisseurs avant cela: Londres → N sauts en amont1 → Y sauts en amont2.
C'était le premier des sauts Y en amont2, juste à la frontière entre amont1 et amont2. Il a endommagé des paquets TCP aléatoires, ce qui a conduit à de nombreuses retransmissions et, selon les spécificités de l'échange de données du protocole, se fige ou réduit les volumes de transmission.
En collaboration avec le service des opérations du centre de données de Londres, nous avons suivi l'adresse IP de ce saut. J'espérais que grâce à leur connexion directe à l'amont1, il serait possible de forcer les corrections.
Par upstream1, j'ai reçu la confirmation que le saut que j'ai indiqué (le premier en amont2) avait une "défaillance du module de contrôle" interne qui affectait BGP et le routage entre les deux réseaux internes. Ils ont réacheminé le périphérique défectueux et l'ont éteint en attendant son remplacement.
Filtre de musique rock
J'ai aidé un utilisateur d'une application de streaming audio à mettre en place une expérience LAN. L'utilisateur a joué uniquement de la musique classique, pas de la musique rock. Sérieusement. Les classiques ont été diffusés en continu et lorsque vous essayez de diffuser de la musique rock, la connexion a été interrompue après quelques minutes.
L'application a reçu des morceaux d'audio, les a compressés à l'aide d'un codec de compression sans perte, puis a envoyé chaque morceau dans un paquet UDP distinct au point de terminaison. Dans la mesure du possible, l'application a essayé d'utiliser IPv6, car il était plus fiable que l'environnement LAN, même s'il pouvait fonctionner via IPv4 si nécessaire.
Après une recherche interminable et fastidieuse de la cause du problème, j'ai finalement compris quel était le problème. D'une manière ou d'une autre, l'utilisateur a défini le MTU sur 1 200 octets sur l'interface réseau. Et IPv6 ne fragmentera pas automatiquement les paquets au niveau IP lorsque le MTU est inférieur à 1280 octets, de sorte que les paquets plus volumineux ne peuvent tout simplement pas être envoyés. L'application de streaming essaie d'envoyer des paquets audio de plus de 1 200 octets, reçoit une erreur et se déconnecte.
Pourquoi est-ce arrivé uniquement avec la musique rock? C'est simple. Les codecs sans perte utilisent un débit binaire variable et la musique classique est mieux compressée que la musique rock. Lors de la diffusion en continu de classiques, l'audio était systématiquement compressé en paquets de moins de 1 200 octets, et les paquets de musique rock dépassaient de manière aléatoire ce seuil.
L'utilisateur ne savait pas pourquoi son MTU avait été réduit, il n'en avait pas besoin, nous avons donc augmenté la valeur et tout fonctionnait bien.
Interruption d'Internet auto-disparaissante
Quand je suis entré à l'université en 1999, je vivais dans un vieux dortoir d'étudiants délabré parce que je ne pouvais rien me permettre de mieux. Mais au moins, il y avait un Internet assez décent dans l'auberge, qui n'était pas encore répandu dans mon pays. Et comme il était interdit de changer de bâtiment, les câbles réseau (toujours coaxiaux) ont été divorcés selon un schéma provisoire. Ils étaient cachés derrière de faux plafonds dans les couloirs et tirés à travers les portes des pièces où ils étaient simplement allongés sur le sol. Toute rupture de communication pourrait conduire au fait qu'un étage entier se retrouve sans réseau. Depuis que j'ai étudié à la Faculté d'informatique, je me suis rapidement et involontairement transformé en une personne à mon étage qui répare des interruptions assez fréquentes, même si je n'avais aucune expérience du réseautage.
Parfois, l'interruption était du côté du fournisseur, parfois le problème était lié à notre proxy, mais le plus souvent, quelqu'un a simplement déconnecté un câble et n'y a pas inséré de terminateur.
Un soir, Internet est tombé en panne, mais seulement pendant quelques minutes. Puis il est réapparu, donc je n'y ai pas beaucoup pensé. Mais le lendemain, la courte interruption se répéta, ainsi que le troisième jour. Habituellement, cela se passait environ 20 heures, l'heure exacte flottait, et parfois ce n'était pas du tout. Mais chaque fois que le réseau tombait en panne, mon téléphone sur place se mettait à sonner et les gens étaient de plus en plus ennuyés par ces interruptions répétées.
Puisque chaque interruption n'a duré que quelques minutes, je n'ai pas pu localiser un emplacement spécifique avant que le réseau ne réapparaisse. J'ai essayé de traverser le sol et de frapper à toutes les portes, demandant si quelqu'un avait sorti un câble ou avait fait quelque chose avec, mais l'idée n'a pas aidé. J'ai finalement décidé d'attendre l'interruption quotidienne avec mon fidèle multimètre en main. En une semaine, j'ai expulsé une pièce après l'autre des suspects. Enfin, dans l'un des câbles de la chambre, j'ai remarqué une surtension lors de la prochaine interruption.
J'ai frappé, mais ils ne l'ont pas ouvert. Le château était verrouillé. Mais s'il n'y a personne dans la pièce pour faire quelque chose avec l'ordinateur ou le câble, alors pourquoi la connexion est-elle interrompue? Et pourquoi se rétablit-il? Le lendemain, tout est arrivé à nouveau, ils n’ont plus ouvert la porte. J'ai décidé d'éteindre complètement cette pièce afin que l'Internet fonctionne sur le reste de l'étage.
Le lendemain matin, les locataires de cette chambre m'ont informé que leur connexion Internet ne fonctionnait pas. Je suis allé vers eux et j'ai mesuré la résistance de tous les câbles, vérifié toutes les connexions et les terminateurs. Tous les câbles ont zéro ohms, tout est en parfait état. J'ai demandé au gars ce qu'il faisait hier soir? J'ai lu des manuels avant les examens, rien de lié à l'ordinateur, a-t-il répondu. J'ai tout revérifié une deuxième et une troisième fois, mais je n'ai trouvé aucun problème. J'ai failli abandonner, puis j'ai remarqué: le câble était attaché sous le lit. Bien sûr, l'âme en cuivre du câble était cassée exactement à cet endroit, mais elle était fermement maintenue par la gaine de sorte que, dans des conditions normales, le contact était maintenu, même si vous vous asseyez sur le lit. Mais quand j'ai commencé à le balancer, le contact a disparu pendant quelques secondes à chaque poussée.
Vous pouvez deviner vous-même ce qui s'est passé sur ce lit pendant plusieurs minutes chaque soir, derrière une porte verrouillée et sans réponse à un coup.
L'histoire de Mel
Les vrais programmeurs écrivent en Fortran
C'est peut-être le cas maintenant, à l'ère décadente de la bière sans alcool, des calculatrices et des applications "conviviales", mais dans le bon vieux temps, quand le terme "logiciel" semblait drôle et que les vrais ordinateurs étaient faits de tambours magnétiques et de tubes radio, Real Programmers a écrit dans langage machine. Pas chez FORTRAN. Pas sur RATFOR. Pas même le langage d'assemblage. En code machine. Sur des nombres hexadécimaux réels, sans ornements et incompréhensibles. Juste comme ça. Plusieurs générations de programmeurs ont grandi sans connaître ce passé glorieux, et je crois que je devrais essayer de combler le fossé des générations et parler de la façon dont un vrai programmeur a écrit du code. Je vais l'appeler Mel parce que c'était son nom.
J'ai rencontré Mel quand j'ai trouvé un emploi chez Royal McBee Computer Corp., filiale aujourd'hui disparue d'un fabricant de machines à écrire. L'entreprise fabriquait le LGP-30 - une boîte à rythmes petite et bon marché (selon les normes actuelles) - et venait juste de commencer à fabriquer le RPC-4000, également sur mémoire de tambour, bien amélioré, plus grand et plus rapide. Les noyaux magnétiques étaient trop chers et ils ne pouvaient pas résister à la concurrence (c'est pourquoi vous n'avez pas entendu parler de cette société ou de ses ordinateurs). J'ai été embauché pour écrire un compilateur FORTRAN pour ce nouveau miracle, et Mel a été mon guide pour ses capacités. Mel désapprouvait les compilateurs. «À quoi bon qu'un programme ne puisse pas réécrire son propre code?», A-t-il demandé. Mel a écrit le programme le plus populaire de l'entreprise en hexadécimal.Elle a travaillé pour le LGP-30 et a joué au blackjack avec des acheteurs potentiels lors de salons informatiques. Cela a toujours eu un effet dramatique. Un stand LGP-30 a été présenté à chaque salon professionnel, et les vendeurs IBM se sont réunis et se sont entretenus. Cela a-t-il aidé à vendre des ordinateurs? Nous n'avons jamais discuté de cette question.
Le travail de Mel était de réécrire le programme de blackjack pour le RPC-4000. (Portage? Qu'est-ce que c'est?) Le nouvel ordinateur avait un schéma d'adressage un plus un: en plus de l'opcode et de l'adresse de l'opérande requis, chaque instruction machine avait également une deuxième adresse, qui indiquait où l'instruction suivante était écrite sur un tambour magnétique rotatif ... Autrement dit, après chaque instruction est allé
GO TO! Mettez-le dans une pipe Pascal et fumez-le.
Mel adorait le RPC-4000 car il pouvait optimiser son code: placer des instructions sur la bobine de sorte que dès qu'une est terminée, la seconde soit immédiatement sous la "tête de lecture" et soit prête pour une exécution immédiate. Pour ce faire, un programme a été écrit qui optimise l'assembleur, mais Mel a refusé de l'utiliser. «Vous ne savez jamais où cela mettra les données», expliqua-t-il, «vous devez donc utiliser des constantes séparées». J'ai compris l'essence de cette phrase bien plus tard. Puisque Mel connaissait les valeurs numériques de tous les codes de fonctionnement et attribuait ses propres adresses dans la mémoire du tambour, chaque instruction qu'il écrivait pouvait être considérée comme une constante numérique. Par exemple, il pourrait sélectionner une instruction «ajouter» antérieure et la multiplier si elle avait une valeur numérique appropriée. Très peu de gens pouvaient changer son code.J'ai comparé les programmes optimisés manuellement de Mel avec le même code qui avait été traité par l'assembleur d'optimisation, et le code de Mel fonctionnait toujours plus vite. Le fait est que la méthode descendante de la construction de l'architecture n'a pas encore été inventée et que Mal ne l'aurait pas utilisée de toute façon. Tout d'abord, il a écrit les parties internes de ses boucles de programmation afin qu'elles soient les premières à obtenir les adresses optimales sur la bobine. Et l'assembleur optimisateur n'était pas capable de cela. Mel n'a jamais écrit de boucles temporisées, même lorsque l'imposant Flexowriter exigeait un délai entre les sorties de caractères. Mel a simplement placé les instructions sur la bobine de sorte que lorsque la prochaine instruction devait être lue, elle passeraitque la méthode d'architecture descendante n'a pas encore été inventée et que Mel ne l'aurait pas utilisée de toute façon. Tout d'abord, il a écrit les parties internes de ses boucles de programmation afin qu'elles soient les premières à obtenir les adresses optimales sur la bobine. Et l'assembleur optimisateur n'était pas capable de cela. Mel n'a jamais écrit de boucles temporisées, même lorsque l'imposant Flexowriter exigeait un délai entre les sorties de caractères. Mel a simplement placé les instructions sur la bobine de sorte que lorsque l'instruction suivante devait être lue, elle passerait parque la méthode d'architecture descendante n'a pas encore été inventée et que Mel ne l'aurait pas utilisée de toute façon. Tout d'abord, il a écrit les parties internes de ses boucles de programmation afin qu'elles soient les premières à obtenir les adresses optimales sur la bobine. Et l'assembleur optimisateur n'était pas capable de cela. Mel n'a jamais écrit de boucles temporisées, même lorsque l'imposant Flexowriter exigeait un délai entre les sorties de caractères. Mel a simplement placé les instructions sur la bobine de sorte que lorsque la prochaine instruction devait être lue, elle passeraitmême lorsque le Flexowriter imposant nécessitait un délai entre les sorties de caractères. Mel a simplement placé les instructions sur la bobine de sorte que lorsque la prochaine instruction devait être lue, elle passeraitmême lorsque le Flexowriter imposant nécessitait un délai entre les sorties de caractères. Mel a simplement placé les instructions sur la bobine de sorte que lorsque l'instruction suivante devait être lue, elle passerait parau-delà de la tête de lecture, et le tambour devrait faire encore une révolution pour le trouver. Mel a trouvé un terme inimitable pour cette procédure. Le mot «optimum» (optimum) a un sens absolu, ainsi que «unique», de sorte que dans le langage familier, ils étaient souvent rendus relatifs: «pas tout à fait optimal» ou «moins optimal» ou «pas très optimal». Mel a appelé les endroits sur le tambour avec le temps de latence le plus long "le plus pessimum" ( pessimum - les pires conditions environnementales tolérées par le corps ).
Après avoir terminé le travail sur le programme de blackjack et l'avoir exécuté («Même l'initialiseur est optimisé», dit-il fièrement), Mel a reçu une demande du service commercial pour apporter des modifications. Un élégant générateur de nombres aléatoires (optimisé) était responsable du mélange des cartes et de la distribution à partir du jeu dans le programme. Et certains vendeurs ont pensé que c'était trop honnête, car parfois les acheteurs perdaient. Ils ont demandé à Mel de changer le programme afin que l'interrupteur tactile sur la console puisse changer les chances du joueur et permettre à l'acheteur de gagner. Mel a refusé. Il a considéré que c'était malhonnête - c'était ainsi - et que cela empiétait sur sa moralité de programmeur - c'était ainsi - alors il a refusé de participer. Mel a été persuadé par le chef du département des ventes, Big Boss et d'autres programmeurs sur l'insistance du Boss. Finalement, Mel a abandonné et a écrit le codemais la triche a-t-elle vérifié l'inverse: lorsque l'interrupteur était activé, le programme trichait et gagnait toujours. Mel était ravi de sa décision. Il a affirmé que son esprit subconscient montrait une éthique incontrôlable et refusait catégoriquement de corriger le programme. Lorsque Mel a quitté l'entreprise pour un revenu plus élevé, Big Boss m'a demandé de regarder le code et de me dire si je pouvais trouver un validateur et changer la façon dont cela fonctionnait. J'ai accepté à contrecœur.puis-je trouver le module de vérification et changer son fonctionnement. J'ai accepté à contrecœur.puis-je trouver le module de vérification et changer son fonctionnement. J'ai accepté à contrecœur.
Traiter le code de Mel était une véritable aventure. Il m'a souvent semblé que la programmation est une forme d'art dont la valeur réelle ne peut être appréciée que par ceux qui comprennent cet art mystérieux. Il contient de vrais bijoux et des mouvements brillants, cachés à la vue et à l'admiration humaines par la nature même du processus, parfois pour toujours. Vous pouvez en apprendre beaucoup sur une personne simplement en lisant son code, même hexadécimal. Je pense que Mel était un génie méconnu. Le choc le plus puissant a peut-être été le cycle innocent que j'ai trouvé, dans lequel il n'y a pas eu de vérification frauduleuse. Aucune vérification. Non .
Le bon sens a dicté que cela devrait être une boucle fermée, à l'intérieur de laquelle le programme circule, pour toujours, sans fin. Cependant, le contrôle logiciel l'a traversé avec succès et est sorti en toute sécurité de l'autre côté. Il m'a fallu deux semaines pour comprendre cela. Le RPC-4000 était équipé d'un appareil moderne - un registre d'index. Il permettait d'écrire des boucles de programme, à l'intérieur desquelles des instructions indexées étaient utilisées. Chaque fois qu'il passait par la boucle, un numéro du registre était ajouté à l'adresse de l'instruction afin qu'il se réfère à la position suivante dans la série. Il ne restait plus qu'à incrémenter le registre d'index à chaque passage. Mel n'en a pas profité. Au lieu de cela, il a tiré l'instruction dans le registre de la machine, en a ajouté une à son adresse et l'a sauvegardée. Et puis il a exécuté l'instruction modifiée directement à partir du registre.Le cycle était écrit en tenant compte du temps d'exécution supplémentaire: dès que l'instruction était terminée, la suivante apparaissait sous la tête de lecture du tambour. Mais il n'y a pas eu de vérification non autorisée dans la boucle. L'indice de sauvegarde était qu'un bit dans le registre d'index était activé - il se trouvait dans le code de commande entre l'adresse et le code de fonctionnement. Cependant, Mel n'a pas utilisé le registre d'index, le laissant à zéro.
Quand ma révélation est venue, j'ai failli devenir aveugle. Les données sur lesquelles il travaillait se rapprochaient des niveaux élevés de mémoire - les plus grandes adresses auxquelles les instructions pouvaient faire référence - Mel disposées de telle sorte qu'après le traitement de la dernière position, l'incrémentation de l'adresse d'instruction provoquerait un débordement. Lors du transfert, un a été ajouté au code de fonctionnement, en le remplaçant par le code suivant dans l'ensemble: l'instruction de saut. Bien sûr, cette instruction suivante était située à l'adresse zéro, et le programme y est allé avec bonheur. Je n'ai pas parlé à Mel et je ne sais pas s'il a abandonné face au flot de changements qui a inondé la programmation depuis. Je préfère penser que je n'ai pas abandonné. J'ai été tellement impressionné que j'ai arrêté de chercher un cheat cheat et j'ai dit à Big Boss que je ne pouvais pas le trouver. Il n'a pas été surpris. Quand j'ai quitté l'entreprisele programme de blackjack était toujours en train de tricher si le bon interrupteur était activé, et à juste titre, je pense. Je n'aimais pas pirater le code d'un vrai programmeur.
Problème exceptionnellement USB
Dès la sortie de l'université, j'ai rejoint une entreprise et travaillé sur un appareil grand public pendant cinq mois avant qu'il ne soit montré au public. L'appareil exécutait Linux. Et pendant que je m'habitue à l'idée de me faire dorloter dans l'espace noyau, j'ai été attiré à une réunion pour prioriser les bogues. De nombreux bugs. Des centaines de bugs. Chacun d'eux lit: "C'est impossible, comment est-ce arrivé?"
Ils ont crié: "Dommages à la mémoire!" J'ai pensé: "Hospadi, corrige tes bogues." En regardant les décharges sur incident, nous avons vu ... qu'est-ce que c'est? Le programme a exécuté l'instruction interdite en concaténant les deux chaînes à l'aide d'une fonction de la bibliothèque standard. Hmm, bizarre ... Journal suivant: Impossible de récupérer une page à partir d'un fichier d'échange sur un appareil qui n'a pas du tout d'espace de fichier d'échange alloué (je pense que je comprends pourquoi nous n'avons pas pu récupérer la page!).
J'ai écrit une fois un programme court. Il a alloué 80% de la mémoire système à un seul tableau et y a écrit des entiers séquentiels. Ensuite, j'ai attendu que Entrée soit pressée et vérifié pour voir si le contenu du tableau avait changé. Maintenant, j'ai téléchargé ce programme, j'ai attendu 30 secondes, puis j'ai effectué la vérification. Aucun problème. J'ai essayé plusieurs fois - ha, je savais qu'il n'y avait aucun dommage à la mémoire! J'ai sorti le câble de débogage (USB), après 10 secondes, je l'ai rapidement inséré et retiré, puis réinséré. Bam! 90 erreurs.
Le tiens.
D'accord, je vais devoir bricoler le port USB. Le problème est donc lié à lui? Le pilote USB ne semble pas implémenter un algorithme magique qui génère des erreurs de bits de manière aléatoire. Probablement un problème avec le matériel? Non, pas avec lui, mais cela ne nous a pas empêché de faire toutes sortes de lubies avec le port USB. Ils ont appelé des ingénieurs qui étaient passés à un autre produit il y a longtemps, et maintenant ils étaient perplexes sur le problème. Je ne me souviens pas combien de temps nous avons passé à nous prouver que le matériel était en ordre complet, complet, oooooo. La mise à la terre était en ordre, la tension était stable, l'horloge fonctionnait avec précision et les lignes DDR étaient si parfaites que vous pleureriez de bonheur en la voyant.
Les appareils testés par les ingénieurs sont devenus de plus en plus instables. J'ai supposé que la machine pouvait charger des données en mémoire, obtenir des erreurs de bits, puis les vider dans la mémoire flash, peut-être même au mauvais endroit (la table des pages était souvent endommagée, on pourrait donc supposer que cela se produit également avec les structures de suivi de fichiers Le contenu pouvait être écrit aux mauvais endroits, et les structures du système de fichiers pourraient se casser, etc.) Au fil du temps, les périphériques se sont tellement dégradés qu'ils ne pouvaient plus démarrer de manière fiable. Finalement, l'un des ingénieurs est tombé en panne et a écrasé l'image qui se trouvait sur son ordinateur portable. Cette image était relativement ancienne.
- Mec. Il s'agit du logiciel.
- Quelle?!?!?! Je vous assure que nous n'avons pas écrit peu de fée!
Non: il a téléchargé un assemblage il y a trois mois et le problème a disparu. À ce moment-là, je me sentais responsable d'avoir impliqué un groupe de personnes dans une entreprise très longue et dénuée de sens, alors je suis resté toute la nuit et j'ai fait une recherche binaire dans tous les correctifs au cours des derniers mois (il a fallu plus de temps pour étudier les assemblages complets de l'ensemble du système d'exploitation que je ne le souhaiterais. ...).
Alors, quel était ce patch magique? Quelqu'un a ajouté un pilote pour la puce que nous avons analysée au noyau. Cette puce n'était pas dans l'appareil.
Ha! Nous avons trouvé une sorcière! BRÛLE LE!
Beaucoup ont annoncé que le problème était résolu. Ils étaient heureux que dans la prochaine version, ils puissent annuler le patch et passer à autre chose. Nous l'avons fait reculer avec une extrême difficulté, assemblé une image, l'avons testée, tout allait bien. Nous ne nous attendions pas à ce que le même défaut apparaisse dans le noyau dans quelques jours.
Attendre. Si la puce n'était pas sur la carte, comment le conducteur nous a-t-il empêchés? J'ai lancé lsmod, le pilote n'était pas chargé ... «Quoi qu'il en soit, quelle est la différence, supprimez le fichier du module et rechargez-le. Nifiga, le problème demeure. Ce n'est pas normal ... "
Maintenant, j'étais seul et je regardais la diable se dérouler. A commencé à analyser attentivement le patch. C'était un joli fichier C de 10K lignes fourni par le fabricant de puces. Il serait trop condescendant de le décrire avec le mot «chaos» (en toute honnêteté, après quelques semaines, ils nous ont envoyé un chauffeur beaucoup plus attentionné). Après avoir fouillé un peu, j'ai décidé que le pilote n'avait pas mis en œuvre le bit-jongling-for-fun. Alors, quel est le problème? 48 octets à partir de cinq lignes de code. Une petite structure dans le fichier de démarrage qui indique quelle adresse de bus rechercher la puce. J'ai supprimé la plupart des pilotes, mais j'y ai laissé une structure différente. Le problème persistait.
Donc, garçons et filles, nous avons un problème d'alignement! D'une manière ou d'une autre, cette structure de 48 octets déplace quelque chose en mémoire et cela conduit à des erreurs. J'ai découvert que le problème se produit lorsque vous mettez quelque chose de plus de 32 et moins de 64 octets dans un fichier. Cette connaissance n'a pas beaucoup aidé, mais au moins elle a créé un sentiment de progrès.
La compilation du noyau a produit un fichier System.map soigné. Il a répertorié où se trouvent dans l'espace d'adressage virtuel du noyau toutes les variables compilées dans le noyau. J'ai découvert que ma petite structure se trouve au milieu de la section ".data". Cette section est remplie de variables initialisées, de sorte que lorsque le binaire du noyau a été décompressé en mémoire, il écrirait toutes ces variables à partir de l'image compilée. En utilisant System.map comme référence, j'ai implémenté une recherche binaire plutôt loufoque. Pour la plupart, j'ai recherché les liens de différents fichiers C. J'ai trouvé une variable avec laquelle comparer; trouvé le fichier noyau qui le contient; mettre ma structure magique à côté de moi dans un fichier aléatoire et j'ai commencé à voir si le problème réapparaissait.
La recherche a procédé aux derniers éléments .data et est revenue les mains vides. Il n'y avait aucune donnée requise en mémoire avec des variables initialisées. En parcourant le fichier System.map, j'ai vu que je n'avais pas prêté attention à toute la section .bss, qui contenait des variables non initialisées. Tiré des leçons des erreurs du passé, j'ai d'abord vérifié le début et la fin. Bien sûr, une variable non initialisée au début d'une section entraînait des erreurs, contrairement à une variable à la fin d'une section. Trouver le coupable n'était qu'une question de temps. La variable dont le mouvement a causé le problème était ...
Pointeur de fonction?!
Comment diable l'alignement du pointeur de fonction ruine-t-il notre système? Dans l'architecture ARM, vous ne pouvez pas lire les mots lors d'un accès sans alignement, c'est-à-dire que chaque variable 32 bits doit être mise en mémoire à une adresse multiple de 4. Un pointeur de fonction ne fait pas exception, il obtient toujours l'adresse minimale. Il s'avère que dans notre situation de problème, l'adresse était un multiple de 2 n , supérieur ou égal à 64. Toute valeur inférieure à ce seuil - et le problème a disparu. Il y avait aussi de l'ordre avec l'alignement du pointeur.
Il n'y a pas de bon alignement. Du moins pas avant que ce bogue ne se produise.
Or, ce pointeur de fonction n'était pas le pointeur «à l'ancienne». Il faisait référence à quelque chose de spécial. Il y avait une zone dans la SRAM du processeur que nous pourrions utiliser pour les tâches liées à la charge si nous ne pouvions pas utiliser la RAM. Pour économiser de l'énergie pendant l'inactivité, nous avons copié un sous-programme dans cette zone, défini un pointeur spécial qui s'y référait, puis l'avons appelé. Que faisait le sous-programme? Jetons un coup d'œil à l'assembleur. Je ne suis pas un expert assembleur ARM, mais les commentaires étaient assez éloquents.
// ...
...
// LPDDR
Qu'est-ce que tu fais?! Vous êtes rapidement passé des opérations de base des registres à la désactivation du contrôleur de mémoire. J'ai envoyé un e-mail au fabricant qui a écrit le sous-programme et lui ai demandé s'il manquait quelque chose.
Trois jours plus tard, j'ai reçu une réponse dans le style «Oh oui, il doit y avoir une barrière de mémoire». Il s'avère qu'en raison de la structure de leur cache L2, ils devraient en plus prendre en charge TLB si nous écrivions accidentellement un multiple de 64 à l'adresse mémoire. Dans ce cas, nous pouvons toujours utiliser la RAM lorsque le contrôleur est éteint.
Considérant que l'alignement des variables nécessite une multiplicité minimum de 4, et que le dernier enregistrement ne peut pas avoir une multiplicité de 64 ou plus, à chaque compilation un seizième des données était totalement inutilisable par le système.
En fin de compte, nous avons expédié un produit fiable avec une barrière de mémoire, et les clients ont adoré. Oui, et au cas où vous vous poseriez la question, je ne pouvais pas le remarquer avec le câble USB, car nous ne pouvions pas entrer en mode basse consommation en raison de l'utilisation de l'USB. C'est purement un problème USB.
Message d'erreur non valide
Dans les dernières heures du 17 septembre 1996, la veille du lancement prévu du service WebTV, notre groupe s'est réuni au centre des opérations de Palo Alto. Une foule d'administrateurs système du réseau et de développeurs de logiciels de service se sont retrouvés à proximité pour assister au lancement officiel.
Lorsque l'heure fixée a sonné, l'un des réseaux a commencé à s'inscrire sur son appareil WebTV. Nous avons compris que les bons surnoms prendraient fin rapidement, il était donc important de s'inscrire avant que les utilisateurs ne commencent à le faire. De plus, c'était agréable d'être parmi les premiers à s'inscrire au premier "vrai" service. Avant cela, tous les comptes étaient des comptes de test «à usage unique».
Plusieurs personnes se pressaient, le regardant taper sur le clavier, se sentant étourdi par l'anticipation et le manque de sommeil. Bryce a entré son nom, son adresse et d'autres informations, puis a commencé à taper un surnom. C'était son nom pour une adresse e-mail. Il a tapé "jazz", ce qui signifie que son courrier devrait être "jazz@webtv.net". Lorsqu'il a appuyé sur Entrée sur le clavier sans fil, nous avons entendu un son distinctif indiquant l'apparition d'un message d'erreur. Tout le monde a regardé l'écran.
Pour comprendre ce qui s'est passé ensuite, il est important de savoir une ou deux choses sur le service. WebTV était positionné comme une télévision familiale, il était donc nécessaire de vérifier le langage grossier et de filtrer les noms d'utilisateur et autres informations visibles par les utilisateurs. Il est impossible de tout attraper, mais il n'est pas difficile de filtrer les choses évidentes.
Les noms personnalisés ont été comparés à une liste d'expressions régulières, ce qui leur a permis d'être mis en correspondance avec un modèle. Par exemple, "fu. * Bar" sera comparé à tous les noms commençant par "fu" et se terminant par "bar". Si vous choisissez vos modèles avec soin, vous pouvez attraper et rejeter des variations flagrantes comme "shitake" et "matsushita", qui ont des malédictions intégrées.
Le même mécanisme a été utilisé pour empêcher les utilisateurs de choisir des noms "interdits" comme "postmaster", "root", "admin" et "help". Nous avions un fichier texte comme celui-ci:
admin.*
"admin".
postmaster
postmaster.
poop
.
weenie
.
Chaque entrée se composait de deux lignes. La première était l'expression régulière à comparer, et la deuxième ligne était le message d'erreur qui était affiché à l'utilisateur. Le système a lu le fichier deux lignes à la fois, et lorsque l'utilisateur a entré le nom, il a été comparé à toutes les expressions régulières. Un message d'erreur a été affiché pour la première correspondance trouvée. S'il n'y avait pas de correspondance, le nom personnalisé était accepté.
Le code qui lisait le fichier savait ignorer les commentaires. Mais il ne savait pas comment gérer les lignes vides.
Quelqu'un a modifié le fichier des jurons, en ajoutant en cours de route une ligne vierge après les noms «réservés» et avant les jurons. Lorsque le code lit la liste, il prend la chaîne vide comme expression régulière et le mot qui la suit comme message d'erreur. Une expression de chaîne vide correspond à tout.
Minuit. Nous sommes tous un peu nerveux. Bryce écrit le nom et le système répond avec un message simple:
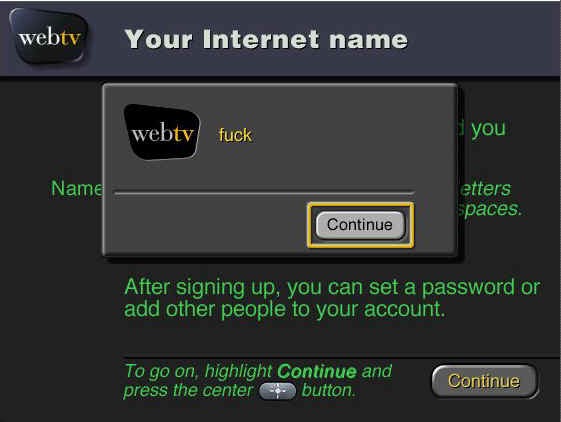
Nous avons commencé à rire hystériquement. D'autres sont venus nous voir pour savoir ce qui se passait. Nous l'avons montré à l'écran. Ils ont commencé à rire hystériquement.
À ce moment-là, dans un autre bâtiment, Mark Armstrong (en charge de l'assurance qualité), avec Bruce Leek (l'un des fondateurs de l'entreprise), était assis devant un comptoir de seize consoles WebTV. Ce rack, surnommé «racksville», était connecté via un multiplexeur vidéo à un grand téléviseur, affichant les images des 16 boîtiers simultanément. Mark et Bruce ont commencé à enregistrer les décodeurs à l'aide d'un clavier avec un émetteur infrarouge. Nous les avons appelés sur l'interphone:
- Comment ça va?
- Tout parfaitement.
- Oh super. Vous avez peut-être remarqué certaines choses lors de votre inscription.
- Oui? Nous n'avons rien remarqué d'étrange.
- Remarquer.
- D'accord. Entrer le code postal ... jusqu'à présent, tout va bien. OGO !!!
Un message amical est apparu sur les images des 16 pièces jointes. Les patrons ont suggéré que nous devions peut-être corriger ce problème dès que possible. Cela nous a semblé une excellente idée.
Nous avons corrigé le fichier et appris au code à reconnaître et à ignorer les lignes vides. Autant que je sache, WebTV n'a dit "f - k" à aucun client.
Problème de crash Xbox
À l'époque, l'équipe travaillait sur l'un des premiers jeux pour une toute nouvelle console appelée Xbox. Lorsque les tests finaux ont été accélérés, le contrôle qualité a lancé trois décodeurs à partir du lot d'installation pour exécuter des tests automatisés la nuit. Si la version d'hier du jeu était encore en cours de test dans la matinée, cela indiquait sa stabilité.
Malheureusement, l'une des consoles s'est écrasée le matin. Les plantages sont toujours mauvais, mais c'était un cas extrêmement grave: quelque chose exécuté par la carte vidéo a fait planter tout le système. Diagnostiquer les problèmes de carte graphique est difficile: pas de débogueur, pas de traces de pile, pas de débogage avec
printf. Vous ne pouvez lire que le code et expérimenter.
Ainsi commença la chasse aux insectes. Chaque jour, les ingénieurs principaux examinaient les preuves disponibles, émettaient des hypothèses et écartaient les possibilités. Chaque nuit, QA a obtenu une baisse «aléatoire» sans raison. "C'est impossible", "Comment cela se produit-il?", "C'est peut-être un bogue dans le compilateur?" - tous les succès les plus populaires.
Sur la voiture des ingénieurs, le jeu a parfaitement fonctionné pendant plusieurs jours. Mais ce n'était pas une consolation, car la date limite d'envoi du jeu à l'impression et à l'expédition en magasin approchait.
Heureusement, nous avons rapidement trouvé un modèle, quoique plutôt étrange. Le jeu ne s'est écrasé que la nuit et uniquement sur l'une des trois consoles. Nous avons commencé à chercher des différences entre eux. Il ne s'agissait pas du câble d'alimentation. Pas dans les contrôleurs. DVD brûlé dans le désordre. Transférer la console sur votre table - elle ne tombe pas. Remettez-le - il tombe. Il s'agissait d'un stand spécifique utilisé par QA.
Maintenant, le processus d'exclusion des facteurs exigeait l'exclusion de toutes les variables. À la fin, désespéré, l'ingénieur a tenté d'échanger les pièces jointes de la table.
Il s'est avéré que ce n'était pas un préfixe spécifique qui fonctionnait mal. Tout préfixe de cette table est tombé. Au milieu de la nuit. Parfois, pour des raisons scientifiques, il faut agir de façon étrange, et c'était l'un de ces cas. L'ingénieur s'est assis stoïquement sur une chaise, recouverte de canettes de Red Bull, et Bug Hunt s'est transformé en Bug Watching. L'ingénieur a juré qu'il regarderait des tests automatisés s'exécuter sur les consoles de cette foutue table jusqu'à ce qu'il voie l'échec de ses propres yeux.
La nuit passa lentement, puis rapidement, et enfin l'aube vint. Le jeu a continué à fonctionner. C'était inspirant. Le soleil a commencé à se lever.
Et puis quelque chose d'intéressant s'est finalement produit: un rayon de soleil levant est tombé sur la table. Minute après minute, le faisceau se glissa sur la table jusqu'aux accessoires, sa lueur chaude enveloppa tranquillement le dôme noir de l'accessoire.
Qui est tombé rapidement.
La première Xbox avait un problème: la carte vidéo pouvait mal fonctionner si la température de la console atteignait une certaine valeur. Le logiciel n'avait rien à voir avec cela. Un problème matériel a été signalé, le jeu est sorti et Red Bull a été remplacé par de la bière. D'accord, soyons honnêtes, pour le whisky. Un: zéro pour la science.