Une grande partie de la vie d'un projet dépend de la façon dont le modèle objet et la structure de la base sont bien pensés au départ.
L'approche généralement acceptée a été et demeure diverses options pour combiner le schéma "en étoile" avec la troisième forme normale. En règle générale, selon le principe: données initiales - 3NF, vitrines - étoile. Cette approche éprouvée par le temps, soutenue par de nombreuses recherches, est la première (et parfois la seule) chose à laquelle une personne expérimentée en DWH pense lorsqu'elle réfléchit à ce à quoi un référentiel analytique devrait ressembler.
D'autre part, les entreprises en général et les besoins des clients en particulier ont tendance à évoluer rapidement et les données croissent à la fois «en profondeur» et «en largeur». Et c'est là que se manifeste le principal inconvénient de la star: une flexibilité limitée .
Et si dans votre vie tranquille et chaleureuse en tant que développeur DWH, soudainement:
- la tâche est venue «de faire au moins quelque chose rapidement, et ensuite nous verrons»;
- un projet en développement rapide est apparu, avec la connexion de nouvelles sources et une refonte du business model au moins une fois par semaine;
- un client est apparu qui n'imagine pas à quoi devrait ressembler le système et quelles fonctions il devrait remplir à la fin, mais est prêt pour des expériences et un raffinement cohérent du résultat souhaité avec une approche cohérente;
- le chef de projet est passé avec la bonne nouvelle: "Et maintenant nous avons agile!"
Ou si vous êtes simplement curieux de savoir comment vous pouvez construire un espace de stockage - bienvenue sous le chat!

Que signifie flexibilité?
Tout d'abord, définissons les propriétés que le système doit avoir pour être qualifié de «flexible».
Séparément, il convient de noter que les propriétés décrites doivent se rapporter spécifiquement au système , et non au processus de son développement. Par conséquent, si vous souhaitez en savoir plus sur Agile en tant que méthodologie de développement, il est préférable de lire d'autres articles. Par exemple, juste là, sur Habré, il y a beaucoup de matériel intéressant (à la fois d' enquête et pratique , et problématique ).
Cela ne veut pas dire que le processus de développement et la structure du CD ne sont pas du tout liés. En général, il devrait être beaucoup plus facile de développer un stockage Agile d'architecture flexible. Cependant, dans la pratique, il y a plus d'options avec le développement Agile de DWH classique par Kimball et DataVault par cascade que d'heureuses coïncidences de flexibilité dans ses deux hypostases sur un projet.
Alors, quelles sont les capacités du stockage flexible? Il y a trois points ici:
- Une livraison précoce et une révision rapide signifient que, idéalement, le premier résultat commercial (par exemple, les premiers rapports de travail) devrait être reçu le plus tôt possible, c'est-à-dire avant même que l'ensemble du système ne soit entièrement conçu et mis en œuvre. De plus, chaque révision ultérieure devrait également prendre le moins de temps possible.
- — , . — , , . , , — .
- Adaptation constante aux besoins changeants de l'entreprise - la structure globale de l'objet doit être conçue non seulement en tenant compte de l'expansion possible, mais dans l'espoir que la direction de cette prochaine expansion ne rêve même pas de vous au stade de la conception.
Et oui, il est possible de répondre à toutes ces exigences dans un seul système (bien sûr, dans certains cas et avec quelques réserves).
Ci-dessous, je considérerai deux des méthodologies de conception agile les plus populaires pour la HD: le modèle Anchor et le Data Vault.... Derrière les parenthèses se trouvent d'excellentes techniques comme EAV, 6NF (dans sa forme pure) et tout ce qui concerne les solutions NoSQL - non pas parce qu'elles sont en quelque sorte pires, et même pas parce que dans ce cas l'article menacerait d'acquérir le volume de la moyenne dissera. C'est juste que tout cela fait référence à des solutions d'une classe légèrement différente - soit à des techniques que vous pouvez appliquer dans des cas spécifiques, quelle que soit l'architecture générale de votre projet (comme EAV), soit à d'autres paradigmes de stockage d'informations (comme les bases de données graphiques et autres options) NoSQL).
Problèmes de l'approche «classique» et leurs solutions dans les méthodologies agiles
Par l'approche «classique», j'entends la bonne vieille star (quelle que soit l'implémentation spécifique des couches sous-jacentes, que les adeptes de Kimball, Inmon et CDM me pardonnent).
1. Cardinalité rigide des liens
Ce modèle est basé sur une séparation claire des données en dimensions (dimension) et faits (faits) . Et cela, bon sang, est logique - après tout, l'analyse des données dans la très grande majorité des cas se résume à l'analyse de certains indicateurs numériques (faits) dans certaines sections (dimensions).
Dans ce cas, les liens entre objets sont posés sous forme de liens entre tables par une clé étrangère. Cela semble tout à fait naturel, mais conduit immédiatement à la première limitation de la flexibilité - une définition rigide de la cardinalité des connexions .
Cela signifie qu'au stade de la conception des tables, vous devez définir précisément pour chaque paire d'objets liés s'ils peuvent être plusieurs à plusieurs, ou seulement 1 à plusieurs, et «dans quelle direction». Cela détermine directement laquelle des tables aura une clé primaire et laquelle aura une clé externe. Changer cette attitude lorsque de nouvelles exigences seront reçues entraînera très probablement une refonte de la base.
Par exemple, lors de la conception de l'objet «caisse enregistreuse», vous avez prévu, en vous appuyant sur les serments du service commercial, la possibilité d' une promotion agissant sur plusieurs postes chèques (mais pas l'inverse):
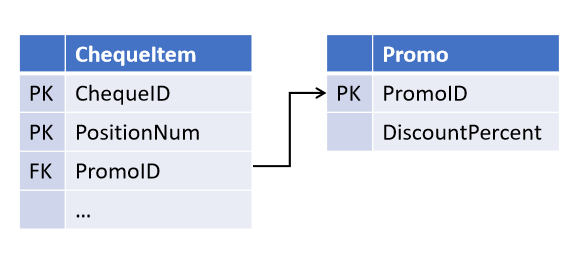
Et après un certain temps, les collègues ont introduit une nouvelle stratégie marketing, dans laquelle plusieurs promotions peuvent agir simultanément sur le même poste . Et maintenant, vous devez modifier les tables en sélectionnant le lien dans un objet séparé.
(Tous les objets dérivés, dans lesquels une vérification promotionnelle est effectuée, doivent maintenant également être améliorés).
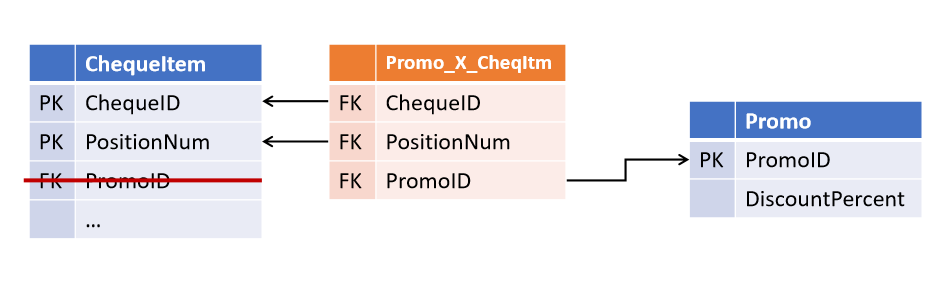
Liens dans le Data Vault et Anchor Model Il
s'est avéré assez simple d'éviter une telle situation: vous
Cette approche a été proposée par Dan Linstedt dans le cadre du paradigme Data Vault et est entièrement prise en charge par Lars Rönnbäck dans le modèle d'ancrage .
En conséquence, nous obtenons la première caractéristique distinctive des méthodologies agiles:
Les relations entre les objets ne sont pas stockées dans les attributs des entités parentes, mais constituent un type d'objet distinct.Le Data Vault est un ligament de table appelé Link , et les Anchor Models - le Tie . À première vue, ils sont très similaires, bien que leurs différences ne se limitent pas au nom (qui sera discuté ci-dessous). Dans les deux architectures, les tables de liaison peuvent lier n'importe quel nombre d'entités (pas nécessairement 2).
À première vue, cette redondance offre une grande flexibilité pour les modifications. Une telle structure devient tolérante non seulement pour changer la cardinalité des liens existants, mais aussi pour en ajouter de nouveaux - si maintenant la position du chèque a également un lien vers le caissier qui l'a poinçonné, l'apparition d'un tel lien deviendra simplement un add-on sur les tables existantes sans affecter les objets existants et processus.

2. Duplication des données
Le second problème, résolu par des architectures flexibles, est moins évident et est essentiellement inhérent aux mesures de type SCD2 (dimensions lentement changeantes du second type), mais pas uniquement à elles.
Dans un magasin classique, une dimension est généralement une table qui contient une clé de substitution (sous forme de PK) et un ensemble de clés métier et d'attributs dans des colonnes séparées.

Si la dimension est versionnée, les limites de temps de version sont ajoutées à l'ensemble standard de champs et plusieurs versions apparaissent par ligne dans la source dans le magasin (une pour chaque modification des attributs versionnés).
Si une dimension contient au moins un attribut versionné qui change fréquemment, le nombre de versions d'une telle dimension sera impressionnant (même si les autres attributs ne sont pas versionnés ou ne changent jamais), et s'il existe plusieurs de ces attributs, le nombre de versions peut augmenter de manière exponentielle à partir de leur nombre. Une telle dimension peut occuper une quantité importante d'espace disque, bien que la plupart des données qui y sont stockées soient simplement des valeurs dupliquées d'attributs inchangés à partir d'autres lignes.

Dans ce cas, la dénormalisation est également très souvent utilisée - certains des attributs sont intentionnellement stockés sous forme de valeur et non de référence à un répertoire ou à une autre dimension. Cette approche accélère l'accès aux données en réduisant le nombre de jointures lors de l'accès à une dimension.
En règle générale, cela conduit au fait queles mêmes informations sont stockées simultanément à plusieurs endroits . Par exemple, des informations sur la région de résidence et appartenant à la catégorie du client peuvent être stockées simultanément dans les dimensions «Client» et les faits «Achat», «Livraison» et «Appels au centre d'appels», ainsi que dans le tableau de liaison «Client - Gestionnaire de clients».
En général, ce qui précède s'applique aux mesures régulières (non versionnées), mais dans celles versionnées, elles peuvent avoir une échelle différente: l'apparition d'une nouvelle version d'un objet (surtout avec le recul) conduit non seulement à mettre à jour toutes les tables associées, mais à l'apparition en cascade de nouvelles versions d'objets associés - lorsque le tableau 1 est utilisé pour construire le tableau 2, et le tableau 2 est utilisé pour construire le tableau 3, etc. Même si aucun des attributs du tableau 1 ne participe à la construction du tableau 3 (et d'autres attributs du tableau 2 obtenus à partir d'autres sources sont impliqués), une mise à jour versionnée de cette construction entraînera au moins des frais généraux supplémentaires, et tout au plus - des versions inutiles du tableau 3. ce qui n'a rien à voir avec cela et plus loin dans la chaîne.

3. Complexité non linéaire de la révision
De plus, chaque nouveau magasin, construit sur un autre, augmente le nombre d'endroits dans lesquels les données peuvent «diverger» lorsque des modifications sont apportées à ETL. Ceci, à son tour, conduit à une augmentation de la complexité (et de la durée) de chaque révision ultérieure.
Si ce qui précède concerne des systèmes avec des processus ETL rarement modifiés, vous pouvez vivre dans un tel paradigme - il vous suffit de vous assurer que les nouvelles modifications sont correctement introduites dans tous les objets associés. Si des révisions se produisent fréquemment, la probabilité de «manquer» accidentellement plusieurs connexions augmente considérablement.
Si, en plus, on tient compte du fait que l'ETL «versionné» est beaucoup plus compliqué que «non versionné», il devient assez difficile d'éviter les erreurs avec une révision fréquente de toute cette économie.
Stockage d'objets et d'attributs dans le coffre-fort de données et le modèle d'ancrage
L'approche proposée par les auteurs d'architectures agiles peut être formulée comme suit:
Il est nécessaire de séparer ce qui change de ce qui reste inchangé. Autrement dit, séparez les clés des attributs.Dans le même temps, il ne faut pas confondre un attribut non versionné avec un attribut inchangé : le premier ne stocke pas l'historique de sa modification, mais il peut changer (par exemple, lorsqu'une erreur de saisie est corrigée ou de nouvelles données sont reçues); le second ne change jamais.
Les points de vue sur ce qui peut être considéré comme immuable dans le Data Vault et le modèle d'ancrage diffèrent.
Du point de vue de l'architecture Data Vault , l' ensemble des clés peut être considéré comme inchangé - naturel (TIN de l'organisation, code produit dans le système source, etc.) et substitut. Dans ce cas, les attributs restants peuvent être divisés en groupes par source et / ou fréquence des modifications, et une table séparée avec un ensemble indépendant de versions peut être gérée pour chaque groupe .
Dans le paradigmeLe modèle d'ancrage est considéré comme une clé de substitution d' entité uniquement immuable . Tout le reste (y compris les clés naturelles) n'est qu'un cas particulier de ses attributs. Dans le même temps, tous les attributs par défaut sont indépendants les uns des autres , par conséquent, une table distincte doit être créée pour chaque attribut .
Dans Data Vault, les tables contenant des clés d'entité sont appelées Hubs . Les hubs contiennent toujours un ensemble fixe de champs:
- Clés naturelles d'entité
- Clé de substitution
- Lien vers la source
- Enregistrer le temps d'ajout
Les entrées dans Hubs ne sont jamais modifiées et n'ont pas de version . Extérieurement, les hubs sont très similaires aux tables du type ID-map utilisé dans certains systèmes pour générer des substituts, cependant, il est recommandé de ne pas utiliser une séquence d'entiers comme substituts dans Data Vault, mais un hachage d'un ensemble de clés métier. Cette approche simplifie le chargement des liens et des attributs à partir des sources (vous n'avez pas besoin de rejoindre le hub pour obtenir un substitut, il vous suffit de calculer le hachage à partir de la clé naturelle), mais peut causer d'autres problèmes (liés, par exemple, aux collisions, à la casse et aux caractères non imprimables dans les clés de chaîne, etc.) .p.), il n'est donc pas généralement accepté.
Tous les autres attributs d'entité sont stockés dans des tables spéciales appelées Satellites... Un hub peut avoir plusieurs satellites stockant différents ensembles d'attributs.
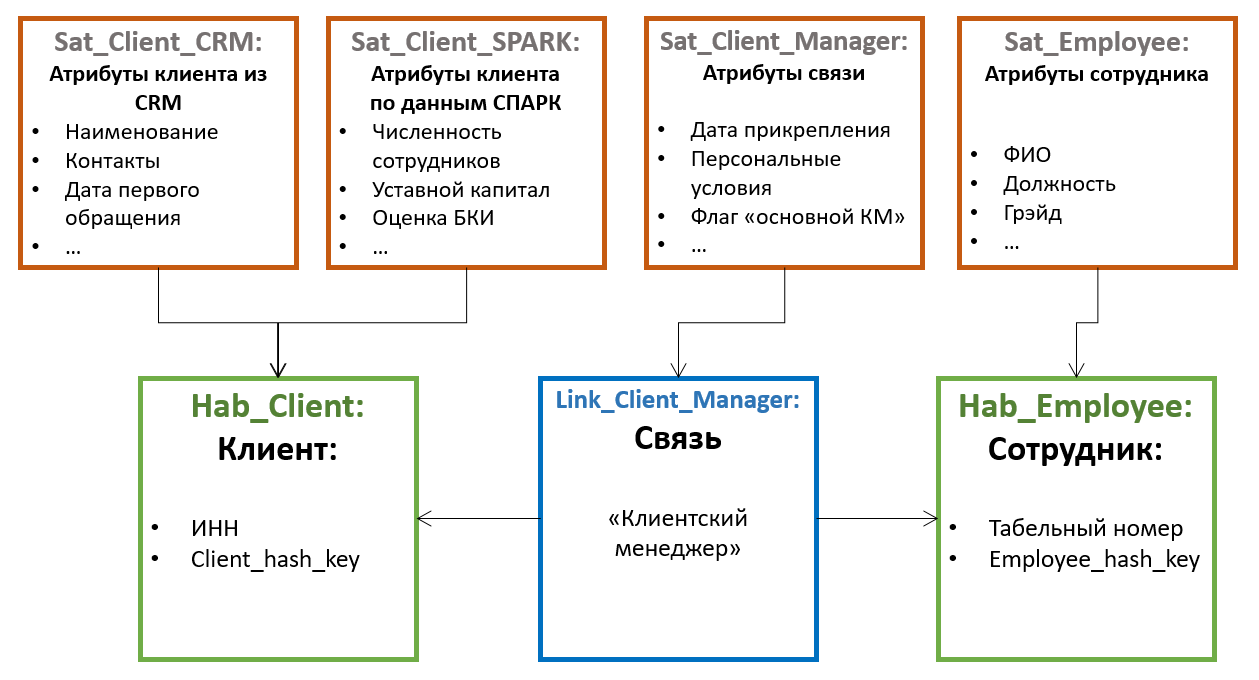
La distribution des attributs entre les satellites est basée sur le principe du changement conjoint - un satellite peut stocker des attributs non versionnés (par exemple, date de naissance et SNILS pour un individu), dans un autre - ceux qui changent rarement de version (par exemple, nom de famille et numéro de passeport), dans le troisième - souvent changement (par exemple, adresse de livraison, catégorie, date de la dernière commande, etc.). Dans ce cas, le versionnage est effectué au niveau des satellites individuels, et non de l'entité dans son ensemble, il est donc conseillé de distribuer les attributs de sorte que l'intersection des versions au sein d'un satellite soit minimale (ce qui réduit le nombre total de versions stockées).
De plus, afin d'optimiser le processus de chargement des données, les attributs obtenus à partir de diverses sources sont souvent placés dans des satellites séparés.
Les satellites communiquent avec le Hub à l'aide d'une clé étrangère (qui correspond à une cardinalité 1 à plusieurs). Cela signifie que plusieurs valeurs d'attribut (par exemple, plusieurs numéros de téléphone de contact pour un client) sont prises en charge par cette architecture «par défaut».
Dans le modèle d'ancrage, les tables qui contiennent des clés sont appelées Ancre . Et ils gardent:
- Clés de substitution uniquement
- Lien vers la source
- Enregistrer le temps d'ajout
Les clés naturelles sont considérées comme des attributs ordinaires du point de vue du modèle d'ancrage . Cette option peut sembler plus difficile à comprendre, mais elle laisse beaucoup plus de place à l'identification des objets.

Par exemple, si les données relatives à la même entité peuvent provenir de systèmes différents, chacun utilisant sa propre clé naturelle. Dans le Data Vault, cela peut conduire à des structures assez lourdes de plusieurs hubs (un par source + la version maître unificatrice), tandis que dans le modèle Anchor, la clé naturelle de chaque source tombe dans son propre attribut et peut être utilisée lors du chargement indépendamment de toutes les autres.
Mais il y a un point insidieux ici: si les attributs de différents systèmes sont combinés dans une seule entité, il y en a probablementdes règles de "collage" , selon lesquelles le système doit comprendre que les enregistrements de différentes sources correspondent à une instance d'une entité.
Dans Data Vault, ces règles détermineront très probablement la formation du «hub de substitution» de l'entité maître et n'affecteront en aucun cas les hubs qui stockent les clés naturelles des sources et leurs attributs d'origine. Si à un moment donné le changement des règles d'épissage (ou une mise à jour des attributs par lesquels il est fait) arrive, il suffira de reformer les hubs de substitution.
Dans le modèle Anchor, cependant, une telle entité sera très probablement stockée dans une seule ancre.... Cela signifie que tous les attributs, quelle que soit leur source, seront liés au même substitut. Séparer les enregistrements fusionnés par erreur et, en général, suivre la pertinence de la fusion dans un tel système peut être beaucoup plus difficile, surtout si les règles sont suffisamment complexes et changent souvent, et que le même attribut peut être obtenu à partir de sources différentes (bien que cela soit certainement possible, car chaque la version de l'attribut conserve un lien vers sa source).
Dans tous les cas, si votre système est censé implémenter la fonctionnalité de déduplication, fusionner des enregistrements et d'autres éléments MDM, il vaut la peine d'examiner de près les aspects du stockage des clés naturelles dans les méthodologies agiles. La conception plus lourde du Data Vault est susceptible de se révéler soudainement plus sûre en termes d'erreurs de fusion.
Le modèle d'ancre prévoit également un type d'objet supplémentaire appelé nœud, en fait il s'agit d'un type d'ancre dégénéré spécial qui ne peut contenir qu'un seul attribut. Les nœuds sont censés être utilisés pour stocker des livres de référence plats (par exemple, le sexe, l'état matrimonial, la catégorie de service client, etc.). Contrairement à Anchor, Node n'a pas de tables attributaires associées, et son seul attribut (nom) est toujours stocké dans la même table avec la clé. Les nœuds sont liés aux ancres par des tables de liens, tout comme les ancres le sont entre elles.
Il n'y a pas d'opinion sans équivoque sur l'utilisation de Nodes. Par exemple, Nikolai Golov , qui promeut activement l'utilisation du modèle Anchor en Russie, estime (ce qui n'est pas déraisonnable) que pour aucun ouvrage de référence, il est impossible de dire avec certitude qu'il sera toujours statique et à un seul niveau, il est donc préférable d'utiliser une ancre à part entière pour tous les objets à la fois.
Une autre différence importante entre le Data Vault et le modèle Anchor est la présence d' attributs pour les liens :
dans le Data Vault, les Liens sont les mêmes objets à part entière que les Hubs et peuvent avoirpropres attributs . Dans le modèle Anchor, les liens sont utilisés uniquement pour connecter des ancres et ne peuvent pas avoir leurs propres attributs . Cette différence donne des approches sensiblement différentes de la modélisation des faits , qui seront discutées ci-dessous.
Stockage des faits
Avant cela, nous parlions principalement de modélisation des mesures. Avec les faits, la situation est un peu moins simple.
Dans Data Vault, un objet typique pour stocker des faits est un lien , dans les satellites duquel de vrais indicateurs sont ajoutés.
Cette approche semble intuitive. Il offre un accès facile aux indicateurs analysés et est généralement similaire à une table de faits traditionnelle (seuls les indicateurs sont stockés non pas dans la table elle-même, mais dans celle «adjacente»). Mais il y a aussi des pièges: l'une des modifications typiques du modèle - l'extension de la clé de fait - nécessite l' ajout d'une nouvelle clé étrangère à Link . Et cela, à son tour, «rompt» la modularité et entraîne potentiellement le besoin d'améliorations à d'autres objets.
Dans le modèle d'ancreUn lien ne peut pas avoir ses propres attributs, donc cette approche ne fonctionnera pas - absolument tous les attributs et indicateurs doivent être liés à un ancrage spécifique. La conclusion est simple - chaque fait a également besoin de son propre ancrage . Pour une partie de ce que nous avons l'habitude de prendre pour des faits, cela peut paraître naturel - par exemple, le fait d'un achat se réduit parfaitement à l'objet «commande» ou «reçu», une visite sur un site - à une séance, etc. Mais il y a aussi des faits pour lesquels il n'est pas si facile de trouver un tel «objet porteur» naturel - par exemple, les restes de marchandises dans les entrepôts au début de chaque journée.
En conséquence, la modularité ne pose aucun problème lors de l'extension de la clé de fait dans le modèle Anchor (il vous suffit d'ajouter un nouveau lien à l'ancre correspondante), mais la conception du modèle pour afficher les faits est moins claire, des ancres «artificielles» peuvent apparaître et refléter le modèle d'objet métier n'est pas évidente.
Comment la flexibilité est atteinte
La construction résultante dans les deux cas contient beaucoup plus de tableaux que la dimension traditionnelle. Mais il peut occuper beaucoup moins d'espace disque avec le même ensemble d'attributs versionnés qu'une dimension traditionnelle. Naturellement, il n'y a pas de magie ici - tout est question de normalisation. En répartissant les attributs sur les satellites (dans le Data Vault) ou sur des tables séparées (Anchor Model), nous réduisons (ou éliminons complètement) la duplication des valeurs de certains attributs lors de la modification d'autres .
Pour le Data Vault, le gain dépendra de la distribution des attributs sur les satellites, et pour le modèle d'ancrage , il sera presque directement proportionnel au nombre moyen de versions par objet de mesure.
Cependant, gagner de l'espace est un avantage important mais pas le principal du stockage des attributs séparément. Associée au stockage séparé des liens, cette approche fait du référentiel une conception modulaire . Cela signifie que l'ajout d'attributs individuels et de nouveaux domaines entiers dans un tel modèle ressemble à un complément sur un ensemble d'objets existant sans les modifier. Et c'est exactement ce qui rend les méthodologies décrites flexibles.
Cela ressemble également à la transition de la production à la pièce à la production en série - si dans l'approche traditionnelle chaque table modèle est unique et nécessite une attention particulière, alors dans les méthodologies flexibles, il s'agit déjà d'un ensemble de «détails» typiques. D'une part, il y a plus de tables, les processus de chargement et de récupération des données devraient paraître plus compliqués. En revanche, ils deviennent typiques . Cela signifie qu'ils peuvent être automatisés et gérés par des métadonnées . La question «comment allons-nous la poser?», À laquelle la réponse pourrait occuper une part importante de la conception des améliorations, n'en vaut tout simplement plus la peine (ainsi que la question de l'impact des changements de modèle sur les processus de travail).
Cela ne signifie pas que les analystes ne sont pas du tout nécessaires dans un tel système - quelqu'un doit encore élaborer un ensemble d'objets avec des attributs et déterminer où et comment charger tout cela. Mais la quantité de travail, ainsi que la probabilité et le coût d'une erreur, sont considérablement réduits. Tant au stade de l'analyse que lors du développement d'ETL, qui dans une partie essentielle peut se réduire à l'édition de métadonnées.
Côté obscur
Tout ce qui précède rend les deux approches vraiment flexibles, technologiquement avancées et adaptées au raffinement itératif. Bien sûr, il y a aussi un «baril de pommade», dont je pense que vous êtes déjà en train de deviner.
La décomposition des données, qui est à la base de la modularité des architectures flexibles, conduit à une augmentation du nombre de tables et, par conséquent, à la surcharge des jointures lors de l'échantillonnage. Afin d'obtenir simplement tous les attributs d'une dimension, une seule sélection suffit dans le référentiel classique et une architecture flexible nécessitera un certain nombre de jointures. De plus, si pour les rapports toutes ces jointures peuvent être écrites à l'avance, alors les analystes habitués à écrire du SQL à la main en souffriront doublement.
Plusieurs faits facilitent cette situation:
Lorsque vous travaillez avec de grandes dimensions, tous ses attributs ne sont presque jamais utilisés en même temps. Cela signifie qu'il peut y avoir moins de jointures qu'il n'y paraît lorsque vous regardez le modèle pour la première fois. Dans le Data Vault, vous pouvez également prendre en compte la fréquence de partage estimée lors de la distribution des attributs sur les satellites. Dans le même temps, les concentrateurs ou les ancres eux-mêmes sont nécessaires principalement pour générer et mapper des substituts au stade du chargement et sont rarement utilisés dans les demandes (en particulier pour les ancres).
Toutes les jointures se font par clé.De plus, une manière plus «concise» de stocker les données réduit la surcharge de l'analyse des tables si nécessaire (par exemple, lors du filtrage par valeur d'attribut). Cela peut conduire au fait que la récupération à partir d'une base de données normalisée avec un tas de jointures sera encore plus rapide que l'analyse d'une dimension lourde avec plusieurs versions par ligne.
Par exemple, dans cet article, il y a un test de performances comparatif détaillé du modèle d'ancrage avec une sélection dans une seule table.
Cela dépend beaucoup du moteur. De nombreuses plates-formes modernes ont des mécanismes d'optimisation des jointures internes. Par exemple, MS SQL et Oracle peuvent «ignorer» les jointures aux tables si leurs données ne sont utilisées nulle part sauf pour d'autres jointures et n'affectent pas la sélection finale (élimination de table / jointure), tandis que MPP Vertica estl'expérience de collègues d'Avito , s'est avérée être un excellent moteur pour le modèle Anchor, en tenant compte d'une optimisation manuelle du plan de requête. D'un autre côté, conserver le modèle d'ancrage, par exemple, sur Click House, qui a un support de jointure limité, ne semble pas être une bonne idée pour le moment.
En outre, il existe des techniques spéciales pour les deux architectures afin de faciliter l'accès aux données (à la fois du point de vue des performances des requêtes et pour les utilisateurs finaux). Par exemple, des tables ponctuelles dans le coffre-fort de données ou des fonctions de table spéciales dans le modèle d'ancrage.
Total
L'essence principale des architectures flexibles considérées est la modularité de leur «conception».
C'est cette propriété qui permet:
- , ETL, , . ( ) .
- ( ) 2-3 , ( ).
- , - .
- En raison de la décomposition en éléments standard, les processus ETL dans de tels systèmes ont le même type, leur écriture se prête à l'algorithmisation et, finalement, à l' automatisation .
Le prix de cette flexibilité est la performance . Cela ne signifie pas qu'il est impossible d'obtenir des performances acceptables sur de tels modèles. Le plus souvent, vous avez juste besoin de plus d'efforts et d'attention aux détails pour atteindre les paramètres que vous souhaitez.
Applications
Types d'entités Data Vault

Plus d'informations sur Data Vault:
le site de Dan Listadt
Tout sur Data Vault en russe A
propos de Data Vault sur Habré
Types d'entités de modèle d'ancrage

En savoir plus sur Anchor Model:
Site of Anchor Model creators
Un article sur l'expérience de l'implémentation d'Anchor Model dans Avito
Un tableau récapitulatif présentant les caractéristiques communes et les différences des approches envisagées:
